文章目录
技术方案
- fastapi 中可以基于sqlmodel连接关系型数据库, 是一种异步ORM方案;
- 安装 pip install sqlmodel;
- sqlmodel 是基于sqlalchemy、pydantic实现的,所以基于sqlmodel定义的模型类既可以作为sqlalchemy的模型类来操作数据库,实现CRUD,又可以作为pydantic的模型类来实现数据的验证、过滤、序列化、反序列;
- 常用的类及方法
- SQLModel 基类,定义的模型类必须继承该类;
- Field字段类,用于定义模型类的字段约束;
- create_engine方法,创建对数据库的连接;
- Session会话类,实现对数据库的CRUD操作;
- select 数据查询;
- sqlmodel官网教程
单表的CRUD
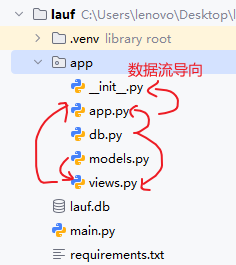
代码目录结构及数据流导向:
python
# __author__ = "laufing"
# 基于 sqlmodel 异步ORM框架 连接关系数据库
from fastapi import Depends
from typing_extensions import Annotated # 创建具有元信息的类
from sqlmodel import SQLModel, Field, Session, create_engine, select
# 连接数据库
database_uri = "sqlite:///lauf.db"
engine = create_engine(database_uri, connect_args={"check_same_thread": False})
def get_db():
with Session(engine) as session:
yield session
# 创建具有元信息的类
# Session类型,实例来源于get_db
SessionDep = Annotated[Session, Depends(get_db)]
python
# __author__ = "laufing"
# 定义模型类
from typing import Union
from sqlmodel import SQLModel, Field
from pydantic import field_validator
# 单表
class UserModel(SQLModel, table=True): # 默认的表名usermodel
# 继承父类,并为其传递参数,将模型类映射为表;
# 否则仅作为pydantic模型使用
id: Union[int, None] = Field(default=None, primary_key=True) # nullable
# 数据库字段的完整性验证
name: str = Field(..., unique=True, index=True, description="user name", nullable=False)
email: str = Field(..., index=True, unique=True, nullable=False)
# 字段验证的自定义逻辑
@field_validator('email')
def validate_email(cls, v):
if "@" not in v:
raise ValueError("Email address is not valid, no '@'")
return v
python
from idlelib.query import Query
from fastapi import APIRouter, Query
from .models import UserModel
from .db import get_db, SessionDep
from sqlmodel import select
user_roter = APIRouter(prefix="/users", tags=["users"]) # tags api文档中展示标签
# 查询所有的用户
@user_roter.get("/", status_code=200)
def list_users(session: SessionDep,
page_num: int = Query(default_factory=lambda:1, ge=1, description="页码"),
page_size: int = Query(default_factory=lambda: 10, le=100, gt=0, description="每页大小")
) -> list[UserModel]:
