Linux 的进程状态设置与前文讨论有所不同,各操作系统在这方面各有特色,但都具备进程状态的基本共性。下面我们一起来看看Linux内核中是怎样规定进程状态的
cpp
/*
* Linux内核中的 task_state_array 定义
*/
static const char * const task_state_array[] = {
"R (running)", /* 0: TASK_RUNNING */
"S (sleeping)", /* 1: TASK_INTERRUPTIBLE */
"D (disk sleep)", /* 2: TASK_UNINTERRUPTIBLE */
"T (stopped)", /* 4: __TASK_STOPPED */
"t (tracing stop)", /* 8: __TASK_TRACED */
"X (dead)", /* 16: EXIT_DEAD */
"Z (zombie)", /* 32: EXIT_ZOMBIE */
"P (parked)", /* 64: TASK_PARKED */
"I (idle)", /* 128: TASK_IDLE */
NULL,
};sleeping(浅度睡眠)running(运行)
接下来我们编译并运行下面的代码
cpp
#include<stdio.h>
int main()
{
while(1)
{
printf("hello world!\n");
}
return 0;
}
打开另一个终端来查看这个进程的状态:
bash
while : ;do ps ajx |head -1;ps ajx | grep myprocess;sleep 1;done通过观察可以发现,./process进程的状态大多显示为S+,很少出现R状态。原因在于:当./myprocess执行时,进程在打印完"hello world"后会立即返回等待队列,等待资源就绪后再次执行打印任务。由于打印操作耗时极短,进程大部分时间都处于等待资源的状态(阻塞队列),只有极短时间处于运行状态,进程一直在运行队列和阻塞队列之间切换。因此我们观察到的进程状态几乎都是S+状态。
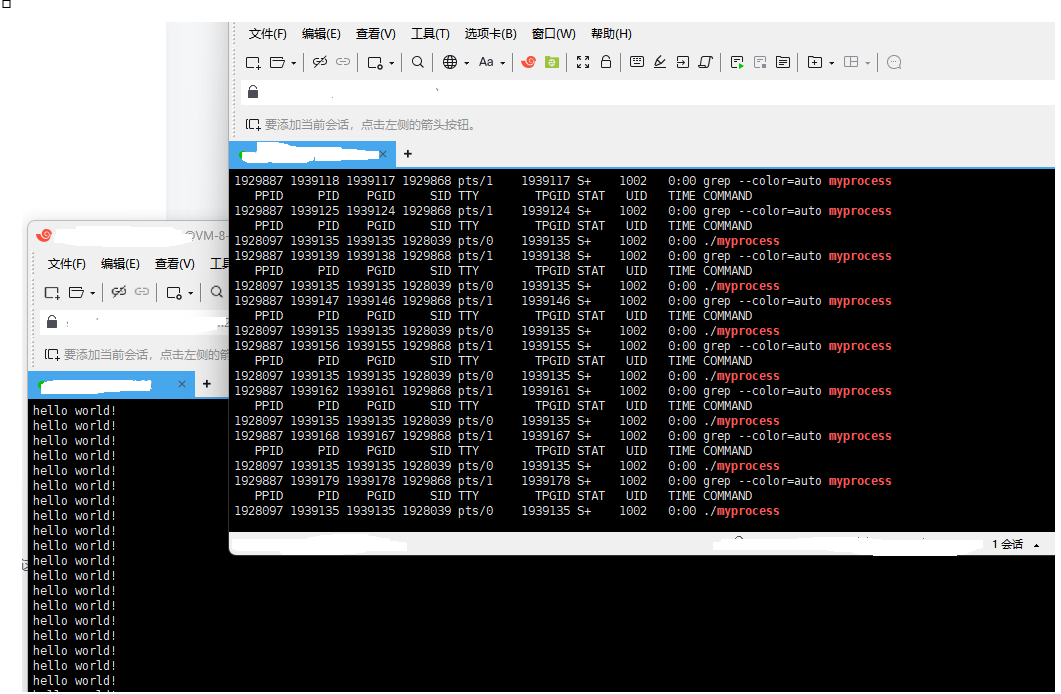
为什么称为S+状态? "S"表示进程处于可中断的睡眠状态(Sleeping),而"+"号标识该进程为前台进程。前台进程可直接通过Ctrl+C快捷键终止,而后台进程则需使用kill命令等特殊方式终止(具体方法将在后续Linux网络章节详细介绍)。
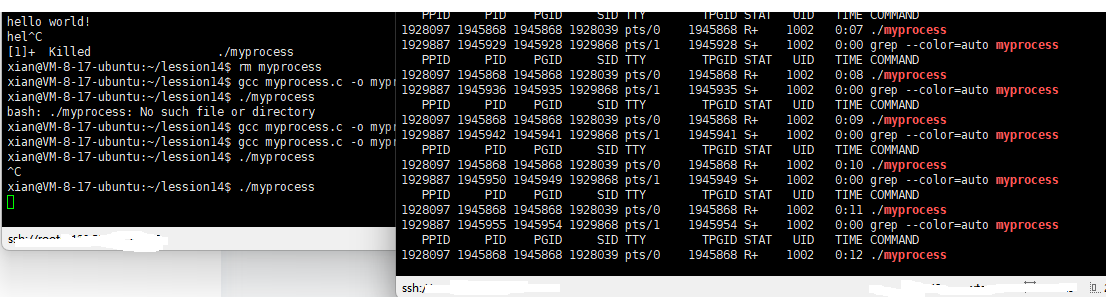
