LangSmith
介绍
1. 核心功能支柱
LangSmith 的功能主要围绕开发周期的三个阶段展开:
A. 全链路追踪 (Tracing & Debugging) - "应用的X光机"
这是 LangSmith 最基础也最强大的功能。当你开发一个复杂的 Agent(比如 RAG 系统或多步推理机器人)时,仅仅看到最终输出是不够的。
-
可视化执行流:它能记录每一次 LLM 调用的完整链路。你可以看到 Agent 是如何思考的,检索了什么文档(Retriever),调用了什么工具(Tool),以及每一步的输入输出。
-
性能分析:精确显示每一步消耗了多少 Token,花费了多少时间(Latency),以及产生的费用。
-
Bug 定位:如果链条在第 5 步断了,或者是第 3 步产生了幻觉,你可以直接在 LangSmith 的 UI 界面中点击进去查看当时的具体 Prompt 和错误信息。
B. 评估与测试 (Evaluation) - "智能体的单元测试"
你可能修改了 Prompt,觉得"感觉"变好了,但如何量化?LangSmith 提供了强大的评估框架:
-
数据集管理:你可以创建"金标准数据集"(Golden Datasets),比如上传 100 个问题和标准答案。
-
自动评估器:利用 LLM(如 GPT-4)作为裁判,自动给你的模型打分(例如:准确性、相关性、是否有害)。
-
回归测试:每次修改代码或 Prompt 后,一键运行测试集,LangSmith 会生成对比报告,告诉你新版本在哪些问题上变好了,哪些变差了。
C. 监控与观测 (Monitoring) - "生产环境的仪表盘"
当应用上线后,LangSmith 帮助你盯着它:
-
实时统计:监控 Token 消耗速率、错误率、延迟分布 P95/P99。
-
用户反馈:可以集成用户点"赞/踩"的数据,将用户的负面反馈直接关联到具体的对话 Trace 上,方便后续复盘优化。
D. 提示词中心 (Prompt Hub)
类似 GitHub 的代码版本管理,但是针对 Prompt 的:
-
版本控制:保存 Prompt 的 v1, v2, v3 版本,随时回滚。
-
游乐场 (Playground):在网页端直接调整参数测试 Prompt,满意后直接在代码中通过 API 拉取特定版本的 Prompt。
2. 它解决了什么痛点?
| 开发痛点 | LangSmith 的解决方案 |
|---|---|
| "代码跑通了,但回答效果时好时坏" | 通过 Evaluation 建立量化指标,用数据说话,而不是凭感觉。 |
| "链条太长,不知道哪一步卡住了" | 通过 Tracing 可视化每一层调用,像看代码堆栈一样清晰。 |
| "Token 费用突然暴涨" | 通过 Monitoring 定位是哪个功能模块或哪类用户消耗了过多资源。 |
| "Prompt 改乱了,找不回以前的版本" | 通过 Prompt Hub 进行版本管理和协同编辑。 |
3. 技术集成与兼容性
虽然它是 LangChain 团队开发的,但 LangSmith 并不强制绑定 LangChain 框架。
-
原生支持 LangChain :如果你用 LangChain (Python/JS),只需要设置环境变量
LANGSMITH_TRACING=true,几乎零代码改动就能把数据流向 LangSmith。 -
支持任何 LLM 框架 :正如你在 README 中看到的,即使你只使用 OpenAI 原生 SDK,或者其他的框架(如 AutoGen, LlamaIndex),只需加上简单的 Wrapper(包装器)代码(如
wrap_openai),同样可以使用 LangSmith 的追踪功能。
