多线程概念
Java多线程是Java并发编程的核心,它允许在程序中并发执行多个线程,每个线程可以执行不同的任务,并且它们共享相同的地址空间。
计算机设计原理
我们知道在计算机组成原理中,由于CPU和内存的读写速度差异巨大,所以为了保证软件层面的运行效率,计算机不会每次读写数据都从内存中获取或者修改 ,所以计算机设计者在CPU和内存之间增加了一个缓存cache机制,当然随着操作系统的不停更新换代,CPU和内存之间的缓存机制已经很复杂了(有多级缓存),这也是后话了,反正只要知道,CPU和内存之间有缓存,程序每次读取内存中数据基本都是从缓存中读取的,写数据也是写给缓存 。CPU和内存的基本架构如下图所示,JMM(java内存模型)就是基于这种架构方式设计的。
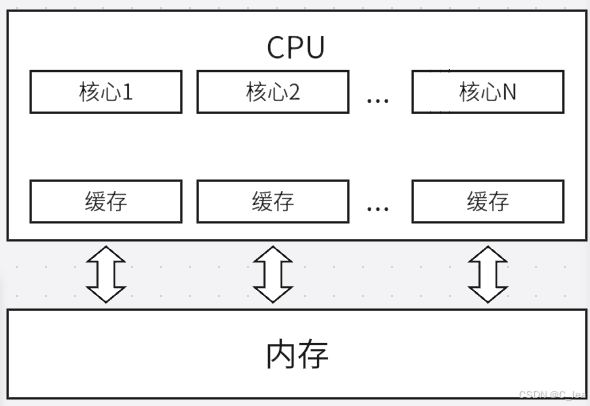
所以线程并发问题的根本原因就很明了了,最主要的就是线程1和线程2读取的数据或者写入的数据不一致导致的,这就是所谓的内存可见性
内存可见性:
内存可见性是指在多线程环境中,当一个线程修改了共享变量的值,其他线程是否能够立即看到这个变化。由于现代计算机硬件的优化(如 CPU 缓存和指令重排),线程间的共享数据可能在不同线程的本地缓存中有不同的副本,导致某个线程对共享变量的修改未必能立即反映到其他线程中,从而出现可见性问题。
进而引申出线程同步三大特性
缓存一致性 :每个线程可能会有自己的缓存,这些缓存中的数据可能与主内存中的数据不一致,导致线程读取的数据不是最新的。
指令重排:为了优化执行效率,编译器和处理器可能会重排指令的执行顺序,导致线程之间看到的数据顺序不同,可能引发问题。
原子性:单一执行指令,要么做要么不做,颗粒度精确到汇编层级,注意i++这个就不是原子操作了,在汇编层面,涉及到读取i数据、i自增、写入i数据到内存,三个原子操作。
让我们来看一下这个demo,开辟5000个线程,每个线程对count+1,理论上应该结果是5000,但为什么有时候结果不是5000呢?
java
public class ThreadStudy {
static int count = 0;
public static void main(String []args) {
for (int i=0;i<5000;i++) {
Thread t = new Thread(() -> {
count++;
});
t.start();
}
try {
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("count:"+count);
}
}
其实按照上述所说的内存一致性原理,就好理解为什么会这样了?
可能的情况:线程1对count+1后,即使把结果立马写入了主内存中,但是线程2读取的数据可能还是缓存中的数据,所以做了count+1后的结果和线程1一样,即5000个线程中有几个线程做了相同的操作。
线程同步
既然知道了本质原因就是线程结果没有同步到主内存,那么有什么办法可以做到线程同步呢?其实java中有很多方式可以实现线程安全
1.volatile关键字
被修饰的数据,可以实现内存可见,即线程1如果修改了数据,那么这个数据汇立马写入到主内存,同时其他线程也会收到更新缓存数据的消息(其它处理器的缓存会遵守了缓存一致性协议,比如MSI、MESI、MOSI、Synapse、Firefly及Dragon Protocaol等,就会把这个变量的值从主存加载到自己的缓存),让我们看下下面这个demo
java
public class VolatileTest {
static boolean flag = false;
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
while (!flag) {
}
});
t1.start();
//确保线程1先启动
try {
Thread.sleep(100);
} catch (Exception e) {
e.printStackTrace();
}
Thread t2 = new Thread(() -> {
flag = true;
});
t2.start();
try {
t1.join();
t2.join();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("执行完毕");
}
}运行结果就是一直在循环,程序结束不了,为什么会这样呢????
