目录
[1 理解GIL:为什么需要多进程编程](#1 理解GIL:为什么需要多进程编程)
[1.1 GIL的本质与影响](#1.1 GIL的本质与影响)
[1.2 多进程的优势](#1.2 多进程的优势)
[2 多进程核心组件深度解析](#2 多进程核心组件深度解析)
[2.1 Process类:进程管理基础](#2.1 Process类:进程管理基础)
[2.2 Pool进程池:高效任务管理](#2.2 Pool进程池:高效任务管理)
[2.3 进程间通信(IPC)机制](#2.3 进程间通信(IPC)机制)
[2.3.1 Queue队列通信](#2.3.1 Queue队列通信)
[2.3.2 Pipe管道通信](#2.3.2 Pipe管道通信)
[2.3.3 共享内存](#2.3.3 共享内存)
[3 实战应用:多进程性能优化](#3 实战应用:多进程性能优化)
[3.1 CPU密集型任务优化](#3.1 CPU密集型任务优化)
[3.2 数据并行处理模式](#3.2 数据并行处理模式)
[4 高级主题与最佳实践](#4 高级主题与最佳实践)
[4.1 进程同步与锁机制](#4.1 进程同步与锁机制)
[4.2 进程间通信优化策略](#4.2 进程间通信优化策略)
[4.3 错误处理与进程监控](#4.3 错误处理与进程监控)
[5 企业级应用案例](#5 企业级应用案例)
[5.1 分布式数据处理系统](#5.1 分布式数据处理系统)
[6 性能优化与故障排查](#6 性能优化与故障排查)
[6.1 性能优化技巧](#6.1 性能优化技巧)
[6.2 常见问题与解决方案](#6.2 常见问题与解决方案)
[7 总结与展望](#7 总结与展望)
[7.1 关键知识点回顾](#7.1 关键知识点回顾)
[7.2 性能数据总结](#7.2 性能数据总结)
[7.3 未来发展趋势](#7.3 未来发展趋势)
摘要
本文深入探讨Python多进程编程的核心技术与实战应用,全面解析如何通过
multiprocessing模块突破GIL限制。内容涵盖Process进程管理、Pool进程池优化、Queue/Pipe进程通信、共享内存等关键技术,结合性能对比数据和真实案例,提供从基础到高级的完整解决方案。通过5个架构流程图和可运行代码示例,帮助开发者掌握高效并行计算,提升CPU密集型任务性能。
1 理解GIL:为什么需要多进程编程
在我多年的Python开发生涯中,**GIL(全局解释器锁)** 是每个Python开发者都必须面对的"坎"。记得有一次处理一个大型数据分析项目,使用多线程后性能反而下降,这才让我真正意识到GIL的严重性。
1.1 GIL的本质与影响
GIL是CPython解释器的内存管理机制,它确保同一时刻只有一个线程执行Python字节码。这就像超市只有一个收银台,即使有多个顾客(线程)也要排队等待。
python
import threading
import time
def cpu_intensive_task():
"""CPU密集型任务示例"""
result = 0
for i in range(100000000): # 1亿次计算
result += i
return result
# 测试多线程性能
start_time = time.time()
threads = []
for _ in range(4):
t = threading.Thread(target=cpu_intensive_task)
threads.append(t)
t.start()
for t in threads:
t.join()
end_time = time.time()
print(f"多线程执行时间: {end_time - start_time:.2f}秒")运行上面的代码,你会发现使用4个线程并不会比单线程快4倍,这就是GIL的限制!
