
本节会对一个pdf文件进行读取,将文档分割为分本段(chunk) , 对chunk 进行向量化后存入到向量库中。
1.读取pdf文件
准备一个pdf文件,放入 chapter03文件夹。
因为要读取pdf文件,所以要读取pdf文件的依赖包:
shell
pip install langchain_community pypdf会用到 langchain_community 包中的类来读取pdf,底层依赖 pypdf 库
python
from langchain_community.document_loaders import PyPDFLoader
def loadPdf(file_path: str):
"""
加载 PDF 文件
:param file_path: PDF 文件路径
:return: 加载后的 PDF 文档
"""
loader=PyPDFLoader(file_path)
# 加载 PDF 文件, 返回一个 Document 数组, 每个元素对应 PDF 中的一页
docs=loader.load()
print(f"加载了{str(file_path)}, 共 {len(docs)} 页, 列表元素类型:{type(docs[0])}")
# 打印第一页元信息
print(docs[0].metadata)
# 第一页内容
# print(docs[0].page_content)
return docs
if __name__ == '__main__':
loadPdf("mypdf.pdf")输出:
latex
加载了mypdf.pdf, 共 9 页, 列表元素类型:<class 'langchain_core.documents.base.Document'>
{'producer': 'Microsoft® Word 2019', 'creator': 'Microsoft® Word 2019', 'creationdate': '2023-05-06T22:46:33+08:00', 'author': 'Chen Yang', 'moddate': '2023-05-06T22:46:33+08:00', 'source': 'mypdf.pdf', 'total_pages': 9, 'page': 0, 'page_label': '1'}2.将文本分割为chunk
将pdf每一页加载后,再将其内容分割为文本段:
python
from langchain_text_splitters import RecursiveCharacterTextSplitter
def splitDocs(docs):
"""
将 Document 数组拆分为多个 Document 数组
:param docs: Document 数组
:return: 拆分后的 Document 数组
"""
text_splitter=RecursiveCharacterTextSplitter(chunk_size=1000,
separators=["\n\n", "\n", ".", " ", ""],
chunk_overlap=128)
# 一个List[Document], 每个元素是一个文档块
all_splits=text_splitter.split_documents(docs)
print(f"拆分后的文档数量:{len(all_splits)}")
return all_splits
if __name__ == '__main__':
docs=loadPdf("mypdf.pdf")
splitDocs(docs)输出:
latex
拆分后的文档数量:93.将文本向量化
文本向量化需要一个 embedding模型,这里使用百炼平台上的Embedding模型
如果本地机器性能可以,也可以使用本地 embedding模型
登录百炼平台:
模型服务(在顶部左上角)->全部模型->模态类型 -> 向量 -> 文本向量->通义千问-Embedding
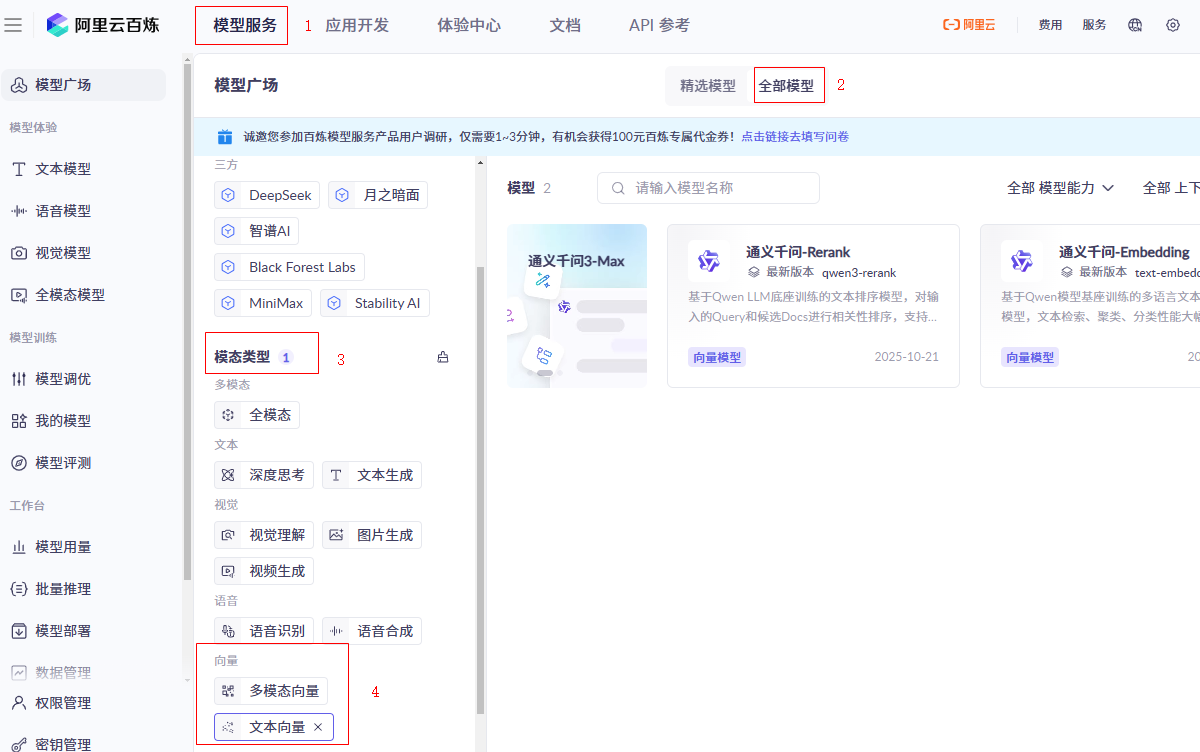
参考文档: https://help.aliyun.com/zh/model-studio/use-bailian-in-langchain#2d28bf78a17ww
langchain_community.embeddings包中已经封装了百炼平台embeddings模型,可以直接使用
导入包:
python
pip install langchain-community dashscope向量化文档:
python
def embedding_docs(docs):
"""
将 Document 数组转换为向量数组
:param docs: Document 数组
:return: 向量数组
"""
embeddings=DashScopeEmbeddings(
model="text-embedding-v4",
dashscope_api_key=os.getenv("AI_BAI_LIAN_API_KEY"),
)
# 一个List[Vector], 每个元素是一个文档块的向量表示
all_embeddings=embeddings.embed_documents([doc.page_content for doc in docs])
print(f"文档向量数量:{len(all_embeddings)} "+
f"类型:{type(all_embeddings[0])}, "+