基于langchain的自动记录
登录langsmith网站,https://smith.langchain.com/
创建项目之后,再创建API key
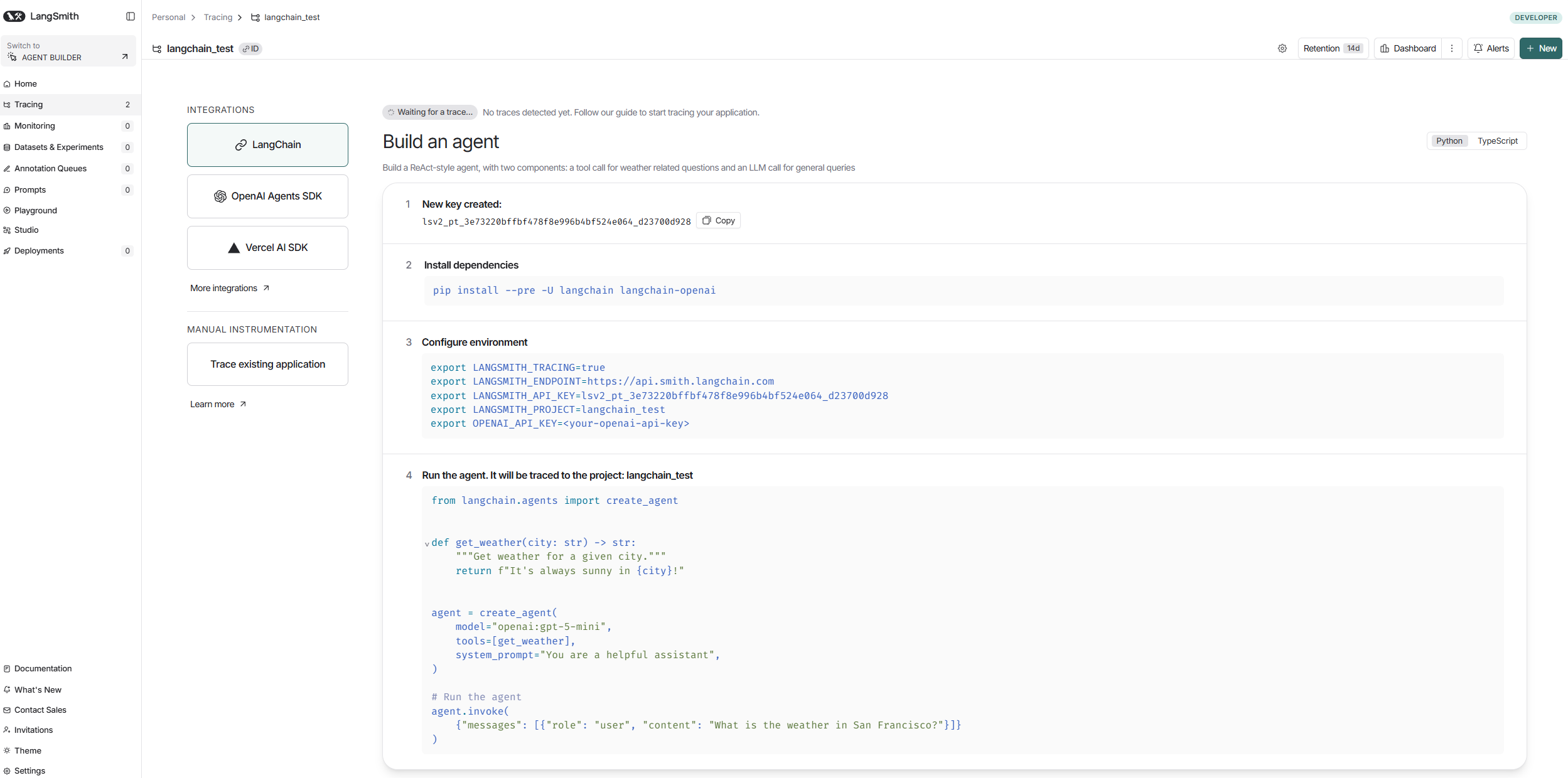
在langchain项目中,创建.env文件,运行langchain项目的时候,读取该配置文件,在运行时,便可自动将所有日志记录上传至网站中
LANGSMITH_API_KEY = 创建的API key
LANGSMITH_ENDPOINT = https://api.smith.langchain.com
LANGSMITH_PROJECT = 创建的项目名称
LANGSMITH_TRACING = true
OLLAMA_BASE_URL=http://localhost:11434
LANGCHAIN_TRACING_V2=true可以看到所有的api 调用,token消耗,时长消耗等信息
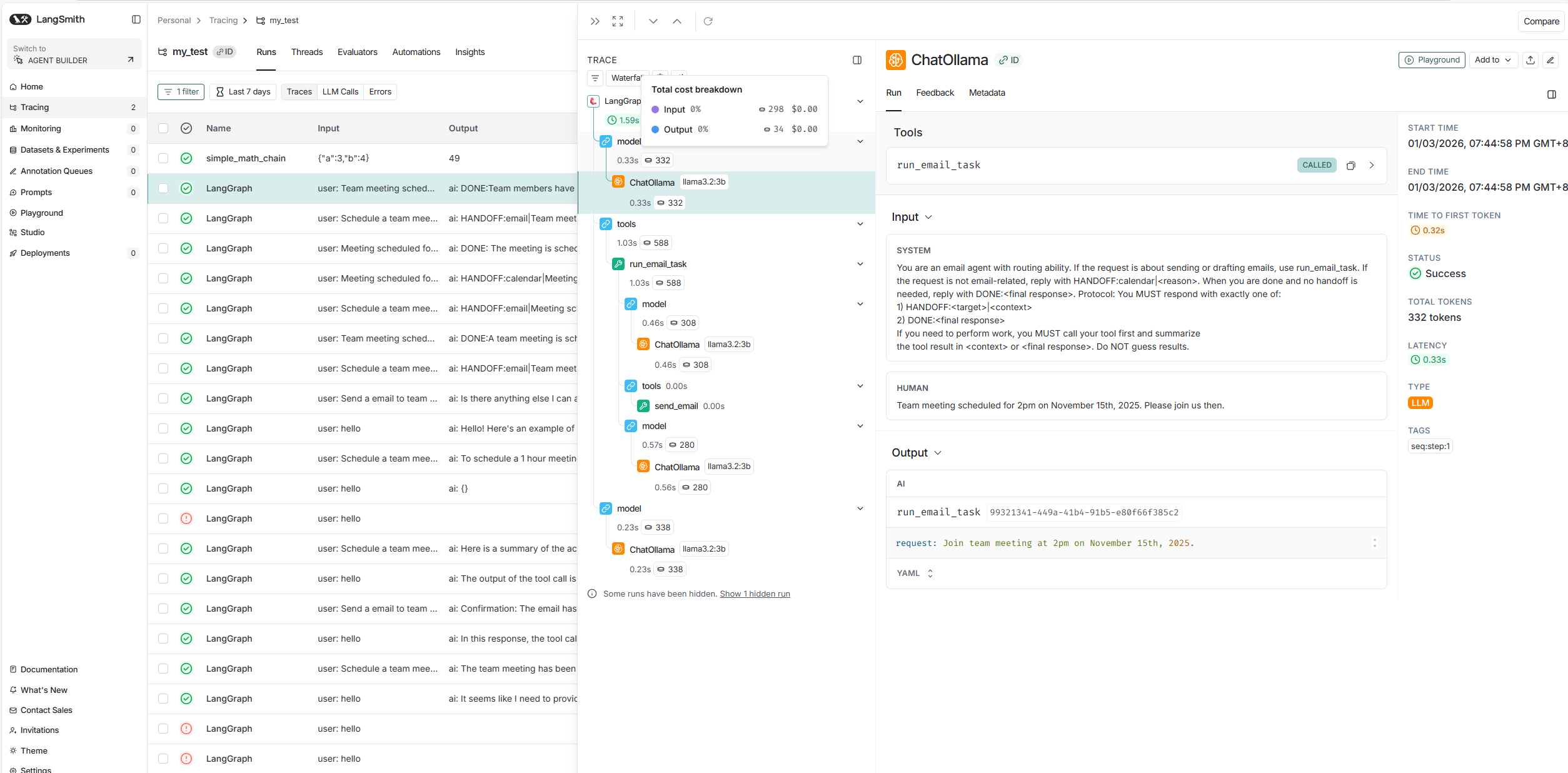
基于langsmith-sdk的显示记录
LANGSMITH_API_KEY = 创建的API key
LANGSMITH_ENDPOINT = https://api.smith.langchain.com
LANGSMITH_PROJECT = 创建的项目名称
LANGSMITH_TRACING = true
OLLAMA_BASE_URL=http://localhost:11434
LANGCHAIN_TRACING_V2=true
# langsmith_case_min.py
import os
from langsmith import traceable
def ensure_tracing_env():
# 没有 key 时就关闭 tracing,保证可运行
if not os.getenv("LANGSMITH_API_KEY"):
os.environ["LANGSMITH_TRACING"] = "false"
@traceable(name="simple_math_chain")
def add_then_square(a: int, b: int) -> int:
# 这里的计算也会被 trace 记录(如果开启 tracing)
return (a + b) ** 2
def main():
ensure_tracing_env()
result = add_then_square(3, 4)
print("result =", result)
if __name__ == "__main__":
main()
-
触发方式
- 之前:LANGCHAIN_TRACING_V2=true + LANGSMITH_*,LangChain 自动把链/agent/工具调用上报到 LangSmith。
- SDK:自己用 traceable 装饰器、RunTree、wrap_openai 等主动包住函数/模型调用,不依赖 LangChain。
-
适用范围
- 环境变量方式:只要走 LangChain 的链/agent,就能自动记录。
- SDK:可以记录任何 Python/JS 代码流程(自定义逻辑、非 LangChain 框架、原生 OpenAI 调用等)。
-
控制粒度
- 环境变量方式:自动且"黑盒",粒度由 LangChain 决定。
- SDK:你决定记录哪些函数、哪些输入输出、哪些子步骤(更灵活)。
-
使用复杂度
- 环境变量方式:最省事,几乎零改代码。
- SDK:需要在代码里加装饰器/包装器,改动更明显,但可控性更强。
LangExtract
介绍
1. 核心定位与解决的问题