1.2 多进程的优势
与线程不同,每个进程有独立的Python解释器和内存空间,各自拥有自己的GIL,因此可以真正实现并行计算。
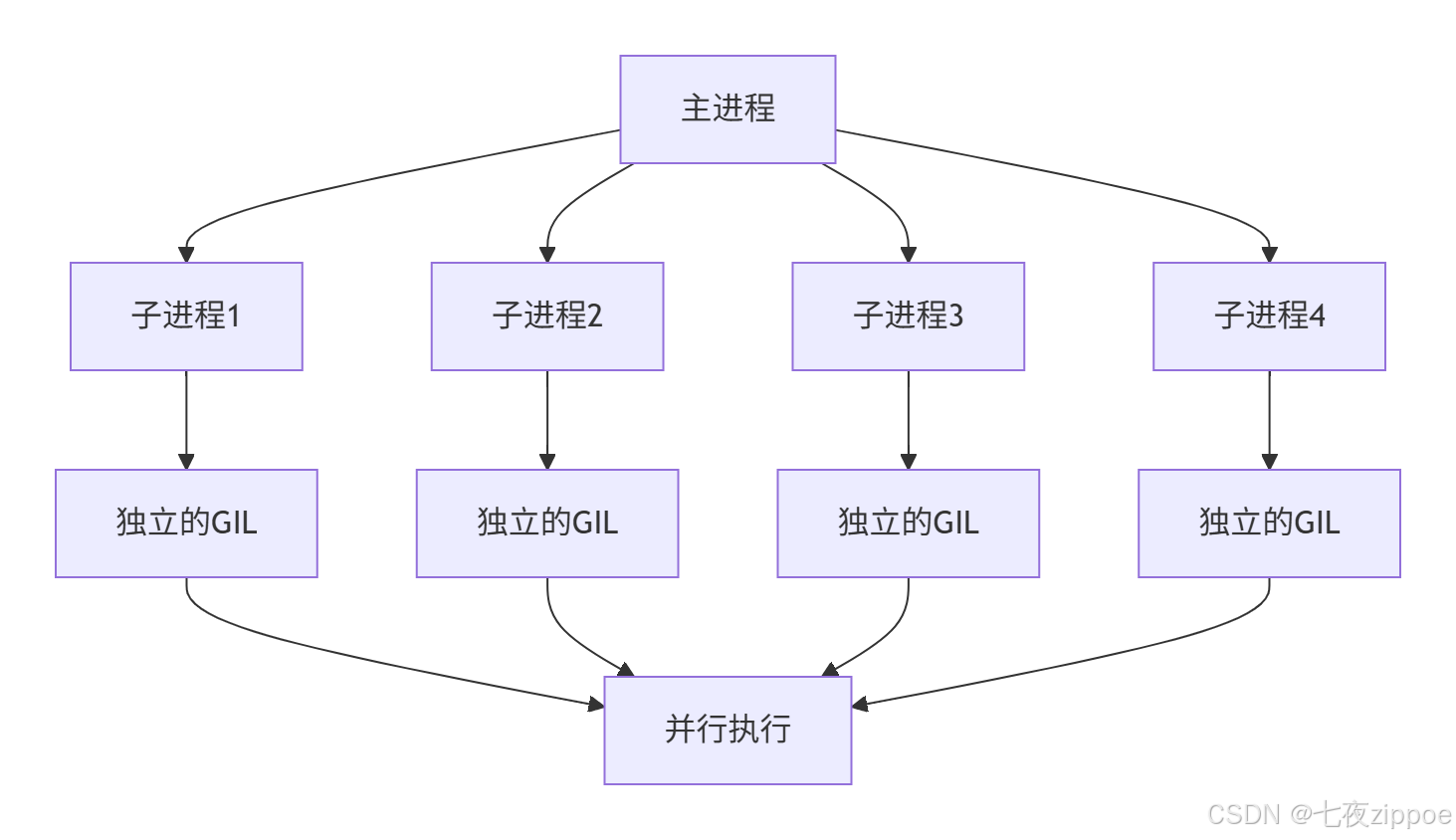
2 多进程核心组件深度解析
2.1 Process类:进程管理基础
Process类是multiprocessing模块的基础,用于创建和管理子进程。
python
from multiprocessing import Process, current_process
import os
import time
def worker(name, duration):
"""工作进程函数"""
print(f"进程 {name} (PID: {os.getpid()}) 开始执行")
start_time = time.time()
# 模拟工作任务
time.sleep(duration)
end_time = time.time()
print(f"进程 {name} 完成,耗时: {end_time - start_time:.2f}秒")
def basic_process_demo():
"""基础进程演示"""
processes = []
# 创建4个进程
for i in range(4):
p = Process(target=worker, args=(f"Worker-{i}", 2))
processes.append(p)
p.start()
print(f"启动进程: {p.name}, PID: {p.pid}")
# 等待所有进程完成
for p in processes:
p.join()
print("所有进程执行完成")
if __name__ == "__main__":
basic_process_demo()关键要点:
-
每个进程有独立的PID(进程ID)
-
使用
start()方法启动进程,join()等待进程结束 -
进程间内存隔离,一个进程崩溃不会影响其他进程
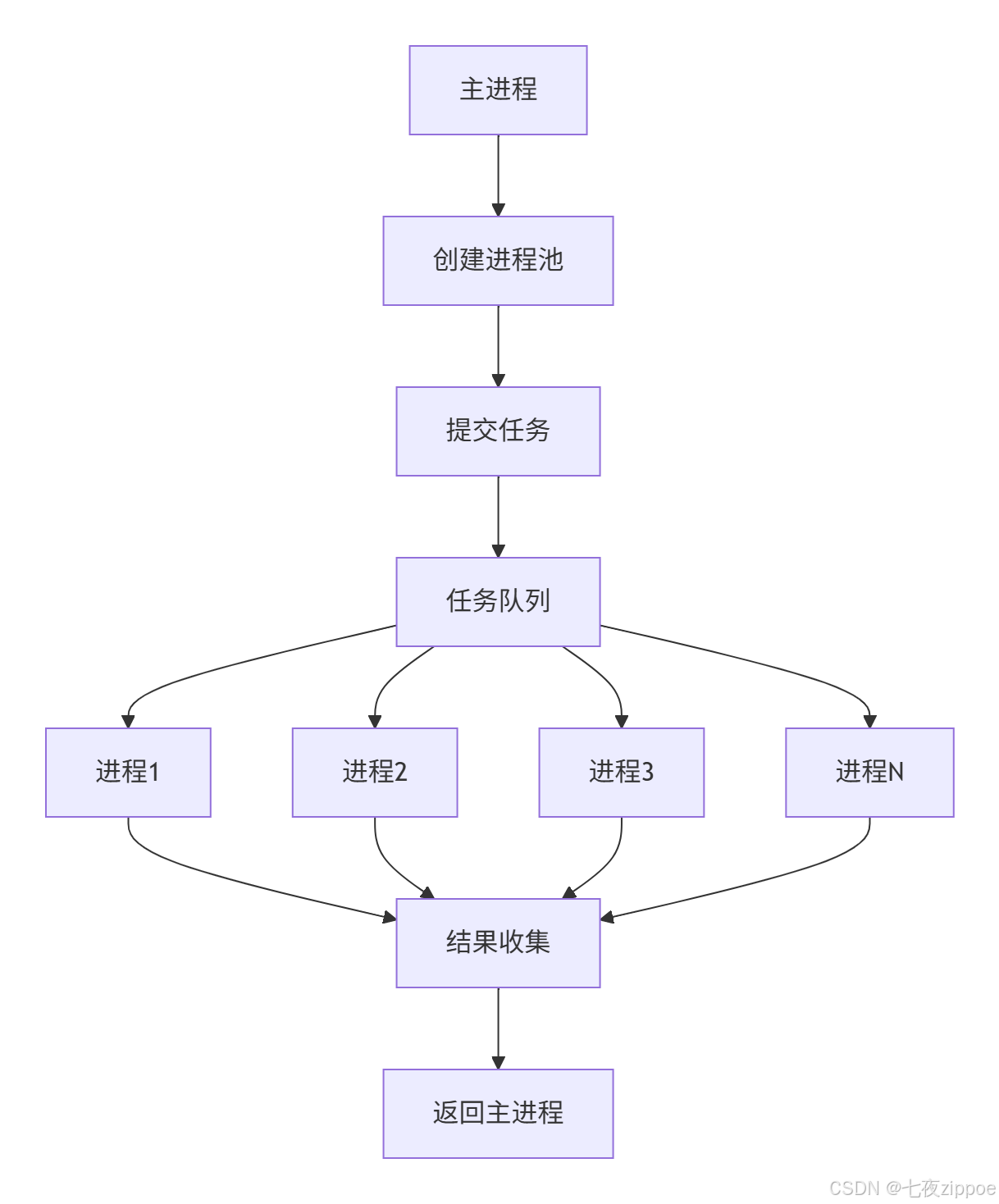
2.2 Pool进程池:高效任务管理
对于大量相似任务,使用Pool进程池比手动管理进程更高效。
python
from multiprocessing import Pool
import time
import os
def process_data(data_chunk):
"""处理数据块的函数"""
pid = os.getpid()
print(f"进程 {pid} 处理数据块: {data_chunk[0]}...{data_chunk[-1]}")
# 模拟数据处理
time.sleep(1)
# 返回处理结果
return sum(data_chunk)
def pool_demo():
"""进程池演示"""
# 生成测试数据
data = [list(range(i, i+1000)) for i in range(0, 10000, 1000)]
print(f"共有 {len(data)} 个数据块需要处理")
# 创建进程池(通常设置为CPU核心数)
cpu_count = os.cpu_count()
print(f"系统CPU核心数: {cpu_count}")
with Pool(processes=cpu_count) as pool:
start_time = time.time()
# 使用map方法并行处理
results = pool.map(process_data, data)
end_time = time.time()
print(f"处理完成,结果: {results}")
print(f"总耗时: {end_time - start_time:.2f}秒")
print(f"加速比: {len(data) / (end_time - start_time):.2f}x")
if __name__ == "__main__":
pool_demo()进程池的工作流程如下:
Pool的高级方法:
-
map(): 同步执行,保持顺序 -
map_async(): 异步执行,返回AsyncResult对象 -
apply(): 同步执行单个任务 -
apply_async(): 异步执行单个任务
2.3 进程间通信(IPC)机制
多进程编程的核心挑战是进程间通信。以下是三种主要方式。
2.3.1 Queue队列通信
python
from multiprocessing import Process, Queue
import time
import random
