LangChain 技术架构深度解析:构建标准化、可组合的LLM应用框架
1. 整体介绍
项目概况
LangChain 是由 LangChain AI 团队开发并维护的开源框架,项目托管于 GitHub,地址为 github.com/langchain-ai/langchain。作为当前 AI 工程化领域的关键基础设施之一,该项目获得了广泛的社区关注与采纳,其 Star 与 Fork 数量在同类项目中位居前列,这反映了其在解决大语言模型(LLM)应用开发共性难题上的有效性与生态活力。
核心价值与功能定位
LangChain 的核心定位是为基于大语言模型的智能体(Agent)和应用程序提供一个标准化、模块化的开发框架。它并非一个单一的运行时或服务,而是一套旨在抽象和简化LLM应用复杂性的开发库与工具集。
其核心功能可概括为:
- 提供标准化接口:为模型(聊天、嵌入)、向量存储、检索器等异质组件定义统一接口,实现技术栈的松耦合。
- 实现组件可组合性:通过"链(Chain)"这一核心抽象,允许开发者像搭积木一样将多个组件串联成复杂的工作流。
- 构建智能体基座:提供智能体(Agent)构建所需的基础设施,包括工具调用(Tool Calling)、记忆(Memory)和规划(Planning)等核心概念的原生支持。
- 集成丰富生态:内置或通过合作伙伴包集成了大量主流的模型提供商(OpenAI、Anthropic等)、向量数据库(Qdrant、Pinecone等)和外部工具,极大降低了集成成本。
- 提供生产级工具链:通过 CLI、LangServe(服务化部署)、LangSmith(可观测性平台)等配套工具,支撑应用从开发、调试到部署、监控的全生命周期。
解决的问题与目标场景
在 LangChain 出现之前,开发LLM应用面临一系列碎片化挑战:
- 接口异构:不同模型提供商(如OpenAI、Anthropic)的API设计、参数命名、响应格式各异,切换成本高。
- 上下文管理复杂:如何处理长对话历史、实现记忆、以及将外部知识(如向量检索结果)注入到提示词中,需要大量定制化代码。
- 工具调用与流程编排困难:让LLM根据需求调用外部工具(如搜索、计算、API),并管理多步骤的、有状态的执行流程,缺乏通用范式。
- 原型到生产的鸿沟:实验阶段的脚本难以直接转化为可维护、可监控、可扩展的生产服务。
LangChain 主要服务于以下人群和场景:
- AI应用开发者:需要快速构建具备检索增强生成(RAG)、智能体、复杂工作流等能力的应用。
- 企业技术团队:寻求将LLM能力集成到现有业务系统中,并需要标准化、可维护的工程实践。
- 研究者与探索者:需要模块化工具来快速实验不同的模型、提示词策略和工作流组合。
解决方案与技术优势
LangChain 提供的是一种基于抽象层和可组合模式的解决方案。
- 旧方式:开发者需要为每个项目编写大量胶水代码,直接调用各异的模型SDK,手动拼接提示词,管理状态,并处理错误和重试逻辑。代码复用性差,且紧耦合于特定技术栈。
- 新方式 :
- 定义通用接口(如
BaseChatModel,VectorStore) :所有具体实现(如ChatOpenAI,QdrantVectorStore)都遵循同一套接口,使核心业务逻辑与具体技术实现解耦。 - 引入链(Chain)和智能体(Agent)抽象:将多步骤、有条件的工作流封装为可复用的单元。链支持同步/异步调用、流式响应、批处理等统一模式。
- 提供丰富的"连接器":开箱即用的集成减少了对接外部服务的代码量。
- 配套开发运维工具:CLI用于项目管理,LangServe用于将任何链快速部署为API服务,LangSmith用于全链路追踪和评估。
- 定义通用接口(如
优势 在于提升开发效率 、保障代码质量与可维护性 、降低技术锁定的风险 ,并通过社区生态加速创新。
商业价值估算(逻辑推演)
LangChain 的商业价值可以从"降低的开发成本"和"拓展的应用可能性"两个维度进行逻辑估算。
- 成本节省:假设一个中等复杂度的RAG应用,不使用框架需要资深工程师约20人日的开发与调试时间。使用 LangChain,借助其标准化组件和模板,可将相同功能的开发时间缩短至5-7人日,节省约65%-75%的直接开发成本。这主要源于对通用模式(如文档加载、分块、向量化、检索、提示词组装)的封装。
