本文翻译该网址Transformers Explained Visually (Part 1): Overview of Functionality | Towards Data Science
一份通俗易懂的自然语言处理 Transformer 入门指南 ------ 用大白话讲清 Transformer 为何优于循环神经网络,以及注意力机制如何助力性能提升。
直观易懂的 Transformer 系列:自然语言处理篇
近年来,Transformer 架构的热度居高不下,这绝非空穴来风(with good reason直译是 "有着充分的理由",结合语境意译为 "绝非空穴来风")。过去几年间,它在自然语言处理领域掀起了一场风暴。Transformer 是一种借助注意力机制大幅提升深度学习自然语言处理翻译模型性能的网络架构。该架构最早在论文《Attention Is All You Need》(《注意力就是你所需要的一切》)中被提出,并迅速成为绝大多数文本数据应用场景下的主流架构。
自此以后,包括谷歌的 BERT 和 OpenAI 的 GPT 系列在内的众多项目均以此为基础进行研发,所公布的性能表现轻松超越了当时已有的顶尖基准模型。
在接下来的系列文章中,我将详细讲解(go over结合技术科普的语境,译为 "详细讲解",比直译 "复习、浏览" 更贴合文本) Transformer 的基础知识、架构体系及其内部工作原理。我们会采用自上而下(top-down manner :技术领域固定表述,译为自上而下) 的方式来介绍 Transformer 的功能逻辑。在后续的文章里,我们还会深入剖析(look under the covers :英文隐喻表达,译为 "深入剖析)该模型的内部运行机制,全方位拆解其工作流程。同时,我们也会对 多头注意力机制 进行深度探究 ------ 这一机制正是 Transformer 架构的核心所在。
以下是本系列往期及后续文章的内容速览。我贯穿始终的目标,不仅是弄清楚技术本身如何运作 ,更要探究其为何要如此设计。
