论文题目:CCASeg: Decoding Multi-Scale Context with Convolutional Cross-Attention for Semantic Segmentation(基于卷积交叉注意的语义分割多尺度上下文解码)
会议:WACV2025
摘要:在特征映射中捕获多尺度上下文对于语义分割至关重要。随着视觉变压器(ViT)的成功,最近的模型已经设计了变压器解码器来捕获它。然而,由于注意机制的固有性质和结构约束,这些模型在利用不同的语境信息方面存在局限性。通常,导致每个令牌特征具有相似接受域的多头注意是以显著增加的计算成本为代价实现的。结构的性质会导致不同层次的信息组合不一致。为了解决这一问题,本文提出了一种新颖有效的解码方案------基于卷积交叉注意(CCA)的CCASeg。所提出的CCA和解码结构不仅可以通过不同大小的卷积核捕获局部和全局上下文,而且可以通过有效利用廉价的卷积操作来实现高效率。此外,译码结构保证了信息在不同层次上的连续组合,便于理解不同的语境。因此,这种新的解码方案使特征映射能够有效地学习不同大小对象之间的关系。通过这种方式,我们提出的CCASeg在流行的语义分割基准上优于以前最先进的方法,包括ADE20K, cityscape, COCO-stuff和iSAID。

CCASeg------用卷积交叉注意力破解语义分割的多尺度难题
引言:语义分割面临的挑战