- 效益提升:框架的模块化特性使得团队能够快速尝试不同模型、不同检索器组合,从而更高效地优化应用效果,缩短产品迭代周期。其生产就绪的特性(如通过LangSmith监控)也能降低线上故障的排查时间和风险成本。
- 覆盖问题空间:LangChain 定义了一套构建LLM应用的标准"词汇表"和"设计模式",其价值不仅在于代码本身,更在于它教育并规范了整个生态的构建方式,降低了行业整体的协作和认知成本。
2. 详细功能拆解
从产品与技术融合的视角,其核心功能设计如下:
| 功能模块 | 产品视角(解决什么问题) | 技术视角(如何实现) |
|---|---|---|
| 核心抽象与接口 | 统一不同技术组件的使用体验,实现"可互换"。 | 定义 BaseLanguageModel, BaseRetriever, BaseMemory, BaseTool 等抽象基类(ABC)。所有具体实现必须继承并实现这些接口。 |
| 链(Chain) | 将多步骤任务(如"检索->生成")封装为可重复使用的单一单元,简化复杂逻辑。 | 提供 LLMChain, SequentialChain, TransformChain 等。核心是 __call__ 或 acall 方法,内部管理组件的执行顺序与数据传递。 |
| 智能体(Agent)与工具 | 使LLM能够感知并调用外部功能,执行超越文本生成的复杂任务。 | 提供 AgentExecutor 作为运行时,循环执行:解析LLM输出 -> 调用对应 Tool -> 将结果返回给LLM。工具通过 bind_tools() 方法与模型绑定。 |
| 记忆(Memory) | 让对话或交互具备上下文感知能力,实现多轮对话。 | 提供 ConversationBufferMemory, ConversationSummaryMemory 等。本质是在链的调用前后,自动从存储中读取历史消息并拼接到输入中,或将新交互写入存储。 |
| 索引与检索 | 为LLM注入私有或实时数据,实现检索增强生成(RAG)。 | 提供文档加载器(Document Loaders)、文本分割器(Text Splitters)、向量存储接口(VectorStore)和检索器(Retriever),形成标准化数据处理流水线。 |
| 提示词管理 | 解耦提示词模板与业务逻辑,便于管理和优化。 | 提供 PromptTemplate, ChatPromptTemplate 等,支持变量插值、部分格式化,并可与其他组件(如输出解析器)组合。 |
| 回调与可观测性 | 为开发调试和生产监控提供钩子。 | 提供 CallbackHandler 接口,允许在LLM调用、链开始/结束等关键节点注入自定义逻辑。LangSmith 是其企业级实现。 |
| CLI 与 LangServe | 降低项目创建、依赖管理和服务部署的门槛。 | CLI 基于 Typer 构建,提供项目模板和包管理命令。LangServe 基于 FastAPI,可将任何 Runnable 序列化为 OpenAPI 文档并启动 HTTP 服务。 |
3. 技术难点与挑战因子
LangChain 在实现其愿景过程中,需克服以下核心工程技术难点:
- 抽象设计的平衡:如何在提供足够强大的抽象以简化开发的同时,避免抽象泄漏,并确保不限制高级用户进行底层定制?这是一个经典的框架设计难题。
- 异构集成的质量与维护:对接上百个外部服务(模型、数据库、工具),如何保证每个集成的质量、与上游API变化的同步、以及错误处理的鲁棒性?
- 状态管理与流式支持:在复杂的、可能并发的智能体工作流中,如何优雅地管理会话状态、工具调用历史?如何将底层的流式响应(如ChatGPT的token-by-token输出)无缝地穿透到顶层链或智能体的流式接口中?
- 性能与可伸缩性:当链中包含多个网络调用(如多次模型调用、向量检索)时,如何通过异步、批处理等机制优化性能?如何设计缓存策略?
- 版本兼容与演化:AI 领域技术迭代极快,框架自身如何平滑演进,避免频繁的破坏性更新,保护用户项目?
