2025年以来,我们正站在人工智能应用演进的一个关键节点上,从预测式AI(分析模式、进行分类)到生成式AI(创造文本、代码、图像),我们如今正迈向第三个阶段:AI Agent。
这并非简单的技术迭代,而是一次根本性的范式转变,第三个阶段 AI Agent 随着模型的不断进化,能自主可控长时间运行,可能2026才是AI普及的开始。
什么是 AI Agent
传统软件或者工作流的目的是为了用户能够简化和自动化工作流,而 AI Agent 则能够以高度的独立性代表用户执行为实现用户目标的一系列步骤。
首先集成了 LLM 但不用它们来控制工作流执行的应用程序(例如简单的聊天机器人、单轮对话LLM或情感分类器)不是称为智能体。
更具体地说,一个智能体拥有使其能够可靠、一致地代表用户行动的核心特征:
- 能利用LLM来管理工作流执行并做出决策,它能识别工作流何时完成,并能在需要时主动纠正其行为,如果失败,它可以停止执行并将控制权交还给用户。
- 能够访问各种工具以与外部系统交互(既能获取上下文,也能采取行动),并根据工作流的当前状态动态选择适当的工具,始终在明确定义的安全内运行。
是不是现在智能体很多,所有的工作都用智能体来解决?
智能体适合那些传统的、确定性的、基于规则的方法难以处理的工作流,所以对于能通过一些确定性编程或者流程就能解决的,其实不太需要智能体。
以支付欺诈分析为例,传统的规则引擎就像一个检查清单,根据预设标准标记交易,相比之下,LLM智能体更像一位经验丰富的调查员,评估上下文,考虑细微模式,即使在没有明确违反规则的情况下也能识别可疑活动,这种细致的推理能力正是智能体能够有效管理复杂、模糊情况的关键。
所以在评估智能体可以在哪些地方的确有价值,请优先考虑那些以前难以自动化、尤其是传统方法遇到阻力的工作流:
- 复杂决策:涉及细微判断、例外情况或上下文敏感决策的工作流。
- 难以维护的规则:由于规则集庞大且复杂而变得笨重、更新成本高昂或容易出错的系统。
- 重度依赖非结构化数据:涉及解读自然语言、从文档中提取含义或与用户进行对话式交互的场景。
AI Agent的构成
- 模型:为智能体的推理和决策提供动力的LLM,决定了智能体的下限。
- 工具:智能体可用于采取行动的外部函数或API。
- 指令:定义智能体行为的明确指导方针和安全策略。
样例代码:
python
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_react_agent
from langchain.tools import tool
from langchain_core.prompts import PromptTemplate
import os
# ============================================
# 第一部分:定义工具(Tools)
# 工具是Agent可以调用的外部函数,扩展了LLM的能力
# ============================================
@tool
def calculator(expression: str) -> str:
"""
计算数学表达式。
输入应该是一个有效的数学表达式,如 '2 + 2' 或 '3 * 4 + 5'。
"""
try:
# 安全地计算数学表达式
result = eval(expression, {"__builtins__": {}}, {})
returnf"计算结果: {expression} = {result}"
except Exception as e:
returnf"计算错误: {str(e)}"
@tool
def get_current_weather(city: str) -> str:
"""
获取指定城市的当前天气信息。
输入应该是城市名称,如 '北京' 或 '上海'。
"""
# 模拟天气数据(实际应用中应调用真实的天气API)
weather_data = {
"北京": "晴天,温度 5°C,湿度 30%",
"上海": "多云,温度 12°C,湿度 65%",
"广州": "小雨,温度 18°C,湿度 80%",
"深圳": "晴天,温度 20°C,湿度 70%",
}
return weather_data.get(city, f"抱歉,暂无{city}的天气信息")
@tool
def search_knowledge(query: str) -> str:
"""
搜索知识库获取相关信息。
输入应该是要搜索的问题或关键词。
"""
# 模拟知识库搜索(实际应用中可接入向量数据库或搜索引擎)
knowledge_base = {
"python": "Python是一种高级编程语言,以简洁易读著称,广泛应用于数据科学、Web开发和人工智能领域。",
"agent": "AI Agent(智能体)是能够感知环境、做出决策并采取行动的自主系统。它由模型、工具和指令三部分组成。",
"langchain": "LangChain是一个用于开发LLM应用的框架,提供了构建Agent、链式调用、记忆管理等功能。",
}
for key, value in knowledge_base.items():
if key in query.lower():
return value
returnf"未找到与'{query}'相关的信息"
# ============================================
# 第二部分:定义指令(Instructions)
# 通过Prompt模板定义Agent的行为方式和安全策略
# ============================================
# ReAct风格的Prompt模板
AGENT_PROMPT = """你是一个智能助手,能够帮助用户完成各种任务。
你可以使用以下工具:
{tools}
工具名称列表: {tool_names}
请按照以下格式回答问题:
Question: 用户的输入问题
Thought: 你需要思考应该做什么
Action: 要使用的工具名称,必须是[{tool_names}]中的一个
Action Input: 工具的输入参数
Observation: 工具返回的结果
... (这个Thought/Action/Action Input/Observation可以重复多次)
Thought: 我现在知道最终答案了
Final Answer: 对用户问题的最终回答
重要指导方针:
1. 仔细分析用户的问题,选择合适的工具
2. 如果问题可以直接回答,无需使用工具
3. 回答要准确、简洁、有帮助
4. 如果不确定,诚实地说明
开始!