如何让进程保持R状态? 核心在于避免进程执行I/O操作。这样进程就不需要等待资源或终端响应,从而能够持续保持运行状态。 需要注意的是,进程的本质是执行任务,完全不涉及I/O的进程实际上是没有实用价值的。
cpp
#include<stdio.h>
int main()
{
while(1)
{
// printf("hello world!\n");
}
return 0;
}
补充说明
ps 命令只能捕获进程状态的瞬间快照,无法实时监控状态变化。连续执行ps时可能出现以下情况:
时间轴: t0 t1 t2 t3 t4
进程状态: R → S → R → S → R → S → R → S
ps采样点: ↑ ↑ ↑
结果显示: R R R由于进程处于运行状态(R)的时间远长于睡眠状态(S),随机采样的结果几乎总是显示为R状态。
即便是纯粹的CPU死循环程序,在top命令中也不会始终显示为R状态。由于Linux是多任务操作系统,CPU时间会被分配给所有就绪的进程。因此你会观察到该进程在R(运行中)和S(可中断睡眠------实际是由于时间片耗尽被调度器暂时挂起,但状态显示为S)之间快速切换。若系统仅有一个CPU核心且只运行该进程,则其显示R状态的时间比例将接近100%。
理解升华
掌握S和R状态的本质,就是把握进程生命周期的关键------计算与等待。R状态代表进程"执行"的瞬间,而大部分时间进程可能处于S状态等待各类资源(数据、用户输入、锁等)。系统性能优化的核心,正是通过减少不必要的等待,使进程能更高效地从S状态转换回R状态。
暂停
stopped
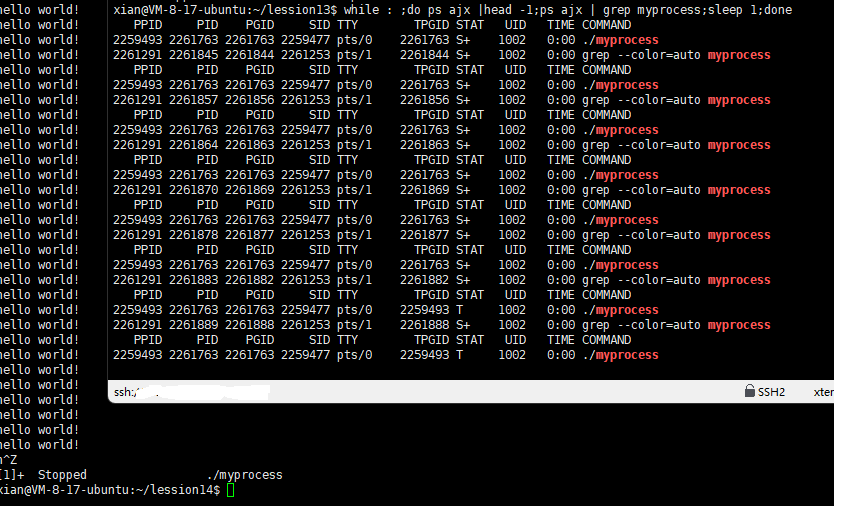
在终端中运行myprocess进程时,它会持续输出"hello world!"。当我们在另一个终端持续监控该进程状态时,如果在第一个终端按下Ctrl+Z,进程状态将变为T(__TASK_STOPPED),即暂停状态。
T状态表示进程因作业控制而暂停,通常由用户主动触发(如使用Ctrl+Z)。这种状态用于临时挂起进程,表明系统检测到进程存在问题,但问题尚不严重到需要终止进程,因此交由用户自行判断处理。
tracing stop
t状态(小写)表示进程被调试器暂停,通常是调试工具(如GDB)在断点处停止执行。这种状态属于调试过程中的正常现象,并不意味着进程出现异常。
disk sleep
S状态被称为浅度睡眠或可中断睡眠。为什么这么称呼呢?因为S状态可以通过Ctrl+C组合键中断。相比之下,D状态(深度睡眠)则无法通过Ctrl+C中断。这种设计意味着系统赋予了D状态进程更高的优先级,表明这些进程正在等待的关键资源必须得到保障,不能丢失。想象一下,如果这个进程被意外终止,而它正在处理的是你刚花600块购买的游戏皮肤数据,那这笔钱不就白白浪费了吗?因此,系统必须确保这些重要进程在等待资源时不会被意外终止。
