Mistral AI:欧洲的开源大模型新势力,如何搅动全球AI格局?
作者:Weisian
科技观察者 · 开源社区践行者 · AIGC实践者 · 相信技术应该像空气一样自由流动

哈喽,各位关注前沿AI的朋友!
最近半年,如果你有在追踪开源大模型的动态,一定反复听到一个名字:Mistral AI 。
它没有 OpenAI 的明星光环,也没有 Google 的万亿美元市值背书,却凭借几款"小而美、强而快"的开源模型,在全球开发者社区掀起一阵旋风。
更令人惊讶的是------这家成立不到两年的公司,估值已突破 60 亿欧元 ,成为欧洲有史以来成长最快的 AI 初创企业;它的模型被 Hugging Face、Perplexity、Microsoft 等巨头争相集成;甚至 Meta 的 Llama 团队都公开表示:"Mistral 是我们最尊重的对手。"
那么,Mistral AI 到底是谁?它凭什么在英美主导的 AI 战场中杀出一条血路?
更重要的是------作为普通开发者或技术爱好者,我们该如何用好 Mistral 的模型?
今天,我就带大家深入拆解这家神秘又高效的欧洲 AI 新锐,从创始人故事、技术哲学、产品矩阵到实战指南,一文讲透 Mistral AI 的全貌。
无论你是想微调本地模型、搭建智能应用,还是单纯好奇"欧洲能否诞生自己的 OpenAI",这篇内容都值得你耐心读完。
一、Mistral AI 是谁?一家"反硅谷"风格的欧洲 AI 新贵
1.1 成立背景:三位法国天才的"理想主义突围"
Mistral AI 成立于 2023 年 4 月 ,总部位于法国巴黎。
它的三位联合创始人个个来头不小:
- Arthur Mensch(CEO):前 Google DeepMind 研究科学家,专注高效 Transformer 架构;
- Timothée Lacroix(CTO):前 Meta FAIR 工程师,参与过 Llama 早期训练系统开发;
- Guillaume Lample(首席科学家):图灵奖级研究者,曾提出"无监督机器翻译"里程碑工作。
有趣的是,他们本可以留在硅谷拿百万年薪,却选择回到欧洲创业。
原因很简单:他们厌倦了大模型竞赛中的"参数军备竞赛"。

"我们不需要 1 万亿参数才能有用。我们要做的是:在有限资源下,榨干每一比特算力的价值。"
------ Arthur Mensch,Mistral AI CEO
这种"效率优先、实用至上"的理念,贯穿了 Mistral 所有产品的基因。
1.2 快速崛起:从零到欧洲 AI 之光
Mistral AI 虽然成立于 2023 年,但其影响力迅速席卷全球:
- 2023 年 9 月 :发布首个开源模型 Mistral 7B,性能碾压 Llama 2 13B,震惊社区;
- 2023 年 12 月 :推出多语言混合专家模型 Mixtral 8x7B,支持 MoE 架构,推理成本降低 6 倍;
- 2024 年 6 月 :发布闭源旗舰 Mistral Large,支持 32K 上下文、多语言、代码生成,对标 GPT-4;
- 2025 年初:与 Microsoft 达成战略合作,Mistral Large 集成至 Azure AI 和 Copilot;
- 2025 年中 :完成 C 轮融资,估值达 60 亿欧元,法国政府将其列为"国家战略科技项目"。
短短两年,Mistral 不仅成为欧洲 AI 的希望,更在全球开源生态中占据了不可替代的位置。
1.3 与 Hugging Face 的核心关系:"优质内容提供者" × "顶级分发平台"
很多新手会疑惑:"为什么不直接去 Mistral 官网用,非要去 Hugging Face?"