LangExtract 的核心任务是信息抽取(Information Extraction, IE)。它致力于将临床笔记、报告、小说等非结构化文本,转换为便于机器处理的结构化数据(如 JSON/JSONL)。
它主要解决了传统 LLM 抽取任务中的几个痛点:
-
幻觉与溯源难: LLM 容易"编造"内容。LangExtract 强调 Source Grounding(溯源),即每一个提取出的实体都能对应到原文的具体位置。
-
长文本限制: 解决了"大海捞针"问题。通过分块(Chunking)、并行处理和多轮扫描,支持处理整本书或长篇报告。
-
结构不一致: 利用 Few-shot(少样本学习)和受控生成(特别是配合 Gemini 时),强制输出符合预定义的 Schema。
2. 核心功能亮点 (Key Features)
-
精准溯源 (Precise Source Grounding):
-
这是该库最大的卖点之一。它不仅提取信息,还能定位信息在原文中的位置。
-
应用场景: 在你的保险合规检测项目中,当模型判定某句话违规时,你可以直接高亮显示原文中的具体句子,提供确凿证据。
-
-
交互式可视化 (Interactive Visualization):
- 自动生成 HTML 文件,允许用户在一个界面中查看提取的实体并高亮显示原文上下文。这对于数据清洗和人工审核(Human-in-the-loop)非常有用。
-
长文档优化:
-
支持并行处理(Parallel processing)和多次传递(Multiple passes)以提高召回率。
-
可以直接处理 URL 或本地大文件(如古登堡计划中的整本小说)。
-
-
模型灵活性:
-
云端: 深度集成 Google Gemini(推荐 Tier 2 以获得高吞吐量),也支持 OpenAI。
-
本地/开源: 通过 Ollama 支持本地模型(如 Gemma 2, Llama 3 等)。这对于数据隐私敏感的项目(如涉及客户隐私的保险数据)至关重要。
-
3. 技术架构与工作流
-
定义任务 (Define):
-
编写 Prompt 描述任务。
-
提供高质量的 Few-shot Examples(少样本示例)。文档强调示例中的提取文本应与原文完全一致(Verbatim),以教导模型进行"原文摘录"而非"意译"。
-
-
执行抽取 (Extract):
-
调用
lx.extract。 -
参数支持
max_workers(并发数)、extraction_passes(多轮扫描)。 -
支持 Vertex AI Batch 模式(用于大规模离线处理,降低成本)。
-
-
结果输出与可视化:
-
输出为 JSONL 格式。
-
提供工具将 JSONL 转换为 HTML 可视化报告。
-
对比
一、 LangExtract 与直接使用大模型+提示词的优势对比
直接使用提示词(Prompt Engineering)常面临输出格式不稳定、信息遗漏、无法溯源等痛点。LangExtract 通过系统化的框架解决了这些问题:
|--------------|-----------------------------------|--------------------------------------------------------------------|----|
| 对比维度 | 直接使用大模型+提示词 | LangExtract 优势 | 来源 |
| 输出格式控制 | 格式不可控,可能随机返回 JSON、表格或自然语言,导致流程崩溃。 | 强制结构化保证:通过 Few-shot 示例和受控生成(如 Gemini 原生 schema 约束)确保输出稳定。 | |