Question: {input}
Thought: {agent_scratchpad}"""
# ============================================
# 第三部分:创建Agent
# 组合模型、工具和指令
# ============================================
def create_simple_agent():
"""创建一个简单的Agent"""
# 1. 初始化模型(Model)
# 这里使用OpenAI的GPT模型,你也可以替换为其他LLM
llm = ChatOpenAI(
model="gpt-3.5-turbo", # 或 "gpt-4"
temperature=0, # 设为0使输出更确定性
# api_key=os.getenv("OPENAI_API_KEY"), # 从环境变量获取
)
# 2. 准备工具列表(Tools)
tools = [calculator, get_current_weather, search_knowledge]
# 3. 创建Prompt模板(Instructions)
prompt = PromptTemplate.from_template(AGENT_PROMPT)
# 4. 创建ReAct Agent
agent = create_react_agent(
llm=llm,
tools=tools,
prompt=prompt
)
# 5. 创建Agent执行器
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True, # 打印详细的执行过程
handle_parsing_errors=True, # 处理解析错误
max_iterations=5, # 最大迭代次数,防止无限循环
)
return agent_executor
# ============================================
# 第四部分:运行示例
# ============================================
def main():
"""运行Agent示例"""
print("=" * 60)
print("LangChain Agent 示例")
print("=" * 60)
# 创建Agent
agent = create_simple_agent()
# 测试用例
test_questions = [
"计算 (15 + 25) * 3 等于多少?",
"北京今天天气怎么样?",
"什么是LangChain?",
"帮我计算一下,如果北京温度是5度,上海是12度,它们的平均温度是多少?",
]
for i, question in enumerate(test_questions, 1):
print(f"\n{'='*60}")
print(f"测试 {i}: {question}")
print("=" * 60)
try:
result = agent.invoke({"input": question})
print(f"\n最终答案: {result['output']}")
except Exception as e:
print(f"执行出错: {str(e)}")
if __name__ == "__main__":
main()选择模型
不同的模型在任务复杂性、延迟和成本方面有不同的优势和权衡,并非每个任务都需要最聪明的模型------一个简单的检索或意图分类任务可以由更小、更快的模型处理,而困难任务则可能需要能力更强的推理模型。
选择模型有效的方法是:使用能力最强的模型为每个任务构建您的智能体原型,以建立性能基线,然后,尝试换用更小的模型,看看它们是否仍能达到可接受的结果。 这样,您就不会过早地限制智能体的能力,并且可以诊断出更小的模型在何处成功或失败,总之,选择模型的原则很简单:
- 建立评估体系以确定性能基线。
- 专注于使用可用的最佳模型达到您的准确率目标。
- 在可能的情况下,用更小的模型替换更大的模型,以优化成本和延迟。
定义工具
工具通过使用底层应用程序或系统的API来扩展智能体的能力,对于没有提供API的历史系统,智能体可以依赖计算机使用模型,通过Web和应用程序UI直接与这些应用程序和系统交互------就像人类一样进行黑盒测试。
每个工具都应具有标准化的定义,从而实现工具与智能体之间灵活的多对多关系,文档完善、经过充分测试且可重用的工具可以提高可发现性,简化版本管理,并防止重复定义,广义上说,智能体需要三种类型的工具。
- 类型描述示例数据工具:使智能体能够检索执行工作流所需的上下文和信息,比如查询交易数据库或CRM等系统,读取PDF文档,或搜索网络。
- 行动工具:使智能体能够与系统交互以采取行动,例如向数据库添加新信息、更新记录或发送消息,发送电子邮件和短信,更新CRM记录,将客户服务工单转交给人工。
- 编排工具:智能体本身可以作为其他智能体的工具,作为多智能体系统中单个
sub agent。
配置Prompt