明明线程2已经启动了,并且修改了flag=true了,为什么线程1停止不了呢?原因很简单,线程2修改的仅仅是缓存里的数据,没有同步到主内存,也没有提示线程1更新,所以一直死循环。改成volatile关键词修饰即可
java
public class VolatileTest {
static volatile boolean flag = false;
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
while (!flag) {
}
});
t1.start();
//确保线程1先启动
try {
Thread.sleep(100);
} catch (Exception e) {
e.printStackTrace();
}
Thread t2 = new Thread(() -> {
flag = true;
});
t2.start();
try {
t1.join();
t2.join();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("执行完毕");
}
}
可以看到能够正常执行完毕了。这就是volatile的一个特性之一:内存可见性。
下面我们来讲一下volatile的第二个特性,就是禁止指令重排序,我们先来了解一下什么是指令重排:
指令重排(Instruction Reordering)是计算机编译器和处理器在执行程序时对指令顺序进行重新排序的优化技术。它的目的是提高程序的性能和并行度,但可能会导致意想不到的结果,特别是在多线程环境下。
比如java中这三行代码,对应的汇编逻辑如下图:
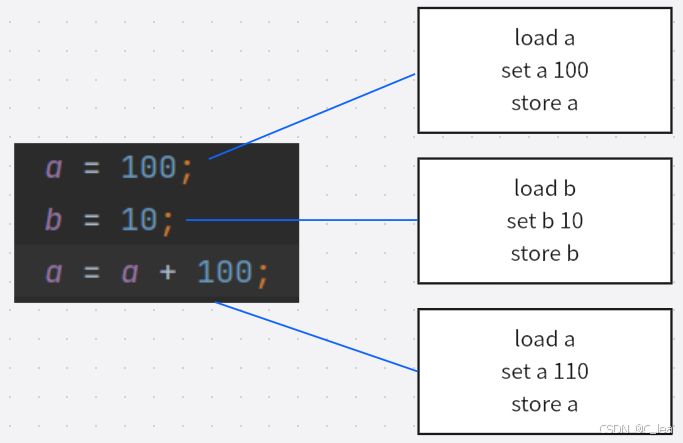
经过指令重排序,不影响结果的情况下,可能会优化为如下图所示
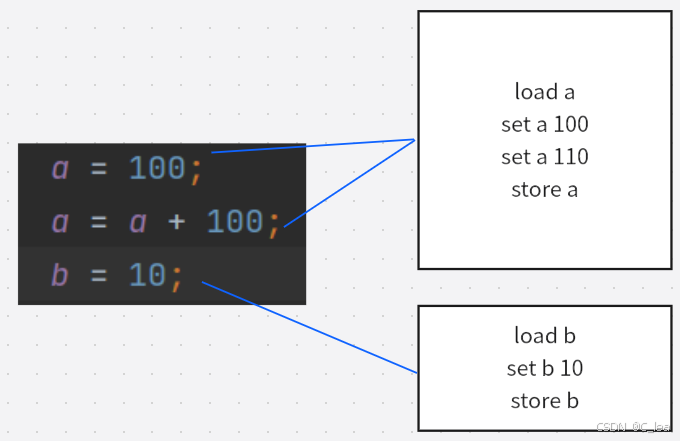
上述只是举个简单的指令重排的例子,我们下面讲一下具体的可能案例,以经典的双重校验锁为例:
java
public class Singleton {
//私有化构造函数
private Singleton(){}
//单例对象(无volatile修饰)
private static Singleton instance=null;
public static Singleton getInstance(){
//第一次检测
if (instance==null){
//加锁
synchronized (Singleton.class){
//第二次检测
if (instance==null){
//初始化
instance=new Singleton();
}
}
}
return instance;
}
}线程1跑到//初始化那一步,按照原理,会进行
1.JVM为对象分配一块内存M。
2.在内存上为对象进行初始化。
3.将内存M的地址赋值给singleton变量。(其中这一步,instance!=null)
但是指令重排可能优化成
1.JVM为对象分配一块内存M。
2.将内存M的地址赋值给singleton变量。(其中这一步,instance!=null)
3.在内存上为对象进行初始化。
可以看到,指令重排对2.3步骤做了交换,那么可能存在的一个风险点就是,如果此时线程2跑到//第一次检测,那么线程1正好执行到指令重排的第二个步骤结束,此时线程2instance判断不为空,return了一个空的instance。
要解决的话,直接禁止它指令重排就行了,所以volatile就派上用场了,只需要用volatile修饰一下instance即可。
看上去volatile很强大啊,一下子就能够让缓存一致性和指令禁重排,感觉线程问题一下子都解决了,那么一开始上文说的那个案例,我们对count修饰一下,是不是5000个线程累加都能一定加到5000了呢?我们看下结果
java
public class ThreadStudy {
static volatile int count = 0;
public static void main(String []args) {
for (int i=0;i<5000;i++) {
Thread t = new Thread(() -> {
count++;
});
t.start();