| 信息准确性/溯源 | 难以确定提取内容在原文中的确切位置,真伪核查困难。 | 精确来源定位(Source Grounding):自动标注每个提取结果在原文中的字符偏移位置(char_interval)。 | |
| 长文档处理 | 受限于上下文窗口,长文档易出现"大海捞针"问题,遗漏细节。 | 长文档优化策略:采用智能分块、并行处理和多轮提取(Multi-Pass)来提高召回率。 | |
| 实体重复问题 | 模型常会重复提取同一实体,导致数据冗余。 | 自动去重:内置最佳实践,能有效识别并合并重复的实体。 | |
| 任务复杂度 | 需要编写极长的 Prompt 来规定各种约束,维护困难。 | 零代码定义任务:只需简单的自然语言描述和 1-3 个示例即可完成复杂任务。 | |
二、 LangExtract 的核心特性
-
精确溯源:支持将每个提取实体映射到原文的精确位置,并支持在交互式 HTML 中可视化高亮展示。
-
多轮扫描(Multi-Pass):针对遗漏内容进行多次扫描(例如 3 轮),显著提升复杂文档的信息抓取能力。
-
灵活的模型支持:适配 Google Gemini、OpenAI 模型,也支持通过 Ollama 使用本地开源模型。
-
领域自适应:无需微调,通过 Prompt 即可快速适应医疗(RadExtract)、法律、金融等垂直领域。
-
交互式可视化:可一键生成 HTML 文件,方便人工按类别筛选实体、查看属性及溯源。
三、 LangExtract 的主要用法
- 定义提取任务与示例
• Prompt 描述:使用自然语言定义需要提取的类别(如时间、人物、事件)及规则。
• Few-shot 示例 :使用 lx.data.ExampleData 定义"输入文本"与"期望输出"的对应关系。要求提取文本必须是原文的精确子串。
- 配置与运行
• 模型初始化 :根据需求配置云端 API(如 OpenAILanguageModel)或本地 Ollama 接口。
• 执行提取 :调用 lx.extract() 函数。对于长文本,可调节以下核心参数:
◦ extraction_passes:设置轮数(如 3 轮)以提高召回率。
◦ max_workers:设置并行处理的线程数以加速。
◦ max_char_buffer:控制分块大小(如 1000 字符)。
- 结果保存与可视化
• 持久化:将结果保存为 JSONL 格式。
• 可视化 :使用 lx.visualize() 生成包含高亮和筛选功能的交互式报告。
四、 如何应用到知识图谱构建上
LangExtract 是构建 Agentic-GraphRAG 系统(带溯源能力的知识图谱问答系统)的核心组件。具体步骤如下:
-
非结构化解析(数据清洗) : 先使用 OCR 工具(如 MinerU)将 PDF 等非结构化文档转换为带结构标记的 Markdown 文本。
-
结构化提取 : 使用 LangExtract 从 Markdown 中提取实体 、数据指标 、事件 以及关系描述。
◦ 关键点 :在 Prompt 中要求模型标注关系涉及的主体(如"主体1"、"主体2"),并保留每个实体的 char_interval。
- 构建语义网络:
◦ 节点(Nodes):将提取的实体作为节点,存储其属性和提及位置信息(mentions)。
◦ 边(Edges):利用提取的"关系描述"构建实体间的关联(Subject-Relation-Object)。
-
向量存储与检索 : 将提取的结构化文本转换为向量存入数据库(如 ChromaDB ),同时将
char_interval存入元数据(metadata)中。 -