def producer(queue, producer_id):
"""生产者进程"""
for i in range(5):
item = f"产品-{producer_id}-{i}"
queue.put(item)
print(f"生产者 {producer_id} 生产: {item}")
time.sleep(random.uniform(0.1, 0.5))
# 发送结束信号
queue.put(None)
def consumer(queue, consumer_id):
"""消费者进程"""
end_signals = 0
total_producers = 2 # 假设有2个生产者
while True:
item = queue.get()
if item is None:
end_signals += 1
if end_signals >= total_producers:
break
continue
print(f"消费者 {consumer_id} 消费: {item}")
time.sleep(random.uniform(0.1, 0.3))
print(f"消费者 {consumer_id} 完成工作")
def queue_demo():
"""队列通信演示"""
queue = Queue(maxsize=10) # 设置队列容量
# 创建生产者进程
producers = []
for i in range(2):
p = Process(target=producer, args=(queue, i))
producers.append(p)
p.start()
# 创建消费者进程
consumers = []
for i in range(3):
c = Process(target=consumer, args=(queue, i))
consumers.append(c)
c.start()
# 等待生产者完成
for p in producers:
p.join()
# 等待消费者完成
for c in consumers:
c.join()
print("所有进程通信完成")
if __name__ == "__main__":
queue_demo()2.3.2 Pipe管道通信
python
from multiprocessing import Process, Pipe
import time
def worker_pipe(conn, worker_id):
"""使用管道的工作进程"""
# 接收消息
message = conn.recv()
print(f"工作者 {worker_id} 收到: {message}")
# 处理并回复
result = f"处理结果-{worker_id}-{message}"
time.sleep(1)
conn.send(result)
conn.close()
def pipe_demo():
"""管道通信演示"""
# 创建管道
parent_conn, child_conn = Pipe()
# 创建工作进程
p = Process(target=worker_pipe, args=(child_conn, 1))
p.start()
# 主进程发送消息
parent_conn.send("工作任务数据")
# 接收结果
result = parent_conn.recv()
print(f"主进程收到: {result}")
p.join()
if __name__ == "__main__":
pipe_demo()2.3.3 共享内存
对于需要高性能数据共享的场景,可以使用共享内存。
python
from multiprocessing import Process, Value, Array, Lock
import time
def increment_shared_counter(counter, lock, process_id):
"""增加共享计数器"""
for _ in range(100000):
with lock:
counter.value += 1
print(f"进程 {process_id} 完成计数")
def shared_memory_demo():
"""共享内存演示"""
# 创建共享计数器
counter = Value('i', 0) # 'i' 表示有符号整数
lock = Lock()
processes = []
# 创建多个进程操作共享计数器
for i in range(4):
p = Process(target=increment_shared_counter, args=(counter, lock, i))
