
前言:为什么选择 openJiuwen Agent-Core?
最近在探索 AI Agent 开发框架时,发现了 openJiuwen agent-core 。市面上 Agent 框架不少,但大多数要么过于复杂,要么缺少灵活性。openJiuwen 给我的感觉是:架构清晰、组件化设计、用起来很舒服。
这篇文章记录我从零开始构建两个 Agent 的过程:一个是入门级的"Hello World",另一个是可以实际使用的"毒舌文档排版助理"。
OpenJiuwen项目地址:https://atomgit.com/openJiuwen?utm_source=csdn
第一部分:5 分钟上手第一个 Agent
理解核心概念
openJiuwen 的设计很简单:一切皆组件,组件即工作流。
核心概念只有三个:
- Workflow(工作流):处理流程的容器
- Component(组件):处理单元(Start、LLM、End 等)
- Agent(代理):对外提供服务的封装
数据流就像管道:
plain
Start → LLM → End安装 openJiuwen agent-core
bash
pip install -U openjiuwen
第一个代码示例
下面是我写的第一个 WorkflowAgent:
python
import os
import asyncio
from openjiuwen.core.component.start_comp import Start
from openjiuwen.core.component.end_comp import End
from openjiuwen.core.component.llm_comp import LLMComponent, LLMCompConfig
from openjiuwen.core.component.common.configs.model_config import ModelConfig
from openjiuwen.core.runner.runner import Runner
from openjiuwen.core.workflow.workflow_config import WorkflowConfig, WorkflowMetadata, WorkflowInputsSchema
from openjiuwen.core.workflow.base import Workflow
from openjiuwen.core.utils.llm.base import BaseModelInfo
from openjiuwen.agent.workflow_agent.workflow_agent import WorkflowAgent
from openjiuwen.agent.config.workflow_config import WorkflowAgentConfig
from openjiuwen.agent.common.schema import WorkflowSchema
# 配置大模型
os.environ.setdefault("API_BASE", "https://api.siliconflow.cn/v1/")
os.environ.setdefault("API_KEY", "你的API_KEY")
os.environ.setdefault("MODEL_PROVIDER", "openai")
os.environ.setdefault("MODEL_NAME", "Qwen/Qwen3-VL-8B-Instruct")
model_config = ModelConfig(
model_provider=os.getenv("MODEL_PROVIDER"),
model_info=BaseModelInfo(
api_key=os.getenv("API_KEY"),
api_base=os.getenv("API_BASE"),
model=os.getenv("MODEL_NAME"),
)
)
# 创建工作流配置
workflow_config = WorkflowConfig(
metadata=WorkflowMetadata(
id="generate_text_workflow",
name="generate_text",
version="1.0",
description="根据用户输入生成文本"
),
workflow_inputs_schema=WorkflowInputsSchema(
type="object",
properties={"query": {"type": "string"}},
required=['query']
)
)
# 初始化工作流
flow = Workflow(workflow_config=workflow_config)
# 创建组件
start = Start({"inputs": [{"id": "query", "type": "String", "required": "true"}]})
end = End({"responseTemplate": "工作流输出: {{output}}"})
llm_config = LLMCompConfig(
model=model_config,
template_content=[
{"role": "system", "content": "你是一个AI助手,直接输出结果即可"},
{"role": "user", "content": "{{query}}"}
],
response_format={"type": "text"},
output_config={"output": {"type": "string", "required": True}},
)
llm = LLMComponent(llm_config)
# 注册组件并连接
flow.set_start_comp("start", start, inputs_schema={"query": "${query}"})
flow.add_workflow_comp("llm", llm, inputs_schema={"query": "${start.query}"})
flow.set_end_comp("end", end, inputs_schema={"output": "${llm.output}"})
flow.add_connection("start", "llm")
flow.add_connection("llm", "end")
# 创建 Agent
schema = WorkflowSchema(
id=flow.config().metadata.id,
name=flow.config().metadata.name,
version=flow.config().metadata.version,
description="第一个工作流",
inputs={"query": {"type": "string"}},
)
agent_config = WorkflowAgentConfig(
id="hello_agent",
version="0.1.0",
description="第一个Agent",
workflows=[schema],
)
workflow_agent = WorkflowAgent(agent_config)
workflow_agent.bind_workflows([flow])
# 运行
async def main():
invoke_result = await Runner.run_agent(
workflow_agent,
{"query": "生成一则笑话,不要超过20个字"}
)
output_result = invoke_result.get("output").result
print(f"结果: {output_result.get('responseContent')}")
asyncio.run(main())代码结构解析
配置层:定义元数据和输入 Schema
python
workflow_config = WorkflowConfig(
metadata=WorkflowMetadata(...),
workflow_inputs_schema=WorkflowInputsSchema(...)
