一、SFT任务背景
SFT(Supervised Fine-Tuning,监督微调)是大语言模型(LLM)训练流程中承上启下的核心环节。在预训练阶段,模型(如BERT、GPT)通过海量无标注文本学习通用的语言规律、语法结构和世界知识,但此时模型仅具备"理解语言"的能力,无法精准遵循人类指令完成特定任务;而SFT阶段则通过人工标注的指令-输出配对数据,对预训练模型进行针对性微调,让模型学会将通用语言知识与具体任务需求对齐,是从"通用语言模型"到"任务型对话/生成模型"的关键一步。
在NLP领域,SFT常应用于问答系统、对话机器人、文本生成等场景,尤其在资源有限的情况下,无需从头训练模型,仅通过少量标注数据微调预训练模型,就能快速适配特定业务需求。
二、BERT适配SFT任务的核心改造工作
BERT(Bidirectional Encoder Representations from Transformers)原生设计目标是文本理解(如分类、NER、阅读理解),其核心是"双向注意力机制",无法直接用于SFT文本生成任务。要让BERT适配SFT,需完成以下关键改造:
1. 注意力机制改造:双向→单向(因果掩码)
- 原生问题:BERT的自注意力层允许每个位置关注整个序列的所有字符(双向),而文本生成需要"自回归"逻辑(预测第t个字符时仅能看到前t-1个字符);
- 改造方案 :生成因果掩码(下三角矩阵),屏蔽未来字符的注意力权重,将双向注意力改为单向注意力,符合文本生成"从左到右"的逻辑。
2. 模型结构适配:理解→生成
- 原生问题:BERT无生成头,仅输出序列的语义特征,无法直接预测下一个字符;
- 改造方案 :在BERT编码器输出后新增分类头(Linear层),将768维隐藏特征映射到字表大小,把"语义理解"转为"字符级分类任务",通过预测每个位置的字符实现生成。
3. 预训练层复用:全量→部分
- 原生问题:BERT有12层编码器,全量微调计算成本高,且易遗忘预训练知识;
- 改造方案 :仅复用BERT的嵌入层(Embeddings) 和前N层编码器(可配置),减少微调参数数量,兼顾训练效率和预训练知识保留。
4. 输入输出适配:固定长度→任务对齐
- 原生问题:BERT输入为单序列文本,SFT需要"指令-输出"配对数据;
- 改造方案:构建"指令文本→输出文本"的配对数据集,统一序列长度(截断/补PAD),将SFT任务转化为"输入指令序列→预测输出字符序列"的监督学习任务。
三、SFT任务作用
- 对齐人类意图:让预训练模型从"被动理解文本"转变为"主动遵循指令生成符合预期的回答",解决预训练模型与人类需求的"对齐问题";
- 适配特定任务:针对问答、文本生成、情感分析等细分任务,快速迁移预训练模型的通用能力到具体场景;
- 降低训练成本:复用BERT等预训练模型的权重,仅微调部分层参数,大幅减少训练数据量和计算资源消耗;
- 提升生成质量:通过监督信号修正模型输出,减少无意义、偏离指令的生成结果,提升文本生成的准确性和可读性。
四、代码整体逻辑解析
1. 代码核心目标
基于中文BERT预训练模型,完成上述适配改造后,构建一个支持自回归生成的语言模型,通过SFT(监督微调)让模型学会根据输入的自然语言指令,生成对应的回答文本。
2. 代码模块功能拆解
| 模块名称 | 核心功能 |
|---|---|
LanguageModel类 |
模型核心结构:实现BERT的嵌入层/编码器复用、因果掩码生成、分类头构建,完成BERT到生成模型的改造 |
build_vocab函数 |
构建字符-ID映射字典(字表),实现文本与张量的双向转换 |
build_stf_sample函数 |
单条样本构建:将指令/输出文本转换为固定长度的ID序列(补PAD、截断、处理未知字符) |
build_sft_dataset函数 |
批量数据集构建:循环生成多条样本,转换为PyTorch张量,供模型训练使用 |
sampling_strategy函数 |
生成策略:混合贪心采样(保证准确性)和随机采样(增加多样性),选择预测字符 |
generate_sentence函数 |
文本生成:基于输入指令,逐字符自回归生成回答文本,验证模型效果 |
train函数 |
训练主流程:初始化模型/优化器→构建训练数据→多轮迭代训练→验证生成效果→保存模型权重 |
3. 核心模块深度解析
(1)LanguageModel类(BERT改造核心)
python
class LanguageModel(nn.Module):
def __init__(self, input_dim = 768, vocab = None, use_bert_layers = 1):
super(LanguageModel, self).__init__()
# 1. 复用BERT预训练层:嵌入层+前N层编码器(改造点3)
full_bert = BertModel.from_pretrained(r"F:\bert-base-chinese")
self.bert_embeddings = full_bert.embeddings # 字符嵌入层:ID→768维向量
self.bert_encoder_layers = nn.Sequential(*full_bert.encoder.layer[:use_bert_layers]) # 前N层编码器
# 2. 新增生成头:分类层(改造点2)
self.classify = nn.Linear(input_dim, len(vocab)) # 768维→字表大小(预测下一个字符)
self.dropout = nn.Dropout(0.1) # 防止过拟合
self.loss = nn.functional.cross_entropy # 监督损失
def generate_causal_mask(self, seq_len, device):
"""3. 生成因果掩码:改造双向注意力为单向(改造点1)"""
mask = torch.tril(torch.ones((seq_len, seq_len), device=device)).bool()
return mask.unsqueeze(0) # 适配BERT输入格式
def forward(self, x, y = None):
batch_size, seq_len = x.shape
device = x.device