Agent 问答与溯源 : 构建智能 Agent。当用户提问时,Agent 调用向量检索或图谱检索工具。由于 LangExtract 记录了精确的原文位置,Agent 在回答时可以明确指出:"该信息源自原文第 X 到 Y 字符处",实现真正的来源验证(Source Grounding)。
总结 :如果把直接用大模型比作"盲人摸象",提取的信息往往支离破碎且不可证;那么 LangExtract 就像是为大模型配备了一个带有精密坐标系的显微镜,它不仅能把有价值的信息结构化,还能精确锁定每一条信息在知识版图中的原始坐标,为构建严谨的知识图谱提供了坚实基础。
案例
# 导入所有需要的库
import os
import time
import json
from pathlib import Path
from collections import Counter
# 纯提示词方式所需
from openai import OpenAI
# LangExtract 方式所需
import langextract as lx
from langextract.providers.openai import OpenAILanguageModel
from langextract.prompt_validation import PromptValidationLevel
# 环境变量加载
from dotenv import load_dotenv
print("所有依赖库导入成功")
# 加载环境变量
load_dotenv()
# 读取 API 配置
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
DEEPSEEK_BASE_URL = os.getenv("DEEPSEEK_BASE_URL", "https://api.deepseek.com")
DEFAULT_MODEL = os.getenv("DEFAULT_MODEL", "deepseek-chat")
# 创建输出目录
OUTPUT_DIR = Path("./outputs")
OUTPUT_DIR.mkdir(exist_ok=True)
print("环境变量加载完成")
print(f" 模型: {DEFAULT_MODEL}")
print(f" API: {DEEPSEEK_BASE_URL}")
# 定义测试文本
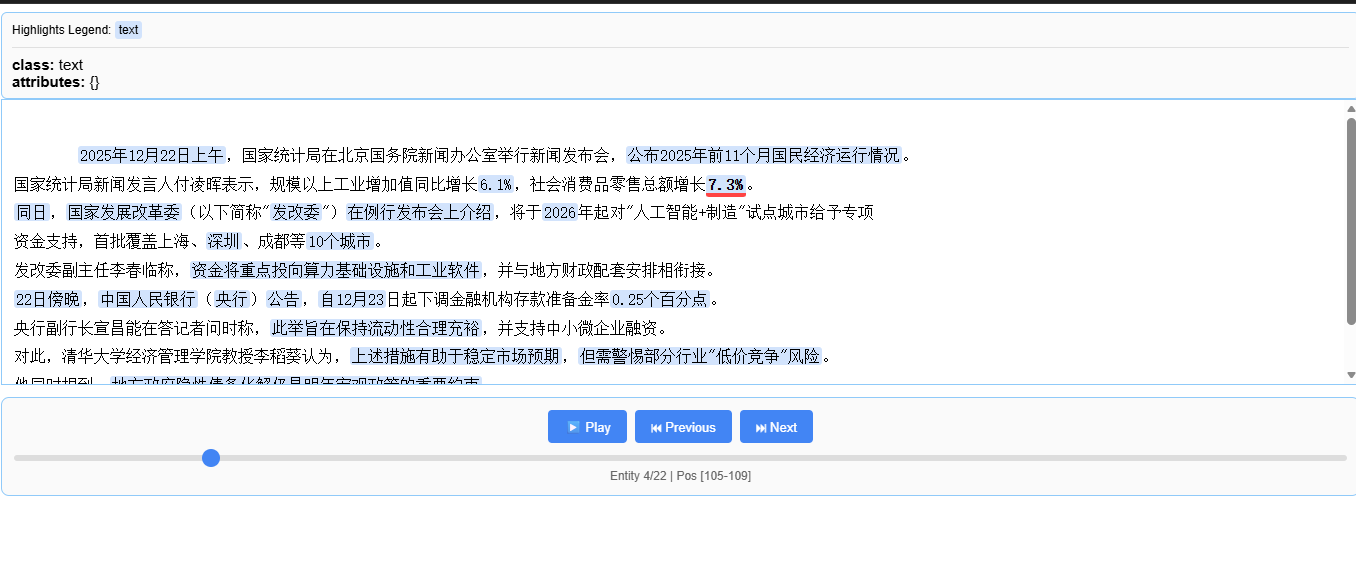
input_text = """
2025年12月22日上午,国家统计局在北京国务院新闻办公室举行新闻发布会,公布2025年前11个月国民经济运行情况。
国家统计局新闻发言人付凌晖表示,规模以上工业增加值同比增长6.1%,社会消费品零售总额增长7.3%。
同日,国家发展改革委(以下简称"发改委")在例行发布会上介绍,将于2026年起对"人工智能+制造"试点城市给予专项
资金支持,首批覆盖上海、深圳、成都等10个城市。
发改委副主任李春临称,资金将重点投向算力基础设施和工业软件,并与地方财政配套安排相衔接。
22日傍晚,中国人民银行(央行)公告,自12月23日起下调金融机构存款准备金率0.25个百分点。
央行副行长宣昌能在答记者问时称,此举旨在保持流动性合理充裕,并支持中小微企业融资。
对此,清华大学经济管理学院教授李稻葵认为,上述措施有助于稳定市场预期,但需警惕部分行业"低价竞争"风险。
他同时提到,地方政府隐性债务化解仍是明年宏观政策的重要约束。
""".strip()
print("✓ 测试文本已准备")
print(f"文本长度: {len(input_text)} 字符")
print(f"\n原文预览(前200字符):\n{input_text[:200]}...")
