引言:
随着计算机视觉技术在工业检测、安防监控、自动驾驶等领域的深度渗透,目标检测作为核心技术之一,对模型的实时性、精度与工程可落地性提出了更高要求。YOLO(You Only Look Once)系列模型凭借 "端到端" 检测架构,实现了精度与速度的高效平衡,其中 YOLOv5 以轻量化设计、灵活可调的模型尺度及简洁的工程化部署流程,成为开发者首选的目标检测工具。
然而,从理论模型到实际应用,开发者常面临诸多实操痛点:数据集划分不规范导致模型泛化能力不足、训练参数调整缺乏针对性引发过拟合 / 欠拟合、模型推理配置与场景适配不当影响检测效果等。这些问题往往成为技术落地的 "拦路虎",亟需一套系统、详实的实操指南提供指引。
本文聚焦 YOLOv5 模型的工程化实践核心,结合实际开发场景,从数据集准备、训练参数优化、模型推理部署等关键环节展开论述,旨在梳理从数据到落地的完整技术链路,为开发者规避实操误区、提升模型部署效率提供切实参考,助力 YOLOv5 在各类实际业务场景中充分发挥其轻量化与高效能的优势。
1、YOLO数据的制作:
1.1、数据集的介绍:
在 YOLO 系列模型的目标检测任务中,数据集是由大量带标注(或无标注)的图像样本及对应标签信息组成的核心集合,是模型学习、训练、验证和测试的基础,就像是模型的 "教材" 和 "考卷"。其核心内容包括两部分,一是涵盖不同场景、光照、角度的目标图像,为模型提取特征提供来源;二是针对目标检测任务的标注信息,通常包含目标的类别标签(如 "人""车")和边界框坐标(用归一化数值表示目标在图像中的位置),且需遵循 YOLO 专属的 txt 标注格式。按照用途,数据集可分为训练集、验证集、测试集,三者各司其职,共同支撑模型从训练到落地的全流程。
其中主要的介绍包含以下三点:
1.1.1、核心定义与核心职能:
- 训练集:模型 "学习样本库",规模最大、覆盖最广,提供标注样本供模型优化参数、学习目标特征,是 "吸收知识" 的核心。
- 验证集:模型 "调优参考系",监控训练性能、避免过拟合 / 欠拟合,助力超参数调整与早停判断,评估泛化能力。
- 测试集:模型 "最终考核卷",独立于训练流程,客观评估真实落地性能,输出 mAP 等无偏指标,是发布前关键依据。
1.1.2、划分原则与比例:
- 通用场景(数万 - 数十万张):7:1:2 或 8:1:1;
- 小样本场景(数千张):6:2:2(需数据增强);
- 百万级大数据:9:0.5:0.5(保证各类别样本足量)。
1.1.3各数据集的关键数据要求:
- 训练集:需多样性、充足性、标注精准(边界框偏差≤2 像素),可通过 Mosaic、MixUp 等增强优化;
- 验证集:需代表性、无重叠,类别比例与训练集一致,避免调优误判;
- 测试集:需客观性(独立封存)、完整性(含极端场景)、真实性,标注规范与训练集统一。
1.2、YOLO数据集划分:
首先,当我们利用图片标注工具(labelme)标注完足够数量的样本之后,就可以进行模型训练前较为重要的一步了------数据集的划分。数据的标注可以前往:深度学习入门篇------YOLOv5的标签制作(Labelme)学习.