核心原因就在于两者的互补关系:
- Mistral AI 是「优质模型的生产者」------专注于研发高性能开源大模型;
- Hugging Face 是「全球最大的 AI 生态平台」------提供模型托管、工具库、社区交流等全链路服务。
简单说:Mistral 把自己研发的模型"放在" Hugging Face 上供全球开发者使用,而 Hugging Face 提供了简单易用的工具和环境,让我们能轻松调用、微调这些模型,不用自己解决复杂的技术适配问题。
这就像:Mistral 是一家优质面包房,Hugging Face 是一个大型超市------面包房把面包放到超市售卖,超市还提供了试吃、包装、配送服务,让消费者能轻松买到并享用面包。
二、技术哲学:不做"更大",只做"更聪明"
如果说 OpenAI 追求的是"通用智能的奇点",Google 追求的是"全能助手",
那么 Mistral AI 的信条就是:在现实约束下,实现最优性价比的智能。
2.1 核心理念一:小模型,大智慧
Mistral 坚信:7B 参数是当前开源模型的"黄金尺寸" 。
为什么?
- 可在消费级 GPU(如 RTX 4090)上全精度运行;
- 推理速度快,适合实时应用场景;
- 微调成本低,个人开发者也能负担。
但"小"不等于"弱"。通过以下技术创新,Mistral 7B 在多项基准测试中超越 Llama 2 13B 甚至接近 Llama 3 8B:
- Sliding Window Attention(滑动窗口注意力):大幅降低长文本内存占用;
- Grouped Query Attention(分组查询注意力):提升推理吞吐量;
- 高质量合成数据训练:用算法生成比人工标注更一致的训练样本。

2.2 核心理念二:混合专家(MoE)不是噱头,而是未来
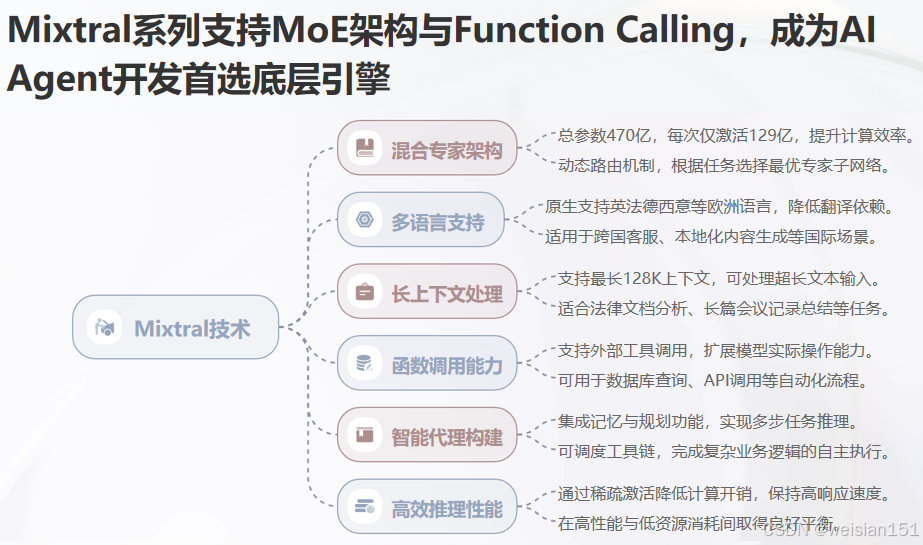
2023 年底发布的 Mixtral 8x7B 是 Mistral 的"王炸"之作。
它采用 Mixture of Experts(MoE)架构:总参数约 47B,但每次推理只激活其中 2 个专家(约 12.9B),实现"大模型能力 + 小模型成本"。
效果惊人:
- 在 MT-Bench、HumanEval、MMLU 等榜单全面领先;
- 支持英语、法语、德语、西班牙语、意大利语等主流欧洲语言;
- 完全开源权重和推理代码,Hugging Face 一键加载。
Mixtral 的出现,直接推动了整个开源社区从"密集模型"向"稀疏模型"转型。

2.3 核心理念三:开源是底线,闭源是选项
Mistral 采取 "双轨策略":
- 基础模型(7B、Mixtral)完全开源,MIT 许可,可商用;
- 高端模型(Mistral Large、Mistral Small)闭源 API,用于商业变现。
这种模式既赢得了开发者信任,又保障了公司可持续发展。
正如 CTO Timothée Lacroix 所说:
"我们开源,是因为相信社区的力量;我们闭源,是为了活下去继续创新。"

三、产品矩阵:从本地部署到云端服务,全覆盖
Mistral AI 的产品线清晰分为两类:开源模型 与 商业 API。
3.1 开源模型家族(免费 + 可商用)
Mistral 在 Hugging Face 上发布了多个系列模型,覆盖从基础对话到多模态的多种需求。新手不用贪多,先掌握这几个核心模型就够了,我按"易用性+实用性"排序整理如下:
(1)入门首选:Mistral-7B 系列(中小参数天花板)
这是 Mistral 最经典的入门模型,参数规模 70 亿,也是开源领域中小参数模型的"标杆"之一。
- 核心优势:体积小(单精度约 28GB,量化后可在 8GB 显存 GPU 运行)、速度快、通用性强,支持文本生成、问答、摘要、翻译等多种任务;
- 代表模型 :
Mistral-7B-v0.1(基础版)Mistral-7B-v0.3(升级版,支持更长上下文)Mistral-7B-Instruct-v0.2(指令微调版,对话更自然)