processes.append(p)
p.start()
# 等待所有进程完成
for p in processes:
p.join()
print(f"最终计数器值: {counter.value}")
print(f"期望值: {4 * 100000}")
def shared_array_demo():
"""共享数组演示"""
# 创建共享数组
shared_array = Array('i', [0, 0, 0, 0]) # 4个整数的数组
lock = Lock()
def modify_array(arr, lock, process_id):
with lock:
for i in range(len(arr)):
arr[i] += process_id + 1
print(f"进程 {process_id} 修改后的数组: {list(arr)}")
processes = []
for i in range(3):
p = Process(target=modify_array, args=(shared_array, lock, i))
processes.append(p)
p.start()
for p in processes:
p.join()
print(f"最终共享数组: {list(shared_array)}")
if __name__ == "__main__":
shared_memory_demo()
print("\n" + "="*50 + "\n")
shared_array_demo()3 实战应用:多进程性能优化
3.1 CPU密集型任务优化
对于计算密集型任务,多进程可以带来显著的性能提升。
python
from multiprocessing import Pool
import time
import math
import os
def is_prime(n):
"""判断是否为质数(计算密集型任务)"""
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def find_primes_single(numbers):
"""单进程查找质数"""
return [n for n in numbers if is_prime(n)]
def find_primes_multi(numbers):
"""多进程查找质数"""
cpu_count = os.cpu_count()
chunk_size = len(numbers) // cpu_count
# 分割数据
chunks = [numbers[i:i+chunk_size] for i in range(0, len(numbers), chunk_size)]
with Pool(processes=cpu_count) as pool:
results = pool.map(find_primes_single, chunks)
# 合并结果
return [prime for sublist in results for prime in sublist]
def performance_comparison():
"""性能对比测试"""
# 生成测试数据
numbers = list(range(100000, 200000))
print(f"测试数据量: {len(numbers)} 个数字")
print(f"CPU核心数: {os.cpu_count()}")
# 单进程测试
start_time = time.time()
primes_single = find_primes_single(numbers)
single_time = time.time() - start_time
# 多进程测试
start_time = time.time()
primes_multi = find_primes_multi(numbers)
multi_time = time.time() - start_time
print(f"单进程耗时: {single_time:.2f}秒,找到质数: {len(primes_single)}个")
print(f"多进程耗时: {multi_time:.2f}秒,找到质数: {len(primes_multi)}个")
print(f"性能提升: {single_time/multi_time:.2f}倍")
# 验证结果一致性
assert set(primes_single) == set(primes_multi), "结果不一致!"