- 功能总览 ------ 本文内容(Transformer 的应用方式、相较循环神经网络的优势所在、架构组成组件、以及训练与推理阶段的运行机制)
- 工作原理解析 (端到端(end-to-end :译为端到端 )的内部运行流程、数据流转路径与执行的运算操作,包括矩阵表示形式)https://towardsdatascience.com/transformers-explained-visually-part-2-how-it-works-step-by-step-b49fa4a64f34
- 多头注意力机制 (注意力模块在 Transformer 架构中的核心工作原理)https://towardsdatascience.com/transformers-explained-visually-part-3-multi-head-attention-deep-dive-1c1ff1024853
- 注意力机制提升性能的原理解析 (不仅阐述注意力机制的功能作用,更深入探究其高效运作的原因,以及该机制如何捕捉句子中词汇间的关联关系)https://towardsdatascience.com/transformers-explained-visually-not-just-how-but-why-they-work-so-well-d840bd61a9d3
另外,如果你对自然语言处理的各类应用感兴趣,我还有一些其他文章或许会合你心意。
1.束搜索算法 (语音转文字与自然语言处理应用中广泛使用的一种算法,用于提升预测效果)https://towardsdatascience.com/foundations-of-nlp-explained-visually-beam-search-how-it-works-1586b9849a242.BLEU 评分(BLEU 评分与词错误率是衡量自然语言处理模型性能的两项核心指标)