想象你正在开发一个自动驾驶系统,需要让AI同时识别道路上的各种物体------远处的交通标志、近处的行人、地面的车道线。这些物体尺寸差异巨大,如何让模型既能"看清"大物体,又不漏掉小细节?这正是语义分割中多尺度上下文捕获的核心挑战。
今天要介绍的这篇WACV 2025论文《CCASeg: Decoding Multi-Scale Context with Convolutional Cross-Attention for Semantic Segmentation》,提出了一个优雅的解决方案。
问题诊断:现有方法哪里不够好?
1. 简单解码器的无力感
尽管Vision Transformer等强大的编码器能提取丰富的多层级特征,但很多模型仍用简单的MLP或卷积层作为解码器。这就像有了米其林三星的食材,却用微波炉加热------没有充分发挥潜力。
2. Transformer解码器的两难困境
近期一些方法尝试用Transformer解码器(如FeedFormer),但遇到了两个本质问题:
计算成本高昂: 多头注意力(MHA)的计算复杂度与token数量的平方成正比。为了覆盖不同尺度,需要大量的注意力头,代价极大。
感受野受限: 将特征图分割成固定大小的token后,每个token的感受野是静态的。虽然可以通过多层堆叠扩大感受野,但这种"逐步扩张"的方式效率低下,且难以同时兼顾局部细节和全局语义。
论文用图1直观展示了这个问题:SegFormer和FeedFormer能识别大物体(如窗户),但在小物体(如红色画作、银色时钟)上表现不佳。