}
try {
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("count:"+count);
}
}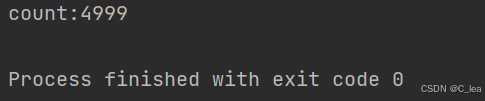
为什么还是不对呢?这个就牵扯到上文所说的并发第三个特性:原子性
我们知道原子性在汇编层面就是单一的操作,但是count++包含了三个操作,就不是原子性操作。那刚才不是说了这个问题的本质还是缓存一致性、内存可见性问题吗?为啥用volatile修饰不行了?
我们看下count++的原子操作
1.读取count数据
2.count+1
3.写入count数据
我们可以看到volatile只能保证第三个步骤,即写入count数据这个操作 实现内存可见和缓存一致性,前面的读取count操作和+1操作,多个线程还是可以并发交替执行的。所以volatile不能保证原子性
2.加锁
线程同步的第二个方法就是加锁了,加锁的概念就很多很杂也很深了,这篇文章主要初步介绍一下,后续文章我会继续加深学习更新。
常见的锁
上述这种情况使用volatile显然是不可以的,那么这一小节我们就引申讲一下锁了。既然上述所说的情况本质上就是多个线程调用同一段逻辑,那么是否可以用一个方式对这一段逻辑实现一个时刻只有一个线程能够调用呢?没错,就是加锁,很简单粗暴,锁住这个逻辑即可
java
public class ThreadStudy {
static int count = 0;
static final Object c = new Object();
public static void main(String []args) {
for (int i=0;i<5000;i++) {
Thread t = new Thread(() -> {
synchronized(c) {
count++;
}
});
t.start();
}
try {
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("count:"+count);
}
}多次运行后,结果都是5000。但很显然,加锁这个方式虽然简单粗暴,但是有风险的 ,可能会造成阻塞,假设在synchronized修饰的方法中出现耗时操作,那么在工作开发中可能带来的风险就很大了。
synchronized
略过,此锁用法比较常见
java
synchronized (o) {
//方法体
}CAS自旋锁
上文说到了 synchronized是一个悲观锁是一个重量级的锁,那么肯定是比较耗性能和资源的,那么肯定也有对应的乐观锁低消耗的锁,CAS自旋锁就是这种锁。 synchronized本质就是认为每一个线程都有可能会更改数据,这个数据可能都会有异常,所以每个线程操作数据的时候,都将这个逻辑锁起来,不给任何人使用,只有自己用完了再释放,CAS却不一样,CAS则认为数据可能有人改过可能没改过,只要每次更新的时候对这个数据做一次CompareAndSwap(CAS)即可,CAS有3个操作数,内存值V,旧的预期值A,要修改的新值N,当且仅当预期原值A和内存值V相同时,将内存值V修改为N,否则什么都不做。 CAS也是java原子类Atomic的核心逻辑
上述代码也优化成(使用原子类):
java
public class ThreadStudy {
static AtomicInteger count = new AtomicInteger(0);
public static void main(String []args) {
for (int i=0;i<5000;i++) {
Thread t = new Thread(() -> {
count.incrementAndGet();
});
t.start();
}
try {
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("count:"+count);
}
}cas原理可以用如下代码来解释:
假设100个线程,每个线程要对count累加2,那么就用到cas循环自测,每次加2前判断一下当前这个线程的的实际值和自己的预测值是不是一样的(即内存值V==预期值pre),如果相等就+2操作,如果不等就一直循环下去,知道拿到属于自己的预期值!