然后是我们得清楚数据集的结构如下图所示,所以我们得在对应目录下创建数据集。
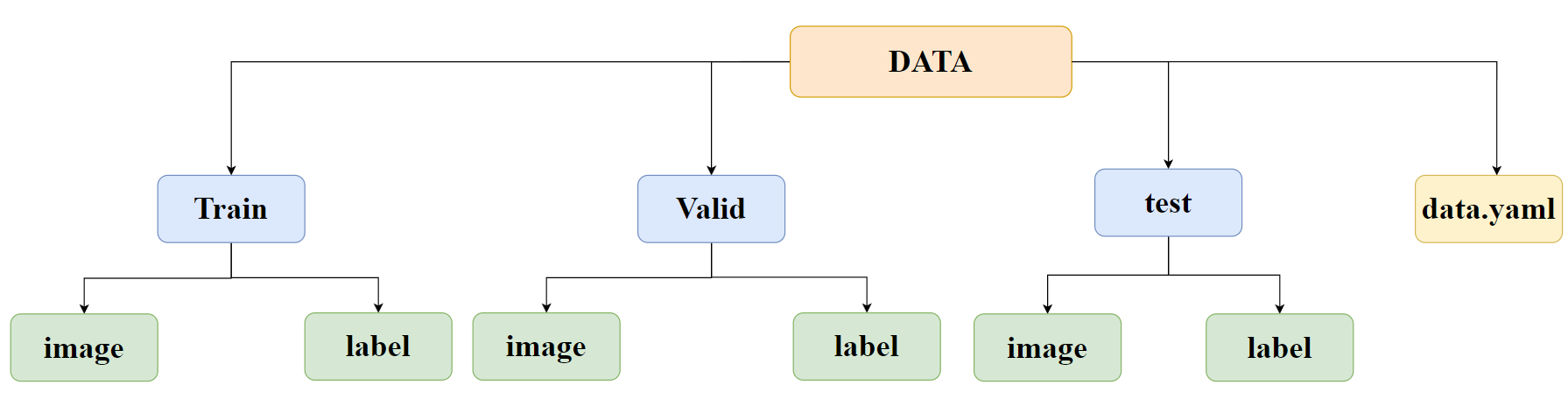
图中
- Train、Valid、test 是按用途划分的三个子目录(对应训练集、验证集、测试集),每个子目录下都包含两个文件夹:
image(存放对应数据集的图像文件)和label(存放对应图像的标注文件,格式是 YOLO 专用的 txt 文件,记录目标类别和边界框信息)。- data.yaml是 YOLO 的配置文件,它的作用是告诉模型 "Train/Valid/test 对应的 image 和 label 文件夹在哪""数据集中有哪些目标类别" 等关键信息,是模型能正确读取数据的 "指引文件"。
注意:image、lable中的文件要严格对应,标签和图像的命名应该相同。
然后利用随机划分程序进行划分以填充数据集,具体的划分程序如下:
1、将收集到的所有数据整合(图像加标签数据),然后运行随机划分程序(注意将程序中的数据路径替换成你的实际数据路径):
python
import os
import shutil
import random
def split_dataset(image_dir, label_dir, output_dir, split_ratio):
"""
划分数据集为训练集、验证集和测试集。
Args:
image_dir (str): 原始图像文件所在目录。
label_dir (str): 原始标签文件所在目录。
output_dir (str): 划分后数据集的输出根目录。
split_ratio (tuple): 划分比例 (train, val, test),例如 (0.7, 0.2, 0.1)。
"""
# 1. 校验输入参数
if not os.path.isdir(image_dir):
print(f"错误:图像目录 '{image_dir}' 不存在。")
return
if not os.path.isdir(label_dir):
print(f"错误:标签目录 '{label_dir}' 不存在。")
return
if len(split_ratio) != 3 or not all(isinstance(x, float) for x in split_ratio):
print("错误:划分比例必须是一个包含三个浮点数的元组。")
return
if abs(sum(split_ratio) - 1.0) > 1e-6:
print("警告:划分比例之和不为1,已自动进行归一化处理。")
total = sum(split_ratio)
split_ratio = (split_ratio[0]/total, split_ratio[1]/total, split_ratio[2]/total)
train_ratio, val_ratio, test_ratio = split_ratio
# 2. 查找所有匹配的图片和标签文件
image_files = [f for f in os.listdir(image_dir) if f.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp'))]
print(f"在 '{image_dir}' 中找到 {len(image_files)} 张图像。")
file_pairs = []
for img_file in image_files:
# 假设标签文件与图像文件同名,只是扩展名为.txt
base_name = os.path.splitext(img_file)[0]
label_file = base_name + '.txt'
if os.path.exists(os.path.join(label_dir, label_file)):
file_pairs.append((img_file, label_file))
else:
print(f"警告:未找到图像 '{img_file}' 对应的标签文件 '{label_file}',已跳过。")
if not file_pairs:
print("错误:没有找到任何匹配的图片和标签对,程序终止。")
return
total_count = len(file_pairs)
print(f"成功匹配到 {total_count} 对图片和标签。")
# 3. 打乱数据
random.seed(42) # 设置随机种子以确保每次划分结果一致
random.shuffle(file_pairs)
# 4. 计算划分数量
train_count = int(total_count * train_ratio)
val_count = int(total_count * val_ratio)
# test_count = total_count - train_count - val_count # 确保所有文件都被分配
# 5. 切分数据
train_pairs = file_pairs[:train_count]
val_pairs = file_pairs[train_count : train_count + val_count]
test_pairs = file_pairs[train_count + val_count:]
print(f"划分结果:训练集 {len(train_pairs)} 对,验证集 {len(val_pairs)} 对,测试集 {len(test_pairs)} 对。")
# 6. 定义输出目录结构
split_dirs = {