创新方案:CCASeg的三板斧
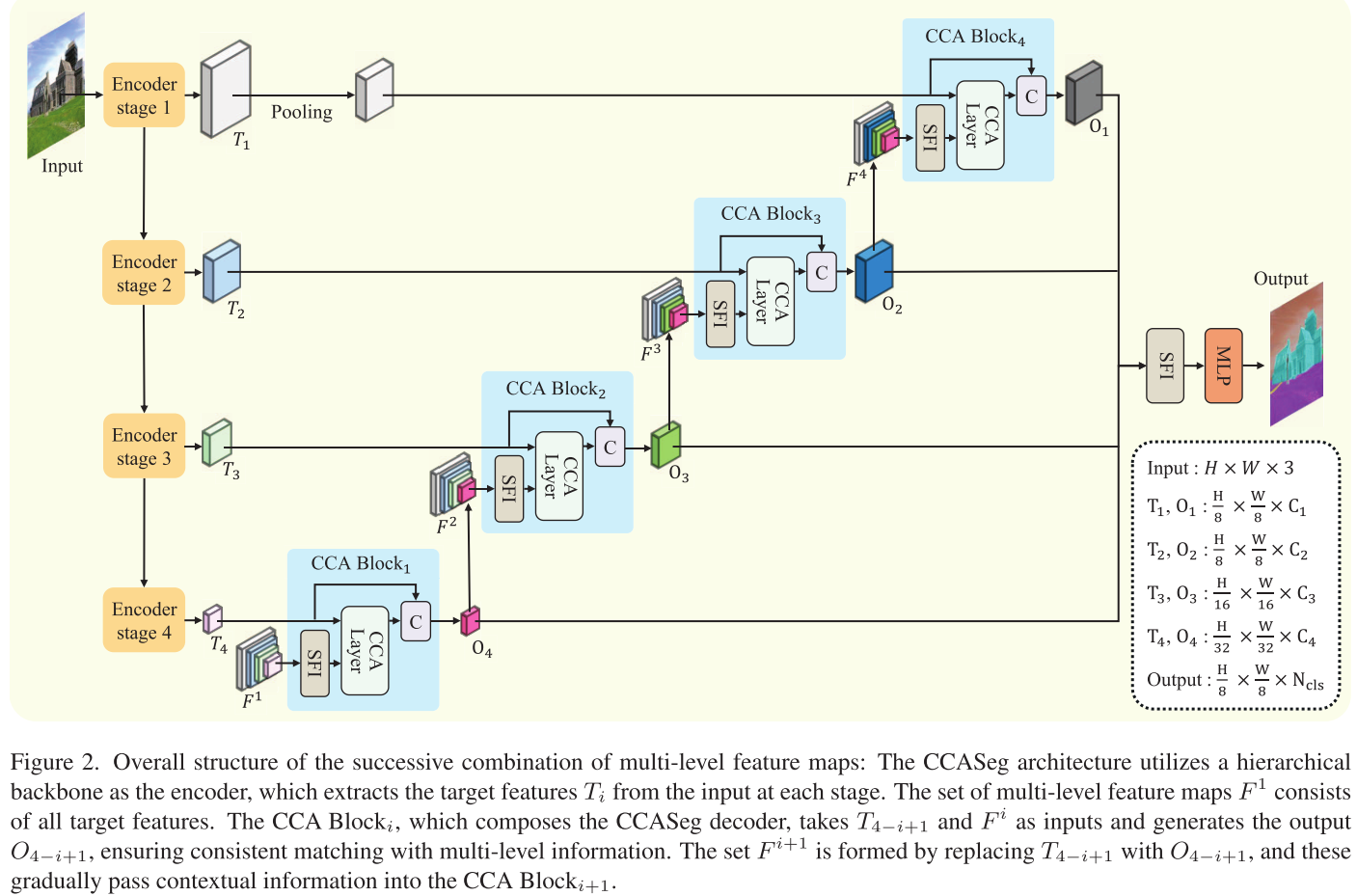
第一板斧:卷积交叉注意力(CCA)
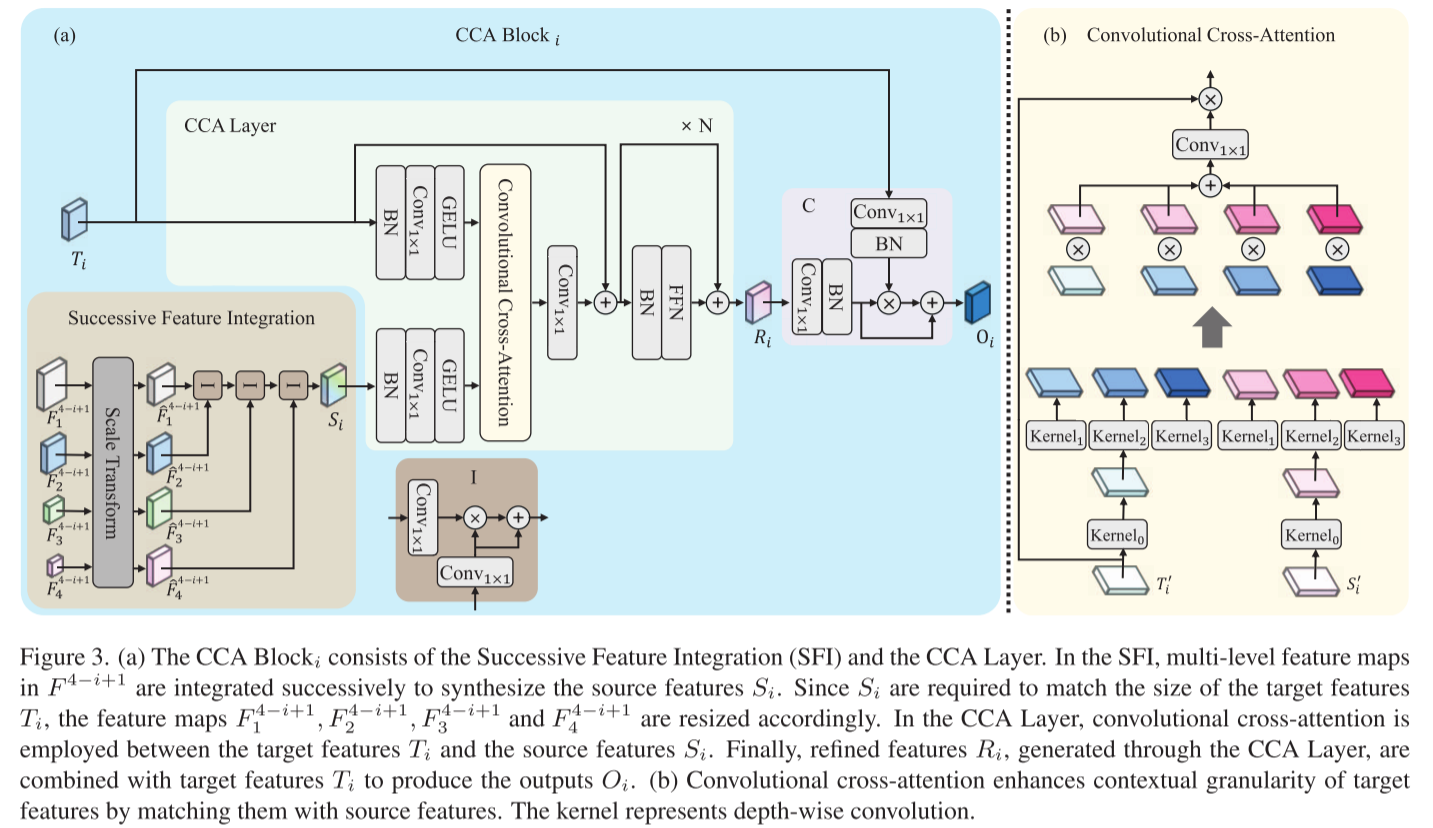
核心思想: 与其把特征图切成固定token,不如直接用不同大小的卷积核来捕获多尺度信息!
具体做法:
# 伪代码示意
T' = GELU(Conv1x1(BN(Target_Features)))
S' = GELU(Conv1x1(BN(Source_Features)))
# 使用4个不同尺寸的深度卷积核
W = Conv1x1(
Kernel0(T') × Kernel0(S') + # 恒等连接
Kernel1(T') × Kernel1(S') + # 如5×5
Kernel2(T') × Kernel2(S') + # 如7×7
Kernel3(T') × Kernel3(S') # 如11×11
)
Refined = Conv1x1(W × T') + T' # 残差连接妙处在哪?
- 多尺度天然支持: 3×3卷积捕获局部细节,13×13卷积捕获全局上下文,一次前向传播搞定
- 计算高效: 使用条带卷积(如11×1和1×11组合)近似大卷积核,比标准卷积更轻量
- 特别适合条状物体: 条带卷积对道路、建筑边缘等场景特别有效
第二板斧:连续特征集成(SFI)
传统方法简单地把不同层级的特征拼接起来,但CCASeg认为"顺序很重要"!