- "胶水代码"框架的固有风险:LangChain 自身不提供LLM或向量数据库,其价值在于"连接"。这可能导致其在复杂场景下被视为"不必要的间接层",特别是当用户需求非常定制化时。
4. 详细设计图
4.1 核心架构图
 架构解读:用户通过构建链或智能体来开发应用。框架核心提供统一的抽象接口(LCEL和Runnable协议)和基础实现。具体的模型、存储等能力由庞大的集成生态提供。配套的CLI、LangServe和LangSmith覆盖了开发生命周期。
架构解读:用户通过构建链或智能体来开发应用。框架核心提供统一的抽象接口(LCEL和Runnable协议)和基础实现。具体的模型、存储等能力由庞大的集成生态提供。配套的CLI、LangServe和LangSmith覆盖了开发生命周期。
4.2 核心链路序列图:一个简单的RAG链调用
序列解读:此图展示了一个典型的检索增强生成(RAG)流程。链协调了检索器与语言模型的调用,并负责中间数据的格式转换与组装。这种清晰的职责分离是框架的关键价值。
4.3 核心类图简析(以ChatModels为例)
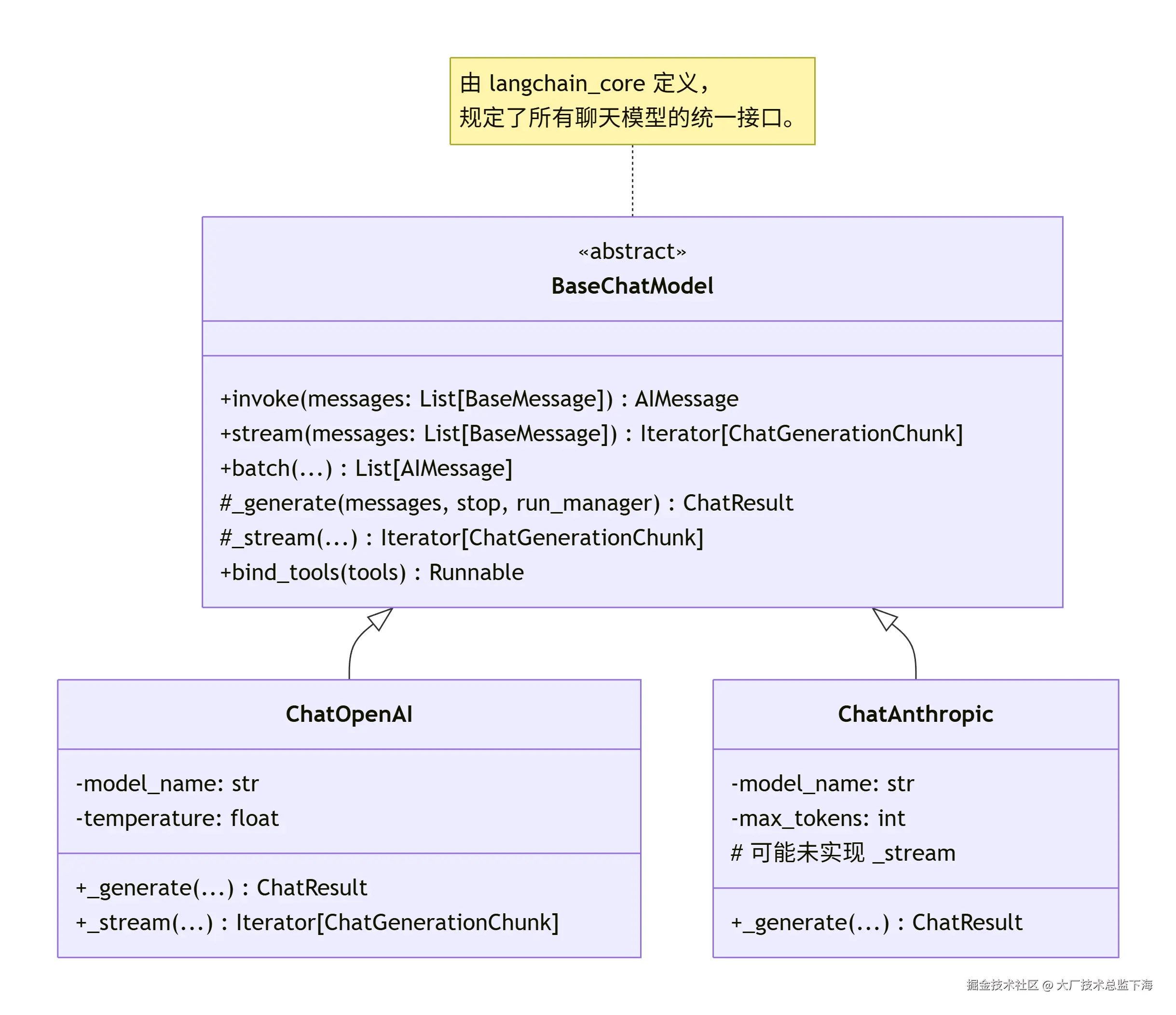 类图解读 :
类图解读 :BaseChatModel 作为抽象基类,定义了所有聊天模型必须实现的核心方法(如invoke, stream)和可选的内部方法(如_generate)。ChatOpenAI 和 ChatAnthropic 作为具体实现,继承该基类,并填充与各自API交互的具体逻辑。这确保了无论底层是哪个厂商的模型,上层调用方式都是一致的。
5. 核心代码解析
我们选取两个关键代码片段进行解析,它们体现了框架的核心设计思想。
5.1 CLI 的 serve 命令分派逻辑
此函数位于 langchain_cli/cli.py,展示了如何通过检查项目元数据来智能分派启动命令。
python
@app.command()
def serve(
*,
port: Annotated[
int | None,
typer.Option(help="The port to run the server on"),
] = None,
host: Annotated[
str | None,
typer.Option(help="The host to run the server on"),
] = None,
) -> None:
"""Start the LangServe app, whether it's a template or an app."""