高质量的Prompt对于任何LLM驱动的应用程序都至关重要,对智能体尤其关键,清晰的指令可以减少歧义,提高智能体的决策质量,从而实现更顺畅的工作流执行和更少的错误。
具体做法可以参考如下:
- 利用现有文档:在创建流程时,使用现有的操作程序、支持脚本或策略文档来创建,例如
Claude提出的Skill,其他模型比较通用的AGENTS.md等。 - 提示智能体分解任务:从密集的资源中提供更小、更清晰的步骤,有助于最小化歧义,并帮助模型更好地遵循指令。
- 定义清晰的动作:确保流程中的每一步都对应一个特定的动作或输出,例如,一个步骤可能指示智能体向用户询问订单号,或调用API来检索账户详情,明确说明动作(甚至面向用户消息的措辞)可以减少解释错误的空间。
- 控制边界处理:现实世界的交互经常会产生决策点,例如当用户提供不完整信息或提出意外问题时如何继续,一个健壮的流程应预见常见的变体,并包含如何处理它们的指令,例如使用条件步骤或分支(如果缺少必要信息,则执行替代步骤)。
从 MCP 到 A2A
AI Agent 为了和多个其他系统交互,衍生了两种系统交互的协议,MCP 和 A2A。
MCP
MCP 在之前的文章已经讲过了(mp.weixin.qq.com/s/qHfSbSjox... LLM 提供上下文的方式,MCP 提供了一种将模型连接到资源、提示和工具的标准化方式。
样例代码如下:
python
import logging
import os
import httpx
from fastmcp import FastMCP
logger = logging.getLogger(__name__)
logging.basicConfig(format="[%(levelname)s]: %(message)s", level=logging.INFO)
mcp = FastMCP("Currency MCP Server 💵")
@mcp.tool()
def get_exchange_rate(
currency_from: str = 'USD',
currency_to: str = 'EUR',
currency_date: str = 'latest',
):
"""Use this to get current exchange rate.
Args:
currency_from: The currency to convert from (e.g., "USD").
currency_to: The currency to convert to (e.g., "EUR").
currency_date: The date for the exchange rate or "latest". Defaults to "latest".
Returns:
A dictionary containing the exchange rate data, or an error message if the request fails.
"""
logger.info(f"--- 🛠️ Tool: get_exchange_rate called for converting {currency_from} to {currency_to} ---")
try:
response = httpx.get(
f'https://api.frankfurter.app/{currency_date}',
params={'from': currency_from, 'to': currency_to},
)
response.raise_for_status()
data = response.json()
if'rates'notin data:
return {'error': 'Invalid API response format.'}
logger.info(f'✅ API response: {data}')
return data
except httpx.HTTPError as e:
return {'error': f'API request failed: {e}'}
except ValueError:
return {'error': 'Invalid JSON response from API.'}
if __name__ == "__main__":
logger.info(f"🚀 MCP server started on port {os.getenv('PORT', 8080)}")
asyncio.run(
mcp.run_async(
transport="http",
host="0.0.0.0",
port=os.getenv("PORT", 8080),
)
)以上代码是汇率的 MCP Server,通过 MCP Client 可以获取汇率数据。
Agent2Agent (A2A)
Agent2Agent (A2A) 协议是一种开放标准,旨在让 AI 智能体之间实现无缝通信和协作,正如 MCP 提供了一种标准化的方式来让 LLM 访问数据和工具一样,A2A 也提供了一种标准化的方式来让智能体与其他智能体对话!