传统方法:
Concat([F1, F2, F3, F4]) # 一锅烩CCASeg的SFI:
S = I(I(I(F1, F2), F3), F4) # 从低层到高层逐级融合
其中 I(A,B) = Conv(A) × Conv(B) + Conv(B) # 带残差的乘法融合这种"连续积累"的方式确保了:
- 低层的细节信息逐级传递到高层
- 高层的语义信息通过残差连接得到保留
- 整个过程保持上下文的层次一致性
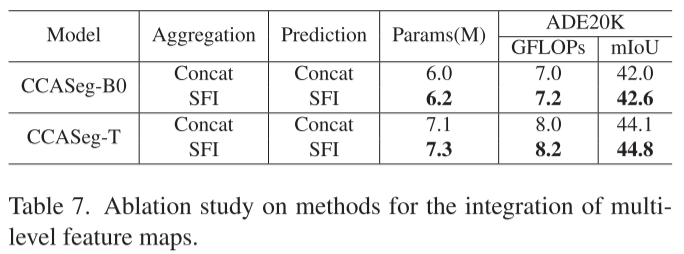
实验验证: 如表7所示,SFI相比简单拼接,在几乎不增加计算量的情况下,精度提升0.6-0.7%。
第三板斧:渐进式解码架构
CCASeg的解码器由4个CCA Block组成,设计非常巧妙:
第一个CCA Block:
- 输入:T4(最深层特征)+ 所有编码器特征{T1, T2, T3, T4}
- 输出:O4(精炼后的特征)
第二个CCA Block:
- 输入:T3 + {T1, T2, T3, O4}(注意T4被O4替换了)
- 输出:O3
以此类推,每个Block都会:
- 接收当前层的目标特征
- 结合所有层级的信息(包括前面Block的输出)
- 产生更精炼的特征传递给下一个Block
这种设计确保了多层级信息的完整利用 和上下文的连续性。
实验结果
1. 在ADE20K上的表现
