一、前置-Python-Pytest框架项目结构
1.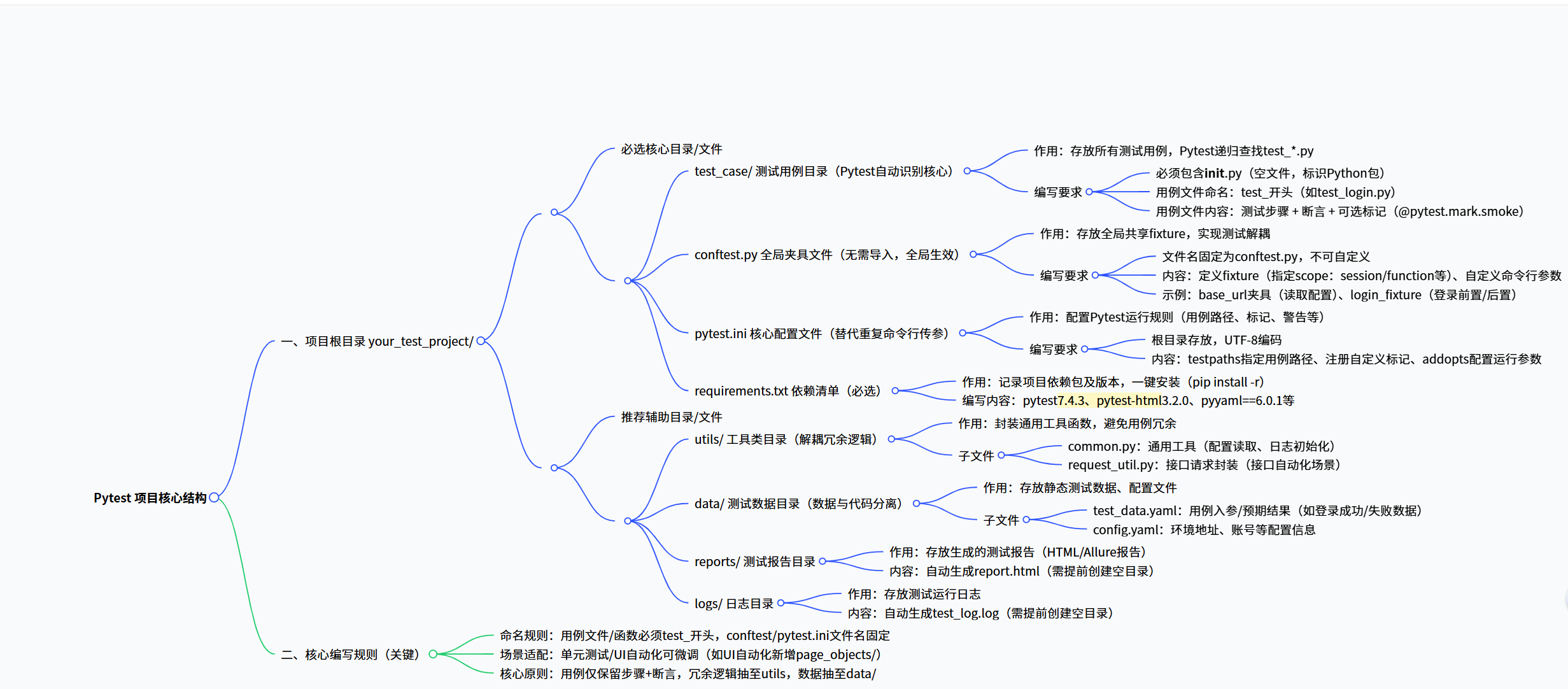
2.项目根目录下
(1)test_case 测试用例目录 需标识卫Python包(有__init__.py文件)
测试用例目录下,是测试用例文件,需以test_开头
(2)conftest.py Pytest全局夹具(fixture)文件
a.conftest.py 是 pytest 框架的专属配置文件,它不是 Python 标准库或第三方库的文件,而是 pytest 约定俗成的文件名。这个文件本质上是一个普通的 Python 模块,但 pytest 会自动识别并加载它,不需要手动导入。
b.conftest.py是 pytest 的"全局工具库",专门用来存放测试用例中共享的配置、夹具(fixture)、插件钩子等内容。
c.如果测试项目非常简单(比如只有几个独立的测试函数,没有共享的前置/后置操作、全局配置),可以不用创建 conftest.py
多个测试文件(如 test_1.py 、 test_2.py )需要共享同一个 fixture(比如共享的测试数据、初始化的数据库连接);
需要自定义 pytest 的运行规则(比如自定义命令行参数、修改测试用例的收集逻辑);
需要统一管理测试的前置/后置操作(比如所有测试用例执行前启动服务,执行后清理数据)。
e. conftest.py 的核心作用:
共享 Fixture(最核心作用)
python
import pytest
# 定义一个全局共享的 fixture,所有测试用例都能调用
@pytest.fixture(scope="session") # scope="session" 表示整个测试会话只执行一次
def init_database():
# 前置操作:连接数据库
print("\n初始化数据库连接...")