# 字符嵌入
embeddings_output = self.bert_embeddings(x)
# 应用因果掩码
causal_mask = self.generate_causal_mask(seq_len, device)
# BERT编码器前向计算(单向注意力)
encoder_output = embeddings_output
for layer_module in self.bert_encoder_layers:
encoder_output = layer_module(
hidden_states = encoder_output,
attention_mask = causal_mask
)[0]
# 生成头预测
encoder_output = self.dropout(encoder_output)
y_pred = self.classify(encoder_output)
# 训练/推理分支
if y is not None:
return self.loss(y_pred.view(-1, y_pred.shape[-1]), y.view(-1))
else:
return torch.softmax(y_pred, dim = -1)关键改造对应:
- 因果掩码函数对应"改造点1",解决注意力方向问题;
classify层对应"改造点2",新增生成头;- 复用
bert_embeddings和bert_encoder_layers对应"改造点3",轻量化微调。
(2)数据构建模块(改造点4适配)
python
def build_vocab(vocab_path):
vocab = {"<pad>" : 0} # 填充符PAD
with open(vocab_path, encoding="utf-8") as f:
for index, line in enumerate(f):
char = line[:-1]
vocab[char] = index + 1
return vocab
def build_stf_sample(vocab, corpus, max_input_len, max_output_len):
item = random.choice(corpus)
input_text = item["instruction"].strip() # 指令文本(SFT输入)
output_text = item["output"].strip() # 输出文本(SFT监督标签)
# 文本→ID:统一长度(改造点4)
x = [vocab.get(char, vocab["<UNK>"]) for char in input_text[:max_input_len]]
x += [vocab["<pad>"]] * (max_input_len - len(x))
y = [vocab.get(char, vocab["<UNK>"]) for char in output_text[:max_output_len]]
y += [vocab["<pad>"]] * (max_output_len - len(y))
return x, y
def build_sft_dataset(sample_length, vocab, corpus, max_input_len, max_output_len):
dataset_x = []
dataset_y = []
for i in range(sample_length):
x, y = build_stf_sample(vocab, corpus, max_input_len, max_output_len)
dataset_x.append(x)
dataset_y.append(y)
return torch.LongTensor(dataset_x), torch.LongTensor(dataset_y)关键改造对应:
- 构建"指令-输出"配对数据,对应"改造点4",将SFT任务转化为监督学习任务;
- 统一序列长度,适配模型固定输入维度要求。
(3)文本生成模块(验证改造效果)
python
def sampling_strategy(y_prob_distribution):
# 混合采样:平衡准确性与多样性
if random.random() > 0.1:
strategy = "greedy" # 贪心:选概率最大字符
else:
strategy = "sampling" # 随机:按概率采样
if strategy == "greedy":
return int(torch.argmax(y_prob_distribution))
elif strategy == "sampling":
y_prob_distribution = y_prob_distribution.cpu().numpy()
sampling_text = np.random.choice(list(range(len(y_prob_distribution))), p = y_prob_distribution)
return sampling_text
def generate_sentence(openings_text, model, vocab):
ix_to_char = {ix:char for char, ix in vocab.items()}
model.eval()
with torch.no_grad():
pred_char = ""
# 自回归生成:逐字符预测(验证改造后的生成能力)
while pred_char != "\n" and len(openings_text) <=30:
openings_text += pred_char
x = [vocab.get(char, vocab["<UNK>"]) for char in openings_text]
x = torch.LongTensor([x])
if torch.cuda.is_available():
x = x.cuda()
y = model(x)[0][-1] # 预测最后一个位置的字符
index = sampling_strategy(y)
pred_char = ix_to_char[index]
return openings_text(4)训练主函数(SFT核心流程)
python
def train(save_weight = True):