- 查找方式:打开 Hugging Face 官网 → 搜索"Mistral-7B" → 优先选择"mistralai"官方账号发布的模型(避免非官方微调的低质量版本)。
(2)进阶选择:Mixtral 系列(多专家模型,性能更强)
如果觉得 7B 模型性能不够,可以试试 Mixtral 系列,它采用"多专家(MoE)"架构,相当于把多个小模型组合起来工作,性能大幅提升。
- 核心优势:同等算力下性能优于单专家模型,支持更长上下文(部分版本支持 128k tokens),适合复杂文本生成、长文档处理等任务;
- 代表模型 :
Mixtral-8x7B-v0.1(8 个 7B 专家,总参数 56 亿)Mixtral-8x7B-Instruct-v0.1(指令微调版,对话体验更好)
- 注意事项:虽然总参数高,但实际推理时只激活部分专家,显存需求比同等参数的单模型低,8GB 以上显存 GPU 可尝试量化版本。
(3)多模态探索:Mistral-v0.3 多模态版(文本+图像)
这是 Mistral 推出的首个多模态模型,支持文本生成和图像理解,适合做图文问答、图像描述等任务。
- 核心优势:延续了 Mistral 系列的高性能,图像理解准确率高,文本生成流畅;
- 使用场景:上传一张图片,让模型描述内容、回答关于图片的问题(比如"这张图片里有什么物品?""帮我写一段关于这张风景图的文案");
- 查找方式:搜索"Mistral-v0.3",选择"mistralai"官方发布的多模态版本,注意查看模型说明中的图像输入要求。
(4)模型选择小技巧(新手避坑)
- 优先选"指令微调版(Instruct)":如果做对话、问答类任务,指令微调版比基础版更懂人类意图,不用复杂提示词;
- 看清楚许可证:Mistral 的模型大多采用 Apache 2.0 许可证,允许商用,但部分微调模型可能有额外限制,商用前务必查看模型详情页的"License"说明;
- 参考下载量和评分:Hugging Face 模型详情页会显示"Downloads"(下载量)和"Likes"(点赞数),下载量高、点赞多的模型质量更有保障。
| 模型 | 发布时间 | 特点 | 适用场景 |
|---|---|---|---|
| Mistral 7B | 2023.09 | 单体 7B,高性能,低资源 | 本地部署、边缘设备、教学 |
| Mistral 7B Instruct | 2023.10 | 经过指令微调,对话友好 | 聊天机器人、客服助手 |
| Mixtral 8x7B | 2023.12 | MoE 架构,47B 总参,12.9B 激活 | 高质量生成、多语言任务 |
| Mixtral 8x7B Instruct | 2024.01 | 指令优化版,支持 function calling | Agent 开发、工具调用 |
| Mistral Small(部分开源) | 2024.06 | 轻量闭源,API 可用 | 移动端、低延迟场景 |
所有开源模型均托管于 Hugging Face Hub ,支持 transformers、vLLM、llama.cpp 等主流框架。
3.2 商业 API 服务(按 token 计费)
通过 Mistral AI 官网 或 Azure 提供:
- Mistral Small:快速、便宜,适合简单任务;
- Mistral Medium:平衡性能与成本(尚未完全开放);
- Mistral Large:旗舰模型,支持 32K 上下文、代码生成、多模态推理(计划中)。
优势:
- 响应速度极快(平均 < 800ms);
- 支持流式输出、函数调用、JSON 模式;
- 数据隐私承诺:不存储用户输入。
四、实操指南:3 步在 Hugging Face 调用 Mistral 模型(新手零门槛)
最核心的部分来了!新手跟着这 3 步走,10 分钟就能完成首次调用 Mistral 模型。以最常用的"Mistral-7B-Instruct-v0.2"为例,全程用 Hugging Face 的 Transformers 库,简单到复制代码就能跑~
