一、HTTP 缓存的本质
HTTP 缓存的核心目标是:让客户端(浏览器)尽可能复用已获取的资源,减少重复请求,提升页面加载速度、降低服务器压力。
简单来说:
- 第一次请求:浏览器从服务器获取资源(如 JS/CSS/ 图片),并保存一份副本到本地缓存;
- 后续请求:浏览器先检查本地缓存,若资源未过期,直接使用本地副本,无需请求服务器;若过期,通过条件请求向服务器验证 "资源是否真的更新",仅在更新时重新下载。
二、HTTP 缓存的分类(按缓存决策主体)
缓存分为两大类型,条件请求主要作用于 "协商缓存" 阶段:
| 缓存类型 | 决策主体 | 核心逻辑 | 特点 |
|---|---|---|---|
| 强缓存(本地缓存) | 浏览器 | 完全由浏览器判断,无需和服务器交互:若资源未过期,直接用本地缓存 | 性能最优(零网络请求) |
| 协商缓存(条件请求) | 浏览器 + 服务器 | 浏览器先发送条件请求到服务器,服务器验证资源是否更新,返回 "复用缓存" 或 "重新下载" | 更精准(避免缓存过期但资源未变) |
第一部分:强缓存
强缓存是浏览器的 "自主决策",核心是通过响应头判断资源是否过期,过期前完全不请求服务器。
1. 核心响应头(服务器下发)
服务器通过以下响应头告诉浏览器 "资源的过期规则":
(1)Expires(HTTP/1.0 字段)
- 格式:绝对时间(GMT 格式),如
Expires: Sat, 03 Jan 2026 12:00:00 GMT; - 逻辑:浏览器对比本地时间和
Expires时间,若本地时间 < Expires 时间,使用本地缓存; - 缺陷:依赖客户端本地时间,若客户端时间错误(如手动修改),会导致缓存失效 / 一直生效。
(2)Cache-Control(HTTP/1.1 字段,优先级高于 Expires)
这是现代浏览器的主流配置,支持多个指令组合,核心指令:
| 指令 | 作用 |
|---|---|
max-age=秒数 |
资源的有效期(相对时间),如 max-age=3600 表示 1 小时内有效 |
public |
资源可被所有缓存(浏览器、CDN、代理服务器)缓存 |
private |
资源仅能被浏览器缓存(CDN / 代理服务器不缓存,适用于用户专属资源) |
no-cache |
不使用强缓存,必须走协商缓存(每次都要和服务器验证) |
no-store |
完全不缓存资源(每次都从服务器重新下载,禁用所有缓存) |
must-revalidate |
缓存过期后,必须向服务器验证,不能使用过期缓存 |
