目录

为什么要分库分表?
单表数据量大,索引先扛不住。MySQL(InnoDB)索引本质是 B+Tree,数据越多树越高导致一次查询磁盘IO越多。
| 行数 | B+Tree 高度 | 影响 |
|---|---|---|
| 100 万 | 3 | 很快 |
| 1000 万 | 4 | 明显变慢 |
| 1 亿 | 5 | 随机 IO 飙升 |
一般Mysql单表存储<500w,而一但>1000w就需要分库分表,让数据量下降 → 索引高度下降。
而分表分库分别解决下面问题:
| 类型 | 解决什么 |
|---|---|
| 分表 | 单表太大 |
| 分库 | 单库 QPS / IO / 连接数用尽扛不住 / 磁盘容量有限 |
| 分库 + 分表 | 高并发 + 大数据量(订单系统标配) |
分库分表是指通过一定的规则,如果按时间范围划分,根据hash取模、指定分片等算法,将数据量大的数据库拆分成多个单独数据库 ,将原本数据量大的表拆分成若干个数据表,使得单一的库、表性能达到最优的效果(响应速度快),以此提升整体数据库性能。
| 名称 | 解释 |
|---|---|
| 垂直分库 | 在开始规模比较小的单体项目来说,所有的业务都是放在同一个数据库中,比如产品、订单、用户、支付都是在同一个库中,但随着项目越来越庞大,数据量也越来越大,就需要按照不同的业务来拆分成多个库。 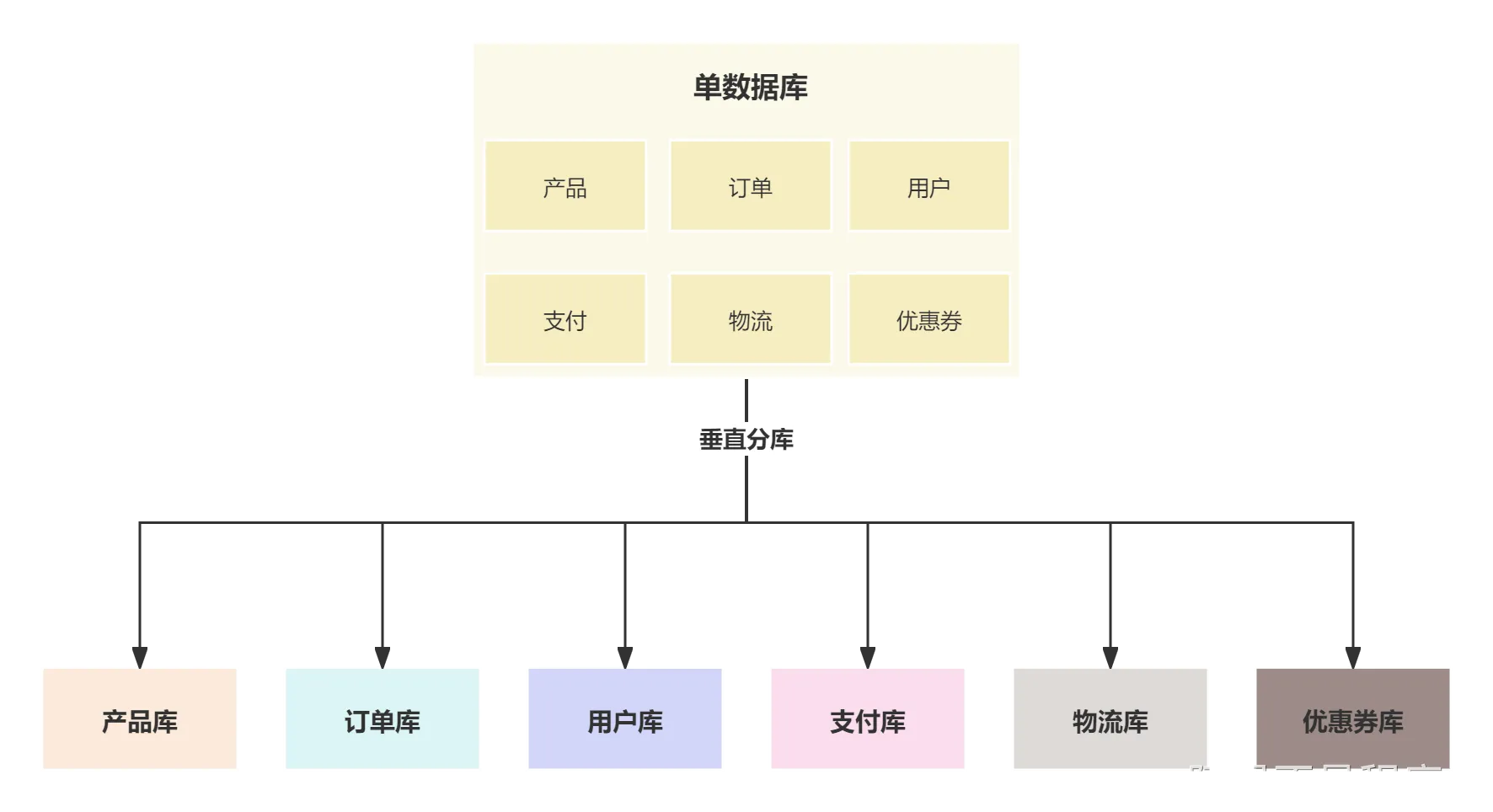 |
| 水平分库 | 水平分库是把同一个表按一定规则拆分到不同的数据库中,每个库可以位于不同的服务器上,每个数据库的库和表结构都是相同的,只有表中的数据不同。可以实现水平扩展,有效缓解单库的性能瓶颈。 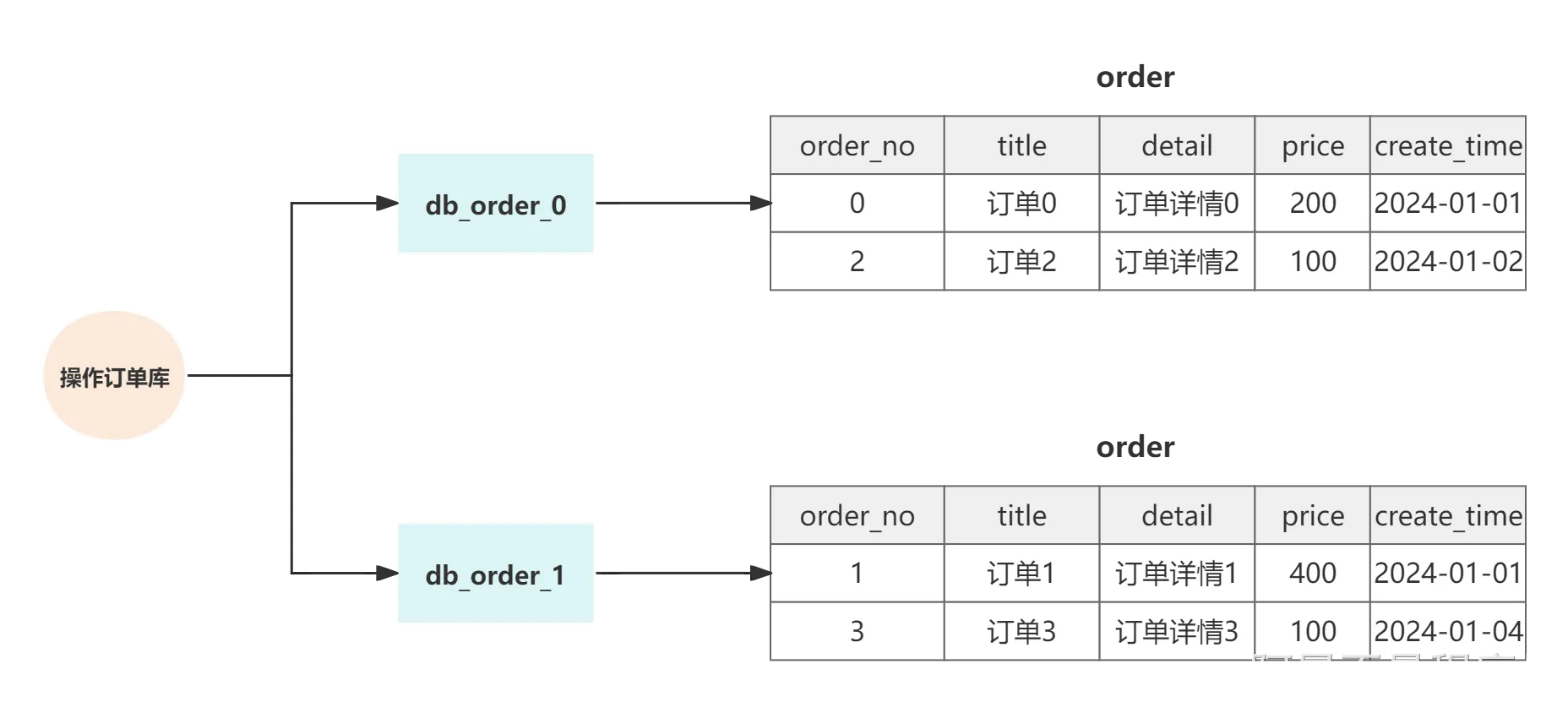 |
| 垂直分表 | 适用于字段非常多的表,对于很多的查询来说,其实不需要一次将所有的字段全都查询出来,这样很浪费性能,影响效率。 将经常查询的字段单独拆分出一个表,将另外的字段单独拆分成另一个表,拆分后的表通过某个字段关联起来,这样既可以减少表的容量大小,又可以提升查询效率。 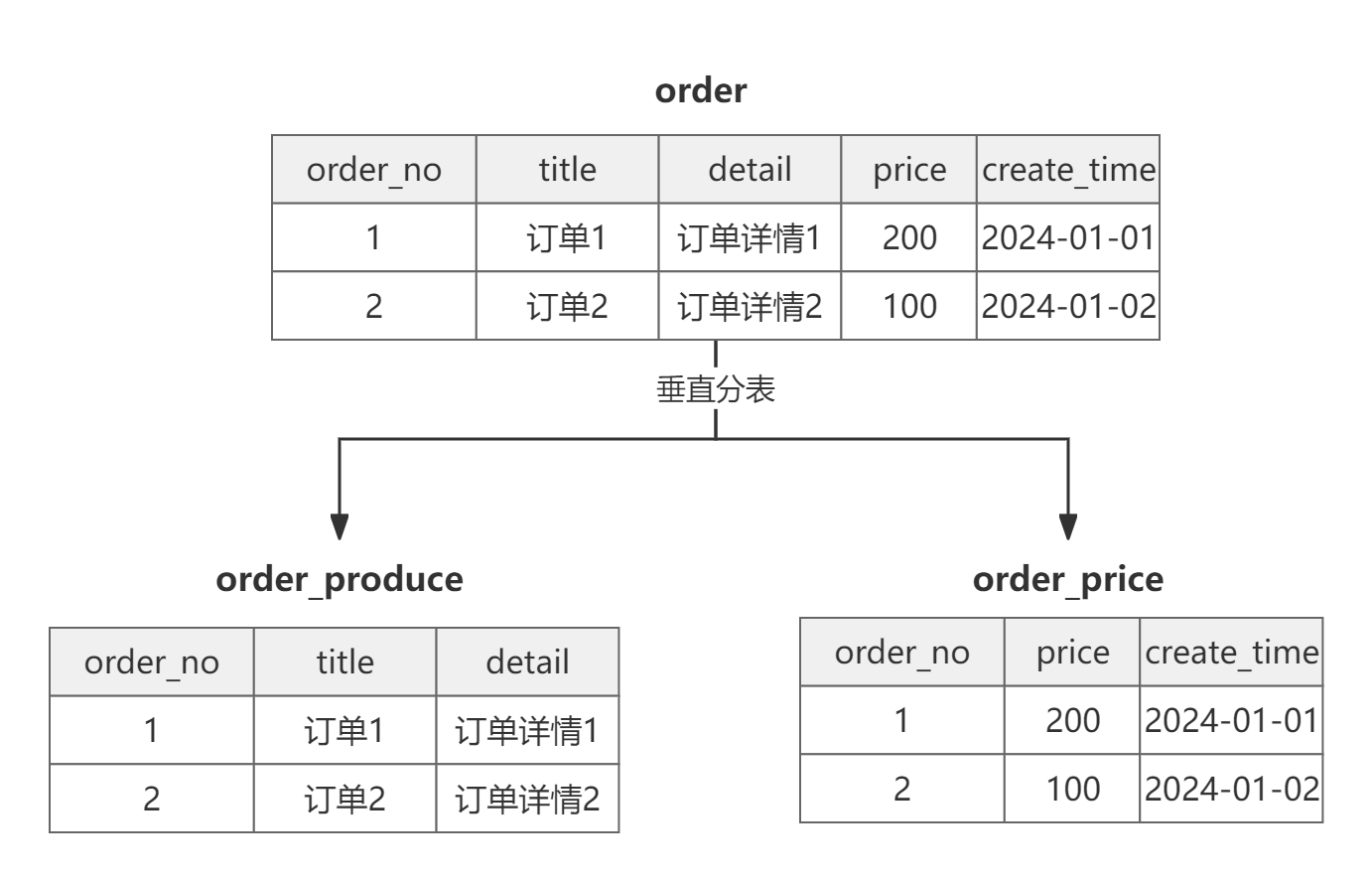 |
| 水平分表 | 水平分表是在同一个数据库内,对大表进行水平拆分,分割成多个表结构相同的表。 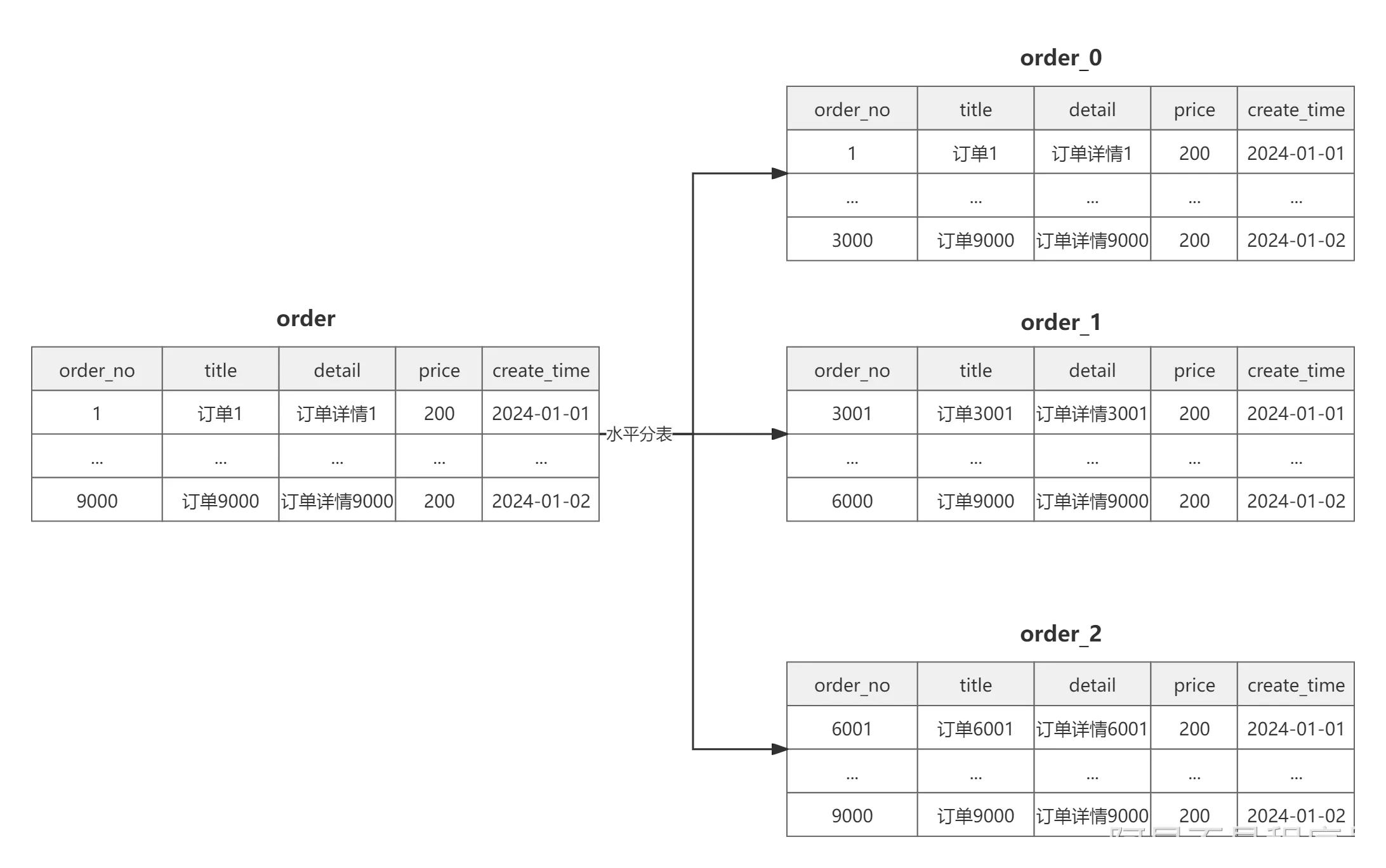 |
如何使用ShardingSphere
下面是官网链接:ShardingSphere 官网地址![]() https://shardingsphere.apache.org/document/5.3.2/cn/overview/Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
https://shardingsphere.apache.org/document/5.3.2/cn/overview/Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
其内部包含两种架构:ShardingSphere-JDBC与ShardingSphere-Proxy
| 组件 | 本质 |
|---|---|
| ShardingSphere-JDBC | 轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 |
| ShardingSphere-Proxy | 透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。 可以理解成 ShardingSphere-Proxy伪装成了 Mysql,我们直接操作这个伪装的 Mysql 即可,但性能上肯定还是不如直接使用 ShardingSphere-JDBC进行分库分表 |
1.概念:
核心概念 :: ShardingSphere![]() https://shardingsphere.apache.org/document/5.3.2/cn/features/sharding/concept/
https://shardingsphere.apache.org/document/5.3.2/cn/features/sharding/concept/
(内容来源:大麦项目介绍 | JavaUp 技术&实战)
| 名称 | 理解 |
|---|---|
| 逻辑表 | 相同结构的水平拆分数据库(表)的逻辑名称,是 SQL 中表的逻辑标识。 例:订单数据根据主键尾数拆分为 10 张表,分别是 t_order_0 到 t_order_9,他们的逻辑表名为 t_order。 我们在代码写SELECT * FROM t_order WHERE order_id = 10001;,这里的 t_order 就是逻辑表,代码里永远只写逻辑表,不关心分库分表。 |
| 真实表 | 在水平拆分的数据库中真实存在的物理表。 即上个示例中的 t_order_0 到 t_order_9。 |
| 绑定表 | 分片规则完全一致的一组表。假设两张表 t_order 与 t_order_item,他们都按照 order_id 进行分库分表,分库数、分表数完全一致。 sql SELECT * FROM t_order o JOIN t_order_item i ON o.order_id = i.order_id WHERE o.order_id = 10001; |
| 广播表 | 指所有的分片数据源中都存在的表,表结构及其数据在每个数据库中均完全一致。 适用于数据量不大且需要与海量数据的表进行关联查询的场景。适用于字典表、配置表、区域表、权限常量。 |
| 单表 | 指所有的分片数据源中仅唯一存在的表。 适用于数据量不大且无需分片的表。 |
