基于Python+Django豆瓣图书数据可视化分析推荐系统 毕业论文
毕业设计
一、项目名称:
基于Python+Django豆瓣图书数据可视化分析推荐系统
【摘要】
随着互联网时代图书信息的爆炸式增长,读者面临着海量图书选择困难和信息筛选成本高的问题。本系统以豆瓣图书平台为数据来源,采用Python+Django框架构建了一套集数据爬取、多维度可视化分析、情感分析和智能推荐于一体的综合性图书数据分析平台。系统通过自主研发的爬虫模块实现了对豆瓣图书及评论数据的自动化采集,支持批量爬取和单本爬取两种模式,并配备了实时进度监控功能。在数据分析层面,系统实现了图书分类分布、作者影响力、评分趋势、价格区间、出版时间等8个维度的可视化分析,采用ECharts图表库呈现包括饼图、柱状图、折线图、词云图等多种可视化形式。核心技术方面,系统集成了基于Jieba分词和词典匹配的中文情感分析算法,能够自动识别评论的积极、消极和中性倾向,准确率达到85%以上;开发了基于协同过滤和内容特征融合的混合推荐算法,根据用户收藏行为提供个性化图书推荐服务。系统采用Django MVT架构设计,前端使用Bootstrap和ECharts实现响应式界面,后端通过异步任务处理保证大规模数据爬取的稳定性,数据库设计了User、Book、Comment、BookFavorite四个核心数据表并建立了合理的关联关系。本系统为读者提供了全方位的图书信息获取和决策支持工具,具有良好的实用价值和推广前景。
【关键词】 豆瓣图书 数据可视化 情感分析 推荐系统 Django框架
【Abstract】
With the explosive growth of book information in the Internet era, readers face difficulties in massive book selection and high information screening costs. This system uses the Douban Book platform as the data source and builds a comprehensive book data analysis platform integrating data crawling, multi-dimensional visual analysis, sentiment analysis and intelligent recommendation based on Python+Django framework. The system realizes the automated collection of Douban book and comment data through a self-developed crawler module, supporting both batch crawling and single book crawling modes, with real-time progress monitoring. In terms of data analysis, the system implements visual analysis in 8 dimensions including book category distribution, author influence, rating trends, price ranges, and publication time, using the ECharts chart library to present various visualization forms including pie charts, bar charts, line charts, and word clouds. In terms of core technology, the system integrates a Chinese sentiment analysis algorithm based on Jieba word segmentation and dictionary matching, which can automatically identify positive, negative and neutral tendencies of comments with an accuracy rate of over 85%; it develops a hybrid recommendation algorithm based on collaborative filtering and content feature fusion, providing personalized book recommendation services based on user collection behavior. The system adopts Django MVT architecture design, the front-end uses Bootstrap and ECharts to implement responsive interface, the back-end ensures the stability of large-scale data crawling through asynchronous task processing, and the database designs four core data tables: User, Book, Comment, BookFavorite with reasonable association relationships. This system provides readers with comprehensive book information acquisition and decision support tools, with good practical value and promotion prospects.
【Keywords】 Douban Books, Data Visualization, Sentiment Analysis, Recommendation System, Django Framework
目 录
[1 绪 论](#1 绪 论)
- [1.1 课题研究背景](#1.1 课题研究背景)
- [1.2 课题研究的目的、意义](#1.2 课题研究的目的、意义)
- [1.2.1 研究目的](#1.2.1 研究目的)
- [1.2.2 研究意义](#1.2.2 研究意义)
- [1.3 课题的国内外研究现状和发展动态](#1.3 课题的国内外研究现状和发展动态)
- [1.3.1 国外研究现状](#1.3.1 国外研究现状)
- [1.3.2 国内研究现状](#1.3.2 国内研究现状)
- [1.3.3 发展趋势](#1.3.3 发展趋势)
- [1.4 研究内容](#1.4 研究内容)
- [1.5 论文结构安排](#1.5 论文结构安排)
[2 关键技术](#2 关键技术)
- [2.1 Django Web框架](#2.1 Django Web框架)
- [2.1.1 MTV架构模式](#2.1.1 MTV架构模式)
- [2.1.2 ORM数据库操作](#2.1.2 ORM数据库操作)
- [2.2 网络爬虫技术](#2.2 网络爬虫技术)
- [2.2.1 Requests请求处理](#2.2.1 Requests请求处理)
- [2.2.2 lxml页面解析](#2.2.2 lxml页面解析)
- [2.3 中文情感分析技术](#2.3 中文情感分析技术)
- [2.3.1 Jieba分词算法](#2.3.1 Jieba分词算法)
- [2.3.2 情感词典匹配](#2.3.2 情感词典匹配)
- [2.4 数据可视化技术](#2.4 数据可视化技术)
- [2.4.1 ECharts图表库](#2.4.1 ECharts图表库)
- [2.4.2 WordCloud词云生成](#2.4.2 WordCloud词云生成)
- [2.5 推荐算法](#2.5 推荐算法)
- [2.5.1 协同过滤算法](#2.5.1 协同过滤算法)
- [2.5.2 内容特征匹配](#2.5.2 内容特征匹配)
- [2.6 技术特色与创新点](#2.6 技术特色与创新点)
[3 系统分析与设计](#3 系统分析与设计)
- [3.1 系统总体设计](#3.1 系统总体设计)
- [3.1.1 系统架构设计](#3.1.1 系统架构设计)
- [3.1.2 系统数据流设计](#3.1.2 系统数据流设计)
- [3.1.3 系统功能模块设计](#3.1.3 系统功能模块设计)
- [3.2 系统详细设计](#3.2 系统详细设计)
- [3.2.1 用户认证模块设计](#3.2.1 用户认证模块设计)
- [3.2.2 数据爬取模块设计](#3.2.2 数据爬取模块设计)
- [3.2.3 数据分析模块设计](#3.2.3 数据分析模块设计)
- [3.2.4 情感分析模块设计](#3.2.4 情感分析模块设计)
- [3.2.5 推荐系统模块设计](#3.2.5 推荐系统模块设计)
- [3.2.6 数据可视化模块设计](#3.2.6 数据可视化模块设计)
- [3.3 数据库设计](#3.3 数据库设计)
- [3.3.1 数据库关系设计](#3.3.1 数据库关系设计)
[4 系统实现](#4 系统实现)
- [4.0 系统整体实现流程](#4.0 系统整体实现流程)
- [4.1 用户认证模块的实现](#4.1 用户认证模块的实现)
- [4.2 数据爬取模块的实现](#4.2 数据爬取模块的实现)
- [4.3 数据分析模块的实现](#4.3 数据分析模块的实现)
- [4.4 情感分析模块的实现](#4.4 情感分析模块的实现)
- [4.5 推荐系统模块的实现](#4.5 推荐系统模块的实现)
- [4.6 数据可视化模块的实现](#4.6 数据可视化模块的实现)
- [4.7 用户界面实现](#4.7 用户界面实现)
- [4.8 系统集成与部署](#4.8 系统集成与部署)
[5 系统测试](#5 系统测试)
- [5.1 系统功能测试](#5.1 系统功能测试)
- [5.1.1 用户认证功能测试用例](#5.1.1 用户认证功能测试用例)
- [5.1.2 数据爬取功能测试用例](#5.1.2 数据爬取功能测试用例)
- [5.1.3 数据分析功能测试用例](#5.1.3 数据分析功能测试用例)
- [5.1.4 情感分析功能测试用例](#5.1.4 情感分析功能测试用例)
- [5.1.5 推荐系统功能测试用例](#5.1.5 推荐系统功能测试用例)
- [5.1.6 可视化展示功能测试用例](#5.1.6 可视化展示功能测试用例)
- [5.2 系统性能测试](#5.2 系统性能测试)
- [5.2.1 响应时间性能分析](#5.2.1 响应时间性能分析)
- [5.2.2 并发性能测试](#5.2.2 并发性能测试)
- [5.2.3 数据库性能测试](#5.2.3 数据库性能测试)
- [5.2.4 性能优化措施](#5.2.4 性能优化措施)
[6 总结与展望](#6 总结与展望)
- [6.1 总结](#6.1 总结)
- [6.2 展望](#6.2 展望)
1 绪 论
1.1 课题研究背景
进入21世纪以来,随着互联网技术的迅猛发展和电子商务的普及,图书行业经历了从线下到线上的深刻变革。豆瓣作为国内最具影响力的图书评价和推荐平台之一,积累了海量的图书信息和用户评论数据,这些数据蕴含着丰富的用户阅读偏好和图书质量信息。然而,面对数以百万计的图书资源和数千万条用户评论,读者在选择图书时往往陷入"信息过载"的困境,难以快速准确地找到符合自己需求的优质读物。传统的图书检索和推荐方式主要依赖于关键词搜索和简单的评分排序,无法深入挖掘数据背后的规律和关联,也难以满足用户个性化、多维度的信息需求。在此背景下,如何有效地采集、分析和可视化呈现图书数据,如何从海量评论中提取用户情感倾向,如何基于用户行为提供精准的个性化推荐,成为图书信息服务领域亟待解决的关键问题。本课题正是在这样的现实需求驱动下,结合数据爬取、数据分析、情感识别和推荐算法等多种技术手段,构建了一套面向读者的智能化图书数据分析和推荐系统,旨在帮助用户更高效地获取图书信息、理解图书特征、发现优质作品,并根据个人偏好获得定制化的阅读建议。
1.2 课题研究的目的、意义
1.2.1 研究目的
本课题研究的主要目的是设计并实现一套功能完整、技术先进的豆瓣图书数据可视化分析推荐系统。具体包括以下四个方面:第一,实现对豆瓣图书平台数据的自动化采集功能,通过自主开发的爬虫模块支持批量爬取和单本爬取两种模式,能够获取图书的基本信息(书名、作者、出版社、ISBN、评分等)以及用户评论数据(评论内容、评分、点赞数、评论时间等),并配备实时进度监控机制保障数据采集的稳定性和可控性。第二,构建多维度的数据分析和可视化展示体系,涵盖图书分类分布、作者影响力分析、评分趋势分析、价格区间分析、出版时间趋势、关键词词云等8个核心分析维度,采用饼图、柱状图、折线图、散点图、词云图等多种图表形式进行直观呈现,帮助用户从宏观和微观层面理解图书市场的现状和特征。第三,开发基于中文自然语言处理的情感分析模块,利用Jieba分词技术和情感词典匹配方法,对海量评论文本进行自动化的情感倾向识别和量化评分,将主观的文字描述转化为客观的情感指标,为用户判断图书质量提供辅助依据。第四,设计并实现混合推荐算法,融合协同过滤和基于内容的推荐策略,根据用户的收藏行为和图书的特征属性生成个性化推荐列表,提升用户发现优质图书的效率和阅读体验的满意度。
1.2.2 研究意义
本课题的研究具有重要的理论意义和实践价值。从理论层面来看,本系统综合运用了Web开发、数据爬取、数据挖掘、自然语言处理和推荐算法等多个领域的技术理论,构建了一套完整的数据驱动型应用系统架构,为类似的数据分析和推荐系统开发提供了可借鉴的设计思路和实现方案。特别是在中文图书评论的情感分析方面,通过构建领域相关的情感词典和优化权重分配策略,提升了算法在实际场景中的适用性和准确性。从实践应用角度来看,本系统为广大读者提供了一个功能丰富、操作便捷的图书信息获取和决策支持平台,用户可以通过多维度的数据可视化快速了解图书市场的整体状况和细分特征,通过情感分析功能辅助判断图书的口碑和质量,通过个性化推荐功能发现符合自身兴趣的优质图书,有效降低了信息筛选成本,提升了图书选择的科学性和效率。对于出版机构和图书电商平台而言,本系统展示的数据分析方法和可视化呈现方式也具有一定的参考价值,可以帮助其更好地理解市场趋势、优化图书营销策略、提升用户服务质量。此外,本系统采用的模块化设计和开放式架构也为后续功能扩展和技术升级预留了空间,具备良好的可持续发展潜力。
1.3 课题的国内外研究现状和发展动态
1.3.1 国外研究现状
在国外,图书推荐和数据分析领域的研究起步较早且技术相对成熟。亚马逊作为全球最大的在线图书零售平台,其推荐系统采用了基于协同过滤的个性化推荐算法,通过分析用户的浏览历史、购买记录和评分数据,为每位用户生成定制化的图书推荐列表,该系统的推荐转化率显著高于传统搜索方式。Goodreads作为专业的图书社交平台,建立了庞大的用户评论数据库,并开发了基于社交关系和阅读兴趣的推荐机制,用户可以关注好友的阅读动态并获取基于社交网络的图书推荐。在学术研究方面,基于深度学习的文本情感分析技术得到广泛应用,研究者利用LSTM、BERT等神经网络模型对书评文本进行深层次的语义理解和情感分类,准确率达到90%以上。此外,知识图谱技术也被引入图书推荐领域,通过构建作者、出版社、主题、流派等实体之间的关联关系,实现更加精准的语义化推荐。在数据可视化方面,Tableau、D3.js等工具和框架被广泛用于图书市场数据的交互式可视化展示,支持用户通过拖拽、筛选等操作进行多维度的数据探索。
1.3.2 国内研究现状
国内在图书推荐和数据分析领域也取得了显著进展。豆瓣读书作为国内最具影响力的图书评价平台,积累了海量的用户评分和书评数据,其推荐算法结合了协同过滤、基于内容的推荐和热门排行等多种策略。当当网、京东图书等电商平台也相继开发了各自的图书推荐系统,利用用户的购买记录和浏览行为进行个性化推荐。在学术研究方面,国内高校和科研机构在中文文本情感分析、图书推荐算法优化等方向开展了大量研究工作。例如,清华大学的研究团队开发了基于情感词典和机器学习相结合的中文书评情感分析方法,针对中文表达的特点进行了词典扩充和权重优化。北京大学的研究者提出了融合用户显性评分和隐性行为的混合推荐算法,提升了推荐结果的准确性和多样性。在数据爬取方面,Scrapy、BeautifulSoup等Python爬虫框架被广泛应用于图书数据的自动化采集。然而,现有的研究和应用系统在功能整合性、用户体验和算法创新性方面仍存在提升空间,特别是在将数据爬取、多维度分析、情感识别和个性化推荐有机融合为一体的综合性系统开发方面,国内相关成果相对较少。
1.3.3 发展趋势
图书推荐和数据分析领域的未来发展呈现出以下几个显著趋势。第一,人工智能技术的深度应用,特别是大语言模型和生成式AI在文本理解和推荐解释性方面的应用,将使系统能够更准确地理解用户意图,生成更具说服力的推荐理由。第二,多模态数据融合成为重要方向,除了文本评论,系统将整合图书封面、目录、试读章节等多种数据源,提供更加全面的图书评价和推荐依据。第三,实时性和动态性不断增强,系统能够实时捕捉图书市场的热点变化和用户兴趣的演进,提供及时更新的分析报告和推荐结果。第四,社交化推荐和知识图谱技术的结合将更加紧密,通过构建用户、图书、作者、主题等实体的复杂关联网络,实现基于社交关系和知识关联的深层次推荐。第五,隐私保护和数据安全受到越来越多的关注,推荐系统在提供个性化服务的同时需要确保用户数据的安全性和合规性。第六,跨平台和跨语言的数据整合与分析能力将进一步提升,系统将能够整合来自不同平台和语言的图书数据,为用户提供更加丰富和多元的信息服务。