https://towardsdatascience.com/foundations-of-nlp-explained-bleu-score-and-wer-metrics-1a5ba06d812b
什么是 Transformer
Transformer 架构擅长处理本身具有序列特性的文本数据。它以文本序列作为输入,输出另一段文本序列。例如,将输入的英语句子翻译成西班牙语。
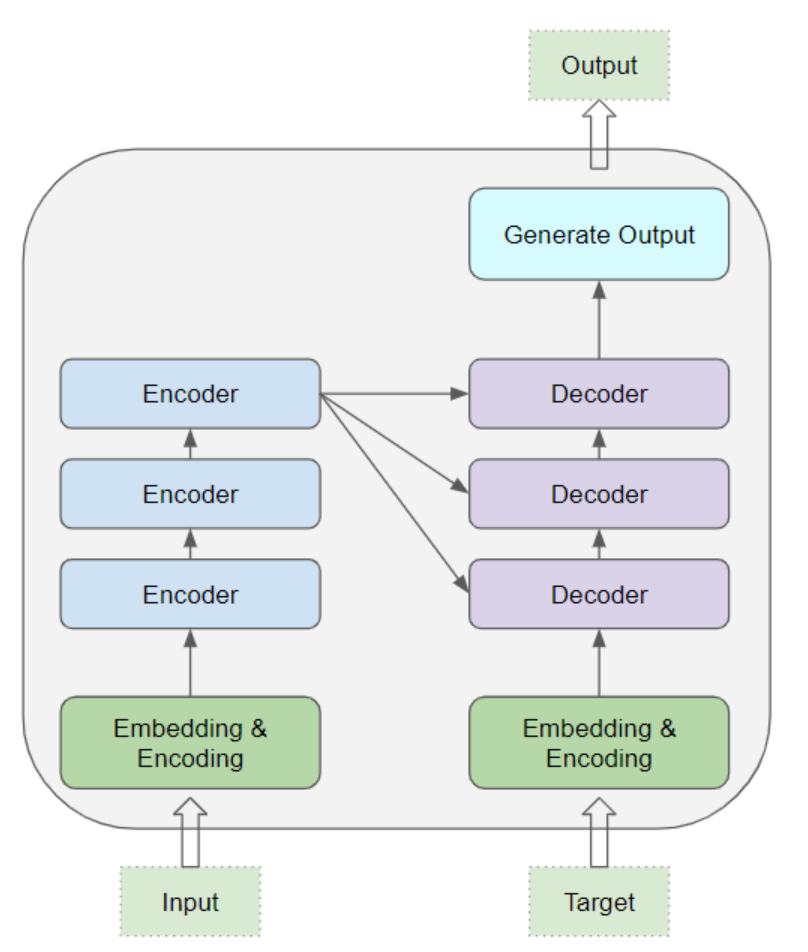
其核心部分由编码器层 与解码器层 堆叠而成。为避免混淆,我们将单独的层级称为编码器 或解码器 ,而由多个编码器层构成的组合则称为编码器堆叠 ,同理多个解码器层的组合称为解码器堆叠。
编码器堆叠 与解码器堆叠 分别拥有各自对应的(corresponding)嵌入层 ,以处理其输入数据(for their respective inputs 译为 "以处理其输入数据",respective各自的)。最后,模型会设置一个输出层,用于生成最终的输出结果。
所有编码器 的结构均完全相同(identical to one another :译为 "结构均完全相同)。同理,所有解码器的结构也完全相同。
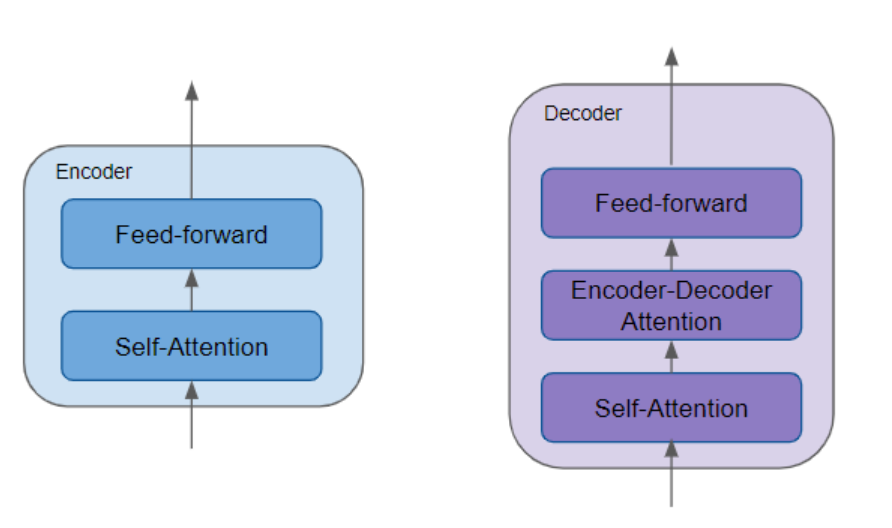
编码器包含至关重要的自注意力层 与前馈层,前者负责计算序列中不同词汇之间的关联关系。
解码器则包含自注意力层、前馈层,以及第二个关键组件 ------编码器 - 解码器注意力层。
每个编码器与解码器都拥有各自独立的参数权重集合(has its own set of weights译为 "拥有各自独立的参数权重集合")。
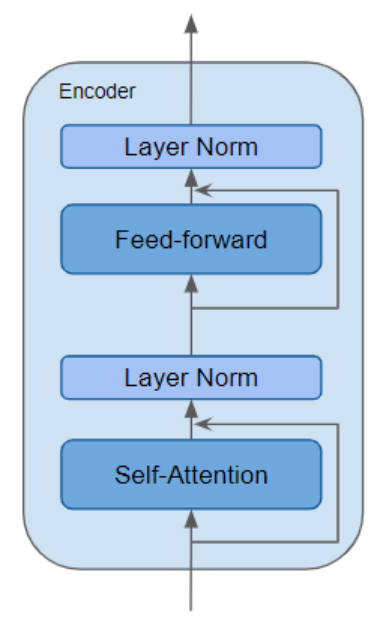
编码器 是一种可复用的模块,同时也是所有 Transformer 架构的标志性核心组件(defining component 译为 "标志性核心组件",比直译 "定义性组件" 更符合中文技术语境)。除了上述两层结构外,编码器还在这两层的外围配置了残差跳跃连接 ,并搭配了两个层归一化层。