示例:服务器返回的强缓存响应头
HTTP/1.1 200 OK
Content-Type: application/javascript
Cache-Control: public, max-age=3600 # 1小时内强缓存
Expires: Sat, 03 Jan 2026 12:00:00 GMT # 兜底(兼容HTTP/1.0)
Last-Modified: Fri, 02 Jan 2026 10:00:00 GMT # 为协商缓存做准备
ETag: "abc123456" # 为协商缓存做准备2. 强缓存的交互流程
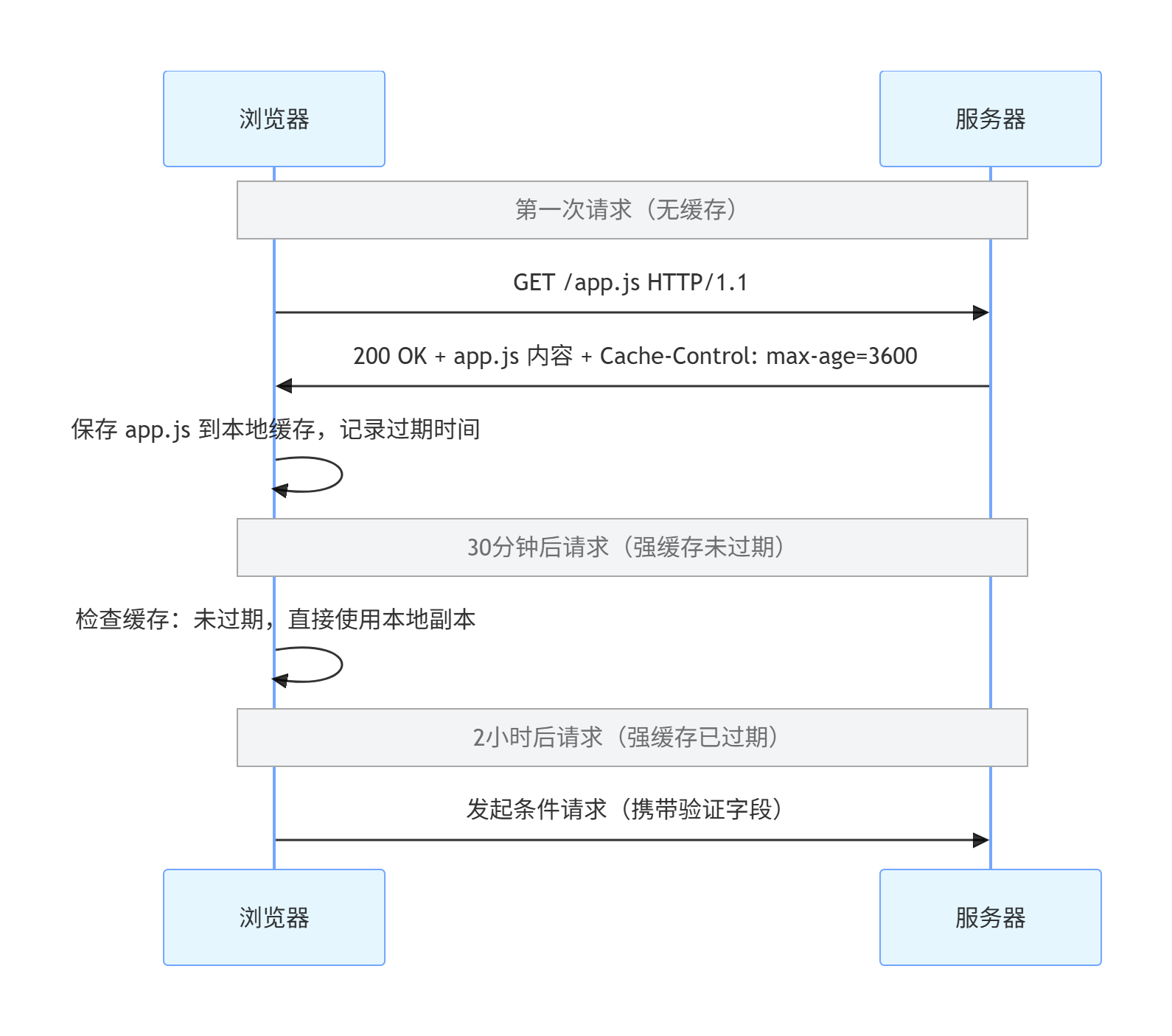
第二部分:条件请求(协商缓存的核心)
当强缓存过期后,浏览器不会直接丢弃缓存,而是发送条件请求到服务器:"我的缓存资源版本是 X,你那边有没有更新?"。服务器验证后,返回 "304 Not Modified"(复用缓存)或 "200 OK"(重新下载)。
1. 条件请求的核心机制
条件请求依赖 "服务器下发的资源标识" + "浏览器携带的验证字段",分为两套验证体系:
| 验证体系 | 服务器响应头(资源标识) | 浏览器请求头(验证字段) | 核心逻辑 |
|---|---|---|---|
| 基于修改时间 | Last-Modified |
If-Modified-Since |
验证资源自上次后是否修改 |
| 基于唯一标识 | ETag(实体标签) |
If-None-Match |
验证资源内容是否变化(更精准) |
2. 第一套:Last-Modified + If-Modified-Since
(1)核心字段解析
Last-Modified(服务器响应头):服务器返回资源的 "最后修改时间"(GMT 格式);If-Modified-Since(浏览器请求头):强缓存过期后,浏览器携带这个字段,值为上次的Last-Modified,意思是 "如果资源在这个时间之后修改过,就返回新内容,否则返回 304"。
(2)交互流程
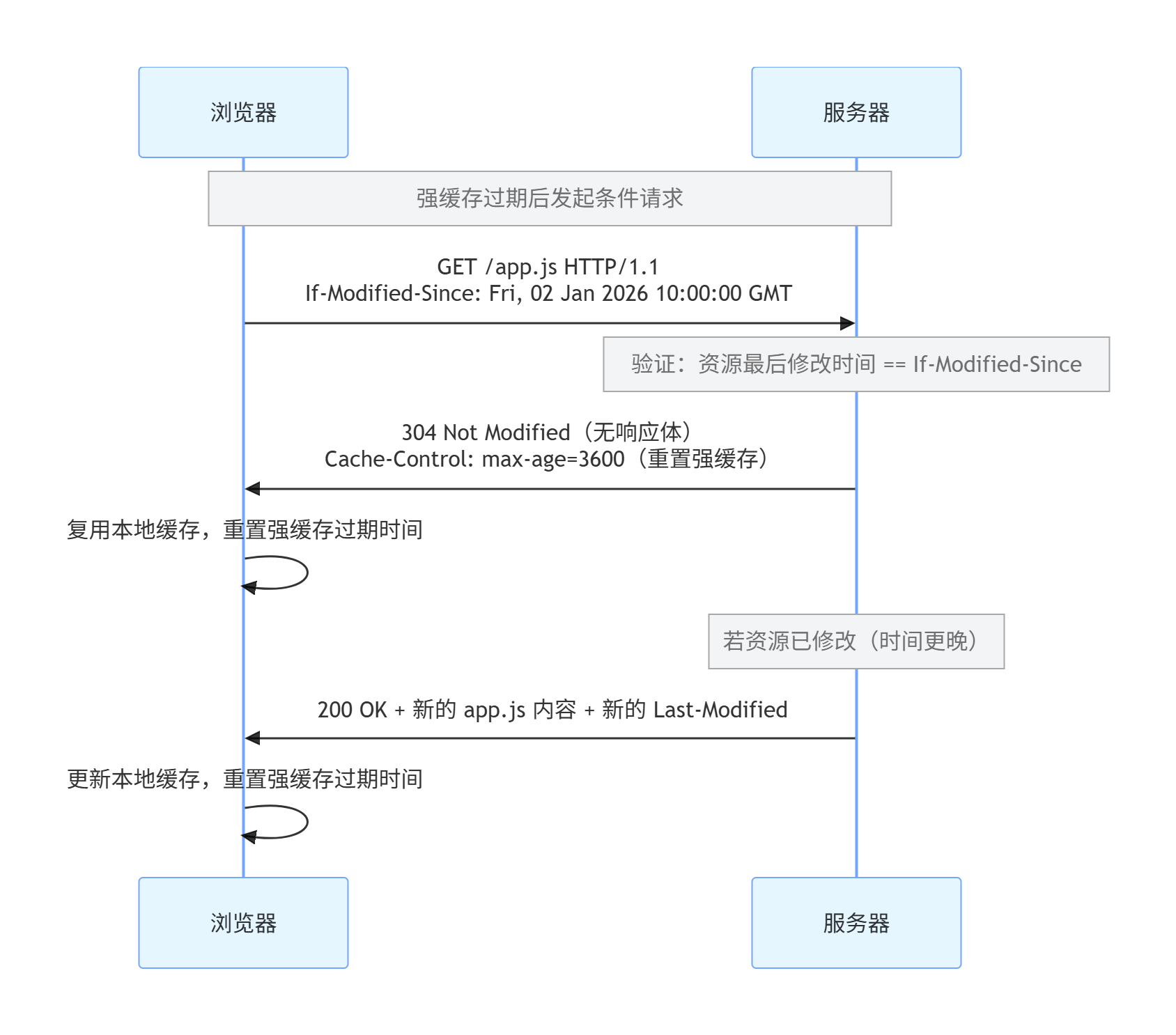
(3)缺陷
- 精度问题:只能精确到秒,若资源 1 秒内多次修改,无法识别;
- 误判问题:资源内容未变,但修改时间变了(如重新保存文件),会导致不必要的重新下载。
3. 第二套:ETag + If-None-Match(推荐,优先级更高)
