【n8n教程】:Switch节点,实现工作流多路由控制
在n8n自动化流程中,最常见的需求之一就是根据数据的不同条件,将其分发到不同的处理路径 。如果你只需要处理"是"或"否"两种情况,可以用If节点 ;但当你需要根据多个条件创建3条、5条甚至更多的处理路径时,Switch节点就是你的最佳选择。
Switch节点就像是一个交通指挥官,它根据你设定的条件规则,将传入的数据准确地引导到对应的输出分支,让复杂的工作流变得清晰有序。
什么是Switch节点?
Switch节点是n8n中的条件路由节点 ,它允许你根据数据的属性值进行多路由决策。与If节点只能分出两条路(真/假)不同,Switch节点可以创建无限个输出分支,每个分支对应一组特定的条件。
核心特性:
- 多路由支持:不限制输出分支数量,想要多少就创建多少
- 灵活的条件系统:支持字符串、数字、日期、布尔值、数组、对象等多种数据类型
- 两种工作模式:Rules模式(可视化条件构建)和Expression模式(编程表达式)
- 智能降级处理:为不匹配任何条件的数据提供备选输出
- 高效的数据流:一条数据一旦匹配到某个输出,默认不会重复匹配其他规则
Switch节点的两种工作模式
模式一:Rules模式(推荐初学者)
Rules模式是可视化条件构建方式,你无需编写任何代码,只需通过下拉菜单和输入框配置条件。
支持的数据类型和比较操作:
| 数据类型 | 支持的比较操作 | 使用场景 |
|---|---|---|
| 字符串 | 等于、不等于、包含、不包含、以...开始、以...结束、正则匹配 | 邮箱地址、分类标签、部门名称 |
| 数字 | 等于、不等于、大于、小于、大于等于、小于等于 | 订单金额、优先级数值、计数器 |
| 日期&时间 | 等于、不等于、之后、之前、之后或等于、之前或等于 | 截止日期、创建时间、过期判断 |
| 布尔值 | 为真、为假、等于、不等于 | 开关状态、验证结果 |
| 数组 | 存在/不存在、为空/非空、包含、长度比较 | 标签列表、多选项 |
| 对象 | 存在/不存在、为空/非空 | 嵌套数据结构 |
模式二:Expression模式(高级用户)
Expression模式使用JavaScript表达式来定义路由逻辑,适合需要复杂条件判断的高级场景。
例如:{``{ $json.status === 'urgent' && $json.amount > 1000 }}
快速上手:3步配置Switch节点
第1步:添加Switch节点
- 在工作流画布上点击"添加节点"(或按Tab键)
- 搜索"Switch"
- 选择Switch节点添加到工作流
第2步:配置路由规则
- 打开Switch节点的配置面板
- 确保"Mode "选择为"Rules"
- 点击"Add Routing Rule"添加第一条规则
- 根据你的数据,配置规则:
- 左侧字段 :选择你要检查的数据字段(例如
priority) - 中间操作符:选择比较方式(例如 "等于")
- 右侧值:输入要比较的值(例如 "high")
- 左侧字段 :选择你要检查的数据字段(例如
示例配置:
规则1:priority 等于 "high" → 输出到第1条分支
规则2:priority 等于 "medium" → 输出到第2条分支
规则3:priority 等于 "low" → 输出到第3条分支第3步:连接后续节点
- Switch节点会自动为每条规则创建一个输出端口
- 从这些输出端口拖拽连线到你的后续处理节点
- 为每个输出分支配置不同的业务逻辑
5个关键配置选项详解
1. 重命名输出(Rename Output)
默认情况下,Switch的输出被标记为"Output 0"、"Output 1"等数字标签。这容易混淆,特别是在复杂流程中。
最佳实践 :启用"Rename Output",给每条分支取个有意义的名字:
- ✅ 好:
高优先级处理、待审核、已完成 - ❌ 差:
Output 0、Output 1
配置步骤:
在配置规则时,勾选"Rename Output",输入自定义名称。
2. 降级输出(Fallback Output)
当数据不匹配任何路由规则时,降级输出决定该数据的去向。
三种选项:
| 选项 | 说明 | 场景 |
|---|---|---|
| None | 忽略不匹配的数据,不输出 | 只关心已知数据类型 |
| Extra Output | 创建单独的输出分支接收未匹配数据 | 需要单独处理异常情况 |
| Output 0 | 将未匹配数据发送到第一条规则的输出 | 快速处理,无需额外分支 |
示例: 如果优先级字段出现意外值"urgent",但你的规则中没有定义它,这条数据就会按照降级设置进行处理。
3. 忽略大小写(Ignore Case)
对于字符串比较,启用此选项后,"HIGH"、"High"、"high"会被视为相同。
建议:大多数场景下启用,避免因大小写不一致导致路由失败。
4. 严格类型验证(Less Strict Type Validation)
启用后,n8n会自动尝试类型转换。例如,字符串"123"可以与数字123比较。
默认建议:关闭。这样可以捕获潜在的数据类型错误。
5. 发送数据到所有匹配输出(Send data to all matching outputs)
默认行为:一条数据只要匹配到第一个规则,就停止检查其他规则。
启用后 :同时匹配多个规则的数据会被复制到所有匹配的输出分支。
场景:标签系统中,一条数据可能同时属于多个标签,需要被发送到所有相关的处理流程。
Switch vs If:何时选择哪个?
