RocketMq基础篇整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】环境搭建、基本使用、可视化界面 | https://zhenghuisheng.blog.csdn.net/article/details/147481401 |
| 【二】rocketmq集群搭建(docker版-2主2从) | https://zhenghuisheng.blog.csdn.net/article/details/154921615 |
| 【三】dashboard安装搭建和启动详解 | https://zhenghuisheng.blog.csdn.net/article/details/155371854 |
| 【四】rocketmq基本使用 | https://zhenghuisheng.blog.csdn.net/article/details/155679428 |
| 【五】精通rocketmq核心组件 | https://zhenghuisheng.blog.csdn.net/article/details/156546721 |
如需转载,请附上链接: https://blog.csdn.net/zhenghuishengq/article/details/156546721
精通rocketmq核心组件
- 一,精通rocketmq核心组件
-
- 1,简述"消息的一生"
- 2,Producer生产者
- 3,Topic消息主题
- 4,CommitLog存储
- 5,ConsumeQueue存储的索引
-
- [5.1,consumeQueue 概念](#5.1,consumeQueue 概念)
- 5.2,consumeQueue存储内容
- 5.3,配合offset使用
- 5.4,总结consumeQueue
- 6,MessageQueue消息队列
- 7,ConsumerGroup消费者组
- 8,Consumer
- 9,Offset偏移量
- 10,核心组件设计
- 11,总结
一,精通rocketmq核心组件
前面几篇文章已经讲解了rocketmq的集群搭建,dashboard可视化界面的使用,并且通过案例打通了整个链路,包括消息的生产、发送,以及集群的同步等,已经形成了一个闭环,整体测试都没问题。
在基础环境搭建好之后,接下来这篇正式对rocketmq相关组件的介绍, 用一条消息的 "人生轨迹" 串起所有基础概念,把 Topic、Queue、Message、Producer、Consumer、ConsumerGroup、Offset、commitLog 全部讲清楚。在学习之前,还是不能脱离官方文档:官方文档--领域模型 。
1,简述"消息的一生"
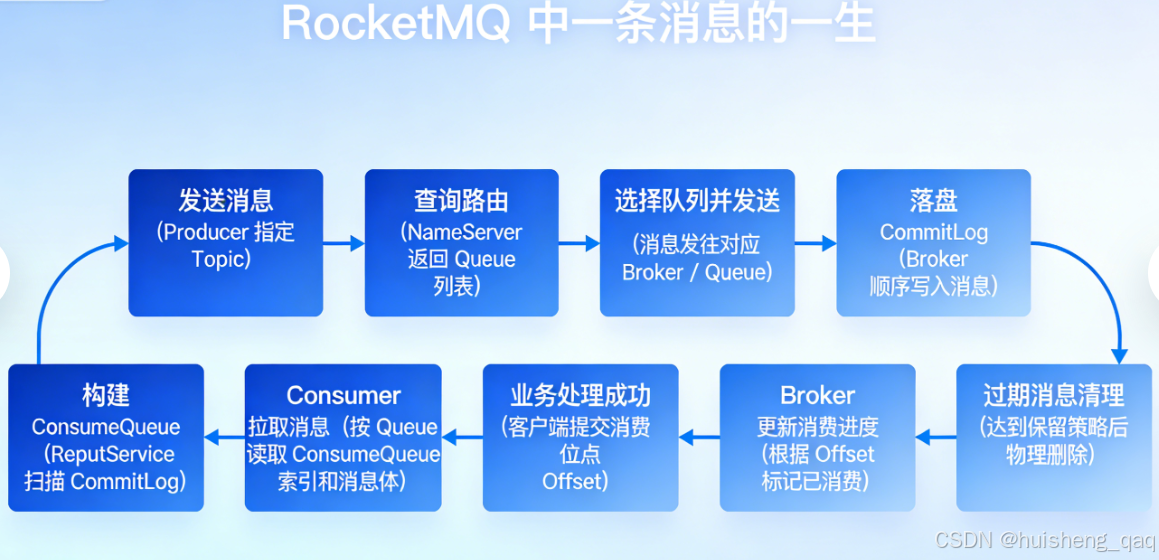
在学习rocketmq相关组件之前,先从消息的角度来看,消息的生命周期到底是怎么样的,其主要经历以下的流程:
- 消息最初开始从producer发送,并且指定对应的nameserver和topic
- nameserver即注册中心,将topic以及queue信息返回给producer
- producer拿到nameserver注册中心信息之后,决定将消息发往哪个broker以及queue
- broker 将消息顺序写入 CommitLog(磁盘文件)
- 后台线程 ReputService 通过异步扫描CommitLog,给每个Queue构建逻辑索引ConsumeQueue
- Consumer按Queue拉取ConsumeQueue 里的消息索引,再去 CommitLog读消息体
- 业务代码消费成功后,随后提交消费进度 Offset
- Broker再根据Offset偏移量判断哪些消息已经消费过,哪些还需要投递
- 再达到保留时间/空间策略后,旧消息被物理删除,结束一生
2,Producer生产者
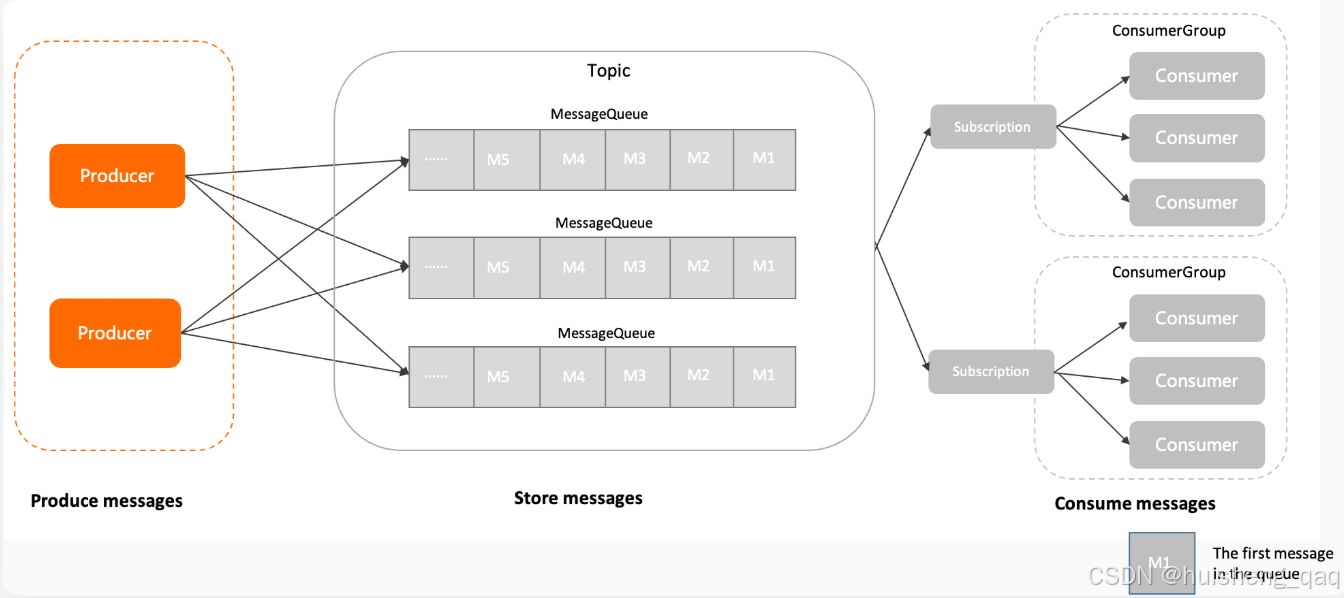