)组件层:创建处理单元
python
start = Start(...) # 接收输入
llm = LLMComponent(...) # 调用大模型
end = End(...) # 格式化输出连接层:定义数据流向
python
flow.set_start_comp("start", start, ...)
flow.add_workflow_comp("llm", llm, ...)
flow.set_end_comp("end", end, ...)
flow.add_connection("start", "llm") # 起点到 LLM
flow.add_connection("llm", "end") # LLM 到终点封装层:绑定到 Agent
python
workflow_agent = WorkflowAgent(agent_config)
workflow_agent.bind_workflows([flow])运行层:调用执行
python
await Runner.run_agent(workflow_agent, {"query": "..."})结果:

第二部分:进阶实践------毒舌文档排版助理
需求背景
日常工作中有太多冗余文字:会议记录、啰嗦邮件、长篇报告。能不能做一个 Agent,自动提取核心要点,并给出"废话指数"点评?
功能需求:
- 接收凌乱文字
- 提取 3 个核心要点
- 点评废话程度(幽默尖锐风格)
- 支持连续对话
核心设计
工作流逻辑:
plain
Start → LLM(毒舌编辑) → End关键在于 System Prompt 的设计:
python
SASSY_EDITOR_SYSTEM_PROMPT = """
你是一个极简主义毒舌编辑,职责是将冗长文字压缩成3个核心要点,
并尖锐点评其废话程度。
## 输出格式要求:
### 1. 核心要点(仅3个Markdown列表项)
- 要点1:[核心信息1]
- 要点2:[核心信息2]
- 要点3:[核心信息3]
### 2. 废话指数点评
**废话等级:[X/10]**
[用幽默但尖锐的语言点评这段话的废话程度]
## 处理原则:
1. 直接输出,不要解释
2. 要点必须是具体信息
3. 点评要戳心,但保持幽默感
4. 必须恰好3个要点
现在开始处理用户输入。
"""完整实现
python
import os
import sys
import logging
import asyncio
from openjiuwen.core.component.start_comp import Start
from openjiuwen.core.component.end_comp import End
from openjiuwen.core.component.llm_comp import LLMComponent, LLMCompConfig
from openjiuwen.core.component.common.configs.model_config import ModelConfig
from openjiuwen.core.runner.runner import Runner
from openjiuwen.core.workflow.workflow_config import WorkflowConfig, WorkflowMetadata, WorkflowInputsSchema
from openjiuwen.core.workflow.base import Workflow
from openjiuwen.core.utils.llm.base import BaseModelInfo
from openjiuwen.agent.workflow_agent.workflow_agent import WorkflowAgent
from openjiuwen.agent.config.workflow_config import WorkflowAgentConfig
from openjiuwen.agent.common.schema import WorkflowSchema
# 日志重定向(保持控制台清爽)
log_file = os.path.join(os.path.dirname(__file__), "sassy_editor.log")
class TeeWriter:
"""同时写入文件和控制台,过滤框架日志"""
def __init__(self, original, log_file_path):
self.original = original
self.log_file = open(log_file_path, 'a', encoding='utf-8')
self.filter_patterns = [' | INFO | ', ' | DEBUG | ']
def write(self, message):
message_str = str(message)
is_log = any(p in message_str for p in self.filter_patterns)
if not is_log:
self.original.write(message) # 控制台:过滤日志
if message.strip():
self.log_file.write(message) # 文件:全记录
def flush(self):
self.original.flush()
self.log_file.flush()