| 对比维度 | If节点 | Switch节点 |
|---|---|---|
| 输出分支数 | 固定2个(真/假) | 无限制 |
| 条件复杂性 | 简单(单一真假判断) | 复杂(多分支选择) |
| 最适用场景 | 二元决策:发送或不发送、通过或阻止 | 多路由:优先级划分、类型分类、状态判断 |
| 易用性 | 直观简洁 | 功能更强大 |
| 性能 | 略快 | 略慢(但差异微乎其微) |
实际建议:
- 问自己:"我需要2个还是更多个处理分支?"
- 如果≤2个,用If
- 如果>2个,用Switch
实战案例:客户反馈优先级路由工作流
现在让我们用一个完整的、可执行的案例来演示Switch节点的强大功能。
业务场景
你的公司收到多渠道客户反馈,需要根据优先级进行分发:
- 高优先级(high):立即通知管理员,通过紧急Slack频道
- 中优先级(medium):记录到数据库,定期处理
- 低优先级(low):存档,月度回顾
- 未知优先级:人工审核队列
工作流架构
┌─────────────────┐
│ Webhook触发 │ (接收客户反馈数据)
└────────┬────────┘
│
▼
┌─────────────────┐
│ Switch节点 │ (根据priority字段路由)
└────────┬────────┘
┌────┼────┬─────┐
│ │ │ │
▼ ▼ ▼ ▼
高优 中优 低优 未知
先级 先级 先级 优先级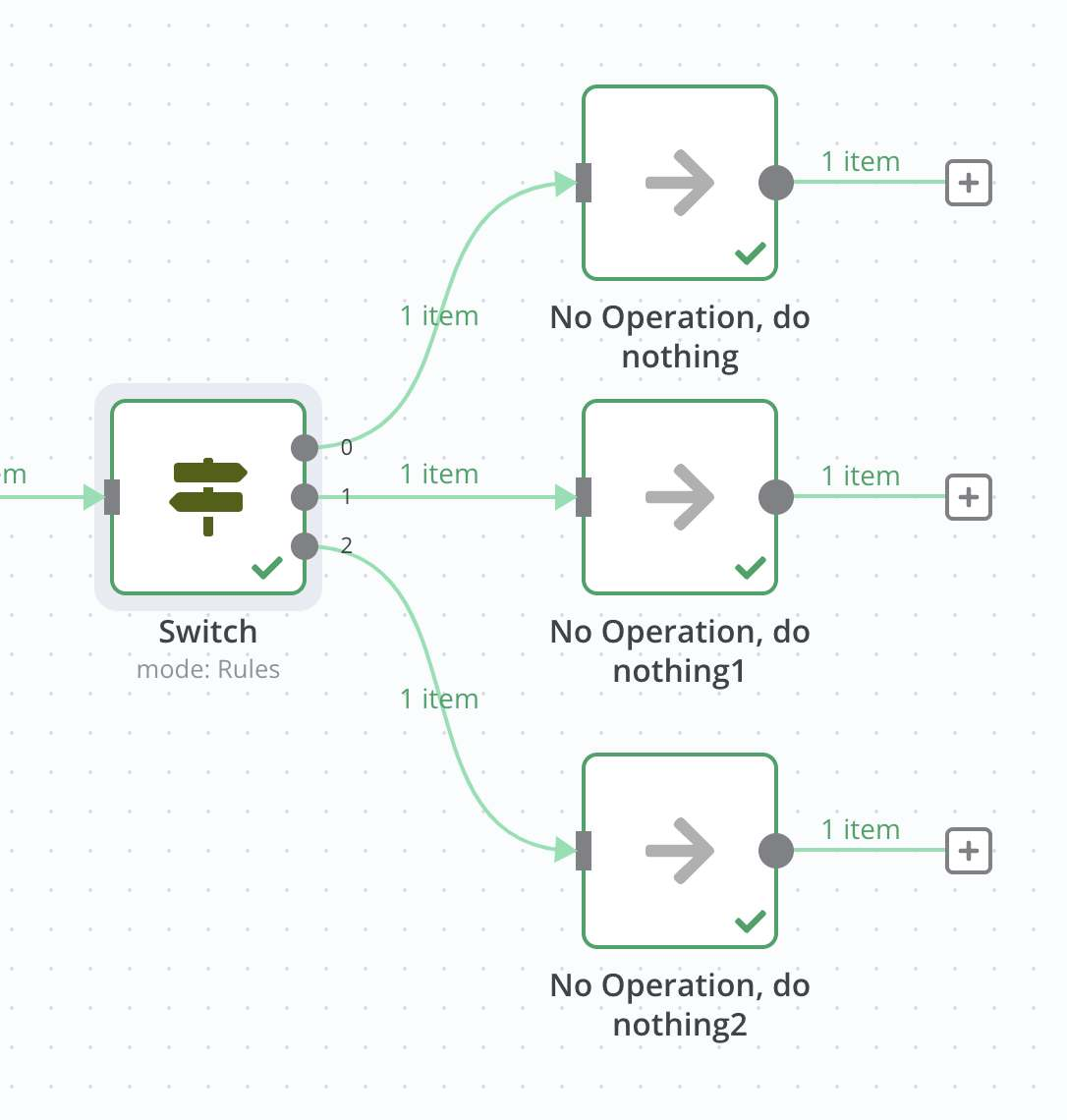
完整工作流JSON代码
json
{
"name": "客户反馈优先级路由 - Switch节点教程",
"nodes": [
{
"parameters": {
"method": "POST",
"url": "https://webhook.site/your-unique-id",
"options": {}
},
"id": "1",
"name": "Webhook",
"type": "n8n-nodes-base.webhook",
"typeVersion": 2,
"position": [100, 300]
},
{
"parameters": {
"options": {}
},
"id": "2",
"name": "Switch",
"type": "n8n-nodes-base.switch",
"typeVersion": 1,
"position": [400, 300],
"mode": "rules",
"rules": [
{
"condition": "string",
"value1": "={{ $json.priority }}",
"value2": "high",
"operator": "equal",
"output": 0
},
{
"condition": "string",
"value1": "={{ $json.priority }}",
"value2": "medium",
"operator": "equal",
"output": 1
},
{
"condition": "string",
"value1": "={{ $json.priority }}",
"value2": "low",
"operator": "equal",
"output": 2
}
],
"options": {
"fallbackOutput": 3,
"ignoreCaseInStringComparison": true
}
},
{
"parameters": {
"content": "🔴 高优先级反馈\n来自: {{ $json.sender }}\n内容: {{ $json.message }}"