# 定义 Few-shot 示例文本
example_text = (
"2025年6月3日,工业和信息化部在北京发布《算力基础设施高质量发展行动计划》。"
"工信部副部长张云明表示,到2027年全国算力总规模将达到300 EFLOPS。"
)
# 定义示例的标准输出格式
example_output = """{
"extractions": [
{"class": "时间", "text": "2025年6月3日"},
{"class": "机构", "text": "工业和信息化部"},
{"class": "地点", "text": "北京"},
{"class": "人物", "text": "张云明"},
{"class": "事件", "text": "发布《算力基础设施高质量发展行动计划》"},
{"class": "指标", "text": "300 EFLOPS"}
]
}"""
print("Few-shot 示例已准备")
print(f"示例文本: {example_text}")
print(f"\n示例输出:\n{example_output}")
# 构建完整 Prompt
prompt = f"""
请从下面的新闻文本中提取结构化信息。
【抽取类别】
- 时间
- 地点
- 机构
- 人物
- 事件
- 指标(数值/增速/比例/数量等)
【要求】
1. 所有 `text` 必须是原文中的精确子串,不要改写
2. 去重并按原文出现顺序输出
【输出格式】
请严格输出 JSON(不要添加任何解释、Markdown、代码块):
{{
"extractions": [
{{
"class": "类别",
"text": "原文精确文本"
}}
]
}}
【Few-shot 示例】
示例文本:
{example_text}
示例输出:
{example_output}
---
现在请抽取这段新闻文本:
{input_text}
"""
print("Prompt 构建完成")
print(f"Prompt 总长度: {len(prompt)} 字符")
# 创建 DeepSeek 客户端
client = OpenAI(
api_key=DEEPSEEK_API_KEY,
base_url=DEEPSEEK_BASE_URL
)
print("DeepSeek 客户端创建成功")
# 调用 DeepSeek API
print("正在调用 DeepSeek API...")
start_time = time.time()
response = client.chat.completions.create(
model=DEFAULT_MODEL,
messages=[
{
"role": "system",
"content": "你是一个文本信息抽取助手,请严格按照用户指定的 JSON 格式输出,不要添加多余解释。"
},
{
"role":"user",
"content":prompt
}
],
temperature=0.3,
max_tokens=2000,
stream=False
)
result_prompt = response.choices[0].message.content
elapsed = time.time() - start_time
print(f"提取完成(耗时 {elapsed:.2f} 秒)")
# 打印原始结果
print("纯提示词提取结果:")
print("=" * 80)
print(result_prompt)
print("=" * 80)
# 解析 JSON 并统计
prompt_result = json.loads(result_prompt)
prompt_extractions = prompt_result["extractions"]
# 基本统计
total_count_prompt = len(prompt_extractions)