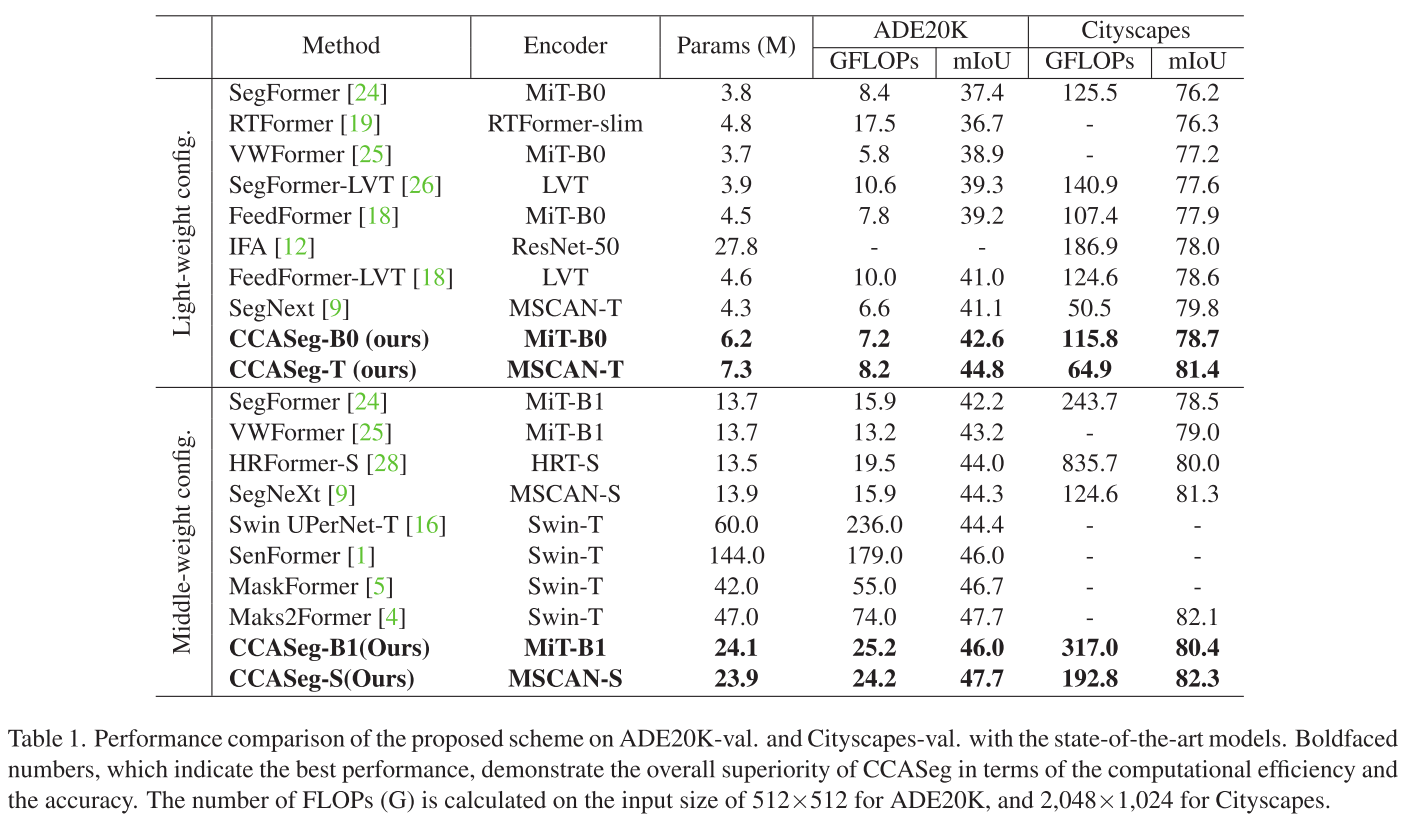
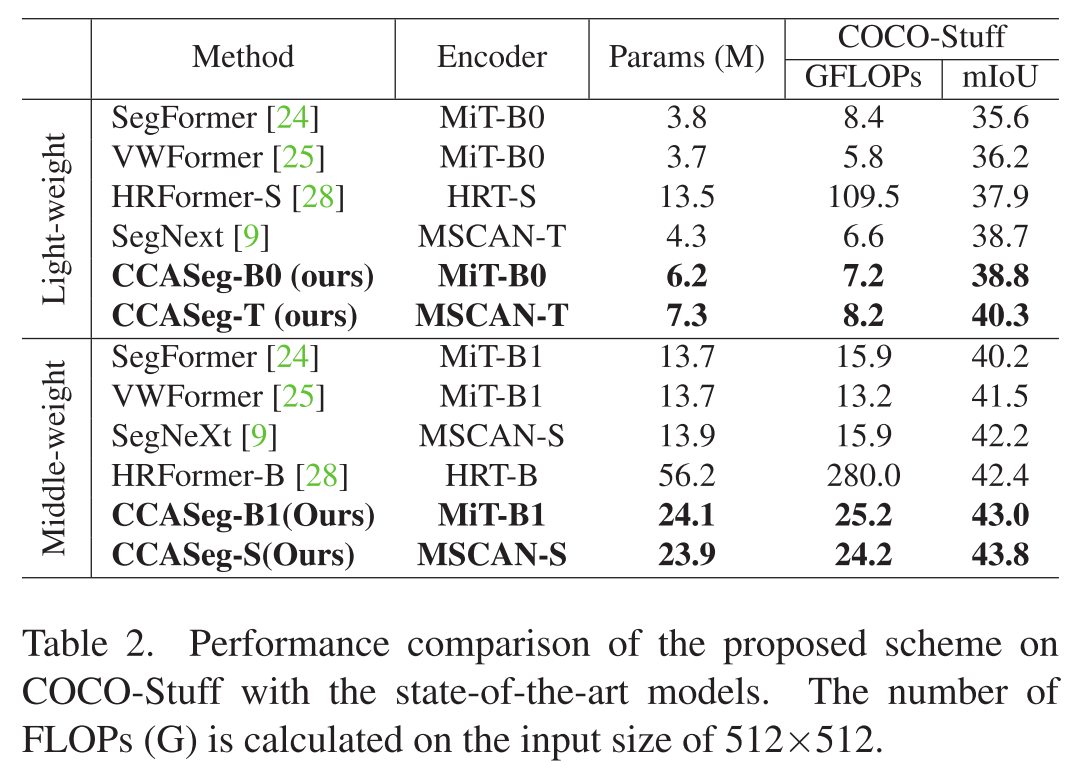
这是一个包含150个类别的室内场景数据集,非常具有挑战性。
轻量级对比:
- CCASeg-T(7.3M参数,8.2 GFLOPs)达到44.8% mIoU
- 对比SegNext-T:参数↓47.5%,计算量↓48.4%,精度↑0.5%
- 对比SegFormer-B1(使用更强编码器):参数↓54.7%,计算量↓54.7%,精度↑0.4%
中等权重对比:
- CCASeg-S(23.9M参数,24.2 GFLOPs)达到47.7% mIoU
- 对比Mask2Former:参数↓49.1%,计算量↓67.3%,精度持平
2. 在Cityscapes上的表现
这是自动驾驶场景的经典数据集。
- CCASeg-T: 81.4% mIoU(64.9 GFLOPs)
- CCASeg-S: 82.3% mIoU(192.8 GFLOPs)
- 显著优于同等计算量的其他方法
3. 在遥感图像iSAID上的突破
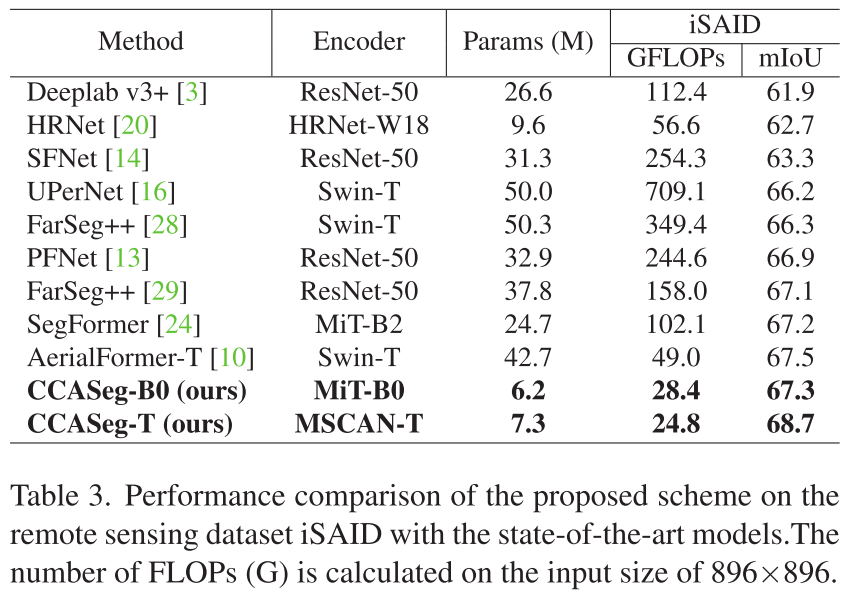
这个数据集特别有意思,因为航空图像中物体尺度差异极大。
- CCASeg-T达到68.7% mIoU,超越所有对比方法
- 对比SegFormer-B2:参数↓74.9%,计算量↓72.2%,精度持平
