
文章目录
-
- 一、Git的核心:三种对象及其引用
- 二、三种对象如何协作?
-
- [场景 1:首次提交](#场景 1:首次提交)
- [场景 2:新增文件并提交](#场景 2:新增文件并提交)
- [场景 3:删除文件再提交](#场景 3:删除文件再提交)
- 三、那怎么真正"删掉"大文件?
- 四、分支(Branch)到底是什么?
- 五、空间优化的秘密与潜在问题
- 六、结语
举个例子,有一次我不小心将一个依赖文件夹提交了进去,导致仓库大小暴增到几百MB。我赶紧删除模型并重新提交,但仓库大小并未缩小。这让我意识到,我其实并不真正理解Git是如何工作的。
如果你也有过类似的困惑,那么这篇文章将用 5 分钟 ,带你穿透 git commit的表层操作,直击 Git 的核心机制------三种对象与引用系统 。看完之后,你会真正理解:为什么删掉文件后仓库体积没变?分支到底是什么?Git 为何如此高效又可靠?
写给在日常开发中,只记住了Git的常用命令,却对底层机制一知半解,像我一样的开发者。
一、Git的核心:三种对象及其引用
Git的核心在于三种不可变对象:commit 、tree 和 blob 。这些对象存储在 .git/objects 目录中,通过哈希值也就是唯一标识相互引用,形成一个高效的版本控制系统。
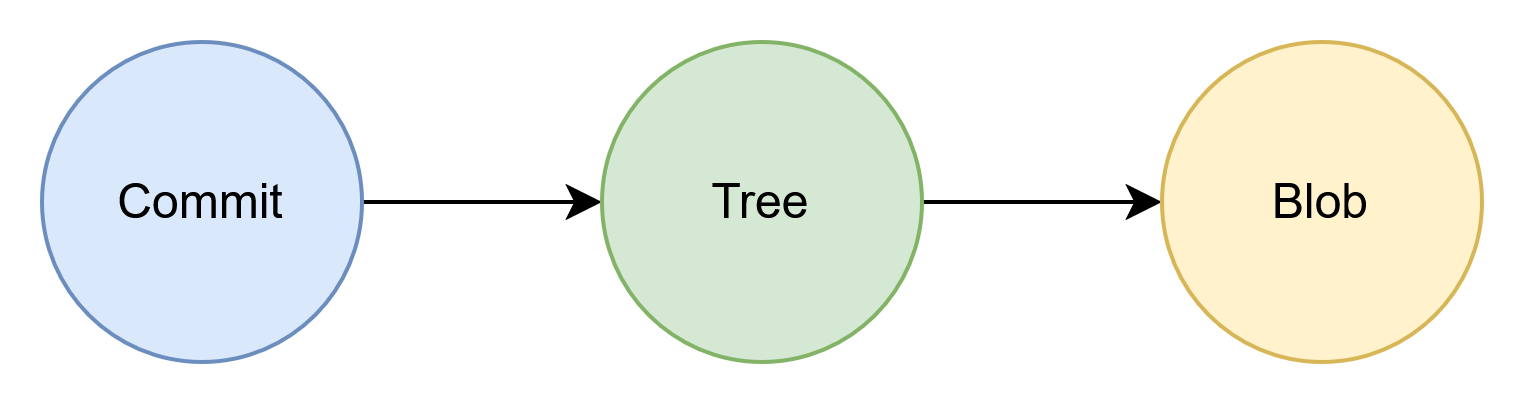
- Commit 对象:每次提交代码时创建,记录了变更的快照。它包含提交消息、作者、提交者、父提交(parent),并指向一个 tree 对象。
- Tree 对象:代表提交时的目录结构,包括文件和子目录。它指向 blob 对象或其他 tree 对象。
- Blob 对象:存储文件的实际内容,是最底层的对象。一旦创建,blob 永不修改或删除。
这种引用机制避免了重复存储:不变的文件只需引用相同的 blob,新变更才创建新 blob,从而节省空间。
二、三种对象如何协作?
场景 1:首次提交
假设你新建一个项目,创建一个文件 text1.txt,内容为:
Hello Git!然后执行:
bash
git add text1.txt
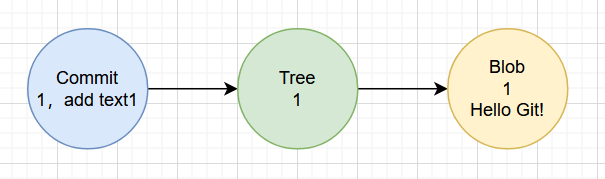
git commit -m "commit one"此时,Git 会做三件事:
-
生成一个 Blob 对象
- 内容:
Hello Git! - 哈希值:
737c... - 存储路径:
.git/objects/73/7c...
- 内容:
-
生成一个 Tree 对象
- 表示当前目录结构
- 内容:
blob 737c... text1.txt - 哈希值:
caae...
-
生成一个 Commit 对象
- 指向上述 Tree
- 包含作者、提交者、时间、提交信息
- 哈希值:
eddf...