Transformer 架构存在诸多变体。部分 Transformer 架构完全不设解码器,仅依靠编码器来实现功能。
注意力机制的作用是什么?
Transformer 之所以能实现突破性的性能表现(ground-breaking performance :译为 "突破性的性能表现"),核心就在于它对注意力机制的运用。
在处理某个词汇时,注意力机制能够让模型聚焦于输入序列中与该词汇密切相关的其他词汇。
例如,"球" 这个词与 "蓝色的" 和 "拿着" 紧密相关;而另一方面,"蓝色的" 与 "男孩" 则并无关联。

Transformer 架构通过自注意力机制 ,建立输入序列中每个词 与其他所有词 之间的关联(by relating every word...to every other word译为 "建立...... 每个词与其他所有词之间的关联")。
例如,请看以下两个句子:
- 那只猫喝了牛奶,因为它饿了。
- 那只猫喝了牛奶,因为它很甜。
在第一个句子中,代词 "它" 指代的是 "猫";而在第二个句子中,"它" 指代的是 "牛奶"。当模型处理 "它" 这个词时,自注意力机制会为模型提供更多与该词含义相关的信息,从而让模型能够将 "它" 与正确的指代对象关联起来。
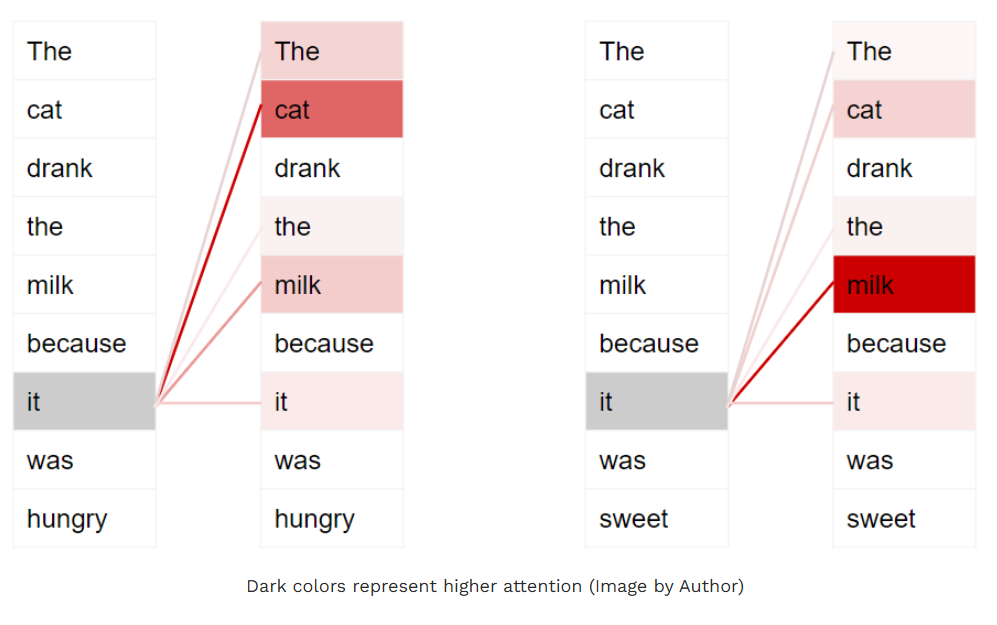
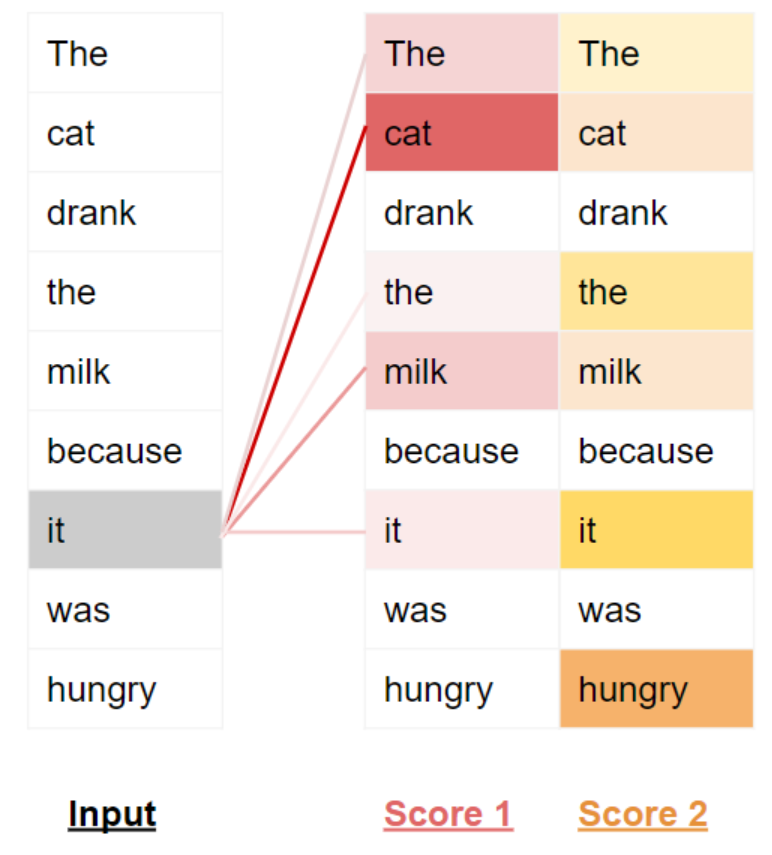
为使模型能够捕捉句子中关于意图 与语义 的更多细微差别(nuances about the intent and semantics 译为 "意图与语义的更多细微差别","细微差别" 精准对应 nuances 的含义),Transformer 会为每个词生成多个注意力分数。
例如,在处理 "它" 这个词时,第一个注意力分数会突出 "猫" 的关联性,第二个注意力分数则会突出 "饿" 的关联性。因此,当模型对 "它" 这个词进行解码时 ------ 比如将其翻译成另一种语言 ------ 就会把 "猫" 和 "饿" 这两个概念的相关特征融入到翻译后的词汇中。