try:
# 1. 尝试定位项目根目录并读取 pyproject.toml
project_dir = get_package_root()
pyproject = project_dir / "pyproject.toml"
# 2. 关键检查:尝试获取 LangServe 导出配置
get_langserve_export(pyproject)
except (KeyError, FileNotFoundError):
# 3. 如果失败,说明当前目录不是一个 LangChain 模板项目
# 按照普通应用的方式启动
app_namespace.serve(port=port, host=host)
else:
# 4. 如果成功,说明当前目录是一个 LangChain 模板项目
# 按照模板项目的特定方式启动
template_namespace.serve(port=port, host=host)代码解析:
get_package_root()和get_langserve_export()是用于探测项目类型的工具函数。它们检查pyproject.toml中是否包含特定的[tool.langchain]配置项,这是 LangChain 项目模板的标记。- 这种基于约定的探测机制,允许同一个
langchain-cli命令无缝支持两种使用场景:从模板创建的新项目 和已有的自定义应用项目。这提升了开发者体验。 - 错误处理简洁明确,将
KeyError(配置项缺失)和FileNotFoundError(配置文件缺失)统一处理为"非模板项目"。 - 最终将启动逻辑分派给不同的命名空间(
app_namespace或template_namespace),体现了良好的职责分离。
5.2 合作伙伴包中 ChatModel 的 _generate 方法模板
此代码片段来自合作伙伴包的模板文件,揭示了如何为一个新的模型提供商实现标准接口。
python
# 注意:以下代码是合作伙伴包的模板,包含大量 TODO。
# 它展示了实现一个聊天模型所需的最小结构和模式。
def _generate(
self,
messages: List[BaseMessage],
stop: list[str] | None = None,
run_manager: CallbackManagerForLLMRun | None = None,
**kwargs: Any,
) -> ChatResult:
"""Override the _generate method to implement the chat model logic."""
# 此处应替换为实际调用模型API的逻辑
# 模板中是一个简单的"复读机"实现,用于演示
last_message = messages[-1]
tokens = last_message.content[: self.parrot_buffer_length]
ct_input_tokens = sum(len(message.content) for message in messages)
ct_output_tokens = len(tokens)
# 构建符合 LangChain 消息协议的对象
message = AIMessage(
content=tokens,
additional_kwargs={}, # 存放模型原生返回的额外信息(如 finish_reason)
response_metadata={ # 存放响应元数据(如耗时、模型ID)
"time_in_seconds": 3,
"model_name": self.model_name,
},
usage_metadata={ # 存放token使用量
"input_tokens": ct_input_tokens,
"output_tokens": ct_output_tokens,
"total_tokens": ct_input_tokens + ct_output_tokens,
},
)
##
# 将消息封装为 ChatGeneration,再放入 ChatResult
generation = ChatGeneration(message=message)
return ChatResult(generations=[generation])代码解析:
- 模板作用:这份模板极大地降低了为新的AI模型服务创建 LangChain 集成包的门槛。贡献者只需填充调用真实API的代码,并正确映射返回数据。
- 关键输入 :
messages: 标准化后的消息列表(SystemMessage,HumanMessage,AIMessage等),调用者无需关心原始API的消息格式。stop: 停止词序列,需要实现者将其转换为对应API的参数。run_manager: 回调管理器,用于在生成过程中触发回调事件(如on_llm_new_token),是实现流式处理和可观测性的关键。
- 关键输出 :必须返回
ChatResult对象,其内部包含ChatGeneration。AIMessage的各个字段设计精良:content: 核心回复内容。additional_kwargs: 保留模型原生响应中可能存在的特殊字段,保证信息不丢失。response_metadata&usage_metadata: 标准化了监控和成本核算所需的关键元数据。
- 设计模式 :这是模板方法模式 的典型应用。
BaseChatModel的invoke()方法定义了调用流程(可能包括预处理、回调触发等),并调用子类必须实现的_generate()这个"变体"部分。
总结与展望
LangChain 成功地将构建LLM应用的常见模式抽象为了一套标准化的、可组合的接口与组件。其技术架构的核心价值在于通过定义行业通用接口和协议,降低了生态的碎片化,并显著提升了开发效率。它并非银弹,在处理极致性能或高度定制化的场景时可能引入额外复杂度,但其在快速原型、标准化生产以及教育市场方面的作用毋庸置疑。
从技术演进看,其表达式语言(LCEL)和 Runnable 协议的引入,正试图提供更声明式、更灵活的编排方式。未来,如何进一步优化复杂智能体工作流的性能与可靠性,深化与各类运行时(如云函数、边缘计算)的集成,以及如何更好地平衡框架的"重量"与"灵活性",将是 LangChain 持续面临的技术挑战。