在前面我们已经通过一张"鸟瞰图"看过了一条消息的一生,无论后面的存储结构多复杂、消费模型多精巧,所有消息的起点只有一个:Producer 。 简单来说:Producer 是消息的生产者,负责把业务消息送进 RocketMQ 系统。 如下图,来自官网,producer就是整个架构的起点
2.1,Producer发送流程
接下来站在开发者的角度通过一段代码来体现,在创建Producer到发送消息前,整个流程到底做了哪些事件
java
// 1. 创建生产者(Producer Group 名称)
DefaultMQProducer producer = new DefaultMQProducer("zhsProducerGroup");
// 所有参数中,该参数必须绑定
producer.setNamesrvAddr("192.168.1.246:9876");
// 2. 启动 Producer(不启动会报错)
producer.start();
// 3. 构建消息
Message msg = new Message("zhsTopicV1", "TagA", "测试");
// 4. 发送消息
producer.send(msg)
// 5. 关闭 Producer
producer.shutdown();- 首先第一步是指定生产者组的名称,可以用于事务消息、故障恢复等场景
- 第二步需要指定nameserver,nameserver类似于一个注册中心,里面记录topic,messageQueue以及broker之间的关系,拿到这些信息之后,这样producer就知道应该往哪个broker下的哪个topic下的哪个messageQueue发送消息,一条消息只会发送到一个messageQueue消息队列中
- 第三步就开始真正的发送消息,首先会将消息发送到对应的broker中,随后等待broker的回应,一个broker就是一个物理机器的结点的意思。返回结构主要有三种,只要Producer收到发送成功的返回结果,那么就可以认为这条消息被broker接管了
- 发送成功
- 发送失败
- 发送超时
- 至于后面消息如何被存储、怎么消费等等,producer不需要关心。
3,Topic消息主题
接下来讲解的核心概念topic ,topic是一个逻辑概念 ,用于对消息进行分类。message消息具体不是存储在topic中,而是落盘存储在commitlog磁盘中, messageQueue消息队列也不存储真实数据,而是一个逻辑队列,用于路由、顺序、消费维度的划分,这个后面重点会讲。topic的作用就是决定这条消息属于哪个业务,因此就可以通过不同的topic之间实现业务与业务之间的隔离
用一个比较贴切的案例来讲解一下topic,在企业中的不同功能或者业务可能会拉不同的群,比如用户注册群、订单处理群、广告投放群等等,那么这些群名称就是可以真实的对应我们的topic,如下图标
| 群聊名称 | topic名称 | 含义 |
|---|---|---|
| userRegisterChatGroup | userRegisterTopic | 用户注册 |
| userOrderChatGroup | userOrderTopic | 订单 |
| adChatGroup | adTopic | 广告投放 |
群名其本身也不存储任何消息,我们需要往哪个群发消息时,只需要找到对应的群发即可,不需要具体的关心消息是否发送成功,触达成功,如何存储等。topic的角色就是这里的群名,发消息需要确定哪个群(指定topic),收消息也只能看到自己所加入群的消息(消费者订阅的topic)
在开发中,创建一条消息时,需要指定好topic,这样就能保证这条消息会发送到哪个topic中。即我要发送一个今日订单统计到订单群,那么只需要找到这个订单群聊并且往里面发送消息即可
java
Message msg = new Message("userOrderTopic", uuid.getBytes());topic在整个分布式架构中分布如下:一个broker会存在会存在多个topic,一个topic也可以存在多个broker中。如下面有四个broker,每个broker都有用户注册主题、订单主题、广告投放主题;每个主题都会分布在这四个broker上面
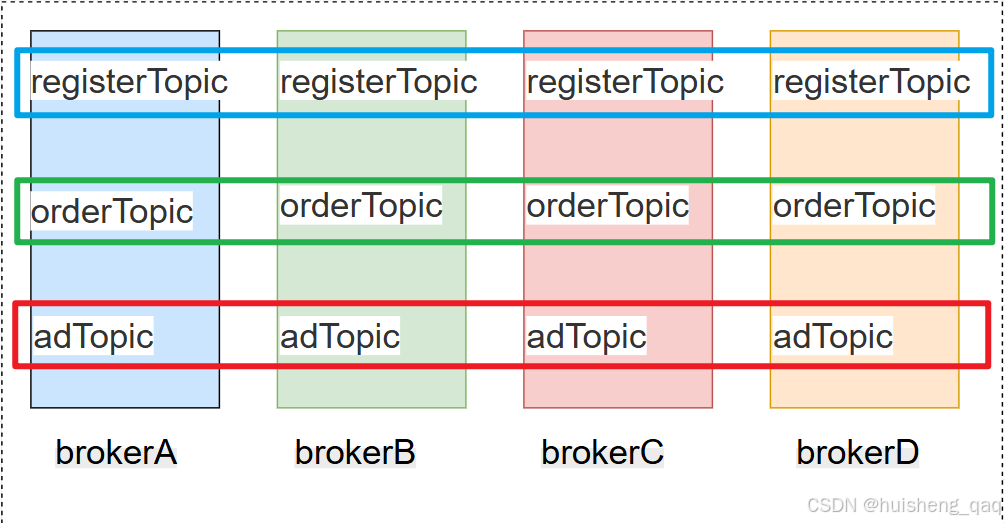
