这是我系统可以处理的数据格式:
00:00:08,7067115856073642,[如何清除sysloader],1,2,wenwen.soso.com/z/q51741455.htm
00:00:12,8237461928374651,[周杰伦新歌],3,1,www.qqmusic.com/song/123456
00:01:05,1928374650918273,[北京天气预报],1,1,www.weather.com.cn/beijing
00:01:47,3847561928374650,[苹果手机价格],2,1,www.jd.com/product/10001234.html
00:02:44,5678901234567890,[如何安装MySQL],5,2,dev.mysql.com/downloads/
00:03:21,9988776655443322,[王者荣耀下载],2,1,www.taptap.com/app/12345
00:03:58,2233445566778899,[考研数学真题],4,2,kaoyan.eol.cn/shuxue/2025.html
00:04:07,1122334455667788,[Python多线程教程],4,3,www.runoob.com/python3/python3-multithreading.html
00:05:30,6655443322110099,[NBA总决赛录像],7,2,www.youtube.com/watch?v=abcd1234
00:06:15,5566778899001122,[杭州旅游攻略],3,1,travel.qunar.com/p-hz这是现有的数据文本toutiao_cat_data.txt,一共三十八万条数据
6552368441838272771_!_101_!_news_culture_!_发酵床的垫料种类有哪些?哪种更好?_!_用以下python程序处理完十几秒即可得到我们可以直接处理的数据格式
py
# -*- coding: utf-8 -*-
import os
import re
import random
from datetime import timedelta
from collections import Counter
def build_log_times(seed: int = 42):
"""生成一个时间生成器:每次 next() 返回一个 HH:MM:SS"""
rnd = random.Random(seed)
t = timedelta(seconds=0)
while True:
t += timedelta(seconds=rnd.randint(1, 60))
sec = int(t.total_seconds()) % (24 * 3600)
hh = sec // 3600
mm = (sec % 3600) // 60
ss = sec % 60
yield f"{hh:02d}:{mm:02d}:{ss:02d}"
def ranks_from_id(_id: str):
digits = re.sub(r"\D", "", _id or "")
if not digits:
return 1, 1
last = int(digits[-1])
last2 = int(digits[-2]) if len(digits) >= 2 else last
return (last % 7) + 1, (last2 % 3) + 1
def esc(s: str) -> str:
if s is None:
return ""
s = s.strip().replace("\r", " ").replace("\n", " ")
s = s.replace("~", "~~")
s = s.replace(",", "~c")
s = s.replace("[", "~l")
s = s.replace("]", "~r")
s = s.replace("/", "~s")
s = s.replace("?", "~q")
s = s.replace(" ", "~_")
return s
def validate_6cols(line: str) -> bool:
# 必须恰好 6 列(5个逗号)
return line.count(",") == 5 and len(line.split(",")) == 6
def looks_like_old_csv(line: str) -> bool:
# 旧格式:逗号 6 列,且第3列通常以 [ 开头
if line.count(",") != 5:
return False
parts = line.split(",", 5)
if len(parts) != 6:
return False
return parts[2].startswith("[") # 经验判断
def convert_file(in_path: str, out_path: str, seed: int = 42):
stats = Counter()
time_gen = build_log_times(seed)
with open(in_path, "r", encoding="utf-8") as f_in, open(out_path, "w", encoding="utf-8", newline="\n") as f_out:
for raw in f_in:
stats["total"] += 1
raw = (raw or "").strip()
if not raw:
stats["skip_empty"] += 1
continue
# 1) 如果本来就是旧格式(逗号6列),直接保留(不改)
if looks_like_old_csv(raw):
if validate_6cols(raw):
f_out.write(raw + "\n")
stats["write_old_passthrough"] += 1
else:
stats["skip_old_badcols"] += 1
continue
# 2) 新格式:_!_ 分隔
if "_!_" not in raw:
stats["skip_no_delim"] += 1
continue
parts = raw.split("_!_")
if len(parts) < 4:
stats["skip_too_few_fields"] += 1
continue
_id = parts[0].strip()
_cls = parts[1].strip() if len(parts) > 1 else ""
_cat = parts[2].strip() if len(parts) > 2 else ""
_title = parts[3].strip() if len(parts) > 3 else ""
_kw = "_!_".join(parts[4:]).strip() if len(parts) > 4 else ""
if not _id:
stats["skip_no_id"] += 1
continue
# 输出 6 列
logtime = next(time_gen)
userid = _id
queryword = f"[{esc(_title)}]"
result_rank, click_rank = ranks_from_id(_id)
url = f"www.example.com/n/{esc(_cat)}/{esc(_id)}/c{esc(_cls)}/k{esc(_kw)}?p=1"
out_line = f"{logtime},{userid},{queryword},{result_rank},{click_rank},{url}"
if not validate_6cols(out_line):
stats["skip_out_badcols"] += 1
continue
f_out.write(out_line + "\n")
stats["write_new_converted"] += 1
return stats
def main():
import tkinter as tk
from tkinter import filedialog, messagebox
root = tk.Tk()
root.withdraw()
in_path = filedialog.askopenfilename(
title="选择要转换的新数据文件(UTF-8)",