},
"id": "3",
"name": "高优先级处理",
"type": "n8n-nodes-base.noOp",
"typeVersion": 1,
"position": [700, 100]
},
{
"parameters": {
"content": "🟡 中优先级反馈\n来自: {{ $json.sender }}\n内容: {{ $json.message }}"
},
"id": "4",
"name": "中优先级处理",
"type": "n8n-nodes-base.noOp",
"typeVersion": 1,
"position": [700, 300]
},
{
"parameters": {
"content": "🟢 低优先级反馈\n来自: {{ $json.sender }}\n内容: {{ $json.message }}"
},
"id": "5",
"name": "低优先级处理",
"type": "n8n-nodes-base.noOp",
"typeVersion": 1,
"position": [700, 500]
},
{
"parameters": {
"content": "⚪ 未知优先级 - 需要人工审核\n来自: {{ $json.sender }}\n内容: {{ $json.message }}\n优先级值: {{ $json.priority }}"
},
"id": "6",
"name": "降级处理",
"type": "n8n-nodes-base.noOp",
"typeVersion": 1,
"position": [700, 700]
}
],
"connections": {
"Webhook": {
"main": [
[
{
"node": "Switch",
"type": "main",
"index": 0
}
]
]
},
"Switch": {
"main": [
[
{
"node": "高优先级处理",
"type": "main",
"index": 0
}
],
[
{
"node": "中优先级处理",
"type": "main",
"index": 0
}
],
[
{
"node": "低优先级处理",
"type": "main",
"index": 0
}
],
[
{
"node": "降级处理",
"type": "main",
"index": 0
}
]
]
}
}
}如何使用这个工作流
第1步:导入工作流
- 复制上述JSON代码
- 进入你的n8n仪表板,点击"新建工作流"
- 点击右上角"..."菜单,选择"从文件导入"
- 粘贴JSON代码并导入
第2步:配置Webhook
- 打开Webhook节点
- 复制显示的Webhook URL
- 使用任何HTTP工具(如Postman或curl)向该URL发送测试数据
第3步:发送测试数据
使用cURL命令:
bash
curl -X POST https://your-webhook-url \
-H "Content-Type: application/json" \
-d '{
"sender": "customer@example.com",
"message": "我的订单出现了问题",
"priority": "high"
}'第4步:检查执行结果
- 运行工作流
- 查看"执行历史"
- 观察数据是否被正确路由到对应的优先级分支
常见错误与解决方案
❌ 错误1:数据没有被路由到任何输出
原因: 数据不匹配任何配置的规则
解决:
- 检查字段名称是否正确(区分大小写)
- 使用"执行单个节点"来查看前一个节点的实际输出
- 检查比较值是否包含多余空格
❌ 错误2:大小写导致的匹配失败