**数据节点:**数据分片的最小单元,由数据源名称和真实表组成。 例:ds_0.t_order_0。 逻辑表与真实表的映射关系,可分为均匀分布和自定义分布两种形式。
**分片键:**用于将数据库(表)水平拆分的数据库字段。 例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL 中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,Apache ShardingSphere 也支持根据多个字段进行分片。
如何选择分片键?
如何选择分片键在分库分表中非常的重要,可以说直接影响了整个分库分表的性能,如果分片键选择不当,很可能会导致 全路由 查询,也就是将分库分表的中所有的库以及所有的表都要路由一遍,这样效率是非常低下的,所以一定要慎重考虑分片键。从以下方面来考虑
- 业务相关性:分片键应该与业务密切相关,能够反映出数据访问的模式。通常,选择那些经常作为查询条件的字段作为分片键,可以减少跨分片的查询,提高查询效率。
- 均匀分布数据:理想的分片键能够确保数据在各个分片间均匀分布,避免某些分片数据量过大而成为瓶颈。均匀的数据分布有助于负载均衡,提升整体性能。
- 写入性能:在考虑分片键时,应考虑到写入操作的性能。一个好的分片键可以减少写入时的热点问题,避免某个分片因为频繁的写入操作而过载。
- 避免频繁修改:分片键一旦选择并开始使用后,修改起来将非常困难且成本很高。因此,应选择那些不会或很少需要修改的字段作为分片键。
- 考虑未来的扩展性:在选择分片键时,还需要考虑到数据量增长和系统扩展的需要。分片键的选择应该能够适应数据量的增加,允许在不影响现有系统的前提下添加更多的分片。
- 避免业务操作跨分片:如果业务操作需要跨多个分片进行,可能会严重影响性能。因此,应尽可能选择可以将相关数据局部化的分片键,减少跨分片操作的需求。
- 安全和隐私考虑:在某些情况下,分片键的选择还需要考虑数据的安全和隐私要求。例如,使用敏感信息(如用户ID)作为分片键时,需要确保分片策略遵守相关的数据保护法规。
分片算法: ShardingSphere 对于分片算法有非常灵活的配置,对于常见的分片算法,如 MOD(取模)、HASH_MOD(哈希取模)、BOUNDARY_RANGE(分片边界的范围)都有默认的支持,并且也可以自定义实现分片算法,包括单分片键、复合分片键。
2.使用:
首先引入依赖:
XML
<properties>
<shardingsphere.version>5.3.2</shardingsphere.version>
</properties>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core</artifactId>
<version>${shardingsphere.version}</version>
<exclusions>
<exclusion>
<artifactId>logback-classic</artifactId>
<groupId>ch.qos.logback</groupId>
</exclusion>
</exclusions>
</dependency>之后根据规则进行分库分表的规则配置:
bash
spring:
datasource:
driver-class-name: org.apache.shardingsphere.driver.ShardingSphereDriver
url: jdbc:shardingsphere:classpath:shardingsphere-user.yaml之后在下面目录创建YAML文件:

shardingsphere-user.yaml配置:
首先声明数据库的配置:(这里声明两个库 user_0 与 user_1)
bash
dataSources:
# 第一个用户库
ds_0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://127.0.0.1:3306/user_0?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: xxx
password: xxx
# 第二个用户库
ds_1:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://127.0.0.1:3306/user_1?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: xxx
password: xxx之后进行数据分片配置:
数据分片 YAML 配置方式具有非凡的可读性,通过 YAML 格式,能够快速地理解分片规则之间的依赖关系,ShardingSphere 会根据 YAML 配置,自动完成 ShardingSphereDataSource 对象的创建,减少用户不必要的编码工作。
bash
rules:
- !SHARDING
tables: # 数据分片规则配置
<logic_table_name> (+): # 逻辑表名称
actualDataNodes (?): # 由数据源名 + 表名组成(参考 Inline 语法规则)
databaseStrategy (?): # 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
standard: # 用于单分片键的标准分片场景
shardingColumn: # 分片列名称
shardingAlgorithmName: # 分片算法名称
complex: # 用于多分片键的复合分片场景
shardingColumns: # 分片列名称,多个列以逗号分隔
shardingAlgorithmName: # 分片算法名称
hint: # Hint 分片策略
shardingAlgorithmName: # 分片算法名称
none: # 不分片
tableStrategy: # 分表策略,同分库策略