4.1 第一步:准备环境(安装必要工具)
首先要安装 Hugging Face 的核心工具库,以及运行模型需要的框架(推荐 PyTorch,兼容性最好)。
bash
pip install transformers datasets torch accelerate sentencepiece说明:
transformers:Hugging Face 核心模型调用库;torch:PyTorch 框架,用于运行模型;accelerate:用于优化模型运行,支持低显存设备;sentencepiece:Mistral 模型的分词工具,必须安装。
4.2 第二步:获取模型访问权限(关键!避免报错)
Mistral 的部分模型需要先在 Hugging Face 上申请访问权限,才能下载使用(比如 Mistral-7B 系列),步骤很简单:
- 注册/登录 Hugging Face 账号:打开官网(https://huggingface.co/),用邮箱或 GitHub 账号注册登录;
- 找到目标模型:搜索"mistralai/Mistral-7B-Instruct-v0.2",进入模型详情页;
- 申请访问:点击页面右上角的"Request access",按照提示填写申请理由(随便写一句"个人学习使用"即可),提交后一般几分钟内就会通过(官方审核很宽松);
- 获取访问令牌(Token):登录后,点击右上角头像 → 选择"Settings" → 左侧找到"Access Tokens" → 点击"New token",创建一个令牌(权限选"read"即可),复制保存好,后续调用需要用。
4.3 第三步:调用模型(复制代码就能跑)
打开你的 Python 开发工具(新手用 VS Code、PyCharm 都可以,甚至用 IDLE 也能跑),复制以下代码,替换掉其中的"你的 Hugging Face 令牌",运行即可。
python
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
# 1. 加载模型和分词器
model_name = "mistralai/Mistral-7B-Instruct-v0.2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto", # 自动适配设备精度
device_map="auto", # 自动分配模型到可用设备(CPU/GPU)
use_auth_token="你的Hugging Face令牌" # 替换成你刚才复制的令牌
)
# 2. 创建对话管道(适合问答/聊天任务)
chat_pipeline = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512, # 最大生成文本长度
temperature=0.7, # 生成多样性(数值越小越稳定,越大越随机)
top_p=0.95,
repetition_penalty=1.1 # 避免重复生成
)
# 3. 输入问题,获取模型输出
prompt = """你是一个乐于助人的AI助手,请用简洁的语言回答问题。
用户:请介绍一下Hugging Face平台的核心功能。
助手:"""
result = chat_pipeline(prompt)
print(result[0]["generated_text"].split("助手:")[-1])4.4 运行结果与常见问题解决
成功运行后,模型会输出类似这样的内容:
Hugging Face 是集模型仓库、开发工具、社区交流于一体的 AI 生态平台,核心功能包括:1. 模型仓库(Model Hub),托管全球数百万开源模型;2. 开发工具库(如 Transformers、Datasets),降低 AI 开发门槛;3. 应用展示平台(Spaces),可零代码部署 AI demo;4. 社区交流板块,方便开发者分享经验、协作开发。
