一、xfs文件系统的构成
1.1、xfs文件结构
在一个磁盘上创建xfs文件系统之后,磁盘会被格式化成如下结构: xfs将整个磁盘切成若干个 分配组(Allocation Group 简称AG,默认大小 4 MB 的倍数)。每个 AG 内部再细分为 5 个固定区域,所有元数据就分布在这些区域里。
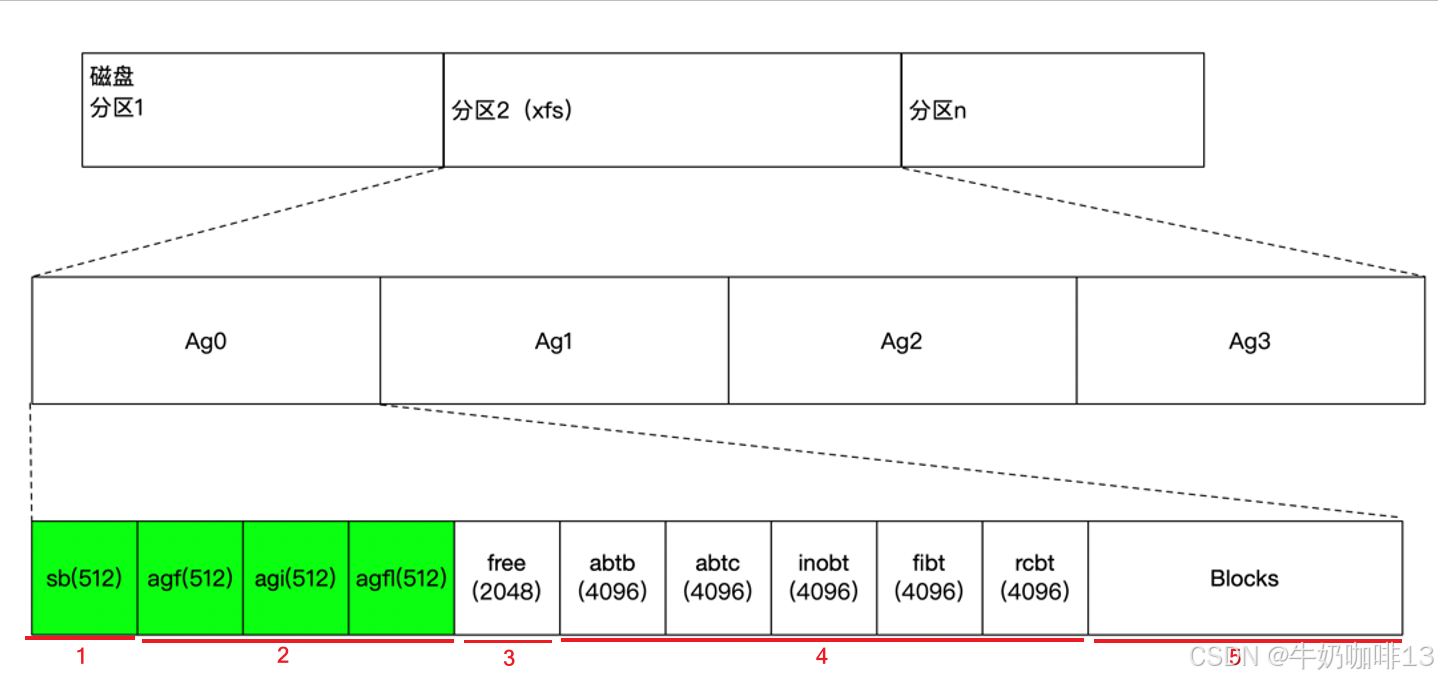
1.2、xfs分配组的构成
|--------|---------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 序号 | 分配组(AG)的构成 | 说明 |
| 1 | 超级块 (Super Block) | **定义:**是文件系统全局元数据锚点,位于每个 AG 起始位置,主 SB (AG 0)为主用,其余为备份。 **作用:**存储文件系统标识、块大小(sb_blocksize)、总数据块数(sb_dblocks)、AG 数量(sb_agcount)、日志起始位置(sb_logstart)、根 inode 号(sb_rootino)等关键参数,是文件系统挂载与恢复的基础。 **特征:**v5 版本兼容扩展字段,含 UUID(sb_uuid)与特性标志(sb_features),保障跨环境一致性与兼容性。 |
| 2 | 头部元数据 | 包含如下三个内容(是AG的起始块,各占512字节): 1、(Allocation Group Free Space Header 简称:agf)主要作用:管理 AG 内自由块,维护空间分配 B+ 树; 2、(Allocation Group Inode Header 简称:agi)主要作用:管理 AG 内 inode,维护 inode 分配 B+ 树; 3、(Allocation Group Free Block List 简称:agfl)主要作用:记录 AG 内空闲块的快速访问列表; |
| 3 | 空闲空间 | 存放预留free space节点数据的区域,由AGFL中对应的字段指向。 |
| 4 | 核心B+树 | 是元数据索引核心,主要包含如下4个B+树: 1、(Allocation Block Tree by Block Number 简称:abtb)块号排序自由块 B+ 树: 《1》功能:按块号排序组织 AG 内自由块区间,支持快速定位指定块号附近的空闲块,适配顺序分配场景。 《2》标识:magic 为 0x41425442(v5 为 0x41423342),根节点位置存于 agf_roots XFS_BNO。 2、(Allocation Block Tree by Count 简称:abtc)块数排序自由块 B+ 树: 《1》功能:按空闲块长度排序,快速查找符合大小的连续块,适配预分配与大文件写入场景。 