type_counts_prompt = Counter(ext["class"] for ext in prompt_extractions)
print(f"纯提示词统计:")
print(f" 总实体数: {total_count_prompt}")
print(f" 按类型分布:")
for entity_type, count in sorted(type_counts_prompt.items()):
print(f" - {entity_type}: {count} 个")
# 检查重复
text_counts = Counter(ext["text"] for ext in prompt_extractions)
duplicates = {text: count for text, count in text_counts.items() if count > 1}
if duplicates:
print("发现重复实体:")
for text, count in duplicates.items():
print(f" - '{text}' 重复了 {count} 次")
total_duplicates = sum(count - 1 for count in duplicates.values())
unique_count_prompt = total_count_prompt - total_duplicates
print(f"\n去重后实际数量: {unique_count_prompt} 个(减少了 {total_duplicates} 个重复)")
else:
print("✓ 未发现重复实体")
unique_count_prompt = total_count_prompt
# 定义 LangExtract 的任务描述
langextract_prompt = """
从新闻文本中提取以下信息:
- 时间
- 地点
- 机构
- 人物
- 事件
- 指标(数值/增速/比例/数量等)
要求:
1. 使用原文中的完整表述
2. 不要重复
3. 按出现顺序提取
"""
print("LangExtract 任务描述已定义")
print(f"Prompt 长度: {len(langextract_prompt)} 字符(比纯提示词简洁得多)")
# 定义 LangExtract 的 Few-shot 示例
examples = [
lx.data.ExampleData(
text=example_text,
extractions=[
lx.data.Extraction("时间", "2025年6月3日"),
lx.data.Extraction("机构", "工业和信息化部"),
lx.data.Extraction("地点", "北京"),
lx.data.Extraction("人物", "张云明"),
lx.data.Extraction("事件", "发布《算力基础设施高质量发展行动计划》"),
lx.data.Extraction("指标", "300 EFLOPS"),
]
)
]
print("LangExtract Few-shot 示例已定义")
print(f"示例数量: {len(examples)}")
print(f"示例实体数: {len(examples[0].extractions)}")
# 创建 LangExtract 模型
model = OpenAILanguageModel(
model_id=DEFAULT_MODEL,
api_key=DEEPSEEK_API_KEY,
base_url=DEEPSEEK_BASE_URL
)
print("LangExtract 模型创建成功")
print(f"使用模型: {DEFAULT_MODEL}(与纯提示词相同)")
