目录
[1.1 函数的定义和调用](#1.1 函数的定义和调用)
[1.2 拆包和装包](#1.2 拆包和装包)
[1.3 函数变量的作用域](#1.3 函数变量的作用域)
[2.1 装饰器(无参数)](#2.1 装饰器(无参数))
[2.2 装饰器(带参数)](#2.2 装饰器(带参数))
[2.3 装饰器链(多个装饰器叠加)](#2.3 装饰器链(多个装饰器叠加))
[2.4 装饰器的缺点](#2.4 装饰器的缺点)
[3.1 迭代器](#3.1 迭代器)
[3.2 生成器](#3.2 生成器)
[4.1 map()](#4.1 map())
[4.2 filter()](#4.2 filter())
[4.3 sorted()](#4.3 sorted())
[4.4 自定义高阶函数](#4.4 自定义高阶函数)
[5.1 类的基本语法](#5.1 类的基本语法)
[5.2 类的三大特性](#5.2 类的三大特性)
[5.2.1 继承(复用父类代码)](#5.2.1 继承(复用父类代码))
[5.2.2 多态(同一方法不同实现)](#5.2.2 多态(同一方法不同实现))
[5.2.3 封装(隐藏内部细节)](#5.2.3 封装(隐藏内部细节))
[5.3 类的高级用法](#5.3 类的高级用法)
[8.1 builtins模块](#8.1 builtins模块)
[8.2 os模块](#8.2 os模块)
[8.3 时间日期模块](#8.3 时间日期模块)
[8.3.1 datetime 模块](#8.3.1 datetime 模块)
[8.3.2 time 模块](#8.3.2 time 模块)
[8.3.3 calendar 模块](#8.3.3 calendar 模块)
[8.4 random模块](#8.4 random模块)
[8.5 math模块](#8.5 math模块)
[8.6 hashlib模块](#8.6 hashlib模块)
[8.7 logging模块](#8.7 logging模块)
[8.8 文件读取模块](#8.8 文件读取模块)
[8.9 json库](#8.9 json库)
一、函数
1.1 函数的定义和调用
python
def 函数名([形参,...]):
函数体
函数调用:
函数名([实参])-
定义函数时形式参数的个数和调用时实参的个数一致
-
可变类型参数传递的是地址,不可变类型参数传递的是值
-
如果传入函数内部的是不可变类型的参数,那么函数内部对参数的操作不会影响函数外部的变量,如果传入函数内部的是可变类型的参数,即传入的参数是地址,那么函数内部对参数的操作会对函数外部的变量造成影响.
python
num=10
list1=[]
def fun(num,li):
num+=1
li.append(10)
li.append(11)
print(num)
print(li)
fun(num,list1)
print(num)
print(list1)参数类型
-
普通参数:必填参数(参数列表开头)
-
默认值参数:def func(a,b=10)
-
关键字参数:调用的时候通过关键字的方式指明
-
可变参数
python
# 默认值参数
def func1(a=None):
print(a)
func1()
# a是关键字参数
def func2(b,a=10):
print(a,b)
func2(b=9)
# 可变参数
def func3(*args,**kwargs):
print(args,kwargs)
func3(1,2,3,a=5,b=6)
# 例如args = (1,2,3)
# 例如kwargs = ("a":"5","b":"6")
*args:接收任意数量的位置参数(非键值对),参数会被打包成一个元组
**kwargs:接收任意数量的关键字参数(键值对),参数会被打包成一个字典
1.2 拆包和装包
一般情况下,拆包的顺序应该是:必传参数,关键字参数,可变参数,而且关键字参数一般都会在末尾,必传参数一般都会在开头
python
# 拆包
list1=[6,8,2]
n1,n2,n3=list1 # 都会先做拆包,然后做后面变量的赋值
print(n1,n2,n3)
# 装包
list2=[1,2,3,4,5]
x,*y,z=list2 # 一个变量名前面加一个*号表示多值参数,
print(x,y,z)1.3 函数变量的作用域
-
局部变量local
-
嵌套变量弄local
-
全局变量glocal
-
内置模块builtins中找
-
没有就报错
python
a=1
b=2
c=3
def func1():
a=10
b=20
c=30
def func2():
c=300 # 局部变量
print(c)
nonlocal a # 嵌套变量
print(a)
global b # 全局变量
print(b)
return func2
f=func1()
print(f())二、装饰器
装饰器(Decorator)是 Python 中一种高阶函数,本质是 "函数包装器"------ 它可以在不修改原函数代码、不改变原函数调用方式的前提下,为函数添加额外功能(如日志记录、性能统计、权限校验、缓存等)。
装饰器的核心依赖:
- 函数是一等对象(可作为参数传递、作为返回值、赋值给变量);
- 闭包(嵌套函数可访问外层函数的变量)。
2.1 装饰器(无参数)
python
# 定义装饰器函数(接收被装饰的函数作为参数)
def log_decorator(func): # 函数的地址传给func
# 闭包:嵌套函数wrapper接收原函数的参数,并调用原函数
def wrapper(*args, **kwargs):
print(*args)
# 新增功能:执行原函数前打印日志
print(f"[日志] 函数 {func.__name__} 开始执行")
# 调用原函数,获取返回值
result = func(*args, **kwargs)
# 新增功能:执行原函数后打印日志
print(f"[日志] 函数 {func.__name__} 执行完成,返回值:{result}")
# 返回原函数的返回值
return result
# 返回嵌套的wrapper函数(替代原函数)
return wrapper
# 使用装饰器(@+装饰器名,放在函数定义上方)
@log_decorator
def add(a, b): # 加
return a + b
@log_decorator
def sub(a, b): # 减
return a - b
@log_decorator
def mul(a, b): # 乘
return a * b
@log_decorator
def div(a, b): # 除
return a / b
# 调用被装饰后的函数(调用方式不变)
add(4, 2)
sub(4, 2)
mul(4, 2)
div(4, 2)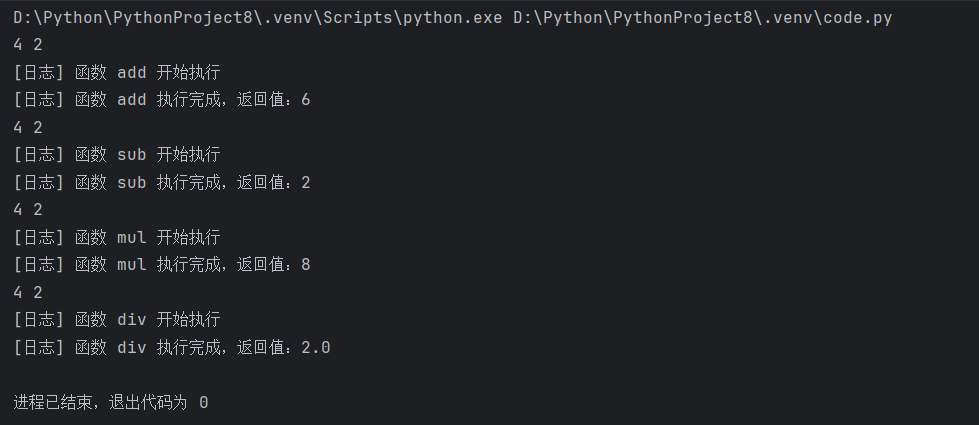
2.2 装饰器(带参数)
python
# 带参数的装饰器:外层接收装饰器参数,中层接收被装饰函数,内层是执行逻辑
def log_decorator(level="INFO"):
def decorator(func):
def wrapper(*args, **kwargs):
print(f"[{level}] 函数 {func.__name__} 执行")
result = func(*args, **kwargs)
return result
return wrapper
return decorator
# 使用装饰器时传入参数
@log_decorator(level="DEBUG")
def multiply(a, b):
return a * b
multiply(4, 5)
# 输出:[DEBUG] 函数 multiply 执行2.3 装饰器链(多个装饰器叠加)
一个函数可同时被多个装饰器修饰,执行顺序是从下到上(靠近函数的先执行):
python
def decorator1(func):
def wrapper(*args, **kwargs):
print("装饰器1 前置逻辑")
result = func(*args, **kwargs)
print("装饰器1 后置逻辑")
return result
return wrapper
def decorator2(func):
def wrapper(*args, **kwargs):
print("装饰器2 前置逻辑")
result = func(*args, **kwargs)
print("装饰器2 后置逻辑")
return result
return wrapper
@decorator1
@decorator2
def say_hello():
print("Hello World")
say_hello()
# 输出:
# 装饰器1 前置逻辑
# 装饰器2 前置逻辑
# Hello World
# 装饰器2 后置逻辑
# 装饰器1 后置逻辑装饰器就是不改变原函数的内容,通过装饰为原函数增加功能,说白了,就是传递函数的引用,首先执行距离被装饰函数最近的装饰器,完了之后返回函数引用,然后将函数引用传递给上一层的装饰器,一次类推.就是通过引用,不断的将函数包裹起来,然后一层一层的拆开.