# 1. 构建SFT配对语料(改造点4)
corpus = [
{"instruction": "请介绍一下人工智能。", "input": "", "output": "人工智能(AI)是计算机科学的一个分支..."},
# 其他样本...
]
# 2. 超参数
epoch_num = 10 # 训练轮数
batch_size = 64 # 批次大小
train_sample = 50000 # 每轮样本数
char_dim = 768 # BERT隐藏维度
encoder_layers = 2 # 复用BERT前2层(改造点3)
max_input_len = 50 # 输入长度
max_output_len = 50 # 输出长度
# 3. 初始化
vocab = build_vocab(r"F:\vocab.txt")
model = build_model(vocab, char_dim, encoder_layers)
if torch.cuda.is_available():
model = model.cuda()
optim = torch.optim.Adam(model.parameters(), lr = 0.001)
# 4. 初始效果验证
print("模型加载完成,开始训练...")
print("================================================")
print(generate_sentence("请介绍一下人工智能。", model, vocab))
print(generate_sentence("什么是Agent。", model, vocab))
print("================================================")
# 5. SFT训练
print("开始SFT训练...")
for epoch in range(epoch_num):
model.train()
watch_loss = []
for batch in range(int(train_sample / batch_size)):
# 生成批量SFT数据
x, y = build_sft_dataset(batch_size, vocab, corpus, max_input_len, max_output_len)
if torch.cuda.is_available():
x = x.cuda()
y = y.cuda()
# 梯度更新
optim.zero_grad()
loss = model(x, y)
loss.backward()
optim.step()
watch_loss.append(loss.item())
# 每轮验证生成效果
print(f"============第{epoch + 1}轮训练完成,平均损失:{np.mean(watch_loss):.4f}============")
print("===============================================")
print(generate_sentence("请介绍一下人工智能。", model, vocab))
print(generate_sentence("什么是Agent", model, vocab))
# 6. 保存模型
if save_weight:
torch.save(model.state_dict(), "sft_bert_model.pth")
print("模型权重保存完成!")4. 代码逻辑文字流程图
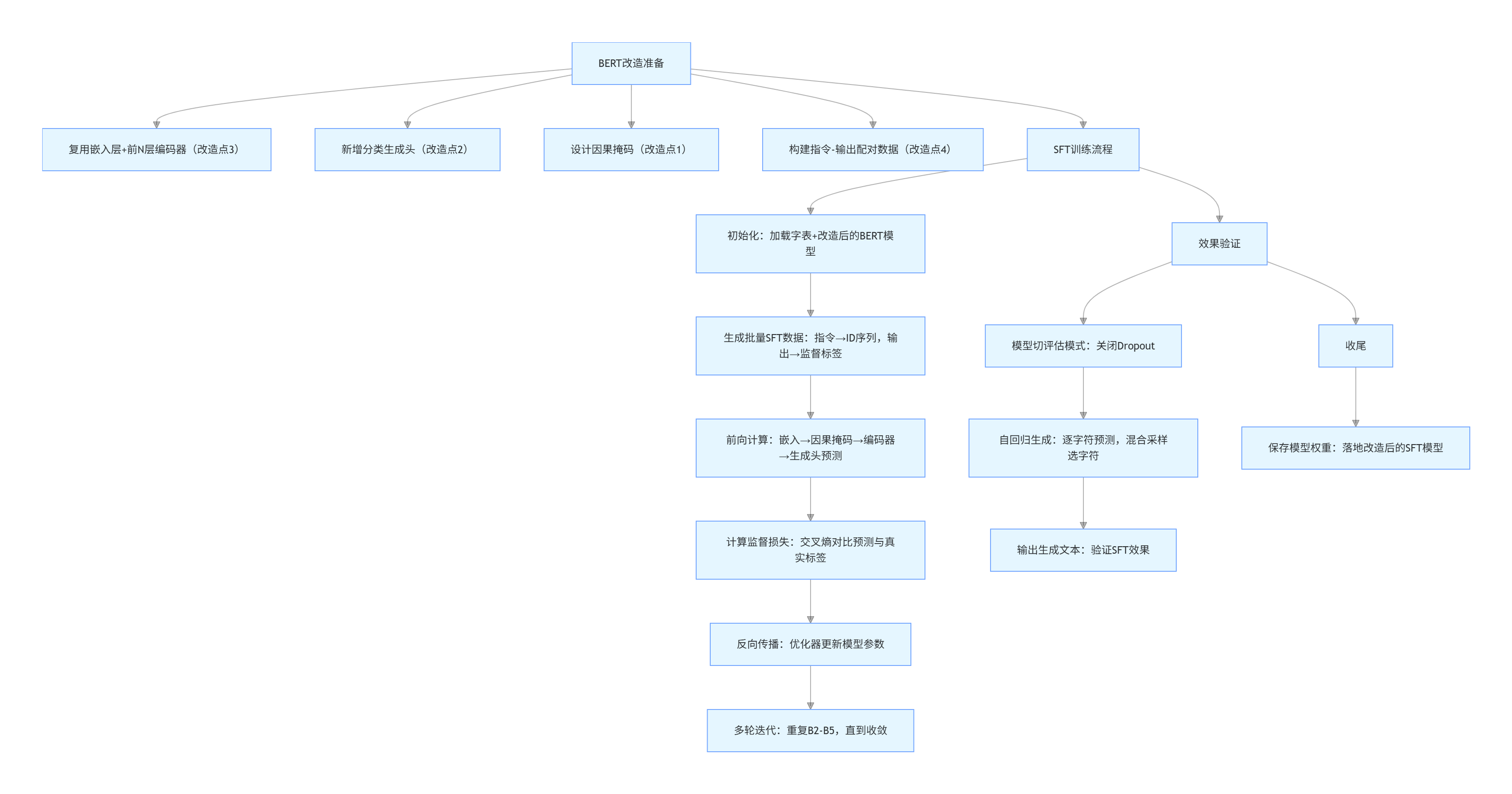
五、总结
1. BERT适配SFT的核心要点
- 注意力改造:通过因果掩码将双向BERT改为单向自回归模型,是适配生成任务的核心;
- 结构改造:新增分类头,将语义理解转化为字符级生成任务;
- 轻量化改造:复用预训练层,仅微调部分参数,平衡效率与效果;
- 数据改造:构建"指令-输出"配对数据,将SFT转化为监督学习任务。
2. 代码核心逻辑
代码围绕"BERT改造→SFT训练→生成验证"展开,先完成BERT从"理解"到"生成"的核心改造,再通过标注的指令-输出数据进行监督微调,最终验证模型的指令跟随和文本生成能力。
完整代码
python
import torch
import torch.nn as nn
import numpy as np
import math
import random
import os
import re
from transformers import BertModel
class LanguageModel(nn.Module):
def __init__(self, input_dim = 768, vocab = None, use_bert_layers = 1):