Linux将阻塞状态分为D和S两种,它们本质上都属于等待资源的状态。系统根据所等待资源的重要性,将阻塞状态细分为D(不可中断)和S(可中断)两种类型。
一个进程一旦被设置为D状态,系统无法将它杀掉,只有等待到了资源或者重启计算机,才能杀掉进程。
dead
结束状态是指一个进程已经完成执行或被强制终止后所处的状态。
zombie
目前我们接触的进程都是其他进程的子进程。当进程退出时,并非所有资源都能立即释放:虽然代码和数据可以被释放,但进程控制块(PCB)(退出信息保存在PCB中)需要保留。创建子进程的主要目的是让它们完成父进程分配的任务。当子进程终止时,必须等待父进程回收资源,并向父进程报告任务执行情况。这也是为什么main函数通常返回0------表示程序正常执行完毕并退出。当子进程退出之后,父进程回收它之前,进程一直处于Z(僵尸状态)。
cpp
#include<stdio.h>
#include<unistd.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
//chlid
int count =5;
while(count--)
{
printf("我是子进程我正在运行%d\n",count);
sleep(1);
}
}
else
{
while(1)
{
printf("我是一个父进程\n");
sleep(1);
}
}
return 0;
}当count减为0时,子进程退出,父进程未回收,为Z僵尸状态。
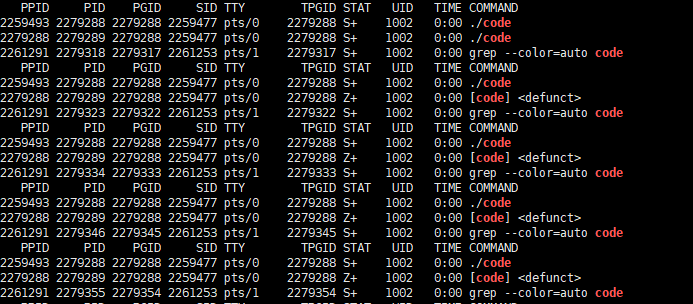
如果父进程未能回收子进程,子进程的进程控制块(PCB)将一直驻留内存,导致资源泄漏。
需要注意的是,当进程正常退出时,系统会自动释放其通过new或malloc分配的内存空间,因此内存泄漏问题会随之消失。但对于长期运行的常驻进程而言,内存泄漏问题会造成持续性的负面影响。
unuse列表
当进程退出时,操作系统通常会采用一种优化策略来管理进程控制块(PCB)的回收和重用。具体实现方式如下:
进程终止处理流程:
首先操作系统会保存进程的退出状态码
然后断开进程与所有资源的关联
将进程从调度队列中移除
但不会立即释放PCB占用的内存
PCB回收机制:
系统维护一个unuse列表(空闲PCB链表)
退出的进程PCB会被标记为"僵尸状态"
将该PCB从活动进程表中移除
将PCB插入unuse列表的头部或尾部
重用优化:
当创建新进程时,系统首先检查unuse列表
如果列表不为空,则直接复用已有的PCB
只需重置PCB中的关键字段即可
这避免了频繁的内存分配/释放操作
实现示例(Linux内核):
使用slab分配器管理PCB内存