2.4 装饰器的缺点
装饰器会替换原函数的 name、doc等元信息,需用functools.wraps 修复:
python
import functools
def log_decorator(func):
# 保留原函数的元信息(必须加在wrapper上)
def wrapper(*args, **kwargs):
print(f"执行函数:{func.__name__}")
return func(*args, **kwargs)
return wrapper
@log_decorator
def add(a, b):
"""两数相加"""
return a + b
print(add.__name__) # 输出:wrapper
print(add.__doc__) # 输出:两数相加
def log_decorator(func):
# 保留原函数的元信息(必须加在wrapper上)
@functools.wraps(func)
def wrapper(*args, **kwargs):
print(f"执行函数:{func.__name__}")
return func(*args, **kwargs)
return wrapper
@log_decorator
def add(a, b):
"""两数相加"""
return a + b
print(add.__name__) # 输出:add
print(add.__doc__) # 输出:两数相加因为加上装饰器之后文档的名字变了,文档注释也变了,为了消除装饰器的这种副作用.我们在装饰器内部函数的前面加上@functools.wraps(func)即可
三、迭代器和生成器
在 Python 中,迭代器(Iterator)和 生成器(Generator)是处理可迭代对象 的核心工具,主要用于按需生成数据(节省内存),二者密切相关但定位不同:
3.1 迭代器
迭代器是实现了迭代协议(__iter__() 和 __next__() 方法) 的对象,用于逐个返回数据,是 Python 中 "可迭代对象"(如列表、字典)的底层遍历机制。
迭代器的核心特点
-
惰性计算 :仅在调用next() 时才生成下一个数据,不提前占用内存;
-
一次性 :遍历完所有数据后,再次调用 next() 会抛出 StopIteration 异常;
-
统一接口 :所有可迭代对象(如 list/dict)都可通过 iter() 转为迭代器。
方式 1:通过 iter() 转换可迭代对象
Python 中可迭代对象 (如 list/str/range)都可通过 iter() 转为迭代器:
python
# 列表是可迭代对象,通过iter()转为迭代器
nums = [1, 2, 3]
it = iter(nums)
# 用next()逐个获取数据
print(next(it)) # 输出1
print(next(it)) # 输出2
print(next(it)) # 输出3
print(next(it)) # 抛出StopIteration(无数据了)方式 2:自定义迭代器(实现__iter__()和__next__())
通过类实现迭代协议,自定义迭代逻辑:
python
class MyIterator:
def __init__(self, start, end):
self.current = start
self.end = end
# 迭代器必须实现__iter__(),返回自身
def __iter__(self):
return self
# 实现__next__(),返回下一个数据
def __next__(self):
if self.current > self.end:
raise StopIteration # 遍历结束,抛出异常
value = self.current
self.current += 2
return value
# 使用自定义迭代器
it = MyIterator(1, 6)
for num in it:
print(num) # 输出1、3、5(for循环自动处理StopIteration)3.2 生成器
生成器是特殊的迭代器 ,无需手动实现**iter()和 next(),而是通过函数 +yield关键字** 或生成器表达式创建,是 Python 中 "惰性生成数据" 的常用方式。
1. 生成器的核心特点
- 自动实现迭代协议 :生成器本质是迭代器,自带 iter() 和**next()**;
- 更简洁 :用 yield 替代手动维护状态,代码更短;
- 内存高效:仅在需要时生成数据,适合处理大量 / 无限数据(如大数据流)。
方式 1:生成器函数(yield关键字)
在函数中用 yield 替代 return,函数执行到 yield 时会暂停并返回数据 ,下次调用 next() 时从暂停处继续执行:
python
def num_generator(start, end):
current = start
while current <= end:
yield current # 暂停并返回current,下次从这里继续
current += 1
# 创建生成器(调用函数不会执行,仅返回生成器对象)
gen = num_generator(1, 3)
# 遍历生成器(和迭代器用法一致)
for num in gen:
print(num) # 输出1、2、3执行流程:
-
调用
num_generator(1,3)→ 返回生成器对象(不执行函数体); -
第一次
next(gen)→ 执行到yield 1,返回 1,暂停; -
第二次
next(gen)→ 从current +=1继续,执行到yield 2,返回 2,暂停; -
第三次
next(gen)→ 继续执行到yield 3,返回 3,暂停; -
第四次
next(gen)→ 循环结束,抛出StopIteration。
方式 2:生成器表达式(类似列表推导式)
用 () 替代列表推导式的 [],直接创建生成器对象:
python
# 生成器表达式(对比列表推导式 [x for x in range(1,4)])
gen = (x for x in range(1, 4))
for num in gen:
print(num) # 输出1、2、3迭代器 vs 生成器:核心区别
| 对比维度 | 迭代器(Iterator) | 生成器(Generator) |
|---|---|---|
| 本质 | 实现迭代协议的对象 | 特殊的迭代器(自动实现迭代协议) |
| 创建方式 | 1. iter()转换可迭代对象2. 类实现iter/next | 1. 生成器函数**(yield)**2. 生成器表达式 |
| 代码复杂度 | 高(需手动维护状态) | 低(yield自动维护状态) |
| 适用场景 | 自定义复杂迭代逻辑 | 快速实现惰性数据生成(常用) |
四、高级函数
一、高阶函数(Higher-Order Function)核心定义
高阶函数是满足以下任一条件的 Python 函数:
- 接收一个或多个函数作为参数 (如
map()/filter()接收函数参数); - 返回值是一个函数(如装饰器、闭包函数)。
其核心依赖 Python 的「函数一等对象特性」:函数可作为参数传递、赋值给变量、作为返回值、存储在数据结构中。
二、高阶函数的核心场景与示例
1. 场景 1:函数作为参数传入
最典型的是 Python 内置的高阶函数**(map/filter/sorted)**,也可自定义此类逻辑。
4.1 map()
作用:将传入的函数应用于可迭代对象的每个元素,返回迭代器。
python
# 定义普通函数:计算平方
def square(x):
return x * x
# map(函数, 可迭代对象) → 高阶函数
nums = [1, 2, 3]
result = map(square, nums) # 返回迭代器
print(list(result)) # 输出 [1, 4, 9]
# 结合匿名函数(lambda)更简洁
result = map(lambda x: x*2, nums)
print(list(result)) # 输出 [2, 4, 6]4.2 filter()
作用:用传入的函数判断可迭代对象的元素,返回符合条件的元素迭代器。
python
# 定义判断偶数的函数
def is_even(x):
return x % 2 == 0
nums = [1, 2, 3, 4, 5]
result = filter(is_even, nums)
print(list(result)) # 输出 [2, 4]
# 结合lambda
result = filter(lambda x: x > 3, nums)
print(list(result)) # 输出 [4, 5]4.3 sorted()
作用 :通过key参数传入函数,自定义排序规则。
python
# 按字符串长度排序(key接收len函数)
words = ["apple", "banana", "cherry", "date"]
result = sorted(words, key=len)
print(result) # 输出 ['date', 'apple', 'banana', 'cherry']
# 按字典的value排序(key接收lambda函数)
students = [
{"name": "张三", "score": 90},
{"name": "李四", "score": 85},
{"name": "王五", "score": 95}
]
# 按score降序排序
result = sorted(students, key=lambda x: x["score"], reverse=True)
print(result)
# 输出:[{'name': '王五', 'score': 95}, {'name': '张三', 'score': 90}, {'name': '李四', 'score': 85}]4.4 自定义高阶函数
python
# 高阶函数:执行传入的函数,并统计执行耗时
import time
def timer(func, *args, **kwargs):
start = time.time()
result = func(*args, **kwargs) # 执行传入的函数
end = time.time()
print(f"函数 {func.__name__} 耗时:{end - start:.4f} 秒")
return result
# 测试函数
def slow_func():
time.sleep(0.5)
return "完成"
# 调用高阶函数(传入slow_func)
timer(slow_func) # 输出:函数 slow_func 耗时:0.5001 秒 → 返回"完成"场景 2:函数作为返回值返回
核心是「闭包」:外层函数返回内层函数,内层函数可访问外层函数的变量。
生成定制化函数
python
# 高阶函数:返回一个"固定倍数"的乘法函数
def create_multiplier(n):
# 内层函数(闭包)
def multiplier(x):
return x * n
return multiplier # 返回内层函数
# 创建"乘以2"的函数
double = create_multiplier(2)
print(double(5)) # 输出 10
# 创建"乘以3"的函数
triple = create_multiplier(3)
print(triple(5)) # 输出 15五、python类
类是 Python 中面向对象编程(OOP) 的核心,是对 "具有相同属性和行为的对象" 的抽象描述;而对象是类的具体实例(比如 "猫" 是类,"我家的橘猫" 是对象)。
类的核心要素:
-
属性:描述对象的特征(如名字、年龄、颜色);
-
方法:描述对象的行为(如跑、叫、吃饭);
-
封装:将属性和方法包裹在类中,隐藏内部细节;
-
继承:子类复用父类的属性和方法;
-
多态:不同子类对同一方法有不同实现。
5.1 类的基本语法
定义类与创建对象
python
# 定义类(首字母大写,驼峰命名)
class Cat:
# 类属性:所有对象共享的属性
species = "哺乳动物"
# 初始化方法:创建对象时自动执行,初始化实例属性
def __init__(self, name, age):
# 实例属性:每个对象独有的属性(self代表当前对象)
self.name = name
self.age = age
# 实例方法:对象的行为(必须带self参数)
def meow(self):
print(f"{self.name} 喵喵叫,今年{self.age}岁")
# 创建对象(实例化)
cat1 = Cat("橘猫", 3)
cat2 = Cat("黑猫", 2)
# 访问属性
print(cat1.name) # 输出:橘猫
print(Cat.species) # 输出:哺乳动物(类属性)
# 调用方法
cat1.meow() # 输出:橘猫 喵喵叫,今年3岁
cat2.meow() # 输出:黑猫 喵喵叫,今年2岁关键说明:
-
init:构造方法(初始化方法),创建对象时必执行,用于给对象绑定属性;
-
self:指代当前实例对象,调用方法时无需手动传参,Python 自动传递;
-
类属性 vs 实例属性:类属性属于类本身(所有对象共享),实例属性属于单个对象(互不影响)。
访问控制(封装)
Python 没有严格的 "私有 / 公有" 关键字,通过命名约定实现:
-
普通属性/方法:公有(默认),外部可访问; -
_属性/方法:受保护(约定俗成),外部不建议访问;
-
属性/方法:私有(底层改名),外部无法直接访问。
python
class Person:
def __init__(self, name, age):
self.name = name # 公有
self._age = age # 受保护
self.__id = 123 # 私有
def __private_func(self): # 私有方法
print("私有方法")
def get_id(self): # 提供接口访问私有属性
return self.__id
# 实例化
p = Person("张三", 25)
# 访问公有/受保护属性(受保护仅约定,仍可访问)
print(p.name) # 输出:张三
print(p._age) # 输出:25(不建议这么做)
# 访问私有属性/方法(直接访问报错)
# print(p.__id) # AttributeError
# p.__private_func() # AttributeError
# 通过接口访问私有属性
print(p.get_id()) # 输出:1235.2 类的三大特性
5.2.1 继承(复用父类代码)
子类继承父类的属性和方法,可扩展或重写父类逻辑。
python
# 父类(基类)
class Animal:
def __init__(self, name):
self.name = name
def sleep(self):
print(f"{self.name} 睡觉")
def eat(self):
print(f"{self.name} 吃东西")
# 子类(派生类):继承Animal
class Dog(Animal):
# 重写父类方法
def eat(self):
print(f"{self.name} 吃骨头")
# 子类新增方法
def bark(self):
print(f"{self.name} 汪汪叫")