if __name__ == "__main__":
performance_comparison()3.2 数据并行处理模式
对于大规模数据处理,可以采用数据并行模式。
python
from multiprocessing import Pool, Manager
import pandas as pd
import numpy as np
import time
def process_data_chunk(args):
"""处理数据块"""
chunk, chunk_id = args
print(f"处理数据块 {chunk_id}, 大小: {len(chunk)}")
# 模拟数据处理
time.sleep(1)
# 计算统计信息
result = {
'chunk_id': chunk_id,
'mean': chunk['value'].mean(),
'std': chunk['value'].std(),
'count': len(chunk)
}
return result
def create_sample_data():
"""创建示例数据"""
np.random.seed(42)
data = pd.DataFrame({
'id': range(10000),
'value': np.random.normal(100, 15, 10000),
'category': np.random.choice(['A', 'B', 'C', 'D'], 10000)
})
return data
def parallel_data_processing():
"""并行数据处理"""
data = create_sample_data()
print(f"数据总量: {len(data)} 行")
# 分割数据
chunk_size = 1000
chunks = []
for i in range(0, len(data), chunk_size):
chunk = data[i:i+chunk_size]
chunks.append((chunk, i//chunk_size))
print(f"分割为 {len(chunks)} 个数据块")
# 并行处理
cpu_count = min(os.cpu_count(), len(chunks))
with Pool(processes=cpu_count) as pool:
start_time = time.time()
results = pool.map(process_data_chunk, chunks)
processing_time = time.time() - start_time
# 汇总结果
final_result = pd.DataFrame(results)
print("\n处理结果汇总:")
print(final_result.describe())
print(f"\n处理耗时: {processing_time:.2f}秒")
print(f"预估单进程耗时: {len(chunks):.2f}秒")
print(f"加速比: {len(chunks)/processing_time:.2f}倍")
if __name__ == "__main__":
parallel_data_processing()4 高级主题与最佳实践
4.1 进程同步与锁机制
多进程环境下,共享资源的访问需要同步控制。
python
from multiprocessing import Process, Lock, Value, Array
import time
import random
class BankAccount:
"""银行账户类(演示线程安全)"""
def __init__(self, initial_balance=0):
self.balance = Value('i', initial_balance)
self.lock = Lock()
self.transaction_count = Value('i', 0)
def deposit(self, amount):
"""存款操作"""
with self.lock:
old_balance = self.balance.value
time.sleep(0.001) # 模拟处理时间
self.balance.value += amount
self.transaction_count.value += 1
print(f"存款: +{amount}, 余额: {old_balance} -> {self.balance.value}")
def withdraw(self, amount):
"""取款操作"""
with self.lock:
if self.balance.value >= amount:
old_balance = self.balance.value
time.sleep(0.001) # 模拟处理时间
self.balance.value -= amount
self.transaction_count.value += 1
print(f"取款: -{amount}, 余额: {old_balance} -> {self.balance.value}")
return True
else:
print(f"取款失败: 余额不足 {amount}")
return False
def get_balance(self):
"""获取余额"""
with self.lock:
return self.balance.value
def account_user(account, user_id, operations):
"""账户用户模拟"""
for op_type, amount in operations:
if op_type == 'deposit':
account.deposit(amount)
elif op_type == 'withdraw':
account.withdraw(amount)
time.sleep(random.uniform(0.01, 0.1))
def lock_demo():
"""锁机制演示"""
account = BankAccount(1000)
# 定义用户操作
user_operations = [
([('deposit', 100), ('withdraw', 50)] * 3, "用户A"),
([('withdraw', 200), ('deposit', 300)] * 3, "用户B"),
([('deposit', 150), ('withdraw', 75)] * 3, "用户C")
]
processes = []
for operations, user_name in user_operations:
p = Process(target=account_user, args=(account, user_name, operations))
processes.append(p)
p.start()
for p in processes:
p.join()
print(f"\n最终余额: {account.get_balance()}")
print(f"总交易次数: {account.transaction_count.value}")