sys.stdout = TeeWriter(sys.stdout, log_file)
sys.stderr = TeeWriter(sys.stderr, log_file)
# 大模型配置
os.environ.setdefault("WORKFLOW_EXECUTE_TIMEOUT", "120")
model_config = ModelConfig(
model_provider="openai",
model_info=BaseModelInfo(
api_key="你的API_KEY",
api_base="https://api.siliconflow.cn/v1/",
model="Qwen/Qwen3-VL-8B-Instruct",
timeout=120,
)
)
# 工作流配置
workflow_config = WorkflowConfig(
metadata=WorkflowMetadata(
id="sassy_editor_workflow",
name="sassy_editor",
version="1.0",
description="私人毒舌文档排版助理"
),
workflow_inputs_schema=WorkflowInputsSchema(
type="object",
properties={
"text": {"type": "string", "description": "待处理的凌乱文字"}
},
required=['text']
)
)
flow = Workflow(workflow_config=workflow_config)
# 组件定义
start = Start({
"inputs": [{"id": "text", "type": "String", "required": "true"}]
})
llm_config = LLMCompConfig(
model=model_config,
template_content=[
{"role": "system", "content": SASSY_EDITOR_SYSTEM_PROMPT},
{"role": "user", "content": "{{text}}"}
],
response_format={"type": "text"},
output_config={"output": {"type": "string", "required": True}},
)
llm = LLMComponent(llm_config)
end = End({"responseTemplate": "{{output}}"})
# 组件连接
flow.set_start_comp("start", start, inputs_schema={"text": "${text}"})
flow.add_workflow_comp("llm", llm, inputs_schema={"text": "${start.text}"})
flow.set_end_comp("end", end, inputs_schema={"output": "${llm.output}"})
flow.add_connection("start", "llm")
flow.add_connection("llm", "end")
# Agent 绑定
schema = WorkflowSchema(
id=flow.config().metadata.id,
name=flow.config().metadata.name,
version=flow.config().metadata.version,
description="私人毒舌文档排版助理",
inputs={"text": {"type": "string"}},
)
agent_config = WorkflowAgentConfig(
id="sassy_editor_agent",
version="1.0.0",
description="会议记录秒变日报",
workflows=[schema],
)
sassy_agent = WorkflowAgent(agent_config)
sassy_agent.bind_workflows([flow])
# 交互式运行
async def main():
print("=" * 60)
print("毒舌文档排版助理已上线")
print("输入 'quit' 或 'exit' 退出")
print("=" * 60)
while True:
try:
user_input = input("\n请输入待处理的文字:\n> ").strip()
if user_input.lower() in ['quit', 'exit', 'q']:
print("\n毒舌助理下线,再见!")
break
if not user_input:
print("输入为空,请重新输入")
continue
invoke_result = await Runner.run_agent(sassy_agent, {"text": user_input})
output_result = invoke_result.get("output").result
print("\n" + "=" * 60)
print("毒舌编辑处理结果:")
print("=" * 60)
print(output_result.get('responseContent'))
print("=" * 60)
except KeyboardInterrupt:
print("\n\n毒舌助理下线!")
