💡 本文价值提示 : 欢迎回到我们的 "大数据工程师转型 AI 架构师" 系列专题! 在搞定了 Python 高级工程化 和 大模型基础理论 之后,今天我们正式开启第三个重磅专题------RAG 架构与数据工程之向量数据库。
对于大数据老兵来说,数据库是我们的"后花园"。但 AI 时代的数据库(Vector DB)彻底颠覆了我们熟悉的 SQL 逻辑。本文将带你从底层思维上完成从"精确匹配"到"语义模糊匹配"的跨越,并用最轻量级的代码跑通你的第一个 RAG 闭环。这不仅是技术的升级,更是架构认知的重构。
01 引言:当 SQL 遇到"灵魂拷问" 🤯
作为一名在大数据领域摸爬滚打多年的工程师,你一定对这样的 SQL 语句烂熟于心:
sql
SELECT * FROM products WHERE category = 'electronics' AND price < 5000;这是一种精确匹配(Exact Match) 。数据库像一个一丝不苟的图书管理员,你给它一个 ISBN 号,它给你一本书。如果 ISBN 错了一位,它就冷冰冰地告诉你:0 rows returned。
但在 AI 的世界里,用户的问题往往是模糊的、充满"灵魂"的。比如用户问:
"有没有那种适合打游戏、散热好,而且不太贵的手机?"
如果你试图用 SQL 的 LIKE 语句去匹配"散热好"、"不太贵",那你大概率会疯掉。因为数据库里存的是"骁龙8 Gen 2"、"VC液冷"、"4999元",根本没有"不太贵"这个字段。
这时候,向量数据库(Vector Database) 就登场了。它不再比较"字面是否一样",而是比较"意思是否相近"。
今天,我们就来揭开这个 AI 时代"新基建"的神秘面纱,完成从大数据工程师到 AI 数据架构师的第一步蜕变。
02 核心思维转变:从 KV 到 Embedding 🧠
要理解向量数据库,首先要理解它的原子单位------Embedding(嵌入)。
什么是 Embedding?
想象一下,我们把世界上所有的词语都扔进一个巨大的、多维的坐标系里。
- "苹果" 和 "香蕉" 都是水果,它们在坐标系里的距离应该很近。
- "苹果" 和 "iPhone" 虽然字一样,但在语义空间里,一个在"食物区",一个在"电子产品区",距离应该很远。
Embedding 就是把文本变成一串数字(向量),这串数字代表了它在这个高维空间里的坐标。
🧪 大数据视角映射 : 以前做用户画像(User Profile)时,我们会给用户打标签:
[男, 25-30岁, 喜欢运动]。这其实就是一种低维的、稀疏的向量。 而现在的 Embedding(如 OpenAI 的text-embedding-3-small),是一个 1536 维 的稠密向量。它捕捉的特征比我们手动打的标签要丰富亿万倍。
核心差异对比表
| 特性 | 传统数据库 (MySQL/HBase) | 向量数据库 (Milvus/Chroma) |
|---|---|---|
| 查询逻辑 | 精确匹配 (=, LIKE) |
相似度匹配 (Approximate Nearest Neighbor) |
| 核心操作 | CRUD | Insert & Search (TopK) |
| 数据形态 | 结构化 (Row/Column) | 非结构化 (Vector + Metadata) |
| 结果 | 确定性结果 | 概率性结果 (Score) |
03 距离度量:向量世界的"尺子" 📏
既然数据变成了空间里的点,那怎么判断两个点"像不像"呢?我们需要一把尺子。在大数据聚类算法(如 K-Means)中,你可能已经见过它们:
1. 欧氏距离 (L2 - Euclidean Distance)
- 原理:两点之间直线最短。
- 直觉:空间距离越近,越相似。
- 场景 :对向量的大小 和方向都敏感的场景。
2. 余弦相似度 (Cosine Similarity) 🌟 (最常用)
- 原理 :看两个向量的夹角。
- 直觉:不管你跑得远不远(向量模长),只要我们方向一致,就是"同道中人"。
- 场景:文本语义检索。因为文本长短不一可能导致模长不同,但核心语义(方向)是一致的。
3. 内积 (IP - Inner Product)
- 原理:向量对应位相乘再求和。
- 场景:通常用于归一化(Normalized)后的向量,此时 IP 等价于 Cosine,但计算更快。
04 极速上手:你的第一个 RAG 闭环 (MVP) 🛠️
光说不练假把式。作为工程师,我们直接上代码。 我们将使用 Chroma ------ 向量数据库界的 SQLite。它轻量、无需安装服务器,直接作为 Python 库运行,非常适合 MVP(最小可行性产品)验证。
场景设定
我们要存入三句话,然后问一个问题,看它能不能找到最相关的那句。
1. 环境准备
bash
pip install chromadb2. 代码实战 (Python)
python
import chromadb