f"每个向量维度:{len(all_embeddings[0])}")
return all_embeddings
if __name__ == '__main__':
# 加载环境变量
load_dotenv(dotenv_path="../.env")
# 加载 PDF 文件
docs=loadPdf("mypdf.pdf")
# 拆分文档
split_docs=splitDocs(docs)
# 向量化文档
embedding_docs(split_docs)输出:
latex
文档向量数量:9 类型:<class 'list'>, 每个向量维度:1024
第一个文档向量前10个元素:[-0.005699451547116041, -0.017936402931809425, 0.025555020198225975, -0.04695970565080643, -0.04234500229358673, 0.0006779662799090147, 0.03114200569689274, 0.10610920190811157, -0.01998254470527172, 0.06884327530860901]4.将向量保存到向量数据库中
向量数据库这里使用 Chroma 数据库,常用的向量数据库有:
| 数据库 | 类型 | 核心特点 |
|---|---|---|
| Milvus | 开源 + 云 | 功能全面、支持多种索引和分布式部署,适合大规模生产环境。 |
| Pinecone | 商业 SaaS | 全托管、API 简单易用,适合快速开发,但不开源、需联网。 |
| Weaviate | 开源 + 企业版 | 内置语义搜索与知识图谱能力,支持 GraphQL,上手容易。 |
| Qdrant | 开源 + 云 | 性能优秀、支持过滤和集群,Rust 编写,部署简单。 |
| Chroma | 开源 | 轻量级,专为 LLM 应用设计,与 LangChain 深度集成,适合原型或小项目。 |
| FAISS | 开源库(非数据库) | Meta 出品,高效向量检索,但无持久化或服务功能,常用于研究或嵌入其他系统。 |
| Vespa | 开源 | Yahoo 出品,支持实时搜索、排序和向量混合查询,适合复杂业务逻辑。 |
| Redis(带向量模块) | 开源 + 商业 | 在 Redis 中添加向量搜索能力,适合已有 Redis 架构、要求低延迟的场景。 |
Chroma 是一款开源的向量数据库,专为高效存储和检索高维向量数据设计。其核心能力在于语义相似性搜索,支持文本、图像等嵌入向量的快速匹配,广泛应用于大模型上下文增强(RAG)、推荐系统、多模态检索等场景。与传统数据库不同,Chroma 基于向量距离(如余弦相似度、欧氏距离)衡量数据关联性,而非关键词匹配。
安装依赖包:
shell
pip install chromadbChroma 有内存运行模式,参考文档 :https://docs.trychroma.com/docs/run-chroma/ephemeral-client ,持久化运行模式,参考文档: https://docs.trychroma.com/docs/run-chroma/persistent-client
python
def get_chroma_collection(collection_name="my_collection"):
"""
创建 Chroma 集合
:param embeddings: 向量数组
:param collection_name: 集合名称
:return: Chroma 集合
"""
# 数据保存至本地目录
client = chromadb.PersistentClient(path="./chroma")
# 如果集合不存在,则创建
collection = client.get_or_create_collection(name=collection_name)
return collection
if __name__ == '__main__':
# 加载环境变量
load_dotenv(dotenv_path="../.env")
# 加载 PDF 文件
docs=loadPdf("mypdf.pdf")
# 拆分文档
split_docs=splitDocs(docs)
# 向量化文档
all_embeddings=embedding_docs(split_docs)
# 获取Chroma 集合
collection=get_chroma_collection()
# 生成集合ID列表,ID必须是唯一的
ids=[f"id_{i}" for i in range(len(all_embeddings))]
# 向集合中添加向量
collection.add(
ids=ids,
documents=[doc.page_content for doc in split_docs],
embeddings=all_embeddings,
metadatas=[doc.metadata for doc in split_docs])
print(f"向集合中添加了{collection.count()}个向量")程序执行后,生成了 chroma向量数据库,保存到了磁盘上:
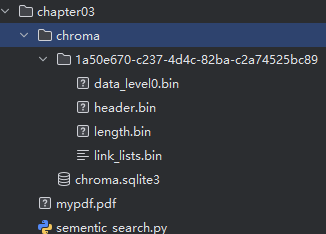
5.相似度查询
现在数据已经被向量化到数据库中了,此时就可以对它进行检索了.