当然上面这是属于比较理想的状态,前面我们有用那个自动创建topic的方式,那种方式就是只会只在一个broker中创建topic,但是在实际开发中可以通过这个mqadmin中创建或者运维脚本提前创建
最后总结topic:只负责对消息进行业务分类,决定某一条消息属于哪一类的业务,本身不存储消息,而并且不需要关心数据的存储、消费进度、存储细节等。在producer消息发送前,就会指定对应的topic,因此topic本身也不需要关心数据混乱的问题。
4,CommitLog存储
4.1,commitlog概念
接下来先讲解commitlog,当消息从producer生产者发到broker的时候,消息会携带topic,messageQueue队列等参数,随后需要做的重点的事情就是先将消息持久化到磁盘。那么此时就需要将消息持久化到commitlog中,即我们的磁盘。
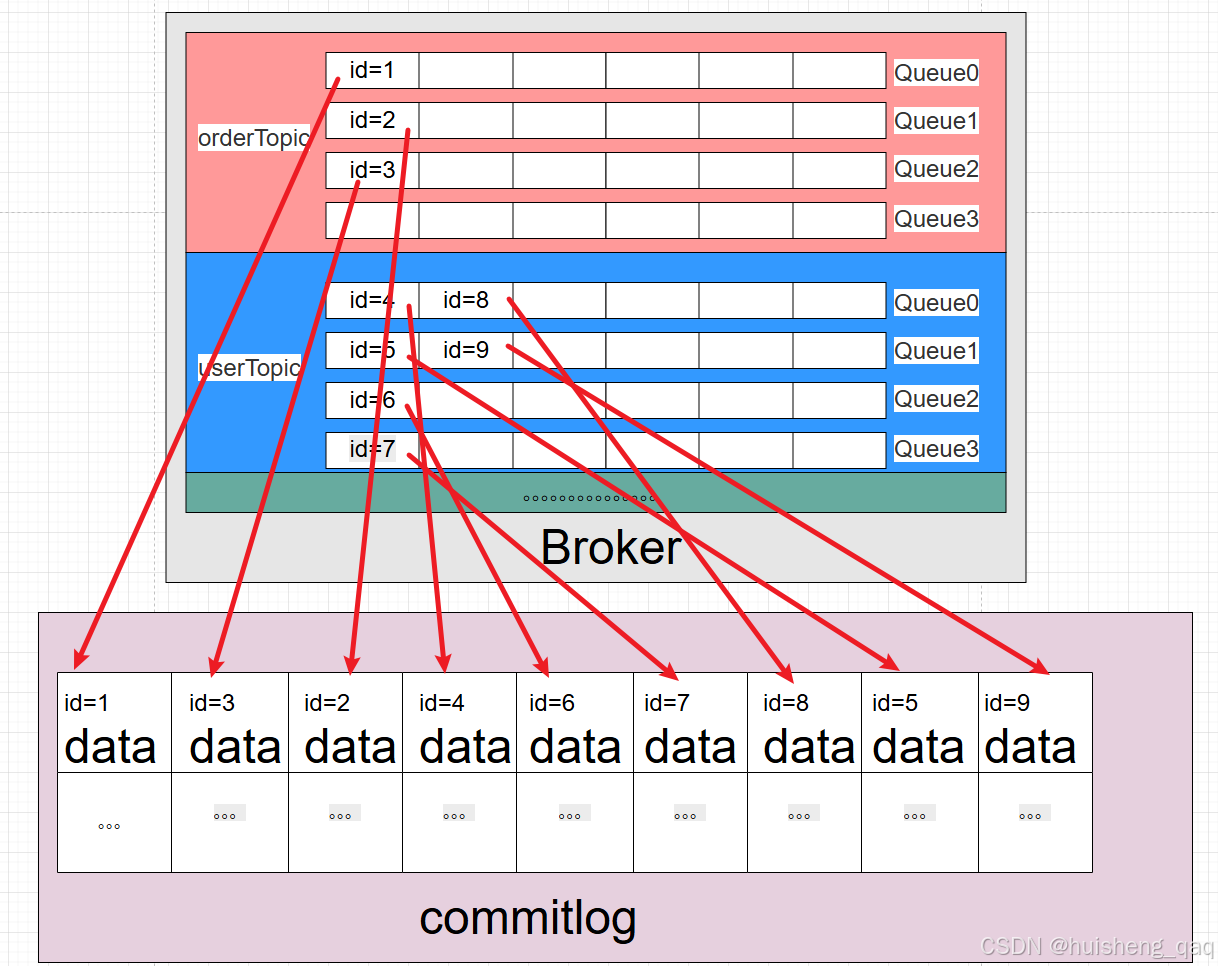
上面这幅图就是表示的queue队列和commitlog的真实关系,也就是说commitlog是真实存储数据的地方,接下来对这幅图做一个详细的解释:
- commitlog顺序追加写他不区分topic和队列,他会将所有的数据都通过顺序追加写的方式写到commitlog中。
- 通过上图也可以得知,单个topic下的多个队列在commitlog中并不能保证有序性,因为消息在producer发送前就会指定messageQueue,因此在messageQueue内部是有序。但是在producer中确实是按轮询顺序发送消息,但是在实际业务场景中是producer由多个线程发送消息的,即使确定了发送往broker的顺序,但是由于并发的场景下后面的线程后发但是会先到broker,因此无法保证 Topic 级别的全局有序 。如下面这个例子:
- 时间点 t1:线程T1 发送 A1(Queue0)到 Broker
- 时间点 t2:线程T2 发送 B1(Queue1)到 Broker
- 时间点 t3:线程T2 发送 B2(Queue1)到 Broker
- 时间点 t4:线程T1 发送 A2(Queue0)到 Broker
- 实际情况在broker中,可能接收到的顺序是A1--B1--B2--A2 。这里主要强调一点就是producer是顺序发,commitlog也是顺序追加写,但是由于并发的问题,导致谁先到broker谁写写入到commitlog中,因此无法保证不了topic的全局有序
- commitlog磁盘文件通过多段segment组成一个整体,数据都会通过追加写的方式写入内部。commitlog本身也存在过期,当 segment 停止写入后,且该 segment 中最后一条消息距离当前时间超过保留时间时,会被删除,默认是72小时 ,或者是磁盘使用率超过一定的阈值时就会被删,broker会以segment文件为单位清理过期的commitlog
- commitlog本身不限制逻辑大小,实际受限于磁盘容量和清理策略。
注意:图中的 id=1 并不是一条真实消息,而是一个抽象表示,用于说明 MessageQueue 中记录的是一条指向 CommitLog 的索引位置,在 RocketMQ 中对应的是真实的 CommitLogOffset(物理偏移量)。
4.2,与messageQueue关系
需要再讲解一个重点,再broker的数据的真实流转中,虽然 commitlog 我写在了MessageQueue 队列后面,但是实际情况是先有commitlog的数据存储,再有messageQueue的映射,因为messageQueue存储的是commitlog数据的具体索引,按理来说也是先有数据存储再有具体的位置,所以说先有commitlog再有messageQueue的view视图
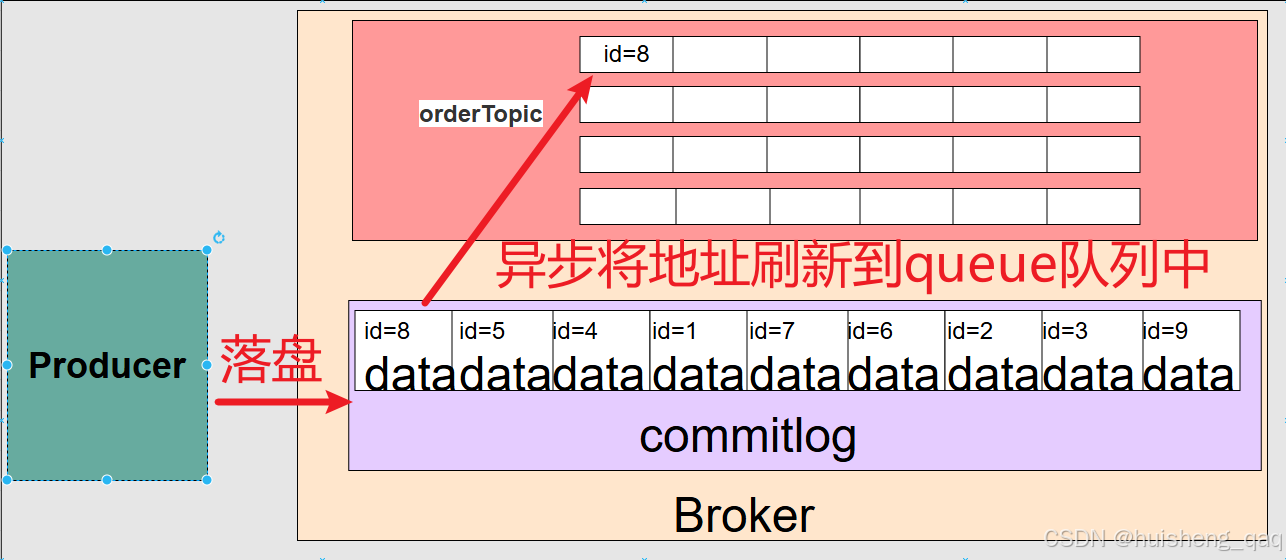
这里的id和上面的一样,也是一个抽象概念,具体是存的真实的偏移量。
4.3,segment过期删除
最后再提一下commitlog的组成,commitlog由多段的segment组成,每段segment为1g的磁盘容量,如果commitlog过期被删除时,就是以segment为单位删除,删除条件如下:
- 删除的第一要素:文件在停止写入的情况下,否则不能删除
- 在满足停止写入条件之后:
- 删除主要两个要素判断,一个是停止写后72小时没有数据往里面写,那么这段segment会被删除
- 或者当磁盘使用率超过阈值(默认75%)时,Broker 会优先删除最老、且已停止写入的 segment

5,ConsumeQueue存储的索引
ok上面讲解完了commitlog,commitlog主要是通过顺序追加写的方式将数据存储,上面也举了一个例子,commitlog可以类似于我们的mysql中的表(这里只是举例),用于存储数据,但是随着时间的增长,数据量会越来越大,而且所有的topic以及队列都会全部追加在commitlog上,那么随着时间的推移,数据量就会越来越大,后面需要找数据也是一个难题。
就比如consumer消费者在消费数据之后,需要将offset偏移量提交给broker,这样消费者在下次消费时就可以通过上次记录的偏移量接着消费。但是这里就出了一个难题,假设数据有100w,此时消费者消费记录到10w,那么定位对应的下一条消息,就需要全量从头到尾扫描一次,这样效率肯定会大大降低,一次在rocketmq内部,就给commitlog增加了一个索引,就是本章节需要讲的:consumeQueue
5.1,consumeQueue 概念
commitlog是一张顺序追加写的大表,那么consumeQueue就是用来快速定位消息的索引,里面不存储消息内容,只存储如何找到消息的信息
consumeQueue队列是按照Topic+MessageQueue维度进行维护的,为什么需要这一层,因为在producer中说了,在消息发送前,会先从nameServer中路由相关信息,就已经确定了这条消息会落到哪个topic对应的哪个messageQueue中,并且保证了消息时一定会落盘到commitlog。在这个基础上,Broker会为每一个messageQueue维护一份对应的consumeQueue,用于记录该messageQueue下的消息在commitlog中的物理位置。
- commitlog负责存储真实数据
- messageQueue用于决定消费和顺序的逻辑边界
- consumeQueue按messageQueue维度建立commitlog的索引
通过这种方式,就可以将确定的messageQueue和不确定的commitlog位置给关联。在后面消费者消费时,比如根据offset偏移量得知已经消费到了10万条,那么下一条可以直接通过consumeQueue去定位,而不需要对commitlog进行全量扫描,类似于mysql的索引。

5.2,consumeQueue存储内容
在mysql索引的b+树中,非叶子结点不会存数据,而是存指向叶子结点的id,consumeQueue也与之类似,不会存整条消息的内容,而是存储找到commitlog中这条内容的视图索引,加快查询,减少全量扫描。
consumeQueue主要存储三个核心的字段,分别是:commitlogOffset物理偏移量、msgSize消息长度、tagHashCode标签哈希值
- commotlogOffset:表示这条消息在commitlog文件中的起始位置,有了这个偏移量就可以直接定位commitlog的起始位置。有点类似于mysql的主键id,可以快速定位某条数据
- msgSize:表示这条消息的长度,从上面的commitlogOffset为开始,连续读取到少个字节,这样就能获取到一条完整的消息
- tagHashCode:辅助优化的字段,消息tag的hash值,某些hash过滤的场景下,可以判断是否符合订阅条件。
通过这个consumeQueue的索引视图,这样就能快速的定位commitlog存储位置,如弟N条消息,在commitlog的第X个字节开始,长度是Y。每个索引固定占用20个字节,因此consumeQueue的文件非常小。
5.3,配合offset使用
offset在后续会详讲解,这里大概讲一下consumeQueue和offset如何配合使用,offset就是偏移量的意思,一个消费者组消费了某个topic的消息之后,消费者会往broker中提交消费记录,这个就是offset偏移量,消费者下次消费就可以继续消费下一条消息即可。