# 实例化子类
dog = Dog("旺财") # 调用父类的构造函数
dog.eat() # 输出:旺财 吃骨头(重写后的方法)
dog.bark() # 输出:旺财 汪汪叫(子类新增)
dog.sleep() # 输出:旺财 睡觉 直接调用父类方法多继承:一个子类继承多个父类(慎用,易引发冲突):
python
class A: pass
class B: pass
class C(A, B): pass # C继承A和B5.2.2 多态(同一方法不同实现)
不同子类对同一方法有不同实现,调用时自动适配。
python
# 父类
class Animal:
def sound(self):
pass # 空实现
# 子类1
class Dog(Animal):
def sound(self):
print("汪汪汪")
# 子类2
class Cat(Animal):
def sound(self):
print("喵喵喵")
# 通用函数(接收Animal子类对象)
def make_sound(animal):
animal.sound()
# 多态体现:传入不同子类,执行不同逻辑
make_sound(Dog()) # 输出:汪汪汪
make_sound(Cat()) # 输出:喵喵喵5.2.3 封装(隐藏内部细节)
将属性和方法封装在类中,仅通过公开接口访问,保证数据安全。
python
class BankAccount:
def __init__(self, balance):
self.__balance = balance # 私有属性:余额
# 公开接口:查询余额
def get_balance(self):
return self.__balance
# 公开接口:存款
def deposit(self, money):
if money > 0:
self.__balance += money
print(f"存款{money}元,余额:{self.__balance}")
else:
print("存款金额无效")
# 实例化
account = BankAccount(1000)
# 只能通过接口操作余额,无法直接修改
account.deposit(500) # 输出:存款500元,余额:1500
print(account.get_balance()) # 输出:1500
# account.__balance = 999999 # 无法修改私有属性5.3 类的高级用法
类方法与静态方法
| 方法类型 | 定义方式 | 参数 | 访问属性 | 用途 |
|---|---|---|---|---|
| 实例方法 | def func(self): | self | 实例属性 / 类属性 | 操作对象的行为 |
| 类方法 | @classmethod | cls | 类属性 | 操作类本身(如工厂方法) |
| 静态方法 | @staticmethod | 无 | 无(需手动传) | 通用工具函数 |
python
class MathUtils:
# 类属性
PI = 3.14159
# 实例方法
def __init__(self, radius):
self.radius = radius
def circle_area(self):
return self.PI * self.radius **2
# 类方法
@classmethod
def update_pi(cls, new_pi):
cls.PI = new_pi
print(f"更新PI为:{cls.PI}")
# 静态方法
@staticmethod
def add(a, b):
return a + b
# 静态方法(无需实例化)
print(MathUtils.add(2, 3)) # 输出:5
# 类方法(修改类属性)
MathUtils.update_pi(3.14)
# 实例方法(需实例化)
circle = MathUtils(2)
print(circle.circle_area()) # 输出:12.56特殊方法
以__开头和结尾的方法,自动触发执行,实现自定义逻辑:
-
init:创建实例时自动执行,用于初始化对象属性(如
title书名、pages页数); -
str:打印对象时自动执行,自定义对象的字符串展示格式;
-
len:调用
len()函数时自动执行,自定义 "长度" 的计算逻辑(这里返回书籍页数); -
call:将对象当作函数调用时自动执行,实现对象的 "可调用" 行为。
python
class Book:
def __init__(self, title, pages):
self.title = title
self.pages = pages
def __str__(self):
return f"《{self.title}》,共{self.pages}页"
def __len__(self):
return self.pages
def __call__(self):
print(f"正在阅读《{self.title}》")
# 创建Book实例(触发__init__)
book = Book("Python编程从入门到实践", 500)
# 打印对象(触发__str__)
print(book) # 输出:《Python编程从入门到实践》,共500页
# 调用len()(触发__len__)
print(len(book)) # 输出:500
# 将对象当作函数调用(触发__call__)
book() # 输出:正在阅读《Python编程从入门到实践》六、异常处理
异常(Exception)是程序运行过程中发生的非预期错误(如除零、索引越界、文件不存在),会中断正常执行流程。Python 通过 "异常处理机制" 捕获并处理这些错误,避免程序崩溃,同时提供错误定位和恢复的能力。
异常的分类
| 异常类型 | 触发场景 |
|---|---|
TypeError |
类型错误(如数字 + 字符串) |
ValueError |
值错误(如 int ("abc")) |
IndexError |
索引越界(如 list 100) |
KeyError |
字典键不存在(如 dict "none_key") |
FileNotFoundError |
文件不存在(如 open ("none.txt")) |
AttributeError |
属性 / 方法不存在(如 str.abc ()) |
NameError |
变量未定义(如 print (undefined_var)) |
通过 try-except-else-finally 四件套捕获和处理异常,各模块分工明确:
基础结构:try-except(捕获异常)
python
# 基本用法:捕获指定异常
try:
# 可能触发异常的代码
result = 10 / 0 # 除零错误 → ZeroDivisionError
except ZeroDivisionError as e:
# 处理指定异常(e是异常对象,包含错误信息)
print(f"异常类型:{type(e)},错误信息:{e}")
except TypeError as e:
# 可捕获多个异常,按顺序匹配
print(f"类型错误:{e}")
except Exception as e:
# 万能异常捕获(所有异常的父类),建议放在最后
print(f"未知异常:{e}")
# 结果
# 异常类型:<class 'ZeroDivisionError'>,错误信息:division by zeroelse:无异常时执行
python
try:
result = 10 / 2
except ZeroDivisionError as e:
print(f"除零错误:{e}")
else:
# 仅当try块无异常时执行
print(f"计算结果:{result}") # 输出:计算结果:5.0finally:无论是否异常都执行(释放资源)
python
try:
f = open("test.txt", "r", encoding="utf-8")
content = f.read()
except FileNotFoundError as e:
print(f"文件不存在:{e}")
finally:
# 无论是否异常,最终都会执行(常用于关闭文件/数据库连接)
if "f" in locals() and not f.closed:
f.close()
print("文件已关闭")
# 简洁写法:try-except-finally
try:
print(10 / 0)
except Exception as e:
print(f"捕获异常:{e}")
finally:
print("程序执行完毕") # 必执行主动抛出异常:raise
通过 raise 手动触发异常,适用于业务规则校验(如年龄为负、参数非法)。
抛出内置异常
python
def check_age(age):
if not isinstance(age, int):
# 抛出指定异常,可自定义错误信息
raise TypeError("年龄必须是整数")
if age < 0 or age > 150:
raise ValueError(f"年龄{age}不符合规则(0-150)")
print(f"年龄校验通过:{age}")
# 测试
try:
check_age(-10)
except (TypeError, ValueError) as e:
print(f"校验失败:{e}") # 输出:校验失败:年龄-10不符合规则(0-150)自定义异常(继承Exception)
python
# 自定义异常(继承 Exception)
class LoginError(Exception):
"""登录异常(基类)"""
pass
class UserNotFoundError(LoginError):
"""用户名不存在"""
pass
class PasswordError(LoginError):
"""密码错误"""
pass
# 使用自定义异常
def login(username, password):
if username != "admin":
raise UserNotFoundError(f"用户名 {username} 不存在")
if password != "123456":
raise PasswordError("密码错误")
print("登录成功")
# 捕获自定义异常
try:
login("admin", "123")
except UserNotFoundError as e:
print(f"登录失败:{e}")
except PasswordError as e:
print(f"登录失败:{e}")
except LoginError as e: # 捕获所有登录相关异常(父类)
print(f"登录异常:{e}")自定义异常添加属性
python
class BusinessError(Exception):
def __init__(self, code, msg):
self.code = code # 错误码
self.msg = msg # 错误信息
def __str__(self):
return f"[{self.code}] {self.msg}" # 自定义异常打印格式
# 使用
raise BusinessError(500, "数据库连接失败")
# 捕获
try:
raise BusinessError(500, "数据库连接失败")
except BusinessError as e:
print(e) # 输出:错误码:[500] 数据库连接失败七、模块
模块是 Python 中组织代码的基本单元,本质是一个以**.py** 为后缀的 Python 文件(如 utils.py),包含变量、函数、类、可执行代码等。通过模块可实现:
-
代码复用:将通用逻辑封装为模块,在多个项目 / 脚本中调用;
-
代码隔离:不同功能的代码分属不同模块,避免命名冲突;
-
项目结构化 :大型项目通过多模块 / 包(Package)分层管理(如
requests、pandas都是模块 / 包)。
模块的分类
| 类型 | 说明 | 示例 |
|---|---|---|
| 内置模块 | Python 自带的模块(无需安装) | os、sys、json、time |
| 第三方模块 | 需通过pip安装的模块(社区贡献) |
requests、pandas、flask |
| 自定义模块 | 开发者自己编写的.py文件 |
my_utils.py、api_test.py |
模块的基础使用
导入模块(import)
核心语法:通过
import导入模块,可直接使用模块内的变量 / 函数 / 类。
- 导入整个模块
python
# 导入内置模块os
import os
# 使用模块中的函数:模块名.函数名
current_path = os.getcwd() # 获取当前工作目录
print(f"当前路径:{current_path}")- 导入模块并指定别名(简化调用)
python
# 导入第三方模块requests,别名r
import requests as r
# 用别名调用
response = r.get("https://www.baidu.com")
print(f"响应状态码:{response.status_code}")- 导入模块中的指定内容
python
# 从os模块导入指定函数:from 模块名 import 函数/类/变量
from os import getcwd, path
# 直接调用(无需加模块名)
print(f"路径是否存在:{path.exists('test.txt')}")
# 导入时指定别名
from datetime import datetime as dt
print(f"当前时间:{dt.now()}")- 导入模块中的所有内容(不推荐)
python
# 导入os模块的所有内容(易引发命名冲突)
from os import *
# 直接调用,但无法区分来源,大型项目禁用
print(getcwd())模块的高级用法
- 模块的执行控制(
__name__ == "__main__")
模块被直接运行时执行测试代码,被导入时不执行:
python
# my_utils.py
def add(a, b):
return a + b
# 仅当直接运行my_utils.py时执行
if __name__ == "__main__":
print("测试add函数:", add(2, 3)) # 直接运行输出5,被导入时不执行- 隐藏模块内容(
__all__)
定义
__all__后,from 模块 import *仅导入指定内容:
python
# my_utils.py
__all__ = ["add", "Calculator"] # 仅暴露add和Calculator
def add(a, b):
return a + b
def internal_func(): # 不暴露,import * 无法导入
pass
class Calculator:
pass八、内置模块
8.1 builtins模块
builtins模块包含 Python 所有内置函数(共 80+),这些函数无需手动导入即可直接调用,覆盖数据类型转换、序列操作、对象判断、交互输入输出等核心场景。以下按功能分类详解高频内置函数的用法,结合示例说明其实际应用。
输入输出函数
python
# ========== print 函数 ==========
print("1-2-3") # 输出:1-2-3!