《2》标识:magic 为 0x41425443(v5 为 0x41423343),根节点位置存于 agf_roots XFS_CNUM。 3、(Inode B+ Tree 简称:inobt)inode 分配 B+ 树: 《1》功能:管理 AG 内 inode 分配状态,记录已分配 / 空闲 inode 位置,支持快速分配与查找 inode。 《2》标识:根节点位置存于 agi_root,配合 agi_freecount 实现 inode 高效管理。 4、(File Extent Index B+ Tree 简称:fibt)文件扩展区索引树: 《1》功能:每个文件的 extent 索引,记录文件数据块的物理位置与长度,支持高效的 extent 查找、扩展与截断。 《2》特性:采用 extent 机制减少碎片,配合日志保障数据一致性,是 XFS 高性能读写的核心基础。 5、(Realtime Copy B+ Tree 简称:rcbt)实时区副本树: 《1》功能:仅用于带实时设备(RT)的 XFS 系统,管理实时区(用于小文件 / 元数据快速写入)的副本块分配与一致性,保障实时数据可靠性。 《2》逻辑:与 AGF/AGFL 协同,维护实时块的分配映射,避免冲突与数据丢失。 |
| 5 | 基础存储单元 | 是文件系统 I/O 最小单元,大小由 sb_blocksize 指定(常见 4KB/8KB);分为数据块(存文件内容)与元数据块(存 sb/agf/agi/ 各类 B+ 树节点等)。 特点: 《1》按 AG 划分,独立管理,支持并行 I/O 与故障隔离。 《2》extent 机制将连续 blocks 视为一个单元,减少元数据开销,提升大文件读写性能。 《3》实时块(RT blocks)独立于普通数据块,通过 rcbt 管理,适配低延迟场景。 |
[分配组的构成]
XFS文件系统结构 | Zorro's Linux Book
1.3、xfs的核心逻辑
|--------|---------------------------------------------------------|
| 序号 | xfs的核心逻辑说明 |
| 1 | 挂载时,内核先读取主超级块(SB)获取全局参数,定位各分配组(AG)头部。 |
| 2 | 分配或回收块时,通过 agf 找到 abtb/abtc,快速匹配空闲块区间,更新 agfl 与 B+ 树状态。 |
| 3 | 分配 inode 时,通过 agi 访问 inobt,定位空闲 inode 并更新计数。 |
| 4 | 文件读写时,通过 fibt 索引 extent,映射物理块地址,配合日志保障事务原子性。 |
| xfs文件系统通过超级块统筹全局,以 AG 为单位,借助 agf/agi/agfl 管理基础元数据,通过 abtb/abtc/inobt/fibt/rcbt 等 B+ 树实现高效索引,blocks 作为存储载体,共同构成了高吞吐、易扩展的文件系统架构,适配大容量与高性能场景。 ||