新手常见问题解决:
- ① 显存不足报错 :如果你的 GPU 显存小于 8GB,可以使用"量化版本",在加载模型时添加
load_in_8bit=True参数(需要安装 bitsandbytes 库:pip install bitsandbytes); - ② 下载速度慢:可以配置国内镜像源,或者手动下载模型文件后本地加载(具体方法我会在文末资源包中分享);
- ③ 令牌无效:检查令牌是否正确,以及是否有"read"权限,若失效可重新创建一个。
五、进阶操作:在 Hugging Face 微调 Mistral 模型(适配你的场景)
如果基础模型的效果不符合你的具体需求(比如做行业问答、专属对话机器人),可以在 Hugging Face 上微调 Mistral 模型。这里给大家分享一个简单的微调流程,用 AutoTrain 工具(Hugging Face 推出的零代码微调工具),新手也能上手。
5.1 微调前准备:整理数据集
首先需要准备一份符合要求的数据集,格式推荐 CSV,包含两列:"text"(输入提示)和"target"(期望输出)。比如做电商客服问答微调,数据集可以是这样的:
| text | target |
|---|---|
| 用户:这个商品支持7天无理由退货吗? | 支持的哦~ 我们店铺所有商品均符合7天无理由退货政策... |
| 用户:发货后多久能收到? | 默认发中通快递,江浙沪皖地区发货后1-2天送达... |
数据集规模:微调 Mistral-7B 模型,建议至少准备 100 条以上高质量数据,数据越多,微调效果越好。
5.2 微调步骤:用 AutoTrain 零代码操作
- 安装 AutoTrain:命令行输入
pip install huggingface-autotrain; - 创建微调配置文件:新建一个 Python 脚本,复制以下代码,修改数据集路径、模型名称等参数;
python
from autotrain import AutoTrain
# 微调配置
autotrain = AutoTrain(
task="text-generation", # 任务类型:文本生成
model="mistralai/Mistral-7B-Instruct-v0.2", # 基础模型
data_path="./电商客服数据集.csv", # 你的数据集路径
output_dir="./mistral-电商微调模型", # 微调后模型保存路径
use_peft=True, # 使用 PEFT 方法,节省显存
peft_method="lora", # 常用的微调方法,适合低显存设备
batch_size=4, # 批次大小,根据显存调整
epochs=3, # 训练轮数
learning_rate=2e-4, # 学习率
use_auth_token="你的Hugging Face令牌"
)
# 开始微调
autotrain.train()- 运行脚本:等待训练完成,微调后的模型会保存在
output_dir指定的路径; - 测试微调效果:用之前的调用代码,将
model_name改成微调后的模型路径,输入相关问题,就能看到模型输出符合你场景的答案了。
六、为什么开发者爱 Mistral?真实使用体验分享
很多人会问:"市面上开源模型那么多,为什么非要选 Mistral + Hugging Face 的组合?"
核心在于两者结合带来的"1+1>2"的生态价值,不管是新手、开发者还是企业,都能从中受益。
6.1 对新手:降低开源大模型入门门槛
新手最头疼的就是"模型适配难、环境配置复杂",而 Hugging Face 的工具库已经把 Mistral 模型的调用逻辑封装好了,不用写复杂的底层代码;同时 Mistral 的中小参数模型(如 7B)对硬件要求不高,普通电脑加个中端 GPU 就能跑,让新手能快速体验开源大模型的魅力。
6.2 对开发者:提升项目落地效率
开发者做项目时,最核心的需求是"高效出成果":