filetypes=[("Text Files", "*.txt *.log *.csv"), ("All Files", "*.*")]
)
if not in_path:
return
out_path = os.path.join(os.path.dirname(in_path), "result.txt")
stats = convert_file(in_path, out_path, seed=42)
# 组织展示信息(重点看 skip_no_delim / skip_too_few_fields)
msg_lines = [
f"输出文件:{out_path}",
f"总行数:{stats['total']}",
"",
f"写入(旧格式原样透传):{stats['write_old_passthrough']}",
f"写入(新格式转换输出):{stats['write_new_converted']}",
"",
f"跳过-空行:{stats['skip_empty']}",
f"跳过-不含 '_!_' 分隔符:{stats['skip_no_delim']}",
f"跳过-字段数<4:{stats['skip_too_few_fields']}",
f"跳过-id为空:{stats['skip_no_id']}",
f"跳过-旧格式列数异常:{stats['skip_old_badcols']}",
f"跳过-输出列数异常:{stats['skip_out_badcols']}",
]
messagebox.showinfo("转换完成(带统计)", "\n".join(msg_lines))
if __name__ == "__main__":
main()输出结果文件为result.txt。上传至虚拟机后修改为对应文件名sogoulogs.log即可
优化速度
删除重建topic
bash
#删除 topic(正确命令)
/home/hadoop/app/kafka/bin/kafka-topics.sh \
--zookeeper hadoop01:2181 \
--delete \
--topic sogoulogs
# 确认 topic 已被删除
/home/hadoop/app/kafka/bin/kafka-topics.sh \
--zookeeper hadoop01:2181 \
--list
# 重新创建 topic(推荐参数)
/home/hadoop/app/kafka/bin/kafka-topics.sh \
--zookeeper hadoop01:2181 \
--create \
--topic sogoulogs \
--partitions 3 \
--replication-factor 1
# 验证
/home/hadoop/app/kafka/bin/kafka-topics.sh \
--zookeeper hadoop01:2181 \
--describe \
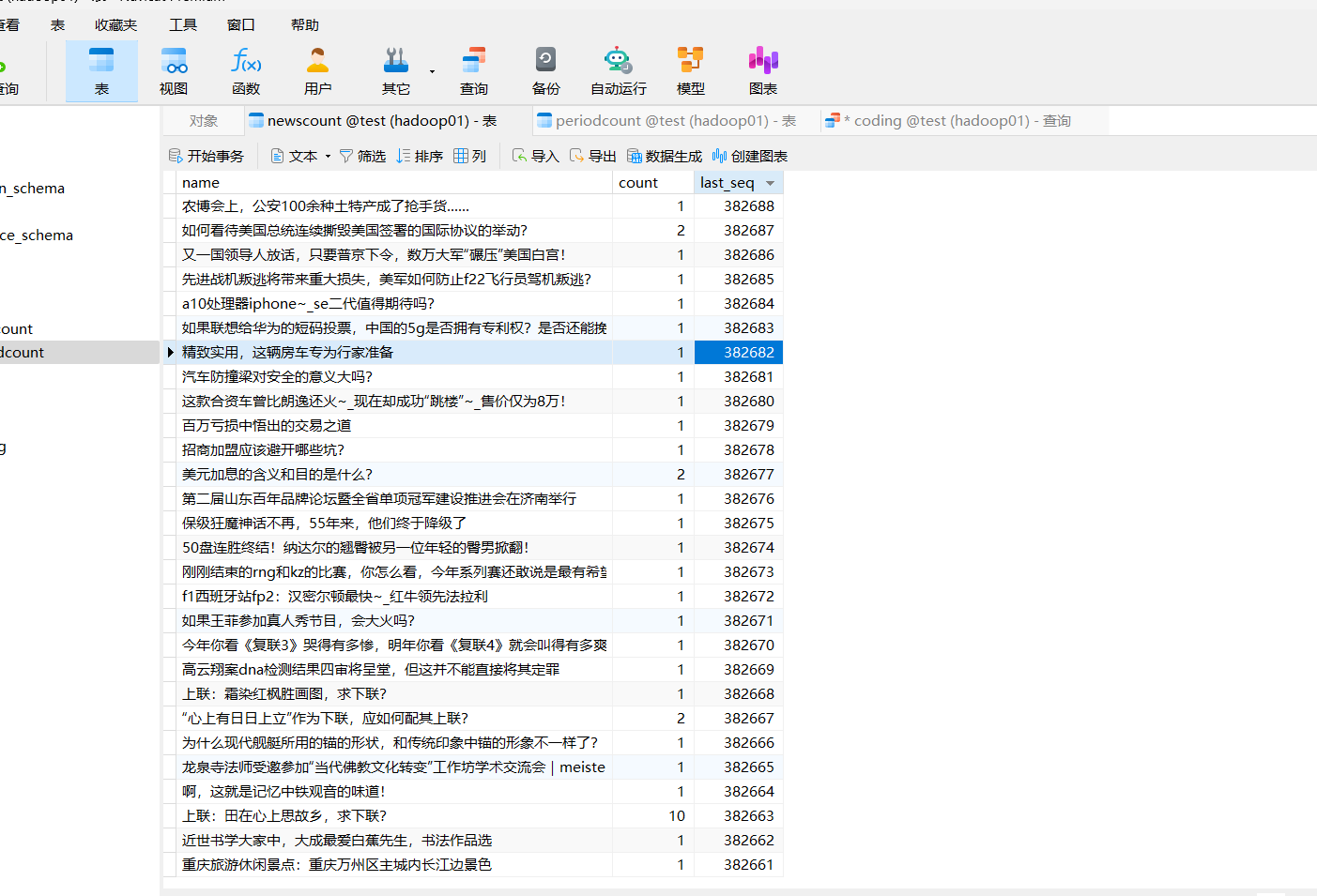
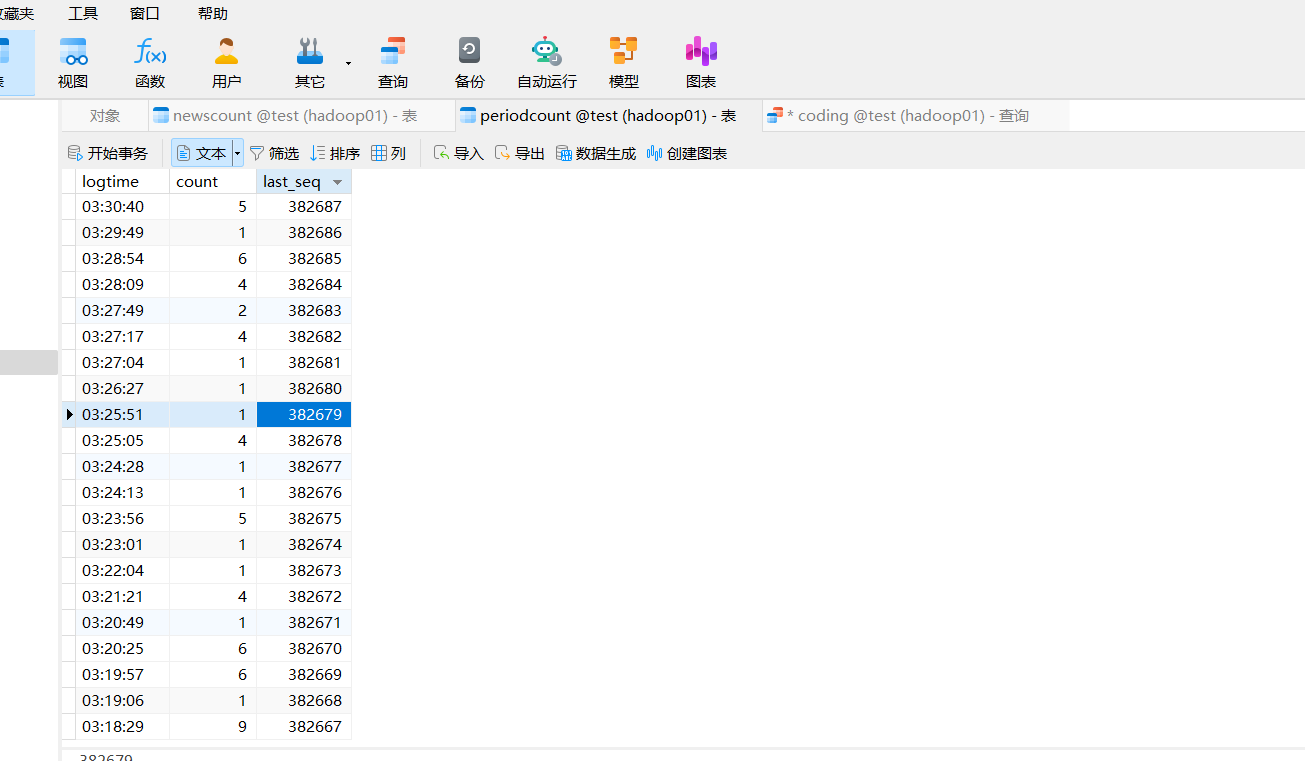
--topic sogoulogs数据库优化:
sql
USE test;
ALTER TABLE newscount MODIFY COLUMN name VARCHAR(255) NOT NULL;
ALTER TABLE newscount ADD COLUMN last_seq BIGINT NOT NULL DEFAULT 0;
ALTER TABLE periodcount ADD COLUMN last_seq BIGINT NOT NULL DEFAULT 0;
ALTER TABLE newscount ADD UNIQUE KEY uk_name (name);
ALTER TABLE periodcount ADD UNIQUE KEY uk_logtime (logtime);/home/hadoop/shell/bin下的sogoulogs.sh优化
sh
#!/bin/bash
home=$(cd "$(dirname "$0")"; cd ..; pwd)
. "${home}/bin/common.sh"
INPUT="${data_home}/sogoulogs.log"