offset中记录的内容结构如下:分别是topic、messageQueue,consumerGroup,显而易见,消费者在消费下一条消息时,为了可以快速的定位到commitlog的位置,就可以利用这个consumeQueue快速定位即可。
java
(ConsumerGroup, Topic, MessageQueue) -> ConsumeOffset定位到消息之后,通过consumeQueue获取起始位置,消息长度,从而在commitlog中获取到完整消息,并且在消费者完成消费之后,继续提交的offset就是加上这段消息大小即可。
java
(Topic, MessageQueue, ConsumerGroup) -> Offset = N + batchSize完整消费流程如下:
- 首先消费者从broker中读取这三元组:Topic、MessageQueue和上一次提交的offset偏移量大小N,N代表已经消费的条数
- 随后Broker去consumerQueue中找到对应的第N条索引,索引中记录了消息的commitlogOffset起始位置和msgSize消息长度
- 通过起始位置和消息长度读取commitlog中的数据,随后完成消费
- 消费成功之后提交offset偏移量回broker,offset = N + 这次消费条数
5.4,总结consumeQueue
consumeQueue主要是为了实现消费进度和真实物理存储的关键桥梁,是以messageQueue为维度建立的真实存储commitlog的一个视图索引,类似于b+树的一个高效稳定索引,总结一下几点:
- 实现快速定位commitlog,不需要全量扫描commitlog
- 每个索引占20个字节,本身轻量,可以支撑海量信息
- 可以精确恢复消费进度,支撑高并发消费
consumeQueue就是下图中的中间层,MessageQueue中的M1代表和commitlog关联,其本身不存储消息本身,CQ代表为每个topic中的messageQueue维度所建立的索引,真实的数据都存储在commitlog中,用data表示。因此消费者的offset就可以搞笑的从consumeQueue中定位到commitlog。
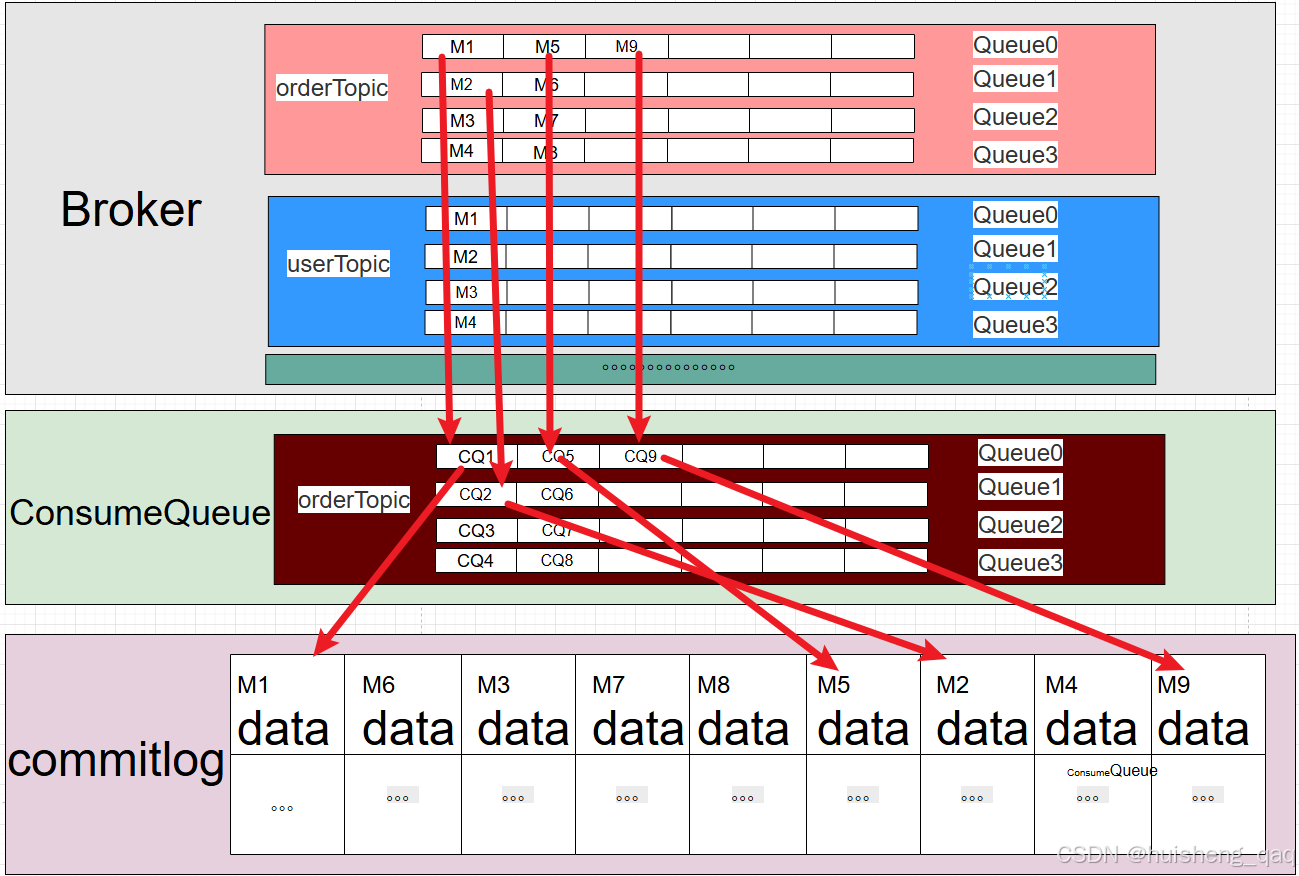
6,MessageQueue消息队列
6.1,messageQueue概念
上面讲解了commitlog数据存储和commitlog的索引consumeQueue,接下来讲解rocketmq的核心组件messageQueue,上面也有提到messageQueue相关:
- producer 在发送消息前会显式指定 Topic,随后从 NameServer 获取该 Topic 下的 MessageQueue 列表,并根据内置路由算法(如轮询、一致性哈希等),在客户端本地选择一个具体的 MessageQueue 作为发送目标。
- consumeQueue是以messageQueue维度设置的commitlog索引,每一条消息在逻辑上都会归属于某一个 MessageQueue等
结合官方的话说就是:MessageQueue消息的最小存储单元 。也就是说,消息的路由、分配、消费顺序、消费进度的推进、消费的rebalance等,都是以 MessageQueue 为维度来进行的。
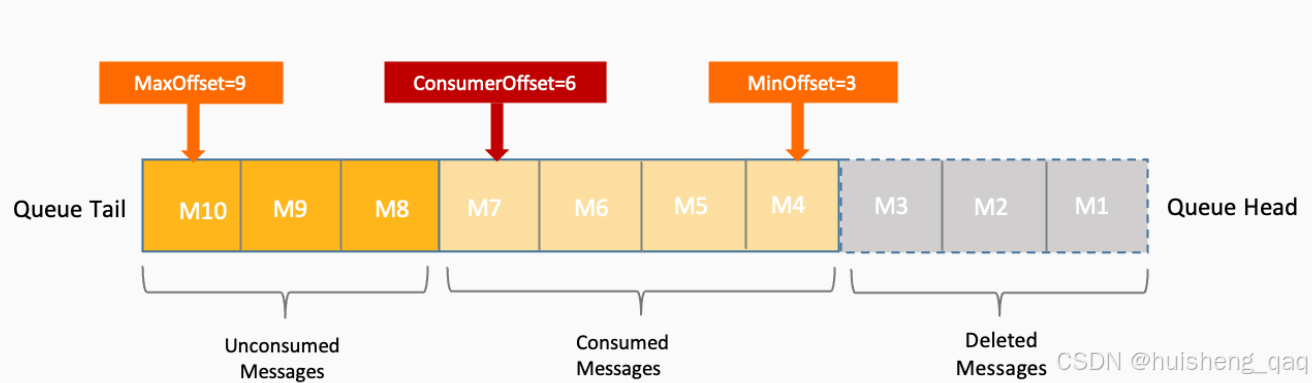
消息的落盘位置不是在MessageQueue队列中,而是在commitlog中,所以说MessageQueue本身不存储真实数据,它更多是一个逻辑队列视图概念,在Broker端,会为每一个MessageQueue维护对应的索引结构,用来记录消息在 CommitLog 中的物理位置,但是我们真实的操作消息的时候,比如消费等环节还是以messageQueue维度进行。
6.2,messageQueue与topic关系