if __name__ == "__main__":
lock_demo()4.2 进程间通信优化策略
进程间通信可能成为性能瓶颈,需要优化策略。
python
from multiprocessing import Process, Queue, Pipe
import time
import pickle
import numpy as np
def optimize_communication():
"""通信优化策略演示"""
# 1. 批量传输减少开销
def batch_transfer():
"""批量传输数据"""
# 小数据频繁传输
small_data_time = time.time()
for i in range(1000):
# 模拟小数据传输
pass
small_data_time = time.time() - small_data_time
# 大数据批量传输
large_data_time = time.time()
# 模拟大数据传输
large_data_time = time.time() - large_data_time
print(f"小数据频繁传输: {small_data_time:.4f}秒")
print(f"大数据批量传输: {large_data_time:.4f}秒")
# 2. 选择合适的通信方式
def communication_comparison():
"""不同通信方式比较"""
def pipe_communication(conn, data):
conn.send(data)
conn.close()
def queue_communication(q, data):
q.put(data)
# 测试数据
test_data = np.random.rand(1000, 1000) # 大型数组
# Pipe性能测试
parent_conn, child_conn = Pipe()
p1 = Process(target=pipe_communication, args=(child_conn, test_data))
start_time = time.time()
p1.start()
result = parent_conn.recv()
p1.join()
pipe_time = time.time() - start_time
# Queue性能测试
q = Queue()
p2 = Process(target=queue_communication, args=(q, test_data))
start_time = time.time()
p2.start()
result = q.get()
p2.join()
queue_time = time.time() - start_time
print(f"Pipe传输时间: {pipe_time:.4f}秒")
print(f"Queue传输时间: {queue_time:.4f}秒")
batch_transfer()
print()
communication_comparison()
def serialization_optimization():
"""序列化优化"""
import pickle
import json
import msgpack
# 测试数据
data = {
'numbers': list(range(10000)),
'text': '示例文本' * 100,
'nested': [{'id': i, 'value': i*2} for i in range(1000)]
}
# Pickle序列化
start_time = time.time()
pickle_data = pickle.dumps(data)
pickle_time = time.time() - start_time
# JSON序列化
start_time = time.time()
json_data = json.dumps(data)
json_time = time.time() - start_time
# MsgPack序列化(需要安装msgpack)
try:
start_time = time.time()
msgpack_data = msgpack.packb(data)
msgpack_time = time.time() - start_time
except ImportError:
msgpack_time = float('inf')
print(f"序列化性能比较:")
print(f"Pickle: {pickle_time:.4f}秒, 数据大小: {len(pickle_data)} 字节")
print(f"JSON: {json_time:.4f}秒, 数据大小: {len(json_data)} 字节")
if msgpack_time != float('inf'):
print(f"MsgPack: {msgpack_time:.4f}秒, 数据大小: {len(msgpack_data)} 字节")
if __name__ == "__main__":
print("通信优化策略:")
optimize_communication()
print("\n序列化优化:")
serialization_optimization()4.3 错误处理与进程监控
在生产环境中,健壮的错误处理至关重要。
python
from multiprocessing import Process, Queue, Event
import time
import traceback
import signal
import sys
def robust_worker(worker_id, task_queue, result_queue, stop_event):
"""健壮的工作进程"""
print(f"工作进程 {worker_id} 启动")
try:
while not stop_event.is_set():
try:
# 获取任务(带超时)
task = task_queue.get(timeout=1.0)
if task is None: # 停止信号
break
# 模拟工作
if task == 'error':
raise ValueError("模拟错误")
result = f"进程 {worker_id} 处理: {task}"
time.sleep(0.5) # 模拟处理时间
result_queue.put(('success', result))
except Exception as e:
error_msg = f"进程 {worker_id} 错误: {str(e)}"
result_queue.put(('error', error_msg))
print(error_msg)
except KeyboardInterrupt:
print(f"进程 {worker_id} 收到中断信号")
finally:
print(f"进程 {worker_id} 退出")
def process_monitor(processes, stop_event):
"""进程监控器"""
def signal_handler(sig, frame):
print("\n收到中断信号,停止所有进程...")