java
public class CASTest {
volatile int count = 0;
CASTest(){}
void add(int v, int addSize) {
while (true) {
if (compareAndSwap(v,count,count+addSize)){
break;
}
}
}
//v这里假设是旧值,pre是预期的旧值,nv是新值
boolean compareAndSwap(int v, int pre, int nv) {
System.out.println("v:"+v+",pre:"+pre+",nv:"+nv);
if (v == pre) {
count = nv;
System.out.println("break,nv:"+count);
return true;
}
return false;
}
@Override
public String toString() {
return Integer.toString(count);
}
public static void main(String []args) {
CASTest count = new CASTest();
for (int i = 0; i < 100; i++) {
int temp = i;
Thread t = new Thread(() -> {
count.add(temp*2,2); //每个线程累加2
});
t.start();
}
try {
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("count:"+count);
}
}cas存在的问题
1.ABA问题:比如线程1获取到内存值V=A,且和预期值一样,但这个值A可能是线程2改成了B,然后线程3又改回了A的情况,所以这个值就不一定是预想中的A了;应对措施:增加时间戳或者版本号即可
线程控制
线程控制与线程同步存在着关联,可以这么说线程控制的最终目的是为了线程同步做的
CountDownLatch
它是JDK内置的同步器。通过它可以定义一个倒计数器,当倒计数器的值大于0时,所有调用await方法的线程都会等待。而调用countDown方法则可以让倒计数器的值减一,当倒计数器值为0时所有等待的线程都将继续往下执行。
java
public class CountDownLatchTest {
CountDownLatch c = new CountDownLatch(4); //定义计数器4
class MyThread extends Thread {
@Override
public void run() {
int random = new Random().nextInt(5);
try {
Thread.sleep(random*1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
c.countDown();
}
}
public void startThread() {
for (int i = 0; i < 4; i++) {
new MyThread().start();
}
}
public static void main(String[] args) {
CountDownLatchTest test = new CountDownLatchTest();
test.startThread();
try {
test.c.await(); //开始堵塞,记住一定要等线程开始执行才堵塞,否则先阻塞了会导致永远唤星不了
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("countDown finish");
}
}上述代码好理解的,就是定义了四个线程开始执行,等到四个线程全部执行完毕了,main主线程继续执行。使用countDownLatch就可以实现线程之间按需执行了。
使用场景举例:
比如需要获取用户的当月账单消费总数据(接口A)和用户当月的食物消费总数据(接口B)来计算恩格尔系数,那么就需要这个countDownLatch了,需要等待这两个接口数据都返回了,才可以继续执行,代码如下。
java
public class CountDownLatchTest {
CountDownLatch c = new CountDownLatch(2);
Float allCost = 0F;
Float foodCost = 0F;
public void startThread() {
new Thread(new Runnable() {
@Override
public void run() {
int random = new Random().nextInt(5);
try {
Thread.sleep(random*1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
allCost = 3000F;
c.countDown();
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
int random = new Random().nextInt(5);
try {
Thread.sleep(random*1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
foodCost = 1000F;
c.countDown();
}
}).start();
}
public static void main(String[] args) {
CountDownLatchTest test = new CountDownLatchTest();
test.startThread();
new Thread(new Runnable() {
@Override
public void run() {
try {
test.c.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("countDown finish,Engel's Coefficient:" + test.foodCost/test.allCost);
}
}).start();
}
}当然了实际在工作开发中,要记得给CountDown设置一个时间期限,不然一直await下去,容易出大事!