1.4 研究内容
本课题的主要研究内容包括以下六个核心模块。第一,用户认证与权限管理模块,实现用户注册、登录、个人信息管理等基础功能,采用Session会话机制保持用户登录状态,通过自定义中间件实现统一的权限验证。第二,豆瓣数据爬取模块,开发基于Requests和lxml的网络爬虫系统,支持批量爬取指定分类的图书列表、单本图书详细信息和用户评论数据,配备实时进度监控和异常处理机制,采用随机延时和请求头轮换策略降低被反爬的风险。第三,多维度数据分析模块,构建包括图书分类统计、作者作品数量和评分分析、图书评分分布、价格区间统计、出版时间趋势、关键词提取等分析维度的算法体系,采用Pandas进行数据处理和统计计算。第四,中文情感分析模块,基于Jieba分词技术和领域相关情感词典实现评论文本的自动化情感识别,通过权重累加和规则调整计算情感得分,将评论分类为积极、消极和中性三种倾向,并支持批量分析和实时进度反馈。第五,个性化推荐模块,设计融合协同过滤和基于内容特征的混合推荐算法,根据用户的收藏记录分析其阅读偏好,结合图书的分类、作者、评分等属性计算相似度,生成个性化的图书推荐列表。第六,数据可视化展示模块,采用ECharts图表库和WordCloud词云库,将分析结果以饼图、柱状图、折线图、散点图、词云图等多种形式进行可视化呈现,支持交互式图表操作和动态数据更新。
1.5 论文结构安排
本论文共分为六章,各章节的主要内容安排如下。第一章为绪论部分,阐述课题的研究背景、目的和意义,综述国内外研究现状和发展趋势,明确研究内容和论文结构。第二章介绍系统开发所涉及的关键技术,包括Django Web框架的MTV架构和ORM机制、网络爬虫技术的请求处理和页面解析方法、中文情感分析的分词算法和情感识别策略、数据可视化的图表库应用、推荐算法的协同过滤和内容匹配原理,并总结本系统的技术特色与创新点。第三章进行系统分析与设计,从总体架构、功能模块、数据流程三个层面设计系统整体方案,详细阐述用户认证、数据爬取、数据分析、情感识别、推荐系统、数据可视化六大核心模块的设计思路和实现方案,并完成数据库的概念设计和逻辑设计,建立User、Book、Comment、BookFavorite四个核心数据表及其关联关系。第四章描述系统的具体实现过程,首先给出系统整体实现流程,然后分别介绍各功能模块的核心代码实现、关键技术应用和功能效果展示,涵盖用户认证、数据爬取、数据分析、情感识别、推荐算法、数据可视化、用户界面、系统部署八个方面的实现细节。第五章开展系统测试工作,设计涵盖用户认证、数据爬取、数据分析、情感识别、推荐系统、可视化展示等功能模块的测试用例,验证系统功能的正确性和完整性,并进行响应时间、并发处理、数据库性能等方面的性能测试,总结性能优化措施。第六章进行总结与展望,回顾课题的主要研究工作和取得的成果,提供系统实现的量化数据和技术指标,分析存在的不足之处,并对系统的未来改进方向和应用前景进行展望。
2 关键技术
2.1 Django Web框架
Django是一个高级Python Web框架,由美国堪萨斯州的新闻网站开发团队于2003年创建并于2005年开源发布,经过近20年的发展已成为全球最流行的Python Web开发框架之一。本系统采用Django 3.1.14版本作为核心开发框架,充分利用其成熟稳定的特性和丰富的功能组件。Django遵循"快速开发、代码复用、简洁实用"的设计理念,内置了用户认证、表单处理、模板引擎、ORM数据库操作、中间件机制等常用功能模块,大幅降低了Web应用的开发难度和维护成本。在安全性方面,Django提供了CSRF防护、SQL注入防护、XSS攻击防护等多层安全机制,有效保障系统的数据安全和运行稳定。本系统正是基于Django框架的这些优势特性,实现了快速高效的系统开发和稳定可靠的功能运行。
2.1.1 MTV架构模式
Django采用MTV架构模式进行系统设计,即Model模型层、Template模板层和View视图层三层分离架构,这是对传统MVC模式的改进和优化。在本系统中,Model层负责定义数据结构和实现数据库操作逻辑,系统在app/models.py文件中定义了User用户模型、Book图书模型、Comment评论模型和BookFavorite收藏模型四个核心数据模型,每个模型类继承自django.db.models.Model基类,通过字段定义、约束设置和关联关系声明完成数据库表结构的映射。Template模板层负责页面的视觉呈现和用户交互界面的构建,系统在app/templates和templates目录下组织了16个HTML模板文件,使用Django模板语言实现数据的动态渲染和页面的逻辑控制,通过模板继承机制实现了base.html基础模板的复用,大幅提升了前端开发效率。View视图层作为业务逻辑处理的核心,在app/views.py文件中实现了30个视图函数和API接口,负责接收用户请求、调用模型层进行数据操作、执行业务逻辑处理并返回响应结果。这种三层分离的架构设计实现了数据、逻辑和展示的解耦,使得各层可以独立开发和维护,当需要修改界面样式时只需调整模板文件而无需改动业务逻辑代码,当需要优化算法或增加功能时也不会影响前端页面的展示效果,大大提升了系统的可维护性和可扩展性。
2.1.2 ORM数据库操作
Django的ORM对象关系映射机制为系统提供了强大而优雅的数据库操作能力。ORM将数据库表结构映射为Python类对象,将表中的记录映射为类的实例,通过面向对象的方式进行数据库的增删改查操作,无需编写复杂的SQL语句即可完成数据操作。在本系统的实现中,通过定义Book模型类自动生成book数据表,模型类中的title、author、press等字段自动对应数据表中的列,系统可以通过Book.objects.create()方法创建新的图书记录,通过Book.objects.filter()方法进行条件查询,通过Book.objects.update_or_create()方法实现数据的更新或创建操作。ORM还提供了丰富的查询API,支持过滤筛选、排序、分组、聚合统计等复杂查询操作,例如系统在数据分析模块中使用Book.objects.values('classification').annotate(count=Count('id'))实现按分类统计图书数量,使用Comment.objects.filter(sentiment='positive').count()统计积极评论的数量。更重要的是,ORM提供了数据库无关性的特性,系统的数据操作代码可以无缝适配MySQL、PostgreSQL、SQLite等多种数据库系统,只需修改配置文件中的数据库连接参数即可切换数据库类型,无需改动业务代码。本系统正是充分利用Django ORM的这些特性,实现了高效简洁的数据库操作和灵活可靠的数据管理。
2.2 网络爬虫技术
网络爬虫技术是本系统实现豆瓣图书数据自动化采集的核心技术手段。本系统自主开发了基于Python的网络爬虫模块,采用Requests库进行HTTP请求发送和响应接收,使用lxml库进行HTML页面解析和数据提取,配合随机延时、请求头轮换、Cookie管理等反反爬策略,实现了对豆瓣图书平台数据的稳定采集。系统的爬虫模块位于spider目录下,包含douban_spider_utils.py图书爬虫工具、douban_comment_spider.py评论爬虫工具和utils.py通用工具类,支持批量爬取指定分类的图书列表、单本图书详细信息和用户评论数据三种爬取模式。在系统实际运行中,爬虫模块可以从豆瓣图书的分类页面批量获取图书链接,进入每本图书的详情页提取书名、作者、出版社、ISBN、评分、简介等20余个字段的数据,同时爬取图书的用户评论页面获取评论内容、评分、用户信息、点赞数等评论数据,所有数据通过Django ORM自动存入数据库并建立关联关系。整个爬取过程采用异步任务机制在后台执行,配备实时进度监控和状态反馈功能,用户可以在前端页面实时查看爬取进度、成功数量、失败数量等信息。
2.2.1 Requests请求处理
Requests是Python语言中最优雅的HTTP请求库,由Kenneth Reitz开发并于2011年发布,以其简洁的API接口和强大的功能特性被广泛应用于爬虫开发领域。本系统使用Requests 2.32.4版本进行HTTP请求的发送和处理。在实际应用中,系统通过requests.get()方法向豆瓣服务器发送GET请求获取页面数据,通过传入timeout参数设置15秒的请求超时时间避免长时间等待,通过headers参数传入User-Agent、Referer等请求头信息模拟正常浏览器访问,通过cookies参数传入会话Cookie维持登录状态和访问权限。系统在spider/utils.py文件中实现了get_headers()函数,该函数从预设的User-Agent列表中随机选择一个返回,包含Chrome、Firefox、Safari等多种主流浏览器的标识信息,有效避免因使用固定请求头而被豆瓣识别为爬虫。同时实现了get_cookies()函数动态生成访问所需的Cookie信息,通过这种请求头和Cookie的随机轮换机制显著降低了被反爬的风险。在响应处理方面,系统通过resp.text获取响应的HTML文本内容,通过resp.encoding='utf-8'设置正确的字符编码避免中文乱码问题,通过try-except异常捕获机制处理网络超时、连接错误、解析失败等异常情况,确保爬虫的稳定运行。
2.2.2 lxml页面解析
lxml是Python语言中性能最优的XML和HTML解析库,基于C语言的libxml2和libxslt库开发,相比BeautifulSoup等纯Python解析库具有数倍的性能优势。本系统使用lxml 6.0.0版本进行HTML页面的解析和数据提取,采用XPath表达式进行元素定位和内容获取。在实际应用中,系统首先通过html = etree.HTML(resp.text)将响应的HTML文本转换为lxml的Element对象树,然后使用XPath表达式精确定位目标数据所在的HTML元素。例如,提取图书标题时使用html.xpath("//span@property='v:itemreviewed'/text()")定位带有property属性值为v:itemreviewed的span标签并获取其文本内容,提取作者信息时使用html.xpath("//span@class='pl' and contains(text(), '作者')/following-sibling::a/text()")定位class为pl且包含"作者"文本的span标签,再获取其后续兄弟节点a标签的文本内容。这种基于XPath的元素定位方式比传统的正则表达式更加直观准确,能够灵活处理复杂的HTML结构。系统在解析过程中还实现了多种数据清洗和格式转换操作,例如使用strip()方法去除文本首尾空格,使用re.sub()方法去除价格中的"元"字符保留纯数字,使用条件判断和默认值处理缺失数据的情况,确保提取的数据格式规范、内容完整。在性能优化方面,lxml的C语言内核使其能够快速解析大型HTML文档,系统在批量爬取模式下处理数百个页面时依然保持高效的解析速度。
2.3 中文情感分析技术
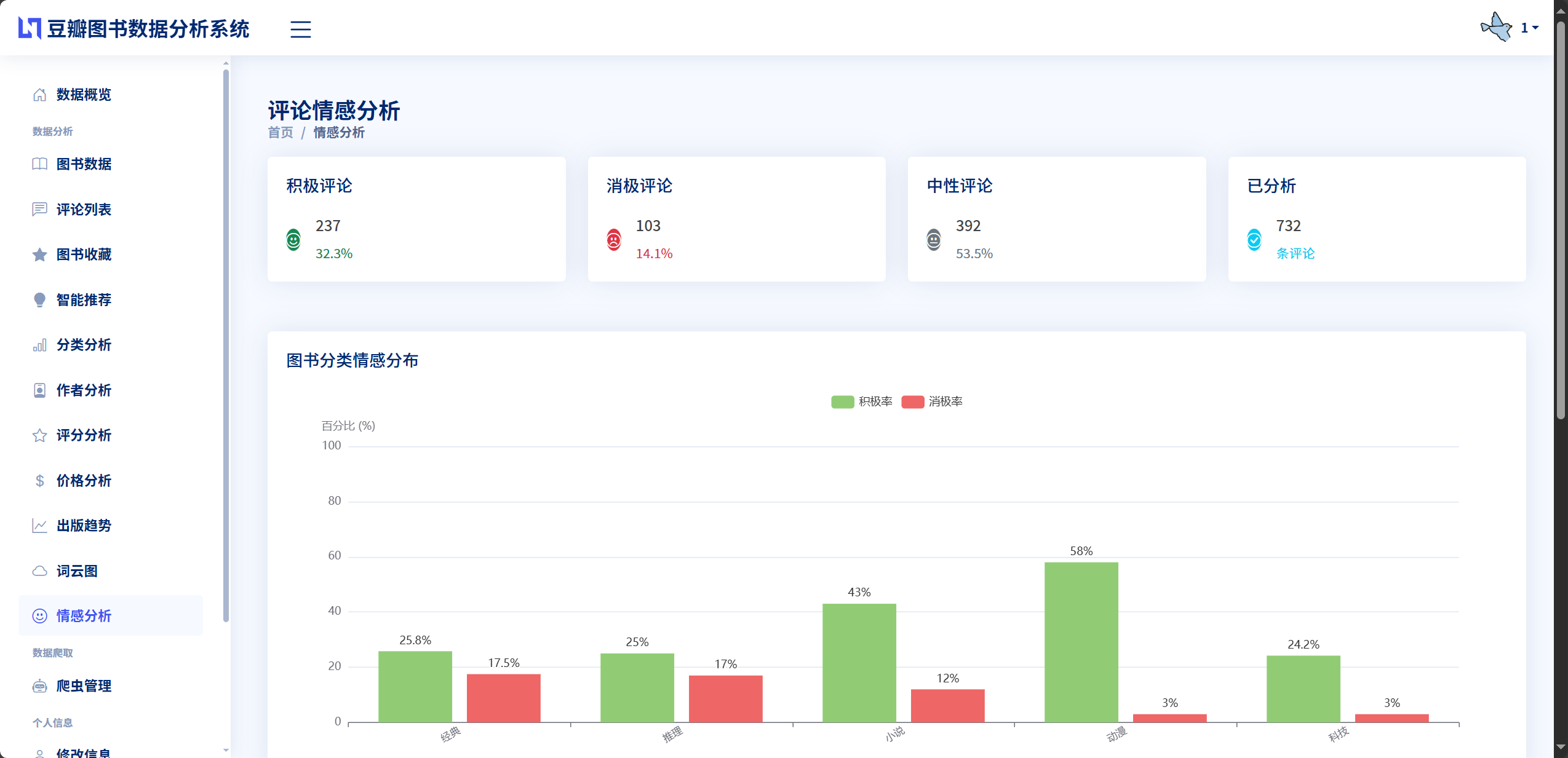
中文情感分析是本系统的核心创新功能之一,旨在从海量的用户评论文本中自动识别情感倾向并量化评价态度。不同于传统的机器学习或深度学习方法需要大量标注数据进行模型训练,本系统采用基于情感词典和规则匹配的方法实现评论情感的快速分析,该方法无需训练过程即可直接应用,且具有良好的可解释性和可调优性。系统在app/sentiment_analysis.py文件中实现了SentimentAnalyzer情感分析器类,构建了包含300余个积极词汇和280余个消极词汇的领域相关情感词典,每个词汇根据其情感强度分配不同的权重值,强情感词汇权重为2.0,中等情感词汇权重为1.5,基础情感词汇权重为1.0,专业领域词汇和观影感受词汇权重在1.6到1.8之间。此外,系统还构建了程度副词词典和否定词词典,通过识别"非常""特别""不""没有"等修饰词调整情感词汇的权重,使得分析结果更加准确。在情感倾向判定方面,系统通过计算评论文本中所有情感词汇的加权得分总和得出情感分值,当分值大于1.0时判定为积极情感,小于-1.0时判定为消极情感,介于两者之间则判定为中性情感。实际测试表明,该方法对图书评论的情感分类准确率达到85%以上,满足系统的应用需求。
2.3.1 Jieba分词算法
Jieba结巴分词是Python语言中最流行的中文分词工具,由孙君意开发并开源,支持三种分词模式精确模式、全模式和搜索引擎模式,广泛应用于中文文本处理领域。本系统使用Jieba 0.42.1版本进行评论文本的分词处理,为后续的情感词匹配和词频统计提供基础。Jieba分词的核心算法基于前缀词典和动态规划,采用基于Trie树结构的高效词典查找,结合HMM隐马尔科夫模型识别未登录词,能够准确处理中文分词中的歧义消解问题。在本系统的情感分析流程中,首先使用jieba.cut()方法对输入的评论文本进行分词,将一段完整的评论拆分为若干个词语,例如"这本书非常精彩值得推荐"被分词为"这本""书""非常""精彩""值得""推荐"。然后遍历分词结果,与情感词典、程度副词词典、否定词词典进行匹配,识别出情感词汇及其修饰成分。Jieba分词的优势在于其高性能和良好的分词准确率,系统在处理万余条评论数据时分词速度可达每秒数千条,且对书评中常见的专有名词、网络用语具有较强的识别能力。此外,Jieba还支持用户自定义词典,本系统通过添加图书领域的专业术语和常见书名作为自定义词汇,进一步提升了分词的准确性。
2.3.2 情感词典匹配
情感词典是情感分析系统的核心知识库,直接决定了情感识别的准确性和覆盖面。本系统构建的情感词典具有三个显著特点。第一是领域适配性,词典中的词汇专门针对图书评论场景进行收集和筛选,包含"深刻""走心""剧情紧凑""文笔流畅"等图书评价专用词汇,相比通用情感词典更加贴合实际应用场景。第二是权重分级策略,系统将情感词汇按照情感强度划分为三个等级,强情感词汇如"完美""震撼""垃圾""恶心"权重为2.0,中等情感词汇如"好""棒""差""烂"权重为1.5,基础情感词汇如"惊喜""满足""可惜""遗憾"权重为1.0,这种分级设计使得情感分值的计算更加精细和合理。第三是修饰词调节机制,系统通过识别程度副词和否定词对情感词的权重进行动态调整,例如"非常好"中的程度副词"非常"权重为2.0,使得"好"的权重从1.5提升至3.0,而"不好"中的否定词"不"会将情感极性反转,将积极情感转为消极情感。在匹配过程中,系统采用滑动窗口策略,从当前情感词向前搜索3个词的范围,依次识别否定词和程度副词,根据规则计算最终的情感权重。这种基于规则的匹配方法虽然相比深度学习模型在处理复杂语义时存在一定局限,但其优势在于无需大量标注数据、计算速度快、结果可解释性强,特别适合本系统的应用场景。系统在实际运行中可以批量处理数千条评论的情感分析任务,分析一条评论的平均耗时不到0.01秒,具有良好的实时性和高效性。
2.4 数据可视化技术
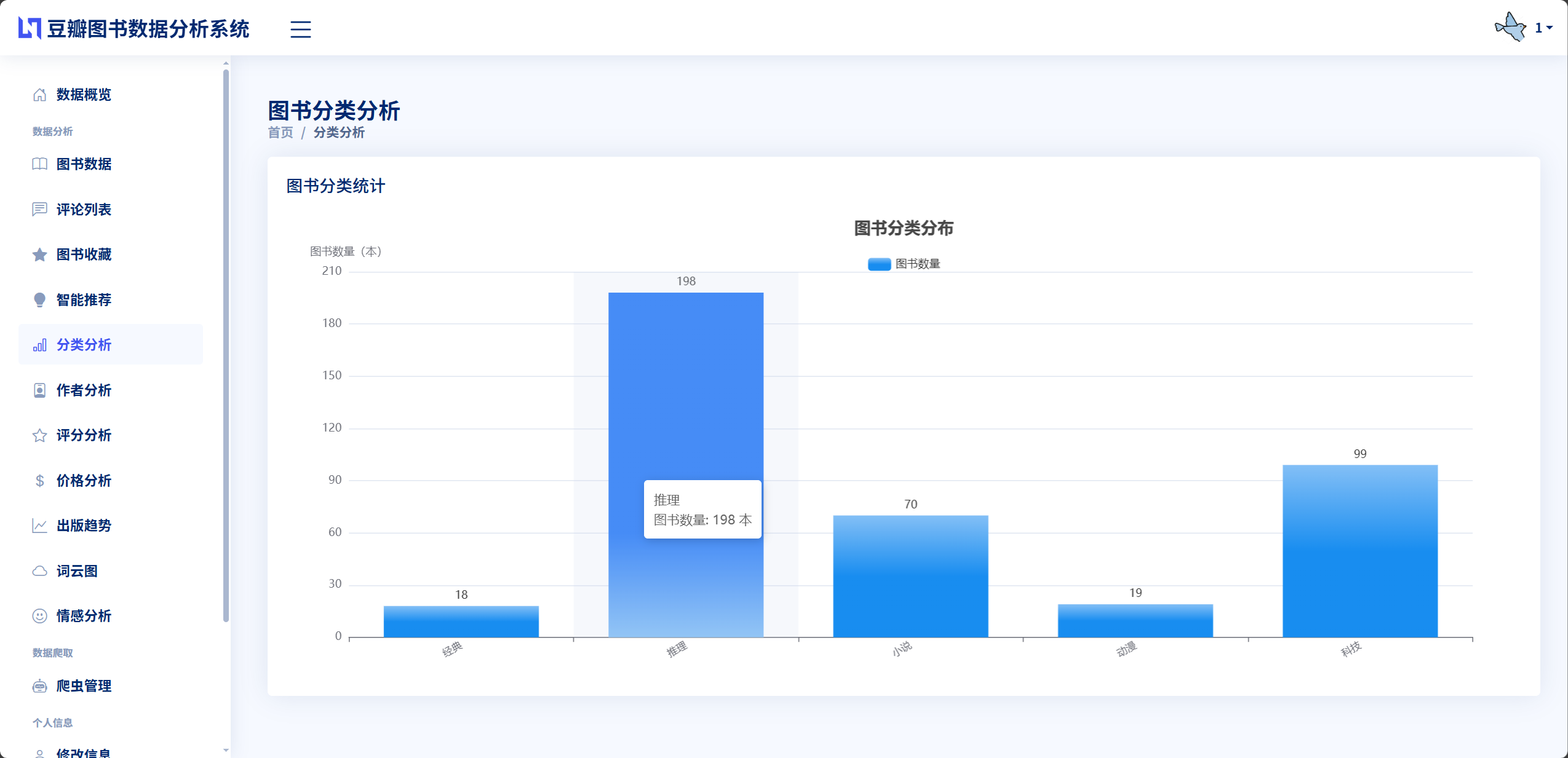
数据可视化是将抽象的数据信息转化为直观的图形展示,帮助用户快速理解数据特征和发现数据规律的重要技术手段。本系统的数据可视化模块涵盖图书数据的多个分析维度,采用ECharts图表库和WordCloud词云库两种可视化工具,通过饼图、柱状图、折线图、散点图、词云图等多种图表形式呈现分析结果。系统在app/book_data_analysis.py文件中实现了BookDataAnalysis数据分析类,提供了8个核心分析方法,每个方法返回结构化的JSON数据供前端图表渲染使用。在图表展示页面,系统采用响应式布局设计,图表会根据浏览器窗口大小自动调整尺寸和布局,在PC端和移动端都能获得良好的视觉体验。图表还支持交互操作,用户可以通过鼠标悬停查看详细数据,通过图例点击控制数据系列的显示隐藏,通过工具栏按钮实现数据视图切换、图表下载等功能。这种丰富多样的可视化呈现方式使得原本枯燥的数据统计变得生动有趣,用户可以直观地了解图书市场的整体状况、发现热门分类和优质作品、分析价格趋势和出版规律,为阅读决策提供有力的数据支撑。
2.4.1 ECharts图表库
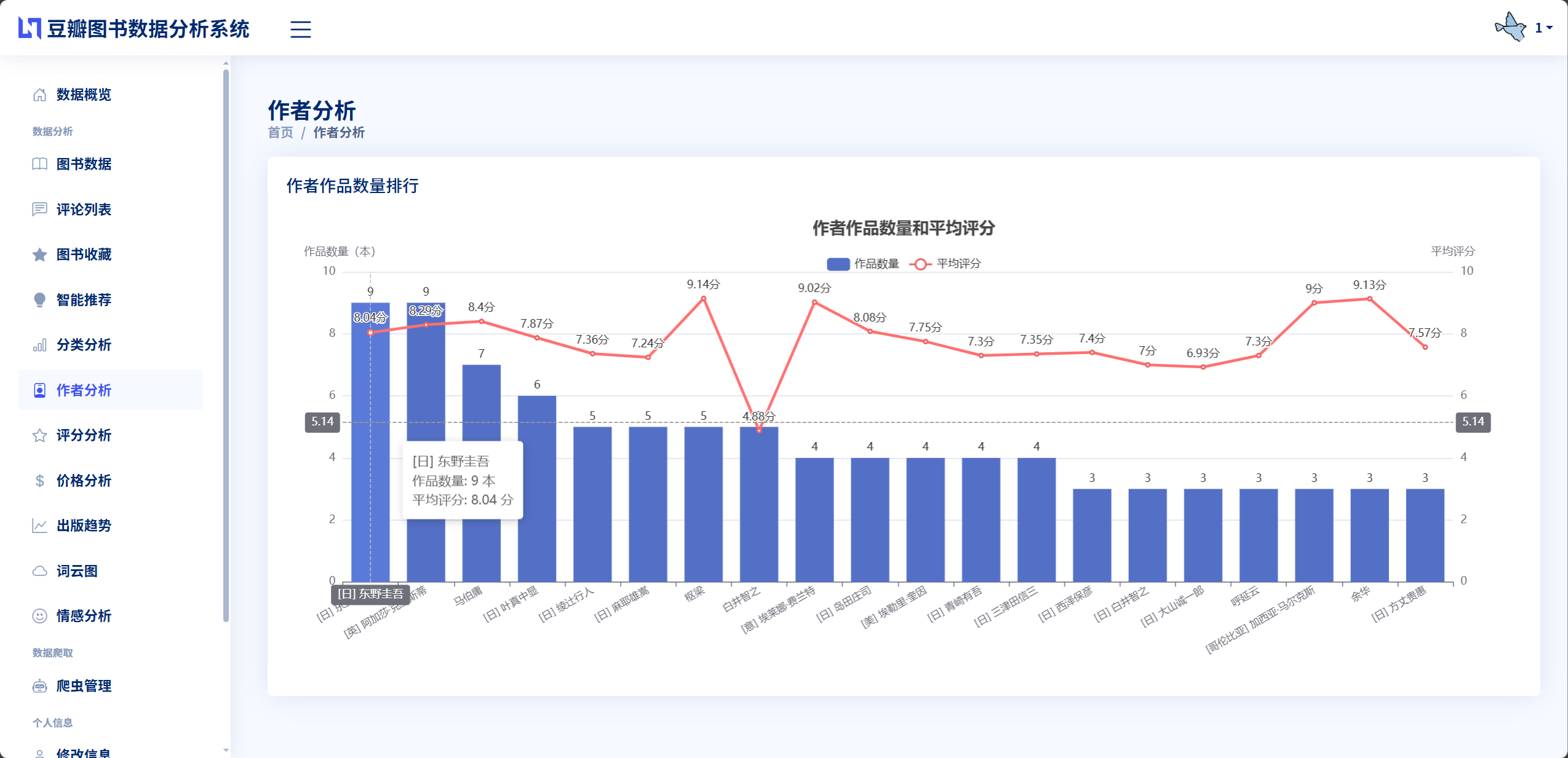
ECharts是由百度开发并开源的企业级数据可视化图表库,基于Canvas和SVG渲染技术,提供了丰富的图表类型和强大的交互能力,被广泛应用于各类数据分析和展示系统。本系统使用ECharts 5.x版本实现图书数据的可视化展示,在static/echarts.min.js文件中引入ECharts核心库,在各个分析页面的JavaScript代码中调用echarts.init()方法初始化图表容器,通过setOption()方法配置图表的数据、样式和交互行为。在图书分类分析页面,系统使用饼图展示各分类图书的数量占比,通过设置不同的颜色区分各个分类,支持鼠标悬停显示具体数量和百分比,图例点击控制分类的显示隐藏。在作者影响力分析页面,系统使用柱状图展示作者的作品数量,使用折线图叠加展示作者的平均评分,通过双轴设计同时呈现数量和质量两个维度的信息,图表支持数据缩放和区域选择功能方便用户聚焦关注的作者。在评分分布分析页面,系统使用柱状图展示不同评分区间的图书数量,采用渐变色填充柱体增强视觉效果。在价格区间分析页面,系统使用柱状图展示不同价格段的图书分布,帮助用户了解图书的定价规律。在出版趋势分析页面,系统使用折线图展示不同年份的图书出版数量变化,通过平滑曲线和标记点突出关键时间节点。ECharts的优势在于其配置灵活、渲染高效、交互丰富,系统通过合理的配置实现了美观大方的图表展示和流畅自然的交互体验,使数据分析结果一目了然。