前面保存向量化模型使用的是 百炼平台的 embedding model, 那么查询的时候,对于问题依然要使用这个嵌入模型,所以这里封装一个查询的函数:
python
def embedding_query(collection, query_texts):
"""
向 Chroma 集合查询向量
:param collection: Chroma 集合
:param query_texts: 查询文本数组
:return: 查询结果
"""
embeddings = DashScopeEmbeddings(
model="text-embedding-v4",
dashscope_api_key=os.getenv("AI_BAI_LIAN_API_KEY"),
)
# 将问题进行向量化
query_embeddings=embeddings.embed_documents(query_texts)
query_result=collection.query(
query_embeddings=query_embeddings,
n_results=2)
return query_result
if __name__ == '__main__':
# 加载环境变量
load_dotenv(dotenv_path="../.env")
# 加载 PDF 文件
docs=loadPdf("mypdf.pdf")
# 拆分文档
split_docs=splitDocs(docs)
# 向量化文档
all_embeddings=embedding_docs(split_docs)
# 获取Chroma 集合
collection=get_chroma_collection()
# 生成集合ID列表,ID必须是唯一的
ids=[f"id_{i}" for i in range(len(all_embeddings))]
# 向集合中添加向量
collection.add(
ids=ids,
documents=[doc.page_content for doc in split_docs],
embeddings=all_embeddings,
metadatas=[doc.metadata for doc in split_docs])
# 相似度查询
query_texts=["客户经理被投诉,投诉一次扣多少分?"]
query_result=embedding_query(collection, query_texts)
print(f"查询结果:{query_result}")6.向量数据库的相关操作
可以看到我们经常要对向量数据库进行操作,所以这里可以将这些操作封装到Python类中。
python
# Chroma向量数据库操作封装为class
class ChromaDBHelper:
def __init__(self, collection_name="my_collection"):
self.collection_name=collection_name
self.client = chromadb.PersistentClient(path="./chroma")
# 如果集合不存在,则创建
self.collection = self.client.get_or_create_collection(name=self.collection_name)
print(f"集合名称:{self.collection_name}, 向量维度:{self.collection.count()},集合中的数量:{self.collection.count()}")
# 向量嵌入模型, 用于将文本转换为向量, 这里使用 DashScope 提供的模型
self.embeddings = DashScopeEmbeddings(
model="text-embedding-v4",
dashscope_api_key=os.getenv("AI_BAI_LIAN_API_KEY"))
def add_embeddings(self, docs: List[Document])->List[str]:
"""
向 Chroma 集合添加向量
:param docs: Document 数组
:return: None
"""
# 一个List, 每个元素是一个文档块的向量表示
all_embeddings=self.embeddings.embed_documents([doc.page_content for doc in docs])
print(f"文档向量数量:{len(all_embeddings)} ")
ids=[f"id_{i}" for i in range(len(all_embeddings))]
self.collection.add(
ids=ids,
documents=[doc.page_content for doc in docs],
embeddings=all_embeddings,
metadatas=[doc.metadata for doc in docs])
return ids
def query(self, query_texts: List[str])->List[str]:
"""
向 Chroma 集合查询向量
:param query_texts: 查询文本数组
:return: 集合中的文档ID
"""
# 将问题进行向量化
query_embeddings=self.embeddings.embed_documents(query_texts)
query_result=self.collection.query(
query_embeddings=query_embeddings,
n_results=4)
return query_result
python
if __name__ == '__main__':
# 加载环境变量
load_dotenv(dotenv_path="../.env")
chromadb_helper=ChromaDBHelper()
query_texts=["客户经理被投诉,投诉一次扣多少分?"]
query_result=chromadb_helper.query(query_texts)
# 打印查询结果, 包含文档ID, 文档内容, 距离
for i, doc in enumerate(query_result["documents"][0]):
print(f"第{i}个查询结果:")
print(f"文档ID:{query_result['ids'][0][i]}, 文档内容:{doc[:20]}, 距离:{query_result['distances'][0][i]}")
print("="*50)输出结果:(文档值输出了前20个字符)
latex
第0个查询结果:
文档ID:id_4, 文档内容:百度文库 - 好好学习,天天向上
-5, 距离:0.4578714370727539
==================================================
第1个查询结果:
文档ID:id_7, 文档内容:百度文库 - 好好学习,天天向上
-8, 距离:0.6115385293960571
==================================================
第2个查询结果:
文档ID:id_3, 文档内容:百度文库 - 好好学习,天天向上
-4, 距离:0.6421006321907043
==================================================
第3个查询结果:
文档ID:id_6, 文档内容:百度文库 - 好好学习,天天向上
-7, 距离:0.7456348538398743
==================================================