# ========== input 函数 ==========
#读取用户输入(注意:运行时需手动输入)
name = input("请输入你的姓名:")
print(f"你好,{name}!")基础类型转换函数
python
# 1. int():转整数(支持进制转换)
print(int("1010", 2)) # 二进制"1010"转十进制 → 运行结果:10
print(int(3.99)) # 浮点数转整数(截断小数)→ 运行结果:3
# 2. float():转浮点数
print(float("3.1415")) # 字符串转浮点数 → 运行结果:3.1415
print(float(True)) # 布尔值True转浮点数 → 运行结果:1.0
# 3. str():转字符串(自定义类可重写__str__)
class Person:
def __str__(self):
return "这是一个Person对象"
print(str(Person())) # 运行结果:这是一个Person对象
# 4. bool():转布尔值(0/空为False,其余为True)
print(bool([])) # 空列表 → 运行结果:False
print(bool("非空字符串")) # 非空 → 运行结果:True统计相关函数
python
# 测试数据
nums = [3, 1, 4, 2, 5, -1]
# 1. len():获取长度
print(len(nums)) # 列表长度 → 运行结果:6
# 2. max():取最大值(支持自定义规则)
print(max(nums)) # 基础最大值 → 运行结果:5
print(max(nums, key=abs))# 按绝对值最大 → 运行结果:-1
# 3. min():取最小值(支持默认值)
print(min(nums)) # 基础最小值 → 运行结果:-1
print(min([], default=0))# 空列表返回默认值 → 运行结果:0
# 4. sum():求和(支持初始值)
print(sum(nums)) # 基础求和 → 运行结果:14
print(sum(nums, 10)) # 初始值10,总和=14+10 → 运行结果:24进制转换函数
python
# 1. 其他进制 → 十进制(用int())
print(int("1010", 2)) # 二进制→十进制 → 10
print(int("FF", 16)) # 十六进制→十进制 → 255
print(int("12", 8)) # 八进制→十进制 → 10
# 2. 十进制 → 其他进制(bin/oct/hex)
print(bin(10)) # 十进制→二进制(带0b前缀)→ 0b1010
print(oct(10)) # 十进制→八进制(带0o前缀)→ 0o12
print(hex(255)) # 十进制→十六进制(带0x前缀)→ 0xff
# 3. 去掉前缀(切片[2:])
print(bin(10)[2:]) # 二进制字符串(无前缀)→ 1010编码相关函数
python
# 1. chr():Unicode编码→字符
print(chr(65)) # ASCII编码65→A → A
print(chr(20013)) # 中文"中"的编码→中 → 中
print(chr(128512)) # Emoji😀的编码→😀 → 😀
# 2. ord():字符→Unicode编码
print(ord("A")) # A→65 → 65
print(ord("中")) # 中→20013 → 20013
print(ord("😀")) # 😀→128512 → 128512
# 3. bytes():字符串→字节串(指定编码)
print(bytes("中文", "utf-8")) # 中文转utf-8字节串 → b'\xe4\xb8\xad\xe6\x96\x87'
print(bytes("中文", "gbk")) # 中文转gbk字节串 → b'\xd6\xd0\xce\xc4'数据结构转换函数
python
# 1. list():转列表
print(list((1, 2, 3))) # 元组转列表 → [1, 2, 3]
print(list("abc")) # 字符串转列表 → ['a', 'b', 'c']
# 2. tuple():转元组
print(tuple([1, 2, 3])) # 列表转元组 → (1, 2, 3)
# 3. dict():转字典
print(dict(a=1, b=2)) # 关键字参数转字典 → {'a': 1, 'b': 2}
print(dict([("a",1), ("b",2)])) # 元组列表转字典 → {'a': 1, 'b': 2}
# 4. set():转集合(去重)
print(set([1, 1, 2, 3])) # 列表转集合(去重)→ {1, 2, 3}其他核心函数
python
# 1. sorted():排序(返回新列表,原列表不变)
nums = [3, 1, 4, 2]
print(sorted(nums)) # 升序 → [1, 2, 3, 4]
print(sorted(nums, reverse=True))# 降序 → [4, 3, 2, 1]
print(sorted(nums, key=abs)) # 按绝对值排序 → [1, 2, 3, 4]
# 2. enumerate():枚举(索引+元素)
fruits = ["apple", "banana", "orange"]
for idx, val in enumerate(fruits, start=1):
print(f"序号:{idx},水果:{val}")
# 运行结果:
# 序号:1,水果:apple
# 序号:2,水果:banana
# 序号:3,水果:orange
# 3. zip():打包多个序列
lst1 = [1, 2, 3]
lst2 = ["a", "b", "c"]
print(list(zip(lst1, lst2))) # 打包 → [(1, 'a'), (2, 'b'), (3, 'c')]
# 4. isinstance():类型判断(支持子类)
class Dog:
pass
dog = Dog()
print(isinstance(dog, Dog)) # True
print(isinstance(123, (int, str))) # True(123是int类型)高级函数
python
# 1. map():批量处理序列元素
nums = [1, 2, 3]
result = map(lambda x: x * 2, nums)
print(list(result)) # 每个元素乘2 → [2, 4, 6]
# 2. filter():过滤序列元素
nums = [1, 2, 3, 4, 5, 6]
result = filter(lambda x: x % 2 == 0, nums)
print(list(result)) # 过滤偶数 → [2, 4, 6]
# 3. eval():执行字符串表达式(慎用用户输入)
expr = "1 + 2 * 3"
print(eval(expr)) # 执行表达式 → 7
# 4. exec():执行字符串代码块
code = """
x = 100
y = 200
print(x + y)
"""
exec(code) # 执行代码块 → 输出:300
# 5. getattr():动态获取对象属性/方法
class Person:
def __init__(self, name):
self.name = name
def say_hi(self):
return f"你好,{self.name}"
p = Person("张三")
print(getattr(p, "name")) # 获取属性 → 张三
say_hi_func = getattr(p, "say_hi")
print(say_hi_func()) # 调用方法 → 你好,张三8.2 os模块
os 模块是 Python 与操作系统交互的核心模块,涵盖文件 / 目录操作、路径处理、系统信息、进程管理等功能。以下按高频场景分类,提供可直接运行的代码示例,包含功能说明、代码、运行结果及避坑指南。
路径处理
python
import os
# 1. os.path.abspath(path):获取绝对路径
relative_path = "test.txt"
abs_path = os.path.abspath(relative_path)
print(f"相对路径转绝对路径:{abs_path}")
# 运行结果(示例):/Users/xxx/test.txt(Mac)| C:\Users\xxx\test.txt(Windows)
# 2. os.path.join(*paths):拼接路径(自动适配系统分隔符)
dir_path = "data"
file_name = "log.txt"
full_path = os.path.join(dir_path, file_name)
print(f"拼接后的路径:{full_path}")
# 运行结果:data/log.txt(Mac/Linux)| data\log.txt(Windows)
# 3. os.path.split(path):拆分路径(目录+文件名)
path = "/Users/xxx/data/log.txt"
dir_part, file_part = os.path.split(path)
print(f"目录部分:{dir_part},文件部分:{file_part}")
# 运行结果:目录部分:/Users/xxx/data,文件部分:log.txt
# 4. os.path.basename(path):获取文件名(含后缀)
print(f"文件名:{os.path.basename(path)}") # 运行结果:log.txt
# 5. os.path.dirname(path):获取目录名
print(f"目录名:{os.path.dirname(path)}") # 运行结果:/Users/xxx/data
# 6. os.path.exists(path):判断路径是否存在
print(f"路径是否存在:{os.path.exists(path)}") # 运行结果:True/False
# 7. os.path.isfile/isdir:判断是文件/目录
test_path = "/Users/xxx/data"
print(f"是否为文件:{os.path.isfile(test_path)}") # False
print(f"是否为目录:{os.path.isdir(test_path)}") # True
# 8. os.path.splitext(path):拆分文件名和后缀
file_path = "report.pdf"
name, ext = os.path.splitext(file_path)
print(f"文件名:{name},后缀:{ext}") # 运行结果:文件名:report,后缀:.pdf目录操作
创建、删除、遍历目录是文件管理的基础操作。
python
import os
# 1. os.getcwd():获取当前工作目录
current_dir = os.getcwd()
print(f"当前工作目录:{current_dir}")
# 运行结果(示例):/Users/xxx/projects
# 2. os.chdir(path):切换工作目录
target_dir = "/Users/xxx/Documents"
os.chdir(target_dir)
print(f"切换后工作目录:{os.getcwd()}") # 运行结果:/Users/xxx/Documents
# 3. os.mkdir(path):创建单个目录(父目录不存在则报错)
new_dir = "new_folder"
if not os.path.exists(new_dir):
os.mkdir(new_dir)
print(f"目录 {new_dir} 创建成功")
else:
print(f"目录 {new_dir} 已存在")
# 4. os.makedirs(path):递归创建多级目录(父目录不存在自动创建)
multi_dir = "parent/child/grandchild"
if not os.path.exists(multi_dir):
os.makedirs(multi_dir)
print(f"多级目录 {multi_dir} 创建成功")
# 5. os.rmdir(path):删除空目录(非空则报错)
if os.path.exists(new_dir):
os.rmdir(new_dir)
print(f"空目录 {new_dir} 删除成功")
# 6. os.removedirs(path):递归删除空目录(从子到父,遇到非空则停止)
if os.path.exists(multi_dir):
os.removedirs(multi_dir)
print(f"多级空目录 {multi_dir} 删除成功")
# 7. os.listdir(path):列出目录下所有文件/子目录(不含子目录内容)
dir_to_list = "/Users/xxx/Documents"
items = os.listdir(dir_to_list)
print(f"目录 {dir_to_list} 下的内容:{items}")
# 运行结果(示例):['file1.txt', 'folder1', 'file2.pdf']
# 8. os.walk(path):递归遍历目录(返回根目录、子目录、文件)
root_dir = "/Users/xxx/test"
for root, dirs, files in os.walk(root_dir):
print(f"当前根目录:{root}")
print(f"子目录:{dirs}")
print(f"文件:{files}")
print("-" * 20)
# 运行结果(示例):
# 当前根目录:/Users/xxx/test
# 子目录:['subdir1']
# 文件:['test1.txt']
# --------------------
# 当前根目录:/Users/xxx/test/subdir1
# 子目录:[]
# 文件:['test2.txt']
# --------------------文件操作
os 模块提供基础文件操作(重命名、删除),复杂读写建议用 open()。
python
import os
# 1. os.rename(src, dst):重命名文件/目录
old_name = "old_file.txt"
new_name = "new_file.txt"
# 先创建测试文件
with open(old_name, "w") as f:
f.write("test")
# 重命名
if os.path.exists(old_name):
os.rename(old_name, new_name)
print(f"文件 {old_name} 重命名为 {new_name}")
# 2. os.remove(path):删除文件(不能删目录)
if os.path.exists(new_name):
os.remove(new_name)
print(f"文件 {new_name} 删除成功")
# 3. os.replace(src, dst):替换文件(dst存在则覆盖)
src_file = "source.txt"
dst_file = "dest.txt"
# 创建测试文件
with open(src_file, "w") as f:
f.write("source content")
with open(dst_file, "w") as f:
f.write("dest content")
# 替换
os.replace(src_file, dst_file)
with open(dst_file, "r") as f:
print(f"替换后dst文件内容:{f.read()}") # 运行结果:source content
# 清理文件
os.remove(dst_file)系统信息与环境变量
获取操作系统类型、环境变量、CPU 数量等系统信息。
python
import os
# 1. os.name:获取操作系统类型(posix=Linux/Mac,nt=Windows)
print(f"操作系统类型:{os.name}") # 运行结果:posix(Mac)| nt(Windows)