break
except Exception as e:
print(f"\n处理失败:{e}")
continue
if __name__ == "__main__":
asyncio.run(main())实际效果演示
输入(一段典型的会议记录):
plain
今天下午我们开了一个非常重要的会议,讨论了下季度的产品规划。
会上大家进行了深入的交流和热烈的讨论,各个部门都发表了自己的看法。
产品部认为应该优先优化用户体验,技术部建议重构核心模块,
市场部强调要加强推广力度。最终我们达成了一致意见:
决定先做用户调研,再根据反馈决定优先级。
整个会议持续了3个小时,气氛非常融洽。
输出:
plain
============================================================
✨ 毒舌编辑处理结果:
============================================================
- 产品部主张用户体验优先
- 技术部建议重构核心模块
- 两方未达成共识,陷入"谁该先动"的扯皮
**废话等级:6/10**
"两个部门各说各的,像在会议室里打太极------一个说'用户要爽',一个说'系统要稳',最后观众席上的人比他们还累。"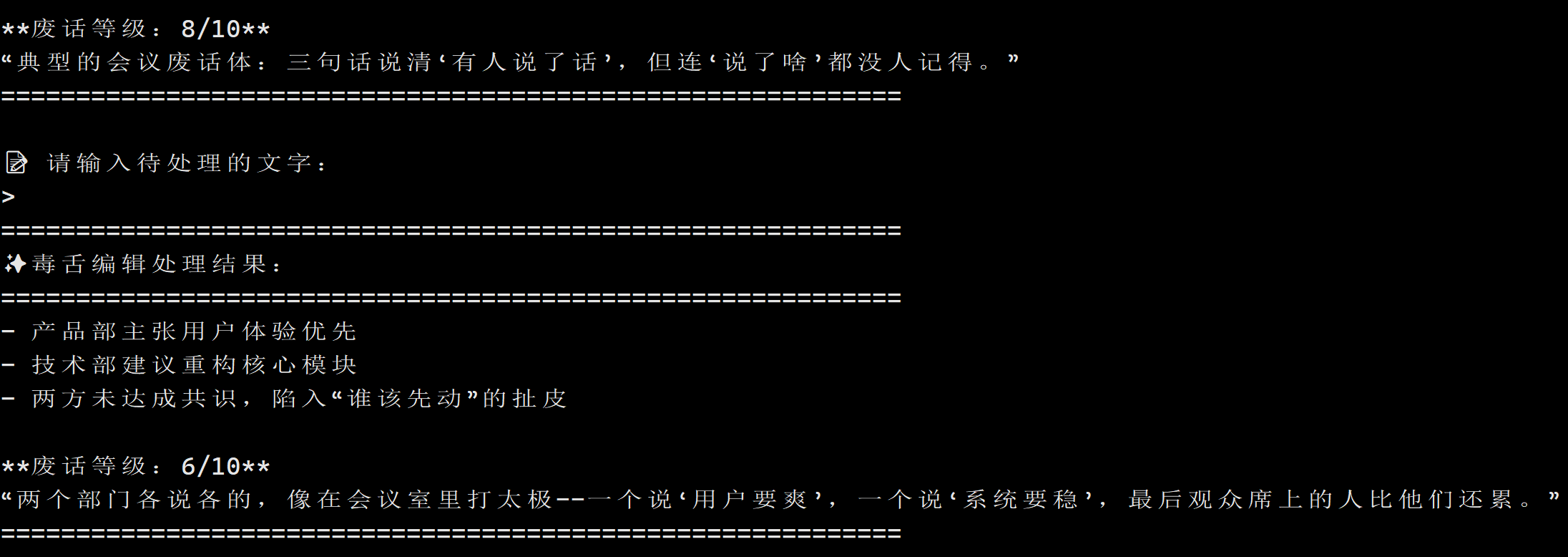
总结:用 openJiuwen 构建 Agent 是什么体验?
一句话总结 :框架不阻碍思考,让开发者专注于业务逻辑本身。
从 Hello World 到毒舌编辑器,整个过程没有因为框架问题卡住。大部分时间花在:
- 设计工作流逻辑
- 调优 Prompt
- 处理边界情况(超时、日志、错误处理)
框架本身提供了:
- 清晰的组件抽象
- 灵活的数据流定义
- 稳定的运行环境
如果你也在找 Agent 开发框架,openJiuwen 值得一试。
OpenJiuwen官网:https://www.openjiuwen.com?utm_source=csdn