- 不用从零训练模型:直接用 Mistral 的预训练模型微调,节省大量算力和时间;
- 工具链完善:Hugging Face 的 Transformers、Datasets、Evaluate 等工具库,覆盖从数据处理、模型训练到评估部署的全流程,不用重复造轮子;
- 社区支持:在 Hugging Face 的 Mistral 模型详情页,有大量开发者分享的使用技巧、微调案例,遇到问题还能在评论区提问,社区活跃度极高。
6.3 对企业:降低 AI 应用研发成本
企业落地 AI 应用时,成本和效率是关键:
- 开源免费:Mistral 模型开源免费,企业不用支付高额的模型授权费;
- 灵活定制:可以基于 Mistral 模型微调适配自己的业务场景(如金融、医疗、电商),比用闭源模型更灵活;
- 部署方便:Hugging Face 提供了 Inference Endpoints 等服务,企业可以一键将 Mistral 模型部署为 API,不用自己搭建复杂的部署环境。
6.4 真实场景案例
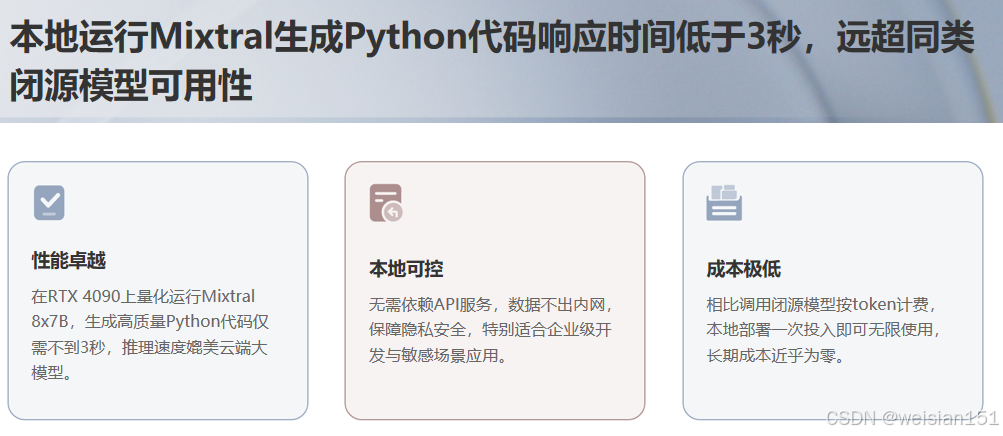
场景一:本地运行高质量聊天机器人
我用一台 RTX 4090 + 32GB RAM 的笔记本,成功运行 Mixtral 8x7B Instruct(量化后仅需 22GB 显存):
python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mixtral-8x7B-Instruct-v0.1",
device_map="auto",
torch_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1")
prompt = "用 Python 写一个快速排序函数"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))结果:代码正确、注释清晰,响应时间 < 3 秒。
对比 Llama 3 70B:后者根本无法在本地运行。
场景二:构建多语言客服系统
某跨境电商客户需支持法、德、西三语客服。
我们基于 Mistral 7B Instruct 微调,仅用 2000 条标注数据 + Google Colab 免费 T4,3 天完成:
- 准确率 92%(高于商用 API);
- 部署成本几乎为零;
- 完全掌控数据,无隐私泄露风险。
场景三:AI Agent 的"大脑"
Mistral 的 function calling 能力极强。
在 Hugging Face Spaces 上,已有多个项目用 Mixtral 驱动自主 Agent:
- 自动查天气、订机票;
- 分析股票数据并生成报告;
- 控制智能家居设备。
得益于其高推理一致性 和低幻觉率,Mistral 成为 Agent 开发者的首选。

七、Mistral vs. 主流模型:一张表看懂差异
| 维度 | Mistral 7B | Llama 3 8B | Gemma 7B | Qwen 7B |
|---|---|---|---|---|
| 开源许可 | MIT(可商用) | LLAMA 社区许可(限制商用) | Gemma 许可(限制严格) | Apache 2.0(可商用) |
| 本地运行 | ✅ 极易 | ✅ | ✅ | ✅ |
| 多语言 | 英、法、德、西等 | 主要英语 | 主要英语 | 中文强,多语言一般 |
| 推理速度 | ⚡ 极快 | 快 | 快 | 快 |
| 社区支持 | 🔥 全球火爆 | 🔥 | 温和 | 🔥(中国强) |
| MoE 架构 | ✅(Mixtral) | ❌ | ❌ | ✅(Qwen-MoE) |
结论 :如果你需要可商用、多语言、高性能的小模型,Mistral 几乎是目前最优解。
八、商业变现:用 Mistral × Hugging Face 怎么赚钱?(亲测可行)
很多小伙伴学完后想知道"能不能靠这个赚钱",答案是肯定的!结合两者的优势,有这几个低门槛的变现方向,新手也能尝试:
8.1 基础变现:定制化 AI 助手开发
在闲鱼、淘宝、小红书等平台发布服务,承接个人或中小企业的"定制化 AI 助手"开发需求,比如:
- 给自媒体博主做"文案生成助手";
- 给小商家做"电商客服问答机器人";
- 给学生做"学习答疑助手"。
核心逻辑:用 Mistral 模型做基础,结合客户的场景数据微调,部署后交付使用,一单价格从几百到几千元不等。
8.2 进阶变现:行业模型微调与部署服务
针对特定行业(如金融、医疗、教育),微调 Mistral 模型,提供"模型+部署"一体化服务:
- 给金融公司做"财经新闻摘要模型";
- 给医疗机构做"医学文献解读模型";
- 给培训机构做"题库生成模型"。
行业模型的需求更大,客单价也更高,适合有一定技术基础的开发者。

8.3 被动变现:优质模型/数据集出售
如果微调了效果很好的模型(比如"中文法律问答 Mistral 模型""短视频文案生成模型"),可以上传到 Hugging Face 的 Marketplace 出售;也可以整理高质量的行业数据集(如"医疗问答数据集""电商评论数据集"),上传到 Hugging Face Datasets 或国内的数据集平台出售,获得被动收入。
8.4 变现注意事项(避坑指南)
- 遵守许可证:Mistral 模型的 Apache 2.0 许可证允许商用,但要注意不能用于违法、侵权的场景;
- 明确服务范围:接定制单时,要和客户说清楚模型的使用范围、修改次数、售后保障,避免后续纠纷;
- 保护数据安全:处理客户数据时,要做好数据脱敏,避免泄露隐私,最好和客户签订数据保密协议。
九、中国用户如何高效使用 Mistral?
和 Hugging Face 一样,Mistral 模型在国内下载也常遇网络问题。别担心,这里提供实操方案。
9.1 方案一:通过 ModelScope(魔搭)镜像加速
阿里云 ModelScope 已同步全部 Mistral 开源模型:
- 入口 :https://modelscope.cn/models/mistralai
- 支持模型:Mistral 7B、Mixtral 8x7B 等
- 下载速度:可达 50MB/s+
python
from modelscope import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained('AI-ModelScope/Mixtral-8x7B-Instruct')9.2 方案二:使用 hf-mirror.com 镜像
设置环境变量即可自动走镜像:
bash
export HF_ENDPOINT=https://hf-mirror.com然后正常使用 transformers 加载:
python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")9.3 方案三:国产平台替代(若仅需功能)
- OpenXLab:提供 Mistral 微调模板和在线 Notebook;
- 智谱 GLM-Edge:中文场景更强,但非 Mistral 生态;
- 百川 Baichuan:类似定位,可作备选。
建议:优先用 ModelScope 或 hf-mirror,保持与国际生态一致。
十、争议与挑战:Mistral 的隐忧
尽管光芒耀眼,Mistral 也面临现实挑战:
❓ 1. 能否持续对抗"巨头碾压"?
Meta、Google 正加速开源节奏(Llama 3、Gemma 2)。
Mistral 作为初创公司,算力、数据、人才储备远不及对手。
应对:聚焦"高效模型"细分赛道,避免正面硬刚。
❓ 2. 闭源模型是否背离初心?
Mistral Large 不开源,引发部分社区质疑。
但团队解释:闭源收入反哺开源研发,形成良性循环。

❓ 3. 欧洲监管是否成双刃剑?
欧盟《AI法案》对生成模型要求严格。
Mistral 主动合规,反而赢得政府支持,成为"可信 AI"标杆。
十一、未来展望:Mistral 想成为什么?