echo "start analog data ****************"
echo "input: ${INPUT}"
awk -v OFS=',' '{print $0, NR}' "${INPUT}" | /home/hadoop/app/kafka/bin/kafka-console-producer.sh \
--broker-list hadoop01:9092,hadoop02:9092,hadoop03:9092 \
--topic sogoulogs \
--producer-property acks=1 \
--producer-property linger.ms=20 \
--producer-property batch.size=65536 \
--producer-property compression.type=snappy \
--producer-property buffer.memory=67108864 \
--producer-property max.request.size=10485760
echo "done."在learningflink1.9中修改
KafkaFlinkMySQL.java
java
package com.djt.flink.news;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicLong;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class KafkaFlinkMySQL {
private static final Logger LOG = LoggerFactory.getLogger(KafkaFlinkMySQL.class);
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 轻薄本稳:先用1;等MySQL降下来再考虑2
env.setParallelism(1);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "hadoop01:9092,hadoop02:9092,hadoop03:9092");
properties.setProperty("group.id", "sogoulogs-group-" + System.currentTimeMillis());
properties.setProperty("auto.offset.reset", "earliest");
properties.setProperty("enable.auto.commit", "true");
properties.setProperty("session.timeout.ms", "30000");
properties.setProperty("request.timeout.ms", "40000");
properties.setProperty("max.poll.records", "2000");
properties.setProperty("heartbeat.interval.ms", "3000");
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>(
"sogoulogs",
new SimpleStringSchema(),
properties
);
consumer.setStartFromEarliest();
DataStream<String> stream = env.addSource(consumer).name("KafkaSource");
// 只每10000条打一次进度
DataStream<String> progress = stream.map(new MapFunction<String, String>() {
private static final long serialVersionUID = 1L;
private final AtomicLong c = new AtomicLong(0);
@Override
public String map(String value) {