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model=model,
fence_output=True,
use_schema_constraints=False,
prompt_validation_level=PromptValidationLevel.OFF,
)
# 打印 LangExtract 结果
print("LangExtract 提取结果:")
print("=" * 80)
for ext in result.extractions:
if ext.char_interval:
pos_info = f"[{ext.char_interval.start_pos}-{ext.char_interval.end_pos}]"
print(f"[{ext.extraction_class}] {ext.extraction_text} {pos_info}")
print("=" * 80)
# 统计 LangExtract 结果
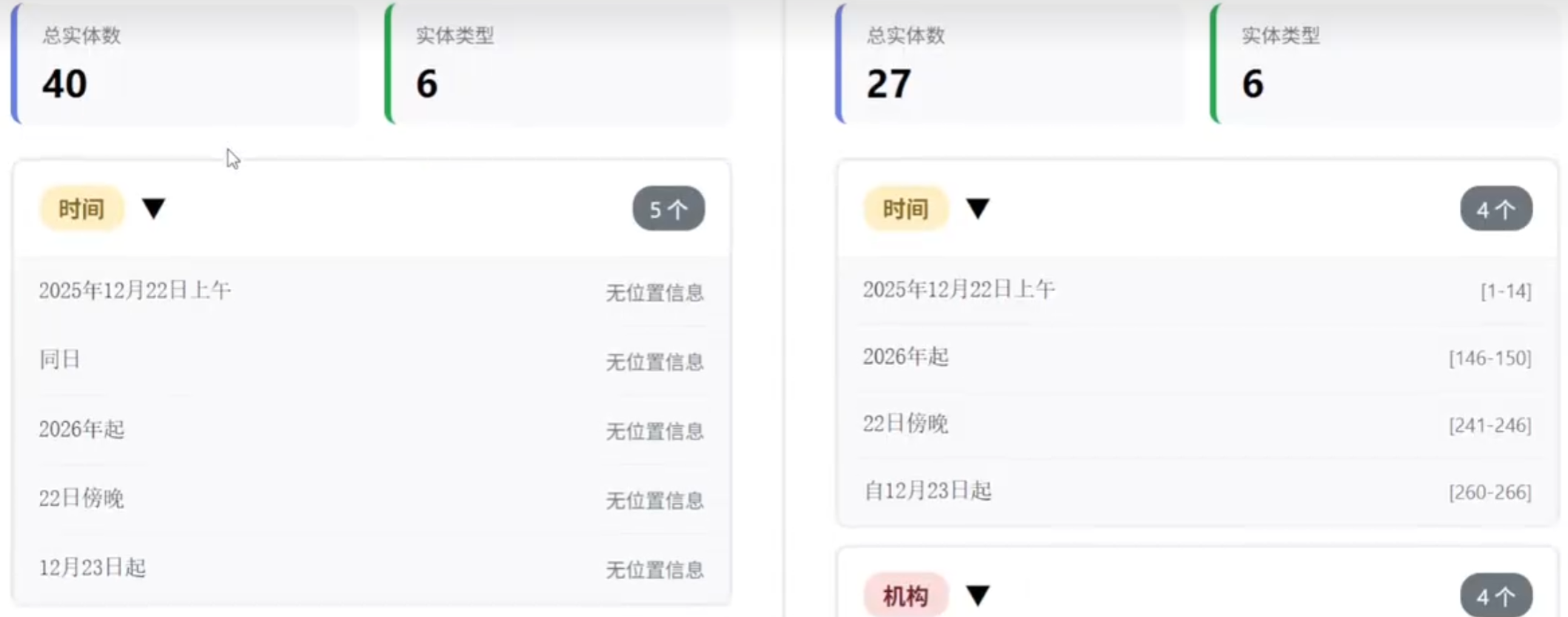
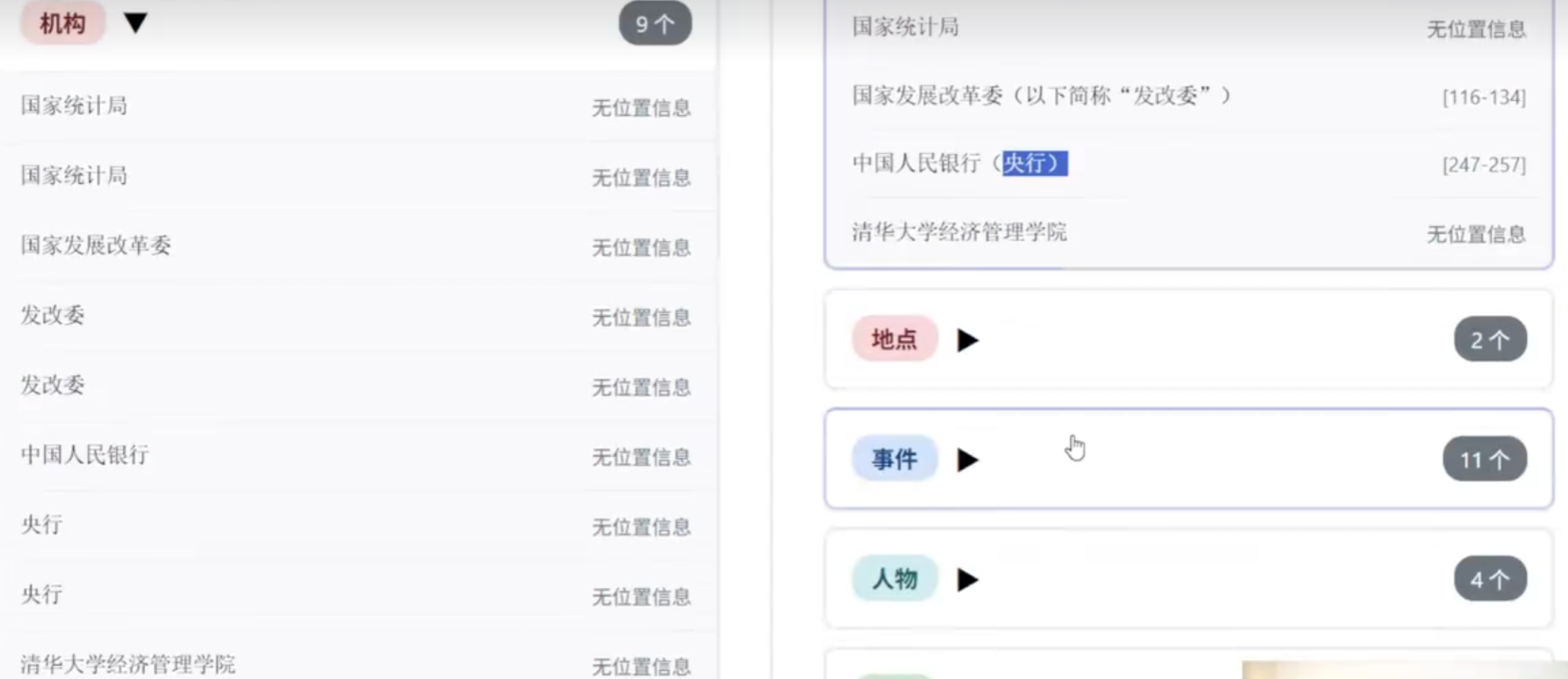
langextract_extractions = result.extractions
total_count_lang = len(langextract_extractions)
type_counts_lang = Counter(ext.extraction_class for ext in langextract_extractions)
# 统计有位置信息的实体数
with_position = sum(1 for ext in langextract_extractions if ext.char_interval is not None)
print(f"LangExtract 统计:")
print(f" 总实体数: {total_count_lang}")
print(f" 按类型分布:")
for entity_type, count in sorted(type_counts_lang.items()):
print(f" - {entity_type}: {count} 个")
# --- 以下是根据图片补充的可视化功能代码 ---
# 1. 保存并导出结果
# 注意:save_annotated_documents 需要接收一个列表,所以这里把 result 放入列表 [result] 中
# 你可以修改 output_name 为你想要的文件名
lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl", output_dir=".")
# 2. 生成交互式可视化内容
# 读取刚才保存的 jsonl 文件来生成可视化对象
html_content = lx.visualize("extraction_results.jsonl")
# 3. 将可视化内容写入 HTML 文件
# 你可以将 "extraction_visualization.html" 修改为你想要的文件名
with open("extraction_visualization.html", "w", encoding="utf-8") as f:
# 兼容性处理:判断是在 Jupyter/Colab 环境还是普通 Python 脚本环境中
if hasattr(html_content, 'data'):
f.write(html_content.data) # For Jupyter/Colab
else:
f.write(html_content)
print("Interactive visualization saved to extraction_visualization.html")也可以制作出html页面展示,知识抽取的过程