在一个智能体由不同供应商使用各种框架构建的世界中,A2A 提供了一种通用语言,打破了孤岛并促进了互操作性。
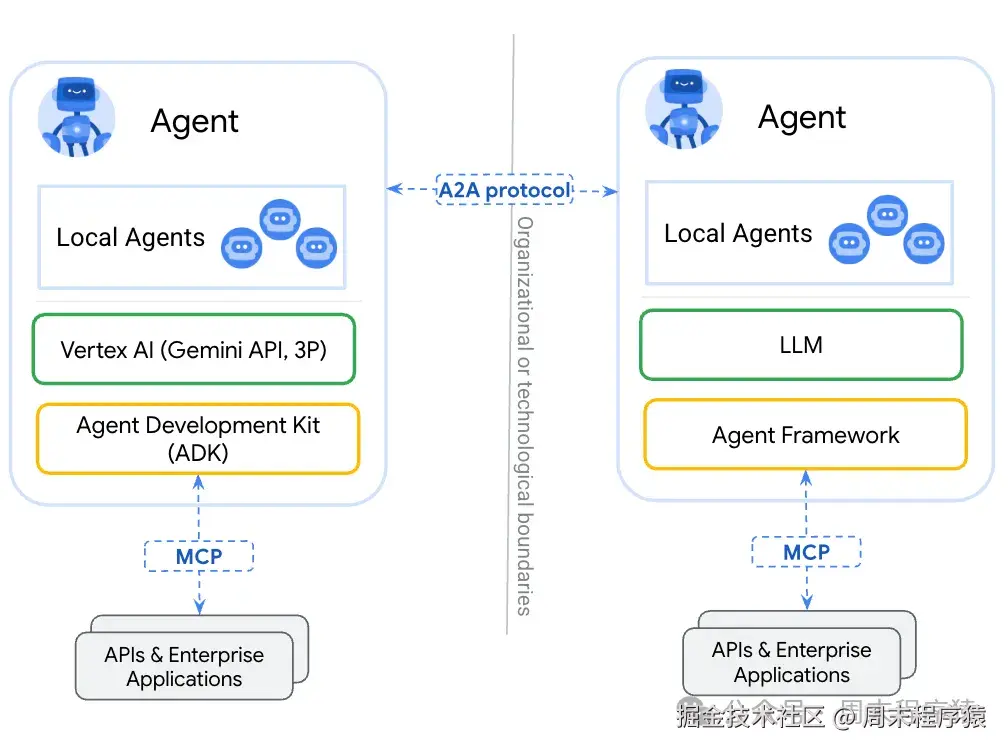
A2A的工作原理:
- 发现:使用标准化的
Agent Card查找其他智能体技能AgentSkill和功能AgentCapabilities; - 协议:安全的交换消息和数据;
- 协作:委派任务给到相应技能的
Agent并协调行动;
样例代码如下:
python
import logging
import os
import click
from a2a.server.apps import A2AStarletteApplication
from a2a.server.request_handlers import DefaultRequestHandler
from a2a.server.tasks import InMemoryTaskStore
from a2a.types import (
AgentCapabilities,
AgentCard,
AgentSkill,
)
from agent import ImageGenerationAgent
from agent_executor import ImageGenerationAgentExecutor
from dotenv import load_dotenv
load_dotenv()
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class MissingAPIKeyError(Exception):
"""Exception for missing API key."""
@click.command()
@click.option('--host', 'host', default='localhost')
@click.option('--port', 'port', default=10001)
def main(host, port):
"""Entry point for the A2A + CrewAI Image generation sample."""
try:
capabilities = AgentCapabilities(streaming=False)
skill = AgentSkill(
id='image_generator',
name='Image Generator',
description=(
'Generate stunning, high-quality images on demand and leverage'
' powerful editing capabilities to modify, enhance, or completely'
' transform visuals.'
),
tags=['generate image', 'edit image'],
examples=['Generate a photorealistic image of raspberry lemonade'],
)
agent_host_url = (
os.getenv('HOST_OVERRIDE')
if os.getenv('HOST_OVERRIDE')
elsef'http://{host}:{port}/'
)
agent_card = AgentCard(
name='Image Generator Agent',
description=(
'Generate stunning, high-quality images on demand and leverage'
' powerful editing capabilities to modify, enhance, or completely'
' transform visuals.'