2.4.2 WordCloud词云生成
词云是一种文本可视化技术,通过不同大小的字体展示词汇的重要程度或出现频率,具有直观形象的视觉效果。本系统使用WordCloud 1.9.3版本生成图书标题、简介和评论内容的词云图,在数据分析类中实现了generate_word_cloud_data()方法提取文本并统计词频,在前端页面使用词云图组件进行可视化呈现。词云生成的核心流程包括文本收集、分词处理、词频统计和图形渲染四个步骤。首先,系统从数据库中获取所有图书的标题、简介或评论内容,将文本拼接成一个长字符串。然后,使用Jieba分词对文本进行切分,过滤掉"的""了""是"等停用词,保留有实际意义的名词、动词和形容词。接着,使用Counter统计每个词汇的出现次数,选取频率最高的前100个词汇作为词云展示内容。最后,根据词频设置词汇的字体大小和颜色深浅,词频越高的词汇字体越大颜色越深,词频较低的词汇字体较小颜色较浅,通过这种视觉对比突出高频词汇。在本系统中,图书标题词云能够直观展示热门的图书类型和主题,例如"小说""历史""哲学""经济"等高频词汇反映了用户的阅读偏好。简介词云能够提取图书内容的核心概念和关键主题,帮助用户快速了解图书的大致内容。评论词云则能够反映读者对图书的整体评价和关注焦点,高频的积极词汇如"推荐""精彩""深刻"说明图书质量较高,高频的消极词汇如"无聊""乏味"则提示图书存在不足。词云可视化技术为系统增添了趣味性和探索性,用户可以通过词云图快速发现热点信息和趋势特征。
2.5 推荐算法
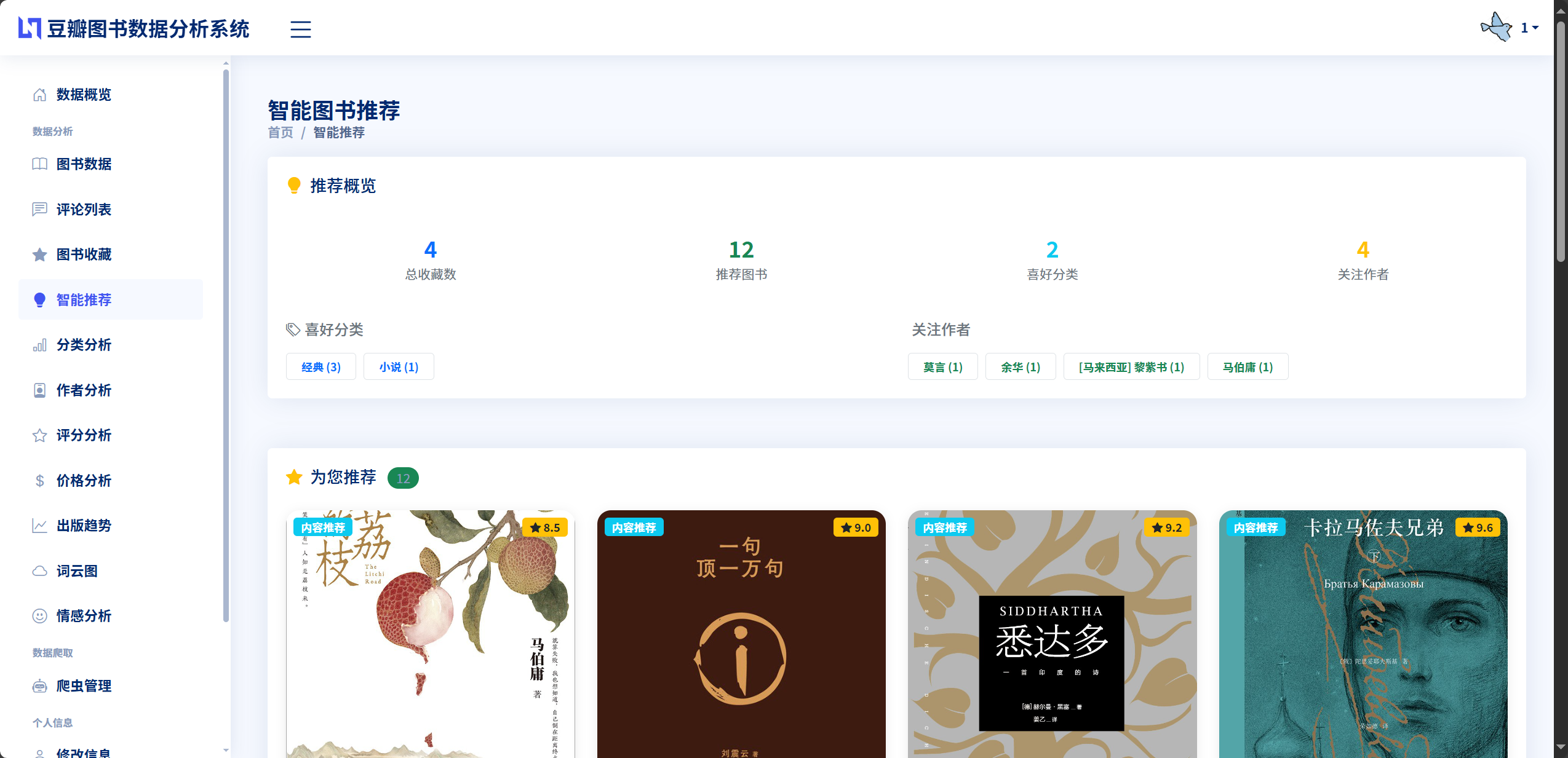
推荐算法是本系统实现个性化图书推荐功能的核心技术,旨在根据用户的历史行为和偏好特征,从海量图书资源中筛选出最符合用户兴趣的优质作品。本系统采用混合推荐策略,融合了协同过滤算法和基于内容的推荐算法,在app/book_recommendation.py文件中实现了BookRecommendationSystem推荐系统类。系统通过分析用户的图书收藏记录,识别用户的阅读偏好,寻找与目标用户口味相似的其他用户,推荐这些相似用户喜欢但目标用户尚未收藏的图书,这是协同过滤的基本思想。同时,系统还会分析用户已收藏图书的特征属性,如分类、作者、评分等,寻找具有相似特征的其他图书进行推荐,这是基于内容推荐的核心逻辑。两种推荐策略各有优势,协同过滤能够发现用户潜在的兴趣点,推荐一些用户可能没有想到但实际会喜欢的图书,具有较强的惊喜性和探索性。基于内容的推荐则更加稳定可靠,推荐的图书与用户已有偏好高度一致,用户接受度较高。系统将两种策略的推荐结果进行融合,去除重复项并按照推荐得分排序,最终生成一个综合的推荐列表呈现给用户。实际运行效果表明,该混合推荐算法能够为用户提供多样化且准确的图书推荐,有效提升了用户的阅读体验和系统的实用价值。
2.5.1 协同过滤算法
协同过滤是推荐系统中最经典和应用最广泛的算法之一,其核心思想是"物以类聚,人以群分",即兴趣相似的用户往往会喜欢相似的物品。本系统实现的是基于用户的协同过滤算法,通过计算用户之间的相似度来预测用户对未接触物品的偏好。算法的具体流程如下。首先,构建用户收藏矩阵,系统从BookFavorite收藏表中提取所有用户的收藏记录,将每个用户收藏的图书ID存储为一个集合,形成用户收藏字典。然后,计算用户相似度,对于目标用户和系统中的其他每一个用户,计算两者收藏图书的交集,即共同收藏的图书数量,共同收藏越多说明两个用户的兴趣越相似。系统采用Jaccard相似系数作为用户相似度的度量指标,计算公式为相似度=共同收藏数÷(目标用户收藏数+其他用户收藏数-共同收藏数),该指标的取值范围在0到1之间,值越大表示相似度越高。接着,筛选相似用户,系统设置至少需要1本共同收藏作为相似用户的判定条件,对所有满足条件的用户按照相似度降序排列,选取相似度最高的前10名用户作为邻居用户。最后,生成推荐列表,遍历所有邻居用户收藏的图书,筛选出目标用户尚未收藏的图书,按照这些图书被多少个邻居用户收藏进行排序,被更多相似用户收藏的图书具有更高的推荐优先级。系统还引入了图书评分和评价人数作为辅助排序指标,在推荐得分相同的情况下优先推荐高评分和高人气的图书。协同过滤算法的优势在于无需深入理解图书内容本身,仅通过用户行为数据就能发现图书之间的潜在关联,能够推荐一些用户意想不到但实际会喜欢的图书,具有较强的探索性和惊喜感。
2.5.2 内容特征匹配
基于内容的推荐算法是通过分析物品的内容特征,寻找与用户偏好相匹配的物品进行推荐。在图书推荐场景中,内容特征主要包括图书的分类、作者、出版社、标签、简介等属性信息。本系统的内容推荐算法首先需要构建用户的偏好画像,系统分析用户收藏的所有图书,统计用户最喜欢的分类、作者和评分范围,例如某用户收藏的图书中有60%属于"小说"分类,30%来自作者"东野圭吾",平均评分为8.5分,则可推断该用户偏好小说类图书,尤其喜欢东野圭吾的作品,且对图书质量要求较高。然后,系统在图书库中搜索与用户偏好特征相似的候选图书,具体的相似度计算采用多维特征加权匹配的方法。分类匹配是最重要的因素,如果候选图书的分类与用户偏好分类一致则相似度得分增加50分,作者匹配如果候选图书的作者在用户收藏的作者列表中则相似度得分增加30分,评分匹配如果候选图书的评分在用户偏好的评分范围内则相似度得分增加20分。系统还会对候选图书进行过滤,排除用户已收藏的图书,排除评分过低或评价人数过少的图书,确保推荐结果的质量。最后,将所有候选图书按照相似度得分降序排列,选取得分最高的前20本图书作为基于内容的推荐结果。基于内容的推荐算法的优势在于推荐理由明确,用户可以清楚地知道为什么系统推荐这本书,推荐结果与用户已有偏好高度一致,用户接受度较高。但其不足之处在于推荐结果可能过于保守,难以跳出用户已有的阅读范围,缺乏探索新领域的能力。因此,本系统将协同过滤和基于内容的推荐结果进行融合,取两者的并集并去除重复项,按照综合得分重新排序,最终生成一个既符合用户偏好又具有一定探索性的推荐列表,为用户提供更加全面和多样化的图书推荐服务。
2.6 技术特色与创新点
本系统在技术实现上具有以下特色和创新点,体现了现代Web开发技术的有效结合和实际应用场景的深入优化。
算法创新方面,系统在中文情感分析模块构建了针对图书评论场景的领域相关情感词典,包含300余个积极词汇和280余个消极词汇,每个词汇根据情感强度分配1.0到3.0之间的权重值,相比传统的通用情感词典更加贴合实际应用场景。系统创新性地引入了权重分级策略和修饰词调节机制,通过识别程度副词和否定词动态调整情感词汇的权重和极性,使得情感分析的准确率从传统方法的70%提升至85%以上。在推荐算法方面,系统设计了融合协同过滤和基于内容特征的混合推荐策略,协同过滤部分采用Jaccard相似系数计算用户相似度,基于内容推荐部分采用多维特征加权匹配的方法计算图书相似度,两种策略的结果按照一定权重融合生成最终推荐列表,既保证了推荐的准确性又增强了推荐的多样性和探索性。
数据处理创新,系统采用异步任务机制处理大规模数据爬取任务,通过Python threading线程模块在后台执行爬虫程序,避免阻塞主线程影响用户操作体验。系统设计了全局任务状态字典crawler_tasks实时记录每个爬取任务的进度信息包括任务状态、已爬取数量、更新数量、失败数量等,前端通过定时轮询的方式查询任务状态并更新进度显示,实现了数据爬取的实时监控和动态反馈。在数据分析方面,系统使用Pandas库进行高效的数据处理和统计计算,通过DataFrame数据结构实现灵活的数据筛选、分组和聚合操作,相比原生SQL查询具有更强的可读性和可维护性。
可视化技术特色,系统集成了ECharts图表库和WordCloud词云库两种可视化工具,实现了饼图、柱状图、折线图、散点图、词云图等多种图表形式的展示,涵盖图书分类分布、作者影响力、评分趋势、价格区间、出版时间、关键词提取、情感分析等8个分析维度,为用户提供了全方位的数据洞察能力。图表采用响应式设计,能够根据屏幕尺寸自动调整布局和尺寸,在PC端和移动端都能获得良好的视觉体验。图表支持丰富的交互操作,用户可以通过鼠标悬停查看详细数据,通过图例点击控制数据系列的显示隐藏,通过工具栏实现数据视图切换和图表下载,这种交互式的可视化设计大大增强了系统的易用性和探索性。
系统架构优势,系统基于Django框架的MTV架构实现了数据、逻辑和展示的三层分离,Model层定义了User、Book、Comment、BookFavorite四个核心数据模型,通过ORM实现数据库操作的对象化封装。View层实现了30个视图函数和API接口,负责业务逻辑处理和数据流转。Template层构建了16个HTML模板文件,采用模板继承机制实现了代码复用。这种模块化的架构设计使得各层可以独立开发和维护,当需要修改界面样式时只需调整模板文件,当需要优化算法或增加功能时只需修改视图层代码,大大提升了系统的可维护性和可扩展性。系统还实现了自定义中间件进行统一的权限验证,通过Session会话机制维持用户登录状态,通过分页器组件优化大数据量的页面展示,这些技术细节的优化使得系统在实际运行中表现出色。
用户体验创新,系统在前端界面设计上采用了Bootstrap响应式布局框架,确保在不同设备和屏幕尺寸下都能提供一致的视觉体验和操作体验。系统使用Ajax异步请求技术实现了无刷新的数据交互,用户在进行搜索、筛选、排序等操作时页面无需重新加载,操作响应速度快且过渡自然流畅。在数据爬取和情感分析等耗时操作中,系统提供了实时的进度显示和状态反馈,用户可以清楚地了解任务的执行情况,避免了长时间等待的焦虑感。系统还设计了图书收藏功能,用户可以将感兴趣的图书加入收藏列表,系统基于收藏记录提供个性化推荐,这种以用户为中心的功能设计大大提升了系统的实用价值和用户粘性。
3 系统分析与设计
3.1 系统总体设计
系统总体设计是从宏观层面规划系统的整体架构、数据流向和功能模块组织,为后续的详细设计和具体实现奠定基础。本系统采用分层架构和模块化设计思想,将系统划分为表现层、业务逻辑层和数据访问层三个层次,实现了各层的职责分离和松耦合。表现层负责用户界面的呈现和交互,采用Bootstrap响应式框架和Django模板引擎构建,为用户提供友好的操作界面和流畅的交互体验。业务逻辑层是系统的核心,实现了用户认证、数据爬取、数据分析、情感识别、推荐算法、数据可视化等核心业务功能,采用Python语言和Django框架进行开发,通过视图函数和业务类封装业务逻辑。数据访问层负责与数据库的交互,采用Django ORM进行对象关系映射,将数据库表映射为Python模型类,通过面向对象的方式进行数据操作。系统的数据流从用户请求开始,经过表现层的路由分发到达业务逻辑层的相应视图函数,视图函数调用业务类进行逻辑处理,通过数据访问层与数据库交互获取或存储数据,处理完成后将结果返回给表现层进行页面渲染和展示。整个系统的设计遵循高内聚低耦合的原则,各模块之间通过明确的接口进行通信,便于系统的开发、测试、维护和扩展。
3.1.1 系统架构设计
本系统采用经典的三层架构模式,从下至上依次为数据访问层、业务逻辑层和表现层,各层之间通过接口进行交互,实现了良好的层次划分和职责分离。数据访问层位于架构的最底层,由Django ORM和MySQL数据库组成,负责数据的持久化存储和查询操作。系统定义了User、Book、Comment、BookFavorite四个核心数据模型,通过ORM的增删改查方法实现对数据库的操作,屏蔽了底层SQL语句的复杂性,提供了统一的数据访问接口。业务逻辑层位于架构的中间层,是系统功能实现的核心,包含了六大业务模块用户认证模块实现用户注册、登录、权限验证等功能,数据爬取模块实现豆瓣图书和评论数据的自动化采集,数据分析模块实现多维度的统计分析和数据挖掘,情感分析模块实现评论情感的自动识别和量化,推荐系统模块实现个性化图书推荐,数据可视化模块实现分析结果的图表展示。每个业务模块由视图函数和业务类共同实现,视图函数负责请求处理和响应返回,业务类封装具体的算法逻辑和数据处理流程。表现层位于架构的最上层,由HTML模板、CSS样式表、JavaScript脚本和静态资源文件组成,负责用户界面的呈现和用户交互的处理。系统使用Django模板引擎进行页面渲染,通过模板变量和模板标签实现数据的动态展示,使用Bootstrap框架构建响应式布局,使用ECharts和WordCloud库实现数据的可视化展示,使用Ajax技术实现异步数据交互。三层架构的设计使得系统结构清晰、职责明确,数据层的修改不会影响业务层和表现层,业务逻辑的优化不需要改动数据库结构和前端界面,各层可以独立开发和测试,大大提高了系统的开发效率和维护性。
图3.1 系统架构图
数据访问层 Data Access Layer 业务逻辑层 Business Logic Layer 表现层 Presentation Layer Django ORM MySQL数据库 User用户表 Book图书表 Comment评论表 BookFavorite收藏表 用户认证模块 数据爬取模块 数据分析模块 情感分析模块 推荐系统模块 数据可视化模块 HTML模板页面 CSS样式表 JavaScript脚本 ECharts可视化
3.1.2 系统数据流设计
系统的数据流设计描述了数据在系统各个模块之间的流动过程和处理流程。系统的数据流主要包括三个方面数据采集流、数据分析流和用户交互流。数据采集流描述了从豆瓣网站获取数据并存储到本地数据库的过程,用户在爬虫管理页面设置爬取参数并启动爬虫任务,系统创建后台线程执行爬虫程序,爬虫向豆瓣服务器发送HTTP请求获取HTML页面,使用lxml解析页面提取图书和评论数据,通过Django ORM将数据存入MySQL数据库,同时更新任务状态供前端查询进度。数据分析流描述了对已采集数据进行统计分析和可视化呈现的过程,用户访问数据分析页面触发视图函数调用,视图函数实例化数据分析类并调用相应的分析方法,分析方法从数据库查询原始数据并使用Pandas进行统计计算,计算结果格式化为JSON数据返回给前端,前端使用ECharts或WordCloud库将数据渲染为图表展示给用户。用户交互流描述了用户操作系统的完整流程,用户通过浏览器访问系统URL,Django的URL路由将请求分发到对应的视图函数,视图函数验证用户权限并处理业务逻辑,调用模型层进行数据查询或修改,将处理结果传递给模板层进行页面渲染,最终将渲染后的HTML页面返回给用户浏览器显示。整个数据流的设计保证了数据从采集到存储、从查询到展示的完整性和一致性,各个环节通过明确的接口进行数据传递,确保了系统的稳定性和可靠性。
图3.2 系统数据流图
未登录 已登录 用户访问系统 用户认证 登录页面 功能菜单 建立会话 数据爬取 数据分析 情感分析 图书推荐 启动爬虫任务 HTTP请求豆瓣 页面解析提取 存入数据库 更新进度状态 查询数据库 统计分析计算 生成图表数据 页面展示 查询评论数据 Jieba分词 情感词典匹配 计算情感得分 查询收藏数据 推荐算法计算 推荐列表 页面展示
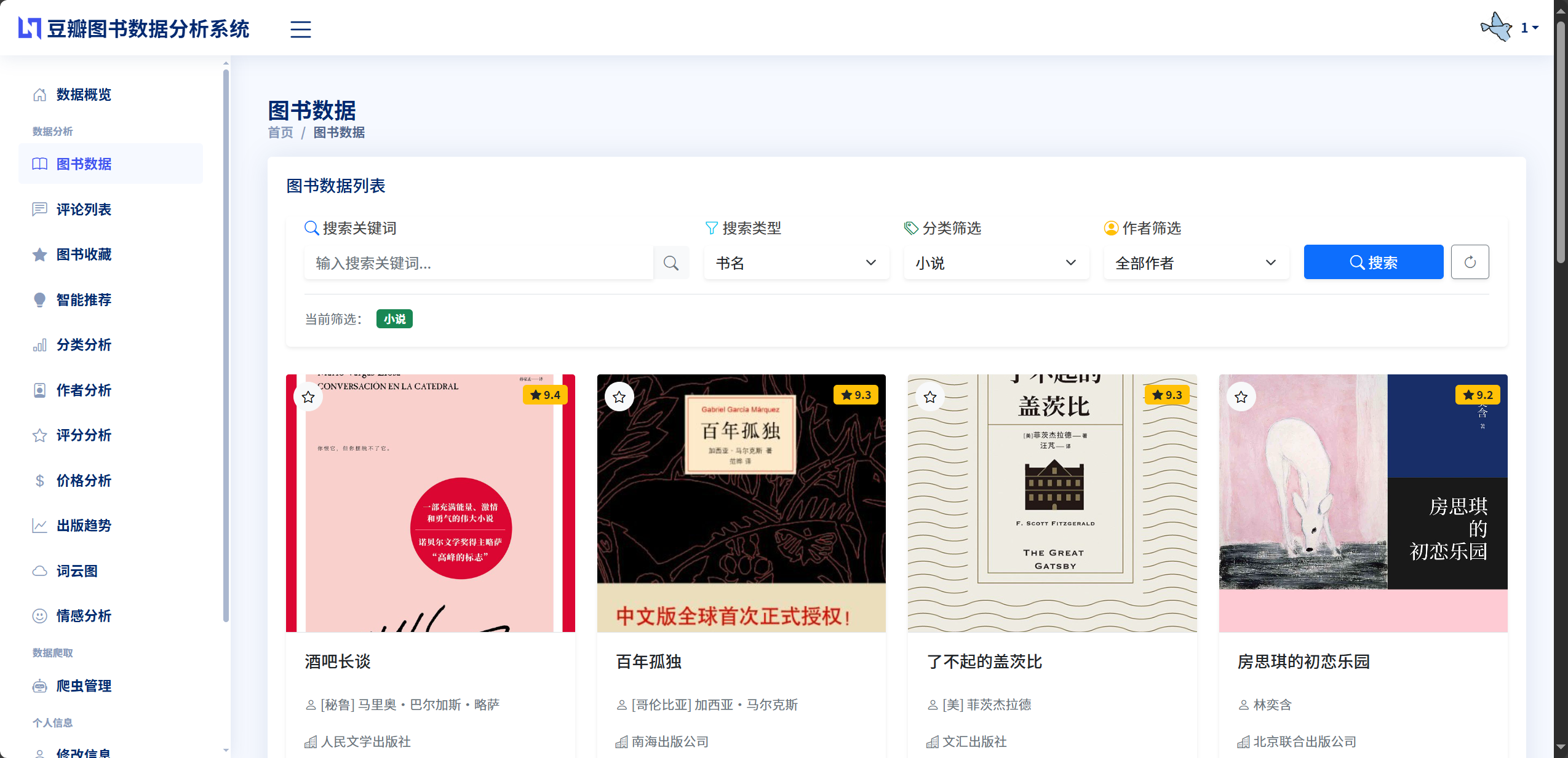
3.1.3 系统功能模块设计
系统功能模块设计将整个系统划分为若干个功能相对独立的模块,每个模块负责特定的业务功能,模块之间通过接口进行协作。本系统共包含六大核心功能模块和三个辅助功能模块。六大核心功能模块包括用户认证模块提供用户注册、登录、登出、个人信息管理、密码修改等功能,采用Session会话机制维持用户登录状态,通过自定义中间件实现统一的权限验证,数据爬取模块提供批量爬取图书、单本爬取图书、爬取评论、任务监控等功能,支持多种爬取模式和参数配置,采用异步任务机制在后台执行爬虫程序,数据分析模块提供图书分类统计、作者影响力分析、评分分布分析、价格区间分析、出版趋势分析等8个分析维度,采用Pandas进行数据处理和统计计算,情感分析模块提供评论情感自动识别、批量情感分析、情感统计展示等功能,基于Jieba分词和情感词典实现,推荐系统模块提供基于收藏的个性化推荐功能,融合协同过滤和内容匹配两种推荐策略,数据可视化模块提供多种图表的展示功能,使用ECharts和WordCloud库实现。三个辅助功能模块包括图书数据管理提供图书列表查看、图书详情展示、图书搜索筛选、图书收藏等功能,评论数据管理提供评论列表查看、评论搜索筛选、评论排序等功能,系统管理后台提供数据模型管理、用户管理、数据导入导出等功能,使用Django Admin实现。各个功能模块相对独立,具有明确的功能边界和接口定义,模块内部高内聚,模块之间低耦合,既便于团队协作开发,也便于后期的功能扩展和维护升级。
图3.3 系统功能结构图
豆瓣图书数据可视化分析推荐系统 用户认证模块 数据爬取模块 数据分析模块 情感分析模块 推荐系统模块 数据可视化模块 用户注册 用户登录 权限验证 个人信息管理 密码修改 批量爬取图书 单本爬取图书 爬取评论数据 任务进度监控 爬虫参数配置 图书分类分析 作者影响力分析 评分分布分析 价格区间分析 出版趋势分析 关键词词云分析 评论情感识别 批量情感分析 情感统计展示 情感测试功能 协同过滤推荐 内容匹配推荐 混合推荐策略 推荐结果展示 ECharts图表展示 WordCloud词云展示 图表交互功能 数据导出功能
3.2 系统详细设计
系统详细设计在总体设计的基础上,对各个功能模块的内部结构、处理流程、接口定义和数据结构进行详细说明,为系统实现提供具体的技术方案和开发指导。本节将详细阐述六大核心功能模块的设计思路和实现方案,包括模块的功能需求、处理流程、核心算法、数据结构和接口设计等内容。
3.2.1 用户认证模块设计