Transformer 的训练过程
Transformer 在训练阶段 与推理阶段 的运行机制略有不同(during Training and while doing Inference,Training / Inference 深度学习领域固定术语,分别译为训练阶段 /推理阶段)。
我们首先来看训练阶段的数据流转过程。训练数据包含两个部分:
- 源序列(即输入序列)(source or input sequence / destination or target sequence 译为源序列(即输入序列) / 目标序列(即输出序列))(例如,在翻译任务中,输入的英语句子 "不客气")
- 目标序列(即输出序列)(例如,对应的西班牙语译文 "De nada")
Transformer 的目标是通过学习输入序列与目标序列的关联,掌握输出目标序列的方法。
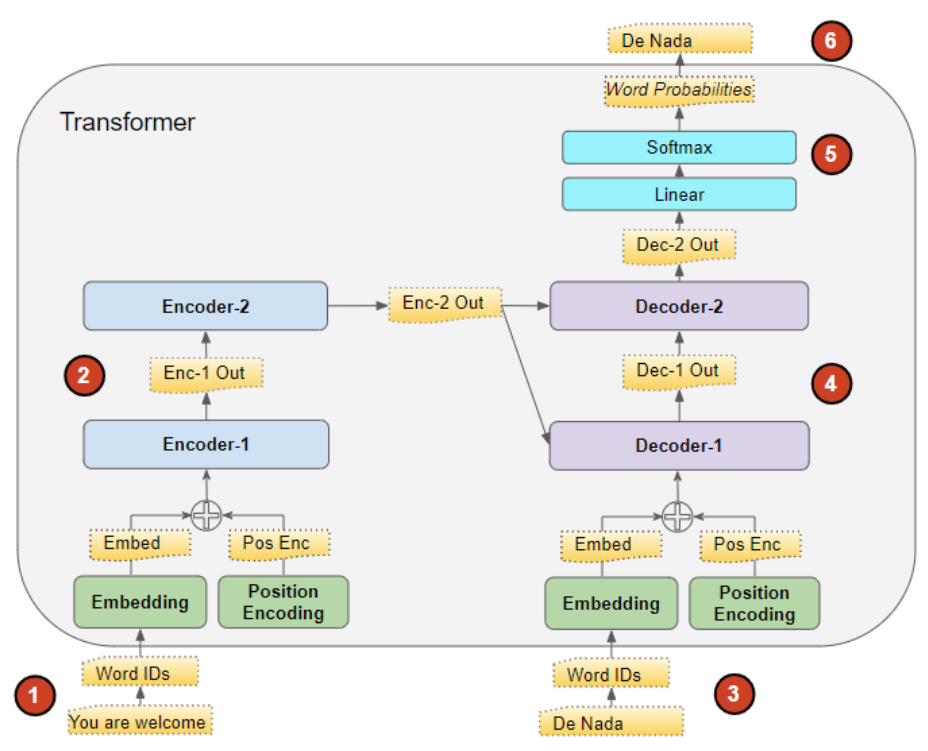
Transformer 处理数据的流程如下:
- 输入序列被转换为嵌入向量 (附带位置编码),并输入至编码器。
- 编码器堆叠对其进行处理,生成输入序列的编码表征。
- 目标序列前会添加一个句首标记(prepended with a start-of-sentence token),随后被转换为嵌入向量(附带位置编码),并输入至解码器。
- 解码器堆叠结合编码器堆叠输出的编码表征进行处理,生成目标序列的编码表征。
- 输出层将该编码表征转换为词汇概率分布( word probabilities 译为词汇概率分布 ,而非 "词汇概率",强调输出层会为目标词汇表中的每个词输出一个概率值,模型会选取概率最高的词作为生成结果。),最终生成输出序列。
- Transformer 的损失函数 会将该输出序列与训练数据中的目标序列进行比对,计算得到的损失值会在反向传播 过程中用于生成梯度,从而完成对 Transformer 的训练(Loss function / back-propagation 均为深度学习核心术语,分别译为损失函数 和反向传播)。