),
url=agent_host_url,
version='1.0.0',
default_input_modes=ImageGenerationAgent.SUPPORTED_CONTENT_TYPES,
default_output_modes=ImageGenerationAgent.SUPPORTED_CONTENT_TYPES,
capabilities=capabilities,
skills=[skill],
)
request_handler = DefaultRequestHandler(
agent_executor=ImageGenerationAgentExecutor(),
task_store=InMemoryTaskStore(),
)
server = A2AStarletteApplication(
agent_card=agent_card, http_handler=request_handler
)
import uvicorn
uvicorn.run(server.build(), host=host, port=port)
except MissingAPIKeyError as e:
logger.error(f'Error: {e}')
exit(1)
except Exception as e:
logger.error(f'An error occurred during server startup: {e}')
exit(1)
if __name__ == '__main__':
main()从单智能体到多智能体
单智能体
单智能体的智能大部分场景下依赖基座模型,在处理明确问题时较为高效,对于约束性任务时较为准确,并且可以进行回测,但面对复杂、多领域任务时,其能力往往受限。
样例代码如下:
python
import asyncio
import nest_asyncio
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.tools import tool as langchain_tool
from langchain.agents import create_tool_calling_agent, AgentExecutor
try:
# 初始化具备工具调用能力的模型
llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash", temperature=0)
print(f"✅ 语言模型已初始化:{llm.model}")
except Exception as e:
print(f"🛑 初始化语言模型出错:{e}")
llm = None
# --- 定义工具 ---
@langchain_tool
def search_information(query: str) -> str:
print(f"\n--- 🛠️ 工具调用:search_information, 查询:'{query}' ---")
# 用预设结果模拟搜索工具
simulated_results = {
"default": f"模拟搜索 '{query}':未找到具体信息,但该主题很有趣。"
}
result = simulated_results.get(query.lower(), simulated_results["default"])
print(f"--- 工具结果:{result} ---")
return result
tools = [search_information]
# --- 创建工具调用 Agent ---
if llm:
agent_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个乐于助人的助手。"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
])
agent = create_tool_calling_agent(llm, tools, agent_prompt)