[xfs的核心逻辑]
二、xfs的超级块故障模拟与恢复
2.1、模拟超级块故障
需要新添加一个磁盘,并给这个磁盘分区且挂载到/data2上后模拟超级块故障。
bash
#给新增的磁盘分区挂载
#1-查看系统当前的所有磁盘
parted -l
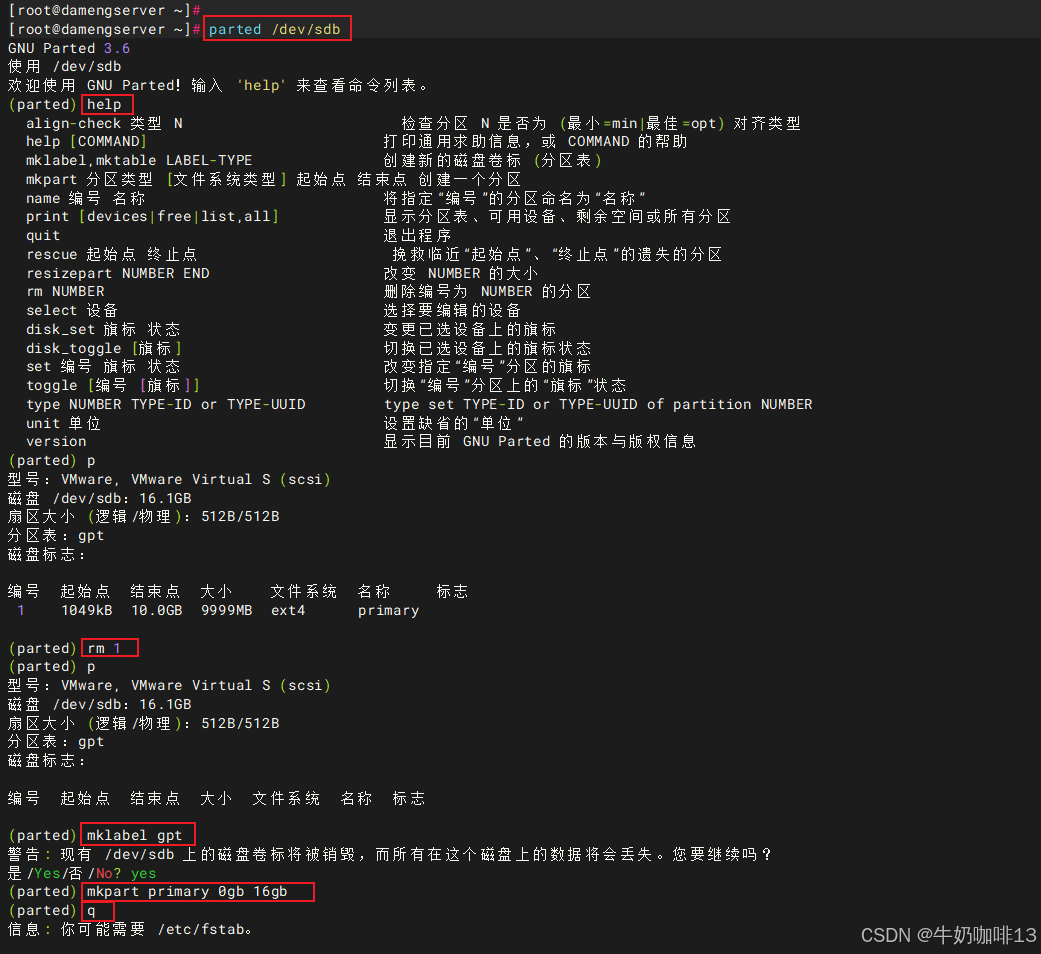
#2-进入新增磁盘(如:/dev/sdb)分区
#2.1-进入/dev/sdb磁盘
parted /dev/sdb
#2.2-设置磁盘的类型为gpt
mklabel gpt
#2.3-设置磁盘的分区类型与大小
mkpart primary 0gb 16gb
#2.4-保存磁盘的分区内容且退出
q
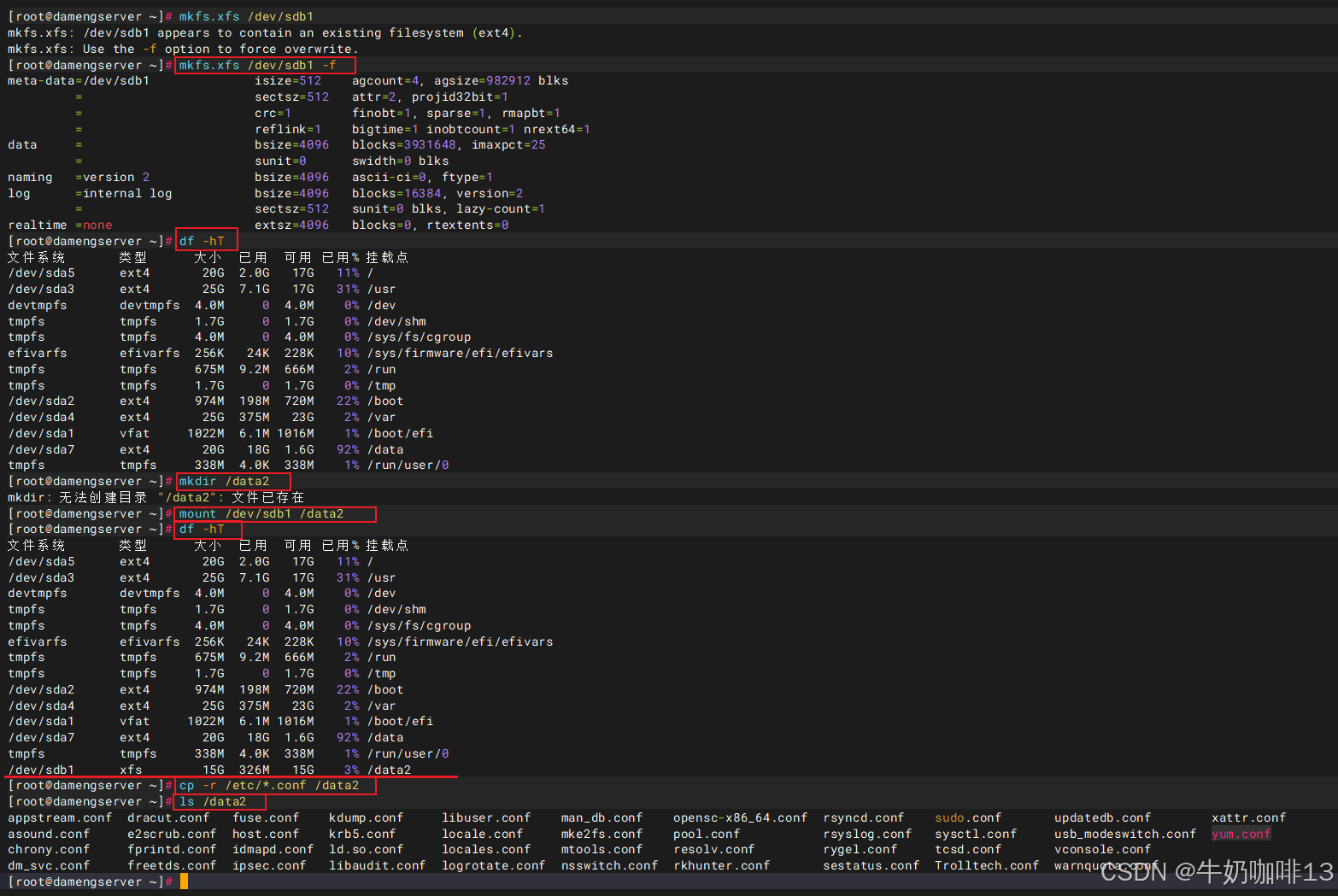
#3-格式化新增的磁盘分区并挂载到/data2上
mkfs.xfs /dev/sdb1 -f
mkdir /data2
mount /dev/sdb1 /data2
df -hT
#4-拷贝一些数据到新增磁盘的/data2挂载点上
cp -r /etc/*.conf /data2
ls /data2
bash
#模拟超级块故障
#1-查看指定磁盘(如:/dev/sdb1)中的超级块等元数据信息
#注意:每个 AG 的 0 号块就是超级块
xfs_info /dev/sdb1 | grep -E 'agsize|bsize'
#2-使用dd命令将sdb磁盘第一个block的内容抹除(在抹除前需要先卸载该挂载点,因为该挂载点的元数据信息已存在内存中)
#覆盖前 4096 字节(块 0),seek=0 表示从设备开头(即块 0)开始写。 只写了 1 个块,因此 其余 AG 的备份超级块完好无损。
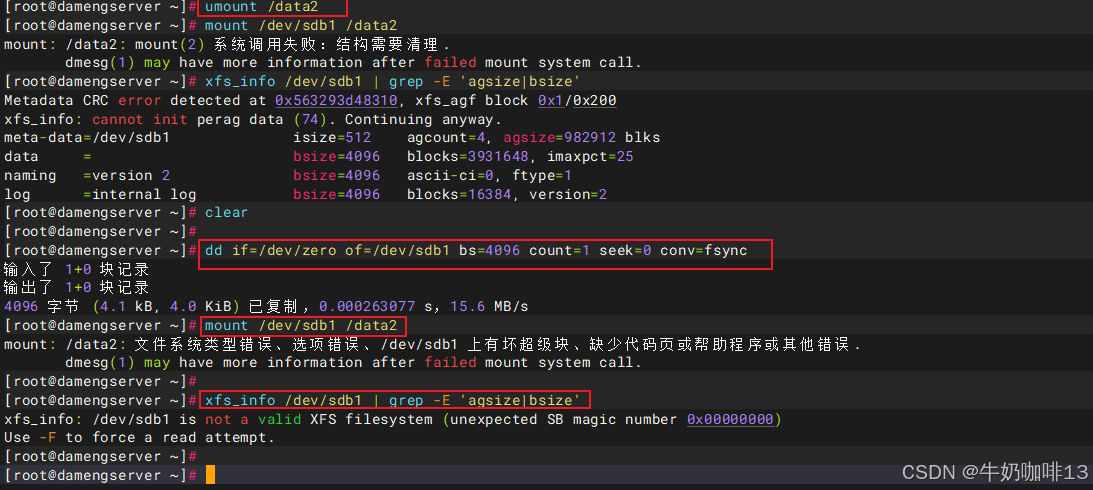
umount /data2
dd if=/dev/zero of=/dev/sdb1 bs=4096 count=1 seek=0 conv=fsync
#3-此时将这个挂载点卸载后重新挂载报错,查看超级块等元数据信息也有报错
mount /dev/sdb1 /data2
xfs_info /dev/sdb1 | grep -E 'agsize|bsize'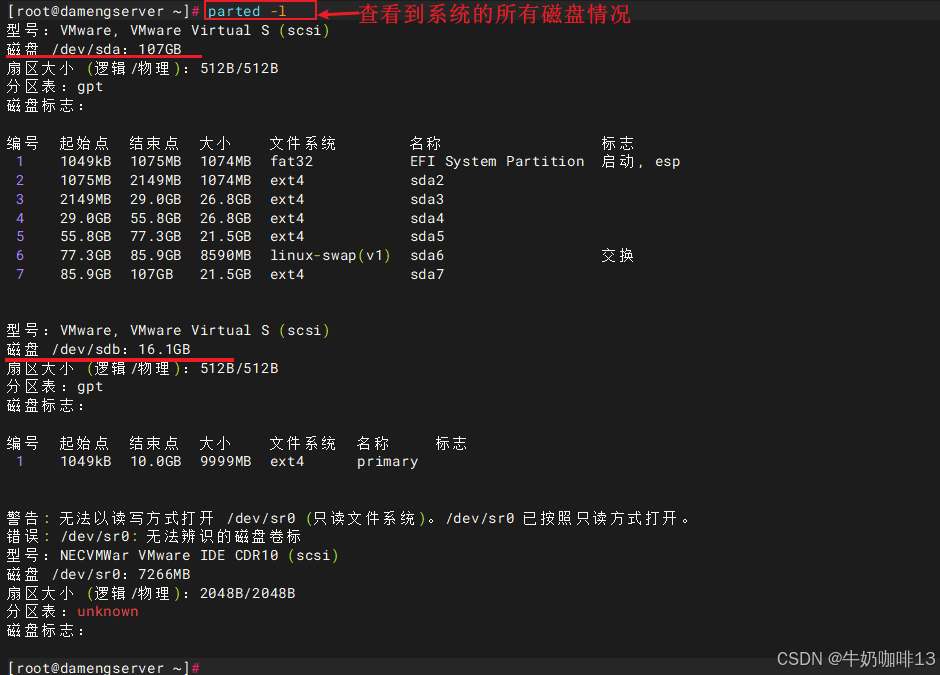
2.2、超级块的故障恢复
超级块故障的表象,体现在:
1、重新挂载这个故障挂载点则显示"mount: /data2: 文件系统类型错误、选项错误、/dev/sdb1 上有坏超级块、缺少代码页或帮助程序或其他错误.
dmesg(1) may have more information after failed mount system call."