- 证明了CCASeg不仅适用于自然图像,也适用于遥感场景
4. 定性结果
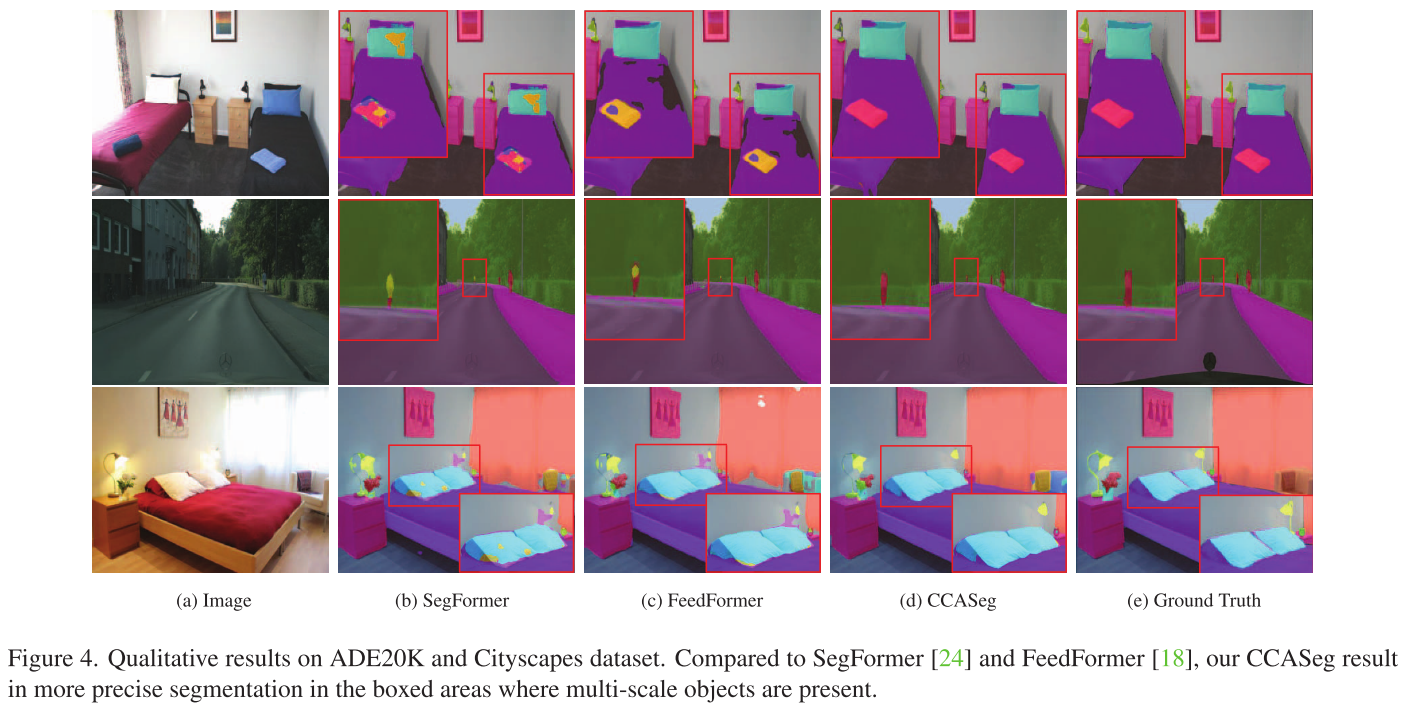
图4展示了对比结果,在多尺度物体混合的场景中:
- 大物体(道路、床): 三种方法都能识别
- 小物体(行人、枕头): CCASeg明显更准确
- 边界细节: CCASeg的分割边界更清晰

图5在航空图像上的对比更明显,CCASeg能准确分割密集的小物体(如停车场的汽车),而AerialFormer则模糊一片。
消融实验:每个设计都有用吗?
1. CCA vs. 传统多头注意力
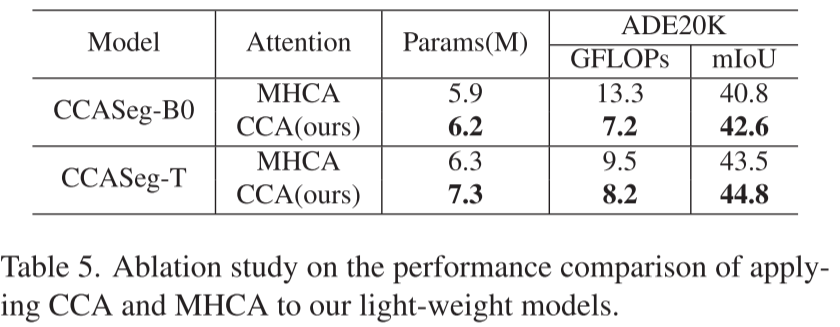
表5对比了CCA和MHCA(Multi-Head Cross Attention):
| 模型 | 注意力类型 | GFLOPs | mIoU |
|---|---|---|---|
| CCASeg-B0 | MHCA | 13.3 | 40.8 |
| CCASeg-B0 | CCA | 7.2 | 42.6 |
结论: CCA不仅快(计算量↓45.9%),而且准(精度↑1.8%)!
2. 应用到不同阶段
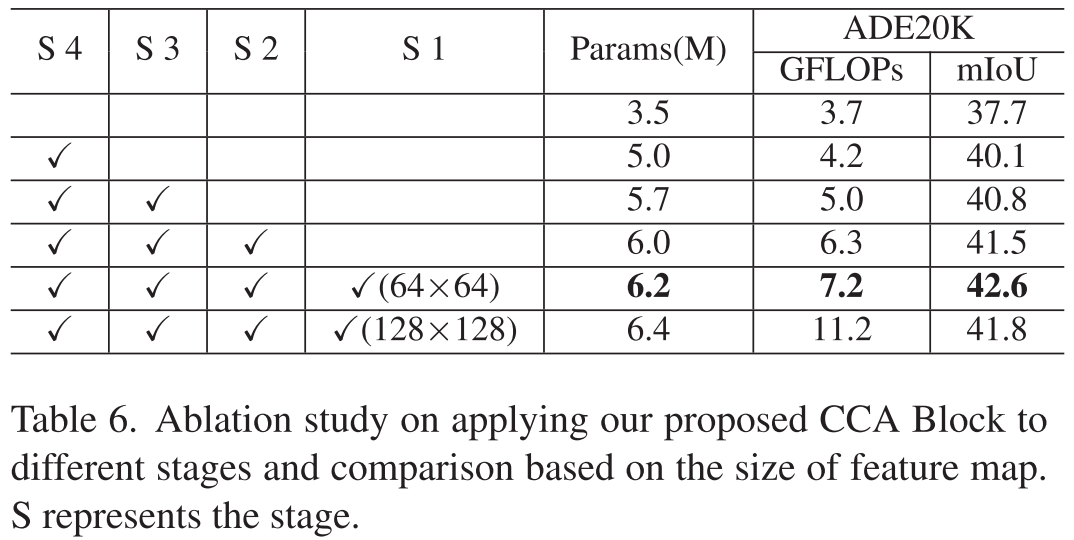
表6测试了在不同编码器阶段应用CCA Block的效果:
- 只应用到Stage 4:37.7% mIoU