根据 2025 年路线图,Mistral 正在布局三大方向:
- Agent 原生模型:内置工具调用、记忆、规划能力;
- 多模态扩展:图像理解、语音生成已在测试;
- 欧洲主权云:与 OVHcloud 合建 AI 算力网络,摆脱美国依赖。
更宏大的愿景是:打造一个"去中心化、高效率、可审计"的开源 AI 生态,与 Hugging Face、EleutherAI 等共建"开源联盟"。
"我们不想赢,我们只想让世界多一个选择。"
------ Mistral AI 官方博客
十二、给你的实操指南:10 分钟跑通 Mistral
步骤 1:安装依赖
bash
pip install transformers torch accelerate步骤 2:加载模型(以 Mistral 7B Instruct 为例)
python
from transformers import pipeline
pipe = pipeline(
"text-generation",
model="mistralai/Mistral-7B-Instruct-v0.2",
torch_dtype=torch.float16,
device_map="auto"
)
messages = [
{"role": "user", "content": "解释量子纠缠是什么?"}
]
prompt = pipe.tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True)
print(outputs[0]["generated_text"][len(prompt):])首次运行会自动下载模型(约 15GB),建议搭配 hf-mirror 使用。
步骤 3:进阶玩法
- 用
llama.cpp量化至 4-bit,在 Mac M1 上运行; - 用
unsloth库 5 分钟微调自己的版本; - 部署到 Hugging Face Spaces 免费展示。
十三、新手必备资源包:学习 Mistral × Hugging Face 的优质资源
最后,给新手整理了一份优质资源包,收藏起来慢慢学,少走弯路:
13.1 官方资源(最权威)
- Mistral AI 官方文档:https://docs.mistral.ai/(了解模型核心参数、使用限制);
- Hugging Face 官方教程:https://huggingface.co/docs(学习 Transformers、AutoTrain 等工具的详细用法);
- Mistral 在 Hugging Face 的官方主页:https://huggingface.co/mistralai(获取最新模型和官方示例)。
13.2 国内学习资源(适合新手)
- B站:搜索"Mistral AI 入门""Hugging Face 微调教程",有大量博主分享的视频实操案例;
- 知乎:搜索"Mistral 模型使用技巧",有很多开发者分享的踩坑经验和项目实战;
- GitHub:搜索"Mistral-HuggingFace-Demo",有很多现成的 demo 项目,下载代码就能跑。
13.3 工具推荐(提升效率)
- 显存优化工具:bitsandbytes(用于模型量化,降低显存需求);
- 可视化工具:Gradio(快速搭建模型演示界面,方便给客户展示);
- 云 GPU 平台:如果本地没有 GPU,可以用 AutoDL、Lambda Labs 等云 GPU 平台,按小时收费,性价比高。
结语:小国大志,技术无疆
聊了这么多关于 Mistral AI 和 Hugging Face 的用法、价值,最后想跟大家说一句:不管是多好的模型,多完善的生态,只有真正用起来,才能发挥它的价值。
很多新手一开始会陷入"纠结选哪个模型""担心自己硬件不够"的误区,其实完全不用怕------先从最简单的 Mistral-7B 模型调用开始,跑通第一个 demo,再慢慢尝试微调、做小项目。一步一步来,你会发现开源大模型并没有那么难。
如果你已经开始尝试用 Mistral 模型做项目,欢迎在评论区分享你的经验和遇到的问题;如果还没开始,希望这篇攻略能给你勇气,大胆迈出第一步~
Mistral AI 的故事,是一个关于效率、克制与信念 的故事。
在一个崇尚"越大越好"的时代,它勇敢地说:"够用就好。"
它证明了:创新不必来自硅谷,伟大不必依赖资本 。
只要有一群聪明人,坚持做正确的事,就能在 AI 的星辰大海中,点亮属于自己的灯塔。
也许未来的 AI 史书会这样写道:
"2023 年,一家巴黎小公司用 70 亿参数,教会了世界什么叫'聪明的 AI'。"
而你我,正有幸见证这一切。
延伸探索
- Mistral 官网 :https://mistral.ai
- Mixtral 在线 Demo :https://huggingface.co/spaces/mistralai/Mixtral-8x7B-Instruct
- 本地部署教程(含量化):GitHub 搜索 "Mistral local inference"