还在苦苦寻找面试题不知道去哪找吗,还在为面试准备发愁吗?确实本人经常也会有这样的烦恼,但是想着近两年的AI大模型这么火爆,为什么不干脆自己手搓一个AI面试机器人呢,一边能从大模型上面出题,还能基于这个自己也回答,完事了给自己评价一下岂不是美哉,顺便还能纠正和发现自己的不足之处,针对性的补充自己的短板,快速提升面试技巧,看看自己和机器人到底谁厉害。
所以花了半个月自己从0开始,基于python+langraph自己做了个面试的智能体。
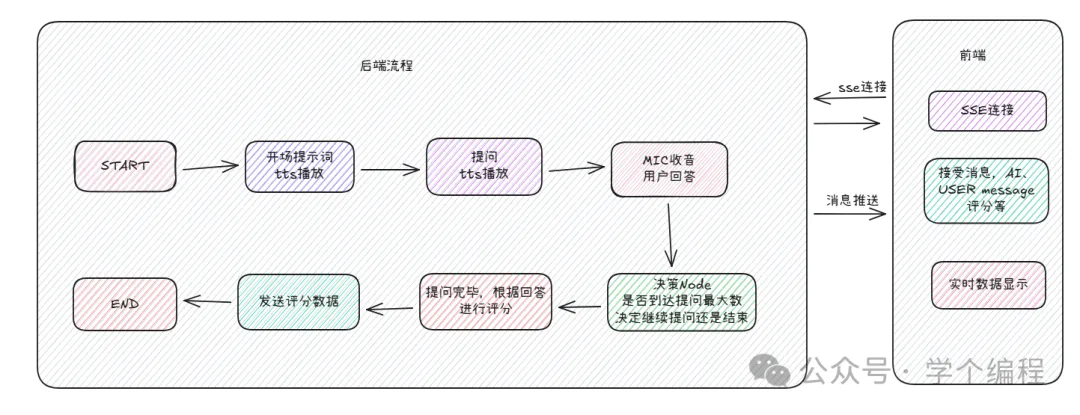
简要设计以及技术栈
技术栈:
后端:
python
fastapi
langraph
前端:
vue3
elementui-plus
主要功能点:
*本地电脑MIC进行收音;
*ASR识别;
*langraph创建agent,以及graph流程编排;
*与LLM进行交互;
*机器人回答进行TTS播报;
*前端与后端通过SSE进行消息推送;
*前端文字与面试结果进行显示
运行效果
aiInterview2
核心代码演示
python
#依旧是放一些核心的部分,其余部分都是正常的执行流程代码,就不展示了,
# 核心的地方还是 graph这里流程的定义
#定义工作流
worker_builder = StateGraph(GraphState)
worker_builder.add_node('interview_init_node', interview_init_node)
worker_builder.add_node('interview_question_node', interview_question_node)
worker_builder.add_node('interview_answer_node', interview_answer_node)
worker_builder.add_node('interview_evaluate_node', interview_evaluate_node)
# 定义工作流边
worker_builder.add_edge(START, 'interview_init_node')
worker_builder.add_edge('interview_init_node', 'interview_question_node')
worker_builder.add_edge('interview_question_node', 'interview_answer_node')
worker_builder.add_conditional_edges("interview_answer_node",
multi_question_next_node,
["interview_question_node","interview_evaluate_node"])
worker_builder.add_edge('interview_evaluate_node', END)
# 会话缓存
# cp = InMemorySaver()
# worker = worker_builder.compile(checkpointer=cp)
worker = worker_builder.compile()
#录音函数
def record_audio():
"""
异步录音函数,启动录音线程
"""
logger.info("core: recording audio...")
dashscope.api_key = settings.DASHSCOPE_API_KEY
dashscope.base_websocket_api_url = settings.DASHSCOPE_ASR_BASE_URL
global should_stop, recording_thread, recognition_instance,thread_id
# 重置停止标志
should_stop = False
thread_id = generate_uuid()
logger.info(f"{TAG}: 新线程ID: {thread_id}")
# 只在没有录音线程或线程已结束时创建新线程
if not recording_thread or not recording_thread.is_alive():
# 在新线程中运行录音函数
recording_thread = threading.Thread(target=continuous_recording_with_silence_detection)
recording_thread.daemon = True
# 设置为守护线程
recording_thread.start()
logger.info(f"{TAG}: 录音线程已启动")
# 异步函数可以立即返回,不会阻塞
return "录音已开始"
# 停止录音
def stop_recording():
"""
停止录音函数,设置全局停止标志
"""
logger.info(f"{TAG}: stop recording...")
global should_stop, recording_thread
should_stop = True
if recording_thread and recording_thread.is_alive():
recording_thread.join(timeout=3.0) # 最多等待5秒
if recording_thread.is_alive():
logger.info(f"{TAG}: 录音线程仍在运行,可能需要强制终止")
else:
logger.info(f"{TAG}: 录音线程已成功停止")
logger.info(f"{TAG}: 停止录音完成")
class ParaforMerRecordAsr:
# 实时语音识别回调
class Callback(RecognitionCallback):
global recording_thread_status, _record_state_change
def on_open(self) -> None:
recording_thread_status = True
logger.info('RecognitionCallback open.')
def on_close(self) -> None:
recording_thread_status = False _
record_state_change(False)
logger.info('RecognitionCallback close.')
# 发送录音的结果到llm进行处理
send_record_msg_to_worker(record_msg)
def on_complete(self) -> None:
recording_thread_status = False
_record_state_change(False)
logger.info('RecognitionCallback completed.')
def on_error(self, message) -> None:
recording_thread_status = False
_record_state_change(False)
logger.info(f'RecognitionCallback task_id: , { message.request_id }')
logger.info(f'RecognitionCallback error: , { message.message }')
# 强制退出程序
sys.exit(1)
def on_event(self, result: RecognitionResult) -> None:
sentence = result.get_sentence()
if 'text' in sentence:
if RecognitionResult.is_sentence_end(sentence):
# logger.info(
# 'RecognitionCallback sentence end, request_id:%s, usage:%s'
# % (result.get_request_id(), result.get_usage(sentence)))
res_text = sentence['text']
logger.info(f'RecognitionCallback text: , { res_text }')
global record_msg
record_msg += res_text
sync_send_msg_sse(MessageData(user_id="user_678", type="message_user", data=res_text))
@staticmethod
def signal_handler(sig, frame):
logger.info(f'{TAG}: Ctrl+C pressed, stop recognition ... sig is {sig}')
# 强制退出程序
sys.exit(0)写在最后
代码并不是很复杂,关键看流程部分如何设计搭配,以及和大模型的交互,其实这只是agent的一部分应用,应用还有很多方面,比如可以构建本地的知识库应用,MCP服务应用,就看具体的运用领域以及深度吧,包括现在各种AI应用工具,开发工具都非常多,像Dify这个工具很多企业也在用,像是几年前很火的低代码开发一样,下篇玩玩这个吧。对比一下代码开发和工具开发区别。
如果感兴趣可以后台交流~