"""
Args:
input_dim: BERT隐藏层维度(固定768)
vocab: 字表字典
use_bert_layers: 使用BERT的前N层(1≤N≤12)
"""
super(LanguageModel, self).__init__()
# 加载完整BERT预训练模型
full_bert = BertModel.from_pretrained(r"F:\bert-base-chinese")
self.bert_embeddings = full_bert.embeddings
self.bert_encoder_layers = nn.Sequential(*full_bert.encoder.layer[:use_bert_layers])
self.classify = nn.Linear(input_dim, len(vocab))
self.dropout = nn.Dropout(0.1)
self.loss = nn.functional.cross_entropy
# 生成 mask 掩码
def generate_causal_mask(self, seq_len, device):
"""
生成因果掩码(下三角矩阵)
:param seq_len: 序列长度
:param device: 设备
:return: [1, seq_len, seq_len]的掩码矩阵
"""
mask = torch.tril(torch.ones((seq_len, seq_len), device=device)).bool()
return mask.unsqueeze(0) # 增加batch维度
def forward(self, x, y = None):
batch_size, seq_len = x.shape
device = x.device
embeddings_output = self.bert_embeddings(x)
# 2. 生成因果掩码(阻止看到未来token)
causal_mask = self.generate_causal_mask(seq_len, device) # [1, seq_len, seq_len]
encoder_output = embeddings_output
# 取出每层BERT编码器进行前向计算
for layer_module in self.bert_encoder_layers:
encoder_output = layer_module(
hidden_states = encoder_output,
attention_mask = causal_mask
)[0]
encoder_output = self.dropout(encoder_output)
y_pred = self.classify(encoder_output)
if y is not None:
return self.loss(y_pred.view(-1, y_pred.shape[-1]), y.view(-1))
else:
return torch.softmax(y_pred, dim = -1)
def build_vocab(vocab_path):
vocab = {"<pad>" : 0} #特殊填充符号
with open(vocab_path, encoding="utf-8") as f:
for index, line in enumerate(f):
char = line[:-1] #去掉结尾换行符
vocab[char] = index + 1
return vocab
def build_model(vocab, char_dim, encoder_layers):
model = LanguageModel(char_dim, vocab, encoder_layers)
return model
def build_stf_sample(vocab, corpus, max_input_len, max_output_len):
item = random.choice(corpus)
input_text = item["instruction"].strip()
output_text = item["output"].strip()
# print('input_text', input_text)
# print('output_text', output_text)
x = [vocab.get(char, vocab["<UNK>"]) for char in input_text[:max_input_len]]
x += [vocab["<pad>"]] * (max_input_len - len(x))