# 利用模型类查询所有的用户
statement = select(UserModel).offset(page_num - 1).limit(page_size)
users = session.exec(statement).all()
return users
# 添加一个用户
@user_roter.post("/", status_code=200)
def create_user(session: SessionDep, user: UserModel) -> UserModel:
# 主动触发自定义字段的验证
UserModel.model_validate(user)
# 默认情况下仅验证数据库字段的 完整性约束
session.add(user) # 即insert 插入一条
session.commit()
session.refresh(user)
return user
# 查询指定的用户
@user_roter.get("/{uid}", status_code=200)
def get_user(session: SessionDep, uid: int) -> UserModel:
user = session.get(UserModel, uid)
return user
# 更新
@user_roter.put("/{uid}", status_code=200)
def update_user(session: SessionDep, uid: int, user: UserModel)-> UserModel:
user_db = session.get(UserModel, uid)
data = user.model_dump(exclude_unset=True) # 排除未给值的字段
print("data:", data)
user_db.sqlmodel_update(data)
# session.add(user) 查询出来的user_db对象已经在会话中,不用再添加(insert)
session.commit()
session.refresh(user_db) # 提交后user_db变量会置空->{}, 必须反刷回来
return user_db
@user_roter.delete("/{uid}", status_code=200)
def delete_user(session: SessionDep, uid: int):
user = session.get(UserModel, uid)
session.delete(user)
session.commit()
return {
"code": 200,
"msg": "delete user ok"
}
python
# __author__ = "laufing"
from fastapi import FastAPI, Path
from contextlib import asynccontextmanager
from sqlmodel import SQLModel
from .db import engine
@asynccontextmanager
async def lifespan(app: FastAPI):
# 启动时执行, 创建所有的表
SQLModel.metadata.create_all(engine)
yield
# 启动过后执行
app = FastAPI(lifespan=lifespan)
from .views import user_roter
app.include_router(user_roter)
if __name__ == '__main__':
# python脚本方式运行服务
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=5050)
# 开启reload模式
# uvicorn.run("app.app:app", host="0.0.0.0", port=5050, reload=True, reload_dirs=[".", "../"])*init*.py
python
# __author__ = "laufing"
from .app import app
python
from app import app
if __name__ == '__main__':
import uvicorn
uvicorn.run(app, host="localhost", port=5050)执行main.py运行项目,并在浏览器中访问:
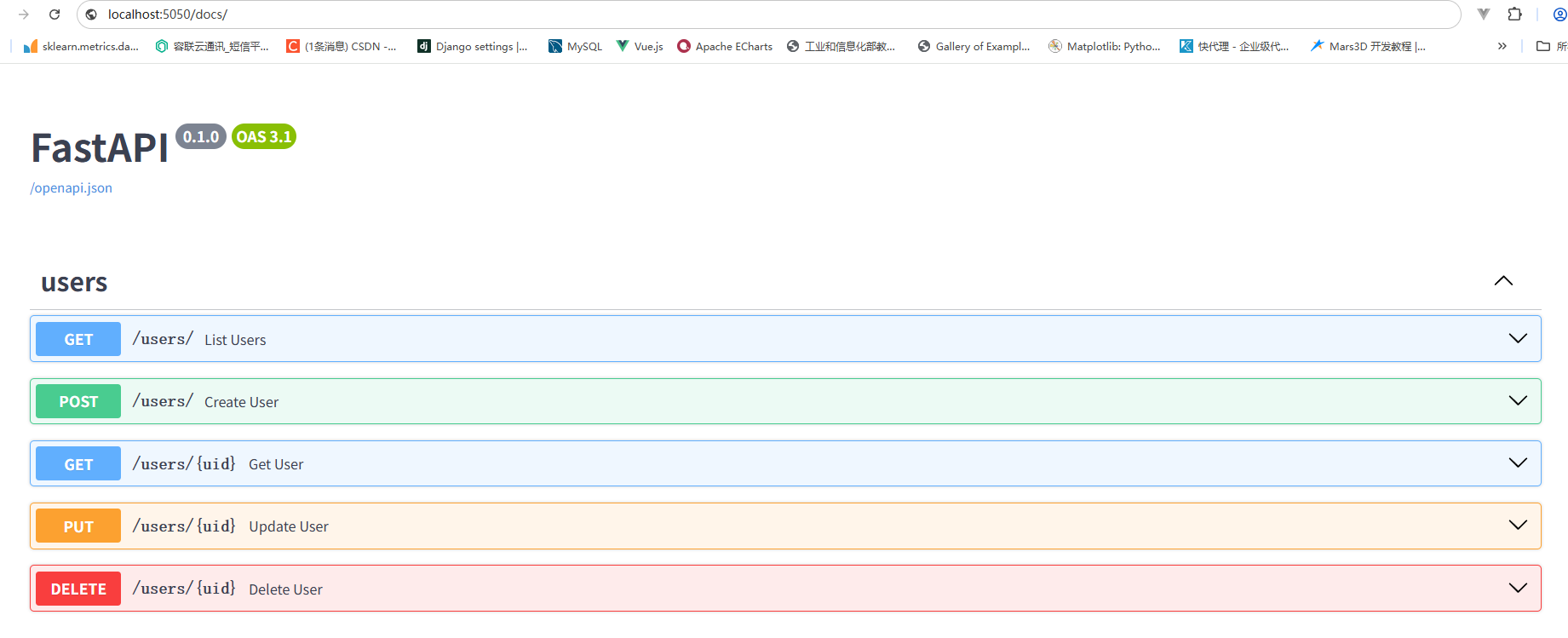
即可以实现数据的增删改查。