# 2. os.environ:获取/设置环境变量(字典格式)
# 获取环境变量
python_path = os.environ.get("PYTHONPATH", "未设置")
print(f"PYTHONPATH:{python_path}")
# 设置环境变量(临时,仅当前进程有效)
os.environ["MY_CUSTOM_VAR"] = "123456"
print(f"自定义环境变量:{os.environ['MY_CUSTOM_VAR']}") # 运行结果:123456
# 3. os.cpu_count():获取CPU核心数
print(f"CPU核心数:{os.cpu_count()}") # 运行结果(示例):8
# 4. os.getpid()/os.getppid():获取当前进程ID/父进程ID
print(f"当前进程ID:{os.getpid()}")
print(f"父进程ID:{os.getppid()}")
# 5. os.sep:获取系统路径分隔符
print(f"路径分隔符:{os.sep}") # 运行结果:/(Mac/Linux)| \(Windows)
# 6. os.linesep:获取系统换行符
print(f"换行符:{repr(os.linesep)}") # 运行结果:'\n'(Mac/Linux)| '\r\n'(Windows)进程管理(简单操作)
执行系统命令、退出进程等基础进程操作。
python
import os
# 1. os.system(command):执行系统命令(返回退出码,0=成功)
# 示例:列出当前目录(Mac/Linux)
if os.name == "posix":
exit_code = os.system("ls -l")
# 示例:列出当前目录(Windows)
else:
exit_code = os.system("dir")
print(f"命令执行退出码:{exit_code}") # 运行结果:0(成功)
# 2. os.popen(command):执行命令并获取输出
if os.name == "posix":
output = os.popen("echo 'Hello OS'").read()
else:
output = os.popen("echo Hello OS").read()
print(f"命令输出:{output}") # 运行结果:Hello OS
# 3. os._exit(status):强制退出进程(无清理,慎用)
# os._exit(0) # 取消注释会直接退出Python进程8.3 时间日期模块
Python 处理时间日期的核心模块有 3 个:
datetime(主流,功能最全)、time(底层时间操作)、calendar(日历相关)。以下按「高频场景 + 可运行代码」分类讲解,覆盖时间获取、转换、计算、格式化等核心需求。
8.3.1 datetime 模块
datetime 模块包含 datetime/date/time/timedelta 类,是处理时间日期的首选。
获取当前时间 / 日期
python
from datetime import datetime, date, time
# 1. 获取当前完整时间(datetime对象)
now = datetime.now()
print(f"当前完整时间:{now}") # 输出示例:2026-01-03 18:30:45.123456
# 2. 获取当前日期(date对象)
today = date.today()
print(f"当前日期:{today}") # 输出示例:2026-01-03
# 3. 获取当前UTC时间(世界协调时间)
utc_now = datetime.utcnow()
print(f"当前UTC时间:{utc_now}") # 输出示例:2026-01-03 10:30:45.123456
# 4. 手动创建datetime/date/time对象
custom_datetime = datetime(2026, 1, 3, 18, 30, 45) # 年,月,日,时,分,秒
custom_date = date(2026, 1, 3)
custom_time = time(18, 30, 45)
print(f"自定义时间:{custom_datetime}") # 2026-01-03 18:30:45时间格式化(datetime ↔ 字符串)
python
from datetime import datetime
now = datetime.now()
# 1. datetime对象 → 字符串(strftime)
# 常用格式化符号:%Y(年)、%m(月)、%d(日)、%H(时24)、%M(分)、%S(秒)、%w(星期0-6)
fmt_str = now.strftime("%Y-%m-%d %H:%M:%S")
print(f"格式化时间字符串:{fmt_str}") # 输出示例:2026-01-03 18:30:45
# 2. 字符串 → datetime对象(strptime)
time_str = "2026-01-03 18:30:45"
parsed_time = datetime.strptime(time_str, "%Y-%m-%d %H:%M:%S")
print(f"解析后的datetime对象:{parsed_time}") # 2026-01-03 18:30:45
# 3. 其他常用格式
print(now.strftime("%Y年%m月%d日 %H时%M分%S秒")) # 2026年01月03日 18时30分45秒
print(now.strftime("%a, %d %b %Y")) # Sat, 03 Jan 2026(英文简写)时间计算(timedelta 时间差)
python
from datetime import datetime, timedelta
now = datetime.now()
# 1. 计算未来/过去的时间
# 加1天、减2小时、加30分钟
future_time = now + timedelta(days=1, hours=-2, minutes=30)
print(f"当前时间+1天-2小时+30分钟:{future_time.strftime('%Y-%m-%d %H:%M:%S')}")
# 2. 计算两个时间的差值
time1 = datetime(2026, 1, 3, 10, 0, 0)
time2 = datetime(2026, 1, 5, 12, 30, 0)
delta = time2 - time1
print(f"时间差:{delta}") # 2 days, 2:30:00
print(f"相差天数:{delta.days}") # 2
print(f"相差秒数:{delta.seconds}")# 9000(2小时30分=9000秒)
print(f"总相差秒数:{delta.total_seconds()}") # 189000.0
# 3. 日期加减(仅日期)
today = date.today()
yesterday = today - timedelta(days=1)
print(f"昨天:{yesterday}") # 2026-01-02datetime 对象属性提取
python
from datetime import datetime
now = datetime.now()
print(f"年:{now.year}") # 2026
print(f"月:{now.month}") # 1
print(f"日:{now.day}") # 3
print(f"时:{now.hour}") # 18
print(f"分:{now.minute}") # 30
print(f"秒:{now.second}") # 45
print(f"微秒:{now.microsecond}") # 123456
print(f"星期(0=周一,6=周日):{now.weekday()}") # 5(周六)
print(f"星期(1=周一,7=周日):{now.isoweekday()}") # 6(周六)8.3.2 time 模块
time 模块偏向底层,常用于时间戳、程序延时、CPU 时间统计。
python
import time
# 1. 获取时间戳(自1970-01-01 00:00:00 UTC以来的秒数)
timestamp = time.time()
print(f"当前时间戳:{timestamp}") # 输出示例:1735929045.123456
# 2. 时间戳 ↔ 结构化时间(struct_time)
# 时间戳→结构化时间(本地时间)
local_struct = time.localtime(timestamp)
print(f"本地结构化时间:{local_struct}") # time.struct_time(tm_year=2026, ...)
# 时间戳→结构化时间(UTC时间)
utc_struct = time.gmtime(timestamp)
print(f"UTC结构化时间:{utc_struct}")
# 3. 结构化时间→时间戳
timestamp2 = time.mktime(local_struct)
print(f"结构化时间转时间戳:{timestamp2}") # 1735929045.0
# 4. 结构化时间→字符串
time_str = time.strftime("%Y-%m-%d %H:%M:%S", local_struct)
print(f"结构化时间转字符串:{time_str}") # 2026-01-03 18:30:45
# 5. 字符串→结构化时间
struct = time.strptime("2026-01-03 18:30:45", "%Y-%m-%d %H:%M:%S")
print(f"字符串转结构化时间:{struct}")
# 6. 程序延时(sleep)
print("开始延时3秒...")
time.sleep(3) # 暂停3秒
print("延时结束")
# 7. 统计程序运行时间(perf_counter 高精度)
start = time.perf_counter()
# 模拟耗时操作
sum(range(1000000))
end = time.perf_counter()
print(f"程序运行耗时:{end - start:.6f} 秒") # 输出示例:0.012345 秒
# 8. 获取CPU时间(区分用户态/系统态)
user_time, sys_time = time.process_time()
print(f"用户CPU时间:{user_time},系统CPU时间:{sys_time}")8.3.3 calendar 模块
calendar 模块用于日历生成、月份 / 星期判断等。
python
import calendar
# 1. 生成指定年份的日历
cal = calendar.calendar(2026)
print(f"2026年日历:\n{cal}") # 输出2026年完整日历
# 2. 生成指定月份的日历
month_cal = calendar.month(2026, 1)
print(f"2026年1月日历:\n{month_cal}")
# 3. 判断闰年
is_leap = calendar.isleap(2026)
print(f"2026年是否为闰年:{is_leap}") # False
print(f"2024年是否为闰年:{calendar.isleap(2024)}") # True
# 4. 获取某年份的闰年数(指定区间)
leap_count = calendar.leapdays(2000, 2026)
print(f"2000-2026年之间的闰年数:{leap_count}") # 7
# 5. 获取某月的天数
days = calendar.monthrange(2026, 1)[1]
print(f"2026年1月的天数:{days}") # 31
# 6. 获取某月第一天是星期几(0=周一,6=周日)
first_weekday = calendar.monthrange(2026, 1)[0]
print(f"2026年1月1日是星期{first_weekday}(0=周一)") # 4(周五)
# 7. 判断某一天是星期几(0=周一,6=周日)
weekday = calendar.weekday(2026, 1, 3)
print(f"2026年1月3日是星期{weekday}(0=周一)") # 5(周六)8.4 random模块
random模块是 Python 生成随机数 / 随机选择的核心模块,涵盖随机数生成、序列随机操作、概率分布随机数等功能。以下按高频场景分类,提供可直接运行的代码示例,包含功能说明、代码、运行结果及实用技巧。
基础随机数生成
python
import random
# 1. random.random():生成 [0.0, 1.0) 范围内的随机浮点数
rand_float = random.random()
print(f"[0,1) 随机浮点数:{rand_float}") # 输出示例:0.789456123
# 2. random.uniform(a, b):生成 [a, b] 范围内的随机浮点数(a/b 顺序无关)
rand_uniform1 = random.uniform(1, 10)
rand_uniform2 = random.uniform(10, 1) # 与上面等价
print(f"[1,10] 随机浮点数:{rand_uniform1}") # 输出示例:5.4321
print(f"[10,1] 随机浮点数:{rand_uniform2}") # 输出示例:8.7654
# 3. random.randint(a, b):生成 [a, b] 范围内的随机整数(闭区间)
rand_int = random.randint(1, 100)
print(f"[1,100] 随机整数:{rand_int}") # 输出示例:45
# 4. random.randrange(start, stop[, step]):生成指定步长的随机整数(左闭右开)
# 示例1:[0, 10) 随机整数(等价于 randint(0,9))
rand_range1 = random.randrange(10)
# 示例2:[1, 10) 步长2(1,3,5,7,9中随机选)
rand_range2 = random.randrange(1, 10, 2)
print(f"[0,10) 随机整数:{rand_range1}") # 输出示例:7
print(f"[1,10) 步长2随机整数:{rand_range2}") # 输出示例:5序列随机操作
对列表、元组等序列进行随机选择、打乱、抽样,是业务开发中最常用的场景。
python
import random
# 测试序列
lst = ["apple", "banana", "orange", "grape", "pear"]
tpl = (1, 2, 3, 4, 5)
# 1. random.choice(seq):从非空序列中随机选择一个元素
rand_choice = random.choice(lst)
print(f"随机选择的水果:{rand_choice}") # 输出示例:banana
# 2. random.choices(seq, weights=None, k=1):有放回抽样(可重复选)
# 示例1:默认权重(等概率),选3个(可重复)
rand_choices1 = random.choices(lst, k=3)
# 示例2:指定权重(概率),权重越大选中概率越高
# apple:0.1, banana:0.2, orange:0.3, grape:0.2, pear:0.2
rand_choices2 = random.choices(lst, weights=[1,2,3,2,2], k=2)
print(f"有放回抽样(等概率):{rand_choices1}") # 输出示例:['pear', 'apple', 'banana']
print(f"有放回抽样(指定权重):{rand_choices2}") # 输出示例:['orange', 'grape']
# 3. random.sample(population, k):无放回抽样(不可重复选,k≤序列长度)
rand_sample = random.sample(lst, k=3)
print(f"无放回抽样(3个):{rand_sample}") # 输出示例:['orange', 'apple', 'pear']