2、使用【xfs_info /dev/sdb1 | grep -E 'agsize|bsize'】命令查看超级块等元数据信息报错"xfs_info: /dev/sdb1 is not a valid XFS filesystem (unexpected SB magic number 0x00000000)
Use -F to force a read attempt."如下图所示:

bash
#恢复超级块故障的实践流程
#1-扫描所有 AG,自动找到有效备份,并重建主超级块
xfs_repair /dev/sdb1
#2-验证超级块故障是否恢复(就重新挂载这个有问题的挂载点,修复后可以正常挂载上则成功,否则失败)
mount /dev/sdb1 /data2
df -hT
ls /data2注意:【xfs_repair】命令提供了【-L】选项用于强制修复(强制修复会将文件系统日志清除),强制日志清零,会清除日志中的脏数据(包含元数据的修改,还未同步到持久化存储)。使用此选项时,文件系统可能会出现损坏的情况,可能导致用户文件或数据丢失。【xfs_repair -L /dev/sdX 】此命令,只用于无计可施的情况下,-L 选项等同于"生死有命,富贵在天",此命令执行后需再次执行【xfs_repair /dev/sdX】。
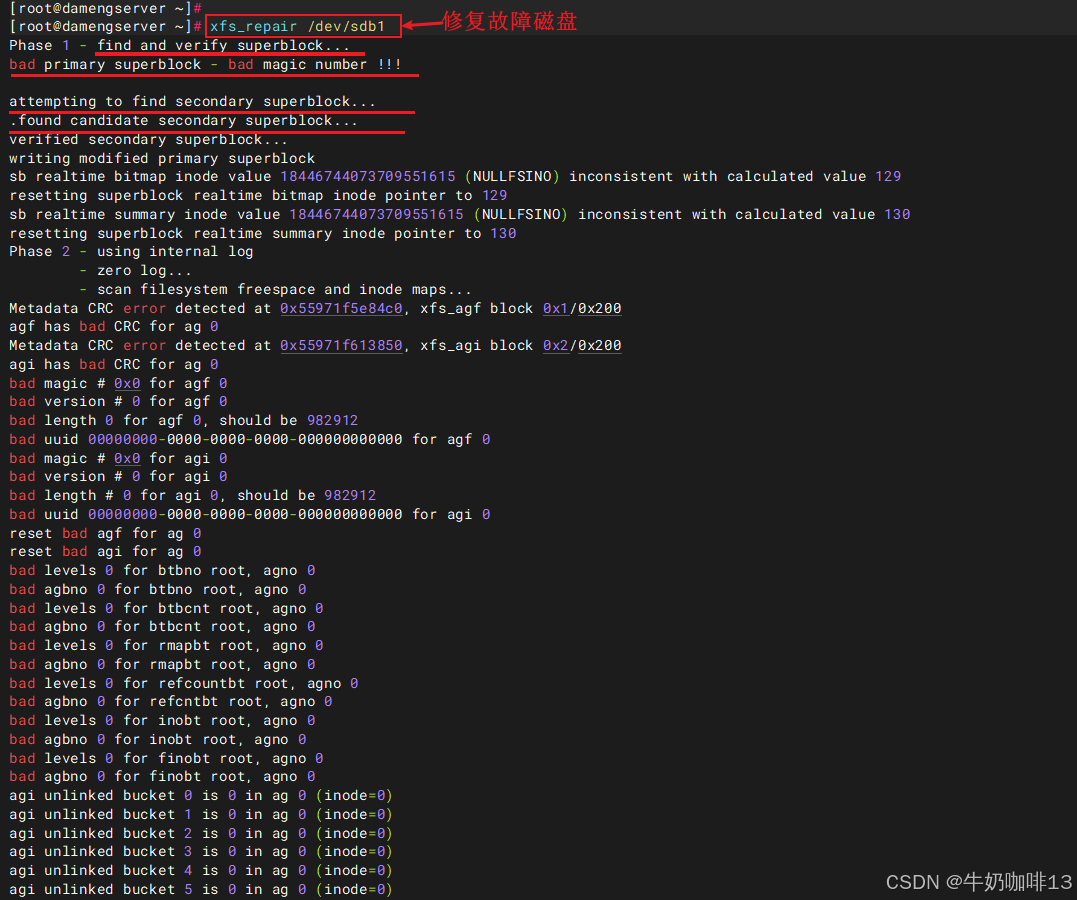
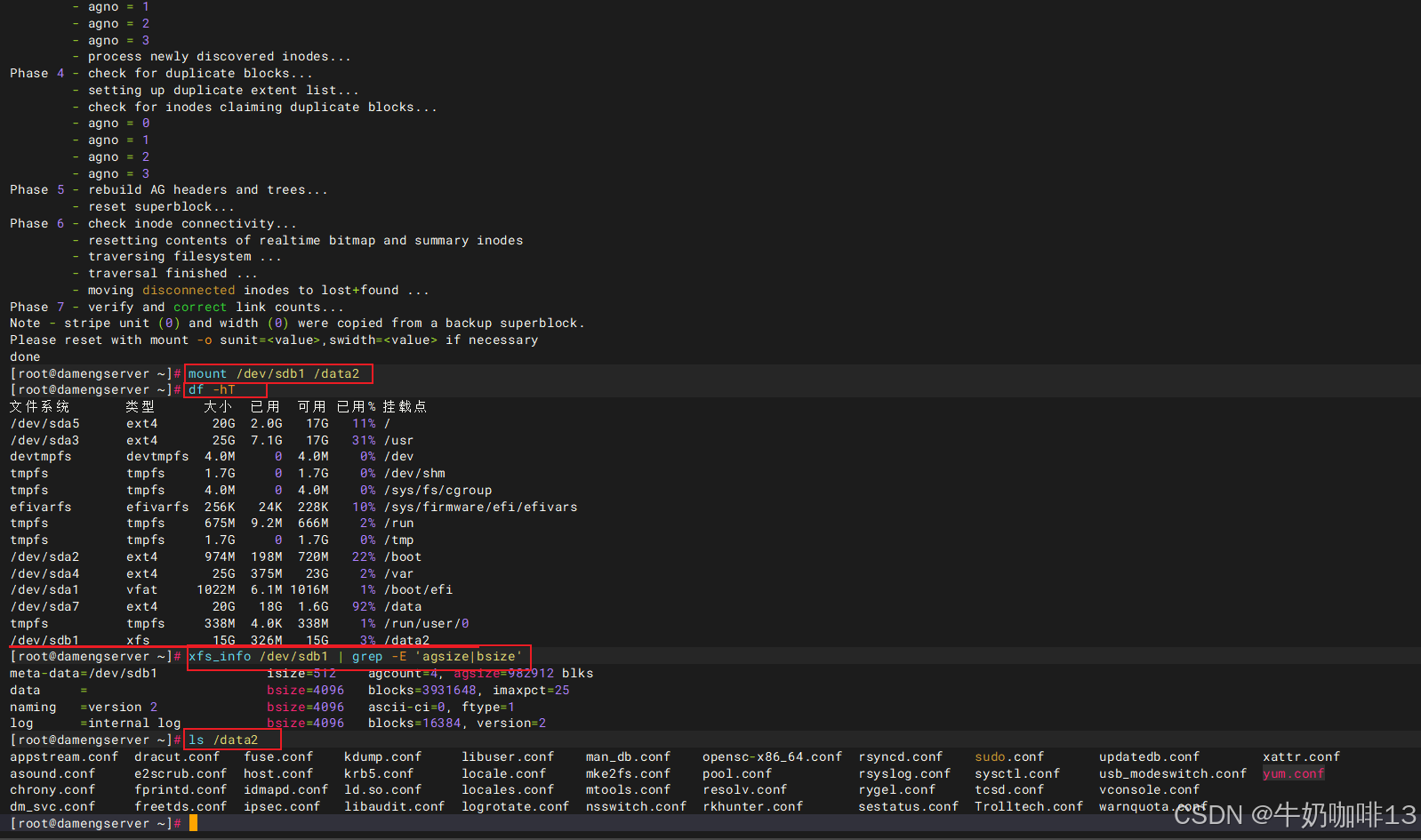
到这里,恭喜你,超级块故障修复完成。
三、xfs的其他元数据丢失故障模拟与恢复
3.1、模拟其他元数据丢失故障
bash
#模拟其他元数据丢失故障实践流程
#1-卸载当前磁盘挂载点
umount /data2
#2-从第【506112】块开始,连续破坏【16】个xfs块的内容,这是一种人工制造元数据损坏的调试手段【仅只在测试或教学场景下使用】。
xfs_db -x -c blockget -c "blocktrash -s 506112 -n 16" /dev/sdb1
#3-重新挂载上这个模拟故障的挂载点后查看该挂载点下的内容
mount /dev/sdb1 /data2
ls /data2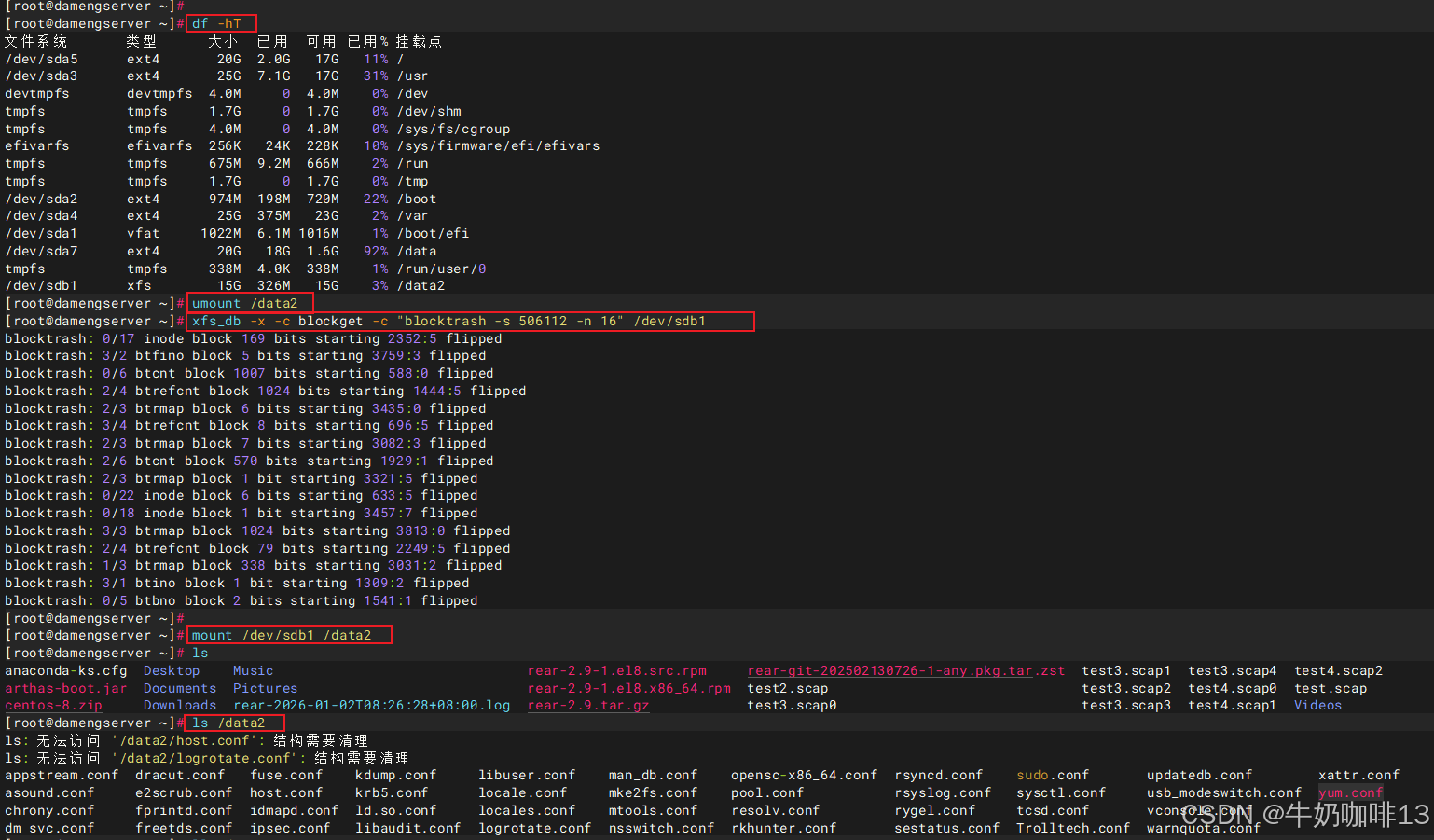
3.2、其他元数据丢失故障恢复
xfs的其他元数据丢失故障表象体现在:
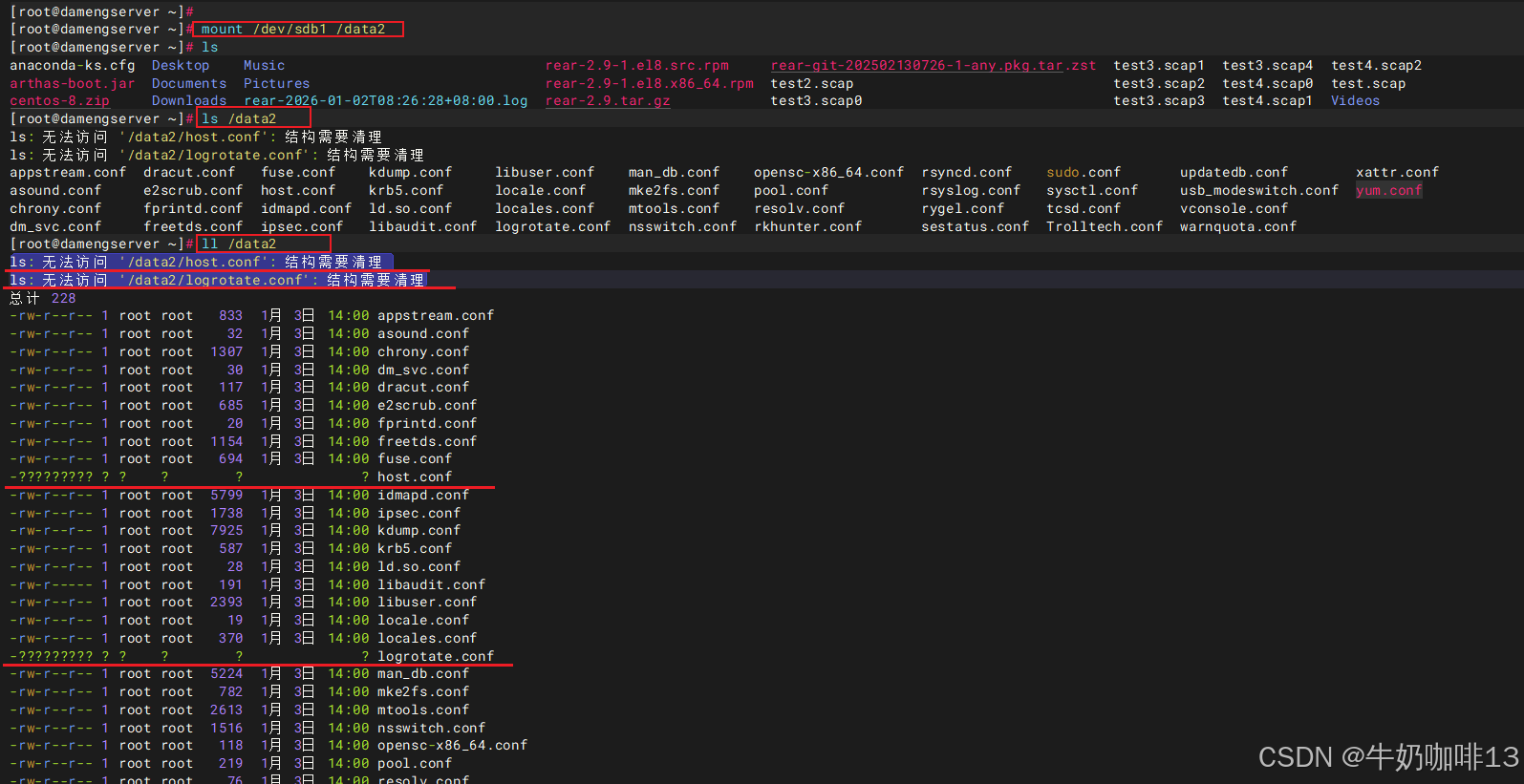