'train': {'images': os.path.join(output_dir, 'train', 'images'), 'labels': os.path.join(output_dir, 'train', 'labels')},
'val': {'images': os.path.join(output_dir, 'val', 'images'), 'labels': os.path.join(output_dir, 'val', 'labels')},
'test': {'images': os.path.join(output_dir, 'test', 'images'), 'labels': os.path.join(output_dir, 'test', 'labels')},
}
# 7. 创建输出目录
for sets in split_dirs.values():
for dir_path in sets.values():
os.makedirs(dir_path, exist_ok=True)
print(f"已在 '{output_dir}' 中创建必要的目录结构。")
# 8. 复制文件
def copy_files(pairs, dest_images, dest_labels):
for img_name, label_name in pairs:
shutil.copy2(os.path.join(image_dir, img_name), os.path.join(dest_images, img_name))
shutil.copy2(os.path.join(label_dir, label_name), os.path.join(dest_labels, label_name))
print("正在复制文件到训练集...")
copy_files(train_pairs, split_dirs['train']['images'], split_dirs['train']['labels'])
print("正在复制文件到验证集...")
copy_files(val_pairs, split_dirs['val']['images'], split_dirs['val']['labels'])
print("正在复制文件到测试集...")
copy_files(test_pairs, split_dirs['test']['images'], split_dirs['test']['labels'])
print("\n数据集划分完成!")
print(f"输出文件已保存至: {os.path.abspath(output_dir)}")
if __name__ == '__main__':
# --- 请在这里修改你的配置 ---
# 1. 设置你的原始图像和标签文件夹路径
# 例如: "C:/my_project/dataset/images" 或 "/home/user/dataset/images"
# 注意:使用 os.path.join 可以提高代码的跨平台兼容性
IMAGE_DIR = "path/to/your/images"
LABEL_DIR = "path/to/your/labels"
# 2. 设置划分后数据的输出根目录
# 如果目录不存在,脚本会自动创建
OUTPUT_DIR = "path/to/output/split_dataset"
# 3. 设置训练集、验证集、测试集的划分比例
# 例如,70% 用于训练,15% 用于验证,15% 用于测试
SPLIT_RATIO = (0.7, 0.15, 0.15)
# --- 配置结束,请勿修改以下代码 ---
print("--- 开始执行数据集划分 ---")
print(f"图像路径: {IMAGE_DIR}")
print(f"标签路径: {LABEL_DIR}")
print(f"输出路径: {OUTPUT_DIR}")
print(f"划分比例: 训练集 {SPLIT_RATIO[0]}, 验证集 {SPLIT_RATIO[1]}, 测试集 {SPLIT_RATIO[2]}")
print("-" * 30)
split_dataset(IMAGE_DIR, LABEL_DIR, OUTPUT_DIR, SPLIT_RATIO)程序运行会自动根据输入数据完成数据集的划分。完成划分后,我们需要在数据集目录下创建一个配置文件:data.yaml,具体内容如下:
python
train: ../train/images
val: ../valid/images
test: ../test/images
nc: 5
names: ['Crack', 'LF', 'LP', 'Pore', 'SL']
- 其中
train,val,test三个关键字,定义了训练、验证和测试图像文件夹的路径。脚本会根据这些路径去加载对应的图片和标签文件。nc: 5告诉模型,你的数据集中一共有 5 个不同的目标类别需要学习识别。names列表,定义了这 5 个类别的具体名称,如'Crack','Pore'等。注意:列表中类别的顺序决定了它们在标签文件(
.txt)中的数字索引(从 0 开始)。例如,'Crack'对应索引0,'LF'对应索引1,以此类推。
到此,我们就完成了YOLO的数据集划分。
2、YOLO模型训练与检测:
2.1、预训练模型权重的导入:
完成了数据集训练后我们就准备开始模型的训练了,开始训练的第一步就是我们得先下载一个预训练模型,那什么是预训练模型呢?