y = [vocab.get(char, vocab["<UNK>"]) for char in output_text[:max_output_len]]
y += [vocab["<pad>"]] * (max_output_len - len(y))
return x, y
def build_sft_dataset(sample_length, vocab, corpus, max_input_len, max_output_len):
dataset_x = []
dataset_y = []
for i in range(sample_length):
x, y = build_stf_sample(vocab, corpus, max_input_len, max_output_len)
dataset_x.append(x)
dataset_y.append(y)
return torch.LongTensor(dataset_x), torch.LongTensor(dataset_y)
def sampling_strategy(y_prob_distribution):
if random.random() > 0.1:
strategy = "greedy"
else:
strategy = "sampling"
if strategy == "greedy":
return int(torch.argmax(y_prob_distribution))
elif strategy == "sampling":
y_prob_distribution = y_prob_distribution.cpu().numpy()
sampling_text = np.random.choice(list(range(len(y_prob_distribution))), p = y_prob_distribution)
return sampling_text
def generate_sentence(openings_text, model, vocab):
# 解码,idx到字的映射
ix_to_char = {ix:char for char, ix in vocab.items()}
model.eval()
with torch.no_grad():
# 一个个字进行预测
pred_char = ""
# 生成了换行符,或生成文本超过30字则终止迭代
while pred_char != "\n" and len(openings_text) <=30:
openings_text += pred_char
x = [vocab.get(char, vocab["<UNK>"]) for char in openings_text]
x = torch.LongTensor([x])
if torch.cuda.is_available():
x = x.cuda()
y = model(x)[0][-1]
index = sampling_strategy(y)
pred_char = ix_to_char[index]
return openings_text
def train(save_weight = True):
corpus = [
{
"instruction": "请介绍一下人工智能。",
"input": "",
"output": "人工智能(AI)是计算机科学的一个分支,致力于创建能够执行通常需要人类智能的任务的系统。这包括学习、推理、感知和自然语言处理等能力。"
},
{
"instruction": "什么是深度学习?",
"input": "",
"output": "深度学习是机器学习的一个子领域,使用具有多个层(深度)的神经网络来学习数据的复杂模式和表示。它模仿人脑的神经网络结构。"
},
{
"instruction": "Python中的列表和元组有什么区别?",
"input": "",
"output": "列表(list)是可变的,可以修改、添加或删除元素,使用方括号[]。元组(tuple)是不可变的,一旦创建就不能修改,使用圆括号()。"
},
{
"instruction": "解释一下什么是监督学习。",
"input": "",
"output": "监督学习是机器学习的一种方法,使用标记的训练数据来训练模型。模型学习输入和输出之间的映射关系,然后可以对新的未标记数据进行预测。"
},
{
"instruction": "如何提高模型的泛化能力?",
"input": "",
"output": "提高模型泛化能力的方法包括:1) 增加训练数据量和多样性 2) 使用正则化技术(如Dropout、L2正则化)3) 数据增强 4) 交叉验证 5) 防止过拟合。"
},
{
"instruction": "什么是Transformer模型?",
"input": "",