1、存在故障的挂载点可以正常挂载上,但是使用ls查看文件的时候会提示类似"
ls: 无法访问 '/data2/host.conf': 结构需要清理
ls: 无法访问 '/data2/logrotate.conf': 结构需要清理"的提示信息;
2、使用【ll】命令查看的时候除了显示"ls: 无法访问 '/data2/host.conf': 结构需要清理"提示外,这些提示的文件的权限、属主、属组、日期信息都是问号。
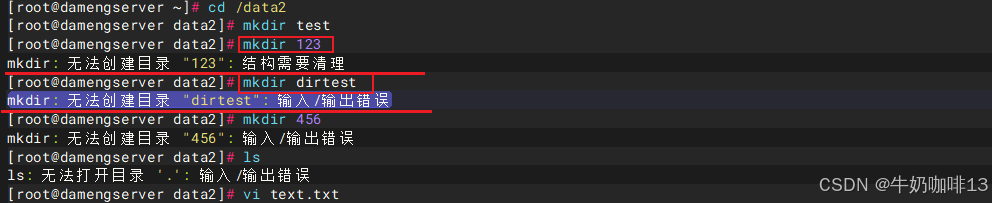
3、在这个存在故障的挂载点上创建目录时会提示"
mkdir: 无法创建目录 "xxx": 结构需要清理
mkdir: 无法创建目录 "dirtest": 输入/输出错误"
4、在这个存在故障的挂载点上编辑文件后保存提示"
E45:'readonly' option is set (add ! to override)
xxx E212:Cant't open file for writing"
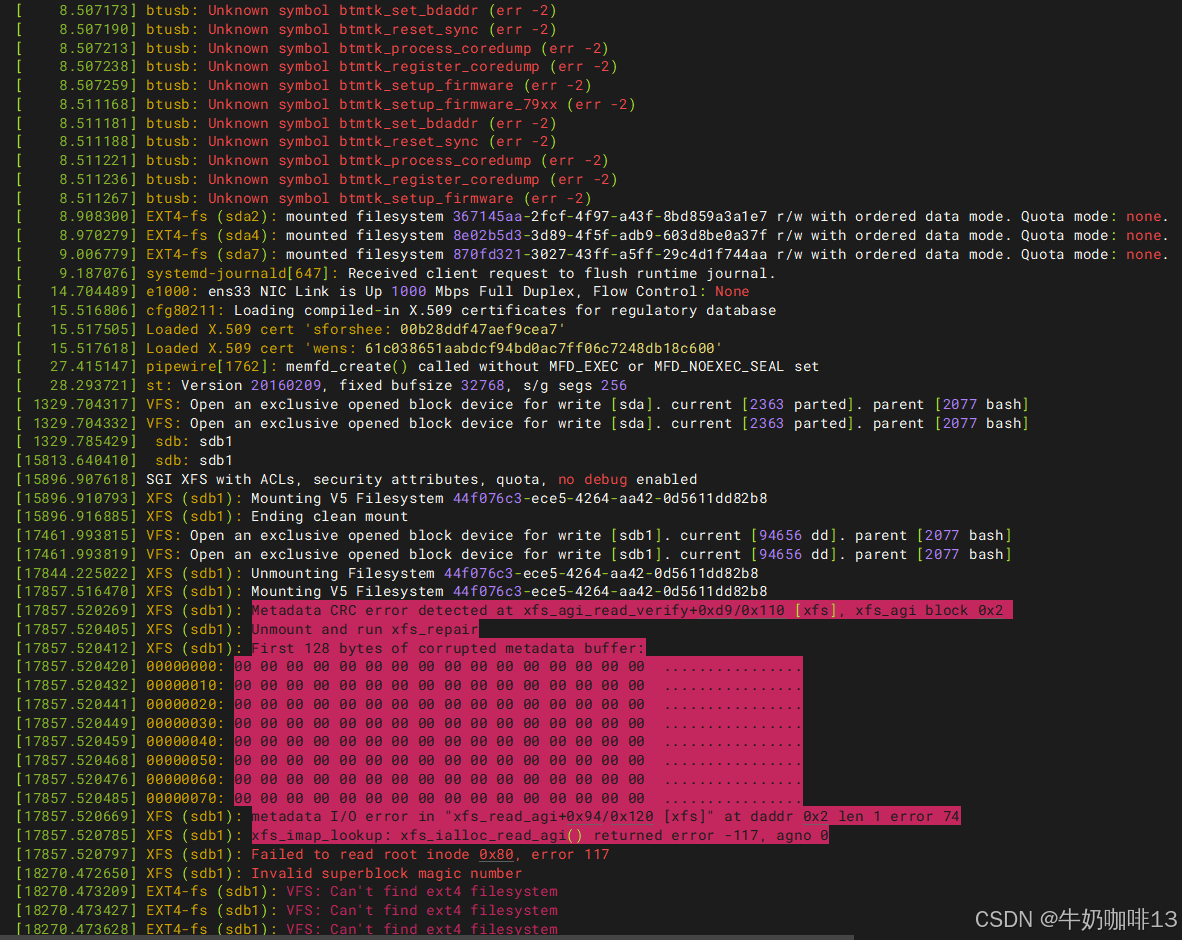