keyGenerateStrategy: # 分布式序列策略
column: # 自增列名称,缺省表示不使用自增主键生成器
keyGeneratorName: # 分布式序列算法名称
auditStrategy: # 分片审计策略
auditorNames: # 分片审计算法名称
- <auditor_name>
- <auditor_name>
allowHintDisable: true # 是否禁用分片审计hint
autoTables: # 自动分片表规则配置
t_order_auto: # 逻辑表名称
actualDataSources (?): # 数据源名称
shardingStrategy: # 切分策略
standard: # 用于单分片键的标准分片场景
shardingColumn: # 分片列名称
shardingAlgorithmName: # 自动分片算法名称
bindingTables (+): # 绑定表规则列表
- <logic_table_name_1, logic_table_name_2, ...>
- <logic_table_name_1, logic_table_name_2, ...>
broadcastTables (+): # 广播表规则列表
- <table_name>
- <table_name>
defaultDatabaseStrategy: # 默认数据库分片策略
defaultTableStrategy: # 默认表分片策略
defaultKeyGenerateStrategy: # 默认的分布式序列策略
defaultShardingColumn: # 默认分片列名称
# 分片算法配置
shardingAlgorithms:
<sharding_algorithm_name> (+): # 分片算法名称
type: # 分片算法类型
props: # 分片算法属性配置
# ...
# 分布式序列算法配置
keyGenerators:
<key_generate_algorithm_name> (+): # 分布式序列算法名称
type: # 分布式序列算法类型
props: # 分布式序列算法属性配置
# ...
# 分片审计算法配置
auditors:
<sharding_audit_algorithm_name> (+): # 分片审计算法名称
type: # 分片审计算法类型
props: # 分片审计算法属性配置
# ...我们的shardingsphere-user.yaml配置:
定义两个**物理数据库:**user_0,user_1【为分库准备两个真实数据库】
分库分表规则(SHARDING):
d_user_mobile表的分库分表都是用的mobile作为分片键,算法为HASH_MOD,hash取模d_user_email表的分库分表都是用的HASH_MOD,hash取模d_user表的分库分表都是用的id作为分片键,算法为MOD,取模
bash
dataSources:
# 第一个用户库
ds_0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://127.0.0.1:3306/user_0?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: xxx
password: xxx
# 第二个用户库
ds_1:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://127.0.0.1:3306/user_1?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: xxx
password: xxx
rules:
# 分库分表规则
- !SHARDING
tables:
# 对d_user_mobile表进行分库分表
d_user_mobile:
# 库为damai_user_0 damai_user_1 表为d_user_mobile_0 至 d_user_mobile_1
actualDataNodes: ds_${0..1}.d_user_mobile_${0..1}
# 分库策略
databaseStrategy:
standard:
# 使用mobile作为分片键
shardingColumn: mobile
# 用user_mobile列使用hash取模作为分库算法
shardingAlgorithmName: databaseUserMobileHashModModel
# 分表策略
tableStrategy:
standard:
# 使用mobile作为分片键
shardingColumn: mobile
# 用user_mobile列使用hash取模作为分表算法
shardingAlgorithmName: tableUserMobileHashMod
# 对d_user_email表进行分库分表
d_user_email:
# 库为damai_user_0 damai_user_1 表为d_user_email_0 至 d_user_email_1
actualDataNodes: ds_${0..1}.d_user_email_${0..1}
# 分库策略
databaseStrategy:
standard:
# 使用email作为分片键
shardingColumn: email
# 用user_mobile列使用hash取模作为分库算法
shardingAlgorithmName: databaseUserEmailHashModModel
# 分表策略
tableStrategy:
standard:
# 使用email作为分片键
shardingColumn: email
# 用user_mobile列使用hash取模作为分表算法
shardingAlgorithmName: tableUserEmailHashMod
# 对d_user表进行分库分表
d_user:
# 库为damai_user_0 damai_user_1 表为d_user_0 至 d_user_1
actualDataNodes: ds_${0..1}.d_user_${0..1}
# 分库策略
databaseStrategy:
standard:
# 使用id作为分片键
shardingColumn: id
# 用id列使用hash取模作为分库算法
shardingAlgorithmName: databaseUserModModel
# 分表策略
tableStrategy:
standard:
# 使用id作为分片键
shardingColumn: id
# 用id列使用hash取模作为分表算法
shardingAlgorithmName: tableUserModModel
# 对d_ticket_user表进行分库分表
d_ticket_user:
# 库为damai_user_0 damai_user_1 表为d_ticket_user_0 至 d_ticket_user_1
actualDataNodes: ds_${0..1}.d_ticket_user_${0..1}
# 分库策略
databaseStrategy:
standard:
# 使用user_id作为分片键
shardingColumn: user_id
# 用user_id列使用hash取模作为分库算法
shardingAlgorithmName: databaseTicketUserModModel
# 分表策略
tableStrategy:
standard:
# 使用user_id作为分片键
shardingColumn: user_id
# 用user_id列使用hash取模作为分表算法
shardingAlgorithmName: tableTicketUserModModel
# 具体的算法
shardingAlgorithms:
# d_user_mobile表分库算法
databaseUserMobileHashModModel:
type: HASH_MOD
props:
# 分库数量
sharding-count: 2
# d_user_mobile表分表算法
tableUserMobileHashMod:
type: HASH_MOD
props:
# 分表数量
sharding-count: 2
# d_user_email表分库算法
databaseUserEmailHashModModel:
type: HASH_MOD
props:
# 分库数量
sharding-count: 2
# d_user_email表分表算法
tableUserEmailHashMod:
type: HASH_MOD
props:
# 分表数量
sharding-count: 2
# d_user表分库算法
databaseUserModModel:
type: MOD
props:
# 分库数量
sharding-count: 2
# d_user表分表算法
tableUserModModel:
type: MOD
props:
# 分表数量
sharding-count: 2
# d_ticket_user表分库算法
databaseTicketUserModModel:
type: MOD
props:
# 分库数量
sharding-count: 2
# d_ticket_user表分表算法
tableTicketUserModModel:
type: MOD
props:
# 分表数量
sharding-count: 2
# 加密规则
- !ENCRYPT
tables:
# d_user表
d_user:
columns:
# 对mobile列进行加密
mobile:
# 密文列mobile
cipherColumn: mobile
# 自定义的加密算法
encryptorName: user_encryption_algorithm
# 对password列进行加密
password:
# 密文列password
cipherColumn: password
# 自定义的加密算法
encryptorName: user_encryption_algorithm
# 对id_number列进行加密
id_number:
# 密文列id_number
cipherColumn: id_number
# 自定义的加密算法
encryptorName: user_encryption_algorithm
# d_user_mobile表
d_user_mobile:
columns:
# 对mobile列进行加密
mobile:
# 密文列id_number
cipherColumn: mobile
# 自定义的加密算法
encryptorName: user_encryption_algorithm
props:
# 打印真实sql
sql-show: true为什么要设计 用户手机表 和 用户邮箱表?
一但我们的++查询条件没有带有分片键++ ,就会出现全路由问题 。++ShardingSphere 无法定位数据具体到在哪个库、哪个表,就只能去所有的分片库、分片表上查询++,这种情况的执行效率是非常慢的,会有数据库连接超时、接口超时 各种的问题。
解决: 为了解决手机号和邮箱登录而且不造成全路由的问题。采取附属表的方案,++设置了 用户手机表 和 用户邮箱表 ,通过 手机号 和 邮箱 查询到 用户id,然后使用 用户id 查询用户表++,这样就解决了问题。
如果以后登录业务修改的话,比如再增加使用用户名登录,那么再增加一个 用户名 表即可解决。但使用这种附属表就没有任何问题了吗?显示不是不可能,任何的解决方案都是有相应代价的。
目前来说 这种++使用 附属表路由的方案 是互联网公司比较通用的方案++ ,那么像这种多字段查询的业务都必须使用附属表的方案吗?答案是 不一定 比如 订单业务,订单可以根据订单编号查询,也可以根据用户id查询,这种业务可以用另一种方案,并不需要额外的表来维护,叫分片基因算法。
基因法
1.问题分析:
在分库分表时,经常会遇到++查询的条件不含有分片键的情况++,比如说用户表,生成的订单中是依靠userId来关联用户信息,而用户在登录时又可以使用手机号和邮箱来登录,这样只有userId一个分片键就搞不定了。
刚刚的解决方案是在设计出 用户手机表 用++手机号当做分片键++ 。以及用户邮箱表 用++邮箱当做分片键++。 当用户用手机或者邮箱登录后,分别从相应的用户手机表和用户邮箱表查询出userId,然后用userId去用户表查询信息。
问题: 目前在订单业务中也遇到类似的问题,我们需要既可以通过订单号查询出订单详细,也想通过 userId 查询该用户下的订单列表,这样就需要既通过 order_number 查询又要通过userId查询。看着这里,估计小伙伴就会想了,还是使用附属表路由的方案呗,再设计出一个订单用户表,通过userId去订单用户表查询,得到order_number,然后再去订单表查询信息。
首先说这种方案确实可以解决,但就是要额外维护表。而且对于订单这种量级很大的表来说,附属路由表的量级也会很大。所以最好有另一种方案,可以不用再设计出一张表去维护它,这种方案就是我们要介绍的 基因法。
2.基因法介绍:
基因法 = 从分片键(二进制)中抽取一部分"基因位",再用这部分去决定落库/落表。
特征说明:
对于191 % 32 = 31
- 191的二进制: 10111111
- 32的二进制: 100000 也就是2的5次方
- 31的二进制: 11111
可以发现31的二进制对应191后5位数。
比如说 159,二进制是 10011111 ,对 32 取模,结果还是31。
也就是说如果随便拿一个数转成二进制,然后把二进制的后5位替换成这个11111,然后将这个替换后的值对32进行取模,那么得到的余数也是31,这个5位长度就是靠32的二进制的长度也就是求log2n对数的值。
那么假设我们的分片数量有32个,而我们订单数是2654324532L,用户id是45346343212L,分片数量32的log2n对数是5,将 用户id【45346343212L】 % 分片数量【32】的余数 = 12 转为二进制【1100】,而由于分片数量32的log2n对数是5,12的二进制位数是4位,需要补位【01100】,于是我们将订单数转为二进制,随后将后5位替换为【01100】,也就是原来的订单数【10011110001101011100011100110100】变为新的订单数【10011110001101011100011100101100】,那么新的订单数变为十进制【2654324524L】% 分片数量【32】 = (用户id % 分片数量的余数)【12】。
总而言之,在分片数量为 32 的情况下,只要保证用于路由计算的二进制低 5 位等于 01100,最终一定会落到第 12 号分片【因为01100变十进制为12】。所以我们可以通过后几位数【二进制】去判断当前存储的分片位置,假设后五位是00010,那么就会去2号分片查找。而刚刚的逻辑是将 用户id % 32,所以同一用户的订单数据就会在同一分片内存放。
3.基因法实现:
同样还是要在 application.yml 内声明:
spring:
profiles:
active: local
datasource:
driver-class-name: org.apache.shardingsphere.driver.ShardingSphereDriver
url: jdbc:shardingsphere:classpath:shardingsphere-order-${spring.profiles.active}.yaml之后在 shardingsphere-order-local.yaml 内说明:
前面对于声明两个真实数据库的配置不变,我们有两个库,每个库有四张表。
关键是在后面分片规则,使用「基因法 + 复杂分片算法」。
配置分库策略:
bashdatabaseStrategy: complex: shardingColumns: order_number,user_id shardingAlgorithmName: databaseOrderComplexGeneArithmetic这里声明分片键是 order_number 或 user_id,而真正的逻辑是在 databaseOrderComplexGeneArithmetic 下面声明。
配置分表策略:
bashtableStrategy: complex: shardingColumns: order_number,user_id shardingAlgorithmName: tableOrderComplexGeneArithmetic这里声明分片键同样是 order_number 或 user_id,而真正的逻辑是在 databaseOrderComplexGeneArithmetic 下面声明。
随后声明 d_order 与 d_order_ticket_user 绑定表:【告诉 ShardingSphere:这两张表是"强关联表"】
bashbindingTables: - d_order,d_order_ticket_user随后注册分片算法:
bashdatabaseOrderComplexGeneArithmetic: type: CLASS_BASED # Java 类实现 props: sharding-count: 2 # 数据库数量 = 2 table-sharding-count: 4 # 每库表数 = 4 strategy: complex # complex(多个分片键) algorithmClassName: com.damai.shardingsphere.DatabaseOrderComplexGeneArithmetic # 分库算法 tableOrderComplexGeneArithmetic: type: CLASS_BASED props: sharding-count: 4 strategy: complex algorithmClassName: com.damai.shardingsphere.TableOrderComplexGeneArithmetic然后具体的分库算法就在 com.damai.shardingsphere 包下写。
打开 sql 调试开关:
bashprops: sql-show: true
bash
dataSources:
ds_0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://39.107.120.1:3306/damai_order_0?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai&autoReconnect=true
username: root
password: eleven*lxs
hikari:
max-lifetime: 60000
ds_1:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://39.107.120.1:3306/damai_order_1?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai&autoReconnect=true
username: root
password: eleven*lxs
hikari:
max-lifetime: 60000
rules:
- !SHARDING
tables:
d_order:
actualDataNodes: ds_${0..1}.d_order_${0..3}
databaseStrategy:
complex:
shardingColumns: order_number,user_id
shardingAlgorithmName: databaseOrderComplexGeneArithmetic
tableStrategy:
complex:
shardingColumns: order_number,user_id
shardingAlgorithmName: tableOrderComplexGeneArithmetic
d_order_ticket_user:
actualDataNodes: ds_${0..1}.d_order_ticket_user_${0..3}
databaseStrategy:
complex:
shardingColumns: order_number,user_id
shardingAlgorithmName: databaseOrderTicketUserComplexGeneArithmetic
tableStrategy:
complex:
shardingColumns: order_number,user_id
shardingAlgorithmName: tableOrderTicketUserComplexGeneArithmetic
bindingTables:
- d_order,d_order_ticket_user
shardingAlgorithms:
databaseOrderComplexGeneArithmetic:
type: CLASS_BASED
props:
sharding-count: 2
table-sharding-count: 4
strategy: complex
algorithmClassName: com.damai.shardingsphere.DatabaseOrderComplexGeneArithmetic
tableOrderComplexGeneArithmetic:
type: CLASS_BASED
props:
sharding-count: 4
strategy: complex
algorithmClassName: com.damai.shardingsphere.TableOrderComplexGeneArithmetic
databaseOrderTicketUserComplexGeneArithmetic:
type: CLASS_BASED
props:
sharding-count: 2
table-sharding-count: 4
strategy: complex
algorithmClassName: com.damai.shardingsphere.DatabaseOrderComplexGeneArithmetic
tableOrderTicketUserComplexGeneArithmetic:
type: CLASS_BASED
props:
sharding-count: 4
strategy: complex
algorithmClassName: com.damai.shardingsphere.TableOrderComplexGeneArithmetic
props:
sql-show: true(1)分库算法:
从订单号 / 用户 ID 中取出基因位(二进制后几位),再通过位运算,把数据稳定、均匀地分配到多个数据库中,保证 同一用户 / 同一订单 → 固定落在同一个库。
java
package com.damai.shardingsphere;
import cn.hutool.core.collection.CollectionUtil;
import com.damai.enums.BaseCode;
import com.damai.exception.DaMaiFrameException;
import com.damai.util.StringUtil;
import org.apache.shardingsphere.sharding.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.sharding.api.sharding.complex.ComplexKeysShardingValue;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
import java.util.Map;
import java.util.Objects;
import java.util.Properties;
public class DatabaseOrderComplexGeneArithmetic implements ComplexKeysShardingAlgorithm<Long> {
private static final String SHARDING_COUNT_KEY_NAME = "sharding-count";
private static final String TABLE_SHARDING_COUNT_KEY_NAME = "table-sharding-count";
private int shardingCount;
private int tableShardingCount;
// 初始化规则参数
@Override
public void init(Properties props) {
this.shardingCount = Integer.parseInt(props.getProperty(SHARDING_COUNT_KEY_NAME));
this.tableShardingCount = Integer.parseInt(props.getProperty(TABLE_SHARDING_COUNT_KEY_NAME));
}
@Override
public Collection<String> doSharding(Collection<String> allActualSplitDatabaseNames, ComplexKeysShardingValue<Long> complexKeysShardingValue) {
List<String> actualDatabaseNames = new ArrayList<>(allActualSplitDatabaseNames.size());
Map<String, Collection<Long>> columnNameAndShardingValuesMap = complexKeysShardingValue.getColumnNameAndShardingValuesMap();
if (CollectionUtil.isEmpty(columnNameAndShardingValuesMap)) {
return allActualSplitDatabaseNames;
}
Collection<Long> orderNumberValues = columnNameAndShardingValuesMap.get("order_number");
Collection<Long> userIdValues = columnNameAndShardingValuesMap.get("user_id");
Long value = null;
// 优先选哪个分片键
// 能用订单号就用订单号,否则退化成用户 ID
if (CollectionUtil.isNotEmpty(orderNumberValues)) {
value = orderNumberValues.stream().findFirst().orElseThrow(() -> new DaMaiFrameException(BaseCode.ORDER_NUMBER_NOT_EXIST));
} else if (CollectionUtil.isNotEmpty(userIdValues)) {
value = userIdValues.stream().findFirst().orElseThrow(() -> new DaMaiFrameException(BaseCode.USER_ID_NOT_EXIST));
}
if (Objects.nonNull(value)) {
// 基因法核心
long databaseIndex = calculateDatabaseIndex(shardingCount,value,tableShardingCount);
String databaseIndexStr = String.valueOf(databaseIndex);
for (String actualSplitDatabaseName : allActualSplitDatabaseNames) {
if (actualSplitDatabaseName.contains(databaseIndexStr)) {
actualDatabaseNames.add(actualSplitDatabaseName);
break;
}
}
return actualDatabaseNames;
}else {
return allActualSplitDatabaseNames;
}
}
/**
* 计算给定表索引应分配到的数据库编号。
*
* @param databaseCount 数据库总数
* @param splicingKey 分片键
* @param tableCount 表总数
* @return 分配到的数据库编号
*/
public long calculateDatabaseIndex(Integer databaseCount, Long splicingKey, Integer tableCount) {
// 把分片键转成二进制
String splicingKeyBinary = Long.toBinaryString(splicingKey);
// 计算"要取几位基因"
long replacementLength = log2N(tableCount);
// 取二进制的"后 N 位"
String geneBinaryStr = splicingKeyBinary.substring(splicingKeyBinary.length() - (int) replacementLength);
if (StringUtil.isNotEmpty(geneBinaryStr)) {
int h;
// 基因二次 Hash(防热点)
int geneOptimizeHashCode = (h = geneBinaryStr.hashCode()) ^ (h >>> 16);
// 最终决定:落哪个数据库
return (databaseCount - 1) & geneOptimizeHashCode;
}
throw new DaMaiFrameException(BaseCode.NOT_FOUND_GENE);
}
public long log2N(long count) {
return (long)(Math.log(count)/ Math.log(2));
}
}(2)分表算法:
java
package com.damai.shardingsphere;
import cn.hutool.core.collection.CollectionUtil;
import com.damai.enums.BaseCode;
import com.damai.exception.DaMaiFrameException;
import org.apache.shardingsphere.sharding.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.sharding.api.sharding.complex.ComplexKeysShardingValue;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
import java.util.Map;
import java.util.Objects;
import java.util.Properties;
public class TableOrderComplexGeneArithmetic implements ComplexKeysShardingAlgorithm<Long> {
private static final String SHARDING_COUNT_KEY_NAME = "sharding-count";
private int shardingCount;
@Override
public void init(Properties props) {
shardingCount = Integer.parseInt(props.getProperty(SHARDING_COUNT_KEY_NAME));
}
@Override
public Collection<String> doSharding(Collection<String> allActualSplitTableNames, ComplexKeysShardingValue<Long> complexKeysShardingValue) {
List<String> actualTableNames = new ArrayList<>(allActualSplitTableNames.size());
String logicTableName = complexKeysShardingValue.getLogicTableName();
Map<String, Collection<Long>> columnNameAndShardingValuesMap = complexKeysShardingValue.getColumnNameAndShardingValuesMap();
if (CollectionUtil.isEmpty(columnNameAndShardingValuesMap)) {
return allActualSplitTableNames;
}
Collection<Long> orderNumberValues = columnNameAndShardingValuesMap.get("order_number");
Collection<Long> userIdValues = columnNameAndShardingValuesMap.get("user_id");
Long value = null;
if (CollectionUtil.isNotEmpty(orderNumberValues)) {
value = orderNumberValues.stream().findFirst().orElseThrow(() -> new DaMaiFrameException(BaseCode.ORDER_NUMBER_NOT_EXIST));
} else if (CollectionUtil.isNotEmpty(userIdValues)) {
value = userIdValues.stream().findFirst().orElseThrow(() -> new DaMaiFrameException(BaseCode.USER_ID_NOT_EXIST));
}
if (Objects.nonNull(value)) {
actualTableNames.add(logicTableName + "_" + ((shardingCount - 1) & value));
return actualTableNames;
}
return allActualSplitTableNames;
}
}