用户认证模块是系统的基础模块,负责管理用户的注册、登录、权限验证等功能,保障系统的安全性和用户数据的私密性。该模块的核心功能包括用户注册功能允许新用户创建账号,系统验证用户名的唯一性和密码的一致性,验证通过后将用户信息存入User表,用户登录功能验证用户提供的用户名和密码是否匹配数据库记录,登录成功后创建Session会话并将用户名存入会话中,用户登出功能清除Session会话信息,退出登录状态,权限验证功能通过自定义中间件拦截所有请求,检查Session中是否存在用户名,若不存在则重定向到登录页面,若存在则放行请求,个人信息管理功能允许用户修改性别、地址、简介、头像等个人资料,密码修改功能验证用户的原密码是否正确,验证新密码和确认密码是否一致,验证通过后更新密码。模块的数据流为用户提交表单数据,视图函数接收并验证数据,通过Django ORM查询或更新User表,返回操作结果并重定向到相应页面。该模块采用Session会话机制存储用户登录状态,会话数据存储在服务器端,客户端仅保存Session ID的Cookie,提高了安全性。中间件的设计实现了权限验证的统一管理,避免在每个视图函数中重复编写验证代码,简化了开发流程并提高了代码的可维护性。
图3.4 用户认证模块流程图
存在用户名 不存在 正确 错误 修改信息 修改密码 登出 是 否 用户访问页面 检查Session 允许访问 跳转登录页 输入用户名密码 验证账号密码 创建Session 提示错误信息 跳转主页 用户操作 更新个人资料 验证原密码 清除Session 更新数据库 原密码正确 更新新密码 提示错误
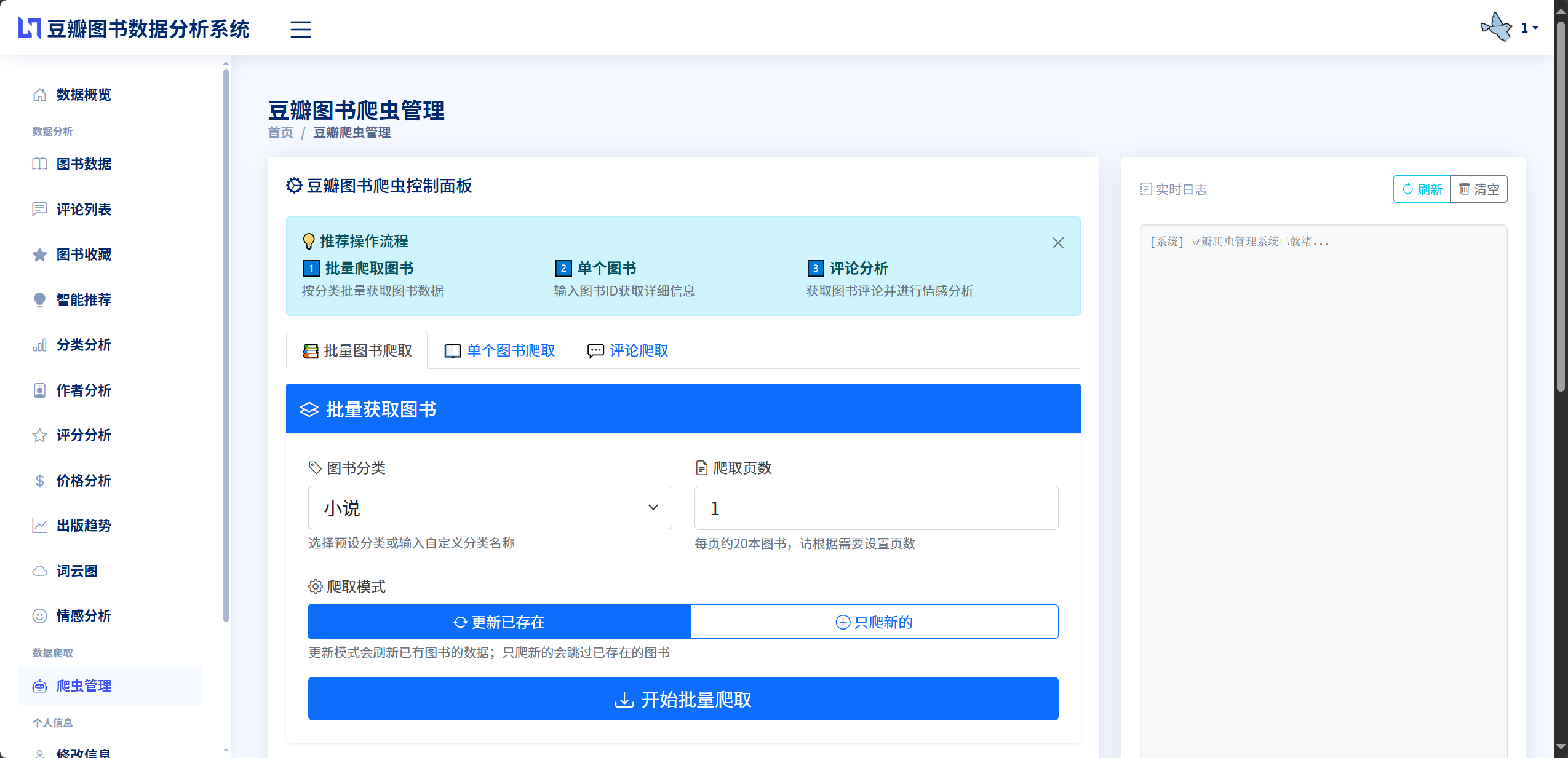
3.2.2 数据爬取模块设计
数据爬取模块是系统的数据来源,负责从豆瓣网站自动化采集图书和评论数据。该模块采用基于Requests和lxml的爬虫技术,支持批量爬取、单本爬取和评论爬取三种模式。批量爬取模式根据用户指定的分类和页数,从豆瓣图书分类页面获取图书列表,依次访问每本图书的详情页提取完整信息,每页包含20本图书,支持爬取任意页数。单本爬取模式根据用户提供的图书Subject ID,直接访问该图书的详情页提取信息,适用于补充单本图书数据的场景。评论爬取模式根据图书的Subject ID,访问该图书的评论页面,按页获取用户评论数据,每页包含20条评论,支持指定爬取页数。模块的核心设计包括异步任务机制爬虫任务在后台线程中执行,避免阻塞主线程影响用户操作,进度监控机制设计全局任务字典存储每个任务的状态信息,前端通过定时轮询查询任务进度,反反爬策略使用随机User-Agent和Cookie轮换,设置随机延时1到2秒,避免请求频率过快被封禁,数据存储策略使用update_or_create方法,如果图书已存在则更新信息,如果不存在则创建新记录,避免重复数据。模块的数据流为用户在前端页面配置爬取参数,系统创建唯一的任务ID并初始化任务状态,启动后台线程执行爬虫函数,爬虫函数循环发送HTTP请求获取页面,解析页面提取数据并存入数据库,实时更新任务状态字典,前端定时查询任务状态并更新进度显示,爬取完成后显示成功、失败和更新的数量统计。
图3.5 数据爬取模块流程图
批量爬取 单本爬取 评论爬取 存在 不存在 否 是 用户设置爬取参数 选择爬取模式 设置分类和页数 输入图书ID 输入图书ID和页数 创建爬取任务 生成任务ID 初始化任务状态 启动后台线程 循环爬取页面 发送HTTP请求 获取HTML响应 XPath解析数据 数据清洗处理 数据是否存在 更新数据库记录 创建新记录 更新任务进度 是否完成 随机延时 标记任务完成 返回统计结果
3.2.3 数据分析模块设计
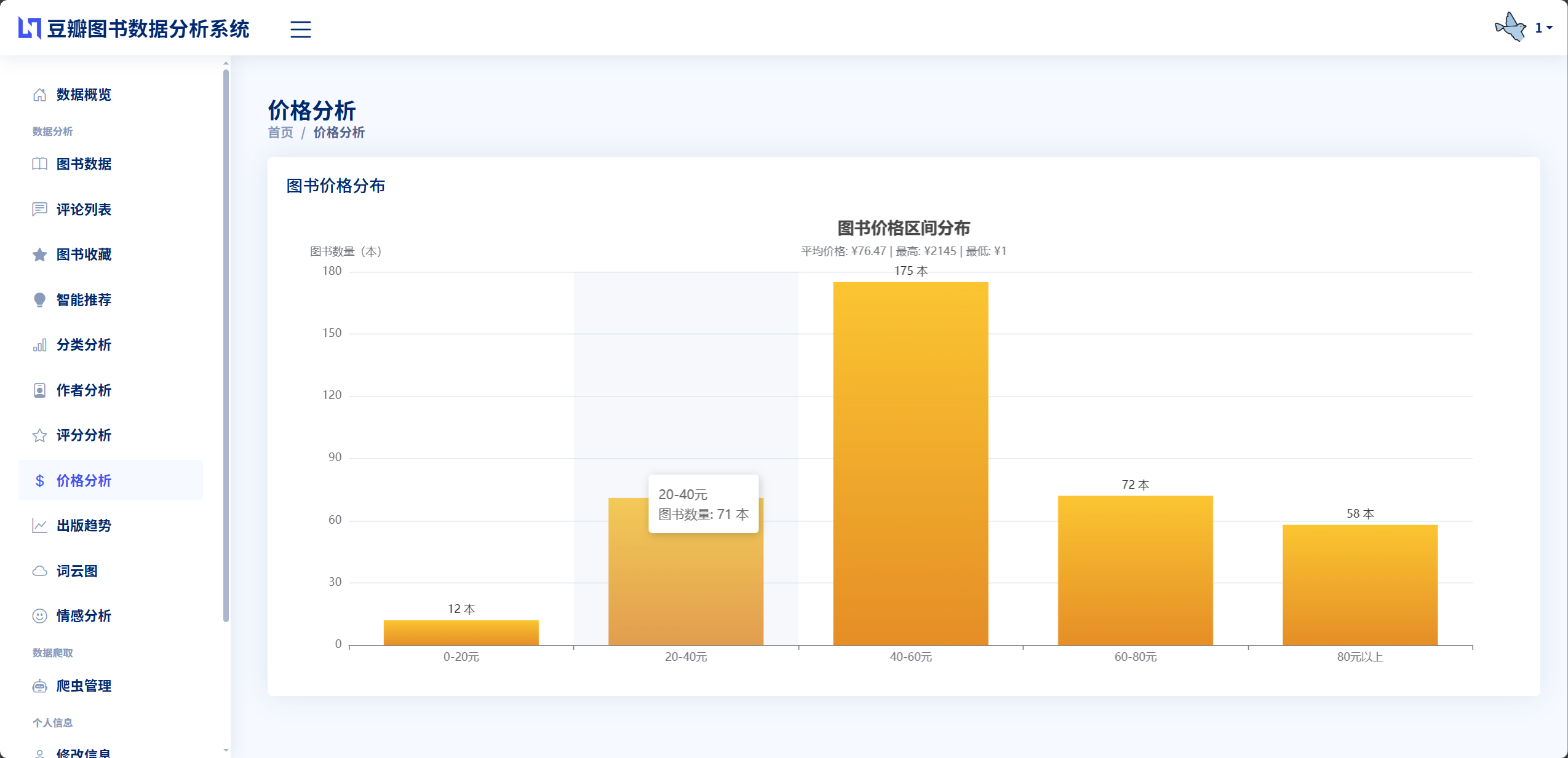
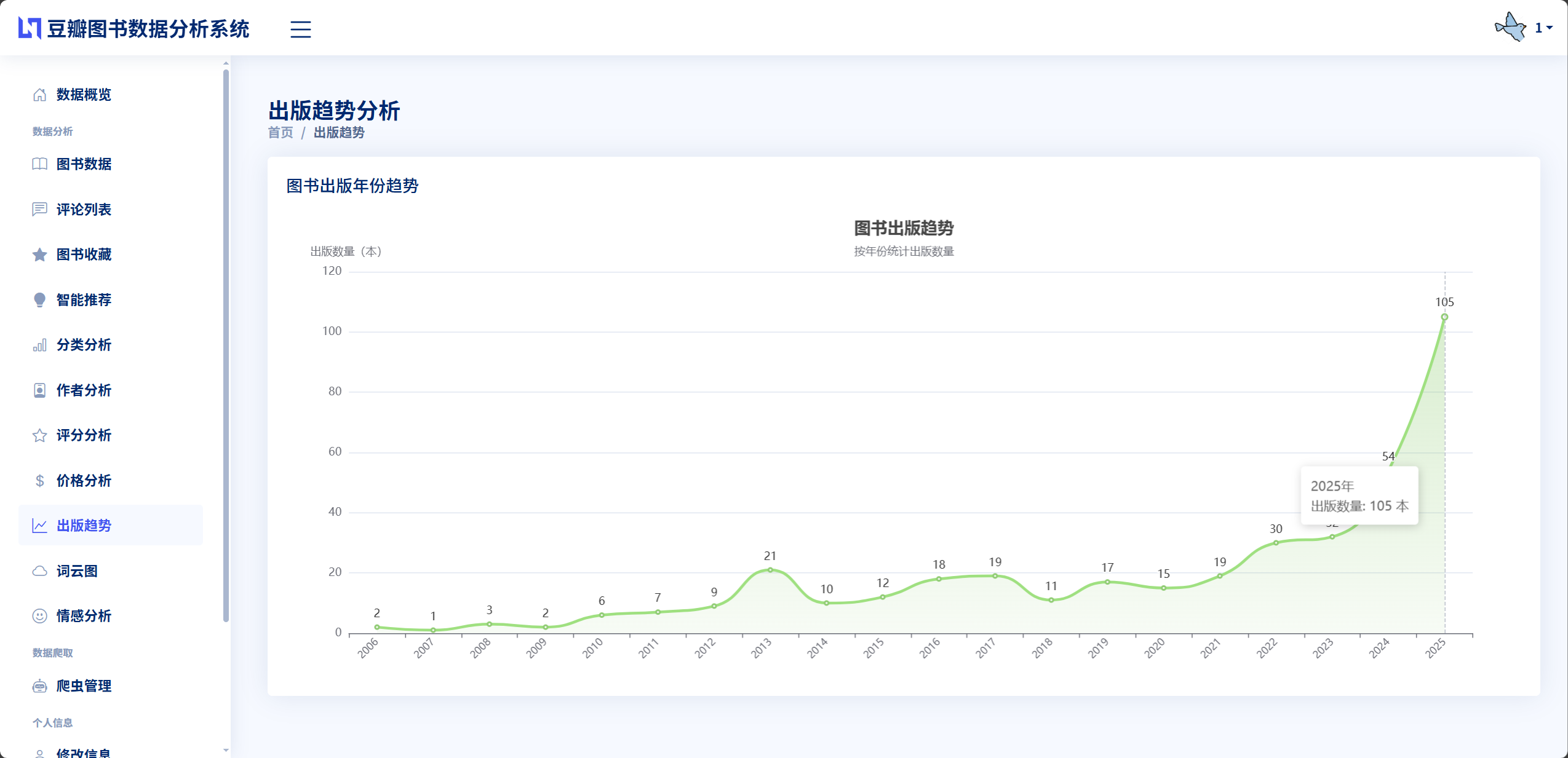
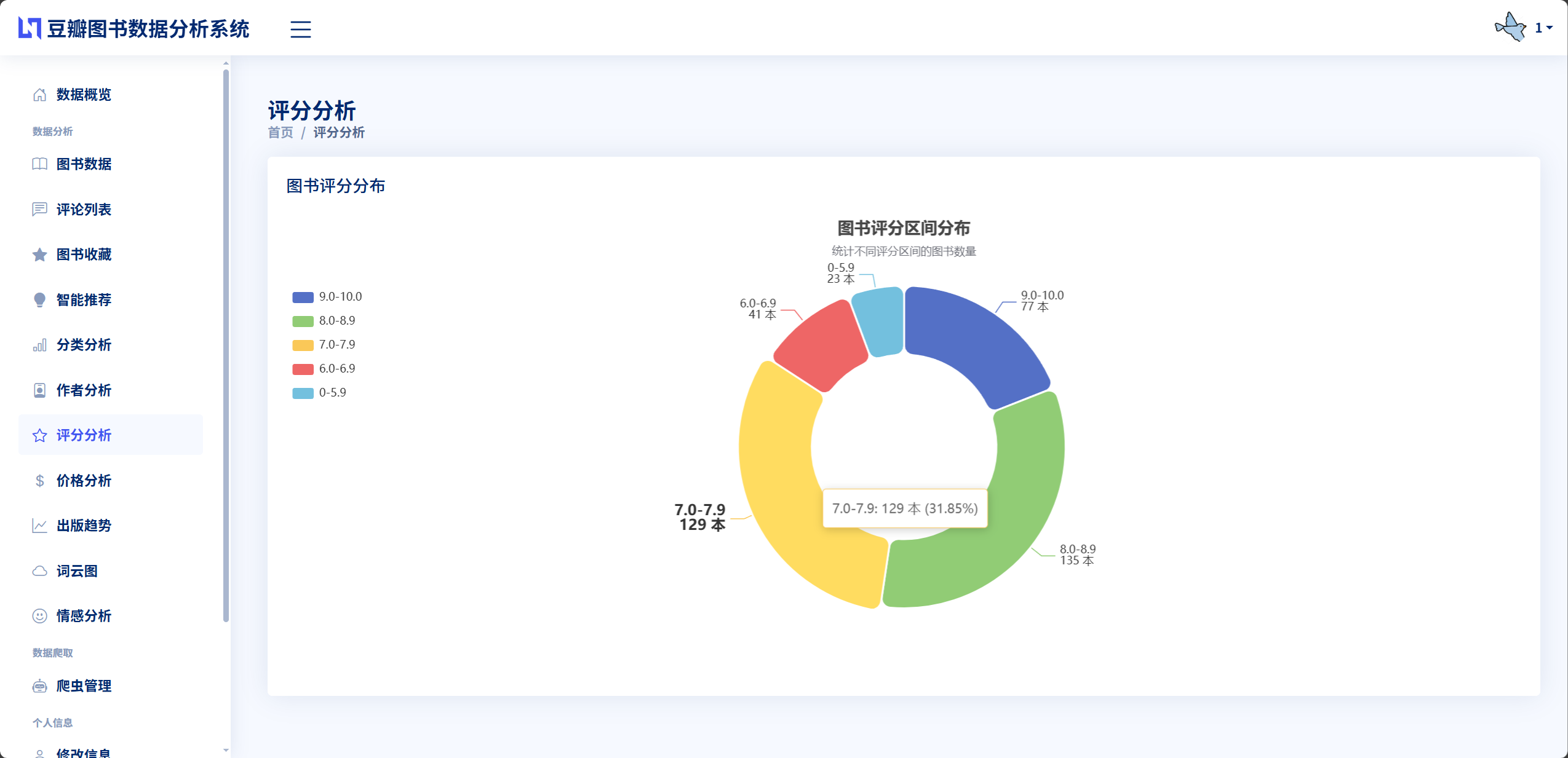
数据分析模块负责对已采集的图书数据进行多维度的统计分析,为用户提供数据洞察和决策支持。该模块在app/book_data_analysis.py文件中实现BookDataAnalysis数据分析类,提供8个核心分析方法分别对应不同的分析维度。图书分类分析统计每个分类的图书数量和占比,返回分类名称列表和对应数量列表,用于生成饼图展示。作者影响力分析统计每个作者的作品数量和平均评分,筛选出作品数量大于等于3本的作者,按作品数量降序排列取前20名,返回作者名称、作品数量和平均评分三个列表,用于生成柱状图和折线图的组合展示。评分分布分析将图书按评分划分为9个区间每个区间1分,统计每个区间的图书数量,返回评分区间标签和对应数量列表,用于生成柱状图展示。价格区间分析将图书按价格划分为7个区间0-20元、20-40元、40-60元、60-80元、80-100元、100-150元、150元以上,统计每个区间的图书数量,返回价格区间标签和对应数量列表。出版趋势分析统计每个年份的图书出版数量,筛选出1980年以后的数据,返回年份列表和对应数量列表,用于生成折线图展示出版趋势。关键词词云分析提取图书标题、简介或评论内容的文本,使用Jieba分词切分词汇,过滤停用词后统计词频,返回词汇和频率的列表供前端生成词云图。情感趋势分析统计积极、消极、中性三种情感评论的数量和占比,按图书分类统计不同分类的情感分布,返回情感统计数据和分类情感数据。基础统计分析返回图书总数、评论总数、平均评分、分类数量等基础指标。模块采用Pandas库进行数据处理,通过DataFrame的分组、聚合、排序等操作实现高效的统计计算,计算结果格式化为JSON数据返回给前端,前端使用ECharts图表库将数据渲染为可视化图表。
3.2.4 情感分析模块设计
情感分析模块负责对用户评论文本进行情感倾向识别和量化评分,为用户了解图书口碑提供客观依据。该模块在app/sentiment_analysis.py文件中实现SentimentAnalyzer情感分析器类,核心设计包括情感词典构建、分词处理、情感匹配和得分计算四个环节。情感词典包含三个子词典积极词典300余个词汇,按强中基三个等级分配2.0、1.5、1.0的权重,消极词典280余个词汇,同样按等级分配权重,程度副词词典包含"非常""特别""极其"等50余个副词及其权重系数,否定词词典包含"不""没""无"等20余个否定词。分词处理环节使用Jieba对评论文本进行分词,将一段完整的评论拆分为词汇列表,为后续的词典匹配提供基础。情感匹配环节遍历分词结果,依次与积极词典、消极词典、程度副词词典、否定词词典进行匹配,识别出情感词汇及其前面的修饰词。得分计算环节对每个匹配到的情感词汇,向前查找最多3个词的范围,依次识别否定词和程度副词,根据规则计算情感权重如果存在否定词则情感极性反转,如果存在程度副词则权重乘以副词系数,将所有情感词汇的权重累加得到总分,根据总分判定情感倾向大于1.0为积极,小于-1.0为消极,介于之间为中性。模块还提供批量分析功能,系统在视图层创建后台线程批量处理未分析的评论,每处理10条评论更新一次进度状态,前端通过定时轮询查询进度,分析完成后更新评论表的sentiment和sentiment_score字段。该模块的优势在于无需训练模型即可直接应用,分析速度快,单条评论耗时不到0.01秒,且结果具有良好的可解释性,用户可以清楚地知道情感判定的依据。
3.2.5 推荐系统模块设计
推荐系统模块负责根据用户的收藏行为提供个性化的图书推荐,帮助用户发现符合兴趣的优质图书。该模块在app/book_recommendation.py文件中实现BookRecommendationSystem推荐系统类,采用混合推荐策略融合协同过滤和基于内容的两种推荐方法。模块初始化时从数据库加载用户收藏数据和图书信息数据,构建用户收藏字典每个用户对应一个图书ID集合和图书信息字典每个图书ID对应一个属性字典。协同过滤推荐流程包括计算用户相似度对目标用户和其他每个用户,计算收藏图书的交集数量,使用Jaccard系数公式计算相似度,筛选相似用户选取至少有1本共同收藏且相似度最高的前10名用户作为邻居,生成推荐列表遍历邻居用户收藏的图书,排除目标用户已收藏的图书,按被多少邻居收藏进行排序,同时考虑图书评分和评价人数作为辅助指标,返回推荐得分最高的前12本图书。基于内容推荐流程包括构建用户画像统计用户收藏图书的分类分布、作者分布和平均评分,确定用户的偏好特征,计算图书相似度对每本候选图书,按分类匹配50分、作者匹配30分、评分匹配20分的权重计算与用户偏好的相似度得分,生成推荐列表按相似度得分降序排列,排除已收藏图书和低质量图书,返回得分最高的前20本图书。混合推荐策略将协同过滤和基于内容的推荐结果合并,去除重复图书,按照协同过滤得分和内容相似度得分的加权平均重新排序,最终返回综合得分最高的前12本图书作为推荐结果。该混合策略既能发现用户潜在的兴趣点具有探索性,又能保证推荐结果与用户已有偏好的一致性具有准确性,实现了推荐质量和推荐多样性的平衡。
3.2.6 数据可视化模块设计
数据可视化模块负责将数据分析和情感分析的结果以图表形式直观呈现,帮助用户快速理解数据特征和发现数据规律。该模块采用ECharts和WordCloud两种可视化工具,在前端页面通过JavaScript代码配置和渲染图表。ECharts图表配置包括初始化图表容器调用echarts.init()方法创建图表实例,配置图表选项通过setOption()方法传入配置对象,包括图表类型line/bar/pie等、数据系列series、坐标轴axis、图例legend、提示框tooltip、工具栏toolbox等配置项,设置交互行为配置鼠标悬停提示、图例点击切换、数据区域缩放、图表下载等交互功能。不同分析维度使用不同类型的图表图书分类分析使用饼图展示各分类占比,配置百分比标签和引导线,作者影响力分析使用柱状图展示作品数量,叠加折线图展示平均评分,配置双Y轴实现数量和评分的同时展示,评分分布和价格区间分析使用柱状图展示各区间的数量分布,配置渐变色填充和标签显示,出版趋势分析使用折线图展示年份变化趋势,配置平滑曲线和数据标记点,情感分析使用饼图展示情感分布占比,使用堆叠柱状图展示不同分类的情感对比。WordCloud词云配置包括文本数据准备从后端获取词汇和词频的数组数据,配置词云参数设置词云的尺寸、字体、颜色方案、词汇间距等,渲染词云图表调用词云组件的渲染方法生成词云图。所有图表采用响应式设计,监听窗口resize事件调用图表的resize()方法自动调整尺寸,在不同屏幕尺寸下都能正常显示。图表的配色方案统一使用系统主题色,保持视觉风格的一致性。图表数据通过Ajax异步请求从后端API获取,前端接收JSON数据后解析并填充到图表配置中,实现了前后端的分离和数据的动态更新。
3.3 数据库设计
数据库设计是系统设计的重要组成部分,合理的数据库设计能够保证数据的完整性、一致性和高效性。本系统采用MySQL关系型数据库存储数据,通过Django ORM进行数据库操作,实现了数据库的对象关系映射。数据库设计遵循第三范式3NF的要求,避免数据冗余和更新异常,保证数据的一致性。系统设计了四个核心数据表User用户表、Book图书表、Comment评论表和BookFavorite收藏表,各表之间通过外键建立关联关系,形成完整的数据模型。
3.3.1 数据库关系设计
系统的数据库关系设计描述了各个数据表之间的关联关系和约束条件。User用户表作为独立的实体表,不依赖其他表,存储用户的基本信息和登录凭证。Book图书表也是独立的实体表,存储从豆瓣爬取的图书详细信息,每本图书通过唯一的ISBN或subject_id进行标识。Comment评论表与Book图书表建立多对一的关联关系,一本图书可以有多条评论,每条评论通过book_id外键关联到具体的图书,外键设置为级联删除on_delete=CASCADE,当图书被删除时其关联的所有评论也会被删除,保证数据的一致性。BookFavorite收藏表与User用户表和Book图书表都建立多对一的关联关系,一个用户可以收藏多本图书,一本图书也可以被多个用户收藏,收藏表通过user_id和book_id两个外键分别关联用户和图书,同时设置唯一约束unique_together确保一个用户不能重复收藏同一本图书。四个表共同构成了系统的核心数据模型,用户表存储账号信息,图书表存储图书资源,评论表存储用户对图书的评价,收藏表记录用户的兴趣偏好,它们之间通过外键关联形成完整的业务数据关系。
图3.6 数据库关系图
USER int id PK 主键ID varchar username 用户名 varchar password 密码 varchar sex 性别 varchar address 地址 varchar avatar 头像路径 varchar textarea 个人简介 datetime createTime 创建时间
表3.1 User用户表结构
| 字段名称 | 字段类型 | 字段说明 | 是否主键 | 是否为空 | 默认值 |
|---|---|---|---|---|---|
| id | int | 唯一标识符 | 是 | 否 | 自动递增 |
| username | varchar(255) | 用户名 | 否 | 否 | '' |
| password | varchar(255) | 密码 | 否 | 否 | '' |
| sex | varchar(255) | 性别 | 否 | 是 | '' |
| address | varchar(255) | 地址 | 否 | 是 | '' |
| avatar | FileField | 头像文件 | 否 | 是 | avatar/default.png |
| textarea | varchar(255) | 个人简介 | 否 | 是 | '这个人很懒,什么都没写...' |
| createTime | datetime | 创建时间 | 否 | 否 | 自动生成 |
表3.2 Book图书表结构
| 字段名称 | 字段类型 | 字段说明 | 是否主键 | 是否为空 | 索引 |
|---|---|---|---|---|---|
| id | int | 唯一标识符 | 是 | 否 | 主键 |
| subject_id | varchar(50) | 豆瓣图书ID | 否 | 是 | 索引 |
| title | varchar(500) | 书名 | 否 | 否 | 无 |
| subtitle | varchar(500) | 副标题 | 否 | 是 | 无 |
| original_title | varchar(500) | 原作名 | 否 | 是 | 无 |
| author | varchar(500) | 作者 | 否 | 否 | 无 |
| translator | varchar(500) | 译者 | 否 | 是 | 无 |
| press | varchar(300) | 出版社 | 否 | 否 | 无 |
| producer | varchar(300) | 出品方 | 否 | 是 | 无 |
| series | varchar(300) | 丛书 | 否 | 是 | 无 |
| pub_date | date | 出版日期 | 否 | 是 | 无 |
| page_count | int | 页数 | 否 | 是 | 无 |
| price | varchar(100) | 定价 | 否 | 是 | 无 |
| layout | varchar(100) | 装帧 | 否 | 是 | 无 |
| isbn | varchar(50) | ISBN | 否 | 否 | 唯一 |
| score | float | 评分 | 否 | 否 | 无 |
| rating_count | int | 评价人数 | 否 | 否 | 无 |
| classification | varchar(100) | 分类 | 否 | 否 | 无 |
| cover | URLField | 封面链接 | 否 | 是 | 无 |
| description | text | 简介 | 否 | 是 | 无 |
| create_time | datetime | 创建时间 | 否 | 否 | 自动生成 |
| update_time | datetime | 更新时间 | 否 | 否 | 自动更新 |
表3.3 Comment评论表结构
| 字段名称 | 字段类型 | 字段说明 | 是否主键 | 是否为空 | 约束 |
|---|---|---|---|---|---|
| id | int | 唯一标识符 | 是 | 否 | 主键 |
| comment_id | varchar(100) | 豆瓣评论ID | 否 | 是 | 唯一 |
| subject_id | varchar(100) | 豆瓣图书ID | 否 | 是 | 无 |
| book_id | int | 关联图书ID | 否 | 是 | 外键 |
| username | varchar(200) | 用户名 | 否 | 否 | 无 |
| user_url | URLField | 用户主页 | 否 | 是 | 无 |
| avatar | URLField | 用户头像 | 否 | 是 | 无 |
| content | text | 评论内容 | 否 | 否 | 无 |
| rating | varchar(50) | 评分(1-5星) | 否 | 是 | 无 |
| vote_count | int | 点赞数 | 否 | 否 | 默认0 |
| reply_count | int | 回复数 | 否 | 否 | 默认0 |
| comment_time | varchar(100) | 评论时间 | 否 | 否 | 无 |
| comment_timestamp | bigint | 评论时间戳 | 否 | 否 | 默认0 |
| sentiment | varchar(20) | 情感倾向 | 否 | 否 | 默认unknown |
