目标: 理解MySQL锁机制,掌握死锁分析和解决方法
开篇:MVCC解决了读写冲突,写写冲突呢?
上一讲我们学了MVCC,读写可以不冲突。但写写冲突 怎么办?两个事务同时修改同一行,必须有先后顺序,这就需要锁。
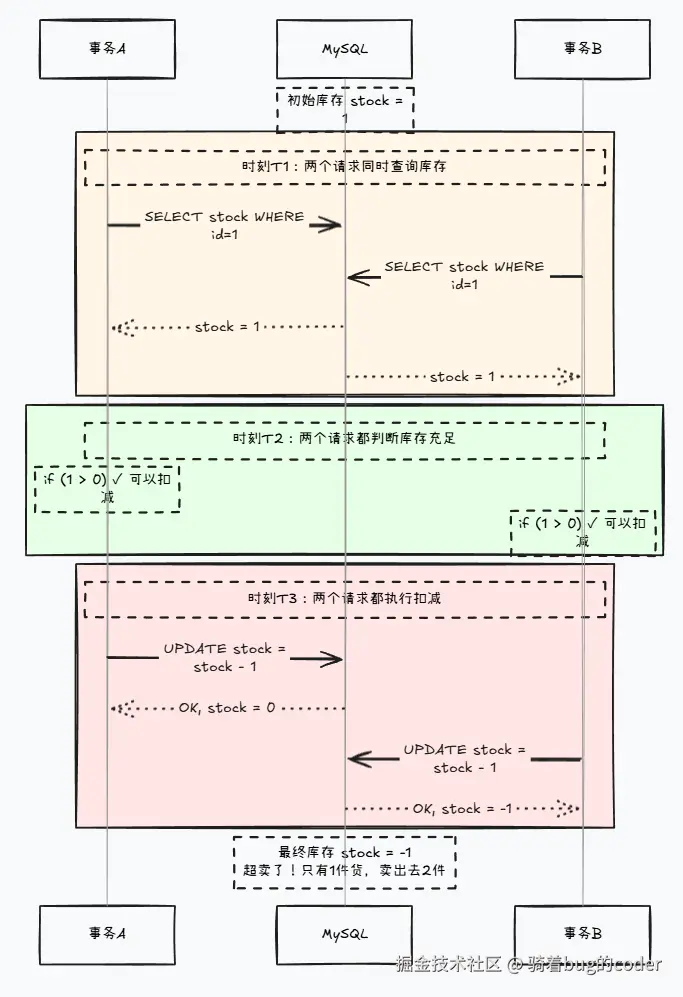
经典问题:秒杀超卖。应用层"先查后改",两个请求同时查到库存=1,都判断>0,都去扣库存,结果库存变成-1。
今天来看MySQL的锁机制、加锁规则和死锁解决方案。
一、为什么需要锁?
上一讲我们学了MVCC,读写可以不冲突。但写写冲突怎么办?
场景:两个事务同时修改同一行数据
sql
-- 初始:stock = 100
-- 事务A
UPDATE product SET stock = stock - 1 WHERE id = 1;
-- 事务B(同时执行)
UPDATE product SET stock = stock - 1 WHERE id = 1;
-- 期望结果:stock = 98如果没有任何控制,两个UPDATE同时读到stock=100,各自计算100-1=99,最后stock=99,丢失了一次更新。
MySQL的解决方案:行锁
InnoDB在执行UPDATE时,会自动对修改的行加排他锁(X锁)。
锁的作用: 让并发的写操作串行执行,事务B必须等事务A提交后才能修改同一行。
关键点:
- UPDATE/DELETE会自动加行锁,不需要手动加
- 锁在事务提交或回滚时释放
- 这就是为什么长事务会阻塞其他事务
二、MySQL锁的三个层级
MySQL的锁从粗到细分三层:全局锁 → 表级锁 → 行级锁。
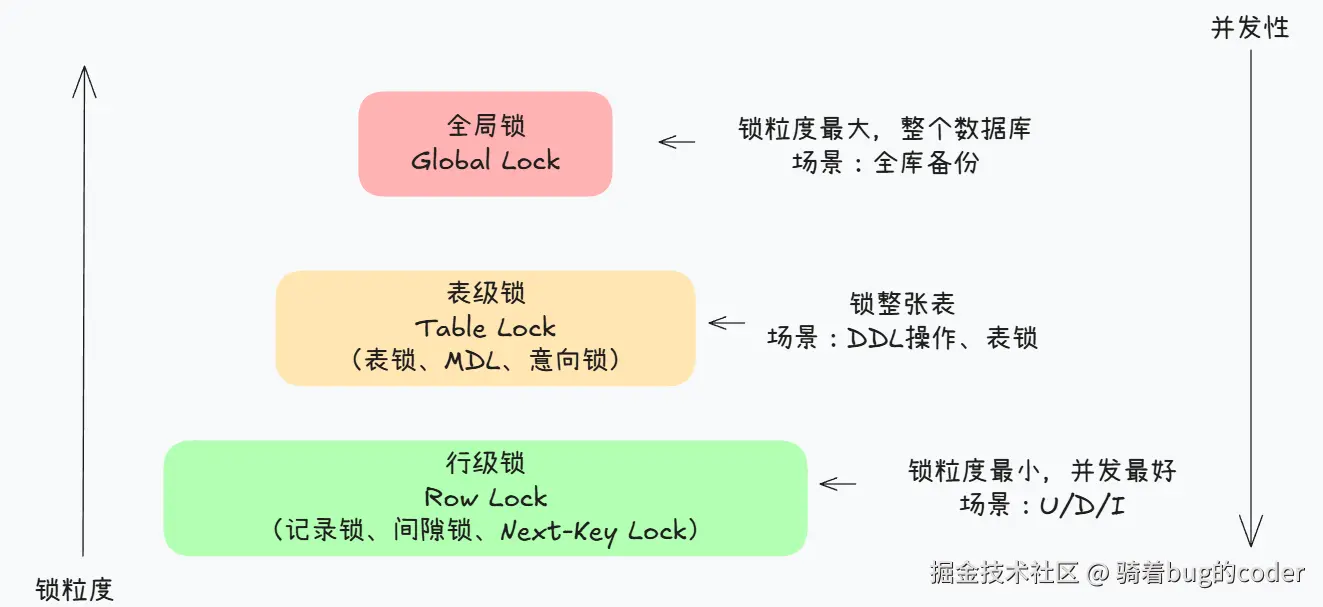
2.1 全局锁:锁住整个数据库
什么时候用? 全库备份的时候。
sql
FLUSH TABLES WITH READ LOCK; -- 加锁,整个库只读
-- 备份...
UNLOCK TABLES; -- 释放问题: 备份期间业务完全不能写,影响太大。
更好的方案: mysqldump的--single-transaction参数,利用MVCC读取一致性快照,不锁表。
2.2 表级锁:锁住整张表
表锁: 锁住整张表,并发性能差,一般不用。
元数据锁(MDL,Metadata Lock):
MDL 是 MySQL 5.5 引入的锁,用于保护表结构,防止查询时表结构被修改。
MDL 的工作方式:
- 执行 SELECT/INSERT/UPDATE/DELETE 时,自动加 MDL 读锁
- 执行 ALTER TABLE/DROP TABLE 时,自动加 MDL 写锁
- 读锁之间不冲突(多个查询可以并发)
- 读锁和写锁互斥(ALTER 必须等所有查询结束)
为什么需要 MDL?
sql
-- 没有 MDL 会出问题:
-- 事务A 正在执行 SELECT * FROM orders WHERE id = 1;
-- 事务B 执行 ALTER TABLE orders DROP COLUMN amount;
-- 事务A 读到一半,表结构变了,崩溃!MDL 保证:查询期间表结构不会被修改。
MDL 的坑: 长事务持有 MDL 读锁,会阻塞 ALTER TABLE,而 ALTER 又会阻塞后续所有查询(后面 5.1 节会详细讲)。
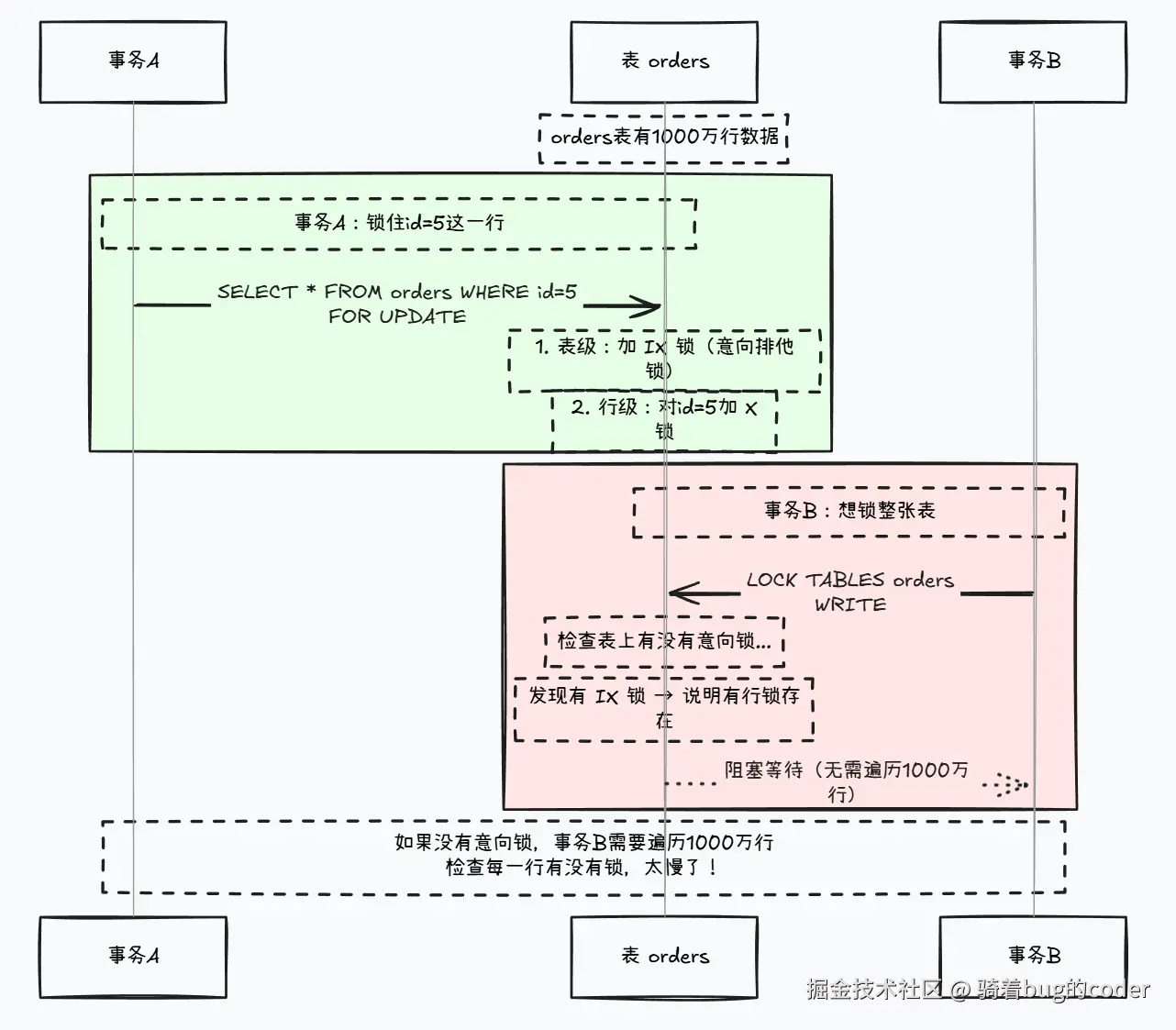
意向锁:快速判断表中有没有行锁
这是个容易被忽略但很重要的概念。
场景: 事务A锁住了id=1这一行,事务B想锁整张表。
没有意向锁: B需要遍历所有行,检查有没有行锁。表有1000万行,遍历一遍太慢了。
有意向锁: A在锁行之前,先在表上加一个意向锁(IX)。B只需要检查表上有没有IX锁,O(1)时间复杂度。
| 锁类型 | 含义 | 加锁时机 |
|---|---|---|
| IS(意向共享锁) | 表中有行被加了S锁 | SELECT ... LOCK IN SHARE MODE |
| IX(意向排他锁) | 表中有行被加了X锁 | SELECT ... FOR UPDATE |
2.3 行级锁:锁住单行或多行(RR隔离级别)
InnoDB支持行级锁,锁粒度最小,并发性能最好。以下加锁行为基于默认的 RR(可重复读)隔离级别,RC 级别下没有间隙锁。
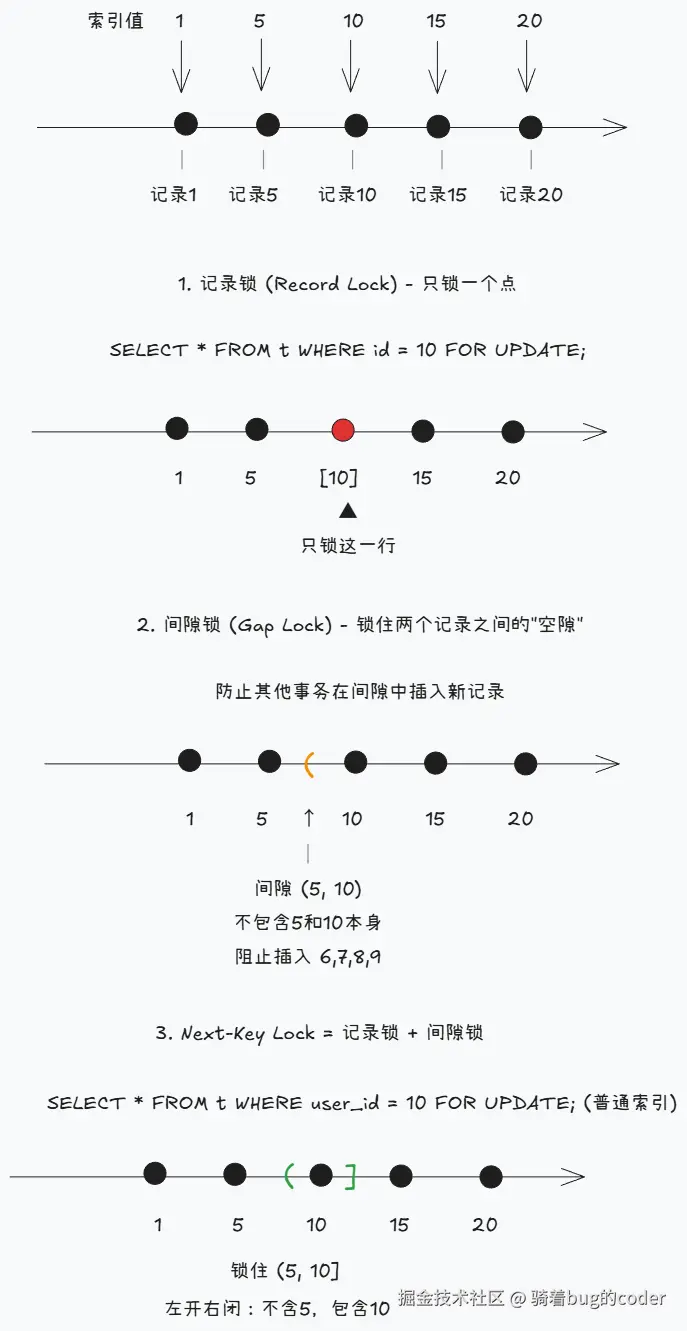
记录锁(Record Lock): 锁住单行记录。
sql
SELECT * FROM orders WHERE id = 1 FOR UPDATE; -- 只锁住id=1这一行间隙锁(Gap Lock): 锁住记录之间的"空隙",防止幻读。
为什么需要间隙锁?看这个场景:
sql
-- 表中有id: 1, 5, 10
-- 事务A
SELECT * FROM orders WHERE id > 3 FOR UPDATE; -- 返回id=5, 10
-- 事务B
INSERT INTO orders(id) VALUES(4); -- 如果成功,事务A再查就多了一行(幻读)间隙锁锁住(3, 5)这个间隙,事务B的INSERT会被阻塞,防止幻读。
Next-Key Lock: 记录锁 + 间隙锁,InnoDB默认的行锁算法。
查看锁信息:
sql
SELECT * FROM performance_schema.data_locks;
SELECT * FROM performance_schema.data_lock_waits;三、加锁规则:不同查询锁的范围不同
这是面试高频考点,也是排查死锁的关键。
核心问题: 执行一条SQL,到底锁了哪些行?
答案取决于两个因素:查询条件 + 索引类型。
3.1 等值查询的加锁规则
主键/唯一索引等值查询:只锁一行
sql
-- id是主键,表中有id: 1, 5, 10
SELECT * FROM t WHERE id = 5 FOR UPDATE;
-- 只加记录锁,锁住id=5这一行为什么只锁一行?因为主键/唯一索引保证了只有一条记录匹配,不需要锁间隙。
普通索引等值查询:锁记录+间隙
sql
-- idx_user_id是普通索引,表中有user_id: 1, 5, 5, 10
SELECT * FROM orders WHERE user_id = 5 FOR UPDATE;
-- 加Next-Key Lock:(1, 5] + (5, 10)为什么要锁间隙?因为普通索引可能有多条记录匹配,需要防止其他事务插入新的user_id=5的记录。
3.2 范围查询的加锁规则
sql
-- id是主键,表中有id: 1, 5, 10, 15
SELECT * FROM t WHERE id >= 5 AND id < 12 FOR UPDATE;
-- 加锁范围:[5, 10] + (10, 15)范围查询会锁住所有扫描到的记录和间隙。
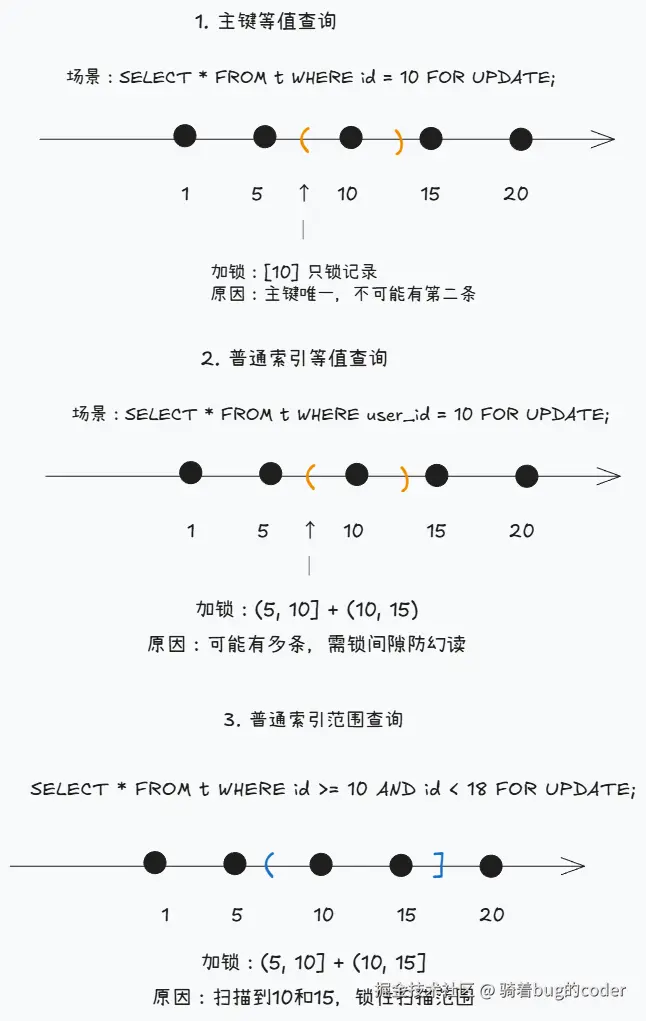
3.3 加锁规则总结
| 查询类型 | 索引类型 | 加锁范围 |
|---|---|---|
| 等值查询 | 主键/唯一索引 | 记录锁(只锁一行) |
| 等值查询 | 普通索引 | Next-Key Lock + 后间隙 |
| 范围查询 | 主键/唯一索引 | 记录锁 + 间隙锁 |
| 范围查询 | 普通索引 | Next-Key Lock |
| 任意查询 | 无索引 | 全表所有行和间隙(等于锁表) |
关键点: 没有索引的查询会锁住整张表的所有行和间隙!这是很多死锁和性能问题的根源。
四、死锁:互相等待,谁也走不了
4.1 什么是死锁?
两个事务互相等待对方持有的锁,形成循环等待,谁也无法继续。
sql
-- 事务A
BEGIN;
UPDATE orders SET status = 1 WHERE id = 1; -- 锁住id=1
UPDATE orders SET status = 1 WHERE id = 2; -- 等待id=2...
-- 事务B
BEGIN;
UPDATE orders SET status = 1 WHERE id = 2; -- 锁住id=2
UPDATE orders SET status = 1 WHERE id = 1; -- 等待id=1...
-- 死锁!A等B,B等A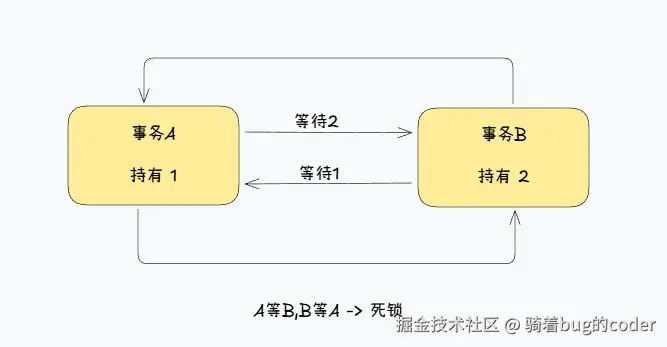
4.2 死锁日志分析实战
遇到死锁怎么排查?看死锁日志。
sql
SHOW ENGINE INNODB STATUS\G真实死锁日志解读:
perl
------------------------
LATEST DETECTED DEADLOCK
------------------------
2026-01-04 18:02:32 140087116523072
*** (1) TRANSACTION:
TRANSACTION 6103196, ACTIVE 14 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 3 lock struct(s), heap size 1128, 2 row lock(s)
MySQL thread id 198162, query id 24473475 223.160.212.163 root updating
UPDATE orders SET status = 1 WHERE id = 2
↑ 事务1正在执行的SQL
*** (1) HOLDS THE LOCK(S):
RECORD LOCKS space id 15 page no 5 n bits 368 index PRIMARY of table `company_db`.`orders`
trx id 6103196 lock_mode X locks rec but not gap
Record lock, heap no 2 PHYSICAL RECORD: n_fields 8; compact format; info bits 0
0: len 8; hex 8000000000000001; asc ;;
↑ 事务1持有 id=1 的锁(0x01 = 1)
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 15 page no 5 n bits 368 index PRIMARY of table `company_db`.`orders`
trx id 6103196 lock_mode X locks rec but not gap waiting
Record lock, heap no 3 PHYSICAL RECORD: n_fields 8; compact format; info bits 0
0: len 8; hex 8000000000000002; asc ;;
↑ 事务1在等待 id=2 的锁(0x02 = 2)
*** (2) TRANSACTION:
TRANSACTION 6103197, ACTIVE 10 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 3 lock struct(s), heap size 1128, 2 row lock(s)
MySQL thread id 198163, query id 24473479 223.160.212.163 root updating
UPDATE orders SET status = 1 WHERE id = 1
↑ 事务2正在执行的SQL
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 15 page no 5 n bits 368 index PRIMARY of table `company_db`.`orders`
trx id 6103197 lock_mode X locks rec but not gap
Record lock, heap no 3 PHYSICAL RECORD: n_fields 8; compact format; info bits 0
0: len 8; hex 8000000000000002; asc ;;
↑ 事务2持有 id=2 的锁
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 15 page no 5 n bits 368 index PRIMARY of table `company_db`.`orders`
trx id 6103197 lock_mode X locks rec but not gap waiting
Record lock, heap no 2 PHYSICAL RECORD: n_fields 8; compact format; info bits 0
0: len 8; hex 8000000000000001; asc ;;
↑ 事务2在等待 id=1 的锁
*** WE ROLL BACK TRANSACTION (2)
↑ InnoDB选择回滚事务2(代价较小的那个)分析三步走:
-
找 HOLDS THE LOCK(S):看事务持有什么锁
- 事务1 持有 id=1 的锁
- 事务2 持有 id=2 的锁
-
找 WAITING FOR THIS LOCK:看事务在等什么锁
- 事务1 等待 id=2 的锁
- 事务2 等待 id=1 的锁
-
画出等待关系图,确认循环等待
bash
事务1 持有 id=1,等待 id=2
事务2 持有 id=2,等待 id=1
事务1 → 等待 → 事务2 → 等待 → 事务1 (形成环 = 死锁)关键字段速查:
| 字段 | 含义 |
|---|---|
lock_mode X |
排他锁 |
locks rec but not gap |
记录锁(不含间隙) |
hex 8000000000000001 |
主键值(去掉最高位8,剩下的是id=1) |
WE ROLL BACK TRANSACTION (2) |
InnoDB回滚了事务2 |
4.3 死锁预防
| 原则 | 说明 | 示例 |
|---|---|---|
| 统一访问顺序 | 所有事务按相同顺序访问表和行 | 都先更新id小的,再更新id大的 |
| 缩短事务时间 | 事务中不要有耗时操作 | 把API调用放到事务外面 |
| 降低隔离级别 | RC无间隙锁,减少死锁 | 如果业务允许,用RC |
| 添加合适索引 | 避免锁住大量行 | 确保WHERE条件有索引 |
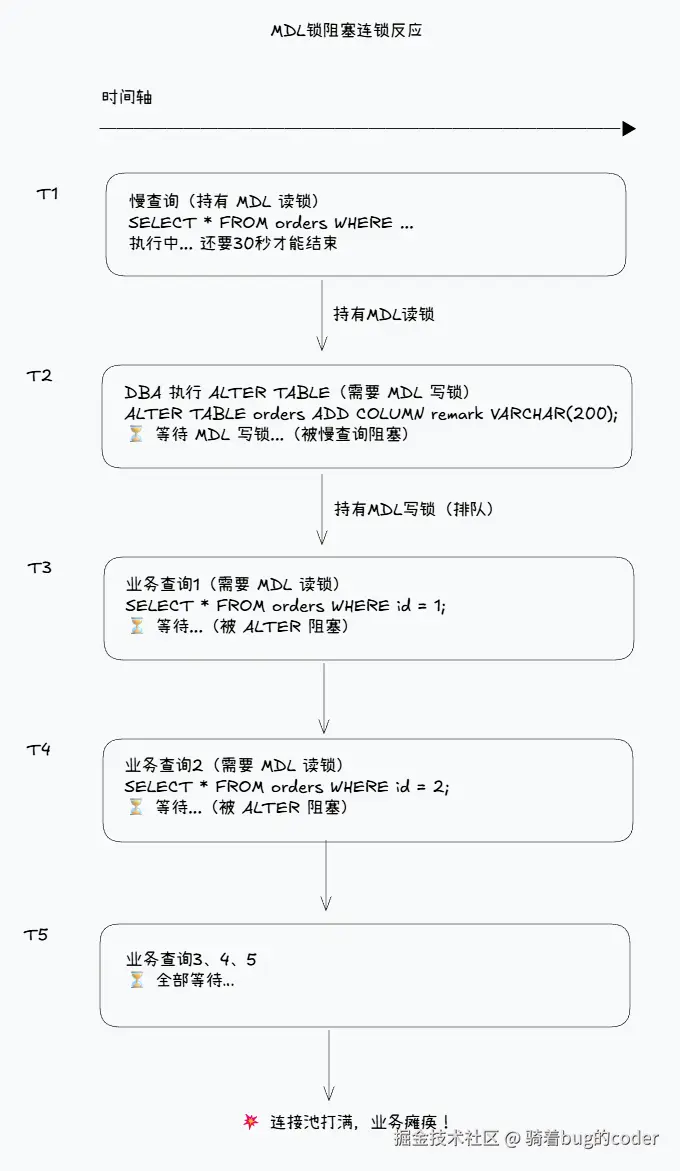
五、在线DDL的锁问题
5.1 问题场景
sql
-- 给大表加字段,业务卡住了
ALTER TABLE orders ADD COLUMN remark VARCHAR(200);为什么会卡住?
原因: ALTER TABLE需要获取MDL写锁。如果有长事务持有MDL读锁(比如一个慢查询),ALTER会等待。更糟糕的是,后续所有查询也会等待ALTER,形成连锁阻塞。
5.2 解决方案
方案1:pt-online-schema-change
原理:创建新表 → 复制数据 → 触发器同步增量 → 原子切换表名
bash
pt-online-schema-change \
--alter "ADD COLUMN remark VARCHAR(200)" \
D=test,t=orders \
--execute方案2:gh-ost(GitHub出品)
原理:类似pt-osc,但用binlog同步增量,不用触发器,对主库压力更小。
bash
gh-ost \
--alter="ADD COLUMN remark VARCHAR(200)" \
--database=test \
--table=orders \
--execute⚠️ 注意: pt-osc 和 gh-ost 都依赖主从复制。如果主从延迟较大,迁移过程会变慢,甚至可能失败。建议在延迟 < 1秒时执行。
方案3:MySQL 8.0 Instant DDL
Instant 的意思是"即时",只修改表的元数据(数据字典),不重建表数据,所以秒级完成。
sql
-- MySQL 8.0 会自动选择最优算法,支持 Instant 的操作会自动使用
ALTER TABLE orders ADD COLUMN remark VARCHAR(200);
-- 也可以显式指定,如果不支持会报错(更安全)
ALTER TABLE orders ADD COLUMN remark VARCHAR(200), ALGORITHM=INSTANT;支持的操作:添加列、修改默认值、重命名列等。不支持修改列类型、加索引。
六、库存超卖:锁的经典应用场景
6.1 问题场景
秒杀场景,库存只有1个,两个请求同时来:
java
// 请求A
int stock = query("SELECT stock FROM product WHERE id = 1"); // stock = 1
if (stock > 0) {
execute("UPDATE product SET stock = stock - 1 WHERE id = 1");
}
// 请求B(同时执行)
int stock = query("SELECT stock FROM product WHERE id = 1"); // stock = 1
if (stock > 0) {
execute("UPDATE product SET stock = stock - 1 WHERE id = 1");
}
// 结果:库存变成-1,超卖了!问题根源: "先查后改"不是原子操作,两个请求都查到stock=1,都判断>0,都去扣减。
6.2 解决方案对比
数据库层方案:
| 方案 | SQL | 优点 | 缺点 |
|---|---|---|---|
| 悲观锁 | SELECT ... FOR UPDATE |
简单可靠 | 性能差,锁等待时间长 |
| 乐观锁 | UPDATE ... WHERE version = ? |
无锁等待 | 高并发时重试多,成功率低 |
| 直接扣减 | UPDATE ... SET stock = stock - 1 WHERE stock > 0 |
原子操作,一条SQL | 热点行锁竞争 |
应用层方案(高并发场景):
| 方案 | 原理 | 适用场景 |
|---|---|---|
| Redis 预扣减 | 库存放 Redis,先扣 Redis 再异步扣 DB | 秒杀、高并发 |
| 分布式锁 | Redis/ZK 加锁,串行处理 | 并发量中等 |
| 消息队列 | 请求入队,串行消费 | 削峰填谷 |
简单场景用直接扣减:
sql
UPDATE product SET stock = stock - 1 WHERE id = 1 AND stock > 0;
-- 检查affected_rows,为0说明库存不足高并发秒杀用 Redis 预扣减:
java
// 1. Redis 扣减(原子操作)
Long remain = redis.decr("stock:" + productId);
if (remain < 0) {
redis.incr("stock:" + productId); // 回滚
return "库存不足";
}
// 2. 异步发消息,扣减数据库
mq.send(new OrderMessage(productId, userId));数据库扛不住高并发写,Redis 单机 10 万 QPS,适合做前置拦截。
七、避坑指南
坑1:长事务持有锁
问题: 事务中调用外部API,持有锁时间过长。
正确做法: 把耗时操作放到事务外面。
坑2:WHERE条件没有索引
问题: 没有索引会锁住整张表。
正确做法: 确保WHERE条件有索引。
坑3:在线DDL阻塞业务
问题: ALTER TABLE等待MDL锁,阻塞所有查询。
正确做法: 使用pt-online-schema-change或gh-ost。
坑4:间隙锁导致死锁
问题: RR隔离级别下,间隙锁容易导致死锁。
正确做法: 如果业务允许,使用RC隔离级别(无间隙锁)。
八、作业
基础题
模拟死锁并分析日志
打开两个MySQL客户端,按以下步骤制造死锁:
sql
-- 准备数据
CREATE TABLE test_lock (id INT PRIMARY KEY, val INT);
INSERT INTO test_lock VALUES (1, 100), (2, 200);| 步骤 | 客户端A | 客户端B |
|---|---|---|
| 1 | BEGIN; |
BEGIN; |
| 2 | UPDATE test_lock SET val=1 WHERE id=1; |
|
| 3 | UPDATE test_lock SET val=2 WHERE id=2; |
|
| 4 | UPDATE test_lock SET val=1 WHERE id=2; -- 等待B |
|
| 5 | UPDATE test_lock SET val=2 WHERE id=1; -- 死锁! |
用 SHOW ENGINE INNODB STATUS 查看死锁日志,画出等待关系图。
进阶题
分析加锁范围
sql
-- 表结构:orders(id PRIMARY KEY, user_id INDEX, status)
-- 数据:id = 1, 5, 10, 15, 20
-- 分析以下SQL在RR隔离级别下的加锁范围:
-- A: SELECT * FROM orders WHERE id = 10 FOR UPDATE;
-- B: SELECT * FROM orders WHERE user_id = 10 FOR UPDATE;
-- C: SELECT * FROM orders WHERE id > 10 FOR UPDATE;
-- D: SELECT * FROM orders WHERE status = 1 FOR UPDATE; -- status无索引九、下一讲预告
并发问题解决了,但数据量增长到千万级,单机MySQL撑不住了。
第11讲:主从复制与读写分离架构
下一讲会讲这些:
- 主从复制原理:Dump线程、IO线程、SQL线程如何协作
- GTID复制:为什么它是故障切换的救星
- 读写分离实现:应用层 vs ShardingSphere中间件
- 主从延迟:原因分析和三种解决方案
- 主从切换实战:计划内切换步骤 + MHA自动切换
下一讲见!