# 4. random.shuffle(x):打乱序列(原地修改,仅支持可变序列如列表)
lst_copy = lst.copy() # 避免修改原列表
random.shuffle(lst_copy)
print(f"原列表:{lst}") # 输出:['apple', 'banana', 'orange', 'grape', 'pear']
print(f"打乱后列表:{lst_copy}") # 输出示例:['grape', 'apple', 'pear', 'banana', 'orange']
# 5. 对不可变序列(元组)打乱:先转列表,打乱后转回
tpl_list = list(tpl)
random.shuffle(tpl_list)
shuffled_tpl = tuple(tpl_list)
print(f"打乱后元组:{shuffled_tpl}") # 输出示例:(3, 1, 5, 2, 4)概率分布随机数
生成符合特定概率分布的随机数,适用于模拟、统计场景。
python
import random
import matplotlib.pyplot as plt # 可选,用于可视化分布
# 1. random.gauss(mu, sigma):生成高斯(正态)分布随机数
# mu=均值,sigma=标准差
gauss_nums = [random.gauss(0, 1) for _ in range(10000)]
print(f"正态分布随机数示例:{gauss_nums[:5]}") # 输出示例:[0.123, -0.456, 0.789, -0.234, 0.567]
# 可视化(可选运行)
# plt.hist(gauss_nums, bins=50)
# plt.title("正态分布随机数")
# plt.show()
# 2. random.expovariate(lambd):生成指数分布随机数(lambd=1/均值)
expo_nums = [random.expovariate(0.5) for _ in range(1000)]
print(f"指数分布随机数示例:{expo_nums[:5]}") # 输出示例:[1.234, 0.567, 3.456, 0.890, 2.345]
# 3. random.paretovariate(alpha):生成帕累托分布随机数
pareto_nums = [random.paretovariate(2) for _ in range(1000)]
print(f"帕累托分布随机数示例:{pareto_nums[:5]}") # 输出示例:[1.23, 2.45, 1.01, 3.67, 1.89]
# 4. random.betavariate(alpha, beta):生成beta分布随机数(0~1之间)
beta_nums = [random.betavariate(2, 5) for _ in range(1000)]
print(f"beta分布随机数示例:{beta_nums[:5]}") # 输出示例:[0.12, 0.34, 0.21, 0.45, 0.18]随机种子
设置随机种子后,随机结果可固定(用于调试、复现场景)。
python
import random
# 1. 设置随机种子(整数/字符串均可)
random.seed(123) # 固定种子
print("固定种子后的随机数:")
print(random.random()) # 输出:0.052363598850944326
print(random.randint(1, 10)) # 输出:2
print(random.choice(["a", "b", "c"])) # 输出:b
# 2. 重新设置相同种子,结果完全一致
random.seed(123)
print("重新设置种子后的随机数:")
print(random.random()) # 输出:0.052363598850944326(与上面一致)
print(random.randint(1, 10)) # 输出:2(与上面一致)
print(random.choice(["a", "b", "c"])) # 输出:b(与上面一致)
# 3. 不设置种子:每次运行结果不同
random.seed() # 重置种子(基于系统时间)
print("重置种子后的随机数:")
print(random.random()) # 输出示例:0.987654321(每次不同)8.5 math模块
math 模块是 Python 提供的数学运算核心模块,涵盖基础算术、三角函数、指数对数、排列组合、常量定义等功能,所有函数均基于浮点数运算(精度更高)。以下按高频场景分类,提供可直接运行的代码示例,包含功能说明、代码、运行结果及实用技巧。
基础数学常量
math 模块定义了数学中常用的常量,无需手动定义,精度远高于手动输入。
python
import math
# 1. 圆周率 π(精确到15位以上)
print(f"圆周率 π:{math.pi}") # 输出:3.141592653589793
# 2. 自然常数 e(对数的底)
print(f"自然常数 e:{math.e}") # 输出:2.718281828459045
# 3. 无穷大(正/负)
print(f"正无穷大:{math.inf}") # 输出:inf
print(f"负无穷大:{-math.inf}") # 输出:-inf
# 4. 非数字(NaN)
print(f"非数字:{math.nan}") # 输出:nan
# 5. 圆周率常量实战:计算圆面积
radius = 5
circle_area = math.pi * (radius **2)
print(f"半径为{radius}的圆面积:{circle_area:.2f}") # 输出:78.54基础算术运算
包含绝对值、取整、阶乘、幂运算等基础数学操作,精度优于内置运算符。
python
import math
# 1. math.fabs(x):绝对值(返回浮点数,区别于内置abs())
print(f"fabs(-5):{math.fabs(-5)}") # 输出:5.0(浮点数)
print(f"内置abs(-5):{abs(-5)}") # 输出:5(整数)
# 2. 取整函数(核心区别)
x = 3.7
print(f"math.ceil({x}):{math.ceil(x)}") # 向上取整 → 4.0
print(f"math.floor({x}):{math.floor(x)}") # 向下取整 → 3.0
print(f"math.trunc({x}):{math.trunc(x)}") # 截断小数 → 3(返回整数)
print(f"round({x}):{round(x)}") # 四舍五入 → 4(内置函数)
# 3. math.factorial(x):阶乘(x≥0且为整数,否则报错)
print(f"5的阶乘:{math.factorial(5)}") # 5! = 5×4×3×2×1 → 120
# math.factorial(-1) # 报错:ValueError
# math.factorial(3.5) # 报错:ValueError
# 4. math.pow(x, y):幂运算(x^y,返回浮点数,区别于**)
print(f"2^3(pow):{math.pow(2, 3)}") # 输出:8.0
print(f"2^3(**):{2**3}") # 输出:8(整数)
print(f"pow(0, 0):{math.pow(0, 0)}") # 输出:1.0(特殊值)
# 5. math.sqrt(x):平方根(x≥0,返回浮点数)
print(f"16的平方根:{math.sqrt(16)}") # 输出:4.0
print(f"2的平方根:{math.sqrt(2):.6f}") # 输出:1.414214(保留6位小数)指数与对数运算
涵盖自然对数、常用对数、指数函数,适用于科学计算场景。
python
import math
# 1. math.exp(x):自然指数 e^x(等价于math.pow(math.e, x))
x = 2
print(f"e^{x}(exp):{math.exp(x)}") # 输出:7.38905609893065
print(f"e^{x}(pow):{math.pow(math.e, x)}") # 结果一致
# 2. 对数函数
x = math.e # 自然常数
print(f"ln({x})(自然对数):{math.log(x)}") # 输出:1.0
print(f"log10(100)(常用对数):{math.log10(100)}") # 输出:2.0
print(f"log2(8)(2为底):{math.log2(8)}") # 输出:3.0
# 3. 自定义底数的对数(换底公式:log_a(b) = ln(b)/ln(a))
a = 5
b = 25
log_ab = math.log(b) / math.log(a)
print(f"log_{a}({b}) = {log_ab}") # 输出:2.0
# 4. math.log1p(x):ln(1+x)(x接近0时精度更高)
x = 1e-10 # 极小值
print(f"ln(1+{x}):{math.log(1+x):.20f}") # 精度低:0.00000000009999999994
print(f"log1p({x}):{math.log1p(x):.20f}") # 精度高:0.00000000009999999995三角函数与反三角函数
所有三角函数的参数均为弧度(非角度),需注意角度与弧度的转换。
python
import math
# 1. 角度转弧度(核心:math.radians(x))
angle_30 = math.radians(30) # 30度转弧度
angle_90 = math.radians(90) # 90度转弧度
print(f"30度 = {angle_30:.6f} 弧度") # 输出:0.523599
print(f"90度 = {angle_90:.6f} 弧度") # 输出:1.570796
# 2. 三角函数(sin/cos/tan)
print(f"sin(30°) = {math.sin(angle_30):.6f}") # 输出:0.500000
print(f"cos(90°) = {math.cos(angle_90):.6f}") # 输出:0.000000
print(f"tan(45°) = {math.tan(math.radians(45)):.6f}") # 输出:1.000000
# 3. 反三角函数(asin/acos/atan)→ 返回弧度
sin_05 = math.asin(0.5) # arcsin(0.5)
print(f"arcsin(0.5) = {sin_05:.6f} 弧度 = {math.degrees(sin_05)} 度") # 输出:30.0度
# 4. 双曲线函数(sinh/cosh/tanh)
x = 1
print(f"sinh(1) = {math.sinh(x):.6f}") # 输出:1.175201
print(f"cosh(1) = {math.cosh(x):.6f}") # 输出:1.543081其他实用数学函数
包含距离计算、排列组合、符号判断等实用功能。
python
import math
# 1. math.hypot(x, y):计算(x, y)到原点的欧几里得距离(√(x²+y²))
x = 3
y = 4
print(f"({x},{y})到原点的距离:{math.hypot(x, y)}") # 输出:5.0
# 2. 排列组合
# math.comb(n, k):组合数 C(n,k) = n!/(k!(n-k)!)(n≥k≥0)
print(f"C(5,2) = {math.comb(5, 2)}") # 5选2 → 10
# math.perm(n, k):排列数 P(n,k) = n!/(n-k)!(n≥k≥0)
print(f"P(5,2) = {math.perm(5, 2)}") # 5排2 → 20
# 3. 符号判断:math.copysign(x, y) → 返回x的绝对值,符号与y一致
print(f"copysign(3, -1):{math.copysign(3, -1)}") # 输出:-3.0
print(f"copysign(-5, 2):{math.copysign(-5, 2)}") # 输出:5.0
# 4. 余数与模运算:math.fmod(x, y)(区别于%)
print(f"fmod(5, 2) = {math.fmod(5, 2)}") # 输出:1.0
print(f"5 % 2 = {5 % 2}") # 输出:1
print(f"fmod(-5, 2) = {math.fmod(-5, 2)}") # 输出:-1.0(符号与x一致)
print(f"-5 % 2 = {-5 % 2}") # 输出:1(符号与y一致)
# 5. 最大公约数/最小公倍数
print(f"gcd(12, 18) = {math.gcd(12, 18)}") # 最大公约数 → 6
print(f"lcm(12, 18) = {math.lcm(12, 18)}") # 最小公倍数 → 36(Python3.9+支持)特殊数学函数
适用于统计、物理、工程等专业场景。
python
import math
# 1. math.erf(x):误差函数(统计学常用)
print(f"erf(0) = {math.erf(0)}") # 输出:0.0
print(f"erf(1) = {math.erf(1):.6f}") # 输出:0.842701
# 2. math.gamma(x):伽马函数(Γ(x) = (x-1)!,x>0)
print(f"gamma(5) = {math.gamma(5)}") # Γ(5)=4! → 24.0
print(f"gamma(0.5) = {math.gamma(0.5):.6f}") # √π → 1.772454
# 3. math.isclose(a, b):判断两个数是否"接近"(解决浮点数精度问题)
a = 0.1 + 0.2
b = 0.3
print(f"0.1+0.2 = {a}") # 输出:0.30000000000000004
print(f"isclose(a, b):{math.isclose(a, b)}") # 输出:True(忽略微小误差)8.6 hashlib模块
hashlib 模块是 Python 提供的加密哈希算法核心模块,支持 MD5、SHA1、SHA256、SHA512 等主流哈希算法,可用于数据加密、文件校验、密码存储(需加盐)等场景。以下按高频场景分类,提供可直接运行的代码示例,包含功能说明、代码、运行结果及安全注意事项。
基础用法(字符串哈希)
对字符串生成哈希值,核心步骤:创建哈希对象 → 更新数据 → 获取哈希值(十六进制)。
python
import hashlib
# 1. 待哈希的原始数据(需转为字节串,utf-8 编码)
data = "Python hashlib 示例".encode("utf-8")
# 2. MD5 哈希(不推荐密码场景)
md5_obj = hashlib.md5() # 创建MD5哈希对象
md5_obj.update(data) # 传入字节串数据
md5_result = md5_obj.hexdigest() # 获取十六进制哈希值
print(f"MD5 哈希值:{md5_result}") # 输出示例:f8b7e0c3d9a8b7e0f8d9c8b7a9d8e7f0
# 3. SHA256 哈希(推荐)
sha256_obj = hashlib.sha256()
sha256_obj.update(data)
sha256_result = sha256_obj.hexdigest()
print(f"SHA256 哈希值:{sha256_result}") # 输出示例:7a8b9c0d1e2f3a4b5c6d7e8f9a0b1c2d3e4f5a6b7c8d9e0f1a2b3c4d5e6f7a8b
# 4. SHA512 哈希(高安全性场景)
sha512_obj = hashlib.sha512()
sha512_obj.update(data)
sha512_result = sha512_obj.hexdigest()
print(f"SHA512 哈希值:{sha512_result}") # 输出示例:超长64字节十六进制串