db_conn = "模拟的数据库连接对象"
# 将连接对象传递给测试用例
yield db_conn
# 后置操作:关闭数据库连接
print("\n关闭数据库连接...")
# 定义另一个共享 fixture(函数级,每个测试函数执行一次)
@pytest.fixture
def test_data():
return {"username": "test_user", "password": "123456"}测试文件示例:
python
def test_login(init_database, test_data):
# 直接使用 conftest.py 中的 fixture,无需导入
print(f"使用数据库连接:{init_database}")
print(f"使用测试数据:{test_data}")
assert test_data["username"] == "test_user"自定义pytest钩子函数
插件注册与管理
作用域控制
(3)pytest.ini Pytest核心配置文件,例如
python
[pytest]
testpaths = testcases
addopts = -vs --alluredir=./temps
python_files = test_*.py
python_classes = Test*
python_functions = test_*(4)utils 工具类目录
(5)reports 生成的测试报告存放目录
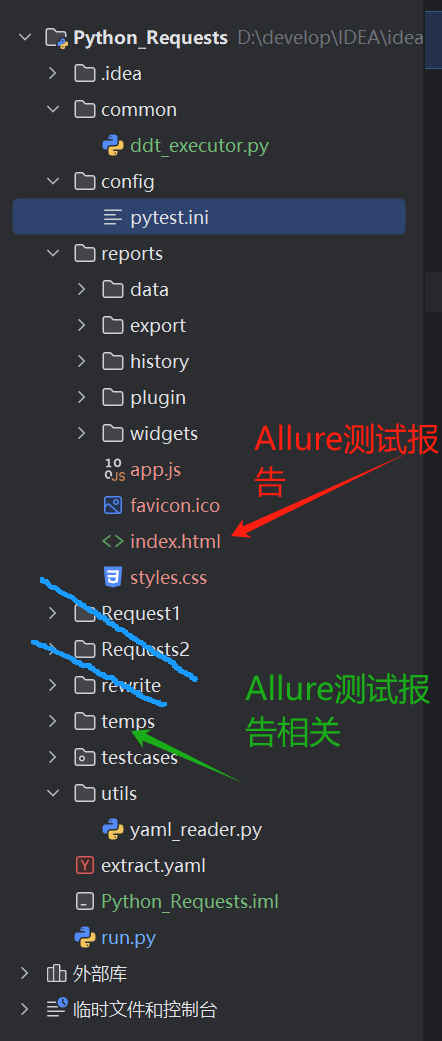
3.示例:
二、
1.HTTP协议:
(1)HTTP协议使用URL(Uniform Resource Locator)来标识互联网上的资源,如网页、图片、视频等。客户端通过发送HTTP请求来获取特定URL对应的资源,请求包括请求方法(如GET、POST)、头部信息(如浏览器类型、请求资源类型等)和可选的请求体(如表单数据、请求参数等)。
(2)作用:
传输数据:HTTP协议是一种用于传输数据的协议(客户端与服务器之间)
客户端与服务器通信:规定之间的通信规则
资源定位和标识:HTTP协议使用URL来定位和标识互联网上的资源。URL由协议类型、服务器地址、资源路径等组成,通过URL可以唯一确定一个资源的位置
无状态协议:
安全性:HTTP明文传输。使用HTTPS,在HTTP上添加了SSL/TLS加密层
2.GET请求:请求参数会暴露在URL中
(1)请求参数通过URL中的查询字符串传递,http://www.baidu.com/path?param1=value1\¶m2=value2
(2)GET请求是幂等的,即多次重复发送同样的GET请求,不会对服务器产生副作用,也不会修改服务器上的资源状态
这和非幂等的请求(如POST)形成对比,POST请求重复发送可能会导致重复创建资源(比如重复提交订单生成多个订单),而GET不会出现这种情况。
(3)优点:
简单直观、可缓存、可书签化(由于GET请求的参数附加在URL中,因此可以将带有GET请求的URL添加到书签中,方便用户保存和分享特定的资源)、可见性
(4)缺点:长度限制、安全性问题、副作用问题
3.POST请求
(1)POST请求不仅可以传输表单数据,也可以传输其他类型的数据,如JSON、XML等。使用POST请求时,需要根据具体的场景和需求,将数据格式化和编码成对应的请求体数据类型
(2)不可缓存、非幂等
- get 和 post 的区别
(1)GET请求适用于获取资源、查询或浏览数据等操作,传输的数据量较小且不涉及敏感信息。
(2)POST请求适用于向服务器提交数据、修改资源状态等操作,支持传输较大量的数据和敏感信息的安全传输。
5.application
(1)在 application/json 这个MIME类型中,application是MIME类型的顶级类型,代表这份数据是应用程序级别的数据,而非文本、图片、音频等基础媒体类型。
具体来说:
(1)MIME类型的结构:MIME类型由「顶级类型/子类型」组成, application 作为顶级类型,标识数据是为应用程序处理设计的、结构化的二进制或文本数据(区别于 text (纯文本)、 image (图片)、 audio (音频)等)。
(2)application的含义:表示该数据不是直接供人阅读的原始文本/媒体,而是需要应用程序(如服务器后端)按照特定规则解析的结构化数据,比如JSON、XML、表单数据等都归属于 application 顶级类型下。
(3)比如:
application/x-www-form-urlencoded :表单数据格式的应用程序数据;
application/xml :XML格式的应用程序数据;
application/json :JSON格式的应用程序数据。
6.重定向:
(1)重定向是服务器告诉客户端(如浏览器、requests库),请求的资源不在当前URL,需要去新的URL获取的过程,HTTP中常用 3xx 状态码表示(如301永久重定向、302临时重定向)。
(2)微博域名重定向:
访问https://t.cn/A63X7h0G时,百度服务器会返回307/302重定向,
将请求导向https://www.weibo.com,这就是一次重定向。
(3) 网页迁移重定向
比如某网站旧地址 https://old.example.com/page ,站长把页面移到 https://new.example.com/page ,访问旧地址时服务器返回301重定向,客户端会自动跳转到新地址。
(4)短链接跳转
像微博短链接 https://t.cn/xxxx ,点击后会重定向到实际的长链接(如新闻、视频页面),这也是典型的重定向应用。
7.User-Agent(用户代理):是HTTP请求头中的一个字段,
(1)用来向服务器标识发起请求的客户端软件类型、版本、操作系统等信息。
(2)Mozilla/5.0:浏览器身份标识的通用前缀,用来让服务器识别请求的客户端类型
三、会话管理和Cookie
1.会话管理
(1)发送多个相关请求时,使用会话(Session)对象来管理这些请求,以便在多个请求之间共享状态、Cookie和身份验证等信息。
(2)使用会话的优点:
自动管理cookie
共享会话级别信息
连接重用
python
# 发送多个相关请求时,使用会话(Session)对象来管理这些请求,
# 以便在多个请求之间共享状态、Cookie和身份验证等信息。
import requests
# 1.创建会话对象
session = requests.Session()
# 2.设置会话级别的头部信息
session.headers.update({
'User-Agent':'Mozilla/5.0' # User-Agent:用户代理;Mozilla/5.0:浏览器身份标识通用前缀
})
# 3.第一个请求 --post请求登录
login_data={
'username':'admin',
'password':123456,
'verify_code':2
}
# https://httpbin.org :专门用于HTTP请求测试的公共接口,
# https://httpbin.org/post :httpbin的专用POST接口
response1=session.post('https://httpbin.org/post',data=login_data)
# 打印登录响应信息,查看是否成功
print("登录请求状态码:", response1.status_code) # 200表示请求成功,401/403可能是账号密码错误
print("登录响应内容:", response1.text) # 查看服务器返回的登录结果
# 4.第二个请求(登录以后的其他操作1)
response2 = session.get('https://httpbin.org/xxx1')
print(response2.text)
print(response2.status_code)
# 5.第三个请求(登录以后的其他操作2)
response3 = session.get('https://httpbin.org/xxx2')
print(response3.text)
print(response3.status_code)
# 5.关闭会话
session.close()2.会话(Session):
(1) 会话是指客户端(如浏览器、Python的requests)与服务器之间一次连续的交互过程,从客户端发起第一个请求开始,到断开连接结束。
(2)作用:服务器通过会话记录用户的临时状态(比如是否登录、购物车内容),让多个请求之间能共享信息。
(3)在 requests 中, Session() 对象就是用来模拟这种连续交互的,它会自动保存请求过程中产生的Cookie、请求头,让后续请求能复用这些信息。
3.Cookie:
(1)Cookie是服务器发送给客户端的小型文本数据,客户端会保存在本地,后续请求同一服务器时会自动携带这些Cookie
(2) 作用:服务器通过Cookie识别用户身份(比如记录登录状态的 sessionid )、保存用户偏好设置等。
(3)登录网站后,服务器返回一个包含登录凭证的Cookie,后续访问该网站的其他页面,浏览器会自动带上这个Cookie,服务器就能识别出是"已登录的用户"
4.会话与Cookie的关系:
(1)Cookie是实现会话状态保持的核心手段:服务器通过向客户端下发Cookie,来标记不同的会话;客户端携带Cookie请求,服务器就能关联到对应的会话。