java
new Thread(new Runnable() {
@Override
public void run() {
int random = new Random().nextInt(10); //模拟随机等待10秒内
System.out.println(random);
try {
Thread.sleep(random*1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
c.countDown();
}
}).start();
try {
if (!c.await(5, TimeUnit.SECONDS)) { //超时5秒就抛出异常
//do timeout
throw new RuntimeException("超时了");
}
} catch (InterruptedException e) {
e.printStackTrace();
}信号量semaphore
信号量SP其实在操作系统中有过系统的学过,其实信号量就是保证在控制线程并发数的,相比较于countDownLatch,semaphore更着重于线程执行的数量,而countDownLatch着重于线程的等待。
在Java中,Semaphore 类是 java.util.concurrent.Semaphore 的一部分,属于 java.util.concurrent 包,用于控制对共享资源的访问。它是一个同步辅助类,用于管理一组许可(permit),线程在访问共享资源前必须先获取许可。如果没有可用许可,线程将阻塞直到许可变为可用。 ------摘自ai
java
public class SemaphoreTest {
int count = 0;
Semaphore s = new Semaphore(1);
public void startThread() throws InterruptedException {
for (int i=0;i<8000;i++) {
new Thread(new Runnable() {
@Override
public void run() {
try {
s.acquire(); //获取许可,如果获取不到就开始等待
} catch (InterruptedException e) {
e.printStackTrace();
}
count ++;
s.release();
}
}).start();
}
Thread.sleep(1000);
System.out.println("count:"+count);
}
public static void main(String[] args) throws InterruptedException {
new SemaphoreTest().startThread();
}
}经典的累加同步代码,除了加锁,也可以用sp信号量来表示,同一时间对共享变量操作的只允许一个线程,那么就可以保证线程同步的了
使用场景举例:
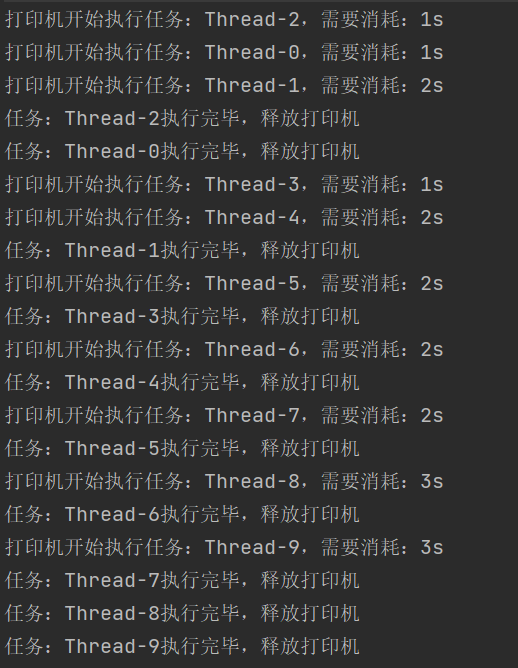
一共有10个任务,但是只有3台打印机,需要合理调度,就可以使用SP信号量
java
public class SemaphoreTest {
Semaphore s = new Semaphore(3);
public void startThread() {
for (int i=0;i<10;i++) {
new Thread(new Runnable() {
@Override
public void run() {
try {
s.acquire(); //获取许可,如果获取不到就开始等待
int random = new Random().nextInt(3)+1;
System.out.println("打印机开始执行任务:"+Thread.currentThread().getName()+",需要消耗:"+random+"s");
try {
Thread.sleep(random*1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("任务:"+Thread.currentThread().getName()+"执行完毕,释放打印机");
s.release();
}
}).start();
}
}
public static void main(String[] args) throws InterruptedException {
new SemaphoreTest().startThread();
}
}
notify和wait
notify和wait都是java object对象中的方法,wait()会堵塞当前线程,notify会激活被阻塞的线程,用法如下(notify和wait都需要放在同步代码块中):
java
Object o = new Object();
synchronized (o) {
o.notify();
}
//...