"output": "Transformer是一种基于注意力机制的神经网络架构,由编码器和解码器组成。它摒弃了RNN和CNN,完全依赖注意力机制来处理序列数据,成为现代NLP的基础架构。"
},
{
"instruction": "请解释一下梯度下降算法。",
"input": "",
"output": "梯度下降是一种优化算法,用于最小化损失函数。它通过计算损失函数对参数的梯度,然后沿着梯度反方向更新参数,逐步接近最优解。学习率控制每次更新的步长。"
},
{
"instruction": "什么是迁移学习?",
"input": "",
"output": "迁移学习是将在一个任务或领域上学到的知识应用到另一个相关任务上的技术。它允许模型利用预训练的知识,从而在目标任务上更快地学习和获得更好的性能。"
},
{
"instruction": "如何处理自然语言处理中的文本分类问题?",
"input": "",
"output": "文本分类的常见步骤包括:1) 文本预处理(分词、去停用词)2) 特征提取(词袋、TF-IDF、词向量)3) 选择分类算法(朴素贝叶斯、SVM、神经网络)4) 训练和评估模型。"
},
{
"instruction": "请介绍一下大语言模型。",
"input": "",
"output": "大语言模型(LLM)是拥有数十亿甚至千亿参数的深度学习模型,通过在海量文本数据上预训练获得语言理解能力。它们可以执行各种NLP任务,如文本生成、问答、翻译等。"
}
]
epoch_num = 10 #训练轮数
batch_size = 64 #每次训练样本个数
train_sample = 50000 #每轮训练总共训练的样本总数
char_dim = 768 #每个字的维度
encoder_layers = 2
max_input_len = 50
max_output_len = 50
vocab = build_vocab(r"F:\vocab.txt") #建立字表
model = build_model(vocab, char_dim, encoder_layers) #建立模型
if torch.cuda.is_available():
model = model.cuda()
# 学习率变小
optim = torch.optim.Adam(model.parameters(), lr = 0.001) #优化器
print("模型加载完成,开始训练...")
print("================================================")
print(generate_sentence("请介绍一下人工智能。", model, vocab))
print(generate_sentence("什么是Agent。", model, vocab))
print("================================================")
print("开始SFT训练...")
for epoch in range(epoch_num):
model.train()
watch_loss = []
for batch in range(int(train_sample / batch_size)):
x, y = build_sft_dataset(batch_size, vocab, corpus, max_input_len, max_output_len)
if torch.cuda.is_available():
x = x.cuda()
y = y.cuda()
optim.zero_grad()
loss = model(x, y)
loss.backward()
optim.step()
watch_loss.append(loss.item())
print("============第{}轮训练完成,平均损失:{:.4f}============".format(epoch + 1, np.mean(watch_loss)))
print("===============================================")
print(generate_sentence("请介绍一下人工智能。", model, vocab))
print(generate_sentence("什么是Agent", model, vocab))
if not save_weight:
return
else:
torch.save(model.state_dict(), "sft_bert_model.pth")
print("模型权重保存完成!")
if __name__ == "__main__":
train(True) #设置为True保存模型权重
# train(False) #设置为False不保存模型权重