agent_executor = AgentExecutor(agent=agent, verbose=True, tools=tools)
asyncdef run_agent_with_tool(query: str):
"""用 Agent 执行查询并打印最终回复。"""
print(f"\n--- 🏃 Agent 运行查询:'{query}' ---")
try:
response = await agent_executor.ainvoke({"input": query})
print("\n--- ✅ Agent 最终回复 ---")
print(response["output"])
except Exception as e:
print(f"\n🛑 Agent 执行出错:{e}")
asyncdef main():
"""并发运行多个 Agent 查询。"""
tasks = [
run_agent_with_tool("今天XXX天气怎么样?"),
]
await asyncio.gather(*tasks)
nest_asyncio.apply()
asyncio.run(main())多智能体
多智能体协作模式通过将系统结构化为多个独立且专用的智能体进行协作,解决了单智能体的局限,该模式基于任务分解原则,将高层目标拆分为若干子问题,并分配给具备相应工具、数据访问或推理能力的智能体。
其中多智能体架构的运作方式:用户查询通过主智能体,主智能体创建专门的子智能体来并行搜索和处理不同信息,样例如下执行流程。
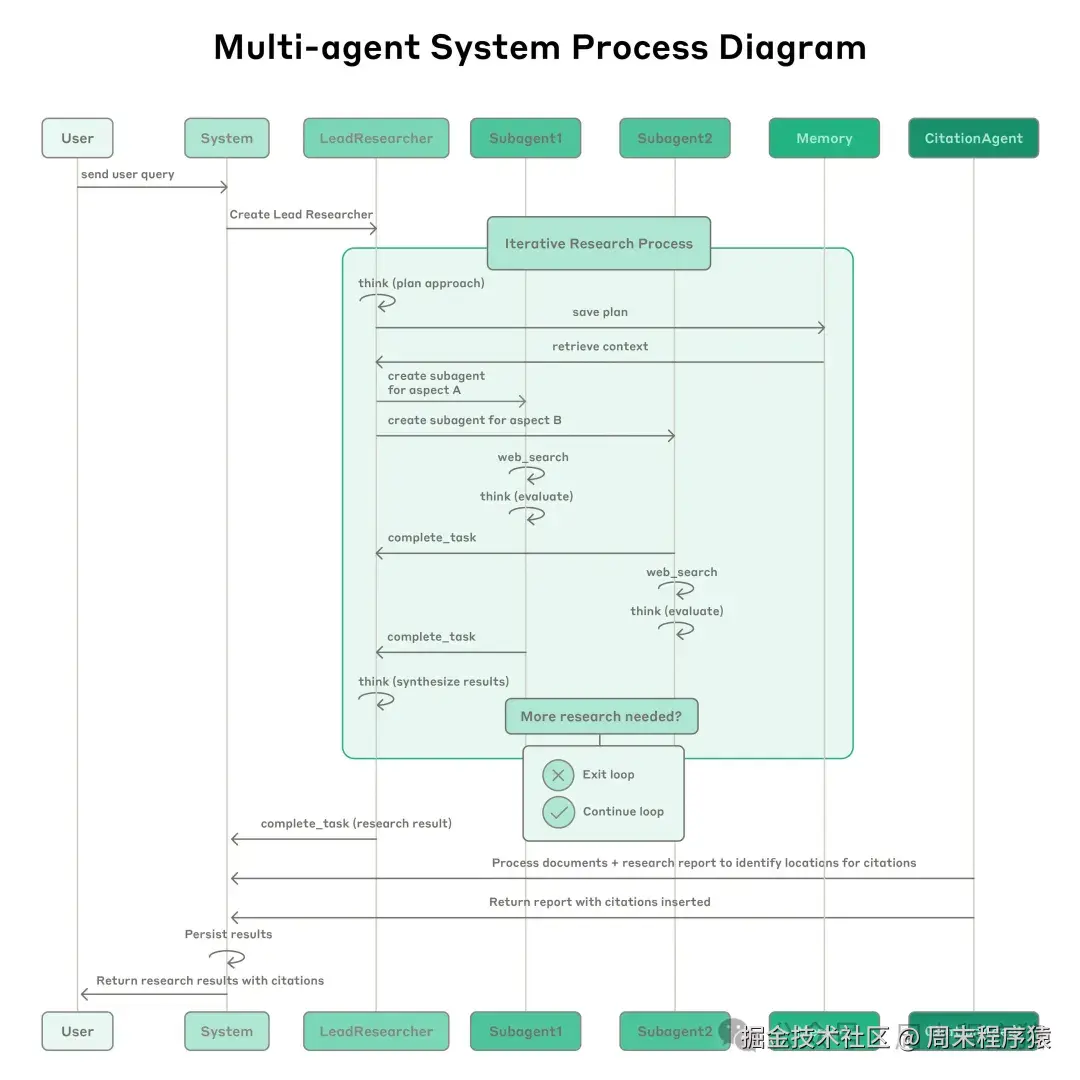
- 当用户提交查询时,系统会创建一个主智能体,该智能体进入迭代任务流程。
- 主智能体首先会思考任务方法,并将计划保存到内存中以持久化上下文信息,因为如果上下文窗口超过 20 万个标记,LLM会信息遗忘或者截断,所以保留计划至关重要。
- 然后,它会创建专门的子智能体,每个子智能体负责特定的任务。
- 每个子智能体独立执行网络搜索,使用交错思维评估工具结果,并将结果返回给主智能体。
- 主智能体综合这些结果,并决定是否需要进行更多任务 ------ 如果需要,它可以创建更多子智能体或优化其策略。
- 一旦收集到足够的信息,系统就会退出循环,并将所有结果传递给引文智能体。
- 引文智能体处理文档和报告,以确定具体的引文位置,最终的结果(包括引用)将返回给用户。
样例代码如下:
python
import asyncio
from typing import List, Dict, Any
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_tool_calling_agent
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.tools import tool as langchain_tool
from langchain_core.messages import HumanMessage, SystemMessage
# ============================================
# 多智能体系统示例
# 架构:主智能体 + 多个专用子智能体
# ============================================
# --- 初始化模型 ---
llm = ChatOpenAI(model="gpt-5", temperature=0)
# ============================================
# 第一部分:定义子智能体的工具
# ============================================
@langchain_tool
def search_web(query: str) -> str:
"""搜索网络获取最新信息。"""
print(f"🔍 [网络搜索] 查询: {query}")
# 模拟网络搜索结果
returnf"网络搜索结果: 关于'{query}'的最新信息..."