# 5. 简化写法(一步生成)
md5_simple = hashlib.md5(data).hexdigest()
print(f"MD5 简化写法:{md5_simple}") # 与上面MD5结果一致
# 6. 分块更新(适用于大文件/分段数据)
big_data = b"part1_part2_part3"
sha256_big = hashlib.sha256()
sha256_big.update(b"part1_") # 分块1
sha256_big.update(b"part2_") # 分块2
sha256_big.update(b"part3") # 分块3
print(f"分块更新哈希值:{sha256_big.hexdigest()}") # 与直接传入big_data结果一致8.7 logging模块
logging 模块是 Python 官方推荐的日志处理模块,支持多级别日志、多输出目标、日志格式化、日志轮转 等功能,替代
print()成为生产环境的首选日志方案。以下按「基础配置→进阶用法→实战场景」分类,提供可直接运行的代码示例,包含功能说明、代码、运行结果及最佳实践。
-
日志级别 (从低到高):
DEBUG(调试)→INFO(常规)→WARNING(警告)→ERROR(错误)→CRITICAL(严重错误),级别越高输出越少; -
日志组件 :
Logger(日志器)→Handler(处理器,输出到控制台 / 文件)→Formatter(格式器,定义日志格式)→Filter(过滤器,筛选日志); -
默认配置 :未手动配置时,默认只输出
WARNING及以上级别日志到控制台。
最简日志输出(默认配置)
python
import logging
# 直接使用根日志器(root logger)
logging.debug("这是DEBUG级别的日志(默认不输出)") # 级别低,无输出
logging.info("这是INFO级别的日志(默认不输出)") # 级别低,无输出
logging.warning("这是WARNING级别的日志(默认输出)") # 输出:WARNING:root:这是WARNING级别的日志(默认输出)
logging.error("这是ERROR级别的日志(默认输出)") # 输出:ERROR:root:这是ERROR级别的日志(默认输出)
logging.critical("这是CRITICAL级别的日志(默认输出)") # 输出:CRITICAL:root:这是CRITICAL级别的日志(默认输出)基础配置(自定义级别 + 格式 + 输出)
通过 basicConfig 快速配置日志的级别、格式、输出目标(控制台 / 文件)。
python
import logging
# 基础配置(需在所有日志调用前执行)
logging.basicConfig(
level=logging.DEBUG, # 日志级别:DEBUG及以上都输出
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s", # 日志格式
datefmt="%Y-%m-%d %H:%M:%S", # 时间格式
handlers=[
logging.StreamHandler(), # 输出到控制台
logging.FileHandler("app.log", encoding="utf-8") # 输出到文件(utf-8避免中文乱码)
]
)
# 测试不同级别日志
logging.debug("调试信息:用户输入了参数x=10")
logging.info("常规信息:数据加载完成")
logging.warning("警告信息:磁盘空间不足80%")
logging.error("错误信息:数据库连接失败")
logging.critical("严重错误:系统即将宕机")
# 运行结果(控制台+app.log文件):
# 2026-01-03 20:00:00 - root - DEBUG - 调试信息:用户输入了参数x=10
# 2026-01-03 20:00:00 - root - INFO - 常规信息:数据加载完成
# 2026-01-03 20:00:00 - root - WARNING - 警告信息:磁盘空间不足80%
# 2026-01-03 20:00:00 - root - ERROR - 错误信息:数据库连接失败
# 2026-01-03 20:00:00 - root - CRITICAL - 严重错误:系统即将宕机日志格式参数说明
| 格式参数 | 说明 | 示例 |
|---|---|---|
%(asctime)s |
日志记录时间 | 2026-01-03 20:00:00 |
%(name)s |
日志器名称(默认 root) | root |
%(levelname)s |
日志级别(大写) | DEBUG/INFO/WARNING |
%(message)s |
日志消息(自定义内容) | 调试信息:xxx |
%(filename)s |
日志所在文件名 | demo.py |
%(lineno)d |
日志所在行号 | 15 |
%(funcName)s |
日志所在函数名 | test_log |
%(process)d |
进程 ID | 12345 |
%(thread)d |
线程 ID | 67890 |
进阶用法(自定义日志器 + 多处理器)
生产环境推荐自定义日志器(避免根日志器冲突),支持多输出目标(控制台 + 文件)、不同级别不同输出。
python
import logging
from logging.handlers import RotatingFileHandler, TimedRotatingFileHandler
def setup_custom_logger(name):
"""
创建自定义日志器
:param name: 日志器名称(通常用__name__)
:return: 配置好的logger对象
"""
# 1. 创建日志器(避免重复配置,先判断是否已有处理器)
logger = logging.getLogger(name)
logger.setLevel(logging.DEBUG) # 日志器级别(需≤处理器级别)
if logger.handlers: # 避免重复添加处理器
return logger
# 2. 创建格式器(自定义日志格式)
formatter = logging.Formatter(
fmt="%(asctime)s - %(name)s - %(levelname)s - %(filename)s:%(lineno)d - %(message)s",
datefmt="%Y-%m-%d %H:%M:%S"
)
# 3. 创建控制台处理器(输出INFO及以上)
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
console_handler.setFormatter(formatter)
# 4. 创建文件处理器(输出DEBUG及以上,按大小轮转)
# RotatingFileHandler:文件达到指定大小后自动切割(避免单个文件过大)
file_handler = RotatingFileHandler(
filename="app_custom.log",
maxBytes=1024*1024*5, # 5MB
backupCount=5, # 保留5个备份文件
encoding="utf-8"
)
file_handler.setLevel(logging.DEBUG)
file_handler.setFormatter(formatter)
# 5. 创建按时间轮转的文件处理器(可选)
# TimedRotatingFileHandler:按时间切割(如每天/每小时)
time_file_handler = TimedRotatingFileHandler(
filename="app_time.log",
when="D", # 轮转单位:S(秒)/M(分)/H(时)/D(天)/W0(周一)/midnight
interval=1, # 每1天轮转一次
backupCount=7, # 保留7天的日志
encoding="utf-8"
)
time_file_handler.setLevel(logging.ERROR) # 仅记录ERROR及以上
time_file_handler.setFormatter(formatter)
# 6. 添加处理器到日志器
logger.addHandler(console_handler)
logger.addHandler(file_handler)
logger.addHandler(time_file_handler)
return logger
# 使用自定义日志器
logger = setup_custom_logger(__name__)
# 测试不同级别日志
logger.debug("调试信息:初始化配置") # 仅写入app_custom.log
logger.info("常规信息:用户登录成功") # 控制台+app_custom.log
logger.warning("警告信息:请求超时") # 控制台+app_custom.log
logger.error("错误信息:接口调用失败") # 控制台+app_custom.log+app_time.log
logger.critical("严重错误:数据库崩溃") # 控制台+app_custom.log+app_time.log日志过滤(按条件筛选)
python
import logging
class LevelFilter(logging.Filter):
"""自定义过滤器:只允许指定级别及以上的日志"""
def __init__(self, min_level):
self.min_level = min_level
def filter(self, record):
# record是日志记录对象,包含levelno(级别数字)、message等属性
return record.levelno >= self.min_level
# 配置日志
logger = logging.getLogger("filter_demo")
logger.setLevel(logging.DEBUG)
# 创建控制台处理器
console_handler = logging.StreamHandler()
console_handler.setFormatter(logging.Formatter("%(levelname)s - %(message)s"))
# 添加过滤器(只输出WARNING及以上)
console_handler.addFilter(LevelFilter(logging.WARNING))
logger.addHandler(console_handler)
# 测试
logger.debug("调试信息") # 被过滤,无输出
logger.info("常规信息") # 被过滤,无输出
logger.warning("警告信息")# 输出:WARNING - 警告信息
logger.error("错误信息") # 输出:ERROR - 错误信息模块功能速查表
| 组件 / 函数 | 功能说明 | 核心参数 / 用法 |
|---|---|---|
logging.getLogger(name) |
创建 / 获取日志器 | name = 日志器名称(推荐用__name__) |
logging.basicConfig() |
快速配置根日志器 | level = 日志级别,handlers = 处理器列表 |
logging.StreamHandler() |
控制台处理器 | 输出到 stdout,设置 level/formatter |
logging.FileHandler() |
文件处理器 | filename = 路径,encoding=utf-8 |
RotatingFileHandler |
按大小轮转的文件处理器 | maxBytes = 最大大小,backupCount = 备份数 |
TimedRotatingFileHandler |
按时间轮转的文件处理器 | when = 轮转单位,interval = 间隔 |
logging.Formatter() |
日志格式器 | fmt = 格式字符串,datefmt = 时间格式 |
logger.debug/info/warning/error/critical() |
记录不同级别日志 | msg = 日志消息,exc_info=True(记录异常) |
logging.exception() |
记录异常日志(自动含堆栈) | msg = 异常消息,在 except 块中使用 |
loggng 模块是 Python 日志处理的标准库,核心优势在于可配置性强、支持多输出目标、日志轮转、多级别控制 ,生产环境中务必替代
print()使用,遵循「不同级别日志分文件存储、按时间 / 大小轮转、包含关键上下文信息」的最佳实践,便于问题排查和日志管理。
8.8 文件读取模块
Python 处理文件读写的核心能力围绕 内置
open()函数 展开,配合os(路径 / 目录)、csv(CSV 专用)、json(JSON 专用)、pickle(序列化)等模块,覆盖「文本 / 二进制文件、批量读写、专用格式文件、大文件读写」等全场景。以下按「基础读写→进阶场景→专用格式→最佳实践」分类,提供可直接运行的代码示例,包含核心参数、避坑指南和实战技巧。
open() 是文件读写的基础,所有文件操作均基于此函数创建的文件对象。
| 参数 | 必选 | 说明 |
|---|---|---|
file |
是 | 文件路径(相对 / 绝对,如 "./test.txt"、"C:/data/log.txt") |
mode |
否 | 打开模式(核心!),常用值:- r:只读(文本,默认)- w:只写(覆盖原有内容,无则创建)- a:追加(文本,末尾添加,无则创建)- r+:读写(文本,不创建)- wb:二进制只写- ab:二进制追加- rb+:二进制读写 |
encoding |
否 | 文本编码(如 utf-8/gbk,二进制模式(rb/wb)禁止指定) |
errors |
否 | 编码错误处理:ignore(忽略)、replace(替换为�)、strict(报错,默认) |
newline |
否 | 换行符处理(\n/\r\n,newline="" 禁用自动转换,CSV/JSON 推荐) |
buffering |
否 | 缓冲策略:0(无缓冲,仅二进制)、1(行缓冲)、>1(指定字节缓冲) |
| 方法 | 说明 |
|---|---|
read(n) |
读:读取 n 个字符(文本)/ 字节(二进制),n=None 读取全部 |
readline() |
读:逐行读取(文本),返回一行内容(含换行符 \n) |
readlines() |
读:读取所有行到列表(每行含换行符) |
write(s) |
写:写入字符串(文本)/ 字节串(二进制),返回写入长度 |
writelines(lst) |
写:写入字符串列表(无自动换行,需手动加 \n) |
flush() |
写:强制刷新缓冲区(立即写入文件,不等待 with 结束) |
seek(offset) |
读写:移动文件指针(offset 为字节数,0= 开头,1= 当前,2= 末尾) |
tell() |
读写:返回当前文件指针位置(字节数) |
close() |
通用:关闭文件(with 语句自动调用,无需手动) |
写入文本文件(覆盖 / 追加)
python
# ========== 场景1:覆盖写入(w 模式) ==========
file_path = "text_write.txt"
# with 语句:自动关闭文件,避免资源泄漏
with open(file_path, mode="w", encoding="utf-8") as f:
# 写入单行
f.write("Python 文件写入示例\n")
# 写入多行(需手动加换行符)
lines = ["第2行内容\n", "第3行内容\n", "中文内容测试✅\n"]
f.writelines(lines)
print(f"覆盖写入完成,文件路径:{file_path}")
# ========== 场景2:追加写入(a 模式) ==========
with open(file_path, mode="a", encoding="utf-8") as f:
f.write("这是追加的内容\n")
print("追加写入完成")