ETag 是服务器为资源生成的唯一标识 (通常是资源内容的哈希值,如 MD5),资源内容不变则 ETag 不变,内容变则 ETag 变,解决了 Last-Modified 的缺陷。
(1)核心字段解析
ETag(服务器响应头):资源的唯一标识,如ETag: "abc123456"(弱 ETag 会加W/,如W/"abc123456",允许内容轻微变化);If-None-Match(浏览器请求头):强缓存过期后,浏览器携带这个字段,值为上次的ETag,意思是 "如果资源的 ETag 不等于这个值,就返回新内容,否则返回 304"。
(2)交互流程(电商场景示例)
假设电商页面的商品列表接口 /api/goods/list 配置了 ETag 缓存:

(3)优势
- 精准:只要资源内容不变,无论修改时间如何,都能返回 304;
- 支持分布式服务器:多台服务器生成的 ETag 一致(基于内容哈希),避免缓存失效。
4. 条件请求的其他场景(断点续传)
条件请求不仅用于缓存,还用于断点续传(之前讲过的下载功能):
- 下载时,浏览器发送
Range: bytes=1000-(请求从 1000 字节开始的内容),这也是一种条件请求; - 服务器返回
206 Partial Content,并携带Content-Range响应头,实现断点续传。
第三部分:缓存的完整生命周期(结合条件请求)
以电商网站的静态资源(如 main.css)为例,完整的缓存流程如下:
- 首次请求 :浏览器发送 GET 请求 → 服务器返回 200 + 资源 +
Cache-Control: max-age=86400+ETag: "css-123"→ 浏览器保存缓存; - 强缓存阶段:24 小时内,浏览器请求该资源时,直接用本地缓存(零网络请求);
- 条件请求阶段 :24 小时后,强缓存过期 → 浏览器发送 GET 请求,携带
If-None-Match: "css-123"→ 服务器验证 ETag:- 若资源未变:返回 304 + 重置
max-age=86400→ 浏览器复用缓存,重置过期时间; - 若资源已变:返回 200 + 新资源 + 新 ETag → 浏览器更新缓存。
- 若资源未变:返回 304 + 重置
关键补充:缓存的失效策略
- 主动失效 :服务器更新资源后,修改文件名(如
main.v2.css),强制浏览器重新下载; - 被动失效 :通过
Cache-Control: no-cache跳过强缓存,每次都走协商缓存; - 完全禁用 :
Cache-Control: no-store,所有请求都从服务器重新下载(适用于敏感数据,如用户余额)。