(2)requests.Session() 会自动管理Cookie:使用同一个Session对象发送多次请求时,Session会把服务器返回的Cookie保存下来,后续请求自动带上,模拟浏览器的会话行为。
(3) 会话(Session对象)接收并保存Cookie
服务器在响应中下发Cookie后,同一个 requests.Session() 对象会将Cookie保存在本地(Cookie是服务器生成的,会话只是存储载体)。
同一会话(比如同一窗口)携带Cookie,新会话不会
python
import requests
# 1. 访问百度首页(百度服务器会下发Cookie)
url = 'https://www.baidu.com'
response = requests.get(url)
# 2. 打印服务器下发的Cookie(通过response.cookies获取)
print("=== 服务器下发的Cookie ===")
for cookie in response.cookies:
print(f"Cookie名称:{cookie.name},Cookie值:{cookie.value}")
# 3. 把获取到的Cookie带入下一次请求
cookies = requests.utils.dict_from_cookiejar(response.cookies) # 把CookieJar转为字典
print("\n=== 携带Cookie发起新请求 ===")
response2 = requests.get(url, cookies=cookies)
# 打印新请求的响应状态和Cookie相关信息
print(f"请求状态码:{response2.status_code}")
print("新请求携带的Cookie:", cookies)
# 4.删除cookie
# 4.1删除名为BDORZ的Cookie
response.cookies.pop('BDORZ')
# 4.2 删除所有cookie
response.cookies.clear()
# 删除后重新转为字典
# 方法一 cookies=requests.utils.dict_from_cookiejar(response.cookies)
print("-----------")
# 方法二
print(response.cookies)(1) session.cookies和response.cookies不是同一个Cookie对象
(2)用 session.get(url) 后, response.cookies 会拿到服务器新给的Cookie, session 会自动把这些Cookie加到 session.cookies 里,下次用同一个 session 请求时,就会带着这些Cookie一起发出去。
(3)示例:
cookies = {'name': 'value'}
session.cookies.update(cookies)
url = 'http://www.baidu.com'
response = session.get(url)
打印服务器下发的Cookie
print("\n=== 服务器下发的Cookie ===")
print(response.cookies)
python
import requests
# session.cookies和response.cookies不是同一个Cookie对象
# 创建一个会话
session = requests.Session()
# 添加Cookie到会话
cookies = {'name': 'value'}
session.cookies.update(cookies)
# 打印Session中存储的Cookie(验证添加是否成功)
print("=== Session中存储的Cookie ===")
for cookie in session.cookies:
print(cookie.name, cookie.value)
# 使用包含Cookie的会话发送请求
url = 'http://www.baidu.com'
response = session.get(url)
# 打印服务器下发的Cookie
print("\n=== 服务器下发的Cookie ===")
print(response.cookies)
# 清空所有Cookie
session.cookies.clear()
print("\n=== 清空后Session中的Cookie ===")
print(session.cookies)四、常见请求
1.Get:获取资源,幂等
2.Post:创建资源,向服务器提交资源,非幂等
3.Put:更新资源,幂等(多次提交结果一致)
4.Delete:删除资源
五、文件上传
1.单个文件上传
(1)requests.post(
url # 必选,指定url地址
