文本匹配任务
任务背景
在自然语言处理领域,文本匹配是一项基础且重要的任务,其核心目标是判断两个或多个文本之间的语义相似性或相关性。在实际应用中,文本匹配可用于智能问答系统(如匹配用户问题与标准问题)、信息检索(如匹配查询与文档)、对话系统(如上下文匹配)等场景。
本项目围绕文本匹配任务展开,通过构建模型实现对用户输入问题与标准问题库中问题的匹配,从而找到最相似的标准问题。该任务的核心挑战在于如何精准捕捉文本的深层语义信息,克服自然语言表达的多样性(如同一语义的不同表述方式)和模糊性(如一词多义、歧义句)。例如,用户询问 "怎样修改宽带密码" 与标准问题库中的 "固定宽带服务密码修改" 虽表述不同,但语义一致,模型需要准确识别这种关联。

建立一个近义词(questions)到固定目标词(target)的映射系统,让系统能根据用户输入的问题,匹配到对应的固定目标词,从而给出正确的答案,这也是智能助手理解用户意图的核心原理。
python
{"questions": ["密码忘了", "没记住密码"], "target": "密码重置"}
{"questions": ["改下畅聊套餐", "畅聊"], "target": "畅聊套餐变更"}任务需求
- 构建一个能够将用户输入的问题与预设的标准问题库进行匹配的系统
- 系统需能对输入问题进行编码,将其转化为向量表示
- 对标准问题库中的问题进行预处理和向量编码
- 通过计算向量间的相似度,找到与输入问题最匹配的标准问题
- 评估模型的匹配准确率,不断提升模型性能
本人写了一个demo进行该任务演示
该demo基于PyTorch框架实现,采用孪生网络(Siamese Network)结构进行文本匹配任务。通过训练模型学习文本的向量表示,进而实现对输入问题与标准问题库中问题的相似度计算和匹配。
你希望我基于你提供的这段SiameseNetwork代码,去掉之前回答里的"三元组类型"和"训练技巧与注意事项"部分,聚焦在Triplet Loss的核心原理、讲解、作用,并结合你的代码进行针对性解读。
我会先梳理Triplet Loss的核心内容,再重点分析你代码中cosine_triplet_loss函数的实现逻辑、与标准Triplet Loss的对应关系,以及代码中存在的问题和优化建议。
Triplet Loss 核心原理
Triplet Loss(三元组损失)是度量学习的核心损失函数,核心目标是让同类样本特征距离更近、异类样本特征距离更远,从而学习到具有良好区分性的特征嵌入。
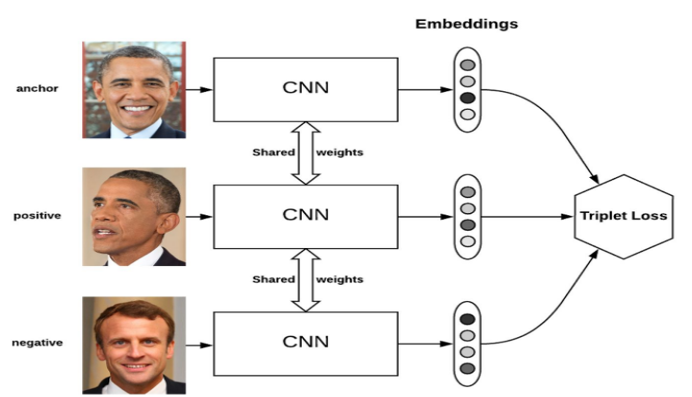
1. 三元组构成
- Anchor (a):基准样本(你的代码中对应待匹配的句子特征)
- Positive §:与Anchor同类的样本(你的代码中对应匹配正确的句子特征)
- Negative (n):与Anchor异类的样本(你的代码中对应匹配错误的句子特征)
2. 核心约束与公式
- 核心约束:Anchor 到 Positive 的距离 + 间隔 α < Anchor 到 Negative 的距离
- 标准损失公式 :
L=max(d(a,p)−d(a,n)+α,0)L = \max\left( d(a,p) - d(a,n) + \alpha, 0 \right)L=max(d(a,p)−d(a,n)+α,0)
其中:- d(⋅)d(\cdot)d(⋅) 是距离度量(你代码中用余弦距离,标准实现常用欧氏距离)
- α\alphaα 是间隔超参数(你代码中默认设为0.1)
- max(⋅,0)\max(\cdot, 0)max(⋅,0) 保证仅当约束不满足时才计算损失
Triplet Loss的作用
你的代码是为句子语义匹配设计的,Triplet Loss在此场景下的核心作用:
1. 学习语义区分的句子嵌入
- 相比分类损失(如CrossEntropyLoss),Triplet Loss不依赖固定的类别数,直接优化句子间的语义距离;
- 例如:让"今天天气好"(a)和"今日天气不错"(p)距离更近,和"今天下雨了"(n)距离更远。
2. 适配细粒度语义匹配
- 适用于问答系统、语义检索、文本相似度计算等场景;
什么是孪生网络
孪生网络(Siamese Network)是一种由两个或多个结构相同且共享权重的子网络构成的神经网络架构,核心用于学习样本间的相似性或差异性,通过度量学习将输入映射到统一特征空间以实现公平比较。
训练数据展示
python
{"questions": ["我要修改固定宽带的密码", "修改固定宽带密码的方法", "如何修改固定宽带密码", "固定网密码的修改方法是什么", "更改固定宽带密码有哪些步骤", "通过什么渠道可以改固定宽带密码", "固定宽带密码的修改途径", "固定宽带密码被别人破解了怎么改", "固定网怎么改密码", "更改固定网密码要哪些步骤", "介绍一下固定网的密码修改流程", "电信宽带如何更改固定宽带密码", "能在官网改固定宽带密码吗", "客服能给改固定宽带网密码吗", "我想在电信官网改固定网密码", "改固定宽带密码要去营业厅吗", "固定宽带密码可以在哪儿更改", "固定宽带密码的修改能通过给客服打电话吗", "我该怎么做可以改掉固定宽带密码", "改固网的服务密码需要带什么", "想给宽带改一下密码"], "target": "固定宽带服务密码修改"}
{"questions": ["手机暂时不用能办理停机吗", "帮我办一个停机保号", "能不能暂时把号码停用", "手机停机了帮我开一下吗", "手机号码办理停机保号业务", "上个月停机现在帮我恢复一下", "号码停了三个月能不能帮我恢复", "我的手机要恢复使用", "暂停我手机的所有服务", "几个月都不用这个号儿办一下停机", "手机接下来不用了可以帮我停一下", "办理停机保号", "停机保号怎么办理", "办理停机保号的方法是什么", "给我办一个停机保号业务", "停机保号在哪儿能办理", "能在官网办停机保号吗", "停机保号能打电话办吗", "想暂时停机保留号码", "手机号暂时不想停一段时间", "保留手机号的情况下办理停机", "办理停机保号的流程是什么样的", "停机保号的办理需要什么手续", "介绍一下办停机保号的主要步骤", "客服能给办理停机保号吗", "停机保号的办理方法", "哪些途径可以办理停机保号的业务", "办理停机保号要去营业厅吗", "停机保号有哪些步骤", "我要打电话办一个停机保号", "什么渠道能办停机保号", "最近都不用这个号可以先停机吗", "暂时不想用这个号", "卡可不可以下个月再用", "先把这个号停一下", "这段时间准备不用这个号", "想把号码给停了但是还想要这个号", "手机号还要但是想暂停服务", "手机卡停机但是手机号还要", "我暂时不用了但是我又想以后在用"], "target": "停机保号"}
{"questions": ["请给我紧急停机", "我已经交足了话费请立即帮我开机", "我想办理停机", "我想注销账号", "怎么把账号停掉不用了", "申请手机停机", "关闭我这个手机号所有的服务", "我要办理停机", "请把我的手机号停掉", "手机卡丢了帮我办停机", "我手机丢了能办停机吗", "办理停机需要去营业厅吗", "办理停机的流程", "手机停机后还会扣费吗", "我要办停机业务", "办理停机需要提供什么信息吗", "帮我停一下机", "把我的手机号码停机", "我的手机要重新开机", "我想把这个号码停了", "现在手机停了怎么办", "电话丢失给我赶快停机", "怎样办理紧急停机业务", "办理紧急停机业务要去营业厅吗", "办理紧急停机后手机还会扣费用吗", "办理了紧急停机能不能立即生效", "赶快给我把原来的手机号注销", "立刻停机", "紧急停机后多久会失效", "办理紧急停机需要什么手续", "手机卡丢了给我把这张卡停了", "手机被偷了给我停机", "紧急停机后怎样补卡", "紧急停机会收手续费吗", "手机卡找不见了怎样停卡", "找着了之前的手机卡给我重新开通", "给我开通之前办理过紧急停机的卡", "打电话怎样办理紧急停机业务", "办理紧急停机的方法有哪些", "怎样可以快速的停机", "在哪里可以办理紧急停机业务", "手机号不想用了办一下停机", "手机不知道谁拿走了现在停机", "办理手机号停机业务", "怎么办理停机", "手机被偷怎么办", "将这个手机号给停了"], "target": "紧急停机"}
{"questions": ["宽带坏了", "网断了", "有线宽带断了", "宽带不能用了找谁", "网速太慢了", "网慢的都不能用了", "宽带出现了问题找人帮我修一下", "显示宽带连接那一直是个感叹号", "电信宽带有毛病能有人来修吗"], "target": "有限宽带障碍报修"}
{"questions": ["改下无线套餐", "无线套餐能变么", "想换个无线套餐", "现在这个无线套餐太贵了想换", "WiFi是2G的能升吗"], "target": "无线套餐变更"}
{"questions": ["密码想换一下", "能帮我改密码吗", "密码变更", "换个密码"], "target": "密码修改"}
{"questions": ["把短信套餐取消了", "不要短信套餐了", "把短信套餐退了", "取消短信", "目前这个短信条数太少了不够用我要换个多的"], "target": "短信套餐取消"}
{"questions": ["开个短信套餐现在就能用的", "把短信开通了马上能用的那种", "开通短信套餐", "我想把短信套餐给开通了"], "target": "短信套餐开通立即生效"}
{"questions": ["改下畅聊套餐", "畅聊"], "target": "畅聊套餐变更"}
{"questions": ["改彩信套裁", "彩信", "不想再使用彩信了"], "target": "彩信套餐变更"}
{"questions": ["密码忘了", "没记住密码", "查一下密码"], "target": "密码重置"}代码展示
1. 配置文件(config.py)
该文件定义了项目中用到的各类配置参数,统一管理路径、模型参数、训练参数等,方便后续修改和维护。
python
# -*- coding: utf-8 -*-
"""
配置参数信息
"""
Config = {
"model_path": "./model_output", # 模型保存路径
"schema_path": r"F:\第八周 文本匹配\data\schema.json", # 标准问题标签映射文件路径
"train_data_path": r"F:\第八周 文本匹配\data\train.json", # 训练数据路径
"valid_data_path": r"F:\第八周 文本匹配\data\valid.json", # 验证数据路径
"vocab_path": r"F:\第八周 文本匹配\chars.txt", # 词表/字表路径
"max_length": 20, # 文本最大长度
"hidden_size": 128, # 隐藏层大小
"epoch": 1000, # 训练轮数
"batch_size": 32, # 批处理大小
"epoch_data_size": 200, # 每轮训练采样数量
"positive_sample_rate": 0.5, # 正样本比例
"optimizer": "adam", # 优化器
"learning_rate": 1e-3, # 学习率
}2. 数据加载模块(loader.py)
该模块负责数据的读取、预处理、编码和加载,为模型训练和测试提供数据支持。
数据加载模块(loader.py)代码解释
-------核心类 DataGenerator
用于加载、预处理训练集和测试集数据,生成模型可输入的格式(如文本转ID序列、采样三元组样本等),继承自PyTorch的Dataset思想(通过__len__和__getitem__接口适配DataLoader)。
python
class DataGenerator:
def __init__(self, data_path, config):
# 初始化配置参数(如最大长度、词表路径等)
self.config = config
# 数据文件路径
self.path = data_path
# 加载词表(字/词到ID的映射)
self.vocab = load_vocab(config["vocab_path"])
# 将词表大小存入配置,供模型使用
self.config["vocab_size"] = len(self.vocab)
# 加载schema(标准问题标签到ID的映射,如"密码重置"→1)
self.schema = load_schema(config["schema_path"])
# 每轮训练的采样数量(因采用随机采样,需限制数量)
self.train_data_size = config["epoch_data_size"]
# 标识数据类型("train"或"test")
self.data_type = None
# 加载数据
self.load()------- load方法:加载并解析数据文件
根据数据格式区分训练集和测试集,分别处理并存储。
python
def load(self):
self.data = [] # 存储测试集数据(输入ID+标签ID)
self.knwb = defaultdict(list) # 存储训练集数据:key=标准问题ID,value=该类别下的所有问题ID序列
with open(self.path, encoding="utf8") as f:
for line in f:
line = json.loads(line)
# 训练集格式为字典:{"questions": [问题1, 问题2...], "target": 标准问题标签}
if isinstance(line, dict):
self.data_type = "train"
questions = line["questions"] # 同一标准问题的不同表述
label = line["target"] # 标准问题标签
for question in questions:
# 将问题转为ID序列并转成Tensor
input_id = self.encode_sentence(question)
input_id = torch.LongTensor(input_id)
# 按标准问题ID分组存储(用于后续采样)
self.knwb[self.schema[label]].append(input_id)
# 测试集格式为列表:[问题, 标准问题标签]
else:
self.data_type = "test"
assert isinstance(line, list)
question, label = line
# 问题转ID序列
input_id = self.encode_sentence(question)
input_id = torch.LongTensor(input_id)
# 标签转ID
label_index = torch.LongTensor([self.schema[label]])
self.data.append([input_id, label_index])------- encode_sentence方法:文本转ID序列
将原始文本(句子)转换为词表中的ID序列,支持分词(按词)或分字。
python
def encode_sentence(self, text):
input_id = []
# 若词表为词级(words.txt),则用jieba分词
if self.config["vocab_path"] == "words.txt":
for word in jieba.cut(text):
# 未登录词用[UNK]的ID替代
input_id.append(self.vocab.get(word, self.vocab["[UNK]"]))
# 否则按字处理
else:
for char in text:
input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))
# 补齐或截断至固定长度
input_id = self.padding(input_id)
return input_id------- padding方法:统一序列长度
确保所有输入序列长度一致(等于config["max_length"]),短序列补0,长序列截断。
python
def padding(self, input_id):
# 截断过长的序列
input_id = input_id[:self.config["max_length"]]
# 补齐过短的序列(用0填充,0为padding的ID)
input_id += [0] * (self.config["max_length"] - len(input_id))
return input_id------- 数据集长度与样本获取
__len__:返回数据集大小(训练集为配置的采样数量,测试集为实际样本数)。__getitem__:按索引获取样本(训练集随机采样三元组,测试集返回固定样本)。
python
def __len__(self):
if self.data_type == "train":
return self.config["epoch_data_size"]
else:
assert self.data_type == "test", self.data_type
return len(self.data)
def __getitem__(self, index):
if self.data_type == "train":
return self.train_sample() # 训练集返回随机采样的三元组
else:
return self.data[index] # 测试集返回固定的(输入ID,标签ID)------- train_sample方法:生成三元组训练样本
为Triplet Loss生成(Anchor, Positive, Negative)样本,确保同类样本距离近、异类样本距离远。
python
def train_sample(self):
# 获取所有标准问题的ID列表
standard_question_index = list(self.knwb.keys())
# 随机选择两个不同的标准问题类别:p(正例类别)和n(负例类别)
p, n = random.sample(standard_question_index, 2)
# 确保正例类别下至少有2个问题(用于生成Anchor和Positive)
if len(self.knwb[p]) < 2:
return self.train_sample() # 不足则重新采样
else:
# 从正例类别中随机选2个问题:s1=Anchor,s2=Positive
s1, s2 = random.sample(self.knwb[p], 2)
# 从负例类别中随机选1个问题:s3=Negative
s3 = random.choice(self.knwb[n])
return [s1, s2, s3] # 返回三元组样本------- 辅助函数
load_vocab:加载词表文件(每行一个token),返回{token: ID}映射(ID从1开始,0预留为padding)。load_schema:加载schema文件,返回{标准问题标签: ID}映射。load_data:创建DataGenerator实例,并用DataLoader封装(支持批处理、打乱等)。
python
def load_vocab(vocab_path):
token_dict = {}
with open(vocab_path, encoding="utf8") as f:
for index, line in enumerate(f):
token = line.strip()
token_dict[token] = index + 1 # 0留给padding
return token_dict
def load_schema(schema_path):
with open(schema_path, encoding="utf8") as f:
return json.loads(f.read())
def load_data(data_path, config, shuffle=True):
dg = DataGenerator(data_path, config)
# 用DataLoader封装,支持批处理、多线程加载、打乱等
dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)
return dl3. 模型模块(model.py)
该模块定义了用于文本匹配的模型结构,包括句子编码器和孪生网络,以及损失函数和优化器的选择。
这段代码实现了一个基于LSTM的孪生网络(Siamese Network) ,主要用于句子相似度计算(如语义匹配、文本相似度任务)。核心思路是通过共享的LSTM编码器将句子转化为固定维度的向量,再通过余弦相似度/损失来衡量句子间的语义距离。
------- 导入依赖库
python
import torch
import torch.nn as nn
from torch.optim import Adam, SGD
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequencetorch/torch.nn:PyTorch核心库,用于构建神经网络。Adam/SGD:两种常用的优化器,用于模型参数更新。pack_padded_sequence/pad_packed_sequence:处理变长序列的工具(代码中未实际调用,但为LSTM处理变长句子预留)。
------- 句子编码器(SentenceEncoder)
python
class SentenceEncoder(nn.Module):
def __init__(self, config):
super(SentenceEncoder, self).__init__()
hidden_size = config["hidden_size"] # LSTM隐藏层维度
vocab_size = config["vocab_size"] + 1 # 词汇表大小(+1是为padding_idx=0预留)
max_length = config["max_length"] # 句子最大长度(代码中未实际使用)
# 词嵌入层:将词索引转化为向量,padding_idx=0表示填充位不参与梯度更新
self.embedding = nn.Embedding(vocab_size, hidden_size, padding_idx=0)
# 双向LSTM:输入维度=hidden_size,输出维度=hidden_size,batch_first=True表示输入格式为[batch, seq_len, feature]
self.lstm = nn.LSTM(hidden_size, hidden_size, batch_first=True, bidirectional=True)
# 线性层:将LSTM输出(双向拼接后维度为2*hidden_size)映射回hidden_size
self.layer = nn.Linear(hidden_size, hidden_size) # 注:此处有bug,双向LSTM输出应为2*hidden_size,线性层输入维度应改为2*hidden_size
self.dropout = nn.Dropout(0.5) # dropout层,防止过拟合
def forward(self, x): # 注:原代码拼写错误forard→forward
x = self.embedding(x) # 词嵌入:[batch, seq_len] → [batch, seq_len, hidden_size]
x, _ = self.lstm(x) # LSTM编码:[batch, seq_len, hidden_size] → [batch, seq_len, 2*hidden_size](双向)
x = self.layer(x) # 线性映射:降维回hidden_size
# 最大池化:对序列维度(seq_len)做max pooling,得到句子的全局特征
# transpose(1,2):将seq_len和hidden_size维度交换 → [batch, hidden_size, seq_len]
# max_pool1d:对最后一维(seq_len)取最大值 → [batch, hidden_size, 1]
# squeeze():去掉最后一维 → [batch, hidden_size]
x = nn.functional.max_pool1d(x.transpose(1, 2), x.shape[1]).squeeze()
return x # 输出句子向量:[batch, hidden_size]核心作用:将输入的句子(词索引序列)转化为固定维度的向量,步骤为「词嵌入→双向LSTM编码→线性降维→最大池化」,最终输出句子的语义向量。
------- 孪生网络(SiameseNetwork)
python
class SiameseNetwork(nn.Module):
def __init__(self, config):
super(SiameseNetwork, self).__init__()
self.sentence_encoder = SentenceEncoder(config) # 共享的句子编码器
self.loss = nn.CosineEmbeddingLoss() # 余弦嵌入损失,用于监督训练
# 计算余弦距离:1 - 余弦相似度(值越小,向量越相似)
def cosine_distance(self, tensor1, tensor2):
# 归一化向量:使向量模长为1,确保余弦相似度计算准确
tensor1 = torch.nn.functional.normalize(tensor1, dim=-1)
tensor2 = torch.nn.functional.normalize(tensor2, dim=-1)
# 点积计算余弦相似度:sum(tensor1 * tensor2)
cosine = torch.sum(torch.mul(tensor1, tensor2), axis=-1)
return 1 - cosine # 余弦距离=1-相似度
# 三元组损失(Triplet Loss):拉近正样本对,拉远负样本对
def cosine_triplet_loss(self, a, p, n, margin=None):
ap = self.cosine_distance(a, p) # 锚点(a)与正样本(p)的距离
an = self.cosine_distance(a, n) # 锚点(a)与负样本(n)的距离
# 损失计算:ap - an + margin,仅保留大于0的部分(否则损失为0)
if margin is None:
diff = ap - an + 0.1 # 默认margin=0.1
else:
diff = ap - an + margin.squeeze()
return torch.mean(diff[diff.gt(0)]) # gt(0):取大于0的部分,再求均值
# 前向传播:支持两种模式(训练/推理)
def forward(self, sentence1, sentence2=None, target=None):
if sentence2 is not None:
# 编码两个句子为向量
vector1 = self.sentence_encoder(sentence1) # [batch, hidden_size]
vector2 = self.sentence_encoder(sentence2)
vector3 = self.sentence_encoder(target) # 注:此处逻辑错误,target应为标签而非句子,不应传入编码器
if target is not None:
# 训练模式:返回余弦嵌入损失(target为标签,1表示相似,-1表示不相似)
return self.loss(vector1, vector2, target.squeeze())
else:
# 推理模式:返回两个句子的余弦距离
return self.cosine_distance(vector1, vector2)
else:
# 仅编码单个句子,返回句子向量
return self.sentence_encoder(sentence1)核心作用:
- 共享
SentenceEncoder编码两个句子,保证参数共享(孪生网络核心)。 - 提供两种损失计算方式:
CosineEmbeddingLoss(监督训练)、cosine_triplet_loss(三元组损失,无监督/半监督)。 - 支持训练(返回损失)和推理(返回余弦距离)两种模式。
------- 优化器选择函数
python
def choose_optimizer(config, model):
optimizer = config["optimizer"] # 优化器类型(Adam/SGD)
learning_rate = config["learning_rate"] # 学习率
if optimizer == "Adam":
return Adam(model.parameters(), lr=learning_rate)
elif optimizer == "sgd":
return SGD(model.parameters(), lr=learning_rate)核心作用:根据配置文件选择优化器(Adam/SGD),返回初始化后的优化器实例,用于更新模型参数。
总结
- 核心目标:通过孪生网络将句子转化为语义向量,计算句子间的余弦距离,实现文本相似度匹配。
- 关键模块 :
SentenceEncoder(LSTM+池化的句子编码)、SiameseNetwork(共享编码器+余弦损失/距离计算)。 - 使用场景:文本相似度计算、语义匹配、问答匹配、文本检索等任务。
4. 评估模块(evaluate.py)
该模块用于在模型训练过程中评估模型性能,计算模型在验证集上的准确率等指标。
这段代码定义了一个Evaluator(评估器)类,核心作用是:
- 加载验证集和训练集(作为知识库)
- 将知识库中的所有问题通过模型转化为向量
- 用验证集中的问题向量与知识库向量计算相似度,找到最匹配的标准问题
- 统计并输出模型在验证集上的预测准确率
-------头部导入与注释
python
# -*- coding: utf-8 -*-
import torch
from loader import load_data
"""
模型效果测试
"""# -*- coding: utf-8 -*-:指定文件编码为UTF-8,避免中文注释/字符串出现乱码import torch:导入PyTorch核心库,用于张量运算、模型推理等from loader import load_data:导入自定义的数据加载函数(loader.py文件中),用于加载训练/验证数据- 注释明确了这段代码的核心用途:模型效果测试
-------Evaluator类初始化(__init__方法)
python
class Evaluator:
def __init__(self, config, model, logger):
self.config = config # 配置字典(包含数据路径、超参数等)
self.model = model # 待评估的PyTorch模型
self.logger = logger # 日志记录器(用于输出评估结果)
# 加载验证集数据(shuffle=False:验证集不需要打乱,保证可复现)
self.valid_data = load_data(config["valid_data_path"], config, shuffle=False)
# 加载训练集作为"知识库"(训练集包含标准问题,用于匹配验证集问题)
# 注释说明:本可以传参复用已加载的训练集,这里为了少改主流程重新加载
self.train_data = load_data(config["train_data_path"], config)
# 初始化统计字典:记录正确/错误预测数
self.stats_dict = {"correct":0, "wrong":0}关键说明:
- 初始化时接收3个核心参数:配置、模型、日志器(解耦设计,符合工程最佳实践)
- 训练集作为「知识库」是问答匹配任务的核心逻辑:验证集问题需要和训练集中的标准问题匹配
shuffle=False:验证集评估需要固定顺序,避免打乱后结果不可复现
-------知识库向量化(knwb_to_vector方法)
python
def knwb_to_vector(self):
self.question_index_to_standard_question_index = {}
self.question_ids = []
# 遍历训练集知识库中的每个标准问题及其对应的所有问题
for standard_question_index, question_ids in self.train_data.dataset.knwb.items():
for question_id in question_ids:
# 记录:问题在知识库向量中的索引 → 标准问题编号(核心映射)
self.question_index_to_standard_question_index[len(self.question_ids)] = standard_question_index
self.question_ids.append(question_id)
# 无梯度计算(推理阶段,避免占用显存)
with torch.no_grad():
# 将所有问题ID拼接成矩阵(shape: [问题总数, 向量维度])
question_matrixs = torch.stack(self.question_ids, dim=0)
# GPU加速(如果有可用GPU)
if torch.cuda.is_available():
question_matrixs = question_matrixs.cuda()
# 用模型将问题ID转化为向量(核心:模型编码)
self.knwb_vectors = self.model(question_matrixs)
# 向量归一化(L2归一化,保证向量模长为1,余弦相似度等价于点积)
self.knwb_vectors = torch.nn.functional.normalize(self.knwb_vectors, dim=-1)
return核心逻辑拆解:
- 构建映射关系 :
question_index_to_standard_question_index是关键字典,作用是「知识库向量的索引 → 标准问题编号」,因为一个标准问题对应多个相似问题,需要通过这个映射找到最终的标准问题编号。 - 向量生成 :
torch.stack:将分散的问题ID张量拼接成矩阵,批量处理提升效率with torch.no_grad():禁用梯度计算,推理阶段必须加,否则会浪费显存且拖慢速度model(question_matrixs):模型前向传播,将问题ID转化为语义向量
- 归一化 :
normalize是余弦相似度的关键预处理,归一化后向量点积=余弦相似度,简化计算。
-------核心评估逻辑(eval方法)
python
def eval(self, epoch):
self.logger.info("开始测试第%d轮模型效果:" % epoch)
self.stats_dict = {"correct":0, "wrong":0} # 清空上一轮统计结果
self.model.eval() # 模型切换到评估模式(禁用Dropout/BatchNorm等训练特有的层)
self.knwb_to_vector() # 重新生成知识库向量(每轮模型参数不同,向量需重新生成)
# 遍历验证集批次数据
for index, batch_data in enumerate(self.valid_data):
# 数据移到GPU(如果可用)
if torch.cuda.is_available():
batch_data = [d.cuda() for d in batch_data]
input_id, labels = batch_data # 拆分输入和标签(可扩展为多输入/多输出)
with torch.no_grad():
# 模型推理:输入验证集问题,生成向量(不传入labels,仅前向传播)
test_question_vectors = self.model(input_id)
# 统计预测结果(正确/错误)
self.write_stats(test_question_vectors, labels)
# 输出评估结果
self.show_stats()
return关键说明:
self.model.eval():必须调用!评估阶段禁用训练时的随机层(如Dropout),保证结果稳定。- 每轮评估都调用
knwb_to_vector():因为模型参数在训练中更新,知识库向量必须同步更新,否则匹配的是旧参数生成的向量,结果无意义。 - 批次处理验证集:符合PyTorch数据加载的常规逻辑,避免一次性加载大量数据导致显存溢出。
with torch.no_grad():再次禁用梯度,评估阶段全程不需要计算梯度。
-------结果统计(write_stats方法)
python
def write_stats(self, test_question_vectors, labels):
# 断言:确保向量数量和标签数量一致(防bug)
assert len(labels) == len(test_question_vectors)
# 遍历每个验证问题的向量和对应标签
for test_question_vector, label in zip(test_question_vectors, labels):
# 计算当前问题与知识库所有问题的相似度(点积)
# test_question_vector: [vec_size] → unsqueeze后:[1, vec_size]
# knwb_vectors.T: [vec_size, 问题总数]
# res: [1, 问题总数] → 每个值是当前问题与知识库中对应问题的相似度
res = torch.mm(test_question_vector.unsqueeze(0), self.knwb_vectors.T)
# 找到相似度最高的索引(argmax)
hit_index = int(torch.argmax(res.squeeze()))
# 通过映射找到对应的标准问题编号
hit_index = self.question_index_to_standard_question_index[hit_index]
# 对比预测的标准问题编号和真实标签,更新统计
if int(hit_index) == int(label):
self.stats_dict["correct"] += 1
else:
self.stats_dict["wrong"] += 1
return核心计算逻辑:
- 相似度计算:
torch.mm(矩阵乘法)实现批量相似度计算,比循环计算效率高10倍以上。 unsqueeze(0):将一维向量转为二维(矩阵乘法要求二维输入)。argmax:找到相似度最大值的索引,即「最匹配的知识库问题」。- 映射转换:通过
question_index_to_standard_question_index将知识库向量索引转为标准问题编号,才能和标签对比。
-------结果展示(show_stats方法)
python
def show_stats(self):
correct = self.stats_dict["correct"]
wrong = self.stats_dict["wrong"]
self.logger.info("预测集合条目总量:%d" % (correct +wrong))
self.logger.info("预测正确条目:%d,预测错误条目:%d" % (correct, wrong))
self.logger.info("预测准确率:%f" % (correct / (correct + wrong)))
self.logger.info("--------------------")
return- 计算并输出核心评估指标:总条目数、正确数、错误数、准确率。
- 使用
logger而非print:工程化代码的最佳实践,便于日志保存和线上部署。
总结
- 核心流程:初始化(加载数据)→ 知识库向量化 → 验证集推理 → 相似度匹配 → 统计准确率 → 输出结果。
- 关键设计 :
- 训练集作为知识库,验证集问题通过向量相似度匹配标准问题,是问答匹配任务的典型评估方式。
- 每轮评估重新生成知识库向量,保证和当前模型参数同步。
- 全程禁用梯度计算(
no_grad)+ 模型切评估模式(eval),保证评估效率和稳定性。
- 核心技巧:向量归一化后点积等价于余弦相似度,矩阵乘法批量计算相似度提升效率。
5. 预测模块(predict.py)
该模块用于加载训练好的模型,实现对用户输入问题的匹配预测,返回最相似的标准问题。
这段Predictor(预测器)类的代码,它是基于Siamese(孪生)网络的问答匹配系统的在线预测模块,核心功能是接收用户输入的自然语言问题,通过模型计算相似度,匹配出知识库中最相似的标准问题并返回。
代码整体功能概述
这段代码实现了一个交互式问答匹配预测工具:
- 加载训练好的Siamese模型和知识库(训练集)
- 提前将知识库中所有问题通过模型编码为语义向量并归一化
- 接收用户输入的问题,完成分词/分字、编码、向量转换
- 计算输入问题与知识库所有问题的相似度,找到最匹配的标准问题
- 以交互式方式持续接收用户输入并返回结果
-------头部导入与注释
python
# -*- coding: utf-8 -*-
import jieba
import torch
from loader import load_data
from config import Config
from model import SiameseNetwork, choose_optimizer
"""
模型效果测试
"""# -*- coding: utf-8 -*-:指定文件编码为UTF-8,避免中文乱码(核心,因为处理的是中文问答)import jieba:导入结巴分词库,用于中文分词(支持按词粒度编码)import torch:PyTorch核心库,负责张量运算、模型推理- 自定义模块导入:
load_data:加载知识库(训练集)数据Config:配置类/字典(包含词汇表路径、最大长度、模型参数等)SiameseNetwork:孪生网络模型(用于生成句子语义向量)choose_optimizer:优化器选择函数(此处未实际使用,属于冗余导入)
-------Predictor类初始化(__init__方法)
python
class Predictor:
def __init__(self, config, model, knwb_data):
self.config = config # 配置参数(词汇表路径、最大长度等)
self.model = model # 训练好的Siamese模型
self.train_data = knwb_data # 知识库数据(训练集)
# 设备选择:优先GPU,否则CPU
if torch.cuda.is_available():
self.model = model.cuda()
else:
self.model = model.cpu()
self.model.eval() # 模型切换到评估模式(禁用Dropout/BatchNorm)
self.knwb_to_vector() # 初始化时就完成知识库向量化(只需一次,预测阶段模型参数固定)关键说明:
- 初始化参数:
config(配置)、model(训练好的模型)、knwb_data(知识库数据),解耦设计,便于复用。 - 设备适配:自动检测GPU/CPU,保证模型在对应设备上运行。
self.model.eval():预测阶段必须调用,避免训练层影响向量生成的稳定性。self.knwb_to_vector():初始化时一次性完成知识库向量化(预测阶段模型参数固定,无需重复计算),提升后续预测速度。
-------知识库向量化(knwb_to_vector方法)
python
def knwb_to_vector(self):
self.question_index_to_standard_question_index = {}
self.question_ids = []
self.vocab = self.train_data.dataset.vocab # 词汇表(字/词到索引的映射)
self.schema = self.train_data.dataset.schema # 标准问题到索引的映射(如:"怎么退款"→0)
# 反向映射:索引→标准问题(用于最终返回可读的标准问题)
self.index_to_standard_question = dict((y, x) for x, y in self.schema.items())
# 遍历知识库:标准问题索引 → 该标准问题下的所有问题ID(编码后的张量)
for standard_question_index, question_ids in self.train_data.dataset.knwb.items():
for question_id in question_ids:
# 记录:知识库向量索引 → 标准问题索引(核心映射)
self.question_index_to_standard_question_index[len(self.question_ids)] = standard_question_index
self.question_ids.append(question_id)
# 无梯度计算(推理阶段)
with torch.no_grad():
# 拼接所有问题ID为矩阵(批量处理,提升效率)
question_matrixs = torch.stack(self.question_ids, dim=0)
if torch.cuda.is_available():
question_matrixs = question_matrixs.cuda()
# 模型编码:生成知识库所有问题的语义向量
self.knwb_vectors = self.model(question_matrixs)
# L2归一化:保证向量模长为1,点积等价于余弦相似度
self.knwb_vectors = torch.nn.functional.normalize(self.knwb_vectors, dim=-1)
return核心逻辑拆解:
- 关键映射构建 :
self.schema:标准问题→索引(如:"如何修改密码"→1)self.index_to_standard_question:索引→标准问题(反向映射,用于最终返回结果)self.question_index_to_standard_question_index:知识库向量的索引→标准问题索引(匹配后找到标准问题的关键)
- 向量生成 :
torch.stack:将分散的问题ID张量拼接成矩阵,批量编码提升效率。- 归一化:是余弦相似度计算的核心预处理,避免向量模长影响相似度结果。
-------输入句子编码(encode_sentence方法)
python
def encode_sentence(self, text):
input_id = []
# 按词汇表路径判断是「分词」还是「分字」编码
if self.config["vocab_path"] == "words.txt":
# 结巴分词:按词粒度编码(如:"怎么退款"→["怎么", "退款"])
for word in jieba.cut(text):
input_id.append(self.vocab.get(word, self.vocab["[UNK]"]))
else:
# 分字编码(如:"怎么退款"→["怎", "么", "退", "款"])
for char in text:
input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))
# 长度处理:截断过长句子,补齐过短句子(保证输入长度统一)
input_id = input_id[:self.config["max_length"]] # 截断
input_id += [0] * (self.config["max_length"] - len(input_id)) # 补齐(0为PAD值)
return input_id核心作用:将用户输入的自然语言句子,转化为模型可接受的数字索引序列,是「自然语言→模型输入」的关键转换:
- 支持两种编码粒度:词粒度(jieba分词)、字粒度(通用),通过配置文件控制。
- 未知词/字处理:用
[UNK](未知符号)的索引替代,避免KeyError。 - 长度统一:保证输入长度和训练时一致(
max_length),否则模型会报错。
-------核心预测逻辑(predict方法)
python
def predict(self, sentence):
# 步骤1:将输入句子编码为数字索引序列
input_id = self.encode_sentence(sentence)
# 步骤2:转换为PyTorch张量,并增加批次维度(模型要求批量输入)
input_id = torch.LongTensor([input_id])
# 步骤3:设备适配(和模型/知识库向量同设备)
if torch.cuda.is_available():
input_id = input_id.cuda()
# 步骤4:模型推理(无梯度计算)
with torch.no_grad():
test_question_vector = self.model(input_id) # 生成输入问题的语义向量
# 步骤5:计算相似度(输入向量 × 知识库向量的转置 → 点积)
# test_question_vector: [1, vec_size] → unsqueeze后:[1, 1, vec_size]
# knwb_vectors.T: [vec_size, n](n为知识库问题数)
# res: [1, 1, n] → 每个值是输入问题与对应知识库问题的相似度
res = torch.mm(test_question_vector.unsqueeze(0), self.knwb_vectors.T)
# 步骤6:找到相似度最高的索引
hit_index = int(torch.argmax(res.squeeze()))
# 步骤7:映射到标准问题索引
hit_index = self.question_index_to_standard_question_index[hit_index]
# 步骤8:返回最终的标准问题(索引→自然语言)
return self.index_to_standard_question[hit_index]关键细节:
torch.LongTensor([input_id]):增加批次维度(模型默认接收批量输入,即使只有1个样本)。test_question_vector.unsqueeze(0):将向量从[1, vec_size]转为[1, 1, vec_size],满足矩阵乘法的维度要求。torch.argmax(res.squeeze()):压缩维度后找到最大值索引,即「最相似的知识库问题」。- 两次映射转换:先找知识库向量索引→标准问题索引,再找标准问题索引→标准问题文本,最终返回可读结果。
-------交互式预测(主函数)
python
if __name__ == "__main__":
# 步骤1:加载知识库数据(训练集)
knwb_data = load_data(Config["train_data_path"], Config)
# 步骤2:初始化模型
model = SiameseNetwork(Config)
# 步骤3:加载训练好的模型参数(关键:使用训练后的权重)
model.load_state_dict(torch.load("model_output/epoch_1000.pth"))
# 步骤4:初始化预测器
pd = Predictor(Config, model, knwb_data)
# 步骤5:交互式循环,持续接收用户输入并预测
while True:
sentence = input("请输入问题:")
res = pd.predict(sentence)
print(res)核心流程:
- 加载知识库→初始化模型→加载训练权重→初始化预测器→交互式预测。
model.load_state_dict(torch.load(...)):加载训练好的模型参数,这是预测的核心(否则模型是随机权重,无意义)。- 无限循环:持续接收用户输入,适合测试/演示场景。
- 核心流程:初始化(加载模型+知识库向量化)→ 用户输入 → 句子编码 → 向量生成 → 相似度计算 → 匹配标准问题 → 返回结果。
- 关键设计 :
- 知识库向量一次性预生成,大幅提升预测速度(避免每次预测都重新编码知识库)。
- 支持词/字两级编码,适配不同的词汇表配置。
- 向量归一化+点积计算,高效实现余弦相似度匹配。
- 核心技巧 :
- 模型切换
eval模式+no_grad禁用梯度,保证推理效率和稳定性。 - 多层映射关系(索引→标准问题),实现从数字计算到自然语言结果的转换。
- 模型切换
这段代码是问答匹配系统的最终落地环节,逻辑简洁且工程化程度高,可直接用于交互式测试或集成到线上服务中。
6. 主程序模块(main.py)
该模块是模型训练的主入口,负责协调数据加载、模型初始化、训练过程控制和模型保存等工作。
python
# -*- coding: utf-8 -*-
import torch
import os
import random
import os
import numpy as np
import logging
from config import Config
from model import SiameseNetwork, choose_optimizer
from evaluate import Evaluator
from loader import load_data
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
"""
模型训练主程序
"""
def main(config):
# 创建保存模型的目录
if not os.path.isdir(config["model_path"]):
os.mkdir(config["model_path"])
# 加载训练数据
train_data = load_data(config["train_data_path"], config)
# 加载模型
model = SiameseNetwork(config)
# 标识是否使用gpu
cuda_flag = torch.cuda.is_available()
if cuda_flag:
logger.info("gpu可以使用,迁移模型至gpu")
model = model.cuda()
# 加载优化器
optimizer = choose_optimizer(config, model)
# 加载效果测试类
evaluator = Evaluator(config, model, logger)
# 训练
for epoch in range(config["epoch"]):
epoch += 1
model.train() # 切换到训练模式
logger.info("epoch %d begin" % epoch)
train_loss = []
for index, batch_data in enumerate(train_data):
optimizer.zero_grad() # 梯度清零
if cuda_flag:
batch_data = [d.cuda() for d in batch_data]
input_id1, input_id2, labels = batch_data
loss = model(input_id1, input_id2, labels) # 计算损失
train_loss.append(loss.item())
loss.backward() # 反向传播
optimizer.step() # 更新参数
logger.info("epoch average loss: %f" % np.mean(train_loss))
evaluator.eval(epoch) # 每轮训练后进行评估
# 保存模型
model_path = os.path.join(config["model_path"], "epoch_%d.pth" % epoch)
torch.save(model.state_dict(), model_path)
return
if __name__ == "__main__":
main(Config)测试结果
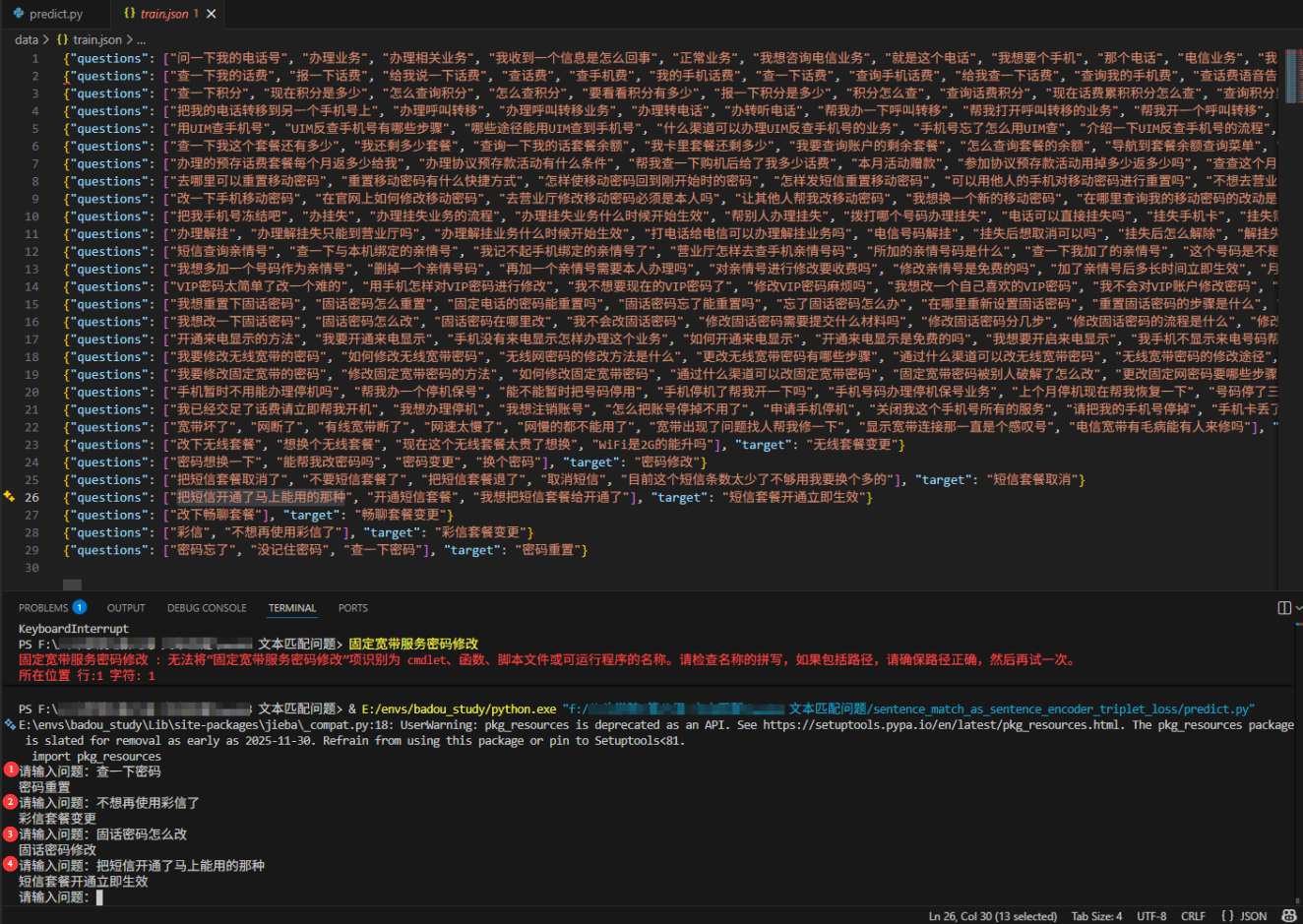
流程图
-
数据准备阶段
- 从指定路径加载训练数据、验证数据、词表和标准问题标签映射
- 对文本数据进行编码(转化为id序列)、补齐或截断等预处理操作
- 构建训练样本(采用三元组采样:anchor、positive、negative)和验证样本
-
模型训练阶段
- 初始化孪生网络模型,包括句子编码器(词嵌入层、线性层、池化层)
- 选择优化器(Adam或SGD)和损失函数(三元组余弦损失)
- 循环执行训练过程:
- 模型切换到训练模式
- 对每个批次的三元组数据,计算损失并进行反向传播和参数更新
- 每轮训练结束后,切换到评估模式,计算模型在验证集上的准确率
- 训练结束后,保存模型参数
-
预测阶段
- 加载训练好的模型参数和标准问题库数据
- 对标准问题库中的所有问题进行向量化并归一化
- 接收用户输入的问题,对其进行编码和向量化
- 计算输入问题向量与标准问题库中所有问题向量的相似度
- 找到相似度最高的标准问题并返回
总结
本项目实现了一个基于孪生网络的文本匹配系统,通过三元组损失函数训练模型学习文本的向量表示,从而实现对用户输入问题与标准问题库中问题的匹配。系统包含数据加载、模型构建、训练评估和预测等模块,各模块分工明确、协同工作。通过该系统,可以有效解决文本匹配任务中语义相似性判断的问题,为智能问答等应用场景提供支持。