# 1. 初始化一个本地的向量数据库客户端(内存模式,重启数据丢失,适合测试)
client = chromadb.Client()
# 2. 创建一个集合 (Collection),类似于 SQL 中的 Table
# 这里我们使用默认的 Embedding 模型 (all-MiniLM-L6-v2),它会自动下载
collection = client.create_collection(name="my_knowledge_base")
# 3. 准备数据 (Documents) 和 元数据 (Metadata)
documents = [
"Hadoop 是一个分布式系统基础架构,主要解决海量数据的存储和分析计算问题。",
"Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。",
"向量数据库是专门用于存储和查询高维向量数据的数据库,是 LLM 的记忆体。"
]
metadatas = [{"type": "bigdata"}, {"type": "bigdata"}, {"type": "ai"}]
ids = ["doc1", "doc2", "doc3"]
# 4. 写入数据 (Upsert)
# Chroma 会自动调用内置模型,将 text 转为 vector,然后存储
print("🔄 正在将文本转化为向量并存入 Chroma...")
collection.add(
documents=documents,
metadatas=metadatas,
ids=ids
)
# 5. 语义查询 (Retrieve)
query_text = "怎么让大模型拥有记忆?"
print(f"🔍 用户提问: {query_text}")
results = collection.query(
query_texts=[query_text],
n_results=1 # TopK = 1
)
# 6. 输出结果
print("\n✅ 检索结果:")
print(f"匹配文档: {results['documents'][0][0]}")
print(f"距离/相似度: {results['distances'][0][0]}")运行结果解析
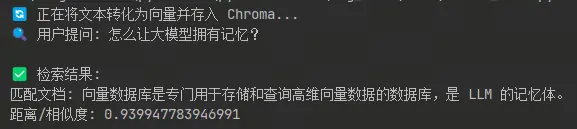
当你运行这段代码,虽然你的问题里没有"向量数据库"这五个字,但系统会精准地返回 doc3。 这就是 语义匹配 的魅力!它听懂了"大模型记忆"和"向量数据库"之间的潜在联系。