预训练模型是开发者先用大规模通用数据集(比如 YOLOv5 用的 COCO 数据集),提前把模型训练好,让模型学会了一些 "通用的目标检测能力"------ 比如识别物体的轮廓、常见目标的基础特征(像 "人""车" 的形状规律)。
首先我们进入Github中YOLOv5的官网,并下滑找到"Pretrained Checkpoints"。(Github如何使用请见:深度学习入门篇------Github的使用和项目的导入)
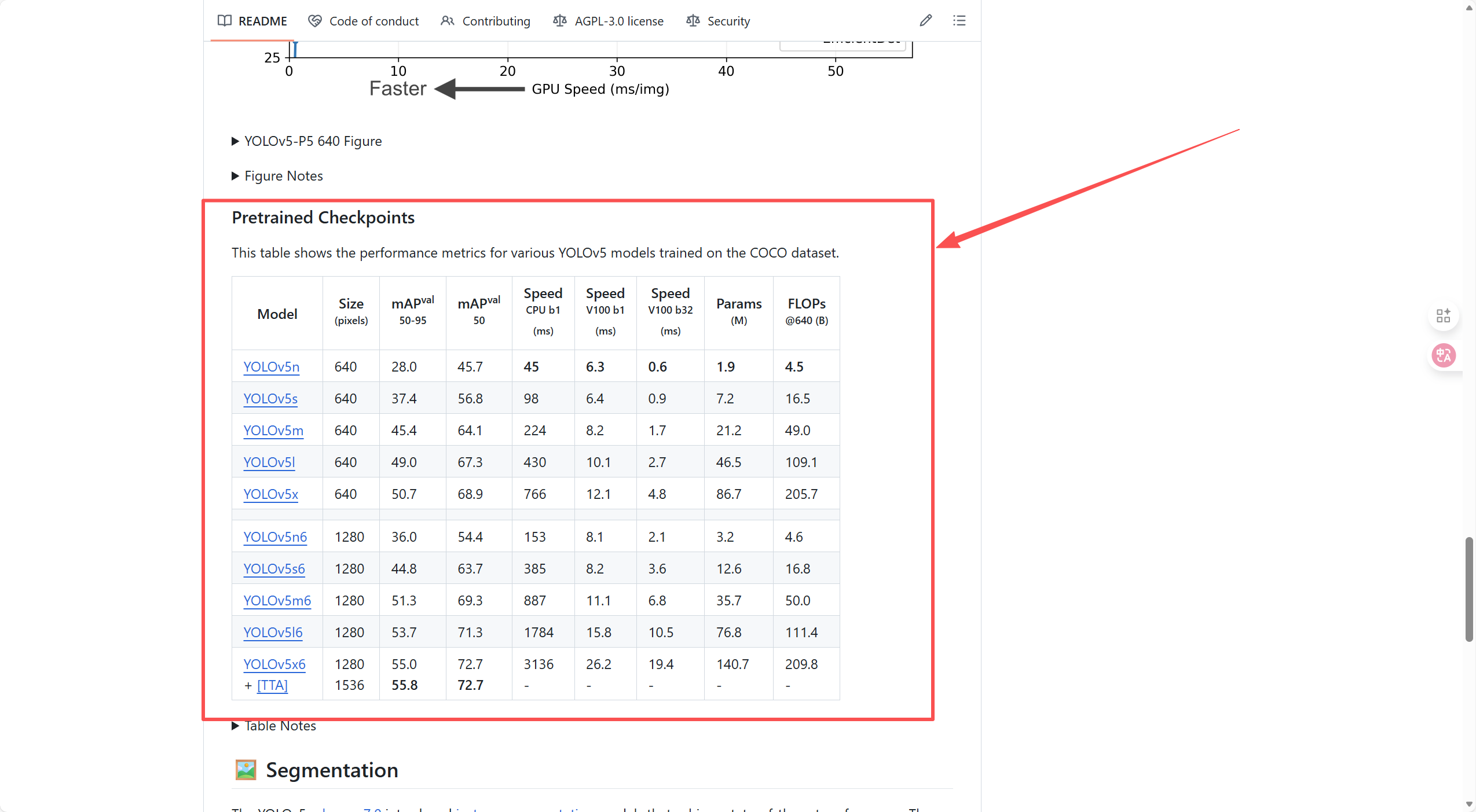
各列含义如下,大家根据自己情况灵活选择,本文使用YOLOv5n6来作为示例。
- Model :YOLOv5 的不同变体,后缀
n/s/m/l/x代表模型尺寸(从极小到极大),后缀6代表输入图像尺寸提升至 1280 像素(普通版本是 640 像素)。- Size (pixels):模型输入图像的分辨率,分辨率越高通常对大目标 / 细节目标的检测精度越好,但计算量会增加。
- mAPval 50-95:COCO 数据集的核心精度指标(平均精度均值,IoU 从 0.5 到 0.95 的均值),数值越高代表检测精度(定位 + 分类)越好。
- mAPval 50:IoU=0.5 时的平均精度,同样是精度指标(对定位要求相对宽松)。
- Speed :推理速度(单位:毫秒):
CPU b1:CPU 上单样本(batch size=1)的推理耗时;V100 b1:V100 显卡上单样本的推理耗时;V100 b32:V100 显卡上批量(batch size=32)的推理耗时;数值越小,模型推理速度越快。- Params (M):模型参数量(单位:百万),数值越大代表模型越复杂、占用内存越多。
- FLOPs@640 (B):输入 640 分辨率时的浮点运算量(单位:十亿),数值越高代表模型计算量越大,对硬件性能要求越高。
选择加载完成后进入到Pycharm中,在项目根目录下创建文件夹"weight"并将下载好的预训练模型文件导入。
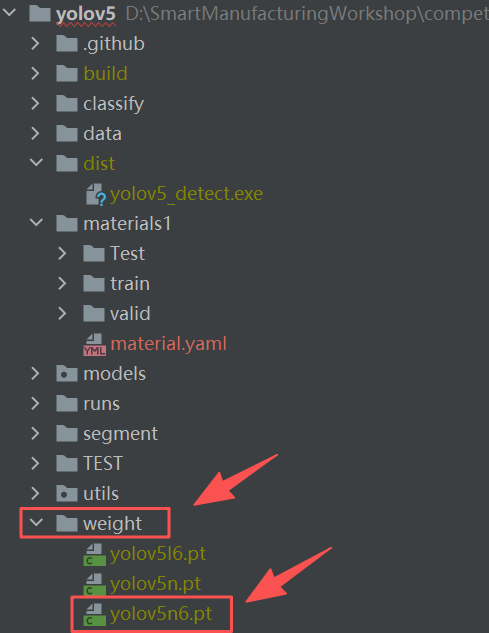
然后打开左下角终端,输入命令:
python
python .\detect.py --source .\data\images --weights .\weight\yolov5n6.pt出现下图所示表示预训练模型导入成功。