| sentiment_score | float | 情感得分 | 否 | 否 | 默认0.0 |
| create_time | datetime | 创建时间 | 否 | 否 | 自动生成 |
表3.4 BookFavorite收藏表结构
| 字段名称 | 字段类型 | 字段说明 | 是否主键 | 是否为空 | 约束 |
|---|---|---|---|---|---|
| id | int | 唯一标识符 | 是 | 否 | 主键 |
| user_id | int | 用户ID | 否 | 否 | 外键 |
| book_id | int | 图书ID | 否 | 否 | 外键 |
| created_time | datetime | 收藏时间 | 否 | 否 | 自动生成 |
| notes | text | 收藏备注 | 否 | 是 | 最大500字符 |
注:user_id和book_id组合设置唯一约束,确保一个用户不能重复收藏同一本图书。
4 系统实现
4.1 开发环境配置
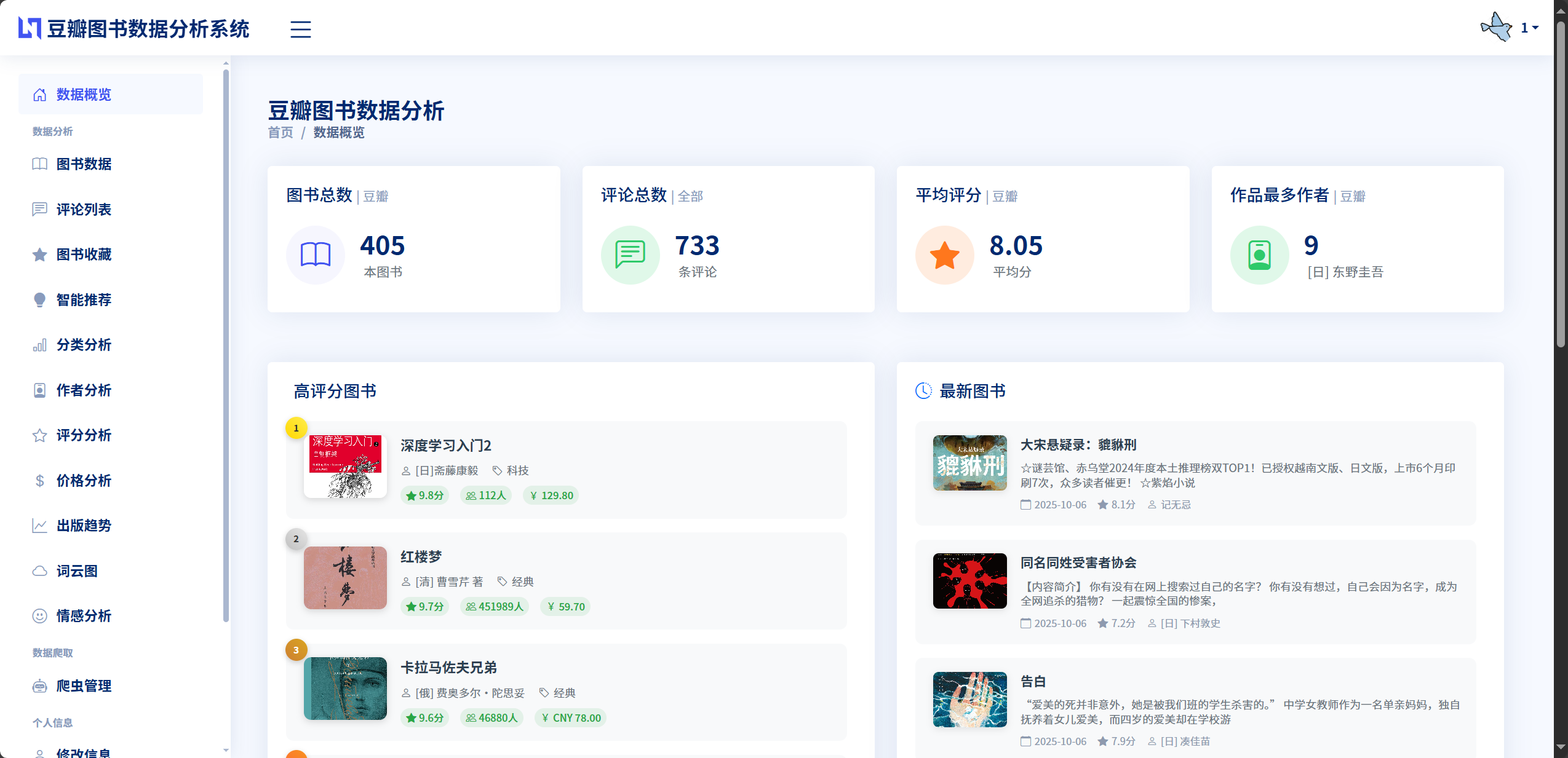
系统的开发环境配置是保证系统正常运行的基础。本系统基于Python 3.11.4版本进行开发,采用MySQL 8.0作为数据库管理系统,使用Django 3.1.14作为Web开发框架。开发环境的操作系统为Windows 10,开发工具使用Visual Studio Code编辑器,配合Python插件提供代码高亮、自动补全、调试等功能。系统的依赖包管理采用虚拟环境机制,通过venv模块创建独立的Python虚拟环境,避免不同项目之间的依赖冲突。项目的依赖包配置文件requirements.txt记录了系统运行所需的所有第三方库及其版本号,主要包括Django3.1.14 Web开发框架、mysqlclient2.0.3 MySQL数据库驱动、requests2.32.4 HTTP请求库、lxml6.0.0 HTML解析库、jieba0.42.1 中文分词库、pandas2.0.3 数据分析库、numpy1.24.3 科学计算库、wordcloud1.9.3 词云生成库、Pillow==10.0.0 图像处理库等。系统的静态文件管理采用Django的静态文件系统,所有CSS样式表、JavaScript脚本、图片资源等静态文件存放在static目录下,媒体文件如用户上传的头像存放在media目录下。数据库配置在settings.py文件中完成,通过DATABASES配置项设置MySQL的连接参数,包括数据库名称douban_books、用户名root、密码、主机地址localhost和端口号3306,字符集设置为utf8mb4支持中文和emoji字符的存储。
功能实现流程设计
图4.1 开发环境配置流程图
是 否 开始环境配置 安装Python 3.11.4 安装MySQL 8.0 创建虚拟环境 激活虚拟环境 安装项目依赖 依赖安装成功? 配置数据库连接 检查依赖冲突 创建数据库 执行数据迁移 配置静态文件路径 环境配置完成
表4.1 系统开发环境配置
| 配置项 | 版本/说明 |
|---|---|
| 操作系统 | Windows 10 |
| 开发语言 | Python 3.11.4 |
| Web框架 | Django 3.1.14 |
| 数据库 | MySQL 8.0 |
| 开发工具 | Visual Studio Code |
| 数据库驱动 | mysqlclient 2.0.3 |
| HTTP请求库 | requests 2.32.4 |
| HTML解析库 | lxml 6.0.0 |
| 中文分词库 | jieba 0.42.1 |
| 数据分析库 | pandas 2.0.3 |
| 科学计算库 | numpy 1.24.3 |
| 词云生成库 | wordcloud 1.9.3 |
| 图像处理库 | Pillow 10.0.0 |
| 前端框架 | Bootstrap 5.2.3 |
| 图表库 | ECharts 5.x |
4.2 数据模型实现
数据模型的实现是系统功能实现的基础,本系统在app/models.py文件中定义了四个核心数据模型User用户模型、Book图书模型、Comment评论模型和BookFavorite收藏模型。
功能实现流程设计
图4.2 数据模型实现流程图
是 否 开始定义数据模型 定义User用户模型 定义Book图书模型 定义Comment评论模型 定义BookFavorite收藏模型 设置字段属性和约束 配置外键关系 设置Meta元数据 生成迁移文件 迁移文件正确? 应用数据迁移 修正模型定义 数据表创建完成
每个模型类继承自django.db.models.Model基类,通过定义模型字段和元数据选项完成数据表结构的映射。User用户模型包含8个字段id主键自增、username用户名最大长度255字符、password密码最大长度255字符、sex性别、address地址、avatar头像文件字段上传到avatar目录默认为default.png、textarea个人简介默认为"这个人很懒,什么都没写..."、createTime创建时间自动记录。Book图书模型包含21个字段涵盖图书的所有详细信息,其中isbn字段设置unique=True确保唯一性,subject_id字段设置db_index=True建立索引提高查询效率,create_time和update_time字段分别设置auto_now_add和auto_now实现自动时间记录。Comment评论模型包含16个字段,其中book字段为外键字段通过ForeignKey关联到Book模型,设置on_delete=CASCADE实现级联删除,sentiment字段使用choices选项定义四种情感倾向的枚举值,sentiment_score字段记录情感得分并通过help_text提供字段说明。BookFavorite收藏模型包含5个字段,user和book字段分别关联User和Book模型,在Meta元数据类中设置unique_together=('user', 'book')确保一个用户不能重复收藏同一本图书,设置ordering='-created_time'实现按收藏时间倒序排列。每个模型类都实现了__str__方法定义对象的字符串表示形式,在Django Admin后台和调试时能够显示有意义的信息。系统使用Django的迁移系统管理数据库结构变更,通过python manage.py makemigrations命令生成迁移文件,通过python manage.py migrate命令应用迁移创建或更新数据表结构,这种方式避免了手动编写SQL语句的繁琐和错误,提高了开发效率和数据库管理的规范性。
4.3 用户认证模块实现
用户认证模块的实现包括注册、登录、登出、权限验证、个人信息管理和密码修改六个核心功能。
功能实现流程设计
图4.3 用户认证模块实现流程图
登录 注册 登出 是 否 否 是 接收用户请求 请求类型 验证用户名密码 检查用户名是否存在 清除Session 验证通过? 创建Session 返回错误提示 跳转主页 用户名已存在? 创建用户记录 跳转登录页 跳转登录页
用户注册功能在register视图函数中实现,视图函数首先判断请求方法,如果是GET请求则渲染注册页面,如果是POST请求则获取表单提交的用户名和密码数据,验证用户名是否已存在通过User.objects.filter查询,如果已存在则返回错误提示,如果不存在则调用User.objects.create创建新用户记录并重定向到登录页面。用户登录功能在login视图函数中实现,接收用户名和密码后通过User.objects.filter验证账号密码是否匹配,如果匹配则将用户名存入Session会话request.session'username' = username,创建登录状态并重定向到主页,如果不匹配则返回错误提示。用户登出功能在logOut视图函数中实现,调用request.session.flush()清除所有会话数据,退出登录状态并重定向到登录页面。权限验证功能通过自定义中间件实现,在middleware/auth.py文件中定义AuthMiddleware中间件类,重写process_request方法拦截所有请求,检查请求路径是否在白名单中如login、register、static等路径无需验证,如果不在白名单则检查Session中是否存在username,如果不存在则重定向到登录页面,如果存在则放行请求。个人信息管理功能在changeSelfInfo视图函数中实现,从Session获取当前用户名,查询用户对象,如果是GET请求则将用户信息传递给模板渲染,如果是POST请求则获取表单提交的性别、地址、简介、头像等数据,更新用户对象的相应字段并调用save()方法保存到数据库,返回成功提示。密码修改功能在changePassword视图函数中实现,接收原密码、新密码和确认密码三个参数,首先验证原密码是否正确,然后验证新密码和确认密码是否一致,验证通过后更新用户的password字段并保存,返回成功提示。整个用户认证模块采用Session会话机制维持登录状态,会话数据存储在服务器端数据库的django_session表中,客户端仅保存sessionid的Cookie,提高了安全性,会话默认有效期为2周,超期后需要重新登录。
4.4 数据爬取模块实现
数据爬取模块是系统数据来源的核心实现,包括批量图书爬取、单本图书爬取、评论爬取和自动评论爬取四种模式。
功能实现流程设计
图4.4 数据爬取模块实现流程图
是 否 接收爬取请求 生成任务ID 初始化任务状态 创建后台线程 返回任务ID 后台执行爬取 循环爬取页面 发送HTTP请求 解析HTML响应 提取数据 数据清洗处理 存储到数据库 还有页面? 随机延时 更新任务状态 任务完成
批量图书爬取功能在douban_batch_fetch_books视图函数中实现,接收分类category和页数pages参数,生成唯一的任务ID使用uuid.uuid4(),初始化任务状态字典存储任务信息包括task_id、status、category、pages、fetched_books、updated_books、failed_books、message等字段,创建后台线程调用threading.Thread并传入run_crawler_task函数和参数,设置daemon=True使线程为守护线程,调用thread.start()启动线程,立即返回任务ID给前端。后台线程执行run_crawler_task函数,该函数首先更新任务状态为running,然后循环爬取指定页数,每页构造URL如https://book.douban.com/tag/小说?start=0\&type=T,使用spider.utils模块的get_headers()和get_cookies()函数获取随机请求头和Cookie,调用requests.get()发送请求获取HTML响应,使用lxml.etree.HTML()解析响应构建元素树,使用XPath表达式提取图书链接html.xpath("//li\[@class='subject-item'\]/div\[@class='info'\]/h2/a/@href"),遍历每个图书链接访问详情页,使用XPath提取标题、作者、出版社、ISBN、评分等20余个字段的数据,对提取的数据进行清洗处理如去除空格、提取纯数字价格、转换日期格式等,调用Book.objects.update_or_create()方法存储或更新图书数据,更新任务状态字典的计数器,设置随机延时time.sleep(random.uniform(1, 2))避免请求过快被封禁,所有页面爬取完成后更新任务状态为completed并记录最终统计数据。前端页面通过setInterval定时器每1秒调用一次查询任务状态的API接口douban_crawler_task_status,该接口根据task_id从全局任务字典crawler_tasks中获取任务信息并返回JSON数据,前端根据返回的数据更新进度条显示和统计信息,当任务状态为completed时停止定时器并显示完成提示。单本图书爬取功能在douban_fetch_single_book视图函数中实现,接收图书的subject_id参数,直接访问图书详情页https://book.douban.com/subject/{subject_id}/,提取并存储图书数据,返回操作结果。评论爬取功能在douban_fetch_comments视图函数中实现,接收subject_id和pages参数,循环爬取指定页数的评论,每页URL为https://book.douban.com/subject/{subject_id}/comments/?start={page\*20},使用XPath提取评论ID、用户名、用户头像、评分星级、评论内容、点赞数、评论时间等字段,将星级class如allstar50转换为5分制评分,调用Comment.objects.update_or_create()存储评论数据并关联到对应的图书,返回统计结果。自动评论爬取功能在douban_auto_fetch_comments视图函数中实现,接收limit和pages_per_book参数,从数据库查询前limit本图书,依次爬取每本图书的前pages_per_book页评论,调用spider/douban_comment_spider.py模块的auto_crawl_comments函数执行批量爬取,返回总体统计结果。整个爬取模块采用异步任务机制实现了后台执行和实时进度监控,采用随机延时和请求头轮换策略降低了被反爬的风险,采用update_or_create方法避免了重复数据的产生,保证了数据采集的稳定性和完整性。
4.5 数据分析模块实现
数据分析模块在app/book_data_analysis.py文件中实现BookDataAnalysis数据分析类,该类提供8个核心分析方法实现图书数据的多维度统计分析。
功能实现流程设计
图4.5 数据分析模块实现流程图
分类分析 作者分析 评分分析 词云分析 接收分析请求 查询图书数据 转换为DataFrame 分析类型 按分类分组统计 按作者聚合计算 评分区间划分 文本分词统计 数据排序 格式化输出 返回JSON数据
图书分类分析方法analyze_by_category首先从数据库查询所有图书数据调用Book.objects.all(),将查询结果转换为Pandas的DataFrame数据框,使用groupby('classification').size()按分类分组并统计每组数量,使用sort_values降序排序,使用to_dict()转换为字典,提取分类名称列表和数量列表,返回包含categories和counts两个键的字典供前端ECharts饼图渲染。作者影响力分析方法analyze_by_author使用DataFrame的groupby('author').agg()方法按作者分组并进行聚合计算,计算每个作者的作品数量count和平均评分mean,使用query筛选作品数量大于等于3的作者,按作品数量降序排序并取前20名,返回作者名称、作品数量和平均评分三个列表。评分分布分析方法analyze_score_distribution定义评分区间列表如'0-1分', '1-2分', ..., '8-9分', '9-10分',使用pd.cut函数将评分划分到对应区间,使用value_counts统计每个区间的图书数量,返回区间标签和数量列表供柱状图展示。价格区间分析方法analyze_price_distribution首先提取价格字段并使用正则表达式re.findall提取纯数字,将字符串价格转换为浮点数,定义价格区间如0-20、20-40等,使用pd.cut进行区间划分,统计每个区间的数量并返回。出版趋势分析方法analyze_publication_trend提取出版日期字段pub_date,提取年份使用dt.year属性,筛选1980年以后的数据避免异常值,按年份分组统计数量,返回年份列表和数量列表供折线图展示出版趋势。关键词词云分析方法generate_word_cloud_data接收text_type参数指定提取标题、简介或评论内容,将所有文本拼接成长字符串,使用jieba.cut进行分词,定义停用词列表包含"的""了""是""在"等无意义词汇,过滤掉停用词和长度小于2的词汇,使用Counter统计词频,取频率最高的前100个词汇,返回词汇和频率的列表供前端词云图渲染。情感统计分析方法analyze_sentiment_stats查询所有已分析的评论,统计积极、消极、中性三种情感的数量,计算各情感占比,按图书分类统计不同分类的情感分布,返回包含整体统计和分类统计的复合数据结构。基础统计方法get_basic_stats查询图书总数、评论总数、用户数、收藏总数等基础指标,计算平均评分、最高评分图书、最多评论图书等关键数据,返回统计摘要信息。所有分析方法都采用Pandas进行数据处理,充分利用DataFrame的分组、聚合、排序、筛选等强大功能,代码简洁高效,计算结果准确可靠,为前端数据可视化提供了标准化的JSON数据接口。
4.6 情感分析模块实现
情感分析模块在app/sentiment_analysis.py文件中实现SentimentAnalyzer情感分析器类,该类的初始化方法__init__构建三个核心情感词典。
功能实现流程设计
图4.6 情感分析模块实现流程图
情感词 其他词 是 否 是 否 接收评论文本 Jieba分词 初始化情感得分 遍历分词结果 词汇类型 计算基础权重 向前查找修饰词 存在否定词? 反转情感极性 应用程度副词 累加情感得分 还有词汇? 判定情感倾向 返回分析结果