files # 可选,指定文件名
)
(2)读取文件 rb:表示打开文件的模式参数,代表以二进制只读文件
r:只读文件;使用requests发送文件时,服务器需要接收二进制格式的文件数据,而非文本格式
with open(file_path,'rb')as file:
python
"""
文件上传
requests.post(
url # 必选,指定url地址
files # 可选,指定文件名
)
"""
import requests
# 1.发送单个文件
url="https://httpbin.org/post"
file_path=r"D:\test_file\python_open.txt"
# 读取文件 rb:表示打开文件的模式参数,代表以二进制只读文件
# r:只读文件;使用requests发送文件时,服务器需要接收二进制格式的文件数据,而非文本格式
with open(file_path,'rb')as file:
# 将读取的二进制信息赋值为字典
files={'file':file}
# 通过字典发送post请求
response=requests.post(url,files=files)
# 获取响应信息
print(response.text)六、代理设置 Proxy:
1.代理作用:
(1)网络中转
(2)访问受限资源
(3)隐藏真实ip
(4)实现访问控制
七、Python+Pytest+Requests 接口自动化测试-单接口测试
1.单接口测试用法
2.测试需要接口关联的接口通过extract关键字实现。
(1)上一个接口提取变量使用extract关键字
两种实现方式 正则表达式、jsonpath
extract:
token: ur(.*?)tp://101.34 正则表达式提取
order id2:$.data.data0.id jsonpath提取
下一个接口使用变量(token即extract提取的变量名说)
${read yaml(token)
python
feature: 用户管理模块
story: 获取access_token鉴权码接口
title: $ddt{title} # 通过ddt数据驱动的方式
request:
method: get
url: https://api.weixin.qq.com/cgi-bin/token
params:
grant_type: $ddt{grant_type}
appid: $ddt{appid}
secret: $ddt{secret}
# 测试需要接口关联的接口 通过 extract关键字实现
# 两种方式 (1)正则表达式提取
# extract:
# token:ur(.*?)tp://101.34
# (2)jsonpath提取
# order_id2:$.data.data[0].id
extract:
access_token: $.access_token # 获取根节点下的access_token
# 实现数据驱动
parametrize:
-["title","grant_type","appid","secret"]
-["测试grant_type参数必填","client_credential","wx8a9de038e93f77ab","8326fc915928dee3165720c910effb86"]
-["测试获取access_token鉴权码接口","wx8a9de038e93f77ab","8326fc915928dee3165720c910effb86"]
validate: null八、jsonpath:
(1)从复杂 JSON 数据中精准提取指定内容的工具,比 Python 自带的字典取值更灵活(支持层级、通配、筛选等)
(2)字典取值:只能逐层取(如data"a""b"0"c"),层级深或结构不固定时很麻烦;
(3)JSONPath:用表达式一次性定位(如$..c),不管层级多深,直接提取所有c字段的值。
2.语法:
(1) 根节点 (整个 JSON 数据) → 取全部数据
(2). 子节点(层级分隔) $.data → 取根下的 data
(3).. 递归下降(所有层级) $..name → 取所有层级的 name
(4)\[\] 数组索引 / 筛选 $.list0 → 取 list 第一个元素
(5)* 通配符(匹配所有) $.list\* → 取 list 所有元素
(6)?() 过滤条件 $..?(@.age\>18) → 取 age>18 的元素
(1)jsonpath核心价值:灵活提取 JSON 中任意层级 / 条件的内容,适配接口返回的复杂数据;
(2)常用场景:接口自动化测试中提取返回值(如 token、用户 ID)、断言关键字段;
(3)核心用法:parse(表达式).find(数据) → 遍历结果取match.value。