long n = c.incrementAndGet();
if (n % 10000 == 0) {
String[] parts = value.split(",", -1);
String seq = (parts.length >= 7) ? parts[6] : "NA";
LOG.info("消费进度: {} 条 (last_seq={})", n, seq);
}
return value;
}
}).name("ProgressLogger");
// 期望7列
DataStream<String> filter = progress.filter(new FilterFunction<String>() {
private static final long serialVersionUID = 1L;
@Override
public boolean filter(String value) {
try {
return value.split(",", -1).length == 7;
} catch (Exception e) {
return false;
}
}
}).name("DataFilter");
// 新闻聚合:5秒窗口内聚合,降低MySQL写频率
DataStream<Tuple3<String, Integer, Long>> newsAgg = filter
.flatMap(new NewsSplitter())
.name("NewsSplit")
.keyBy(t -> t.f0)
.timeWindow(Time.seconds(5))
.reduce(new CountAndMaxSeqReduce())
.name("NewsWindowReduce");
// 时间段聚合:5秒窗口
DataStream<Tuple3<String, Integer, Long>> periodAgg = filter
.flatMap(new PeriodSplitter())
.name("PeriodSplit")
.keyBy(t -> t.f0)
.timeWindow(Time.seconds(5))
.reduce(new CountAndMaxSeqReduce())
.name("PeriodWindowReduce");
newsAgg.addSink(new MySQLSink()).name("NewsMySQLSink").setParallelism(1);
periodAgg.addSink(new MySQLSink2()).name("PeriodMySQLSink").setParallelism(1);
env.execute("FlinkMySQL-FastSafe-Window");
}
public static final class NewsSplitter implements FlatMapFunction<String, Tuple3<String, Integer, Long>> {
private static final long serialVersionUID = 1L;
@Override
public void flatMap(String value, Collector<Tuple3<String, Integer, Long>> out) {
try {
String[] t = value.toLowerCase().split(",", -1);
String name = t[2];
long seq = Long.parseLong(t[6]);
out.collect(new Tuple3<>(name, 1, seq));
} catch (Exception ignored) {}
}
}
public static final class PeriodSplitter implements FlatMapFunction<String, Tuple3<String, Integer, Long>> {
private static final long serialVersionUID = 1L;
@Override
public void flatMap(String value, Collector<Tuple3<String, Integer, Long>> out) {