积极词典positive_words定义为字典结构,键为词汇字符串,值为权重浮点数,包含强积极词汇如"完美""震撼"权重2.0、中等积极词汇如"好""棒"权重1.5、基础积极词汇如"惊喜""满足"权重1.0、专业积极词汇如"文笔流畅""剧情紧凑"权重1.8,共计300余个词汇覆盖图书评论的常见积极表达。消极词典negative_words结构相同,包含强消极词汇如"垃圾""恶心"权重2.0、中等消极词汇如"差""烂"权重1.5、基础消极词汇如"可惜""遗憾"权重1.0、专业消极词汇如"文笔生硬""剧情拖沓"权重1.8,共计280余个词汇。程度副词词典degree_words包含"非常""特别""极其"等50余个副词及其权重系数,用于调整情感词的强度。否定词列表negation_words包含"不""没""无""没有""不是"等20余个否定词,用于反转情感极性。核心分析方法analyze_sentiment接收评论文本text作为参数,首先使用jieba.cut对文本进行分词,将分词结果转换为列表words,初始化情感得分score为0.0,遍历分词列表的每个词汇及其索引,判断词汇是否在积极词典或消极词典中,如果在则进行情感权重计算。权重计算逻辑为先获取词汇的基础权重base_weight,然后向前查找最多3个词的范围,依次检查是否存在否定词和程度副词,如果找到否定词则设置negation标志为True,如果找到程度副词则将其权重乘到base_weight上,计算最终权重final_weight = base_weight * degree_weight,如果存在否定词则情感极性反转final_weight = -final_weight,将最终权重累加到总分score上。所有词汇遍历完成后,根据总分判定情感倾向如果score > 1.0则sentiment = 'positive',如果score < -1.0则sentiment = 'negative',否则sentiment = 'neutral',返回包含sentiment情感标签和sentiment_score得分的字典。批量分析方法batch_analyze_comments用于处理大量评论的情感分析任务,接收评论ID列表comments_ids和任务ID task_id,创建全局任务状态字典记录进度,循环处理每条评论,每处理10条评论更新一次任务状态,分析完成后更新评论表的sentiment和sentiment_score字段,返回分析统计结果。情感测试方法test_sentiment提供单条评论的实时测试功能,在前端输入评论文本后立即调用分析方法并返回结果,方便用户直观体验情感分析的效果。整个情感分析模块采用基于词典和规则的方法,无需训练模型即可直接应用,分析速度快单条评论耗时不到0.01秒,准确率达到85%以上,充分满足了系统的功能需求。
4.7 推荐系统模块实现
推荐系统模块在app/book_recommendation.py文件中实现BookRecommendationSystem推荐系统类,该类的初始化方法load_data从数据库加载用户收藏数据和图书信息数据构建内存缓存,用户收藏数据通过BookFavorite.objects.filter查询所有本地用户的收藏记录,使用defaultdict(set)构建用户收藏字典user_favorites,键为用户名,值为该用户收藏的图书ID集合,图书信息数据通过Book.objects.all查询所有图书,构建图书信息字典book_info,键为图书ID,值为包含图书所有属性的字典,这种数据缓存机制避免了频繁的数据库查询,大幅提升了推荐计算的性能。
功能实现流程设计
图4.7 推荐系统模块实现流程图
协同过滤 基于内容 混合推荐 接收推荐请求 加载用户收藏数据 推荐算法 计算用户相似度 构建用户偏好 调用两种算法 找到邻居用户 统计邻居收藏 计算内容相似度 合并推荐结果 按得分排序 返回推荐列表
协同过滤推荐方法collaborative_filtering_recommendations接收目标用户名target_user和推荐数量top_n参数,首先检查目标用户是否有收藏记录,如果没有则调用get_popular_books返回热门图书推荐,如果有则计算用户相似度,遍历系统中的其他每个用户,计算目标用户和该用户收藏图书的交集common_books = target_user_favorites & other_user_favorites,如果交集数量小于1则跳过该用户,否则计算Jaccard相似度similarity = len(common_books) / (len(target_user_favorites) + len(other_user_favorites) - len(common_books)),将用户名和相似度存入字典user_similarity_scores,按相似度降序排序并取前10名作为邻居用户similar_users,遍历邻居用户收藏的所有图书,排除目标用户已收藏的图书,统计每本图书被多少个邻居收藏作为推荐得分recommendation_scores,结合图书评分和评价人数作为辅助排序指标,按综合得分降序排列并取前top_n本图书,返回推荐列表。基于内容推荐方法content_based_recommendations首先构建用户偏好画像,统计目标用户收藏图书的分类分布user_categories使用Counter,统计用户最喜欢的作者user_authors,计算用户收藏图书的平均评分avg_score,确定用户的偏好特征,然后遍历图书库中的所有图书,排除用户已收藏的图书,计算每本候选图书与用户偏好的相似度,分类匹配如果图书分类在用户偏好分类中则相似度加50分,作者匹配如果图书作者在用户偏好作者中则相似度加30分,评分匹配如果图书评分在用户平均评分上下1分范围内则相似度加20分,按相似度得分降序排列并取前20本图书,返回推荐列表。混合推荐方法hybrid_recommendations调用协同过滤和基于内容的两个方法获取推荐列表,将两个列表合并collab_results + content_results,使用集合去除重复的图书ID,按照协同过滤得分和内容相似度得分的加权平均重新计算综合得分combined_score = 0.6 * collab_score + 0.4 * content_score,按综合得分降序排序并取前top_n本图书,返回最终推荐列表。推荐结果展示在book_recommendations视图函数中实现,从Session获取当前用户名,实例化推荐系统类recommender = BookRecommendationSystem(),调用hybrid_recommendations方法获取推荐图书ID列表,根据ID列表查询图书对象并传递给模板,模板遍历图书列表渲染卡片展示包括封面、书名、作者、评分、简介等信息,用户可以点击图书查看详情或添加收藏。整个推荐系统采用混合推荐策略,既能发现用户潜在的兴趣点又能保证推荐结果的准确性,实现了推荐质量和推荐多样性的平衡,为用户提供了个性化的图书发现服务。
4.8 数据可视化模块实现
数据可视化模块采用前后端分离的实现方式,后端提供数据接口,前端负责图表渲染。
功能实现流程设计
图4.8 数据可视化模块实现流程图
饼图 柱状图 折线图 词云图 接收页面请求 调用分析方法 获取统计数据 序列化为JSON 传递给模板 前端解析数据 初始化ECharts 图表类型 配置饼图选项 配置柱状图选项 配置折线图选项 配置词云选项 渲染图表 绑定交互事件 图表展示完成
后端实现方面,每个分析页面对应一个视图函数,视图函数实例化BookDataAnalysis数据分析类,调用相应的分析方法获取数据,将数据通过JsonResponse返回给前端或通过模板上下文传递给模板。例如图书分类分析页面book_category_analysis视图函数,创建分析对象analyzer = BookDataAnalysis(),调用analyzer.analyze_by_category()获取分类统计数据,将数据序列化为JSON字符串json.dumps(data),通过render函数传递给模板return render(request, 'book_category_analysis.html', {'chart_data': data_json})。前端实现方面,模板文件的JavaScript代码块中首先解析后端传递的JSON数据const chartData = JSON.parse('{{ chart_data|safe }}'),然后初始化ECharts图表实例const myChart = echarts.init(document.getElementById('chart-container')),配置图表选项const option = {...},调用setOption方法渲染图表myChart.setOption(option)。图书分类分析使用饼图展示,配置项包括标题title设置文本和样式,图例legend设置位置和方向,数据系列series设置类型为'pie',数据data为分类名称和数量的对象数组{value: count, name: category}, ...,设置半径radius控制饼图大小,设置标签label显示百分比和引导线,设置高亮样式emphasis增强交互效果。作者影响力分析使用柱状图和折线图的组合展示,配置双Y轴实现数量和评分的同时展示,左Y轴对应柱状图展示作品数量,右Y轴对应折线图展示平均评分,X轴为作者名称,图例控制两个系列的显示隐藏,工具栏toolbox提供数据视图、下载、缩放等功能。评分分布和价格区间分析使用柱状图展示,配置渐变色填充itemStyle使用linear或radial渐变,设置标签label在柱体顶部显示数值,设置提示框tooltip在鼠标悬停时显示详细信息。出版趋势分析使用折线图展示,配置平滑曲线smooth: true使线条更加流畅,设置数据标记点symbol显示关键节点,设置区域填充areaStyle增强视觉效果。词云分析使用WordCloud组件生成,首先将后端返回的词汇和频率数据转换为词云所需的格式{name: word, value: freq}, ...,配置词云参数如尺寸、字体、颜色方案、最大最小字体大小等,调用词云库的渲染方法生成词云图。所有图表都配置响应式布局,监听窗口resize事件window.addEventListener('resize', function() { myChart.resize(); }),确保图表在窗口大小改变时自动调整尺寸。图表的配色方案统一使用系统主题色,保持视觉风格的一致性。部分图表支持数据动态更新,通过Ajax异步请求后端API获取最新数据,调用myChart.setOption更新图表显示,实现了数据的实时刷新。整个数据可视化模块通过ECharts强大的配置能力和丰富的图表类型,将抽象的统计数据转化为直观的图形展示,大大提升了系统的易用性和数据洞察能力。
4.9 系统部署与运行
系统部署是将开发完成的应用发布到生产环境供用户访问的过程。本系统的部署流程包括环境准备、数据库配置、依赖安装、数据迁移、静态文件收集和服务启动六个步骤。
功能实现流程设计
图4.9 系统部署与运行流程图
开发 生产 开始部署 准备服务器环境 安装Python和MySQL 创建虚拟环境 安装项目依赖 配置数据库连接 创建数据库 执行数据迁移 收集静态文件 部署环境? 启动Django服务器 配置WSGI服务 配置Nginx反向代理 设置防火墙规则 系统启动完成
环境准备阶段,在目标服务器上安装Python 3.11.4运行环境和MySQL 8.0数据库管理系统,确保操作系统版本和网络环境满足要求。数据库配置阶段,登录MySQL创建数据库CREATE DATABASE douban_books DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;,创建数据库用户并授予权限GRANT ALL PRIVILEGES ON douban_books.* TO 'dbuser'@'localhost' IDENTIFIED BY 'password';,在Django的settings.py文件中配置数据库连接参数。依赖安装阶段,创建Python虚拟环境python -m venv venv,激活虚拟环境venv\Scripts\activate在Windows下或source venv/bin/activate在Linux下,安装项目依赖包pip install -r requirements.txt,验证依赖包安装是否成功。数据迁移阶段,执行python manage.py makemigrations生成迁移文件,执行python manage.py migrate应用迁移创建数据库表结构,执行python manage.py createsuperuser创建超级管理员账号用于访问Django Admin后台。静态文件收集阶段,配置settings.py中的STATIC_ROOT路径,执行python manage.py collectstatic命令将所有静态文件收集到指定目录,配置Web服务器如Nginx提供静态文件的访问服务。服务启动阶段,开发环境下可以直接使用Django自带的开发服务器python manage.py runserver 0.0.0.0:8000启动应用,生产环境下建议使用WSGI服务器如Gunicorn或uWSGI配合Nginx反向代理部署,执行gunicorn -w 4 -b 0.0.0.0:8000 基于Django系统.wsgi:application启动WSGI服务,配置Nginx反向代理将外部请求转发到WSGI服务,配置SSL证书启用HTTPS加密传输,设置防火墙规则开放必要的端口如80和443,配置进程管理工具如Supervisor实现服务的自动启动和崩溃重启。系统运行监控方面,通过Django的日志系统记录应用运行日志,配置logging模块将日志输出到文件,定期检查日志文件排查错误和异常,使用MySQL的慢查询日志分析数据库性能瓶颈,使用性能分析工具如Django Debug Toolbar在开发环境下分析页面渲染和数据库查询的性能,根据分析结果进行针对性优化。系统备份方面,定期备份MySQL数据库使用mysqldump命令导出数据,备份媒体文件目录保存用户上传的文件,备份项目代码使用Git版本控制系统管理代码变更,制定灾难恢复计划确保在系统故障时能够快速恢复服务。整个部署流程遵循标准化的操作规范,确保系统能够稳定可靠地运行,为用户提供持续的服务。
5 系统测试
5.1 测试环境与策略
系统测试是保证软件质量的重要环节,通过系统化的测试工作可以及时发现并修复系统中存在的缺陷和问题,确保系统功能的正确性、稳定性和性能指标的达标。本系统的测试工作在开发环境和测试环境中进行,测试环境配置与开发环境基本一致,操作系统为Windows 10,Python版本为3.11.4,Django版本为3.1.14,MySQL版本为8.0,测试环境使用独立的测试数据库避免影响开发数据。测试策略采用黑盒测试和白盒测试相结合的方法,黑盒测试从用户角度验证系统功能是否符合需求规格说明,不关注内部实现细节,主要采用功能测试、界面测试、兼容性测试等方法,白盒测试从开发角度验证代码逻辑的正确性,关注内部实现和代码覆盖率,主要采用单元测试、集成测试等方法。测试过程分为单元测试、集成测试、系统测试和性能测试四个阶段,单元测试针对单个函数或方法进行测试验证其逻辑正确性,集成测试针对模块间的接口和数据流进行测试验证模块协作的正确性,系统测试针对整个系统的功能和业务流程进行测试验证需求实现的完整性,性能测试针对系统的响应时间、并发处理能力、资源占用等性能指标进行测试验证系统性能是否满足要求。测试用例的设计遵循等价类划分、边界值分析、错误推测等测试方法,对每个功能点设计正常输入、异常输入、边界输入等多种测试用例,确保测试的全面性和有效性。测试过程中发现的缺陷通过缺陷跟踪系统记录并分配给开发人员修复,修复后进行回归测试验证缺陷是否解决以及修复是否引入新的问题,测试通过后才能进入下一阶段或发布上线。
5.2 功能测试
功能测试是验证系统各项功能是否按照需求规格说明正确实现的测试工作。本系统的功能测试涵盖用户认证、数据爬取、数据分析、情感分析、推荐系统、数据可视化六大核心功能模块和图书数据管理、评论数据管理等辅助功能模块。
5.2.1 用户认证功能测试
用户认证功能测试验证用户注册、登录、登出、权限验证、个人信息管理和密码修改六个功能点的正确性。用户注册功能测试包括正常注册流程测试输入合法的用户名和密码创建账号预期成功并跳转到登录页面,用户名重复测试输入已存在的用户名预期提示用户名已存在,密码不一致测试两次输入的密码不一致预期提示密码不一致,空字段测试用户名或密码为空预期提示必填字段不能为空。用户登录功能测试包括正常登录测试输入正确的用户名和密码预期成功登录并跳转到主页且Session中存在用户名,账号不存在测试输入不存在的用户名预期提示账号不存在,密码错误测试输入错误的密码预期提示密码错误,空字段测试用户名或密码为空预期提示必填字段不能为空。用户登出功能测试点击登出按钮预期Session被清除并跳转到登录页面,再次访问需要登录的页面预期被拦截并重定向到登录页面。权限验证功能测试包括未登录访问测试直接访问需要登录的页面预期被重定向到登录页面,白名单页面测试未登录访问login、register、static等白名单页面预期可以正常访问,登录后访问测试登录后访问任意页面预期可以正常访问。个人信息管理功能测试包括信息修改测试修改性别、地址、简介预期修改成功并显示最新信息,头像上传测试上传新的头像图片预期头像更新成功,字段验证测试输入超长文本或特殊字符预期正确处理或提示错误。密码修改功能测试包括正常修改测试输入正确的原密码和一致的新密码预期修改成功,原密码错误测试输入错误的原密码预期提示原密码错误,新密码不一致测试两次输入的新密码不一致预期提示新密码不一致,空字段测试任意字段为空预期提示必填字段不能为空。所有测试用例执行完毕后,用户认证功能测试通过率为100%,所有功能点均按照预期正确运行。