synchronized (o) {
o.wait();
}注意它们必须在同步块或同步方法中使用,即必须先获取对象的监视器(即锁)后才能调用这些方法。否则,Java虚拟机会抛出IllegalMonitorStateException异常,比如如下代码就会抛出异常
java
//这里 synchronized 块的对象与调用同步方法的对象不一致
Object o = new Object();
Object c = new Object();
synchronized (c) {
o.notify();
}
//没有放在同步代码块中
Object o = new Object();
o.notify();举一个经典多线程互相阻塞、唤醒的例子
java
public class NotifyAndWait {
void testThread() {
Object o = new Object();
Thread t1 = new Thread(){
@Override
public void run() {
for (int i =0;i<5;i++) {
try {
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("t111当前,"+MyUtils.getCurrentTime()+":"+i);
synchronized (o) {
if (i == 2) {
try {
System.out.println("t1开始唤醒t2");
o.notify();
} catch (Exception e) {
e.printStackTrace();
}
}
if (i == 3) {
System.out.println("i=3的时候,t1堵塞了");
try {
o.wait();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("t1恢复了");
}
}
}
}
};
Thread t2 = new Thread(){
@Override
public void run() {
for (int i =0;i<7;i++) {
try {
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("t222当前:"+MyUtils.getCurrentTime()+":"+i);
synchronized (o) {
if (i == 1) {
try {
System.out.println("i=1的时候,t2堵塞了");
o.wait();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("t2恢复了");
}
if (i == 5) {
try {
System.out.println("t2开始唤醒t1");
o.notify();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
};
t1.start();
t2.start();
}
public static void main(String[] args) {
new NotifyAndWait().testThread();
}
}线程t1和线程t2一起执行,线程t2第二次循环的时候wait阻塞了,线程t1第三次循环的时候notify了线程t2,线程t2可以继续执行;线程t1第四次循环的时候wait阻塞了,线程t2第六次循环的时候notify了线程t1,最终全部执行完毕,运行结果如下:
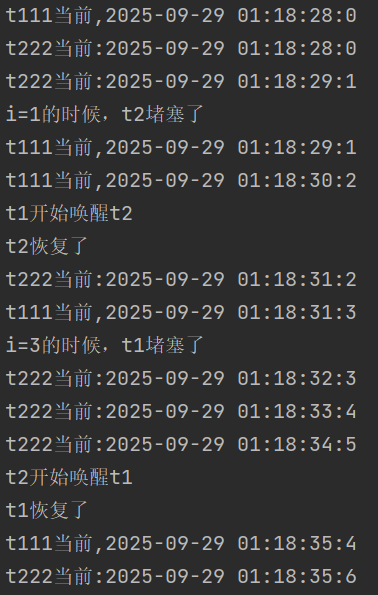
经典案例:生产者消费者模型
生产者消费者模型是经典的线程数据同步的案例,了解如何使用线程同步的来实现生产者消费者模型,有助于更进一步加深线程的概念
java
//生产者线程
thread {
while (true) {
packView?.addPackage(produceText!!,produceText2!!)
if (hasConsume) {
break
}
}
}
//消费者线程
thread {
while (true) {
packView?.removePackage(consumeText!!,consumeText2!!) { c ->
hasConsume = c
}
if (hasConsume) {
break
}
}
}核心逻辑,加了UI表示
java
//生产了一个产品
fun addPackage(proTextView: TextView,proTextView2: TextView) {
val taskId = Random.nextInt(10000) //随机id
val t = Task(taskId)
if (queue.size < 4) { //缓冲区小于等于3个才开始生产
handler.post {
proTextView2.text = "开始生产"
}
val r = Random.nextInt(2)+1
Thread.sleep(r * 1000L)
synchronized(o) {
queue.offer(t)
t.produce()
handler.post {
proTextView.text = "生产了:${t.taskId}"
}
o.notify()
showPackage()
}
} else {
synchronized(o) {
if (queue.size >= 4) { //二次判断校验
handler.post{
proTextView2.text = "等待消费"
}
o.wait()
}
}
}
}
//消费了一个产品
fun removePackage(customTextView: TextView,customTextView2: TextView,callback:(consume:Boolean)->Unit) {
if (queue.size > 0) { //队列中有数据才取物品开始消费
handler.post{
customTextView2.text = "开始消费"
}
val r = Random.nextInt(3)+1
Thread.sleep(r*1000L)
synchronized(o) {
val t = queue.poll()
consumeCount ++
t.consume()
handler.post{
customTextView.text = "消费了:${t.taskId}"
}
if (queue.size <= 3) {
o.notify()
}
showPackage()
if (consumeCount == 20) {
//消费完毕,结束
callback.invoke(true)
handler.post{
customTextView2.text = "生产消费结束!"