try {
String[] t = value.toLowerCase().split(",", -1);
String logtime = t[0];
long seq = Long.parseLong(t[6]);
out.collect(new Tuple3<>(logtime, 1, seq));
} catch (Exception ignored) {}
}
}
public static final class CountAndMaxSeqReduce implements ReduceFunction<Tuple3<String, Integer, Long>> {
private static final long serialVersionUID = 1L;
@Override
public Tuple3<String, Integer, Long> reduce(Tuple3<String, Integer, Long> a,
Tuple3<String, Integer, Long> b) {
return new Tuple3<>(a.f0, a.f1 + b.f1, Math.max(a.f2, b.f2));
}
}
}MySQLSink.java
java
package com.djt.flink.news;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
public class MySQLSink extends RichSinkFunction<Tuple3<String, Integer, Long>> {
private static final long serialVersionUID = 1L;
private transient Connection conn;
private transient PreparedStatement ps;
// 轻薄本:500 左右比较稳;想更快可 800/1000
private static final int BATCH_SIZE = 800;
private int batchCount = 0;
@Override
public void open(org.apache.flink.configuration.Configuration parameters) throws Exception {
Class.forName(GlobalConfig.DRIVER_CLASS);
conn = DriverManager.getConnection(GlobalConfig.DB_URL, GlobalConfig.USER_MAME, GlobalConfig.PASSWORD);
conn.setAutoCommit(false);
// 依赖:newscount.name 有 UNIQUE KEY
String sql =
"INSERT INTO newscount(name, count, last_seq) VALUES(?, ?, ?) " +
"ON DUPLICATE KEY UPDATE " +
"count = VALUES(count), " +
"last_seq = GREATEST(last_seq, VALUES(last_seq))";
ps = conn.prepareStatement(sql);
}
@Override
public void invoke(Tuple3<String, Integer, Long> v, Context context) throws Exception {
String name = (v.f0 == null) ? "" : v.f0.replaceAll("[\\[\\]]", "");
int count = (v.f1 == null) ? 0 : v.f1;
long seq = (v.f2 == null) ? 0L : v.f2;
ps.setString(1, name);
ps.setInt(2, count);
ps.setLong(3, seq);
ps.addBatch();
batchCount++;