你可以用以下命令查看这些对象的内容:
bash
git cat-file -p eddf # 查看 commit
git cat-file -p caae # 查看 tree
git cat-file -p 737c # 查看 blob简单理解:
Blob 存文件内容,Tree 存目录结构,Commit 存"这次快照是谁在什么时候做的"。
场景 2:新增文件并提交
现在你新增 text2.txt,内容为 New file,并提交:
bash
git add text2.txt
git commit -m "commit two"这时:
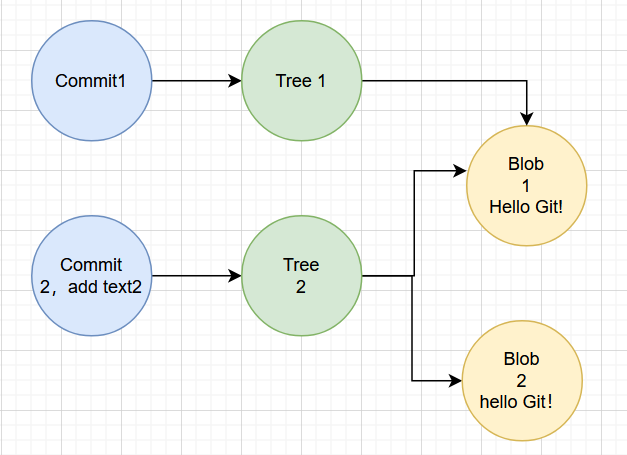
- 新增一个 Blob(
169d...)存text2.txt - 新建一个 Tree,包含两个条目:
blob 737c... → text1.txt,复用旧 Blob对象blob 169d... → text2.txt,新建的 Bolb对象
- 新建一个 Commit,指向新 Tree,并记录 parent 为
eddf...
你会发现:text1.txt 的内容没有变,所以 Git 直接复用了原来的 Blob 对象,没有重复存储!
这就是 Git 节省空间、高效存储的核心秘密。
场景 3:删除文件再提交
接着你删除 text2.txt,并提交第三次:
bash
git rm text2.txt
git commit -m "commit three"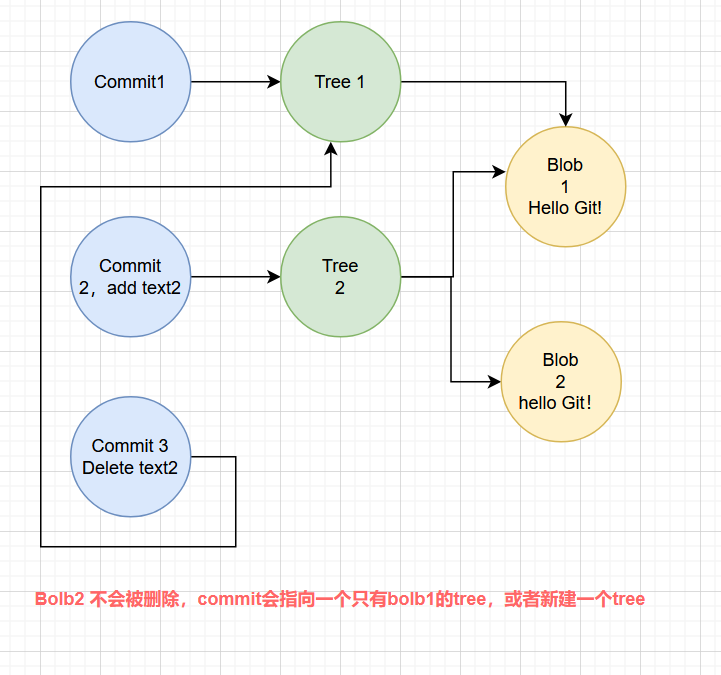
新的 Commit 会指向一个只包含 text1.txt 的 Tree,但 169d... 这个 Blob 依然存在于 .git/objects/ 中!
重要结论 :
一旦 Blob 被创建,它就永远不会被自动删除 ------即使你删掉了对应的文件并提交。因为 Git 的设计哲学是:历史不可篡改,所有对象永久保留(直到被显式清理)。
这正是开头那个"文件删不掉"的根本原因:那个几百 MB 的文件已经被转成 Blob 存入 Git 历史,后续提交无法让它消失。
三、那怎么真正"删掉"大文件?
解决方案分两步:
-
重写历史 ,移除包含大文件的那次提交
比如:git filter-repo或BFG Repo-Cleaner -
清理悬空对象 :
bashgit reflog expire --expire=now --all git gc --prune=now --aggressive
但需注意重写提交历史所带来的影响,比如说团队协作的场景。
四、分支(Branch)到底是什么?
你可能会问:我们天天用的 main、dev 分支去哪儿了?它们也是对象吗?
不是!分支只是一个"指向 Commit 的指针"。
在 .git/refs/heads/ 目录下,每个分支都是一个文本文件。例如:
bash
cat .git/refs/heads/main
# 输出:98ea1234... (即最新 commit 的哈希)当你执行 git checkout main,Git 只是把 HEAD 指向这个 Commit。
你可以随时让分支指向任意 Commit,甚至删除分支 其实只是删掉这个指针,但 Commit 和它的对象依然存在。
五、空间优化的秘密与潜在问题
引用机制的核心优势是高效存储。每个 commit 只记录变更,不复制整个仓库。例如,不变的文件共享 blob,新增或修改才生成新 blob。这在大型项目中显著节省空间。
然而,这也带来问题:如开头所述,误提交大文件会创建大量 blob,即使后续删除,blob 也不会自动消失,导致仓库膨胀。
可以试试:
- 使用
git reset或git rebase删除包含大文件的 commit,使相关 blob 成为"悬空对象"。 - 运行
git gc或git prune清理悬空对象,真正缩小仓库。 - 预防措施:使用
.gitignore忽略大文件,避免初次提交。
六、结语
Git 依赖 commit、tree 和 blob 的引用链来管理版本历史。这种设计确保了不可变性和效率,但也要求开发者理解其不可逆性。掌握这些基础,下次遇到仓库问题时,你能轻松诊断和修复。