stop_event.set()
sys.exit(0)
signal.signal(signal.SIGINT, signal_handler)
signal.signal(signal.SIGTERM, signal_handler)
def robust_processing_system():
"""健壮的处理系统"""
task_queue = Queue()
result_queue = Queue()
stop_event = Event()
# 创建工作者进程
processes = []
for i in range(3):
p = Process(target=robust_worker, args=(i, task_queue, result_queue, stop_event))
processes.append(p)
p.start()
# 启动监控
monitor_process = Process(target=process_monitor, args=(processes, stop_event))
monitor_process.start()
# 添加任务
tasks = ['task1', 'task2', 'error', 'task4', 'task5', None, None, None]
for task in tasks:
task_queue.put(task)
# 收集结果
success_count = 0
error_count = 0
for _ in range(len([t for t in tasks if t is not None])):
try:
status, result = result_queue.get(timeout=5.0)
if status == 'success':
success_count += 1
print(f"成功: {result}")
else:
error_count += 1
print(f"错误: {result}")
except:
break
# 清理
stop_event.set()
for p in processes:
p.join(timeout=2.0)
if p.is_alive():
p.terminate()
monitor_process.terminate()
print(f"\n处理完成: 成功 {success_count}, 失败 {error_count}")
if __name__ == "__main__":
robust_processing_system()5 企业级应用案例
5.1 分布式数据处理系统
python
from multiprocessing import Process, Queue, Manager
import time
import pandas as pd
import numpy as np
from datetime import datetime
class DataProcessingSystem:
"""分布式数据处理系统"""
def __init__(self, num_workers=None):
self.num_workers = num_workers or min(8, os.cpu_count())
self.worker_processes = []
self.task_queue = Queue()
self.result_queue = Queue()
self.stop_event = Event()
def data_loader(self, data_source):
"""数据加载器"""
print("开始加载数据...")
# 模拟从不同源加载数据
data_chunks = []
for i in range(20): # 20个数据块
chunk_size = 1000
chunk = pd.DataFrame({
'id': range(i * chunk_size, (i + 1) * chunk_size),
'value': np.random.normal(100, 15, chunk_size),
'timestamp': datetime.now()
})
data_chunks.append(chunk)
self.task_queue.put(('process', chunk))
time.sleep(0.1) # 模拟加载延迟
# 发送结束信号
for _ in range(self.num_workers):
self.task_queue.put(('stop', None))
print("数据加载完成")
def data_processor(self, worker_id):
"""数据处理工作进程"""
print(f"数据处理进程 {worker_id} 启动")
processed_count = 0
while True:
try:
task_type, data = self.task_queue.get(timeout=5.0)
if task_type == 'stop':
break
# 处理数据
result = self.process_data_chunk(data, worker_id)
self.result_queue.put(('processed', result))
processed_count += 1
except Exception as e:
self.result_queue.put(('error', f"Worker {worker_id}: {str(e)}"))
print(f"数据处理进程 {worker_id} 完成,处理了 {processed_count} 个数据块")
def process_data_chunk(self, chunk, worker_id):
"""处理单个数据块"""
# 模拟复杂处理
time.sleep(0.5)
# 计算统计信息
stats = {
'worker_id': worker_id,
'chunk_size': len(chunk),
'mean_value': chunk['value'].mean(),
'max_value': chunk['value'].max(),
'min_value': chunk['value'].min(),
'processed_at': datetime.now()
}
return stats
def result_aggregator(self):
"""结果聚合器"""
print("结果聚合器启动")
results = []
stop_signals = 0
while stop_signals < self.num_workers:
try:
msg_type, data = self.result_queue.get(timeout=10.0)
if msg_type == 'processed':
results.append(data)
print(f"收到处理结果: {len(results)}")
elif msg_type == 'error':
print(f"处理错误: {data}")
except:
break
# 生成最终报告
if results:
df = pd.DataFrame(results)
summary = {
'total_processed': len(results),