}
}
}
} else {
synchronized(o) {
if (queue.size == 0) { //二次校验
handler.post{
customTextView2.text = "等待生产"
}
o.wait()
}
}
}
}
//ui展示逻辑
private fun showPackage() {
val it = queue.iterator()
var i = 0
if (!it.hasNext()) {
for (index in i..9) {
handler.post{
list[index].clear()
}
}
}
while(it.hasNext()) {
val t = it.next()
handler.post{
list[i].set(t.taskId)
i++
for (index in i..9) {
list[index].clear()
}
}
}
}关于上述的二次校验,是因为可能生产者消费者是两个线程,同时共用我这里自己的linkedlist队列,但是此队列是线程不安全的,可能存在这个场景
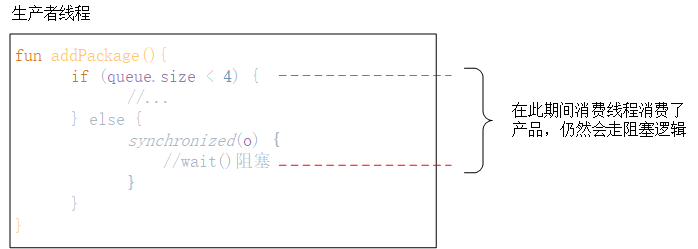
表现上就是产品队列只有3个,但是生产者还在等待生产,直到下一个产品被消费了,生产者线程才会被重新激活
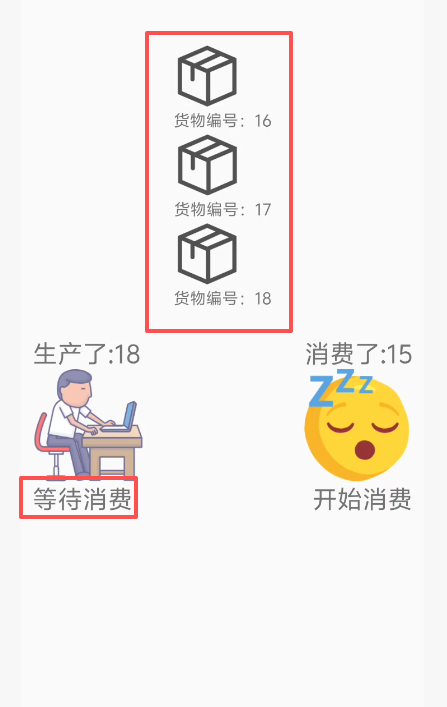
所以需要加一个二次校验(当然了,解决办法很多,因为生产队列本质上是临界区 ,用sp信号量也是可以的),最终结果呈现如下

其实用现有的阻塞队列来实现此逻辑更好,例如用LinkedBlockingQueue来实现,就不需要额外的notify和wait逻辑了,直接queue.take(),当队列为空的时候挂起;直接queue.put(),当队列满的时候也挂起
java
LinkedBlockingQueue<Task> queue = new LinkedBlockingQueue<>(4);
Random random = new Random();
public class ProduceThread extends Thread {
int i = 0;
@Override
public void run() {
while (true) {
int time = (random.nextInt(2)+1) * 1000;
try {
Thread.sleep(time); //模拟理想情况
} catch (Exception e) {
e.printStackTrace();
}
Task t = new Task(i);
try {
queue.put(t);
i++;
t.produce();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class ConsumeThread extends Thread {
@Override
public void run() {
while (true) {
int time = (random.nextInt(5)+1) * 1000;
try {
Thread.sleep(time); //模拟理想情况
} catch (Exception e) {
e.printStackTrace();
}
try {
Task t =queue.take();
t.consume();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}进阶
上述是单生产者和单消费者,如果是多生产者和多消费者呢?那难度就更大了,首先需要考虑到此时生产队列一定要是线程安全的,因为可能多个生产者同时add物品,这里我们可以自己封装queue加锁,或者默认使用LinkedBlockingQueue等阻塞队列,这是最为简便的!!!!
java
public class ProduceThread extends Thread {
@Override
public void run() {
while (true) {
int time = (random.nextInt(2)+1) * 1000;
try {
Thread.sleep(time); //模拟理想情况
} catch (Exception e) {
e.printStackTrace();
}
Task t = new Task(i.getAndIncrement());
try {
queue.put(t);
t.produce();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class ConsumeThread extends Thread {
@Override
public void run() {
while (true) {
int time = (random.nextInt(5)+1) * 1000;
try {
Thread.sleep(time); //模拟理想情况
} catch (Exception e) {
e.printStackTrace();
}
try {
Task t =queue.take();
t.consume();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public void startConsumeAndProduce() {
for (int i=0;i<5;i++) {
Thread produceThread = new ProduceThread();
Thread consumeThread = new ConsumeThread();
produceThread.start();
consumeThread.start();
}
}