1 缓存和内存的读取速度
| 层级 | 典型延迟 | 容量 |
|---|---|---|
| CPU L1 缓存 | ~1-4 纳秒 | 32-64 KB |
| CPU L2/L3 缓存 | ~10-40 纳秒 | 256 KB - 64 MB |
| 主内存(RAM) | ~100 纳秒 | 8-64 GB |
| 固态硬盘 | ~10 微秒 | 更大 |
| 机械硬盘 | ~10 毫秒 | 更大 |
可以看到CPU从缓存中拿去数据的速度比内存中拿取速度快100倍
2 CPU从内存中加载数据到缓存中
缓存是以"缓存行"(Cache Line)为单位加载,是固定长度,比如64 字节。
并且CPU只能处理寄存器中的数据
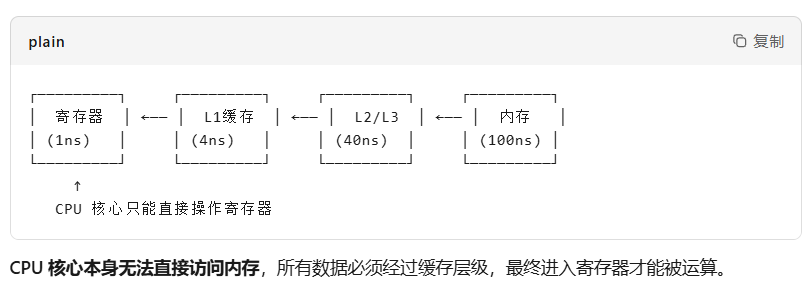
因此如果数据就在缓存中,CPU就能很快处理。
3 缓存命中率
如果CPU去拿数据,数据可能在缓存中(比如上一次读取的Cache Line中),此时就CPU拿取就很快,也可能不在缓存中,此时就要再去内存中拿取数据然后到缓存中,就会耗时,两者的时间差距可能达100倍。
缓存命中率就是拿取数据在缓存中的次数/一共拿取的次数。
4 提高缓存命中率
如果要提高缓存命中率,就需要尽量大部分数据都挨着,此时一次Cache Line拿到数据,第二次再拿数据时,就可能发现数据就在缓存中,例如:
cpp
std::deque<int> dq; // int = 4 字节
// dq 内容: 10 20 30 40 50 60 70 80... 连续存储| 步骤 | CPU 行为 | 实际发生 |
|---|---|---|
访问 dq[0] (10) |
缓存未命中 → 去内存 | 加载 64 字节到缓存行 包含10 20 30 40 50 60 70 80... |
访问 dq[1] (20) |
缓存命中 | 直接从缓存读取,几乎零延迟 |
访问 dq[2]~[15] |
全部命中 | 都在这 64 字节内 |
访问 dq[16] |
可能未命中 | 加载下一个缓存行 |
此时对dq的操作,缓存命中率就很高
如果换为List:
cpp
std::list<int> lst = {10, 20, 30, 40, 50...};| 步骤 | CPU 行为 | 实际发生 |
|---|---|---|
访问 Node1 (地址在0x1000) |
缓存未命中 → 去内存 | 加载 64 字节到缓存行 包含0x1000及后边多个字节的数据 |
访问 Node2 (地址在0x5000) |
缓存未命中 → 去内存 | 加载 64 字节到缓存行 包含0x5000及后边多个字节的数据 |
访问 Node3 (地址在0x8000) |
缓存未命中 → 去内存 | 加载 64 字节到缓存行 包含0x8000及后边多个字节的数据 |
因为list的节点并不是连续的,第一次拿取list后,再拿取下一个节点的数据,可能下一个节点的数据并不在缓存中,需要去内存中拿到缓存中,这样缓存命中率就很低了。