task_struct结构体被放入专用缓存
退出进程的task_struct会被放回freelist
新进程优先从freelist获取内存块
这种设计的好处
减少内存分配的系统开销
提高进程创建速度
避免内存碎片问题
保持内核内存管理的稳定性
系统会定期检查unuse列表的长度,当空闲PCB数量超过阈值时,才会真正释放部分内存。这种延迟释放策略在大多数操作系统中都有应用。
孤儿进程
cpp
#include<stdio.h>
#include<unistd.h>
int main()
{
pid_t id = fork();
if (id == 0)
{
//chlid
while (1)
{
printf("我是一个子进程%d %d\n",getpid(),getppid());
sleep(1);
}
}
else
{
int count = 5;
while (count--)
{
printf("我是一个父进程%d %d\n", getpid(), getppid());
sleep(1);
}
}
return 0;
}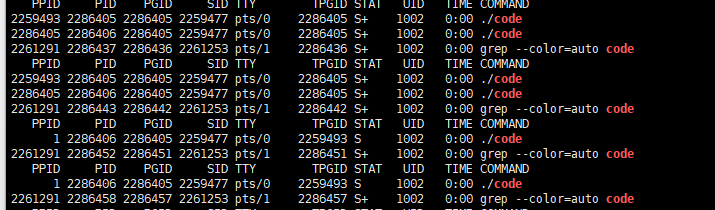
我们可以看到2286405是父进程,父进程退出后,子进程被1号进程领养了,这个时候进程被称为孤儿进程。如果不领养,进程的PCB得不到处理,会造成内存泄漏。
1号进程

cpp
ps axj | head -1 && ps axj | grep systemd
当我们登录Linux系统时,系统会通过一个复杂的初始化过程最终为我们创建交互式shell环境。具体来说:
- 系统启动后,首先运行的进程是PID为1的init进程(在现代系统中是systemd)
- init进程会读取/etc/inittab配置文件(对于systemd则是读取对应的服务单元)
- 根据配置启动getty或类似程序,在终端上显示登录提示
- 当我们输入用户名和密码后,getty会调用login程序验证凭证
- 验证成功后,login程序会:
- 读取/etc/passwd获取用户默认shell(通常是/bin/bash)
- 设置用户环境变量(读取/etc/profile和用户目录下的.profile等文件)
- 根据/etc/login.defs设置用户进程限制
- 最终,login进程会fork并exec用户指定的shell程序(如bash)
- 这个新创建的bash进程会:
- 继承父进程的环境变量
- 执行/etc/bash.bashrc和~/.bashrc中的命令
- 显示命令提示符,等待用户输入
整个过程确保了用户获得一个配置完善、安全隔离的工作环境。虽然1号进程是这一切的源头,但实际的bash创建过程是通过多级进程派生完成的。