推理阶段(Inference 延续前文译法,固定译为推理阶段)
在推理阶段,我们仅能获取输入序列,而没有可输入至解码器的目标序列。此时,Transformer 的目标就是仅依靠输入序列生成对应的目标序列。
因此,与序列到序列(Seq2Seq)模型的原理类似,我们会以循环迭代(in a loop 结合模型生成逻辑,译为循环迭代) 的方式生成输出序列,并将上一时间步的输出序列作为输入,传入下一时间步的解码器;这一过程会持续进行,直至模型生成句尾标记为止。
与序列到序列(Seq2Seq)模型的区别在于,在每一个时间步,我们会将截至当前生成的完整输出序列 重新输入解码器(thus far译为 "截至当前"),而非仅输入上一个生成的词汇。
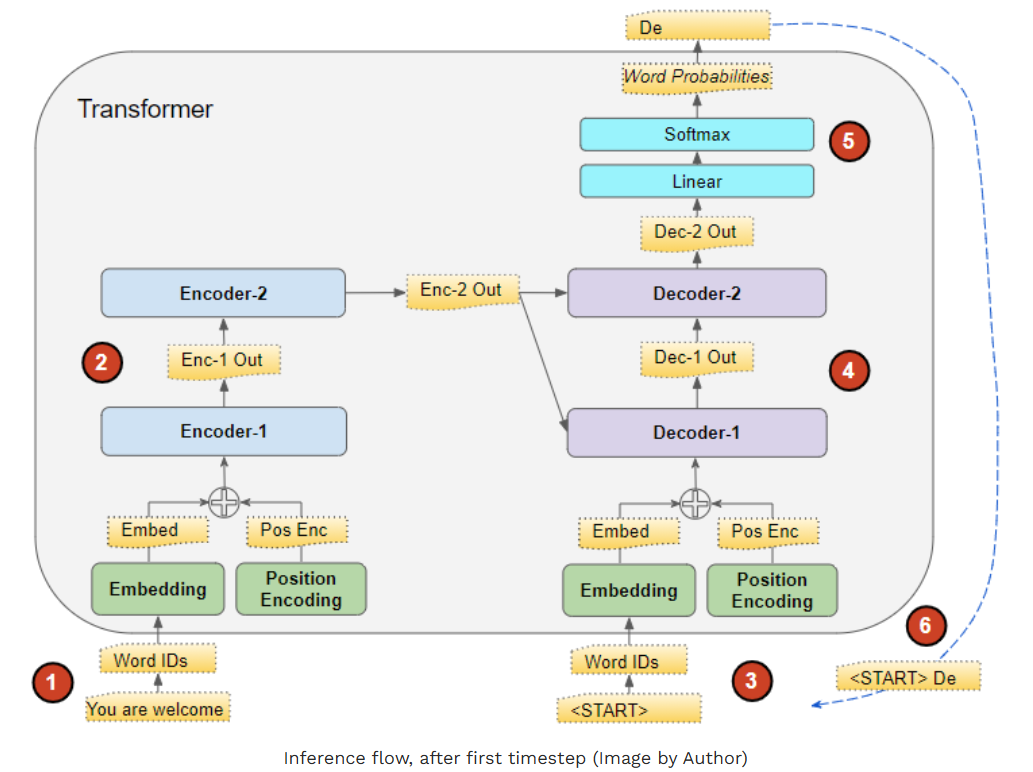
推理阶段的数据流转流程如下:
- 输入序列被转换为嵌入向量 (附带位置编码),并输入至编码器。
- 编码器堆叠对其进行处理,生成输入序列的编码表征(process为处理,produce为生成)。
- 我们不再输入目标序列,而是使用一个仅包含句首标记的空序列;该序列同样被转换为嵌入向量(附带位置编码),并输入至解码器。
- 解码器堆叠结合编码器堆叠输出的编码表征进行处理,生成目标序列的编码表征。
- 输出层将该编码表征转换为词汇概率分布,并生成输出序列。
- 我们选取输出序列的最后一个词作为预测词,将其填充至解码器输入序列的第二个位置 ------ 此时的输入序列已包含句首标记与首个预测词。
- 回到步骤 3,像之前一样将新的解码器输入序列输入模型;随后选取输出序列的第二个词,将其追加至解码器输入序列尾部。重复这一过程,直至模型预测出句尾标记 。注:由于编码器序列在每次迭代中均保持不变,因此无需重复执行步骤 1 与步骤 2(感谢米哈尔・库奇尔卡指出这一点)。
教师强制策略