5、执行【dmesg】查看内核缓存区信息可以看到很多报错信息,如:"Metadata corruption detected at xfs_dinode_verify+0x15d/0x770 xfs, inode 0x8c dinode"。"metadata I/O error xxx"
如下图所示:


bash
#其他元数据丢失故障恢复实践流程
#1-先卸载当前的故障挂载点
umount /data2
#2-执行修复故障挂载点的设备命令实现扫描所有 AG,自动定位和修复损坏的 inode 或目录树
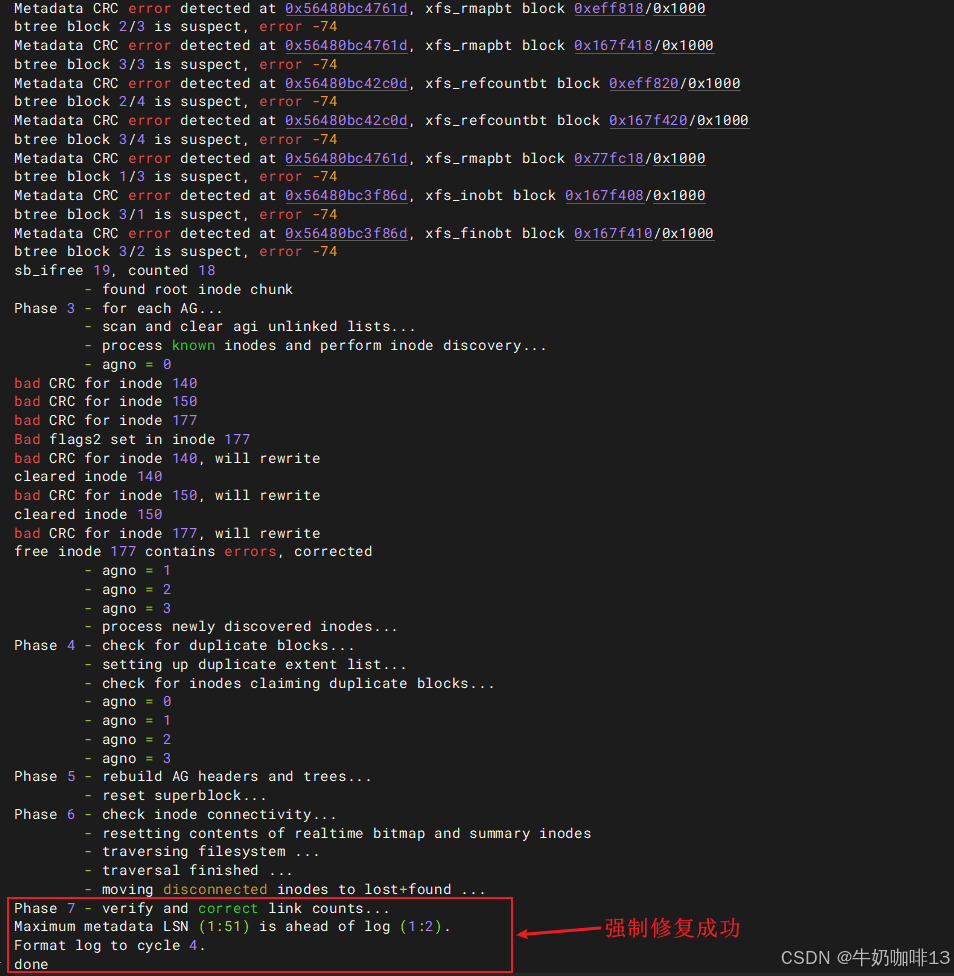
xfs_repair /dev/sdb1
#2.1-(若执行修复命令后提示"ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair.Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this.")错误
#1-若执行修复命令时报错,则需要再次挂载一下该故障挂载点(实现日志重放)
#《1》如果挂载成功:恭喜你日志已经被成功重放。你可以检查一下文件是否都还在。