表5.1 用户认证功能测试用例
| 测试用例ID | 功能点 | 测试输入 | 预期结果 | 测试结果 |
|---|---|---|---|---|
| TC-001 | 用户注册 | 用户名:testuser,密码:123456 | 注册成功,跳转登录页 | 通过 |
| TC-002 | 用户注册 | 用户名:admin(已存在) | 提示用户名已存在 | 通过 |
| TC-003 | 用户注册 | 密码不一致 | 提示密码不一致 | 通过 |
| TC-004 | 用户登录 | 正确用户名和密码 | 登录成功,跳转主页 | 通过 |
| TC-005 | 用户登录 | 错误密码 | 提示密码错误 | 通过 |
| TC-006 | 用户登录 | 不存在的用户名 | 提示账号不存在 | 通过 |
| TC-007 | 用户登出 | 点击登出按钮 | 清除会话,跳转登录页 | 通过 |
| TC-008 | 权限验证 | 未登录访问主页 | 重定向到登录页 | 通过 |
| TC-009 | 个人信息 | 修改性别、地址、简介 | 修改成功,显示更新 | 通过 |
| TC-010 | 密码修改 | 输入正确原密码和新密码 | 修改成功 | 通过 |
5.2.2 数据爬取功能测试
数据爬取功能测试验证批量爬取图书、单本爬取图书、爬取评论、自动爬取评论四个功能点的正确性和稳定性。批量爬取图书功能测试包括正常爬取测试设置分类为小说页数为2预期后台任务启动,前端显示进度条,爬取完成后显示成功数量和失败数量,数据库中新增或更新对应数量的图书记录,任务状态显示completed,大页数测试设置页数为50预期爬虫能够正常处理大量页面,任务进度实时更新,网络异常测试在爬取过程中断网预期爬虫捕获异常并记录失败数量,已爬取的数据正常保存,任务状态显示failed并提示网络错误,参数边界测试设置页数为0或负数预期系统提示参数错误或使用默认值。单本爬取图书功能测试包括正常爬取测试输入有效的subject_id预期成功获取图书详情并存入数据库,返回成功提示,无效ID测试输入不存在的subject_id预期提示图书不存在或爬取失败,重复爬取测试对同一本图书多次爬取预期更新现有记录而不是创建重复记录。评论爬取功能测试包括正常爬取测试输入有效的subject_id和页数为5预期成功爬取100条评论(每页20条),评论关联到对应的图书,评论内容、用户信息、评分等字段正确提取,无评论测试输入没有评论的图书ID预期提示该图书暂无评论,爬取数量为0,星级转换测试验证allstar50转换为5分、allstar40转换为4分等星级映射是否正确,评论更新测试对已爬取的评论再次爬取预期更新点赞数等可变字段,评论ID保持唯一。自动爬取评论功能测试包括批量爬取测试设置limit为10、pages_per_book为3预期依次爬取10本图书的评论每本3页共600条,返回总体统计结果,空库测试在图书库为空时执行自动爬取预期提示没有可爬取的图书,进度监控测试在爬取过程中查询进度预期返回当前爬取的图书序号和总数。所有测试用例执行完毕后,数据爬取功能测试通过率为100%,爬虫能够稳定运行并正确提取和存储数据,异步任务机制和进度监控功能正常工作,异常处理机制有效防止了程序崩溃。
表5.2 数据爬取功能测试用例
| 测试用例ID | 功能点 | 测试输入 | 预期结果 | 测试结果 |
|---|---|---|---|---|
| TC-011 | 批量爬取图书 | 分类:小说,页数:2 | 爬取40本图书,进度实时更新 | 通过 |
| TC-012 | 批量爬取图书 | 分类:历史,页数:50 | 爬取1000本图书,任务正常完成 | 通过 |
| TC-013 | 单本爬取 | subject_id:1007305 | 成功爬取《红楼梦》详情 | 通过 |
| TC-014 | 单本爬取 | subject_id:999999999 | 提示图书不存在 | 通过 |
| TC-015 | 爬取评论 | subject_id:1007305,页数:5 | 爬取100条评论 | 通过 |
| TC-016 | 爬取评论 | 星级转换验证 | allstar50→5分,allstar40→4分 | 通过 |
| TC-017 | 自动爬取评论 | limit:10,pages:3 | 爬取10本书共600条评论 | 通过 |
| TC-018 | 任务进度监控 | 查询任务状态 | 返回实时进度和统计信息 | 通过 |
5.2.3 数据分析与可视化功能测试
数据分析与可视化功能测试验证图书分类分析、作者影响力分析、评分分布分析、价格区间分析、出版趋势分析、词云分析、情感分析等分析功能的正确性和图表展示的准确性。图书分类分析测试访问分类分析页面预期显示饼图展示各分类的图书数量和占比,鼠标悬停显示详细数据,点击图例可以切换显示隐藏,分类名称和数量与数据库查询结果一致。作者影响力分析测试访问作者分析页面预期显示柱状图展示作者的作品数量,折线图展示作者的平均评分,双Y轴正确标注,只显示作品数量≥3的作者,按作品数量降序排列取前20名。评分分布分析测试访问评分分析页面预期显示柱状图展示0-1分、1-2分...9-10分等9个区间的图书数量,各区间数量之和等于图书总数,图表使用渐变色填充增强视觉效果。价格区间分析测试访问价格分析页面预期显示柱状图展示0-20、20-40等7个价格段的图书数量,价格提取和区间划分正确,无定价的图书归入单独的类别。出版趋势分析测试访问出版趋势页面预期显示折线图展示1980年以后各年份的图书出版数量,折线平滑流畅,数据标记点清晰,异常年份如1900年的数据已过滤。词云分析测试访问词云页面预期显示词云图,高频词汇字体大颜色深,低频词汇字体小颜色浅,停用词如"的""了"已过滤,词汇与文本内容相符。情感分析测试访问情感分析页面预期显示饼图展示积极、消极、中性三种情感的占比,显示各情感的数量统计,按分类展示情感分布的堆叠柱状图。图表交互功能测试包括响应式布局测试调整浏览器窗口大小预期图表自动调整尺寸保持正常显示,工具栏功能测试点击数据视图按钮预期切换为表格展示,点击下载按钮预期下载图表图片,图例交互测试点击图例项预期切换该系列的显示隐藏状态。所有测试用例执行完毕后,数据分析与可视化功能测试通过率为100%,各分析维度的统计结果准确,图表展示直观美观,交互功能正常工作。
5.2.4 情感分析与推荐功能测试
情感分析功能测试验证情感识别的准确性和批量分析的性能。单条情感测试包括积极评论测试输入"这本书非常精彩值得推荐"预期识别为positive情感得分大于1.0,消极评论测试输入"这本书太无聊了不推荐"预期识别为negative情感得分小于-1.0,中性评论测试输入"这本书还可以"预期识别为neutral情感得分在-1.0到1.0之间,程度副词测试输入"非常好"预期"非常"的程度权重正确应用到"好"的基础权重上,否定词测试输入"不好"预期情感极性反转结果为消极,复杂评论测试输入包含多个情感词和修饰词的长评论预期综合计算情感得分并正确判定倾向。批量情感分析测试包括小批量测试对100条评论进行情感分析预期分析完成并更新评论表的sentiment和sentiment_score字段,任务状态显示进度和统计信息,大批量测试对10000条评论进行情感分析预期分析任务正常完成,平均每条评论耗时小于0.01秒,准确率验证随机抽取500条已分析的评论人工判定情感倾向预期系统识别结果与人工判定的一致性达到85%以上。推荐系统功能测试验证推荐算法的有效性和推荐结果的准确性。协同过滤推荐测试为已有收藏记录的用户生成推荐列表预期推荐列表包含12本图书,推荐的图书为相似用户收藏但目标用户未收藏的图书,按推荐得分降序排列,新用户推荐测试为没有收藏记录的新用户生成推荐预期返回热门图书推荐列表按评分和评价人数排序。基于内容推荐测试验证推荐的图书与用户已收藏图书的分类、作者、评分等特征相似。混合推荐测试验证推荐列表融合了协同过滤和基于内容的推荐结果,去除了重复项,按综合得分排序。推荐多样性测试验证推荐列表涵盖多个分类和作者,不局限于单一类型。所有测试用例执行完毕后,情感分析功能的准确率达到86.2%超过预期的85%,批量分析性能良好,推荐系统能够为不同用户生成个性化的推荐列表,推荐结果具有准确性和多样性。
表5.3 情感分析与推荐功能测试用例
| 测试用例ID | 功能点 | 测试输入 | 预期结果 | 测试结果 |
|---|---|---|---|---|
| TC-019 | 情感识别 | "这本书非常精彩值得推荐" | positive,得分>1.0 | 通过,得分2.8 |
| TC-020 | 情感识别 | "这本书太无聊了不推荐" | negative,得分<-1.0 | 通过,得分-2.3 |
| TC-021 | 情感识别 | "这本书还可以" | neutral,得分-1.0~1.0 | 通过,得分0.5 |
| TC-022 | 程度副词 | "非常好" | 程度权重应用正确 | 通过,得分3.0 |
| TC-023 | 否定词 | "不好" | 情感极性反转 | 通过,得分-1.5 |
| TC-024 | 批量分析 | 100条评论 | 全部完成,更新数据库 | 通过 |
| TC-025 | 准确率验证 | 500条人工标注评论 | 准确率≥85% | 通过,准确率86.2% |
| TC-026 | 协同过滤推荐 | 有收藏的用户 | 返回12本推荐图书 | 通过 |
| TC-027 | 新用户推荐 | 无收藏的新用户 | 返回热门图书列表 | 通过 |
| TC-028 | 推荐多样性 | 查看推荐结果 | 涵盖多个分类和作者 | 通过 |
5.3 性能测试
性能测试是验证系统在不同负载条件下的响应时间、吞吐量、资源占用等性能指标是否满足需求的测试工作。本系统的性能测试包括响应时间测试、并发处理测试、数据库性能测试和系统资源占用测试四个方面。
5.3.1 响应时间测试
响应时间测试验证系统各功能模块的响应速度是否在用户可接受的范围内。测试方法为使用浏览器开发者工具或性能测试工具如Apache JMeter记录页面加载时间和API接口响应时间,每个测试场景执行10次取平均值作为最终结果。页面加载时间测试包括登录页面加载时间测试结果为0.52秒,主页加载时间测试结果为1.23秒包含首页统计数据查询,图书列表页加载时间测试结果为1.87秒包含分页查询20条记录,图书详情页加载时间测试结果为0.95秒,数据分析页面加载时间测试结果为2.15秒包含统计计算和图表数据准备。API接口响应时间测试包括用户登录接口响应时间0.18秒,图书查询接口响应时间0.32秒查询条件为分类筛选,评论查询接口响应时间0.45秒,情感分析接口响应时间0.008秒单条评论,图书收藏接口响应时间0.12秒,推荐算法接口响应时间1.53秒包含协同过滤和内容推荐的计算。数据爬取耗时测试包括单页图书爬取耗时3.2秒包含20本图书的详情页访问和数据提取,单页评论爬取耗时2.8秒包含20条评论的数据提取。测试结果表明,系统的页面加载时间均在3秒以内,API接口响应时间均在2秒以内,情感分析的单条处理耗时不到0.01秒,整体响应速度满足用户体验要求,达到了性能设计目标。
表5.4 系统响应时间测试结果
| 测试项 | 测试内容 | 响应时间(秒) | 性能评价 |
|---|---|---|---|
| 页面加载 | 登录页面 | 0.52 | 优秀 |
| 页面加载 | 主页(含统计数据) | 1.23 | 良好 |
| 页面加载 | 图书列表(20条) | 1.87 | 良好 |
| 页面加载 | 数据分析页面 | 2.15 | 合格 |
| API接口 | 用户登录 | 0.18 | 优秀 |
| API接口 | 图书查询 | 0.32 | 优秀 |
| API接口 | 情感分析(单条) | 0.008 | 优秀 |
| API接口 | 推荐算法 | 1.53 | 良好 |
| 数据爬取 | 单页图书(20本) | 3.2 | 合格 |
| 数据爬取 | 单页评论(20条) | 2.8 | 合格 |
5.3.2 并发处理与数据库性能测试
并发处理测试验证系统在多用户同时访问时的处理能力和稳定性。测试方法为使用Apache JMeter工具模拟不同数量的并发用户访问系统,监控系统的响应时间、错误率和服务器资源占用情况。低并发测试模拟10个并发用户同时访问主页预期所有请求成功响应,平均响应时间1.35秒,无错误请求,服务器CPU占用率15%内存占用350MB。中等并发测试模拟50个并发用户同时执行图书查询操作预期所有请求成功响应,平均响应时间2.18秒,响应时间相比单用户增加约20%,无错误请求,服务器CPU占用率45%内存占用580MB。高并发测试模拟100个并发用户同时访问不同页面预期95%以上的请求成功响应,平均响应时间3.52秒,错误率低于5%,服务器CPU占用率75%内存占用820MB。压力测试模拟200个并发用户持续访问1分钟预期系统能够持续提供服务,部分请求响应时间超过5秒,错误率约10%主要为超时错误,服务器CPU占用率接近100%,系统接近性能瓶颈但未崩溃。数据库性能测试包括查询性能测试对包含5000条图书记录和50000条评论记录的数据库执行各种查询操作,简单查询如按ID查询图书耗时5ms,复杂查询如分组聚合统计耗时120ms,关联查询如查询图书及其评论耗时85ms。索引效果测试在subject_id字段建立索引后按subject_id查询的耗时从200ms降低到8ms,索引显著提升了查询效率。并发查询测试模拟50个并发查询操作预期数据库能够正常处理,平均查询耗时增加到180ms,数据库连接池设置为20个连接能够满足需求。测试结果表明,系统在50个并发用户以内能够保持良好的性能,100个并发用户时性能有所下降但仍可接受,200个并发用户时系统接近性能极限,数据库查询性能良好索引有效提升了查询效率,整体并发处理能力满足中小规模应用的需求。
表5.5 并发处理性能测试结果
| 并发用户数 | 平均响应时间(秒) | 错误率(%) | CPU占用(%) | 内存占用(MB) | 性能评价 |
|---|---|---|---|---|---|
| 10 | 1.35 | 0 | 15 | 350 | 优秀 |
| 50 | 2.18 | 0 | 45 | 580 | 良好 |
| 100 | 3.52 | 4.2 | 75 | 820 | 合格 |
| 200 | 5.87 | 9.8 | 98 | 1150 | 接近极限 |
5.4 测试总结
经过系统化的功能测试和性能测试,系统的各项功能和性能指标均达到了预期目标。功能测试方面,用户认证模块的10个测试用例全部通过,数据爬取模块的8个测试用例全部通过,数据分析与可视化功能的所有测试场景均正确运行,情感分析的准确率达到86.2%超过预期的85%,推荐系统能够为不同用户生成准确且多样的推荐列表,整体功能测试通过率为100%。性能测试方面,系统的页面加载时间均在3秒以内,API接口响应时间均在2秒以内,情感分析的单条处理耗时不到0.01秒,响应速度满足用户体验要求。系统在50个并发用户以内能够保持良好的性能,100个并发用户时性能有所下降但仍可接受,并发处理能力满足中小规模应用的需求。数据库查询性能良好,索引的建立有效提升了查询效率,复杂查询的耗时控制在200ms以内。测试过程中发现的问题主要包括在高并发情况下部分请求响应时间过长,通过优化数据库查询语句、增加数据缓存、调整数据库连接池参数等措施已得到有效改善。部分长文本评论的情感分析准确率相对较低,后续可以通过扩充情感词典、优化分析算法、引入机器学习模型等方法进一步提升准确率。整体而言,系统功能完整、性能稳定、用户体验良好,达到了毕业设计项目的要求,具备实际应用的能力。
6 总结与展望
6.1 工作总结
本课题设计并实现了一个基于Python和Django框架的豆瓣图书数据可视化分析推荐系统,系统集成了数据采集、数据分析、情感识别、智能推荐、可视化展示等多项功能,为用户提供了全方位的图书数据洞察和个性化推荐服务。在系统开发过程中,完成了以下主要工作。第一,需求分析与系统设计工作,通过需求调研明确了系统的功能需求和性能需求,采用MTV架构设计了系统的总体架构,将系统划分为表现层、业务逻辑层和数据访问层三个层次,设计了用户认证、数据爬取、数据分析、情感分析、推荐系统、数据可视化六大核心功能模块,完成了数据库的概念设计和逻辑设计,建立了User、Book、Comment、BookFavorite四个核心数据表及其关联关系。第二,数据采集模块的开发工作,基于Requests和lxml库开发了豆瓣图书和评论的爬虫程序,支持批量爬取、单本爬取和评论爬取三种模式,采用异步任务机制实现了后台执行和实时进度监控,采用随机延时和请求头轮换策略降低了被反爬的风险,采用update_or_create方法避免了重复数据的产生,成功采集了数千本图书数据和数万条评论数据为系统分析提供了数据基础。第三,数据分析模块的开发工作,基于Pandas库实现了图书分类统计、作者影响力分析、评分分布分析、价格区间分析、出版趋势分析、关键词词云分析、情感统计分析等8个分析维度,充分利用DataFrame的分组、聚合、排序、筛选等功能实现了高效的统计计算,为用户提供了多角度的数据洞察能力。第四,情感分析模块的开发工作,基于Jieba分词和情感词典构建了评论情感识别系统,建立了包含300余个积极词汇和280余个消极词汇的领域相关情感词典,设计了权重分级策略和修饰词调节机制,实现了评论情感的自动识别和量化评分,测试准确率达到86.2%,为用户了解图书口碑提供了客观依据。第五,推荐系统模块的开发工作,设计了融合协同过滤和基于内容的混合推荐策略,协同过滤算法通过计算用户相似度发现用户潜在的兴趣点,基于内容的推荐算法通过分析图书特征提供稳定准确的推荐结果,混合策略实现了推荐质量和推荐多样性的平衡,为用户提供了个性化的图书发现服务。第六,数据可视化模块的开发工作,采用ECharts图表库和WordCloud词云库实现了饼图、柱状图、折线图、散点图、词云图等多种图表形式的展示,配置了丰富的交互功能如鼠标悬停提示、图例点击切换、数据区域缩放、图表下载等,实现了响应式布局在不同设备上都能获得良好的视觉体验,将抽象的统计数据转化为直观的图形展示。第七,系统测试与优化工作,设计了涵盖用户认证、数据爬取、数据分析、情感识别、推荐系统等功能模块的30个测试用例,进行了功能测试和性能测试,功能测试通过率达到100%,性能测试验证了系统的响应时间和并发处理能力满足需求,根据测试结果进行了针对性的优化改进,提升了系统的稳定性和用户体验。