2.2、常见训练参数的调整:
| 参数类别 | 参数名称 | 主要作用 | 调整策略 |
|---|---|---|---|
| 学习率 | lr0 (初始学习率) |
控制模型权重更新的步长,影响收敛速度和稳定性。 | - 损失震荡 / 不收敛 :调小 (如 0.001)。- 收敛过慢 :适当调大 (如 0.02)。- 小数据集 :建议用较小值 (如 0.0005)。 |
lrf (最终学习率比例) |
学习率衰减的最终比例,配合余弦退火等策略使用。 | - 通常保持默认 0.01。- 若后期收敛困难,可适当调大 (如 0.1)。 |
|
| 硬件与输入 | batch-size |
每次送入模型训练的样本数量,影响训练稳定性和显存占用。 | - 显存充足 :设置为最大可能值 (如 16, 32)。- 显存不足 :调小 (如 8, 4) 或使用 --batch-size auto。- 批次过小 :搭配 --rect (矩形训练) 以提高稳定性。 |
imgsz (输入图像尺寸) |
模型输入图像的分辨率,影响小目标检测精度和计算量。 | - 小目标多 :调大 (如 1280),需配合 *6 系列模型。- 大目标多 / 显存不足 :调小 (如 416)。 |
|
| 训练过程 | epochs (训练轮次) |
模型遍历整个训练集的次数。 | - 小数据集 (≤1k) :调小 (如 100-200),防止过拟合。- 大数据集 (≥10k) :调大 (如 500),确保充分学习。 |
patience (早停阈值) |
当验证集性能连续多轮不提升时,提前终止训练。 | - 默认 100 ,对于小数据集可适当调小 (如 50),节省时间。 |
|
| 正则化 | weight_decay (权重衰减) |
L2 正则化,防止模型过拟合。 | - 过拟合 :调大 (如 0.001)。- 欠拟合 :调小 (如 0.0001)。 |
dropout |
随机丢弃部分神经元,防止过拟合。 | - 默认关闭 ,过拟合严重时,在模型 yaml 文件中手动添加 (比例 0.1-0.3)。 |
|
| 数据增强 | mosaic |
将四张图片拼接成一张,增加背景多样性和小目标数量。 | - 默认开启 (1.0) ,对小目标友好。- 小数据集 / 目标单一 :调小 (如 0.5) 或关闭 (0.0),避免信息混乱。 |
mixup |