- 应用到Stage 4+3:40.8% mIoU
- 应用到Stage 4+3+2:41.5% mIoU
- 应用到全部4个阶段 :42.6% mIoU(最佳)
结论: 越多阶段应用CCA,效果越好------充分验证了多层级信息整合的重要性。
3. 兼容性测试
表4测试了CCASeg解码器与不同编码器的兼容性:
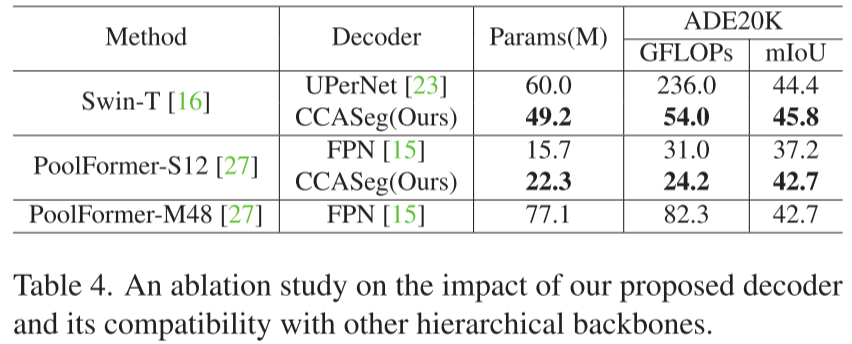
Swin Transformer编码器:
- UPerNet解码器:60.0M参数,236.0 GFLOPs,44.4% mIoU
- CCASeg解码器 :49.2M参数,54.0 GFLOPs,45.8% mIoU
- 参数↓18.0%,计算量↓77.1%,精度↑1.4%
PoolFormer-S12编码器:
- FPN解码器:15.7M参数,31.0 GFLOPs,37.2% mIoU
- CCASeg解码器 :22.3M参数,24.2 GFLOPs,42.7% mIoU
- 精度↑5.5%(这个提升非常显著!)
结论: CCASeg解码器是通用的,能大幅提升各种编码器的性能。
技术亮点总结
1. 设计哲学的转变
- 从"token化+注意力"转向"卷积核+多尺度"
- 用卷积的归纳偏置(locality + multi-scale)替代注意力的灵活性
2. 效率与精度的平衡