如下图,一个broker中会存在多个topic,每个topic和messageQueue的关系如下,创建topic时默认会创建4个messageQueue,当然这个队列的个数可以修改。所以说topic就是一个逻辑概念,一个逻辑分类, messageQueue 并不是物理存储结构,而是消息在 Broker 侧的逻辑队列视图
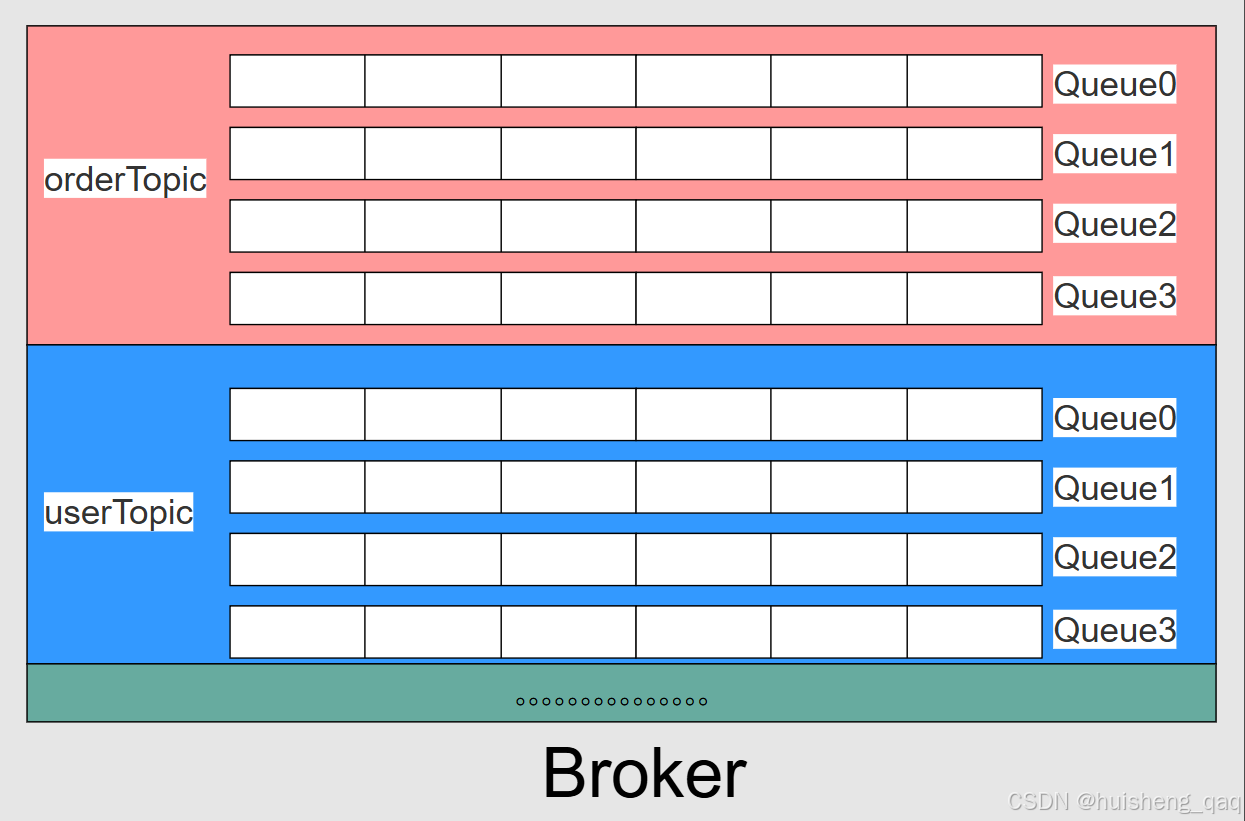
producer发送消息前,会先去nameserver中获取topic信息以及对应的全部queue列表,随后数据在commitlog落盘后,然后根据默认的轮询算法通过子线程异步将存储地址存到messageQueue队列中,消息地址映射只会进入一个queue,队列是消息的最小存储单位。
创建topic时不管时默认创建消息队列,还是官方推荐,都是建议建立多个queue,首先是解决吞吐量 问题,多个queue可以增加读写能力,不管是生产者投递还是消费者消费,都可以对单个queue实现 读/写热点分散。
接下来是消息顺序的问题,首先queue队列的天然特性就是先进先出 ,因此在单个队列中,就已经实现了排队和顺序;当然在不同队列之间,显然是不能保证有序的,所以说rocketmq的顺序消息只能保证单个队列有序,即局部有序 。如果业务允许的情况下:比如整体系统业务吞吐量不高,并且一定要全局有序的话,那么直接设计一个单queue队列的topic即可
6.3,messageQueue和consumeQueue的关联
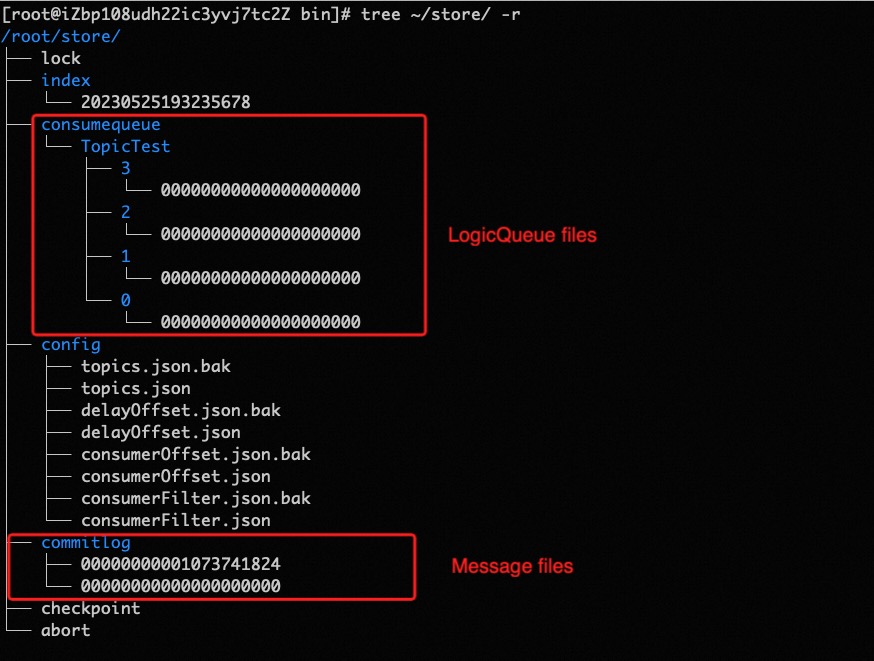
在讲解这个问题之前,可以先看一下官网提供的这张图: consumeQueue存储 ,可以看到TopicTest文件下面,存在4个物理队列文件,每个文件其实就是对应着4个messageQueue。
换句话说,messageQueue就是一个逻辑概念,可以理解为逻辑上的消息文件夹,也就是说磁盘中真实存在的只有commitlog存储文件和consumerQueue索引文件,messageQueue只是一个逻辑概念,除了可以快速通过队列下标定位到consumeQueue之外,还用于定义消息的归属、顺序消费的边界以及消费进度等
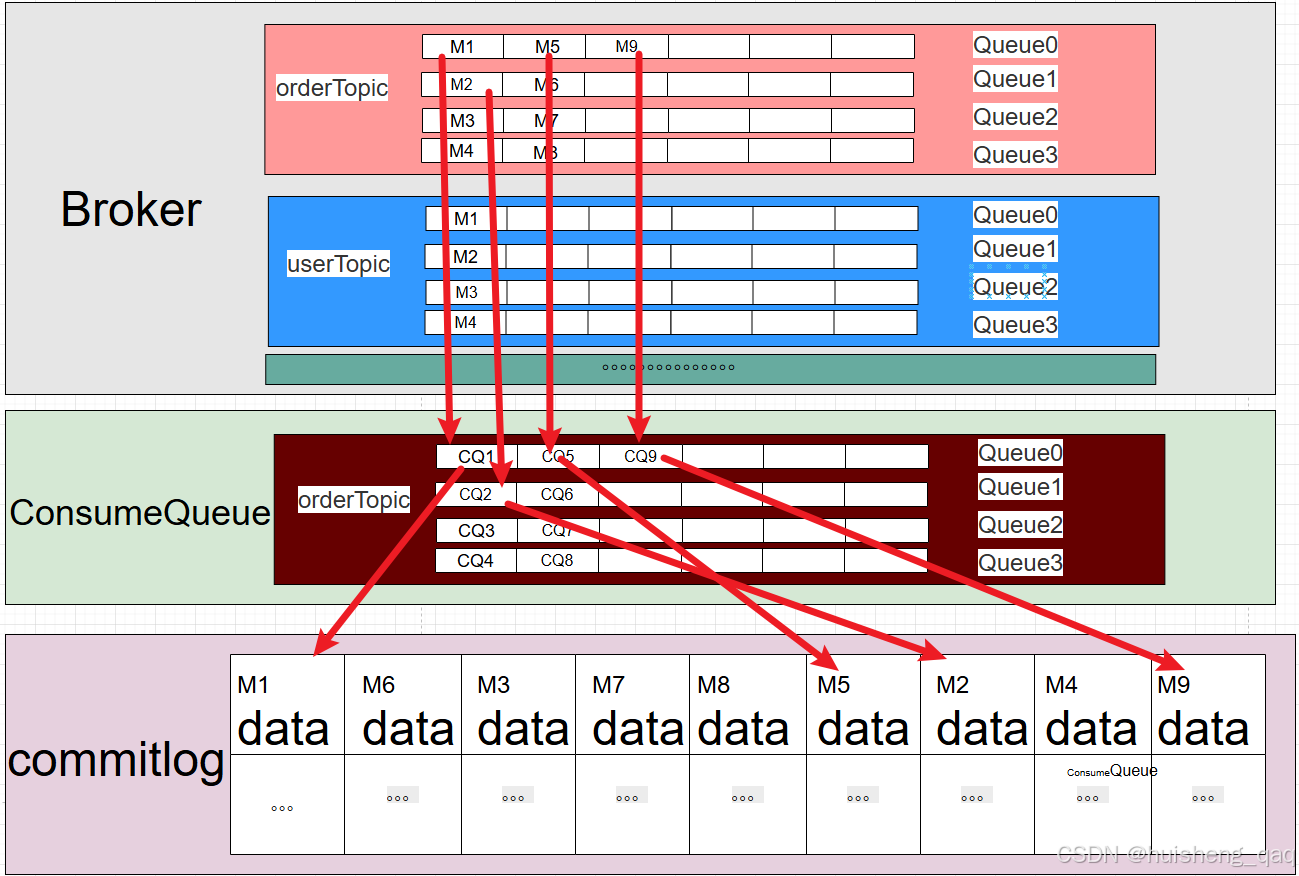
因此MesssageQueue和ConsumeQueue其实就是根据消息的个数一一对应,如下图,M1对应的就是CQ1,因为在单个messageQueue队列中的消息本身是有序的,所以第N个messageQueue对应的commitlog索引就是在对应consumeQueue队列的第N条中。
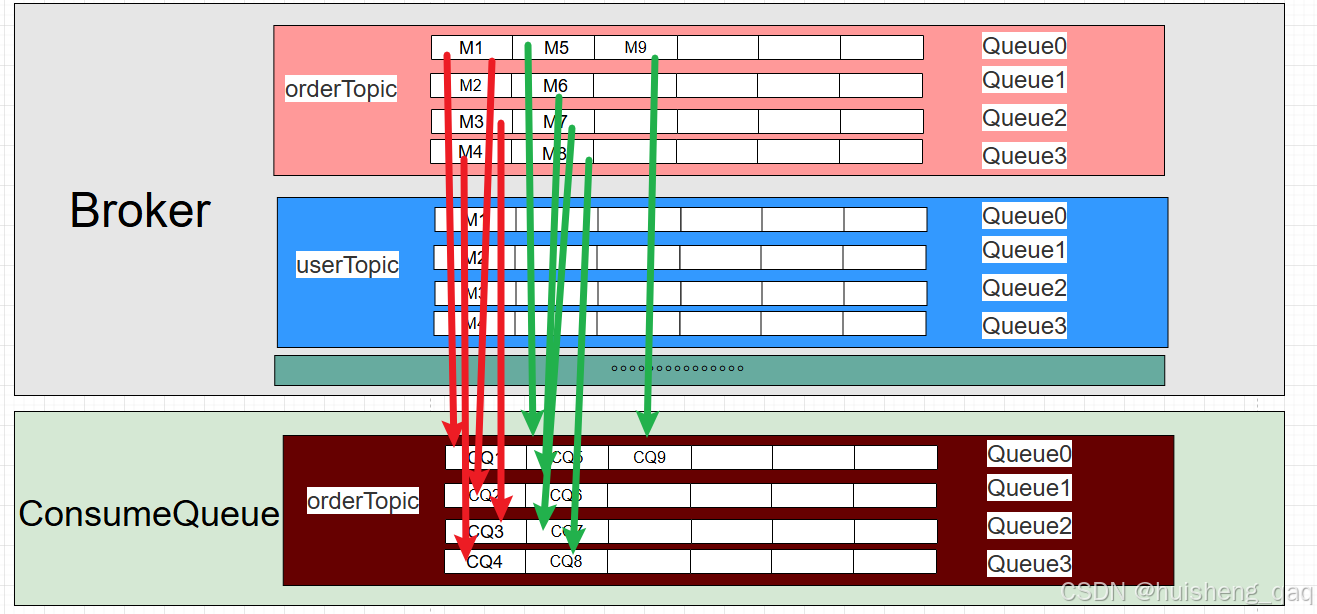
可以直接用表格来展示二者关系,其内容如下:
| consumeQueue | 含义 |
|---|---|
| index = 0 | MessageQueue中的第1条消息 |
| index = 1 | MessageQueue中的第2条消息 |
| index = 2 | MessageQueue中的第3条消息 |
| index = N | MessageQueue中的第N+1条消息 |
消费者下一次拉取消息的流程如下:
- 消费者offset偏移量N之后,这个N是上一次提交的消息最后消息的结束位置,也是下一条消息的起始位置
- 随后定位到对应consumeQueue的第N个索引,从索引中获取到对应的commitlogOffset和msgSize
- 根据偏移量和消息大小获取到commitlog中的内容,消费者消费成功后,再提交offset为N+1到broker中。offset是以消息条数为单位的逻辑偏移量,而不是commitlog中的物理字节偏移量。
6.4,为什么messageQueue是逻辑概念
首先谈一下什么是逻辑概念,首先指的是在实际磁盘中是不存在的,或者说是一个磁盘文件的一个映射物,并且也不负责真实数据的持久化等,而是真实数据的一个抽象视图,主要用于 主要用于路由、分组、顺序、消费等模型 。
上面的topic是逻辑概念,相当于是给messageQueue的划分,核心主要是对开发中不同的业务进行划分和隔离,但是为什么这个messageQueue也要设计成一个逻辑概念呢?