将两张图片按比例混合,提升模型泛化能力。 | - 默认关闭 (0.0) 。- 需要提升泛化能力时 :开启 (如 0.1-0.2),可能轻微降低精度。 |
|
hsv_h/s/v (色彩增强) |
随机调整图像的色相、饱和度、亮度。 | - 数据集光照变化大 :调大增强幅度。- 数据集场景单一:调小或关闭,避免引入不必要的噪声。 | |
| 模型与模式 | --weights |
指定预训练模型路径,用于迁移学习。 | - 从零训练 :--weights ''。- 迁移学习 (推荐) :--weights yolov5s.pt 等官方预训练权重。 |
--freeze |
冻结模型 backbone 部分层的权重,只训练头部。 | - 小数据集迁移学习 :使用 --freeze 10,先冻结 backbone 训练,再解冻微调。 |
2.3、模型训练:
在完成一系列准备后我们就准备开始进行模型的训练了,打开终端,输入下面这条命令:
python
python train.py --batch-size 8 --epochs 50 --data materials1/material.yaml --weights weight/yolov5n6.pt --device 0代码含义是: 启动 YOLOv5 的训练程序 (train.py)。使用 yolov5n6.pt 作为预训练模型,在第 0 块 GPU (--device 0) 上开始训练。训练的数据集信息由 materials1/material.yaml 文件提供。在训练过程中,每次处理 8 张图片 (--batch-size 8),并将整个数据集重复训练 50 遍 (--epochs 50)。根据自身情况修改。

完成训练后,根据控制台提示找到对应的输出文件,一般都是在runs\train文件目录下。
2.4、模型检测:
完成模型训练后,我们接着使用终端来启动检测文件。输入:
python
python .\detect.py --source materials1/cash --weights runs/train/7/weights/best.pt命令含义为:启动 YOLOv5 的检测程序 (detect.py)。使用我第 7 次训练中得到的最佳模型 (best.pt),去分析 materials1/cash 文件夹里的所有图片,并把画好检测框的结果图片保存起来。
运行完毕后可以在runs\detect中找到检测结果。