训练阶段将目标序列直接输入解码器的这种方法(the approach of feeding... 译为 "将目标序列直接输入解码器的这种方法"),被称为教师强制策略。我们为何要采用这种方法?这个术语又具体指代什么含义?
在训练阶段,我们其实可以沿用推理阶段所采用的方法。具体来说,就是让 Transformer 以循环方式运行:从输出序列中提取最后一个词,将其追加至解码器的输入序列尾部,再把这个新的输入序列送入解码器,进行下一轮迭代。最终,当模型预测出句尾标记时,损失函数会将生成的输出序列与真实目标序列进行比对,以此完成对网络的训练。
这种循环方式不仅会大幅延长训练耗时 ,还会增加模型的训练难度 。因为模型需要基于可能存在误差的首个预测词 来推断第二个词,后续的预测过程也会以此类推(and so on译为 "后续的预测过程也会以此类推")。
此外,Transformer 能够并行输出所有词汇,无需进行循环迭代,这一特性大幅提升了训练效率。
Transformer 有哪些应用场景?
Transformer 的功能十分灵活多样,可应用于绝大多数自然语言处理(NLP)任务,例如语言建模与文本分类。在序列到序列(Seq2Seq)模型中,该架构的应用尤为广泛,常见落地场景包括机器翻译、文本摘要、问答系统、命名实体识别以及语音识别。
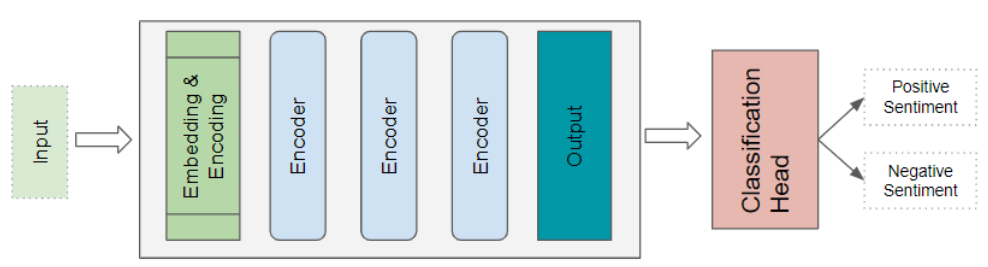
针对不同的任务需求,Transformer 架构衍生出了多种变体(flavors 此处为技术语境中的比喻用法,译为变体) 。基础的编码器层 被用作这些架构的通用构建模块,再根据具体要解决的任务,搭配不同的任务专用头模块。
Transformer 分类架构
以情感分析任务为例(Sentiment Analysis:固定译为情感分析 ),该架构会接收一份文本文档作为输入。分类头模块( Classification head:译为**分类头模块)**会获取 Transformer 的输出特征,并生成类别标签的预测结果,例如判断文本情感为积极或消极。
它们相比循环神经网络有哪些优势?