原因: 数据中是"HIGH",但规则中写的是"high"
解决:
- 启用"Ignore Case"选项
- 或在前一个节点中使用
.toLowerCase()规范化数据
❌ 错误3:Expression模式返回NaN或undefined
原因: 表达式语法错误
解决:
- 检查变量引用是否正确:
$json.fieldName - 使用JavaScript控制台测试表达式
- 参考n8n表达式文档:https://docs.n8n.io/code-examples/expressions/
❌ 错误4:多条规则都匹配,数据只输出到第一个
原因: 没有启用"Send data to all matching outputs"
解决:
- 打开Switch节点的Options
- 启用"Send data to all matching outputs"
- 此时匹配多个规则的数据会被复制到所有对应的输出
进阶技巧
技巧1:使用表达式实现复杂条件
在Rules模式下,虽然界面有限制,但你可以在比较值中使用表达式:
配置示例:
value1: {{ $json.amount }}
operator: 大于
value2: {{ $json.limit + 100 }}技巧2:根据数组长度进行路由
condition: Array
value1: {{ $json.tags }}
operator: length greater than
value2: 5这样,只有标签数大于5的数据才会被路由到这条分支。
技巧3:使用正则表达式进行高级文本匹配
condition: String
value1: {{ $json.email }}
operator: matches regex
value2: ^[a-zA-Z0-9._%+-]+@(gmail|yahoo|outlook)\.com$这样只会匹配特定邮箱域名的用户。
技巧4:先排序再Switch,优化性能
如果你的数据量很大,先用Sort节点对数据进行分组,再用Switch处理,能显著提升性能。
调试技巧
1. 单步执行
点击Switch节点,选择"Execute node"(执行此节点),只执行到这里停止,查看各分支的输出。
2. 使用日志节点(Logger Node)
在Switch前后各添加一个Logger节点,记录数据内容:
json
前置日志: {{ JSON.stringify($json) }}
后置日志: 进入分支 {{ $node["Switch"].json.output }}3. 检查表达式错误
在Expression模式下,若有错误,会显示红色警告。鼠标悬停可看错误详情。
4. 测试数据
使用"测试数据"功能注入虚拟数据:
json
{
"sender": "test@example.com",
"message": "Test message",
"priority": "high"
}总结要点
| 要点 | 说明 |
|---|---|
| 适用场景 | 需要根据条件将数据分发到多个处理分支 |
| 配置方式 | Rules(可视化)或Expression(编程) |
| 核心优势 | 无限制分支、易于维护、无需编码 |
| 关键参数 | 条件、数据类型、比较操作符、降级输出 |
| 常见问题 | 大小写、字段名、降级处理 |
| 最佳实践 | 使用有意义的输出名称、启用Ignore Case、正确配置降级输出 |
下一步学习路径
掌握Switch节点后,你可以进一步学习:
- 与If节点结合 - 构建更复杂的条件逻辑
- Filter节点 - 过滤不需要的数据
- Loop Over Items - 对集合中的每个元素运行Switch
- 错误处理 - 使用Switch处理异常情况
- 性能优化 - 在大数据量场景下优化Switch逻辑