- 顺序写:在开发中,如果一层解决不了,那就加一层,而这个messageQueue就是新加的一层逻辑概念层,这样我们可以不用直接去操作commitlog以及consumeQueue,比如顺序写,直接写commitlog即可,如果直接写messageQueue,那么在一个topic的4个messageQueue中,就要轮询写如messageQueue,顺序写就会变成多文件切换的随机写,那么顺序写的功能没了,吞吐量大大下降。
- ConsumerGroup扩容缩容: 如果messageQueue是物理文件,消费者的rebalance机制也会出现问题,正常来说是一个消费者对应一个队列,如果消费者挂了,那么就需要查询rebalance某个messageQueue到某个消费者中,如messageQueue0对应的consumerA,但是consumerA服务挂了,因此需要rebalance队列messageQueue0到consumerB上面,如果messageQueue是物理文件,那么对应的物理文件也要对应的迁移,锁定等操作,数据迁移是大工程,也是不符合rocketmq设计的初衷的。如果只是逻辑概念,那么只需要messageQueue重新rebalance即可,内部的存储数据和索引是可以不用动的
- Broker扩容: 这个问题和上面的consumerGroup问题是一样的,假设增加一个broker,由于保证一条消息只存在一个messageQueue的原则,那么就需要将一半的数据挪到另一个broker中。如果messageQueue是物理概念,那么也需要涉及到数据迁移问题,需要将messageQueue对应的历史消息数据迁移,如果只是逻辑概念,那么只需要对这个逻辑概念进行迁移即可,不需要迁移大量的数据
6.5,总结messageQueue
综上,MessageQueue 被设计为逻辑概念而非物理存储结构,是 RocketMQ 在性能、扩展性与可运维性之间权衡后的必然结果:
- CommitLog:负责真实消息的顺序写入(物理存储)
- ConsumeQueue:按 MessageQueue 维度建立索引(物理索引)
- MessageQueue:定义消息归属、顺序边界与消费模型(逻辑视图)
到目前为止,rocketmq中的topic和messageQueue都是逻辑概念,真实的物理概念目前只有commitlog和consumeQueue。
7,ConsumerGroup消费者组
上面已经讲解完了product发送消息,commitlog存储消息等,接下来讲解的就是消息如何被消费,下图来自官网,在讲解consumer之前,先讲解rocketmq里面的另一个组件:consumerGroup,因为ConsumerGroup是规则定义者,consumer只是执行者 。 用官网的话说:消费者分组是 Apache RocketMQ 系统中承载多个消费行为一致的消费者的负载均衡分组。
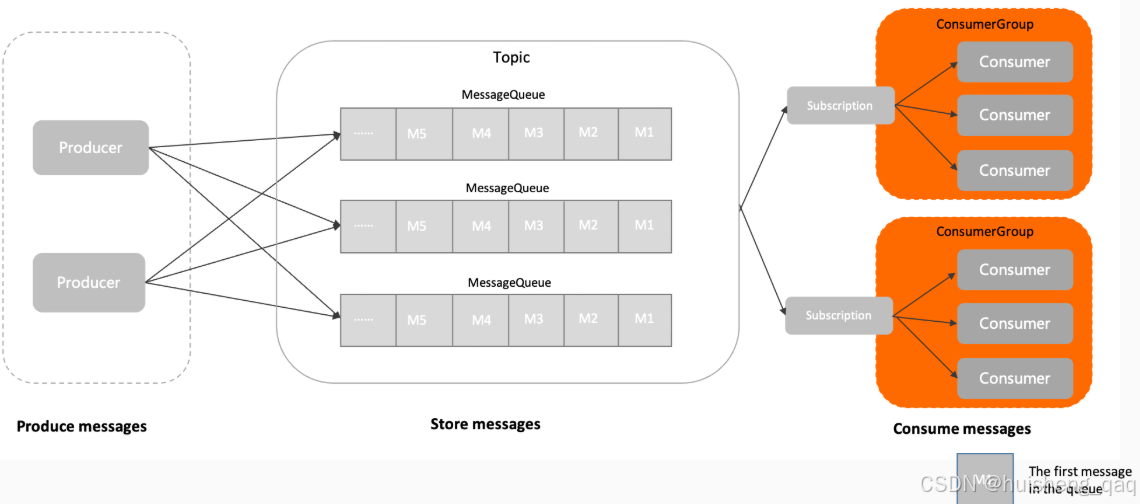
在rocketmq整个架构设计中:
- 消费是以ConsumerGroup为主体,从而解决在多实力环境中,出现相互重复消费的问题。
- Offset是以ConsumerGroup为维度,从而实现消费进度统一
- Rebalance 是以 ConsumerGroup为单位 ,解决一些容灾扩容等问题
consumerGroup更加强调的是消息如何被分配,而不是具体由哪个消费者来消费,如一些集群或者广播消费模式,MessageQueue消息由哪个消费者组中的消费者消费,每个消费者组的offset偏移量的问题,某个消费者挂如何实现Rebalance的问题等。
- 如集群消费和广播消费,这些都是属于consumerGroup的属性,而不是consumer的属性。集群消费一般用的比较普遍,一条消息只会被一个消费者组中的消费者消费一次;广播消费会被组内的所有consumer消费者消费。
- 如前面讲解的逻辑messageQueue消息队列,consumerGroup会分配组内的一个消费者进行消费,如UserTopic对应的MessageQueue0这个消息队列只会被consumerGroupA中consumerA消费,在正常集群消费情况下,1个MessageQueue对应着一个Consumer
- 接下来就是offset偏移量的问题,offset也是针对于真个消费者组的消费进度,在某个messageQueue消费的偏移量。offset是consumeGroup在对应messageQueue上消费的游标
- 最后一个就是rebalance问题,正常来说是一个消费者对于一个messageQueue, 当某个 Consumer 下线时,ConsumerGroup 会触发 Rebalance,将原本分配给该 Consumer 的 MessageQueue 重新分配给组内其他存活的 Consumer。
总而言之:ConsumerGroup不负责消息的具体消费,而是更加偏向于规则的制定,决定消息如何被分配,偏移量如何推进,扩展等问题
8,Consumer
上面已经讲解了consumerGroup是消息消费规则的定义者,那么接下来要讲解的就是消息消费的具体执行者-consumer。不用关心决定消费哪个messageQueue,也不要关心从哪个offset起开始消费,真正需要关心的主要有下面几件事:
- 与broker建立连接
- 按照consumerGroup的分配结果拉取对应messageQueue
- 执行消息消费,完成消费后提交结果和偏移量
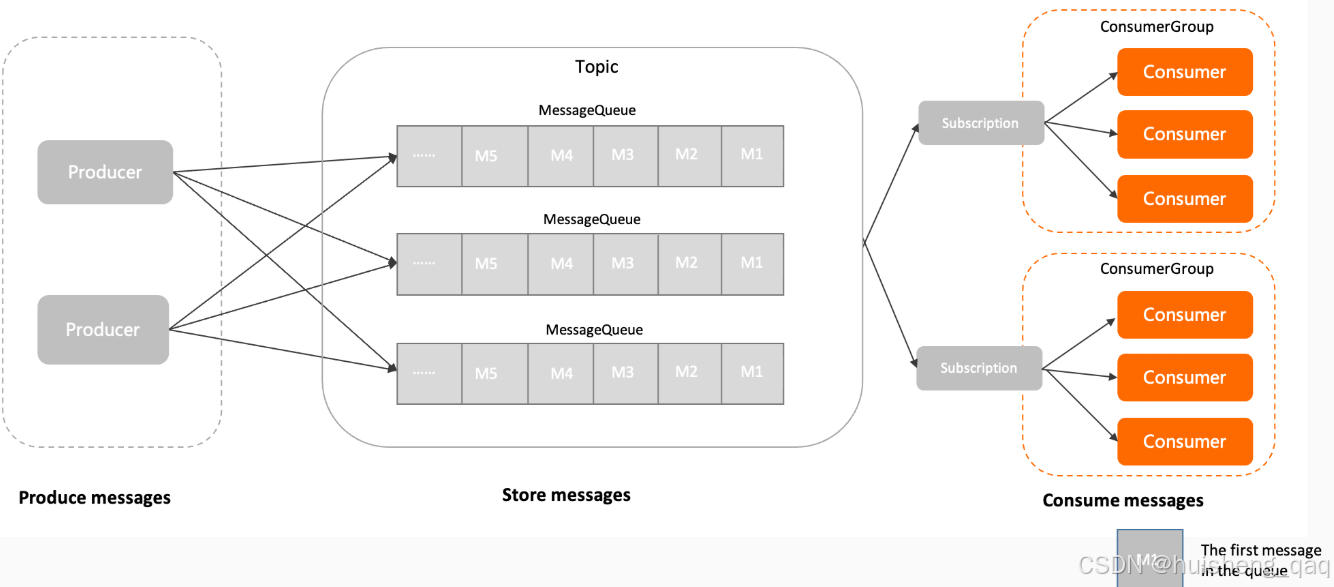
接下来看下面这段消费代码,需要指定consumerGroup消费者组,NameServer注册中心,然后订阅对应的topic以及可以设置tag标签(可选)等,设置监听器用于监听订阅的topic,最后完成消费
java
// 1. 创建 Consumer(必须填写消费组名称)
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("zhsConsumerGroup");
// 2. 指定 NameServer
consumer.setNamesrvAddr("192.168.1.246:9876");
// 3. 订阅 Topic 和 TagA
consumer.subscribe("zhsTopicV2", "TagA");
// 4. 注册消息监听器(并发消费)
consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {
for (MessageExt msg : msgs) {
System.out.println(
"收到消息:" + new String(msg.getBody()) +
", queueId=" + msg.getQueueId() +
", msgId=" + msg.getMsgId()
);
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});
// 5. 启动消费者
consumer.start();
System.out.println("Consumer 启动成功");
System.in.read();8.1,consumer消费流程
上面的代码看起来会稍微比较简单,绝大多数核心流程都在rocketmq内部完成,在完成建立连接,订阅消息和监听消息之后,其核心消费流程如下:
- 首先会或获取consumerGroup的分配结果,正常来说是一个消费者会对应一个messageQueue,但是在某个消费者挂了之后,会触发rebalance,这样就有可能一个消费者会消费多个messageQueue,但是这个主要由consumerGroup进行分配,consumer主要拉取分配结果即可。
- 再获取到指定的messageQueue之后,会根据在consumerGroup中维护的对应messageQueue的offset,对messageQueue进行消费,上面讲解过messageQueue是一个逻辑队列,所以consumer会根据messageQueue获取到真实的物理队列consumerQueue,通过对应的consumerQueue中获取commitlogOffset起始位置、msgSize消息大小、以及一些tagHashCode
- 再根据consumerQueue索引获取的信息,获取commitlog的真实数据,通过这个consumerQueue减少commitlog的全量扫描
- consumer根据获取的对应消息进行消费,开发人员可以对这些数据进行相应的业务处理,比如发送im消息等
- 最后消费完成之后,consumer会向broker提交新的offset,consumer本身是无状态的,不会对这些offset数据保存,offset的更新是以消息的条数为基数单位。

9,Offset偏移量
上面基本已经将所有的流程讲完了,比如生产者发送消息,commitlog存储消息,consumeGroup定制消费规则,consumer执行消费消息,consumeQueue快速定位消息,messageQueue决定消息顺序和边界等。在消息被消费的时候,消费者如何知道消息已经消费到了哪个位置呢,那么就需要这个 offset 偏移量来记录。
9.1,offset核心概念
在整个rocketmq设计中,offset是整个消费系统的核心组成,通过这个offset实现高可用和高性能。
offset的核心本质就是一个指针,用于记录消息消费的位置,上面也谈到了消息的messageQueue和consumerQueue都是以每一条消息为单位边界,因此显而易见在offset的单位也是以消息的条数为单位,比如某个topic下面的某个messageQueue消费到了第N条消息,那么这个offset=N
offset是以topic、messageQueue、consumerGroup为单位进行划分,这三者为一个基本单位,如下面的例子,只要这三者任意一个不一样,那么在broker中就得记录相应的offset
java
(Topic, MessageQueue, ConsumerGroup) -> Offset
# 订单主题
orderTopic
├─ MessageQueue-0
│ ├─ ConsumerGroup-A : Offset = 100
│ └─ ConsumerGroup-B : Offset = 0
├─ MessageQueue-1
│ ├─ ConsumerGroup-C : Offset = 150
│ └─ ConsumerGroup-D : Offset = 50offset属于consumerGroup,而不属于某一个consumer,consumer可能会挂掉或者动态的扩容缩容等,因此offset属于consumerGroup才能保证其连续、稳定以及可恢复等功能。
offset统一由broker保管,而不保存在consumer端本地,防止consumer端出现丢失问题,因此每次消息被成功消费之后,consumer端需要提交offset偏移量到broker中。
如果consumer中出现rebalance,messageQueue可能会归属于不同的consumer,但是对应的offset是不会变化,即使是有了新的consumer,也会继续按照这个offset位置进行消费。
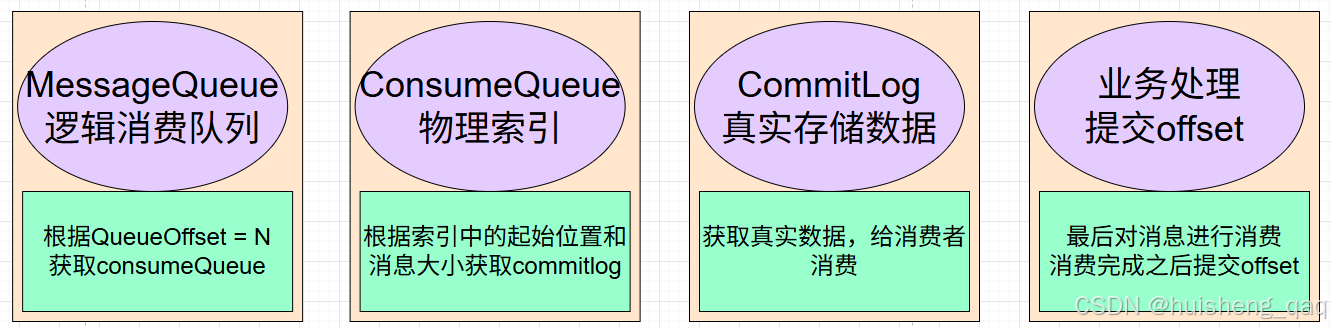
10,核心组件设计
10.1,组件设计动机
| 组件 | 类型 | 是否物理存在 | 主要职责 | 为什么这样设计 | 如果反过来会发生什么 |
|---|---|---|---|---|---|
| CommitLog | 物理存储 | ✅ 磁盘文件 | 存储真实消息内容(Body + 属性) | 顺序追加写,最大化磁盘吞吐,减少随机 IO | 拆成多队列文件会导致随机写、吞吐骤降 |
| ConsumeQueue | 物理索引 | ✅ 磁盘文件 | 按 MessageQueue 维度索引 CommitLog | 快速定位消息,避免扫描大 CommitLog | 无索引将导致消费性能不可接受 |
| MessageQueue | 逻辑概念 | ❌ 不直接存储 | 定义消息归属、顺序边界、消费单元 | 支撑顺序消费、Rebalance、扩容 | 若为物理文件,Rebalance/扩容需搬数据 |
| Topic | 逻辑概念 | ❌ 不直接存储 | 业务分类、消息隔离 | 解耦业务与底层存储 | 若存数据,会导致存储与业务强耦合 |
| Offset | 逻辑状态 | ❌(元数据) | 记录消费进度 | 精确恢复消费位置 | 无 offset 只能全量重复消费 |
| ConsumerGroup | 逻辑概念 | ❌ | 定义消费语义(集群/广播) | 支撑多消费者协同 |
10.2,设计动机和技术收益
| 设计目标 | 采用的结构 | 带来的收益 |
|---|---|---|
| 高吞吐写入 | CommitLog 顺序写 | 单机百万级 TPS |
| 快速定位消息 | ConsumeQueue 索引 | O(1) 定位,无需扫描 |
| 顺序消费 | MessageQueue | 单队列天然 FIFO |
| 高效 Rebalance | MessageQueue(逻辑) | 只调整关系,不搬数据 |
| Broker 可扩展 | Topic + Queue 路由 | 横向扩容低成本 |
| 消费可恢复 | Offset | 精确断点续消费 |
11,总结
上面已经系统的讲述了rocketmq的核心组件,以及每个核心组件的作用和原理,通过这些组件为整个系统带来高可用和高性能。
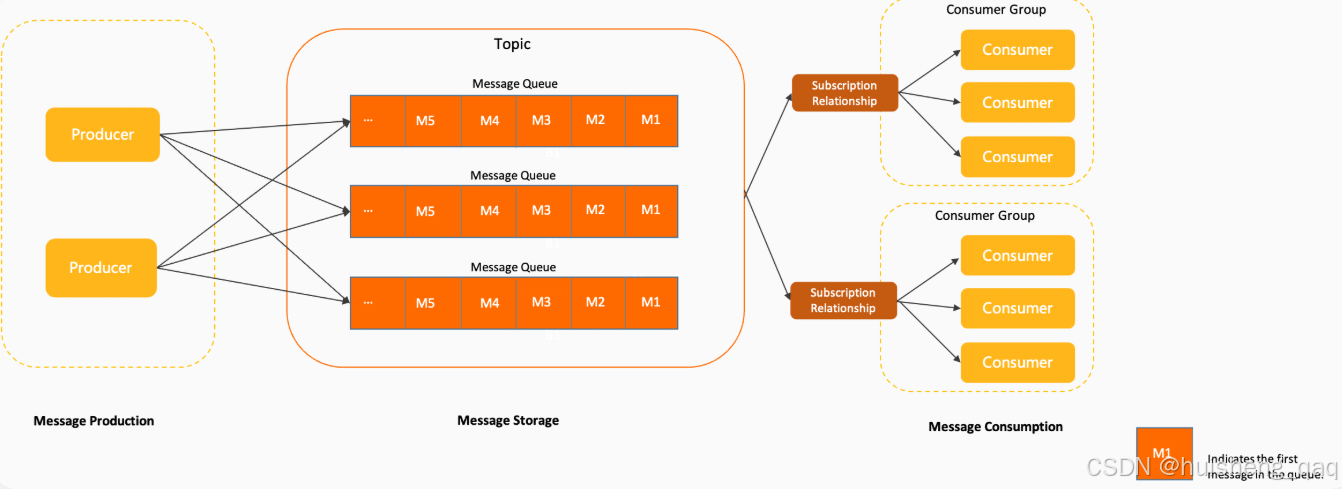
接下来对这些组件做一个最终总结:
- namaserver作为注册中心,记录所有topic和messageQueue的信息,
- producer作为生产者,获取nameserver相关信息,指定naveserver和topic,将消息发送到broker
- topic作为一个逻辑概念,相当于对所有messageQueue进行业务分类,实现业务与业务之间的隔离
- commitlog用于存储所有的真实消息数据,不会区分具体的topic和messageQueue,以顺序追加写的方式存储
- consumeQueue是commitlog的视图索引,以messageQueue为维度设计的,可以用于快定位存储在commitlog的数据
- messageQueue是consumeQueue的逻辑写照,messageQueue和consumeQueue根据队列索引一一对应,用于定义消息顺序和边界
- consumerGroup消费者组不执行具体的消息消费,而是用于制定消费规则,管理offset、定义消费模式、指定consumer和messageQueue之间的关系
- consumer是消息的真正执行者,获取consumerGroup相关信息之后,通过offset偏移量获取相关信息,随后执行消息消费、提交偏移量。