#《2》如果挂载失败:系统会提示错误信息。这说明日志可能已经损坏,无法安全重放。在这种情况下,你才需要考虑使用危险的 -L 选项。
mount /data2
#2.2-针对挂载该故障挂载点失败报错"mount: /data2: 无法读取 /dev/sdb1 上的超级块.dmesg(1) may have more information after failed mount system call."
xfs_repair /dev/sdb1 -L
#3-验证其他元数据丢失故障是否恢复(就重新挂载这个有问题的挂载点,修复后可以正常挂载上则成功,且查看该挂载点下的所有内容也没有提示,可以正常创建目录、文件并保存,否则失败)
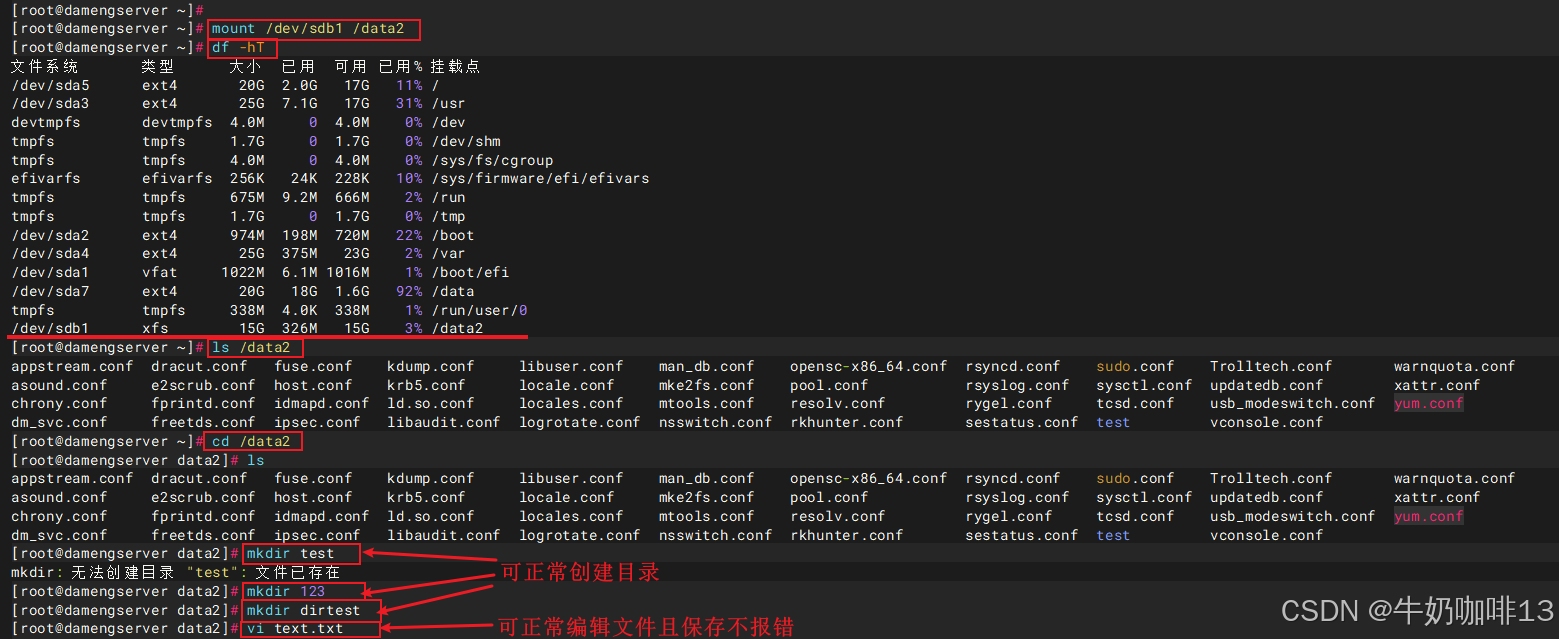
mount /dev/sdb1 /data2
df -hT
cd /data2
ll -a
mkdir test
mkdir 123
mkdir dirtest
vi text.txt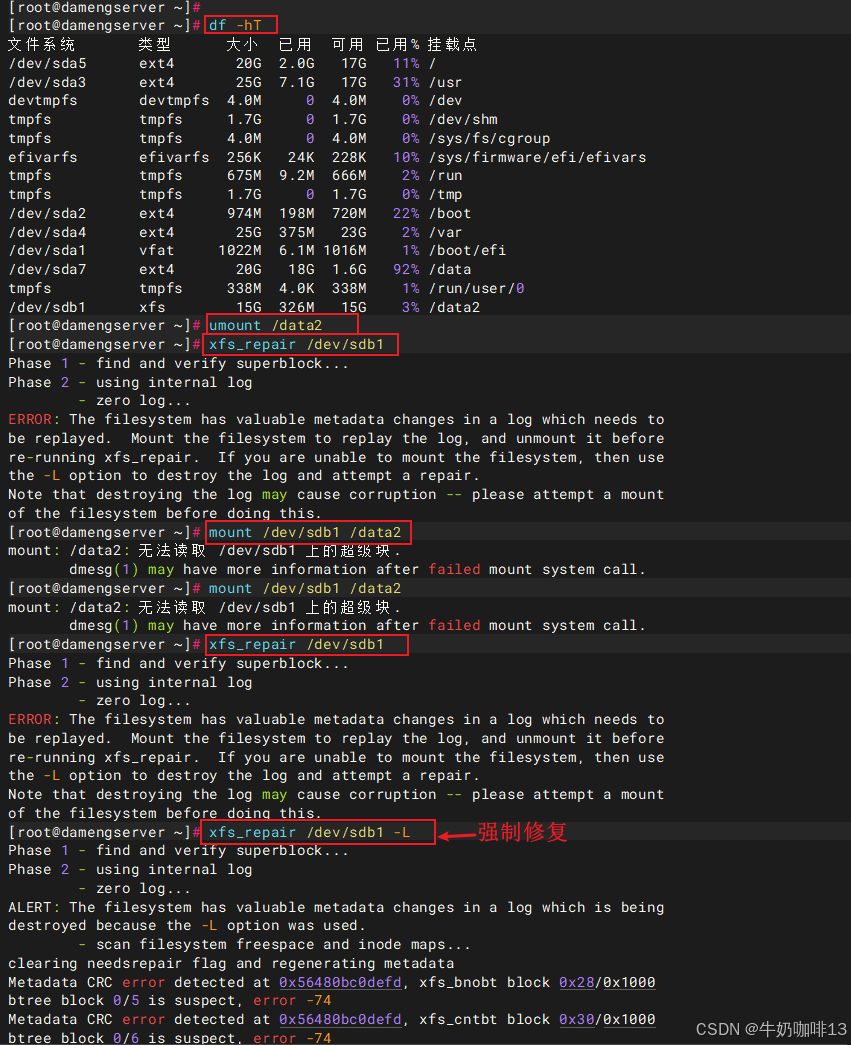
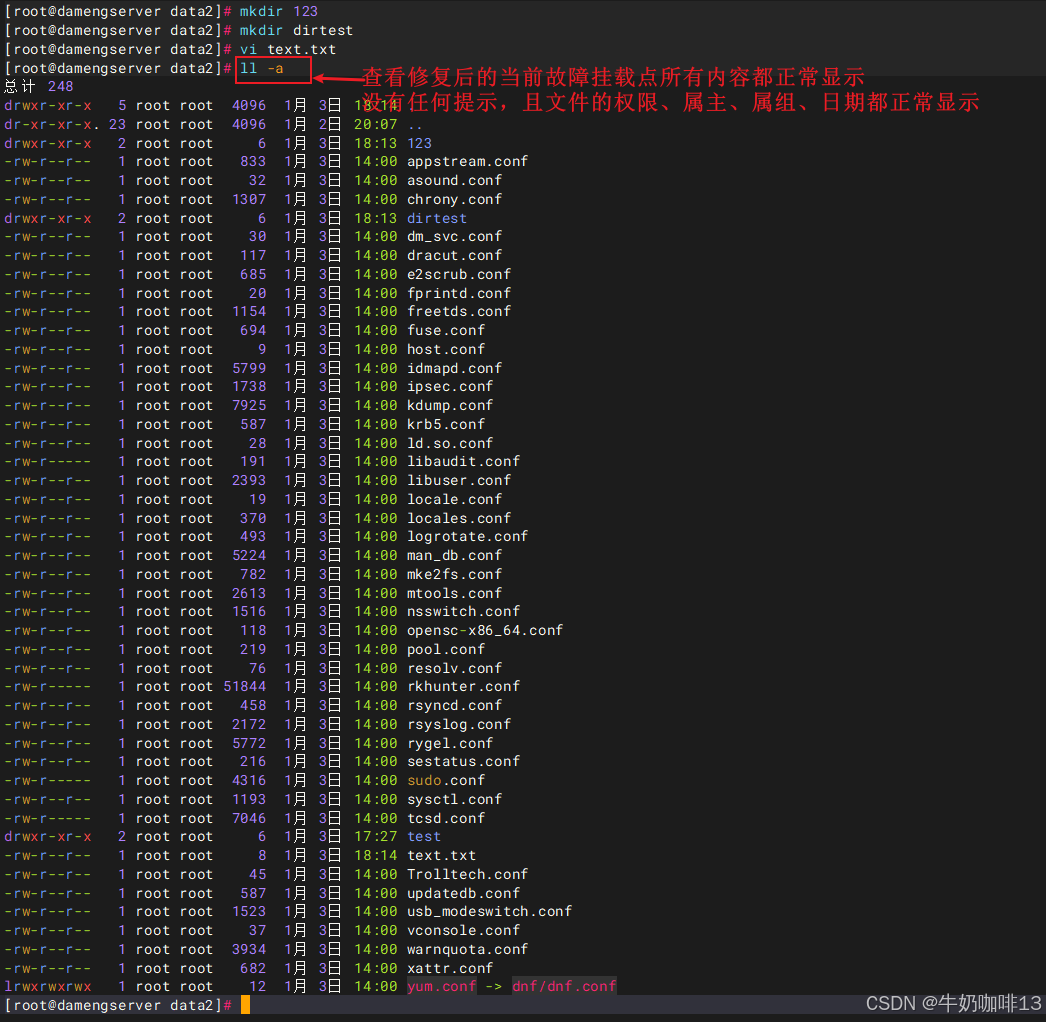
到这里,恭喜你,其他元数据丢失故障修复完成。