05 架构师视角:RAG 的标准数据流水线 🏗️
跑通了 Demo 只是第一步。作为未来的 AI 架构师,你需要关注的是整个数据流的流转。 一个标准的 RAG (Retrieval-Augmented Generation) 数据工程链路如下:
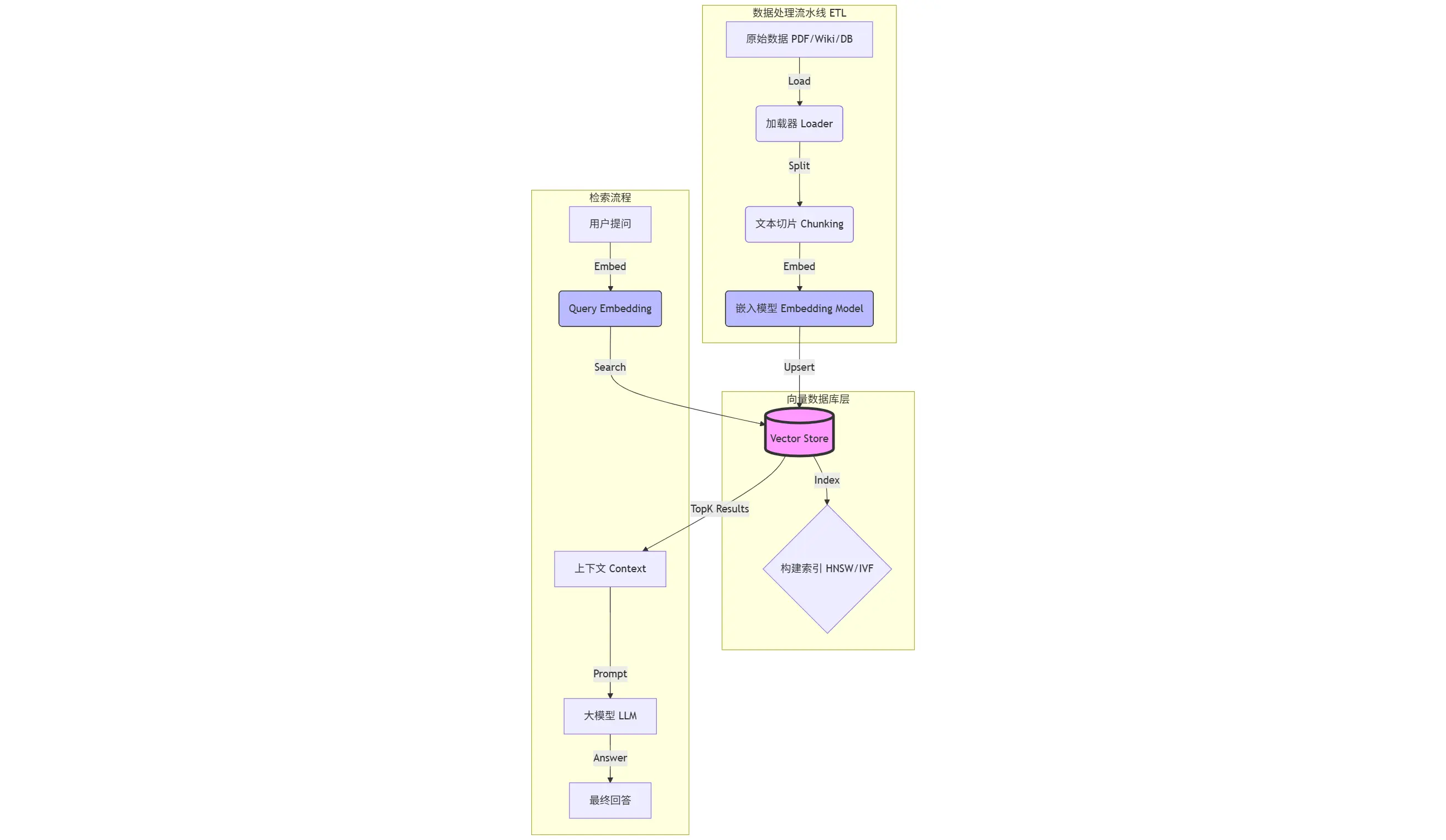
关键环节解析:
- Load (加载):从 HDFS、S3 或本地读取非结构化数据。
- Split (切片) :这是最考验功力的地方。切太长,语义杂糅;切太短,语义破碎。通常使用
RecursiveCharacterTextSplitter。 - Embed (向量化):调用 OpenAI 或 HuggingFace 的模型,将 Chunk 变成 Vector。这是最耗时且产生费用的环节。
- Store (存储):将 Vector + Metadata + Original Text 存入向量库。
- Retrieve (检索):计算 Query Vector 与 Library Vectors 的距离,返回 TopK。
06 总结与预告 📝
今天我们完成了从大数据工程师到 AI 工程师的第一次"脑机接口"升级。我们不再纠结于 WHERE id=1,而是开始思考数据在多维空间中的位置。
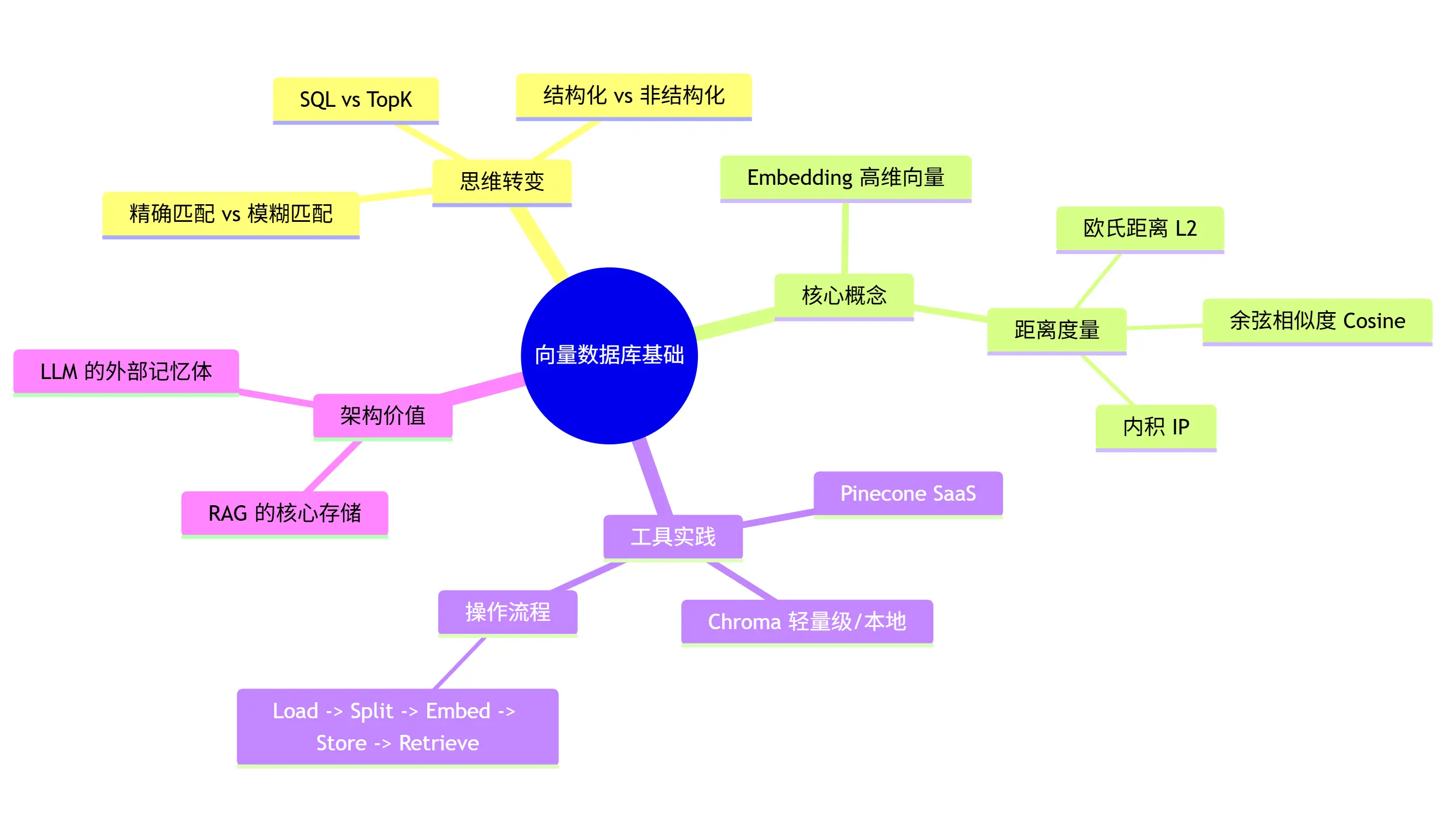
核心知识点回顾:
- Embedding 是数据的灵魂坐标。
- Cosine Similarity 是寻找同类的指南针。
- Chroma 是我们手中的瑞士军刀。
- RAG Pipeline 是我们将非结构化数据转化为 AI 知识的标准工厂。
为了让你更直观地复习,我为你准备了本篇的思维导图:
📢 下期预告:核心战场------分布式向量数据库
用 Chroma 跑 Demo 很爽,但如果数据量到了 10 亿级 怎么办?内存爆了怎么办?写入太慢怎么办? 这正是我们大数据工程师的主场!
下一期,我们将深入 Phase 2 ,硬核拆解 Milvus 的分布式架构。你会发现,它简直就是向量版的 Kafka + HDFS!我们将探讨 Proxy、DataCoord、QueryNode 等组件是如何协同工作的。
💬 互动话题: 你在运行上面的 Python 代码时,有没有遇到 OpenAI API 连接的问题?或者你觉得"文本切片"应该按什么规则切才最合理?欢迎在评论区留言,我们一起探讨!
(别忘了关注,不错过下一篇硬核干货!)