if (batchCount >= BATCH_SIZE) {
ps.executeBatch();
conn.commit();
batchCount = 0;
}
}
@Override
public void close() throws Exception {
try {
if (ps != null) {
if (batchCount > 0) {
ps.executeBatch();
conn.commit();
}
ps.close();
}
} finally {
if (conn != null) conn.close();
}
}
}MySQLSink2.java
java
package com.djt.flink.news;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
public class MySQLSink2 extends RichSinkFunction<Tuple3<String, Integer, Long>> {
private static final long serialVersionUID = 1L;
private transient Connection conn;
private transient PreparedStatement ps;
private static final int BATCH_SIZE = 800;
private int batchCount = 0;
@Override
public void open(org.apache.flink.configuration.Configuration parameters) throws Exception {
Class.forName(GlobalConfig.DRIVER_CLASS);
conn = DriverManager.getConnection(GlobalConfig.DB_URL, GlobalConfig.USER_MAME, GlobalConfig.PASSWORD);
conn.setAutoCommit(false);
// 依赖:periodcount.logtime 有 UNIQUE KEY
String sql =
"INSERT INTO periodcount(logtime, count, last_seq) VALUES(?, ?, ?) " +
"ON DUPLICATE KEY UPDATE " +
"count = VALUES(count), " +
"last_seq = GREATEST(last_seq, VALUES(last_seq))";
ps = conn.prepareStatement(sql);
}
@Override
public void invoke(Tuple3<String, Integer, Long> v, Context context) throws Exception {
String logtime = (v.f0 == null) ? "" : v.f0;
int count = (v.f1 == null) ? 0 : v.f1;
long seq = (v.f2 == null) ? 0L : v.f2;
ps.setString(1, logtime);
ps.setInt(2, count);
ps.setLong(3, seq);
ps.addBatch();
batchCount++;
if (batchCount >= BATCH_SIZE) {
ps.executeBatch();
conn.commit();
batchCount = 0;
}
}
@Override
public void close() throws Exception {
try {
if (ps != null) {
if (batchCount > 0) {
ps.executeBatch();
conn.commit();
}
ps.close();
}
} finally {
if (conn != null) conn.close();
}
}
}在项目的resources目录下创建log4j.properties文件:
properties
log4j.rootLogger=INFO, stdout, file