# ========== 场景3:读取写入后的文件 ==========
with open(file_path, mode="r", encoding="utf-8") as f:
content = f.read() # 读取全部内容
print("文件最终内容:")
print(content)
# 输出结果:
# Python 文件写入示例
# 第2行内容
# 第3行内容
# 中文内容测试✅
# 这是追加的内容按行读写(中等文件,节省内存)
python
# 写入多行(按行构造)
write_lines = ["用户ID,姓名,年龄\n", "1001,张三,25\n", "1002,李四,30\n"]
with open("line_write.csv", mode="w", encoding="utf-8", newline="") as f:
f.writelines(write_lines)
# 按行读取(逐行处理,避免加载全部内容)
print("\n按行读取文件:")
with open("line_write.csv", mode="r", encoding="utf-8") as f:
header = f.readline().strip() # 读取表头
print(f"表头:{header}")
for idx, line in enumerate(f, 2): # 从第2行开始遍历
print(f"第{idx}行:{line.strip()}")
# 输出:
# 表头:用户ID,姓名,年龄
# 第2行:1001,张三,25
# 第3行:1002,李四,30二进制文件读写(图片 / 视频 / 压缩包等)
python
# ========== 场景:复制图片(二进制读写) ==========
src_img = "source.jpg" # 源图片(需提前准备)
dst_img = "copy.jpg" # 复制后的图片
# 读取源图片(rb 模式)
with open(src_img, mode="rb") as f:
img_data = f.read() # 读取二进制数据
print(f"源图片大小:{len(img_data)} 字节")
# 写入目标图片(wb 模式)
with open(dst_img, mode="wb") as f:
f.write(img_data) # 写入二进制数据
print(f"图片复制完成,目标路径:{dst_img}")
# 验证:读取复制后的图片
with open(dst_img, mode="rb") as f:
copy_data = f.read()
print(f"复制后图片大小:{len(copy_data)} 字节")
print(f"图片是否一致:{img_data == copy_data}") # 输出:TrueCSV 文件读写(表格数据,csv 模块)
python
import csv
# ========== 写入CSV文件 ==========
csv_file = "user_data.csv"
header = ["用户ID", "姓名", "年龄", "城市"]
rows = [
[1001, "张三", 25, "北京"],
[1002, "李四", 30, "上海"],
[1003, "王五", 28, "广州"]
]
# newline="" 避免CSV出现空行(Windows关键)
with open(csv_file, mode="w", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
writer.writerow(header) # 写入表头
writer.writerows(rows) # 写入多行数据
print(f"CSV文件写入完成:{csv_file}")
# ========== 读取CSV文件(字典格式,推荐) ==========
print("\n读取CSV文件(字典格式):")
with open(csv_file, mode="r", encoding="utf-8", newline="") as f:
reader = csv.DictReader(f)
for row in reader:
print(f"姓名:{row['姓名']},年龄:{row['年龄']},城市:{row['城市']}")
# 输出:
# 姓名:张三,年龄:25,城市:北京
# 姓名:李四,年龄:30,城市:上海
# 姓名:王五,年龄:28,城市:广州JSON 文件读写(结构化数据,json 模块)
python
import json
# ========== 写入JSON文件 ==========
json_file = "config.json"
config_data = {
"server": {
"host": "127.0.0.1",
"port": 8080,
"timeout": 30
},
"database": {
"name": "test_db",
"user": "root",
"password": "123456"
}
}
# indent=4 格式化输出(便于阅读),ensure_ascii=False 保留中文
with open(json_file, mode="w", encoding="utf-8") as f:
json.dump(config_data, f, indent=4, ensure_ascii=False)
print(f"JSON文件写入完成:{json_file}")
# ========== 读取JSON文件 ==========
with open(json_file, mode="r", encoding="utf-8") as f:
loaded_data = json.load(f) # 解析为Python字典
print("\n读取JSON文件:")
print(f"服务器地址:{loaded_data['server']['host']}:{loaded_data['server']['port']}")
print(f"数据库名:{loaded_data['database']['name']}")
# 输出:
# 服务器地址:127.0.0.1:8080
# 数据库名:test_db序列化文件读写(pickle 模块)
适用于保存 Python 复杂对象(如类实例、列表 / 字典嵌套)。
python
import pickle
# ========== 场景:保存/读取Python对象 ==========
class User:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return f"User(name={self.name}, age={self.age})"
# 写入序列化文件(wb 模式)
pickle_file = "user_data.pkl"
user1 = User("张三", 25)
user2 = User("李四", 30)
with open(pickle_file, mode="wb") as f:
pickle.dump([user1, user2], f) # 序列化列表对象
print(f"序列化文件写入完成:{pickle_file}")
# 读取序列化文件(rb 模式)
with open(pickle_file, mode="rb") as f:
loaded_users = pickle.load(f) # 反序列化为Python对象
print("\n读取序列化对象:")
for user in loaded_users:
print(user)
# 输出:
# User(name=张三, age=25)
# User(name=李四, age=30)核心模块 / 函数速查表
| 模块 / 函数 | 适用场景 | 核心优势 |
|---|---|---|
open(file, mode, encoding) |
所有文件读写(基础) | 原生支持,灵活度高 |
csv.writer/csv.DictReader |
CSV 表格文件 | 自动处理分隔符 / 换行,兼容 Excel |
json.dump/json.load |
JSON 结构化数据 | 跨语言兼容,自动解析为 Python 对象 |
pickle.dump/pickle.load |
Python 对象序列化 | 支持所有 Python 对象,无需手动解析 |
glob.glob(pattern) |
批量匹配文件路径 | 通配符(*.txt/**/*.txt) |
os.path.join/path.exists |
路径处理 / 校验 | 跨平台兼容,避免路径分隔符问题 |
文件读写是 Python 最基础的 IO 操作,核心原则:文本文件指定编码,二进制文件用 rb/wb 模式,大文件分块处理,专用格式用专用模块,所有操作套 with 语句。掌握以上场景和技巧,可覆盖 99% 的文件读写需求。
8.9 json库
json 库是 Python 处理 JSON 数据的标准库,支持Python 基础类型与 JSON 字符串的双向转换,是跨语言数据交互(如 API 接口、配置文件、前端通信)的核心工具。以下按「核心函数→基础用法→进阶场景→避坑指南」展开,提供可直接运行的代码示例,覆盖 99% 的 JSON 处理需求。
核心函数
| 函数 | 功能 | 输入 / 输出 |
|---|---|---|
json.dumps() |
Python 对象 → JSON 字符串 | 输入:Python 对象;输出:str |
json.dump() |
Python 对象 → JSON 文件 | 输入:Python 对象 + 文件句柄;无返回 |
json.loads() |
JSON 字符串 → Python 对象 | 输入:str;输出:Python 对象 |
json.load() |
JSON 文件 → Python 对象 | 输入:文件句柄;输出:Python 对象 |
json.JSONEncoder |
自定义序列化类(扩展支持复杂对象) | 需重写 default() 方法 |
json.JSONDecoder |
自定义反序列化类(扩展解析逻辑) | 需重写 decode() 方法 |
序列化:Python 对象 → JSON(dumps/dump)
1.json.dumps():转 JSON 字符串
python
import json
# 基础 Python 对象(仅包含 json 支持的类型)
data = {
"name": "张三",
"age": 25,
"is_student": False,
"scores": [90.5, 85, 98],
"address": None,
"hobbies": ["篮球", "编程"]
}
# 基础序列化(默认 ASCII 编码,中文会转义)
json_str_basic = json.dumps(data)
print("基础序列化(中文转义):")
print(json_str_basic)
# 输出:{"name": "\u5f20\u4e09", "age": 25, "is_student": false, ...}
# 优化:保留中文 + 格式化输出(易读)
json_str_pretty = json.dumps(
data,
ensure_ascii=False, # 禁用 ASCII 编码,保留中文
indent=4, # 缩进 4 个空格,格式化
sort_keys=True # 按键排序(可选)
)
print("\n优化后序列化(中文+格式化):")
print(json_str_pretty)
# 输出:
# {
# "address": null,
# "age": 25,
# "hobbies": [
# "篮球",
# "编程"
# ],
# "is_student": false,
# "name": "张三",
# "scores": [
# 90.5,
# 85,
# 98
# ]
# }2.json.dump():直接写入 JSON 文件
python
# 序列化到文件(指定 UTF-8 编码,避免中文乱码)
with open("data.json", "w", encoding="utf-8") as f:
json.dump(
data,
f,
ensure_ascii=False,
indent=2
)
print("\nJSON 文件写入完成:data.json")反序列化:JSON → Python 对象(loads/load)
1.json.loads():解析 JSON 字符串
python
import json
# 待解析的 JSON 字符串(含中文)
json_str = '''
{
"name": "李四",
"age": 30,
"is_student": true,
"scores": [88, 92.5],
"address": null
}
'''
# 反序列化为 Python 对象
python_obj = json.loads(json_str)
print("JSON 字符串反序列化结果:")
print(f"类型:{type(python_obj)}") # <class 'dict'>
print(f"姓名:{python_obj['name']},年龄:{python_obj['age']}")
print(f"是否学生:{python_obj['is_student']}")
# 输出:
# 类型:<class 'dict'>
# 姓名:李四,年龄:30
# 是否学生:True2.json.load():从文件读取并解析
python
# 从 JSON 文件反序列化
with open("data.json", "r", encoding="utf-8") as f:
loaded_data = json.load(f)
print("\nJSON 文件反序列化结果:")
print(f"爱好:{loaded_data['hobbies']}")
print(f"分数列表:{loaded_data['scores']}")
# 输出:
# 爱好:['篮球', '编程']
# 分数列表:[90.5, 85, 98]最佳实践代码模板
python
import json
import os
def safe_json_dump(obj, file_path, indent=4, ensure_ascii=False):
"""安全写入 JSON 文件(自动创建目录、异常捕获)"""
try:
# 创建父目录(如果不存在)
dir_path = os.path.dirname(file_path)
if dir_path and not os.path.exists(dir_path):
os.makedirs(dir_path, exist_ok=True)
# 写入文件
with open(file_path, "w", encoding="utf-8") as f:
json.dump(obj, f, indent=indent, ensure_ascii=ensure_ascii)
return True
except Exception as e:
print(f"JSON 写入失败:{e}")
return False
def safe_json_load(file_path):
"""安全读取 JSON 文件(异常捕获)"""
try:
with open(file_path, "r", encoding="utf-8") as f:
return json.load(f)
except FileNotFoundError:
print(f"文件不存在:{file_path}")
except json.JSONDecodeError:
print(f"JSON 格式错误:{file_path}")
except Exception as e:
print(f"JSON 读取失败:{e}")
return None
# 测试模板
test_data = {"name": "模板测试", "value": 123}
safe_json_dump(test_data, "temp/test.json")
loaded_data = safe_json_load("temp/test.json")
print(f"\n模板测试结果:{loaded_data}")json 库是 Python 跨语言数据交互的核心工具,核心掌握 dumps/dump/loads/load 四个基础函数,进阶场景通过 default/object_hook 或自定义编码器扩展对复杂对象的支持。遵循「保留中文、指定编码、异常捕获、特殊类型单独处理」的原则,可高效解决各类 JSON 处理问题。