一、函数
1.1函数的定义与作用
编程中的函数是可重复使用的代码片段,类似数学函数(输入不同参数得到不同结果),主要作用是:
- 消除重复代码,提升代码复用性;
- 便于代码维护(修改函数即可同步所有调用处)。
示例对比:求不同区间的和时,用函数可将重复的求和逻辑封装,只需调用时传入不同参数。
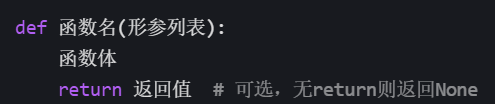
1.2函数的语法格式
1.定义函数:
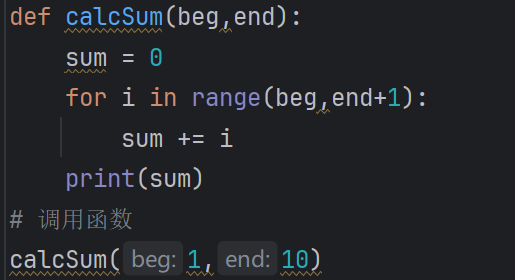
2.调用函数:

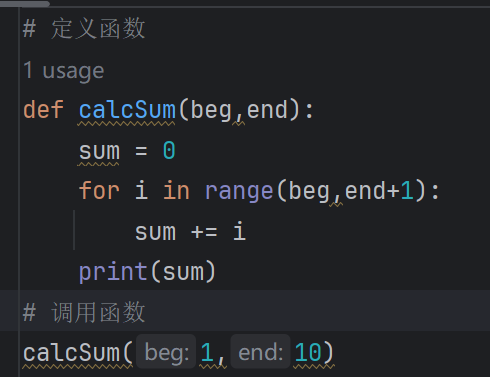
1.3函数的核心规则
- 定义与调用的关系 :
- 函数定义后不会自动执行,必须调用才会执行,调用次数对应执行次数;
- 函数必须先定义,再调用(否则会报
NameError)。
- 参数(形参 & 实参) :
- 形参:函数定义时的参数(如
calcSum(beg, end)中的beg、end); - 实参:函数调用时传递的实际值(如
calcSum(1, 100)中的1、100); - 规则:形参与实参的数量必须匹配;函数可无参数、单参数或多参数。
- 形参:函数定义时的参数(如
1.4函数参数的特性
Python 是动态类型语言,函数形参无需指定类型,可接收多种类型的参数(如同一函数可传入整数、字符串、布尔值)。
- 注意:调用函数时,实参数量必须与形参匹配,否则会报
TypeError。
1.5函数返回值
返回值是函数的 "输出"(类比工厂的产品),通过return语句实现,核心规则:
- 逻辑与交互分离 :函数应专注于计算逻辑(用
return返回结果),而非直接进行用户交互(如打印),便于适配不同的交互场景(保存文件、网络发送等)。 - 多 return 语句 :函数可包含多个
return,执行到return时函数立即结束并返回。 - 多返回值 :函数可通过逗号分隔返回多个值,调用时用多个变量接收;若需忽略部分返回值,可用
_占位。
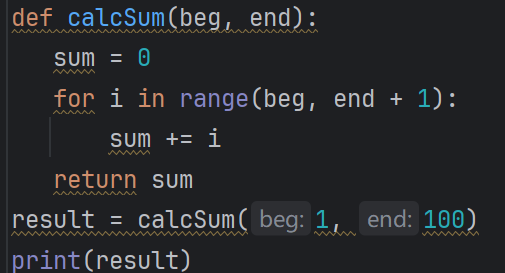
一个函数中可以有多个 return 语句:

执行到 return 语句, 函数就会立即执行结束, 回到调用位置:

一个函数是可以一次返回多个返回值的. 使用 , 来分割多个返回值:
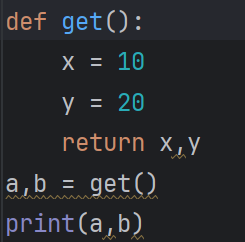
如果只想关注其中的部分返回值, 可以使用 _ 来忽略不想要的返回值:

1.6变量作用域
函数内部定义的变量(局部变量)仅在函数内部生效,外部无法直接访问;函数内外同名变量是不同的独立变量。
- 局部变量与全局变量 :
- 函数内部定义的是局部变量,仅在函数内生效;
- 函数外部定义的是全局变量,作用域覆盖整个代码。
- 同名变量的独立性 :不同作用域中允许存在同名变量,实际是独立的变量(如函数内外的
x互不影响)。 - 变量查找逻辑:函数内部访问变量时,先找局部变量;局部不存在则查找全局变量。
- 修改全局变量 :函数内修改全局变量需用
global关键字声明,否则会被视为创建局部变量。 - 语句块不影响作用域 :
if/while/for等语句块内定义的变量,在块外部仍可使用(与函数作用域不同)。
1.7函数的执行过程
- 函数仅在被调用时执行内部代码,不调用则不执行;
- 函数执行到
return语句或代码结束时,回到调用位置继续执行后续代码。
补充:函数执行的调试方法
可通过 PyCharm 的调试功能观察执行流程:插入断点→以 Debug 模式运行→用Step Into逐行执行。
1.8函数的调用方式
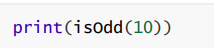
- 链式调用 :将一个函数的返回值直接作为另一个函数的参数,简化代码(如
print(isOdd(10))替代先赋值再打印)。

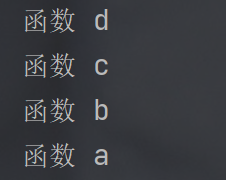
2.嵌套调用 :函数内部调用其他函数,可多层嵌套;执行顺序由调用顺序决定(如d()调用c(),c()调用b(),b()调用a(),则执行顺序为d→c→b→a)。

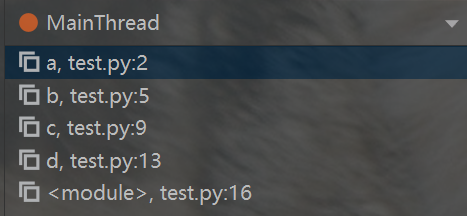
1.9函数调用栈
Python 用函数调用栈管理函数调用关系:
- 每次函数调用会在栈中新增一个 "栈帧",存储该函数的局部变量;
- 函数执行结束后,对应的栈帧会从调用栈中移除;
- 可通过 PyCharm 调试工具查看调用栈及各栈帧的局部变量。
补充:嵌套调用的执行逻辑
嵌套函数的执行顺序取决于调用语句的位置:若b()中先调用a()再打印,则执行顺序为a→b;若先打印再调用a(),则顺序为b→a。
1.10函数递归
递归是函数嵌套调用自身的特殊情况,需满足两个核心条件:
- 存在递归结束条件 (如计算阶乘时
n == 1); - 实参逐渐逼近结束条件 (如
n - 1)。
- 若条件不满足,会出现 "无限递归",导致
RecursionError(调用栈溢出)。 - 优缺点 :
- 优点:代码量少,符合数学归纳法逻辑;
- 缺点:可读性差、易栈溢出,执行效率低于循环。
1.11参数默认值
函数形参可指定默认值,调用时若不传递该参数,则使用默认值:
- 规则:带默认值的参数必须放在无默认值参数的后面 ,否则会报
SyntaxError。 - 示例:
def add(x, y, debug=False)中,debug为默认参数,调用时可省略。

1.12关键字参数
调用函数时,可通过 "形参名=实参值" 的方式显式指定参数,不受形参顺序限制:
- 示例:
test(x=10, y=20)与test(y=100, x=200)均合法,参数按指定名称匹配。

二、列表与元组
2.1列表与元组的概念
两者都是批量存储数据的容器,核心区别是可变性:
- 列表:类似 "散装辣条",元素可修改、新增、删除(可变容器);
- 元组:类似 "包装辣条",元素在创建时固定,无法修改(不可变容器)。

2.2列表的基础操作
- 创建列表 :
- 空列表:
alist = []或alist = list(); - 带初始值:
alist = [1, 2, 3],支持不同类型元素 (如[1, 'hello', True])。
- 空列表:

2.访问元素(下标):
- 下标从 0 开始,通过
alist[下标]读取 / 修改元素(如alist[2]对应第 3 个元素); - 下标越界会报
IndexError,有效范围是[0, len(alist)-1](len()可获取列表长度); - 支持负下标(如
alist[-1]表示倒数第 1 个元素)。



2.3列表的进阶操作
通过下标操作是一次取出里面第一个元素.
通过切片, 则是一次取出一组连续的元素, 相当于得到一个子列表
1.切片 :通过[起始:结束:步长]获取连续子列表,规则:
- 区间是前闭后开 (如
[1:3]取下标 1、2 的元素); - 可省略边界(
[1:]取到末尾,[:-1]取到倒数第 2 个); - 步长可正(正向取)、负(反向取),越界不报错。

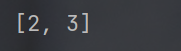
- 切片操作中可以省略前后边界

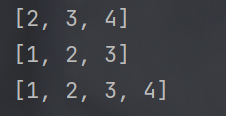
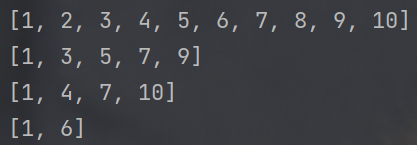
- 切片操作还可以指定 "步长" , 也就是 "每访问一个元素后, 下标自增几步"

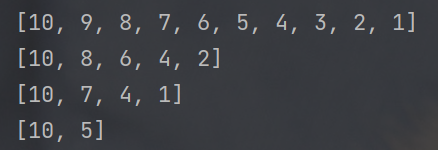
- 切片操作指定的步长还可以是负数, 此时是从后往前进行取元素. 表示 "每访问一个元素之后, 下标自 减几步"

- 如果切片中填写的数字越界了, 不会有负面效果. 只会尽可能的把满足条件的元素过去到


2.遍历:

- 也可以使用 for 按照范围生成下标, 按下标访问

- 还可以使用 while 循环. 手动控制下标的变化

3.新增元素:
- 使用 append 方法, 向列表末尾插入一个元素(尾插).

- 使用 insert 方法, 向任意位置插入一个元素
insert 第一个参数表示要插入元素的下标.


4.查找元素
- 使用 in 操作符, 判定元素是否在列表中存在. 返回值是布尔类型.

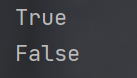
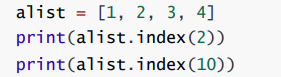
- 使用 index 方法, 查找元素在列表中的下标. 返回值是一个整数. 如果元素不存在, 则会抛出异常.
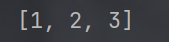
5.删除元素
- 使用 pop 方法删除最末尾元素

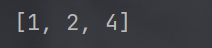
- pop 也能按照下标来删除元素

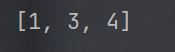
- 使用 remove 方法, 按照值删除元素.

6.连接列表
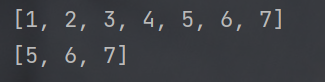
- 使用 + 能够把两个列表拼接在一起.
此处的 + 结果会生成一个新的列表. 而不会影响到旧列表的内容.


- 使用 extend 方法, 相当于把一个列表拼接到另一个列表的后面.
a.extend(b) , 是把 b 中的内容拼接到 a 的末尾. 不会修改 b, 但是会修改 a.

2.4元组的核心特性
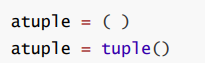
- 定义 :用
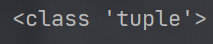
()表示,功能与列表类似,但元素不可修改;
- 支持操作 :仅支持读操作 (下标、切片、遍历、
in、index、+),不支持写操作(修改、增删); - 优势 :
- 数据安全(避免函数乱改数据);
- 可作为字典的键(列表不可,因字典键需为不可变对象);
- 应用场景:函数多返回值默认是元组。

2.5列表与元组的选择
- 元素需修改→选列表;
- 元素无需修改→选元组(更安全、支持字典键)。