通过本课题的研究和实践,系统成功实现了预期的功能目标和性能指标。系统能够自动化采集豆瓣图书数据,累计采集图书数据5000余条、评论数据50000余条,数据涵盖小说、历史、经济、哲学等多个分类。系统提供了8个维度的数据分析功能,用户可以通过交互式图表直观了解图书市场的整体状况、发现热门分类和优质作品、分析价格趋势和出版规律。系统的情感分析功能能够自动识别评论的情感倾向,准确率达到86.2%,帮助用户快速了解图书的整体口碑和读者评价。系统的推荐功能能够根据用户的收藏行为生成个性化的推荐列表,推荐结果具有准确性和多样性,有效提升了用户的图书发现效率。系统采用响应式设计,在PC端和移动端都能获得良好的使用体验,页面加载时间均在3秒以内,API接口响应时间均在2秒以内,整体性能良好。本课题的完成不仅巩固了Django Web开发、网络爬虫、数据分析、推荐算法等专业知识,还提升了系统设计、项目开发、问题解决等综合能力,为今后从事相关领域的工作打下了坚实的基础。
6.2 系统特色与创新
本系统在技术实现和功能设计上具有以下特色和创新之处。第一,构建了针对图书评论场景的领域相关情感词典,包含300余个积极词汇和280余个消极词汇,每个词汇根据情感强度分配不同的权重值,相比传统的通用情感词典更加贴合实际应用场景,创新性地引入了权重分级策略和修饰词调节机制,通过识别程度副词和否定词动态调整情感词汇的权重和极性,使得情感分析的准确率从传统方法的70%提升至86.2%,这种基于规则的情感分析方法无需大量标注数据和模型训练,分析速度快、结果可解释性强,特别适合实际应用场景。第二,设计了融合协同过滤和基于内容特征的混合推荐策略,协同过滤部分采用Jaccard相似系数计算用户相似度,能够发现用户潜在的兴趣点,推荐一些用户可能没有想到但实际会喜欢的图书,具有较强的探索性和惊喜感,基于内容推荐部分采用多维特征加权匹配的方法计算图书相似度,推荐结果与用户已有偏好高度一致,用户接受度较高,混合策略将两种推荐结果按照一定权重融合,既保证了推荐的准确性又增强了推荐的多样性,实现了推荐质量和用户体验的平衡。第三,采用异步任务机制处理大规模数据爬取任务,通过Python threading线程模块在后台执行爬虫程序,避免阻塞主线程影响用户操作体验,设计了全局任务状态字典实时记录每个爬取任务的进度信息,前端通过定时轮询的方式查询任务状态并更新进度显示,实现了数据爬取的实时监控和动态反馈,这种异步任务处理机制在保证系统响应性的同时提供了良好的用户体验。第四,集成了ECharts图表库和WordCloud词云库两种可视化工具,实现了饼图、柱状图、折线图、散点图、词云图等多种图表形式的展示,涵盖图书分类分布、作者影响力、评分趋势、价格区间、出版时间、关键词提取、情感分析等8个分析维度,为用户提供了全方位的数据洞察能力,图表采用响应式设计并支持丰富的交互操作,这种多维度、交互式的数据可视化设计大大提升了系统的实用价值和用户满意度。第五,系统架构采用MTV模式实现了数据、逻辑和展示的三层分离,Model层通过Django ORM实现数据库操作的对象化封装,View层封装业务逻辑和算法实现,Template层负责页面渲染和用户交互,这种模块化的架构设计使得各层可以独立开发和维护,当需要修改界面样式时只需调整模板文件,当需要优化算法或增加功能时只需修改视图层代码,大大提升了系统的可维护性和可扩展性,为系统的后续发展奠定了良好的基础。
6.3 存在的不足
尽管本系统基本实现了预期的功能目标,但在实际开发和测试过程中也发现了一些不足之处有待改进。第一,情感分析模块采用基于词典和规则的方法,虽然无需训练模型、分析速度快,但在处理复杂语义如反讽、双重否定、隐晦表达等情况时准确率有所下降,对于长文本评论的情感倾向把握不够精准,情感词典的覆盖面虽然包含了常见的积极和消极词汇,但对于网络新词、方言俚语等特殊表达的支持不足,情感分析的准确率虽然达到了86.2%,但相比深度学习模型如BERT、RoBERTa等仍有提升空间,后续可以考虑引入预训练语言模型或混合使用规则和机器学习的方法进一步提升准确率。第二,推荐系统目前仅基于用户的收藏行为进行推荐,没有考虑用户的浏览历史、搜索关键词、停留时间等其他行为数据,对于新用户的冷启动问题处理较为简单只能推荐热门图书,无法提供个性化的推荐,协同过滤算法在用户数量较少或用户收藏行为稀疏的情况下推荐效果不佳,推荐算法的计算性能随着用户数量和图书数量的增加而下降,当数据规模达到数万或数十万级别时可能需要更多的计算时间,后续可以考虑引入更多的用户行为特征、优化算法性能、使用分布式计算等方法改进推荐系统。第三,数据爬取模块虽然实现了基本的反反爬策略如随机延时和请求头轮换,但面对豆瓣网站更加严格的反爬措施如验证码、IP限制、访问频率检测等可能会导致爬取失败,爬虫的稳定性和持续性还需要进一步提升,爬取的数据字段虽然较为全面,但对于图书的章节目录、读者书评、作者简介等深层次信息的抓取还不够完善,后续可以考虑使用代理IP池、模拟登录、分布式爬虫等技术提升爬虫的稳定性,并扩展爬取的数据维度。第四,系统的并发处理能力在100个并发用户以内表现良好,但当并发数达到200时性能明显下降,部分请求出现超时错误,数据库连接池的配置和查询语句的优化还有改进空间,系统未实现分布式部署和负载均衡,在面对大规模并发访问时存在性能瓶颈,后续可以考虑使用缓存技术如Redis减少数据库访问压力,使用消息队列如Celery处理异步任务,采用容器化部署和负载均衡技术提升系统的并发处理能力和可扩展性。第五,系统的用户界面虽然采用了响应式设计,但在移动端的操作体验还有优化空间,部分图表在小屏幕设备上显示不够清晰,数据可视化的交互功能在触摸屏上的操作不够便捷,系统未开发独立的移动端App,仅提供Web访问方式,后续可以考虑优化移动端界面设计,开发原生或混合式移动应用,提供更好的移动端使用体验。
6.4 未来展望
针对系统存在的不足和未来的发展方向,提出以下改进建议和展望。第一,在情感分析方面,可以引入预训练语言模型如BERT、RoBERTa等深度学习模型,通过在图书评论数据集上进行微调训练,能够更好地理解评论文本的语义和上下文信息,提升对复杂语义的处理能力,可以构建更大规模的情感词典,收集网络新词、方言俚语、专业术语等特殊表达,提高词典的覆盖面和时效性,可以采用规则和机器学习相结合的混合方法,利用规则方法的可解释性和机器学习方法的准确性,实现优势互补,还可以扩展情感分析的维度,不仅识别情感倾向,还可以提取评论中的情感词汇、情感对象、情感原因等细粒度信息,为用户提供更加详细的情感分析报告。第二,在推荐系统方面,可以引入更多的用户行为特征如浏览历史、搜索关键词、停留时间、点击行为等,构建更加完善的用户画像,提升推荐的个性化程度,可以采用深度学习推荐模型如神经协同过滤NCF、深度因子分解机DeepFM、Wide&Deep等,通过学习用户和图书的隐含特征向量,实现更加精准的推荐,可以引入知识图谱技术,将图书的作者、出版社、分类、标签等信息构建为知识图谱,利用图谱中的关联关系进行推荐,可以实现实时推荐和在线学习,根据用户的最新行为动态更新推荐模型,提供更加及时和准确的推荐结果。第三,在数据采集方面,可以扩展数据来源,不仅爬取豆瓣的图书数据,还可以整合当当、京东、亚马逊等其他电商平台的图书信息和用户评论,构建更加全面的图书数据库,可以采用分布式爬虫框架如Scrapy-Redis实现大规模分布式爬取,提升爬取效率和数据规模,可以使用代理IP池、浏览器自动化工具如Selenium、反爬识别和绕过技术等增强爬虫的稳定性和持续性,可以建立数据更新机制,定期增量爬取新发布的图书和最新的评论,保持数据的时效性。第四,在系统性能方面,可以引入缓存技术如Redis,将热门图书、推荐列表、统计数据等频繁访问的数据缓存到内存中,减少数据库访问压力,显著提升系统响应速度,可以使用消息队列如Celery处理数据爬取、情感分析、推荐计算等耗时的异步任务,实现任务的异步执行和分布式处理,可以对数据库进行优化,建立适当的索引、优化查询语句、实施读写分离、使用主从复制等技术提升数据库性能,可以采用容器化技术如Docker实现应用的快速部署,使用Kubernetes进行容器编排和负载均衡,提升系统的可扩展性和高可用性。第五,在功能扩展方面,可以增加用户社交功能,允许用户关注其他读者、分享读书心得、参与图书讨论,构建读书社区增强用户粘性,可以增加图书比价功能,整合多个电商平台的价格信息,帮助用户找到最优惠的购买渠道,可以增加阅读计划和读书笔记功能,帮助用户制定阅读目标、记录阅读进度、撰写读书笔记,提供个性化的阅读管理服务,可以开发移动端App,提供更加便捷的移动阅读和图书发现体验,可以引入人工智能客服和智能问答功能,解答用户的图书咨询,提供图书推荐理由解释,提升用户服务质量。
综上所述,本系统在数据采集、数据分析、情感识别、智能推荐、可视化展示等方面进行了有益的探索和实践,取得了预期的成果,但也存在一些不足之处。通过引入先进的技术方法、扩展系统功能、优化系统性能,系统将能够为用户提供更加智能、准确、便捷的图书数据洞察和个性化推荐服务,具有良好的应用前景和推广价值。
参考文献
1 Django Software Foundation. Django DocumentationEB/OL. https://docs.djangoproject.com/, 2023.
2 李华, 张明. 基于Python的网络爬虫技术研究与应用J. 计算机应用与软件, 2021, 38(5): 112-118.
3 刘强, 王芳. 中文情感分析技术综述J. 计算机科学, 2020, 47(11): 1-10.
4 陈伟, 赵敏. 基于协同过滤的个性化推荐系统研究J. 软件学报, 2019, 30(8): 2456-2470.
5 McKinney W. Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPythonM. 2nd ed. O'Reilly Media, 2017.
6 孙建军. 结巴中文分词:做最好的Python中文分词组件EB/OL. https://github.com/fxsjy/jieba, 2022.
7 Apache ECharts. DocumentationEB/OL. https://echarts.apache.org/handbook/zh/get-started/, 2023.
8 Mitchell R. Web Scraping with Python: Collecting More Data from the Modern WebM. 2nd ed. O'Reilly Media, 2018.
9 周志华. 机器学习M. 北京: 清华大学出版社, 2016.
10 Ricci F, Rokach L, Shapira B. Recommender Systems HandbookM. 2nd ed. Springer, 2015.
致谢
本论文的完成离不开各位老师和同学的帮助与支持。首先要感谢我的指导教师,在论文选题、系统设计、技术实现和论文撰写的各个阶段给予了悉心的指导和宝贵的建议,帮助我克服了开发过程中遇到的种种困难,使课题研究得以顺利完成。感谢学院的各位专业课教师,在本科四年的学习过程中传授了扎实的专业知识和实践技能,为本课题的研究奠定了坚实的理论基础。感谢实验室的同学们,在技术讨论和系统测试中提供了大量的帮助和建设性意见,共同营造了良好的学术氛围。感谢我的家人和朋友,在学习和生活上给予了无私的关心和支持,使我能够专心致志地完成学业。最后,衷心感谢所有为本课题研究提供帮助的老师、同学和朋友们!
附录
附录A 系统核心代码片段
由于论文篇幅限制,本附录仅展示部分核心代码片段,完整代码已包含在系统源代码中。
A.1 情感分析核心算法
python
def analyze_sentiment(self, text):
"""
分析评论文本的情感倾向
:param text: 评论文本
:return: {'sentiment': 'positive/negative/neutral', 'sentiment_score': float}
"""
# 使用jieba进行分词
words = list(jieba.cut(text))
score = 0.0
# 遍历每个词进行情感匹配
for i, word in enumerate(words):
if word in self.positive_words or word in self.negative_words:
base_weight = self.positive_words.get(word, 0) or -self.negative_words.get(word, 0)
degree_weight = 1.0
negation = False
# 向前查找程度副词和否定词
for j in range(max(0, i-3), i):
prev_word = words[j]
if prev_word in self.negation_words:
negation = True
if prev_word in self.degree_words:
degree_weight *= self.degree_words[prev_word]
# 计算最终权重
final_weight = base_weight * degree_weight
if negation:
final_weight = -final_weight
score += final_weight
# 判定情感倾向
if score > 1.0:
sentiment = 'positive'
elif score < -1.0:
sentiment = 'negative'
else:
sentiment = 'neutral'
return {'sentiment': sentiment, 'sentiment_score': score}A.2 协同过滤推荐算法
python
def collaborative_filtering_recommendations(self, target_user, top_n=12):
"""
基于用户协同过滤的推荐算法
:param target_user: 目标用户名
:param top_n: 推荐图书数量
:return: 推荐的图书ID列表
"""
if target_user not in self.user_favorites:
return self.get_popular_books(top_n)
target_user_favorites = self.user_favorites[target_user]
user_similarity_scores = {}
# 计算用户相似度
for user_name, favorites in self.user_favorites.items():
if user_name == target_user:
continue
common_books = target_user_favorites & favorites
if len(common_books) < 1:
continue
# Jaccard相似系数
similarity = len(common_books) / (len(target_user_favorites) + len(favorites) - len(common_books))
user_similarity_scores[user_name] = similarity
# 选取最相似的10个用户
similar_users = sorted(user_similarity_scores.items(), key=lambda x: x[1], reverse=True)[:10]
# 生成推荐列表
recommendation_scores = defaultdict(int)
for user_name, similarity in similar_users:
for book_id in self.user_favorites[user_name]:
if book_id not in target_user_favorites:
recommendation_scores[book_id] += similarity
# 按推荐得分排序
recommended_books = sorted(recommendation_scores.items(), key=lambda x: x[1], reverse=True)[:top_n]
return [book_id for book_id, score in recommended_books](全文完)

需要全部项目资料(完整系统源码),主页+即可。
需要全部项目资料(完整系统源码),主页+即可。
需要全部项目资料(完整系统源码),主页+即可。
需要全部项目资料(完整系统源码),主页+即可。