- 条带卷积:用11×1和1×11近似11×11,既省计算又适合条状物体
- 深度可分离卷积:进一步降低参数量
- 残差连接:确保梯度流动和信息保留
3. 结构性创新
- SFI的"连续积累"机制确保层次一致性
- 渐进式解码器设计确保信息的充分利用
适用场景与局限
适用场景:
- 自动驾驶:道路、车辆、行人等多尺度物体混合
- 医学影像:器官(大)、病灶(小)同时检测
- 遥感图像:建筑、道路、车辆等尺度差异大
- 室内场景理解:家具、小物件共存
可能的局限:
- 条带卷积对圆形物体可能不如矩形物体有效
- 需要4个CCA Block,深度较大,推理延迟可能略高
- 论文未讨论在极端尺度比(如蚂蚁 vs 大象)下的表现
未来展望
- 动态卷积核: 能否根据输入自适应选择卷积核大小?
- 3D扩展: CCASeg能否应用到视频或医学3D图像?
- 与Transformer融合: 能否结合MHA的长距离建模和CCA的多尺度捕获?
结语
CCASeg用一个简洁而优雅的思路------"用卷积的多尺度特性替代注意力的全局建模"------解决了语义分割中的多尺度难题。它不是简单的工程堆叠,而是对问题本质的深刻洞察:
语义分割需要的不是无限的感受野,而是恰到好处的多尺度感受野组合。
对于研究者,这篇论文提供了一个新的范式;对于工程师,CCASeg提供了一个高效实用的工具。如果你正在做语义分割相关的工作,不妨试试这个方法------它可能会给你带来惊喜!