@langchain_tool
def search_database(query: str) -> str:
"""搜索内部数据库获取结构化数据。"""
print(f"🗄️ [数据库搜索] 查询: {query}")
# 模拟数据库查询
returnf"数据库查询结果: '{query}'相关记录3条..."
@langchain_tool
def analyze_data(data: str) -> str:
"""分析数据并生成洞察。"""
print(f"📊 [数据分析] 分析: {data}")
returnf"分析结论: 基于'{data}'的数据分析完成..."
@langchain_tool
def generate_report(content: str) -> str:
"""根据内容生成报告。"""
print(f"📝 [报告生成] 内容: {content}")
returnf"报告已生成: 包含'{content}'的详细报告..."
# ============================================
# 第二部分:定义子智能体类
# ============================================
class SubAgent:
"""子智能体基类"""
def __init__(self, name: str, role: str, tools: list):
self.name = name
self.role = role
self.tools = tools
self.agent_executor = self._create_executor()
def _create_executor(self) -> AgentExecutor:
prompt = ChatPromptTemplate.from_messages([
("system", f"你是{self.name},职责是{self.role}。专注完成分配的任务,返回简洁结果。"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
])
agent = create_tool_calling_agent(llm, self.tools, prompt)
return AgentExecutor(agent=agent, tools=self.tools, verbose=True)
asyncdef execute(self, task: str) -> Dict[str, Any]:
"""异步执行任务"""
print(f"\n{'='*50}")
print(f"🤖 子智能体 [{self.name}] 开始执行任务: {task}")
print(f"{'='*50}")
result = await self.agent_executor.ainvoke({"input": task})
return {"agent": self.name, "task": task, "result": result["output"]}
# ============================================
# 第三部分:创建主智能体(协调者)
# ============================================
class MasterAgent:
"""主智能体 - 负责任务分解和子智能体协调"""
def __init__(self):
self.sub_agents = self._create_sub_agents()
self.memory = [] # 用于持久化计划和中间结果
def _create_sub_agents(self) -> Dict[str, SubAgent]:
"""创建专用子智能体"""
return {
"researcher": SubAgent(
name="研究员智能体",
role="负责网络搜索和信息收集",
tools=[search_web]
),
"data_analyst": SubAgent(
name="数据分析智能体",
role="负责数据库查询和数据分析",
tools=[search_database, analyze_data]
),
"reporter": SubAgent(
name="报告智能体",
role="负责整合信息并生成最终报告",
tools=[generate_report]
),
}
asyncdef _decompose_task(self, query: str) -> List[Dict[str, str]]:
"""使用LLM分解任务"""
print(f"\n🧠 主智能体正在分析任务: {query}")
# 使用LLM进行任务分解
response = await llm.ainvoke([
SystemMessage(content="""你是一个任务分解专家。将用户查询分解为子任务。
返回格式(每行一个): agent_type|task_description
可用的agent_type: researcher, data_analyst, reporter"""),
HumanMessage(content=f"分解任务: {query}")
])
# 解析任务分解结果
tasks = []
for line in response.content.strip().split("\n"):
if"|"in line:
agent_type, task_desc = line.split("|", 1)
agent_type = agent_type.strip().lower()
if agent_type in self.sub_agents:
tasks.append({"agent": agent_type, "task": task_desc.strip()})
# 默认任务流程(如果LLM分解失败)
ifnot tasks:
tasks = [
{"agent": "researcher", "task": f"搜索关于'{query}'的信息"},
{"agent": "data_analyst", "task": f"分析'{query}'相关数据"},
{"agent": "reporter", "task": "整合以上结果生成报告"},
]
# 保存计划到内存
self.memory.append({"type": "plan", "tasks": tasks})
print(f"📋 任务分解完成,共{len(tasks)}个子任务")
return tasks
asyncdef _execute_parallel_tasks(self, tasks: List[Dict]) -> List[Dict]:
"""并行执行子任务"""
print(f"\n🚀 开始并行执行 {len(tasks)} 个子任务...")