在 Transformer 架构出现并将其取代之前(dethroned them:译为将其取代 ),循环神经网络(RNN)及其变体 (cousins:此处为比喻用法,译为变体 )------ 长短期记忆网络(LSTM)和门控循环单元(GRU),一直是所有自然语言处理(NLP)任务的事实标准架构。
基于循环神经网络(RNN)的序列到序列模型表现不俗,而注意力机制最初被提出时,正是被用于提升这类模型的性能表现。
然而,这类模型存在两个局限性:
- 难以处理长句中距离较远的词汇 之间的长程依赖关系。
- 它们会逐词串行处理 输入序列(
sequentially one word at a time:译为逐词串行处理 ),这意味着只有完成时间步 t −1 的计算,才能开展时间步 t 的计算。这种处理方式会降低训练与推理的效率。
补充一点(as an aside:译为 "补充一点"),对于卷积神经网络(CNNs)而言,其所有输出均可并行计算,这使得卷积运算的效率大幅提升。但这类模型在处理长程依赖关系时同样存在局限:
在卷积层中(In a convolutional layer),仅当图像中的局部区域(或应用于文本数据时的词汇片段)能完整纳入卷积核尺寸范围 内(kernel size:译为卷积核尺寸 ,是 CNN 的核心术语),这些区域内的元素之间才能产生关联交互。若要处理距离较远的元素,则需要构建一个包含大量网络层的深度模型。
Transformer 架构同时解决了这两个局限性(address both of these limitations 译为 "同时解决了这两个局限性","address" 在技术语境中译为 "解决" 而非 "应对"。) 。它彻底摒弃了循环神经网络(RNN)的设计思路(got rid of... altogether 译为 "彻底摒弃了...... 的设计思路") ,转而完全依托注意力机制的优势来构建模型(relied exclusively on 译为 "完全依托")。
该架构能够并行处理序列中的所有词汇 ,从而大幅提升了运算效率。
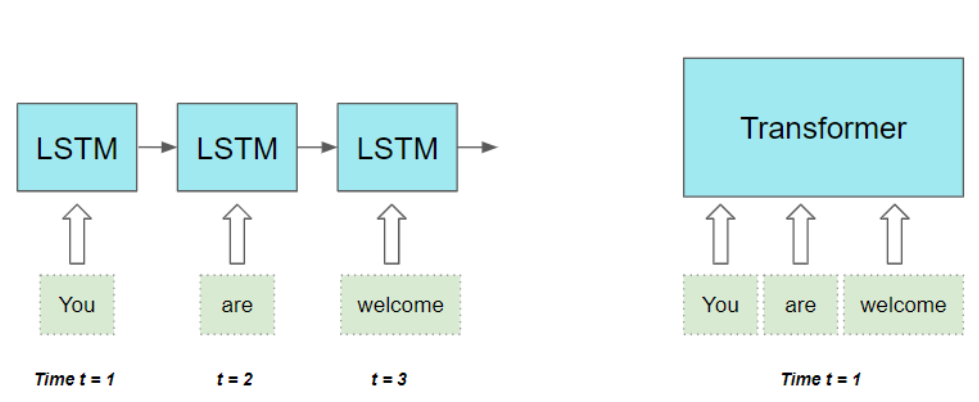
输入序列中词汇之间的距离长短无关紧要( does not matter 译为无关紧要) 。该架构在计算相邻词汇的依赖关系,以及距离较远词汇的依赖关系时,表现同样出色( equally good at 译为同样出色, adjacent邻近的**)**。
既然我们已经对 Transformer 有了一个宏观层面的认识(high-level idea 译为宏观层面的认识),下一篇文章中,我们就可以深入探究它的内部运行机制,从而理解其工作原理的细节。