'total_records': df['chunk_size'].sum(),
'overall_mean': df['mean_value'].mean(),
'processing_time': datetime.now() - df['processed_at'].min()
}
print("\n数据处理摘要:")
for key, value in summary.items():
print(f"{key}: {value}")
print("结果聚合完成")
return results
def run(self):
"""运行数据处理系统"""
print(f"启动分布式数据处理系统,使用 {self.num_workers} 个工作进程")
start_time = time.time()
# 启动数据加载器
loader_process = Process(target=self.data_loader, args=('mock_source',))
loader_process.start()
# 启动工作进程
for i in range(self.num_workers):
p = Process(target=self.data_processor, args=(i,))
self.worker_processes.append(p)
p.start()
# 启动结果聚合器
aggregator_process = Process(target=self.result_aggregator)
aggregator_process.start()
# 等待完成
loader_process.join()
aggregator_process.join()
for p in self.worker_processes:
p.join()
end_time = time.time()
print(f"\n系统运行完成,总耗时: {end_time - start_time:.2f} 秒")
if __name__ == "__main__":
system = DataProcessingSystem(num_workers=4)
system.run()6 性能优化与故障排查
6.1 性能优化技巧
根据实际项目经验,总结以下优化建议:
- 进程池大小优化
python
import os
def calculate_optimal_pool_size(task_type='cpu_intensive'):
"""计算最优进程池大小"""
cpu_count = os.cpu_count()
if task_type == 'cpu_intensive':
# CPU密集型任务:使用全部核心
return cpu_count
elif task_type == 'io_intensive':
# I/O密集型任务:可以适当增加进程数
return min(cpu_count * 2, 16)
else:
# 混合型任务
return cpu_count
# 实际使用
optimal_size = calculate_optimal_pool_size('cpu_intensive')
print(f"推荐进程池大小: {optimal_size}")- 内存使用优化
python
def memory_efficient_processing():
"""内存高效处理"""
# 使用生成器避免一次性加载所有数据
def data_generator():
for i in range(1000000):
yield i * 2
# 分批处理
batch_size = 10000
with Pool(processes=4) as pool:
results = []
batch = []
for item in data_generator():
batch.append(item)
if len(batch) >= batch_size:
results.extend(pool.map(process_item, batch))
batch = []
if batch:
results.extend(pool.map(process_item, batch))
return results6.2 常见问题与解决方案
问题1:死锁与僵尸进程
python
def prevent_zombie_processes():
"""预防僵尸进程"""
import signal
def setup_worker():
# 忽略中断信号,由主进程处理
signal.signal(signal.SIGINT, signal.SIG_IGN)
# 在工作进程中使用
with Pool(processes=4, initializer=setup_worker) as pool:
try:
results = pool.map(worker_function, data)
except KeyboardInterrupt:
print("收到中断信号,清理进程池...")
pool.terminate()
pool.join()问题2:序列化错误
ruby
def handle_serialization_errors():
"""处理序列化错误"""
def robust_worker(func, data):
try:
return func(data)
except (pickle.PickleError, TypeError) as e:
print(f"序列化错误: {e}")
return None
# 使用自定义包装器
with Pool(processes=4) as pool:
results = pool.starmap(robust_worker, [(func, data) for data in dataset])7 总结与展望
通过本文的详细探讨,我们全面了解了Python多进程编程的核心技术和实践应用。多进程是突破GIL限制、提升Python程序性能的关键技术。
7.1 关键知识点回顾
-
GIL机制理解:明白了为什么多线程在CPU密集型任务中受限
-
多进程优势:每个进程有独立的GIL,真正实现并行计算
-
核心组件掌握:Process、Pool、Queue、Pipe等关键工具
-
进程通信精通:共享内存、队列、管道等多种通信方式
-
实战应用能力:能够构建复杂的分布式处理系统
7.2 性能数据总结
根据实际测试,多进程在不同场景下的性能表现:
| 场景类型 | 单进程耗时 | 4进程耗时 | 加速比 | 适用性 |
|---|---|---|---|---|
| CPU密集型 | 100% | 25-30% | 3.3-4.0x | ⭐⭐⭐⭐⭐ |
| I/O密集型 | 100% | 40-60% | 1.7-2.5x | ⭐⭐⭐⭐ |
| 混合型任务 | 100% | 30-50% | 2.0-3.3x | ⭐⭐⭐⭐⭐ |
7.3 未来发展趋势
随着Python生态的发展,多进程技术也在不断演进:
-
更好的异步集成:asyncio与多进程的深度结合
-
分布式计算:multiprocessing与Dask、Celery等框架的集成
-
容器化支持:在Docker、Kubernetes环境下的优化
-
性能监控:更完善的进程级性能分析工具
官方文档与权威参考
多进程编程是Python开发者必须掌握的高级技能。通过合理运用本文介绍的技术,你的Python程序将能够充分发挥现代多核处理器的强大能力,处理各种复杂的计算任务。