# 创建并行任务
coroutines = []
for task_info in tasks:
agent = self.sub_agents[task_info["agent"]]
coroutines.append(agent.execute(task_info["task"]))
# 并行执行所有子智能体任务
results = await asyncio.gather(*coroutines, return_exceptions=True)
# 处理结果
valid_results = []
for r in results:
if isinstance(r, Exception):
print(f"⚠️ 子任务执行失败: {r}")
else:
valid_results.append(r)
self.memory.append({"type": "result", "data": r})
return valid_results
asyncdef _synthesize_results(self, results: List[Dict]) -> str:
"""综合所有子智能体结果"""
print(f"\n🔄 主智能体正在综合 {len(results)} 个结果...")
# 构建综合提示
results_text = "\n".join([
f"- {r['agent']}: {r['result']}"for r in results
])
response = await llm.ainvoke([
SystemMessage(content="你是一个信息综合专家,负责整合多个智能体的执行结果,生成完整、连贯的最终回答。"),
HumanMessage(content=f"请综合以下各智能体的执行结果:\n{results_text}")
])
return response.content
asyncdef run(self, query: str) -> str:
"""运行多智能体系统"""
print(f"\n{'='*60}")
print(f"🎯 多智能体系统启动")
print(f"📝 用户查询: {query}")
print(f"{'='*60}")
# 1. 任务分解
tasks = await self._decompose_task(query)
# 2. 并行执行子任务
results = await self._execute_parallel_tasks(tasks)
# 3. 综合结果
final_answer = await self._synthesize_results(results)
print(f"\n{'='*60}")
print(f"✅ 多智能体系统执行完成")
print(f"{'='*60}")
return final_answer
# ============================================
# 第四部分:运行示例
# ============================================
asyncdef main():
"""运行多智能体系统示例"""
master = MasterAgent()
# 测试查询
query = "分析2025年人工智能行业的发展趋势,并给出投资建议"
result = await master.run(query)
print(f"\n{'='*60}")
print("📊 最终报告")
print(f"{'='*60}")
print(result)
if __name__ == "__main__":
asyncio.run(main())可靠性和工程挑战
在传统软件中,一个错误可能会导致功能失效、性能下降或系统宕机,而在智能体系统中,微小的变化也会引发巨大的行为改变,这使得为需要在长时间运行的进程中维护状态的复杂智能体编写代码变得异常困难,那我们应该怎么做?
- 智能体是有状态的,错误会不断累积,我们需要做好容错和沙盒环境。
智能体可以长时间运行,并在多次工具调用中保持状态,这意味着我们需要持久地执行代码,并在执行过程中处理错误,如果没有有效的缓解措施,即使是轻微的系统故障也可能对智能体造成灾难性后果,当错误发生时,我们不能简单地从头开始:重启成本高昂,因此我们需要构建可以从错误发生时智能体所在位置恢复运行的系统。 - 构建完整的可观测系统,如果某个智能体不符合预期,应该分析原因。
智能体会做出动态决策,即使提示信息完全相同,每次运行的结果也并不确定,这使得调试更加困难,智能体使用了错误的搜索查询?选择了不合适的数据源?还是遇到了工具故障?添加完整的生产环境跟踪功能后,我们能够诊断智能体故障的原因并系统地修复问题,除了标准的可观测性之外,我们还监控智能体的决策模式和交互结构,这种高层次的可观测性帮助我们诊断根本原因、发现异常行为并修复常见故障。 - 智能体同步执行会造成瓶颈,尽可能使用并行处理。
主智能体同步执行子智能体,等待每组子智能体完成任务后再继续执行下一个,这简化了协调,但也造成了智能体间信息流的瓶颈,例如,主智能体无法控制子代智能体,子智能体之间也无法协调,整个系统可能会因为等待单个子智能体完成搜索而被阻塞,异步执行可以实现更高的并行性:智能体可以并发工作,并在需要时创建新的子智能体,当然这种异步性也带来了结果协调、状态一致性和错误在子智能体间传播方面的挑战。 - 智能体的可测试性在线上运行十分重要。
传统的软件对一些子功能我们通常会进行单元测试,这个功能点同样适用于构建的智能体,特别是对于那些希望输入和输出需要保持一致性的智能体系统,那该如何实现?首先智能体功能测试不应该依赖单个大模型;其次将功能测试用例拆分输入和预期输出,对于一些强校验的功能,智能体调用子智能体和系统API的所有的输出应该保持预期测试执行流程一致,才算通过测试用例;最后大模型多次对相同的输入不一定获得相同的结果,所以测试用例应该是多次运行,通过率应该通过次数/执行次数的方式来统计。