# 控制台输出
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
# 文件输出
log4j.appender.file=org.apache.log4j.RollingFileAppender
log4j.appender.file.File=./logs/flink-kafka.log
log4j.appender.file.MaxFileSize=10MB
log4j.appender.file.MaxBackupIndex=10
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
# Flink相关日志设置
log4j.logger.org.apache.flink=INFO
log4j.logger.org.apache.kafka=INFO
log4j.logger.com.djt.flink.news=DEBUG启动 MySQL 服务
因为 Flink 处理结果要落到 MySQL 的 newscount 和 periodcount 表里,所以必须先启动数据库。
-
在
hadoop01节点执行:bashservice mysql start或
bashsystemctl start mysqld -
验证:
bashmysql -uroot -p mysql> show databases;
确保有 test 数据库,以及表 newscount、periodcount 已创建。
启动 Zookeeper 服务
Kafka 依赖 Zookeeper 协调。
-
在
hadoop01/hadoop02/hadoop03各节点执行:bashcd /home/hadoop/app/zookeeper/bin ./zkServer.sh start -
验证:
bash./zkServer.sh status确保有一个是
leader,其他是follower。
启动 Kafka 集群
Flink DataStream 会消费 Kafka 的日志流。
-
在各节点执行:
bashcd /home/hadoop/app/kafka/bin ./kafka-server-start.sh -daemon ../config/server.properties -
验证:
bashjps | grep Kafka
启动 Flink 实时应用
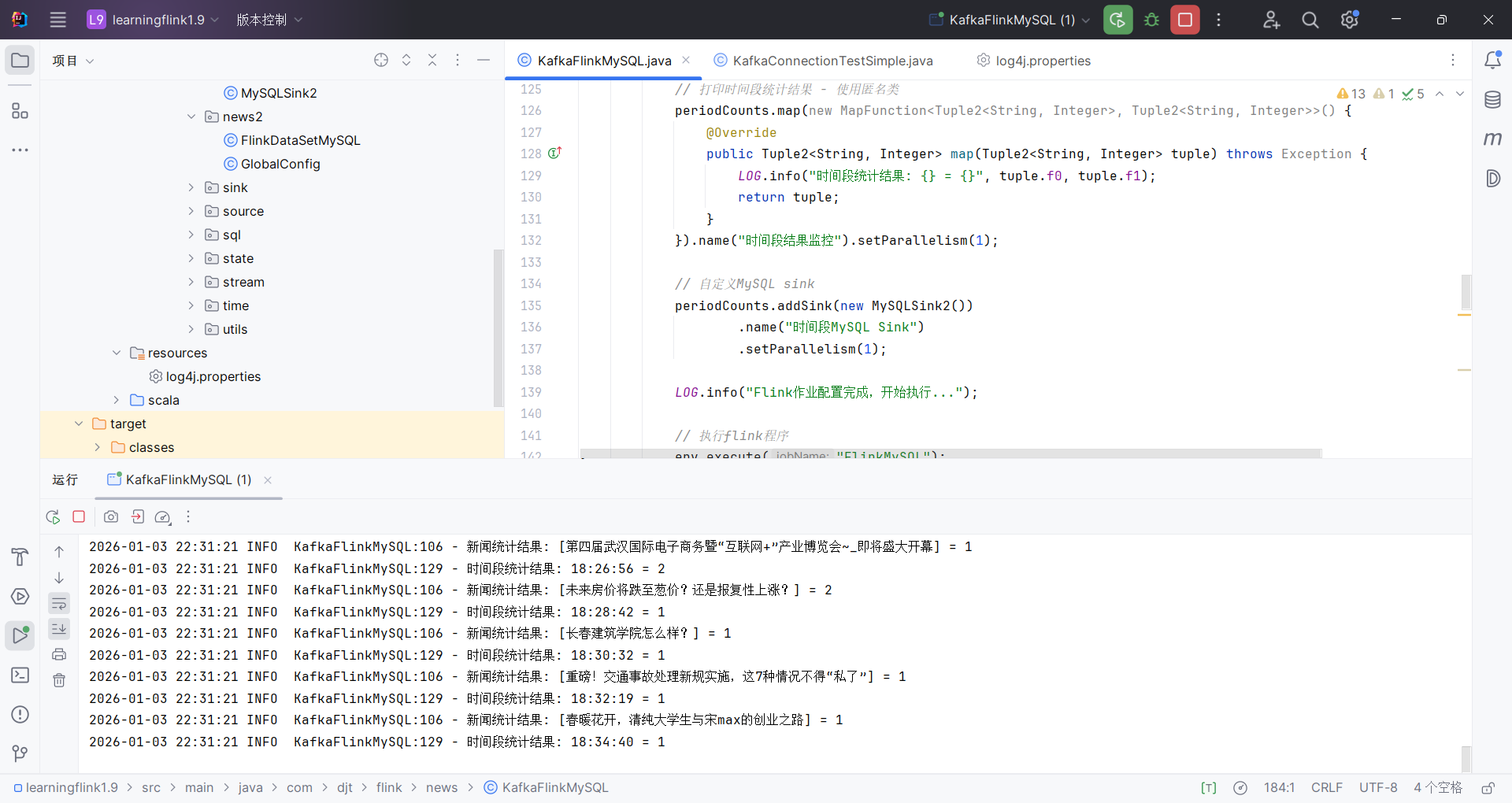
书里用的例子是 KafkaFlinkMySQL,把 Kafka 数据实时处理后写入 MySQL。
- 在 IDEA 里找到
KafkaFlinkMySQL.java - 右键 →
Run 'KafkaFlinkMySQL.main()'
启动 Flume 聚合节点
Flume 负责把采集到的日志推送到 Kafka。
-
在
hadoop02、hadoop03上执行:bashcd /home/hadoop/app/flume bin/flume-ng agent -n a2 -c conf -f conf/xxx.conf -Dflume.root.logger=INFO,console &
启动 Flume 采集节点
-
在
hadoop01上执行:bashcd /home/hadoop/app/flume bin/flume-ng agent -n a1 -c conf -f conf/xxx.conf -Dflume.root.logger=INFO,console &
这一步会把日志源源不断地推送到聚合节点,再写到 Kafka。
模拟产生数据
-
在
hadoop01上执行:bashcd /home/hadoop/shell/bin ./sogoulogs.sh
如果你想在运行过程查看当前的已写入数据数
sql
-- 统计去重后的数量
SELECT COUNT(DISTINCT logtime) FROM periodcount;
SELECT COUNT(DISTINCT name) FROM newscount; 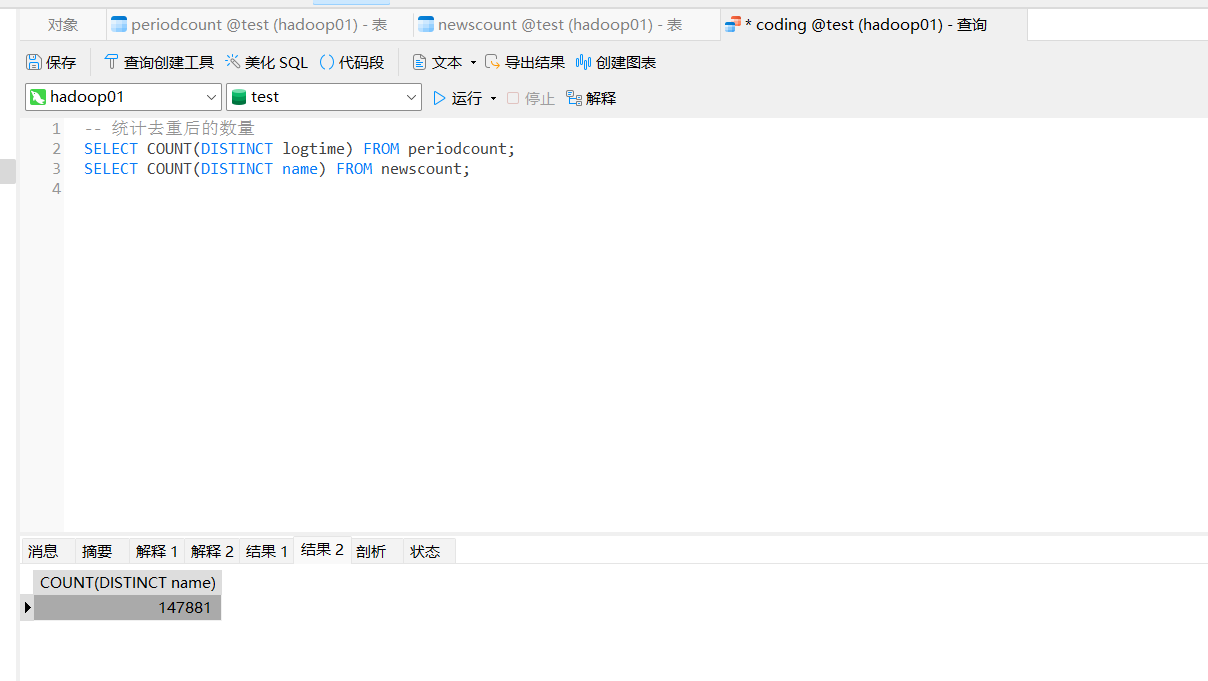
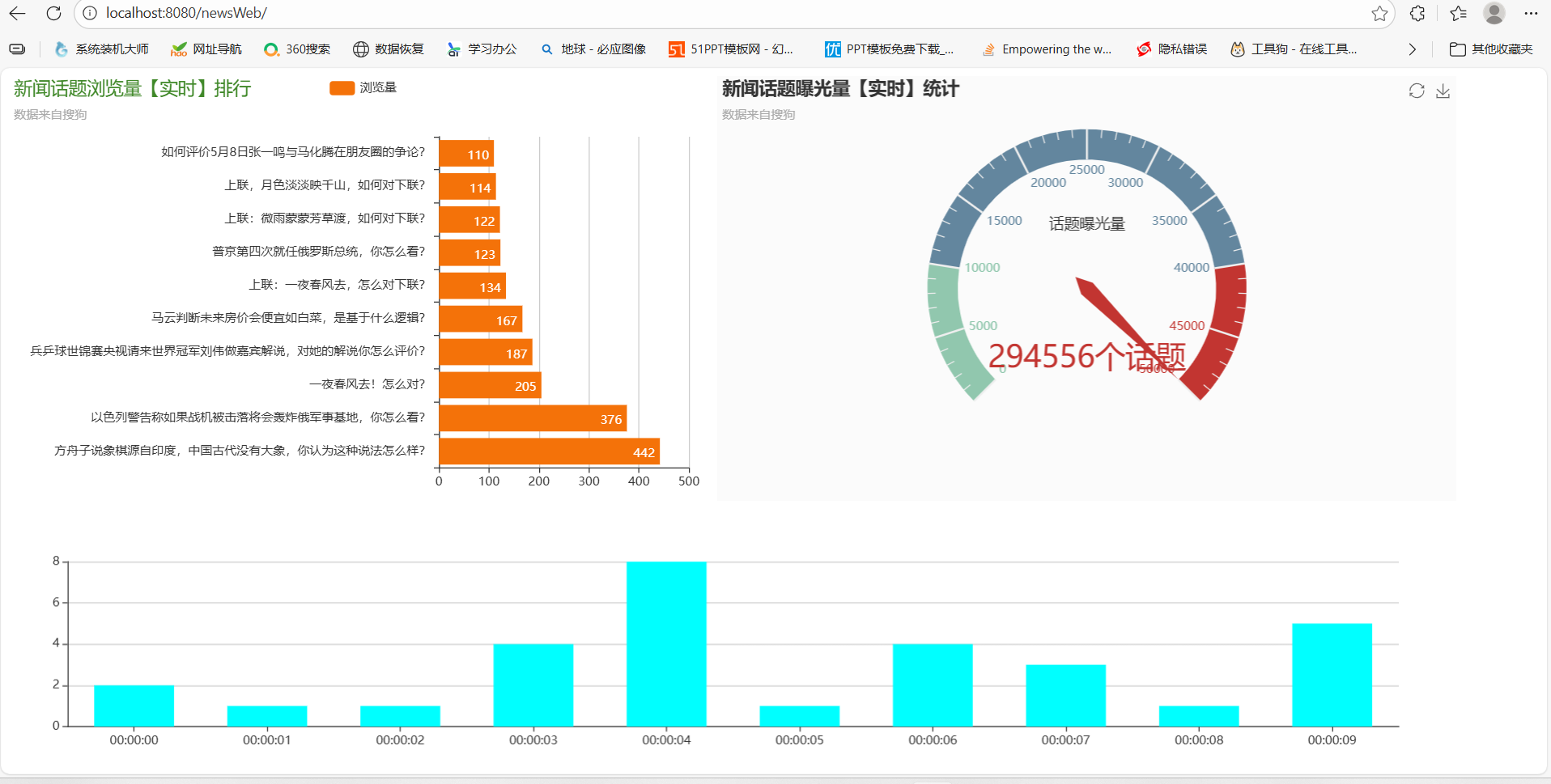
最终效果展示: