介绍
本文是国科大《模式识别与机器学习》课程的简要复习,基于课件然后让ai帮忙补充了一些解释。本文是第二到第四章。
第二章 生成式分类器
相关数学基础
本章建立在概率论基础上,特别是贝叶斯定理。该定理用于在观测到新证据后,从先验知识更新后验信念,实现不确定性条件下的决策。
贝叶斯定理:
P(ωi∣x)=p(x∣ωi) P(ωi)p(x) P(\omega_i \mid x) = \frac{p(x \mid \omega_i) \, P(\omega_i)}{p(x)} P(ωi∣x)=p(x)p(x∣ωi)P(ωi)
各部分含义:
- 后验概率:P(ωi∣x)P(\omega_i \mid x)P(ωi∣x)
- 似然函数:p(x∣ωi)p(x \mid \omega_i)p(x∣ωi)
- 先验概率:P(ωi)P(\omega_i)P(ωi)
- 证据(归一化常数):p(x)=∑jp(x∣ωj) P(ωj)p(x) = \sum\limits_j p(x \mid \omega_j) \, P(\omega_j)p(x)=j∑p(x∣ωj)P(ωj)
重点:贝叶斯定理将先验信念与观测证据相结合。在抛硬币实验中,先验假设正反面概率各 0.5,若连续观测到多次正面,后验概率会逐渐偏向正面更高。
2.1 贝叶斯判别准则
两类情况下的判别规则(最小错误概率准则):
若 P(ω1∣x)>P(ω2∣x),则 x∈ω1 \text{若 } P(\omega_1 \mid x) > P(\omega_2 \mid x) \text{,则 } x \in \omega_1 若 P(ω1∣x)>P(ω2∣x),则 x∈ω1
等价的似然形式 (常用形式,避免计算 p(x)p(x)p(x)):
若 p(x∣ω1) P(ω1)>p(x∣ω2) P(ω2),则 x∈ω1 \text{若 } p(x \mid \omega_1) \, P(\omega_1) > p(x \mid \omega_2) \, P(\omega_2) \text{,则 } x \in \omega_1 若 p(x∣ω1)P(ω1)>p(x∣ω2)P(ω2),则 x∈ω1
似然比判别:
ℓ12(x)=p(x∣ω1)p(x∣ω2) \ell_{12}(x) = \frac{p(x \mid \omega_1)}{p(x \mid \omega_2)} ℓ12(x)=p(x∣ω2)p(x∣ω1)
判别规则:
若 ℓ12(x)>θ21=P(ω2)P(ω1),则 x∈ω1 \text{若 } \ell_{12}(x) > \theta_{21} = \frac{P(\omega_2)}{P(\omega_1)} \text{,则 } x \in \omega_1 若 ℓ12(x)>θ21=P(ω1)P(ω2),则 x∈ω1
例题:地震预测
已知:
- P(ω1)=0.2P(\omega_1) = 0.2P(ω1)=0.2(地震),P(ω2)=0.8P(\omega_2) = 0.8P(ω2)=0.8(正常)
- p(异常∣ω1)=0.6p(\text{异常} \mid \omega_1) = 0.6p(异常∣ω1)=0.6,p(异常∣ω2)=0.1p(\text{异常} \mid \omega_2) = 0.1p(异常∣ω2)=0.1
观测到生物异常,计算后验:
P(ω1∣异常)=0.6×0.20.6×0.2+0.1×0.8=0.120.20=0.6 P(\omega_1 \mid \text{异常}) = \frac{0.6 \times 0.2}{0.6 \times 0.2 + 0.1 \times 0.8} = \frac{0.12}{0.20} = 0.6 P(ω1∣异常)=0.6×0.2+0.1×0.80.6×0.2=0.200.12=0.6
似然比:
ℓ12=0.60.1=6 \ell_{12} = \frac{0.6}{0.1} = 6 ℓ12=0.10.6=6
阈值:
θ21=0.80.2=4 \theta_{21} = \frac{0.8}{0.2} = 4 θ21=0.20.8=4
6>46 > 46>4,故判为地震。
2.2 最小风险判别
"最小风险贝叶斯分类器"的核心思想:不单纯追求正确率最高,而是追求平均损失最小。
条件平均风险 (将 xxx 判为 ωj\omega_jωj 的预期代价):
rj(x)=∑i=1MLij P(ωi∣x) r_j(x) = \sum_{i=1}^M L_{ij} \, P(\omega_i \mid x) rj(x)=i=1∑MLijP(ωi∣x)
LijL_{ij}Lij:损失(代价)矩阵中的元素,表示"真实是 ωi\omega_iωi,却错判成 ωj\omega_jωj" 要付出的代价。
通常约定:判断正确时代价为 0(即 Ljj=0L_{jj} = 0Ljj=0)。
判断错误时代价为正数,且不同错误代价可以不一样(比如医疗中把病人判成健康代价很大)。
rj(x)r_j(x)rj(x):如果选择把 xxx 判成 ωj\omega_jωj,平均(预期)要损失多少。
它把所有可能的真实情况加权求和:
xxx 的真实类别可能是 ω1\omega_1ω1,概率是 P(ω1∣x)P(\omega_1 \mid x)P(ω1∣x),如果真这样却判成 ωj\omega_jωj,损失 L1jL_{1j}L1j。
xxx 的真实类别可能是 ω2\omega_2ω2,概率是 P(ω2∣x)P(\omega_2 \mid x)P(ω2∣x),如果真这样却判成 ωj\omega_jωj,损失 L2jL_{2j}L2j。
......
一直加到第 MMM 类。
总的预期损失就是:每一种可能的真实类别带来的损失 × 它发生的后验概率,再全部加起来。
两类最小风险决策 (常用简化形式,设 L11=L22=0L_{11} = L_{22} = 0L11=L22=0):
判断依据是 若r1(x)<r2(x),则x被判定为属于ω1,将式子推导后也可化为与上文贝叶斯判别形式类似的似然比和阈值的格式,如下:
若 P(ω1∣x)P(ω2∣x)>P(ω2) L21P(ω1) L12,则判为 ω1 \text{若 } \frac{P(\omega_1 \mid x)}{P(\omega_2 \mid x)} > \frac{P(\omega_2) \, L_{21}}{P(\omega_1) \, L_{12}} \text{,则判为 } \omega_1 若 P(ω2∣x)P(ω1∣x)>P(ω1)L12P(ω2)L21,则判为 ω1
例题 :医疗诊断中,误判疾病为健康代价高(L21=10L_{21}=10L21=10),误判健康为疾病代价低(L12=1L_{12}=1L12=1),会使阈值变小,更倾向于判为疾病。(这里ω1\omega_1ω1是健康,ω2\omega_2ω2是疾病,阈值指的是θ12\theta_{12}θ12 ,即判断为疾病所对应的阈值。)
2.3 朴素贝叶斯分类器
核心假设:特征相互独立
p(x∣ωi)=∏k=1dp(xk∣ωi) p(x \mid \omega_i) = \prod_{k=1}^d p(x_k \mid \omega_i) p(x∣ωi)=k=1∏dp(xk∣ωi)
后验概率(比例形式):
P(ωi∣x)∝P(ωi)∏k=1dp(xk∣ωi) P(\omega_i \mid x) \propto P(\omega_i) \prod_{k=1}^d p(x_k \mid \omega_i) P(ωi∣x)∝P(ωi)k=1∏dp(xk∣ωi)
中间是正比于符号
分类规则:取使上式最大的 ωi\omega_iωi。
计算高效,广泛用于文本分类等高维任务。即使独立假设不严格成立,实际效果往往良好。
例题:垃圾邮件分类
给定:
P(垃圾)=0.4P(\text{垃圾})=0.4P(垃圾)=0.4,P(正常)=0.6P(\text{正常})=0.6P(正常)=0.6
特征词: "免费"、"会议"
p(免费∣垃圾)=0.8p(\text{免费} \mid \text{垃圾})=0.8p(免费∣垃圾)=0.8,p(免费∣正常)=0.1p(\text{免费} \mid \text{正常})=0.1p(免费∣正常)=0.1
p(会议∣垃圾)=0.2p(\text{会议} \mid \text{垃圾})=0.2p(会议∣垃圾)=0.2,p(会议∣正常)=0.7p(\text{会议} \mid \text{正常})=0.7p(会议∣正常)=0.7
邮件含"免费"和"会议":
垃圾后验 ∝ 0.4×0.8×0.2=0.0640.4 \times 0.8 \times 0.2 = 0.0640.4×0.8×0.2=0.064
正常后验 ∝ 0.6×0.1×0.7=0.0420.6 \times 0.1 \times 0.7 = 0.0420.6×0.1×0.7=0.042
0.064 > 0.042,因此判为垃圾邮件。
2.4 概率密度函数参数估计(极大似然估计与贝叶斯估计)
生成式分类器需要知道类条件概率密度 ,实际中这些密度函数的形式可能已知(如正态分布),但参数(如均值、协方差)未知,必须从训练样本估计。
2.4.1 极大似然估计(MLE)
思想:把参数视为固定但未知的常数,选择能使观测到的训练样本"最可能发生"的参数值。
首先需要知道:
对于正态分布 N(μ,σ2)\mathcal{N}(\mu, \sigma^2)N(μ,σ2),极大似然估计的均值就是样本平均值。
协方差的极大似然估计就是样本协方差(除以 N)。
给定 ( N ) 个独立同分布样本 {x1,x2,...,xN}\{x_1, x_2, \dots, x_N\}{x1,x2,...,xN},来自同一类别ωi\omega_iωi。
似然函数:
L(θ)=∏n=1Np(xn∣θ) L(\theta) = \prod_{n=1}^N p(x_n \mid \theta) L(θ)=n=1∏Np(xn∣θ)
对数似然(计算更方便):
ℓ(θ)=∑n=1Nlnp(xn∣θ) \ell(\theta) = \sum_{n=1}^N \ln p(x_n \mid \theta) ℓ(θ)=n=1∑Nlnp(xn∣θ)
MLE 估计:
θ^MLE=argmaxθℓ(θ) \hat{\theta}{\text{MLE}} = \arg\max\theta \ell(\theta) θ^MLE=argθmaxℓ(θ)
这里的argmax 是 "argument of the maximum" 的缩写,意思是使得函数取最大值时的参数值。
例如:
argmaxθf(θ)\arg\max_\theta f(\theta)argθmaxf(θ)
意思是:找到一个 θ,让 f(θ)f(\theta)f(θ) 达到最大,这个 θ 就是 argmax 的结果。
多维正态分布的 MLE(最常见情况)
假设 (p(x∣ωi)∼N(μi,Σi))( p(x \mid \omega_i) \sim \mathcal{N}(\mu_i, \Sigma_i) )(p(x∣ωi)∼N(μi,Σi))
均值估计:
μ^i=1Ni∑n∈ωixn(样本均值) \hat{\mu}i = \frac{1}{N_i} \sum{n \in \omega_i} x_n \quad \text{(样本均值)} μ^i=Ni1n∈ωi∑xn(样本均值)
协方差矩阵估计(无偏版本常用 Ni−1N_i-1Ni−1:
Σ^i=1Ni∑n∈ωi(xn−μ^i)(xn−μ^i)T \hat{\Sigma}i = \frac{1}{N_i} \sum{n \in \omega_i} (x_n - \hat{\mu}_i)(x_n - \hat{\mu}_i)^T Σ^i=Ni1n∈ωi∑(xn−μ^i)(xn−μ^i)T
优点 :计算简单、大样本时渐近最优。
缺点:小样本时容易过拟合;没有利用任何先验知识。
2.4.2 贝叶斯参数估计(参数视为随机变量)
思想 :把未知参数 θ\thetaθ 看作随机变量,有先验分布 p(θ)p(\theta)p(θ)。随着样本到来,不断用贝叶斯定理更新后验分布。
贝叶斯估计就是用精度(可靠程度)做权重,把你的旧猜测和数据新证据聪明地平均一下,同时告诉你新信念有多确定。样本越多、测量越准,越相信数据;先验越强,越坚持旧猜测。
后验:
p(θ∣{xn})=p({xn}∣θ) p(θ)p({xn}) p(\theta \mid \{x_n\}) = \frac{p(\{x_n\} \mid \theta) \, p(\theta)}{p(\{x_n\})} p(θ∣{xn})=p({xn})p({xn}∣θ)p(θ)
最终点估计常用后验均值或后验众数(MAP估计)。
优点:能融入先验知识,小样本时更稳健;能给出参数的不确定性(后验方差)。
单变量正态均值贝叶斯学习(经典例子)
假设数据xn∼N(μ,σ2)x_n \sim \mathcal{N}(\mu, \sigma^2)xn∼N(μ,σ2),σ2\sigma^2σ2已知,只估计均值 μ\muμ。
先验:μ∼N(μ0,σ02)\mu \sim \mathcal{N}(\mu_0, \sigma_0^2)μ∼N(μ0,σ02)(共轭先验,后验仍正态,便于计算)
加入NNN 个样本后,后验仍为正态:
后验均值(点估计):
μ^N=μ0σ02+Nxˉσ21σ02+Nσ2=(1/σ021/σ02+N/σ2)μ0+(N/σ21/σ02+N/σ2)xˉ \hat{\mu}_N = \frac{\frac{\mu_0}{\sigma_0^2} + N \frac{\bar{x}}{\sigma^2}}{\frac{1}{\sigma_0^2} + \frac{N}{\sigma^2}} = \left( \frac{1/\sigma_0^2}{1/\sigma_0^2 + N/\sigma^2} \right) \mu_0 + \left( \frac{N/\sigma^2}{1/\sigma_0^2 + N/\sigma^2} \right) \bar{x} μ^N=σ021+σ2Nσ02μ0+Nσ2xˉ=(1/σ02+N/σ21/σ02)μ0+(1/σ02+N/σ2N/σ2)xˉ
这个后验均值的公式看起来有点复杂,但是其实就下下面这个公式这样:
μ^N=w1⋅μ0+w2⋅xˉ\hat{\mu}_N = w_1 \cdot \mu_0 + w_2 \cdot \bar{x}μ^N=w1⋅μ0+w2⋅xˉ
其中两个权重 w₁ + w₂ = 1。
1/σ₀² 叫先验精度(precision = 1/方差)。先验方差 σ₀² 越小(你越相信原来的猜测),精度越高,w₁ 越大。
N/σ² 是数据的总精度:样本越多(N大),测量误差 σ² 越小,数据越可靠,w₂ 越大。
后验方差(不确定性):
σN2=11σ02+Nσ2 \sigma_N^2 = \frac{1}{\frac{1}{\sigma_0^2} + \frac{N}{\sigma^2}} σN2=σ021+σ2N1
直观理解:
- μ^N\hat{\mu}_Nμ^N是先验均值 μ0\mu_0μ0 和样本均值 xˉ\bar{x}xˉ 的加权平均。
- 样本越多(N越大),权重越偏向样本均值;先验方差σ02\sigma_0^2σ02越大(先验越不确定),权重越小。
- 后验方差随样本增加而减小 → 估计越来越确定。
2.5 正态分布模式的贝叶斯分类器
正态分布(高斯分布)是最重要的生成式模型假设,因为中心极限定理,许多实际数据近似正态。
下面的公式看起来多,但其实就三步:
1.写出正态密度函数
2.取对数得到判别函数(避免数值问题)
3.比较判别函数,得到决策边界
2.5.1 多维正态密度
p(x∣ωi)=1(2π)d/2∣Σi∣1/2exp(−12(x−μi)TΣi−1(x−μi)) p(x \mid \omega_i) = \frac{1}{(2\pi)^{d/2} |\Sigma_i|^{1/2}} \exp\left( -\frac{1}{2} (x - \mu_i)^T \Sigma_i^{-1} (x - \mu_i) \right) p(x∣ωi)=(2π)d/2∣Σi∣1/21exp(−21(x−μi)TΣi−1(x−μi))
每个部分的意思:
xxx:d 维特征向量(一个样本)
μi\mu_iμi:第 i 类的均值向量(类的"中心")
Σi\Sigma_iΣi:第 i 类的协方差矩阵(描述类的"形状"和"散布程度")
(x−μi)TΣi−1(x−μi)(x - \mu_i)^T \Sigma_i^{-1} (x - \mu_i)(x−μi)TΣi−1(x−μi):马氏距离平方(Mahalanobis distance²)
直观:样本 x 离类中心 μ_i 有多远?(考虑了协方差方向,不是简单欧氏距离)
这个值越小,概率密度越大(x 越可能属于这个类)
exp(−12×距离²)\exp(-\frac{1}{2} \times \text{距离²})exp(−21×距离²):距离越近,概率越大;距离远,概率指数衰减
前面的 1(2π)d/2∣Σi∣1/2\frac{1}{(2\pi)^{d/2} |\Sigma_i|^{1/2}}(2π)d/2∣Σi∣1/21:归一化常数,确保整个空间积分等于1(可以暂时忽略,比较概率时会抵消)
一维情况退化就是正态分布:
如果 d=1,Σ_i = σ_i²,正态密度就是我们熟悉的:
p(x∣ωi)=12πσiexp(−(x−μi)22σi2)p(x \mid \omega_i) = \frac{1}{\sqrt{2\pi} \sigma_i} \exp\left( -\frac{(x - \mu_i)^2}{2\sigma_i^2} \right)p(x∣ωi)=2π σi1exp(−2σi2(x−μi)2)
多维就是把 (x-μ)² 换成马氏距离,把 σ 换成 |Σ|^{1/2}。
2.5.2 贝叶斯判别函数(取对数,避免数值下溢)
di(x)=lnP(ωi)+lnp(x∣ωi)=lnP(ωi)−12(x−μi)TΣi−1(x−μi)−12ln∣Σi∣+常数 d_i(x) = \ln P(\omega_i) + \ln p(x \mid \omega_i) = \ln P(\omega_i) - \frac{1}{2} (x - \mu_i)^T \Sigma_i^{-1} (x - \mu_i) - \frac{1}{2} \ln |\Sigma_i| + \text{常数} di(x)=lnP(ωi)+lnp(x∣ωi)=lnP(ωi)−21(x−μi)TΣi−1(x−μi)−21ln∣Σi∣+常数
常数对所有类都一样(d 和 2π 固定),比较时可以扔掉。
所以最终判别函数(实际使用的):
di(x)=−12(x−μi)TΣi−1(x−μi)−12ln∣Σi∣+lnP(ωi)d_i(x) = -\frac{1}{2} (x - \mu_i)^T \Sigma_i^{-1} (x - \mu_i) - \frac{1}{2} \ln |\Sigma_i| + \ln P(\omega_i)di(x)=−21(x−μi)TΣi−1(x−μi)−21ln∣Σi∣+lnP(ωi)
分类规则:
计算每个类的 d_i(x),选择最大的那个类(即 argmax d_i(x))。
2.5.3 决策边界的几何形状
两类之间边界 d1(x)=d2(x)d_1(x) = d_2(x)d1(x)=d2(x):
-
同协方差情况 Σ1=Σ2=Σ\Sigma_1 = \Sigma_2 = \SigmaΣ1=Σ2=Σ (最常见,LDA)
二次项抵消,边界退化为线性:
wTx+w0=0(超平面,二维时为直线) w^T x + w_0 = 0 \quad \text{(超平面,二维时为直线)} wTx+w0=0(超平面,二维时为直线)
称为线性判别分析(LDA)。
-
不同协方差情况 Σ1≠Σ2\Sigma_1 \neq \Sigma_2Σ1=Σ2
保留二次项,边界为二次曲面(二维时为圆、椭圆、抛物线、双曲线等)。
称为二次判别分析(QDA)。
实际选择:
- 数据量大、类别协方差明显不同 → 用 QDA
- 数据量小或希望简单模型 → 用 LDA(参数少,鲁棒性好)
2.5.4 详细例子(二维两类)
假设两类正态,均值 μ1=(0,0)T\mu_1 = (0,0)^Tμ1=(0,0)T,μ2=(3,3)T\mu_2 = (3,3)^Tμ2=(3,3)T,先验相等。
情况1:Σ1=Σ2=I\Sigma_1 = \Sigma_2 = IΣ1=Σ2=I(单位阵)→ 决策边界为垂直平分线 x1+x2=3x_1 + x_2 = 3x1+x2=3
情况2:Σ1=I\Sigma_1 = IΣ1=I,Σ2=4I\Sigma_2 = 4IΣ2=4I(第二类更分散)→ 边界为圆形,包围第一类区域。
2.6 正态分布参数的贝叶斯学习(均值向量与协方差矩阵)
就是将 2.4.2 的贝叶斯估计扩展到多维正态的均值向量和协方差矩阵。
2.6.1 均值向量的贝叶斯学习(协方差已知)
先验:多元正态 μ∼N(μ0,Σ0)\mu \sim \mathcal{N}(\mu_0, \Sigma_0)μ∼N(μ0,Σ0)
后验仍为多元正态,后验均值类似加权平均:
μ^N=(Σ0−1+NΣ−1)−1(Σ0−1μ0+NΣ−1xˉ) \hat{\mu}_N = \left( \Sigma_0^{-1} + N \Sigma^{-1} \right)^{-1} \left( \Sigma_0^{-1} \mu_0 + N \Sigma^{-1} \bar{x} \right) μ^N=(Σ0−1+NΣ−1)−1(Σ0−1μ0+NΣ−1xˉ)
2.6.2 协方差矩阵的贝叶斯学习(均值已知或未知)
协方差的共轭先验是 Wishart 分布 或 逆Wishart 分布。
逆Wishart 更常用(直接给出协方差的后验)。
后验形式复杂,但直观结果:
- 后验协方差估计是先验协方差与样本协方差的加权组合。
- 样本越多,后验越接近样本协方差。
2.6.3 均值+协方差联合贝叶斯学习
最完整模型:正态-逆Wishart 共轭先验(Normal-Inverse-Wishart)。
后验仍闭合,可迭代更新。实际中常用于在线学习或小样本场景。
与 MLE 的对比总结
| 方面 | MLE | 贝叶斯估计 |
|---|---|---|
| 参数性质 | 固定常数 | 随机变量,有分布 |
| 小样本表现 | 容易过拟合 | 更稳健(受先验"拉回") |
| 输出 | 单一估计值 | 完整后验分布(可给出置信区间) |
| 计算复杂度 | 简单(闭合解) | 通常需迭代或采样(但共轭时闭合) |
| 先验利用 | 无 | 有(领域知识可融入) |
本章后三小节核心联系:
- 2.4 提供参数估计方法 → 为 2.5 正态贝叶斯分类器准备μi,Σi\mu_i, \Sigma_iμi,Σi
- 2.5 是最重要生成式分类器(LDA/QDA)
- 2.6 是 2.4 在正态模型下的高级版本,强调学习过程的不确定性下降
第三章 判别函数
本章主要介绍判别式分类器(discriminative classifier)的核心思想和一系列经典算法。判别式分类器直接学习从特征 xxx 到类别 yyy 的映射(判别函数 y=f(x)y = f(x)y=f(x) 或条件概率 P(y∣x)P(y \mid x)P(y∣x)),与第二章的生成式分类器形成对比。
3.1 判别式分类器与生成式分类器
分类是监督学习的主要任务之一。分类器主要有两种思路:
-
判别式分类器 :直接学习决策边界或条件概率分布 P(y∣x)P(y \mid x)P(y∣x)。
典型形式是判别函数 y=f(x)y = f(x)y=f(x):给定输入 xxx,直接输出一个值 yyy,通过与阈值比较决定类别(例如 f(x)>0f(x) > 0f(x)>0 属于类别1,否则属于类别2)。
另一种形式是输出各类别的后验概率 P(y∣x)P(y \mid x)P(y∣x),选择概率最大的类别。
-
生成式分类器 (第二章内容):先建模每个类别的条件密度 p(x∣y)p(x \mid y)p(x∣y) 和先验 P(y)P(y)P(y),再通过贝叶斯公式得到 P(y∣x)P(y \mid x)P(y∣x)。
例子:假设分类苹果和橙子。判别式直接学"重量 > 150g 是苹果";生成式先学苹果/橙子的重量分布,再计算概率。
对比总结:
| 方面 | 判别式分类器 | 生成式分类器 |
|---|---|---|
| 学习目标 | 直接学 P(y∣x)P(y \mid x)P(y∣x) 或决策边界 | 学 p(x∣y)p(x \mid y)p(x∣y) 和 P(y)P(y)P(y) |
| 数据利用效率 | 更高(只关心区分边界) | 较低(需建模完整分布) |
| 适用场景 | 大样本、标签充足 | 小样本、可利用未标签数据、需生成样本 |
| 典型算法 | 线性判别、感知器、SVM、神经网络 | 朴素贝叶斯、高斯判别(LDA/QDA) |
本章重点全部在判别式分类器。
3.2 线性判别函数
最简单的判别函数是线性形式:
d(x)=wTx+b d(x) = w^T x + b d(x)=wTx+b
- www 是权重向量,bbb 是偏置(常数项)。
- 分类规则:若 d(x)>0d(x) > 0d(x)>0,则 x∈ω1x \in \omega_1x∈ω1;否则 x∈ω2x \in \omega_2x∈ω2。
几何意义 :
d(x)=0d(x) = 0d(x)=0 即 wTx+b=0w^T x + b = 0wTx+b=0 是一个超平面,将特征空间分成两半。www 是法向量,指向 ω1\omega_1ω1 一侧。
增广表示 (常用技巧):
引入 x0=1x_0 = 1x0=1,令增广向量 x~=(x0,x1,...,xd)T\tilde{x} = (x_0, x_1, \dots, x_d)^Tx~=(x0,x1,...,xd)T,增广权重 w~=(b,w1,...,wd)T\tilde{w} = (b, w_1, \dots, w_d)^Tw~=(b,w1,...,wd)T,则:
d(x)=w~Tx~ d(x) = \tilde{w}^T \tilde{x} d(x)=w~Tx~
多类扩展 :
对 MMM 类,使用 MMM 个判别函数 di(x)=wiTx+bid_i(x) = w_i^T x + b_idi(x)=wiTx+bi,选择 di(x)d_i(x)di(x) 最大的 iii 作为类别。
优点:简单、可解释、计算快。
缺点:只能处理线性可分数据。
3.3 广义线性判别函数
为了处理非线性问题,引入特征非线性变换:
d(x)=wTϕ(x)+b d(x) = w^T \phi(x) + b d(x)=wTϕ(x)+b
其中 ϕ(x)\phi(x)ϕ(x) 是 xxx 的非线性映射(如多项式、RBF等)。
- 常见形式:多项式判别函数(二次、三次等)。
- 相当于在高维 ϕ(x)\phi(x)ϕ(x) 空间中做线性判别。
- 通过核技巧(kernel trick)可避免显式计算高维映射。
例子:若 ϕ(x)=(1,x1,x2,x12,x1x2,x22)T\phi(x) = (1, x_1, x_2, x_1^2, x_1 x_2, x_2^2)^Tϕ(x)=(1,x1,x2,x12,x1x2,x22)T,即可得到二次判别边界。
优点:能处理复杂非线性边界。
缺点:参数数量随维度指数增长(维度灾难)。
3.4 分段线性判别函数
用多个线性函数组合逼近复杂边界:
- 将特征空间分成若干区域,每个区域用一个线性判别函数。
- 多类情况下常用"最大选择"规则:argmaxidi(x)\arg\max_i d_i(x)argmaxidi(x)。
典型实现:多个超平面组合,或后续章节的决策树。
优点:表达能力强,能逼近任意复杂边界。
缺点:区域划分和连接需小心,避免不连续或过拟合。
3.5 Fisher线性判别
Fisher线性判别(Fisher Linear Discriminant,简称FLD),也叫线性判别分析(Linear Discriminant Analysis,LDA),是经典的监督降维+分类方法。
它的核心思想是:找一个最好的投影方向,把高维数据投影到一维直线上,使得投影后同类点尽可能紧凑、不同类点尽可能分开。
这与第二章的正态分布贝叶斯分类器(同协方差的高斯判别)实际上是等价的,但Fisher从几何和散度角度给出了更直观的解释。
目标 :找到投影方向 www,使数据投影到一维后:
- 类间距离最大(不同类中心尽量远)
- 类内散度最小(同类点尽量紧凑)
假设你有二维数据,两类点混在一起,直接看很难分开。
如果沿横轴投影:两类重叠严重,分不开。
如果沿纵轴投影:还是重叠。
但如果沿某个斜方向投影(比如对角线方向),两类投影后的点就分得很开,而且每类内部点都很集中。
Fisher的目标就是自动找到这个"最好的斜方向"www。
投影后的效果用两个指标衡量:
类间散度(between-class scatter):两类投影均值之间的距离,越远越好。
类内散度(within-class scatter):每类投影点到自己均值的方差,越小越好。
我们希望"类间散度大 ÷ 类内散度大"这个比值最大。
数学定义 :
记两类为 ω1\omega_1ω1 和 ω2\omega_2ω2,样本数分别为 N1N_1N1、N2N_2N2。
原始空间均值:μ1=1N1∑x∈ω1x,μ2=1N2∑x∈ω2x\mu_1 = \frac{1}{N_1} \sum_{x \in \omega_1} x, \quad \mu_2 = \frac{1}{N_2} \sum_{x \in \omega_2} xμ1=N11x∈ω1∑x,μ2=N21x∈ω2∑x
投影后的一维均值(投影方向为 www):m1=wTμ1,m2=wTμ2m_1 = w^T \mu_1, \quad m_2 = w^T \mu_2m1=wTμ1,m2=wTμ2
投影后的类间散度(投影均值差的平方):(m1−m2)2=(wTμ1−wTμ2)2=wT(μ1−μ2)(μ1−μ2)Tw(m_1 - m_2)^2 = (w^T \mu_1 - w^T \mu_2)^2 = w^T (\mu_1 - \mu_2)(\mu_1 - \mu_2)^T w(m1−m2)2=(wTμ1−wTμ2)2=wT(μ1−μ2)(μ1−μ2)Tw定义类间散度矩阵 (between-class scatter matrix):SB=(μ1−μ2)(μ1−μ2)TS_B = (\mu_1 - \mu_2)(\mu_1 - \mu_2)^TSB=(μ1−μ2)(μ1−μ2)T所以投影后类间散度 为 wTSBww^T S_B wwTSBw。
投影后的类内散度:每类投影点的方差之和。
定义原始空间的类内散度矩阵(within-class scatter matrix):S1=∑x∈ω1(x−μ1)(x−μ1)T,S2=∑x∈ω2(x−μ2)(x−μ2)TS_1 = \sum_{x \in \omega_1} (x - \mu_1)(x - \mu_1)^T, \quad S_2 = \sum_{x \in \omega_2} (x - \mu_2)(x - \mu_2)^TS1=x∈ω1∑(x−μ1)(x−μ1)T,S2=x∈ω2∑(x−μ2)(x−μ2)T总类内散度矩阵:SW=S1+S2S_W = S_1 + S_2SW=S1+S2投影后类内散度 为 wTSWww^T S_W wwTSWw。
Fisher准则:
我们要最大化的目标是"投影后类间散度 / 投影后类内散度",也就是下面的:
J(w)=wTSBwwTSWw J(w) = \frac{w^T S_B w}{w^T S_W w} J(w)=wTSWwwTSBw
J(w)J(w)J(w) 越大,说明投影后类间分离越好、类内越紧凑。最大化 J(w)J(w)J(w) 的解为:
w=SW−1(μ1−μ2) w = S_W^{-1} (\mu_1 - \mu_2) w=SW−1(μ1−μ2)
(μ1−μ2)(\mu_1 - \mu_2)(μ1−μ2) 是两类中心的连线方向。
SW−1S_W^{-1}SW−1 起到"白化"作用:拉长类内散度小的方向,压缩散度大的方向。
结果:投影方向既考虑了类间距离,又避开了类内噪声大的方向。
得到 www 后:
将所有样本投影到一维:y=wTxy = w^T xy=wTx
在一维上找阈值(通常是两类投影均值的平均),或直接比较距离最近的投影均值。
也可以直接用投影后的距离作为判别函数。
多类 :投影到 M−1M-1M−1 维,求 SW−1SBS_W^{-1} S_BSW−1SB 的前 M−1M-1M−1 个特征向量。
优点:考虑类别分布,泛化能力强。
缺点:假设各类协方差相同(同第二章LDA)。
当假设每个类服从同协方差的高斯分布时,Fisher判别和贝叶斯最优分类器的决策边界完全一致。
Fisher给出了几何解释,贝叶斯给出了概率解释。
3.6 感知器算法
感知器是最早的神经网络模型,用于二分类(线性可分)。
-
模型结构(单层感知器)
感知器就是一个线性判别函数:
y=wTx+by = w^T x + by=wTx+b如果 y>0y > 0y>0,判为类别 +1+1+1(或 ω1\omega_1ω1)
如果 y≤0y \leq 0y≤0,判为类别 −1-1−1(或 ω2\omega_2ω2)
常用增广向量技巧(把偏置 b 合并到权重里):
令 x~=(1,x1,x2,...,xd)T\tilde{x} = (1, x_1, x_2, \dots, x_d)^Tx~=(1,x1,x2,...,xd)T
令 w~=(b,w1,w2,...,wd)T\tilde{w} = (b, w_1, w_2, \dots, w_d)^Tw~=(b,w1,w2,...,wd)T
则 y=w~Tx~y = \tilde{w}^T \tilde{x}y=w~Tx~
下面统一用增广形式,记权重为 www,输入为 xxx,判别函数为 wTxw^T xwTx。
分类规则:
wTx>0→+1w^T x > 0 \to +1wTx>0→+1
wTx≤0→−1w^T x \leq 0 \to -1wTx≤0→−1 -
训练目标
给定训练集 {(x(n),t(n))}\{(x^{(n)}, t^{(n)})\}{(x(n),t(n))},其中 t(n)=+1t^{(n)} = +1t(n)=+1 或 −1-1−1 是真实标签。
我们希望对所有样本都有 wTx(n)⋅t(n)>0w^T x^{(n)} \cdot t^{(n)} > 0wTx(n)⋅t(n)>0(即:正确分类时,判别值和标签同号)。
如果某个样本被误分类,说明 wTx(n)⋅t(n)≤0w^T x^{(n)} \cdot t^{(n)} \leq 0wTx(n)⋅t(n)≤0。
-
感知器学习算法(核心迭代规则)
初始化:w(0)=0w^{(0)} = 0w(0)=0(或小随机值)
迭代过程如下:
随机选取一个训练样本 (x,t)(x, t)(x,t)
计算当前输出:y=wTxy = w^T xy=wTx
如果分类正确(即 y⋅t>0y \cdot t > 0y⋅t>0),什么都不做
如果误分类(y⋅t≤0y \cdot t \leq 0y⋅t≤0),则修正权重:w新=w旧+η t xw^{\text{新}} = w^{\text{旧}} + \eta \, t \, xw新=w旧+ηtx其中 η>0\eta > 0η>0 是学习率(常取 η=1\eta = 1η=1)
重复上述步骤,直到所有样本都正确分类(或达到最大迭代次数)。
-
为什么这样修正能奏效?(直观几何解释)
假设一个样本 (x,t=+1)(x, t=+1)(x,t=+1) 被误分类,即当前 wTx≤0w^T x \leq 0wTx≤0。
修正 w←w+xw \leftarrow w + xw←w+x:权重向量 www 向 xxx 的方向移动一点。
这样下次再看这个样本,wTxw^T xwTx 会变大(更可能 > 0)。
如果样本标签 t=−1t = -1t=−1 被误分类(wTx>0w^T x > 0wTx>0),修正 w←w−xw \leftarrow w - xw←w−x,相当于把 www 远离 xxx 的方向。
一句话:每次误分类,就把决策边界往"把这个点分对"的方向轻轻推一下。
多类感知器扩展
原始感知器是二分类。多类常用"一对余"(one-vs-rest):
为每类 iii 训练一个感知器 wiw_iwi,把第 iii 类作为正类,其他作为负类。
测试时计算所有 wiTxw_i^T xwiTx,选择最大者对应的类别。
优缺点总结
优点:
实现极其简单(几十行代码)
直观易懂,是神经网络的起点
线性可分时理论保证收敛
缺点:
只能处理线性可分问题(XOR问题就失效)
对噪声敏感
收敛速度可能很慢(依赖样本顺序)
不可分时不收敛
与现代深度学习的联系
感知器是单层神经网络,使用阶跃激活函数(sign函数)。
现代神经网络只是把:
激活函数换成 sigmoid/ReLU 等可微函数
损失函数换成交叉熵等
用梯度下降(反向传播)替代手动修正
就能处理非线性、多层、不可分数据了。
3.7 梯度法
梯度法是机器学习中最核心、最通用的优化方法之一。它是感知器算法的升级版,也是现代深度学习(反向传播)的直接前身。
感知器只能处理线性可分数据,而且修正规则是"硬性"的(要么全改,要么不改)。梯度法更灵活:它定义一个连续的、可微的损失函数 ,然后沿着损失函数下降最快的方向(梯度负方向)逐步调整权重 www,可以处理不可分情况,还能优化各种复杂准则。
1. 基本思想(梯度是什么?)
想象你在山上,想下到谷底(损失最小):
- 梯度 ∇J(w)\nabla J(w)∇J(w) 告诉你当前"最陡的上坡方向"。
- 所以下降方向是 −∇J(w)-\nabla J(w)−∇J(w)。
- 每次走一小步:w←w−η∇J(w)w \leftarrow w - \eta \nabla J(w)w←w−η∇J(w),其中 η\etaη 是步长(学习率)。
目标函数 J(w)J(w)J(w) 是我们定义的"损失"或"代价",希望 J(w)J(w)J(w) 越小越好。
我们用梯度法优化一个准则函数 J(w)J(w)J(w),这个函数衡量当前权重 www 的好坏。
2. 梯度法实现步骤(伪代码)
python
初始化 w = 0(或随机小值)
for 迭代次数 k = 1 to max_iter:
计算当前 J(w) 和梯度 ∇J(w) # 可以批量或随机单个样本(SGD)
w ← w - η * ∇J(w)
如果 J(w) 变化很小或达到停止条件,break学习率 η\etaη 的选择:
- 太大:容易越过最小点,甚至发散
- 太小:收敛非常慢
- 常见技巧:固定小值、衰减学习率、Adam等自适应优化器(现代用法)
3. 优缺点总结
优点:
- 通用性极强:只要损失函数可微,就能用
- 可处理线性不可分数据(不像感知器会震荡)
- 是现代优化器的基础(SGD、Adam、RMSProp 都是它的变种)
- 批量/随机/小批量三种方式都适用
缺点:
- 需要选择合适的学习率 η\etaη
- 可能陷入局部极小(尤其非凸损失)
- 对初始点敏感
- 收敛速度受数据规模、特征尺度影响(需归一化)
4. 与感知器和后续算法的联系
- 感知器:相当于用"阶跃损失"(0-1损失),但不可微,所以用硬性规则修正。
- 梯度法:用连续可微损失(如平方损失),每次更新都按梯度走,平滑得多。
- LMSE:就是平方损失的批量闭合解 (伪逆),而梯度法是它的迭代解。
- 现代深度学习:反向传播 + 梯度下降 + 交叉熵损失,就是梯度法的超级升级版。
5. 总结
梯度法是"用数学的坡度告诉你怎么走"的优化方法,它把感知器的"误分类就硬改"变成了"算一下错多少,然后按比例慢慢改",从而能处理更复杂、更不可分的情况。
3.8 最小平方误差算法(LMSE,Least Mean Square Error)
最小平方误差算法(也叫最小二乘分类器,或 Ho-Kashyap 算法)是把分类问题转化为线性回归问题 的一种经典判别式方法。它用平方误差作为损失函数,通过求解线性方程组或迭代方式找到权重 www。
核心思想非常巧妙:既然分类就是要让正类样本的判别值 wTx>0w^T x > 0wTx>0,负类 wTx<0w^T x < 0wTx<0,我们干脆把类别标签设成 +b+b+b 和 −b-b−b(b>0b > 0b>0),然后让 wTxw^T xwTx 尽量接近对应的标签值。这样就变成了一个标准的线性回归问题,用最小平方误差求解。
1. 问题转化(关键一步)
给定训练样本 {x(n),n=1,...,N}\{x^{(n)}, n=1,\dots,N\}{x(n),n=1,...,N},增广向量形式(包含常数1)。
定义:
- 目标向量 b=(b1,b2,...,bN)Tb = (b_1, b_2, \dots, b_N)^Tb=(b1,b2,...,bN)T,其中 bn>0b_n > 0bn>0 是"期望输出裕量"(margin)。
- 正类样本:bn>0b_n > 0bn>0
- 负类样本:bn<0b_n < 0bn<0(通常取正类 +b+b+b,负类 −b-b−b,bbb 是正数)
- 样本矩阵 XXX:N×(d+1)N \times (d+1)N×(d+1) 矩阵,每行是增广样本 x~(n)T{\tilde{x}^{(n)}}^Tx~(n)T
希望找到权重 www,使得:
Xw≈b X w \approx b Xw≈b
即每个样本的判别值 wTx(n)w^T x^{(n)}wTx(n) 尽量接近 bnb_nbn。
如果能精确等于 Xw=bX w = bXw=b,则说明数据线性可分,且有裕量(∣wTx∣≥bmin>0|w^T x| \geq b_{\min} > 0∣wTx∣≥bmin>0)。
2. 最小平方误差目标
最小化平方误差:
J(w)=∥Xw−b∥2=(Xw−b)T(Xw−b) J(w) = \|X w - b\|^2 = (X w - b)^T (X w - b) J(w)=∥Xw−b∥2=(Xw−b)T(Xw−b)
这是一个凸函数,有唯一最小值(如果 XXX 满秩)。
闭合解(批量最小二乘):
w^=(XTX)−1XTb=X+b \hat{w} = (X^T X)^{-1} X^T b = X^+ b w^=(XTX)−1XTb=X+b
其中 X+X^+X+ 是 XXX 的伪逆(Moore-Penrose伪逆)。如果 XTXX^T XXTX 可逆,就是普通逆。
得到 www 后,分类规则仍是 sign(wTx)\text{sign}(w^T x)sign(wTx)。
3. Ho-Kashyap 算法(H-K算法)
直接求伪逆计算量大,且如果数据线性不可分,误差不会为0。Ho-Kashyap 算法是一种迭代方法,同时能自动判断数据是否线性可分。
算法步骤:
- 初始化裕量向量 b(0)b^{(0)}b(0) 为一个小正向量(如全为 1,正类 +1,负类 -1 再取绝对值)。
- 重复以下迭代直到收敛:
- 计算当前权重:w(k)=(XTX)−1XTb(k)w^{(k)} = (X^T X)^{-1} X^T b^{(k)}w(k)=(XTX)−1XTb(k)(或用伪逆 X+b(k)X^+ b^{(k)}X+b(k))
- 计算误差向量:e(k)=Xw(k)−b(k)e^{(k)} = X w^{(k)} - b^{(k)}e(k)=Xw(k)−b(k)
- 更新裕量向量:
b(k+1)=b(k)+η(e(k)+∣e(k)∣) b^{(k+1)} = b^{(k)} + \eta \left( e^{(k)} + |e^{(k)}| \right) b(k+1)=b(k)+η(e(k)+∣e(k)∣)
其中 η>0\eta > 0η>0 是步长(常取 0 < η≤1\eta \leq 1η≤1)。
关键解释:
- e(k)+∣e(k)∣e^{(k)} + |e^{(k)}|e(k)+∣e(k)∣ 只对负误差分量有值(正误差分量抵消为0)。
- 这相当于只增加那些"还没分对"(Xw<bX w < bXw<b,即判别值还没达到裕量)的样本的裕量要求。
- 如果数据线性可分,最终 e(k)e^{(k)}e(k) 会全为非负(或零),bbb 稳定,算法收敛。
- 如果线性不可分,bbb 会持续增长(某些分量趋向无穷),可以设定上限判断不可分。
4.例题
假设两个样本(增广形式):
- 正类:x1=(1,1,1)Tx_1 = (1, 1, 1)^Tx1=(1,1,1)T → 期望接近 +b
- 负类:x2=(1,−1,1)Tx_2 = (1, -1, 1)^Tx2=(1,−1,1)T → 期望接近 -b
初始化 b(0)=(1,−1)Tb^{(0)} = (1, -1)^Tb(0)=(1,−1)T
计算 X=1111−11X = \begin{bmatrix} 1 & 1 & 1 \\ 1 & -1 & 1 \end{bmatrix}X=111−111
解:
已知条件(增广形式)
样本矩阵 XXX(2 行 3 列,每行是一个增广样本):
X=1111−11X = \begin{bmatrix} 1 & 1 & 1 \\ 1 & -1 & 1 \end{bmatrix}X=111−111
第1行:正类样本 x1=(1,1,1)Tx_1 = (1, 1, 1)^Tx1=(1,1,1)T(第一个1是偏置项)
第2行:负类样本 x2=(1,−1,1)Tx_2 = (1, -1, 1)^Tx2=(1,−1,1)T
初始化裕量向量(常用正类 +1,负类 -1):
b(0)=1−1b^{(0)} = \begin{bmatrix} 1 \\ -1 \end{bmatrix}b(0)=1−1
学习率 η=1\eta = 1η=1(便于快速收敛)
目标:找到权重向量 w=(w0,w1,w2)Tw = (w_0, w_1, w_2)^Tw=(w0,w1,w2)T,使得 Xw≈bXw \approx bXw≈b,且误差逐渐减小。
迭代过程
第 1 次迭代(k=0 → k=1)
用当前 b(0)b^{(0)}b(0) 计算权重 w(1)w^{(1)}w(1)(最小二乘解):w(1)=(XTX)−1XTb(0)w^{(1)} = (X^T X)^{-1} X^T b^{(0)}w(1)=(XTX)−1XTb(0)先计算 XTX^TXT:XT=111−111X^T = \begin{bmatrix} 1 & 1 \\ 1 & -1 \\ 1 & 1 \end{bmatrix}XT= 1111−11 计算 XTXX^T XXTX(3×3 矩阵):XTX=111−1111111−11=202020202X^T X = \begin{bmatrix} 1&1 \\ 1&-1 \\ 1&1 \end{bmatrix} \begin{bmatrix} 1&1&1 \\ 1&-1&1 \end{bmatrix} = \begin{bmatrix} 2 & 0 & 2 \\ 0 & 2 & 0 \\ 2 & 0 & 2 \end{bmatrix}XTX= 1111−11 111−111= 202020202 计算 (XTX)−1(X^T X)^{-1}(XTX)−1:行列式 ∣XTX∣=2⋅2⋅2−0=8|X^T X| = 2 \cdot 2 \cdot 2 - 0 = 8∣XTX∣=2⋅2⋅2−0=8,逆矩阵:(XTX)−1=1840−4040−404=0.50−0.500.50−0.500.5(X^T X)^{-1} = \frac{1}{8} \begin{bmatrix} 4 & 0 & -4 \\ 0 & 4 & 0 \\ -4 & 0 & 4 \end{bmatrix} = \begin{bmatrix} 0.5 & 0 & -0.5 \\ 0 & 0.5 & 0 \\ -0.5 & 0 & 0.5 \end{bmatrix}(XTX)−1=81 40−4040−404 = 0.50−0.500.50−0.500.5 计算 XTb(0)X^T b^{(0)}XTb(0):XTb(0)=111−1111−1=1−11−(−1)1−1=020X^T b^{(0)} = \begin{bmatrix} 1&1 \\ 1&-1 \\ 1&1 \end{bmatrix} \begin{bmatrix} 1 \\ -1 \end{bmatrix} = \begin{bmatrix} 1-1 \\ 1-(-1) \\ 1-1 \end{bmatrix} = \begin{bmatrix} 0 \\ 2 \\ 0 \end{bmatrix}XTb(0)= 1111−11 1−1= 1−11−(−1)1−1 = 020 得到权重:w(1)=0.50−0.500.50−0.500.5020=010w^{(1)} = \begin{bmatrix} 0.5 & 0 & -0.5 \\ 0 & 0.5 & 0 \\ -0.5 & 0 & 0.5 \end{bmatrix} \begin{bmatrix} 0 \\ 2 \\ 0 \end{bmatrix} = \begin{bmatrix} 0 \\ 1 \\ 0 \end{bmatrix}w(1)= 0.50−0.500.50−0.500.5 020 = 010 当前权重:w(1)=(0,1,0)Tw^{(1)} = (0, 1, 0)^Tw(1)=(0,1,0)T
计算当前输出 Xw(1)X w^{(1)}Xw(1):Xw(1)=1111−11010=1−1X w^{(1)} = \begin{bmatrix} 1&1&1 \\ 1&-1&1 \end{bmatrix} \begin{bmatrix} 0 \\ 1 \\ 0 \end{bmatrix} = \begin{bmatrix} 1 \\ -1 \end{bmatrix}Xw(1)=111−111 010 =1−1
计算误差向量 e(1)e^{(1)}e(1):e(1)=Xw(1)−b(0)=1−1−1−1=00e^{(1)} = X w^{(1)} - b^{(0)} = \begin{bmatrix} 1 \\ -1 \end{bmatrix} - \begin{bmatrix} 1 \\ -1 \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \end{bmatrix}e(1)=Xw(1)−b(0)=1−1−1−1=00误差全为 0。
更新裕量(虽然已为0,但按公式走):e(1)+∣e(1)∣=00e^{(1)} + |e^{(1)}| = \begin{bmatrix} 0 \\ 0 \end{bmatrix}e(1)+∣e(1)∣=00b(1)=b(0)+η(e(1)+∣e(1)∣)=1−1+1⋅00=1−1b^{(1)} = b^{(0)} + \eta (e^{(1)} + |e^{(1)}|) = \begin{bmatrix} 1 \\ -1 \end{bmatrix} + 1 \cdot \begin{bmatrix} 0 \\ 0 \end{bmatrix} = \begin{bmatrix} 1 \\ -1 \end{bmatrix}b(1)=b(0)+η(e(1)+∣e(1)∣)=1−1+1⋅00=1−1
算法收敛。
从第1次迭代后,误差 e=0e = 0e=0,bbb 不再变化,w=(0,1,0)Tw = (0, 1, 0)^Tw=(0,1,0)T 稳定。
验证分类效果:
判别函数 d(x)=wTx=0⋅x0+1⋅x1+0⋅x2=x1d(x) = w^T x = 0 \cdot x_0 + 1 \cdot x_1 + 0 \cdot x_2 = x_1d(x)=wTx=0⋅x0+1⋅x1+0⋅x2=x1
正类样本 x1=(1,1,1)Tx_1 = (1,1,1)^Tx1=(1,1,1)T → d(x1)=1>0d(x_1) = 1 > 0d(x1)=1>0 → 正确
负类样本 x2=(1,−1,1)Tx_2 = (1,-1,1)^Tx2=(1,−1,1)T → d(x2)=−1<0d(x_2) = -1 < 0d(x2)=−1<0 → 正确
决策边界:x1=0x_1 = 0x1=0(垂直线),完美分开两点。
5. LMSE算法优缺点总结
优点:
- 有闭合解(伪逆),计算精确
- Ho-Kashyap 迭代能自动检测线性可分性
- 比感知器更稳定(平方损失平滑)
- 即使不可分,也能给出"最优"最小误差解
缺点:
- 计算伪逆 O(d3)O(d^3)O(d3),特征维高时慢
- 对异常点敏感(平方损失放大离群误差)
- 需要裕量 bbb 的选择(太大会难收敛)
6. 与前后章节的联系
- 与 3.7 梯度法:LMSE 的闭合解等价于平方损失的批量梯度下降到收敛。
- 与感知器:感知器用 0-1 损失,LMSE 用平方损失,更鲁棒。
- 与现代:线性回归的最小二乘 + 分类阈值,就是早期的"线性分类器"。
7. 总结
最小平方误差算法把"分类"变成"让判别值尽量匹配一个正负标签"的回归问题,用最小二乘求解,既简单又能判断可分性,是感知器到现代线性模型的桥梁。
3.9 决策树简介
决策树是一种直观的判别式分类模型,它通过一系列"如果-则"规则(基于特征的条件判断)将样本逐步划分,最终给出分类结果。
1. 树的结构(如何安排节点和分支)
决策树的结构本质上是递归划分的过程:
- 从根节点开始,包含所有训练样本。
- 根据某个特征和某个取值(或阈值),将样本分成两个或多个子集。
- 对每个子集递归地重复上述过程,直到满足停止条件(如样本全属于同一类、样本太少、特征用尽等)。
树的形状特点:
- 每个内部节点对应一个特征的测试("天气是晴天吗?"、"年龄大于30吗?"等)。
- 每个分支对应测试的一个结果。
- 每个叶子节点对应最终的类别判断。
结构影响:
- 好的结构:重要的特征放在靠上的位置,树较浅,泛化能力强。
- 不好的结构:次要特征放在前面,或树过深,导致过拟合。
2. 特征变量的选择
在每个非终止节点上,需要从所有可用特征中选择一个最合适的特征来进行划分。这个选择直接决定了树的最终预测性能。
为什么需要衡量"合适"?
因为不同的特征划分后,子集的"纯度"(类别分布的集中程度)不同。
我们希望选择那个划分后子集纯度提升最大的特征。
这里列出三种常用的特征选择策略(衡量纯度提升的方法):
| 策略名称 | 核心思想 | 适用算法(课件提及) | 备注 |
|---|---|---|---|
| 信息增益 | 划分前后信息熵(不确定性)下降最多 | ID3 | 倾向于选择取值多的特征 |
| 信息增益比 | 在信息增益基础上除以特征本身的不确定性(固有值) | C4.5、C5.0 | 修正了信息增益的偏向问题 |
| Gini指数 | 划分前后基尼不纯度下降最多 | CART | 计算简单,常用于现代实现 |
三种策略的共同点 :
都是衡量划分前后子集纯度的提升,只不过用的"纯度指标"不同:
- 信息增益用熵(Entropy)
- 信息增益比用熵 + 特征固有值
- Gini指数用基尼不纯度
信息增益倾向于选择取值多的特征(因为取值多时容易产生纯度很高的子集),因此C4.5引入信息增益比来修正这个问题。
3. 树的生成规则(如何确定分裂点)
在选定特征后,还需要在该特征上确定具体的划分规则(即分裂点)。
常见情况:
- 离散特征(如天气:晴/阴/雨):通常每个取值一个分支(多叉树)。
- 连续特征(如年龄):需要在特征值上找一个阈值,将连续值二分为两段(如年龄 ≤ 30 vs. > 30)。
如何找分裂点?
- 对连续特征,通常把所有样本按该特征值排序。
- 尝试相邻样本值之间的中点作为候选分裂点。
- 计算每个候选点的纯度提升(信息增益/Gini下降等),选择提升最大的那个点作为分裂点。
生成规则的核心:
- 在每个非终止节点上,选择一个特征 + 一个分裂点,使得划分后子集的纯度提升最大。
- 重复这个过程,直到满足停止条件。
4. 树的剪枝(避免过度拟合)
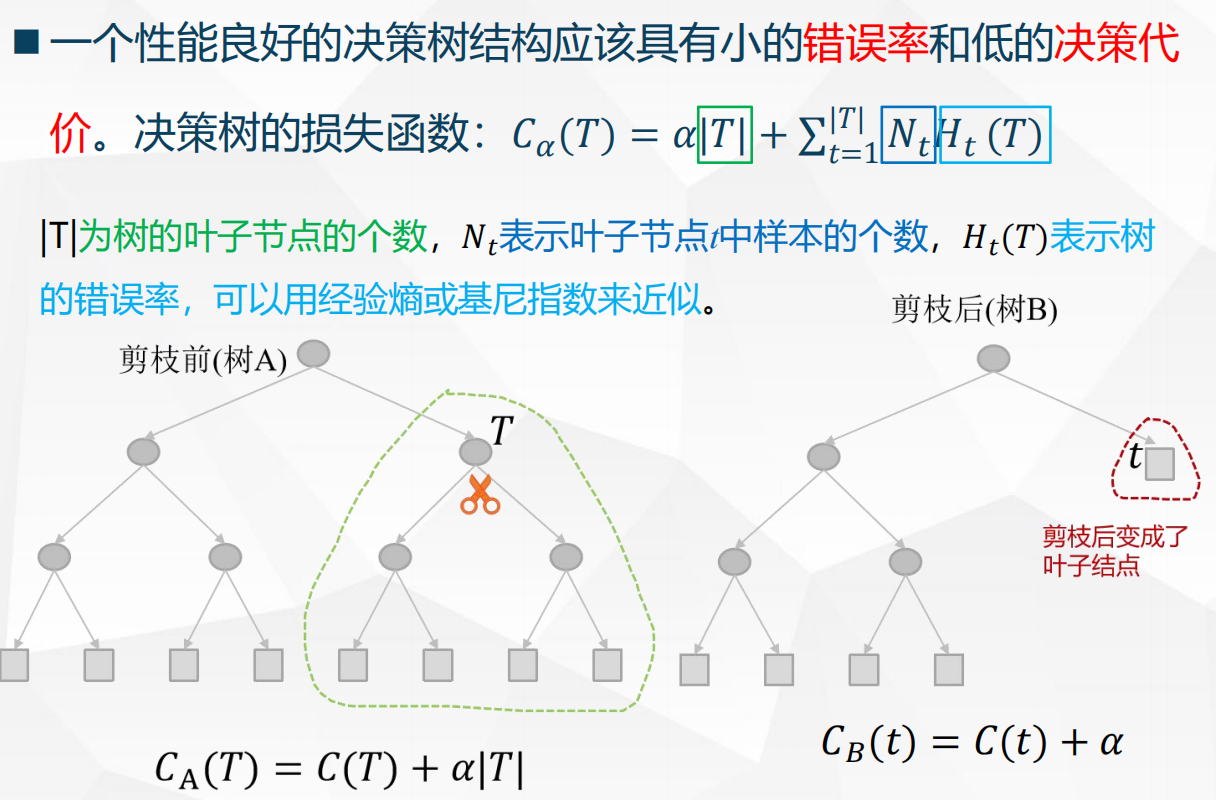
问题 :如果让树完全生长(直到每个叶子只有一个样本或纯度为100%),训练集上准确率会很高,但测试集上往往很差(过度拟合)。
剪枝的目的 :
通过删除一些子树或剪掉一些节点,使树更简单,提高泛化能力。
- 一个性能良好的决策树应该具有:
- 小的错误率(训练误差 + 测试误差)
- 低的决策代价(树越小,节点越少,代价越低)
代价复杂度剪枝 :
用一个损失函数来平衡错误率和树的复杂度:
Cα(T)=错误率(T)+α⋅∣T∣ C_\alpha(T) = \text{错误率}(T) + \alpha \cdot |T| Cα(T)=错误率(T)+α⋅∣T∣
- ∣T∣|T|∣T∣:树的叶子节点个数(树越复杂,∣T∣|T|∣T∣越大)
- 错误率:通常用训练集或验证集上的误分类率
- α\alphaα:调节参数(α\alphaα越大,越倾向于剪掉子树,得到更小的树)
剪枝过程:
- 先让树完全生长(不设停止条件)。
- 从下往上逐层考虑:如果剪掉某个子树后,损失函数 CαC_\alphaCα 没有显著增加(或降低),则剪掉。
- 通过交叉验证或验证集选择合适的 α\alphaα,得到最优的树。
剪枝前后对比:
- 剪枝前:树很深,很多叶子,训练集拟合完美,但泛化差。
- 剪枝后:剪掉一些分支,树变浅,泛化能力提升。
总结:决策树模型的四个关键问题
| 关键问题 | 核心内容 | 课件强调点 |
|---|---|---|
| 树的结构 | 如何安排节点和分支 | 递归划分 |
| 特征变量的选择 | 选哪个特征划分(信息增益/增益比/Gini) | 直接影响预测效果 |
| 树的生成规则 | 如何确定分裂点(离散/连续特征的处理) | 贪心选择纯度提升最大的划分 |
| 树的剪枝 | 如何避免过拟合(代价复杂度剪枝) | 平衡错误率与树复杂度 |
这是一份为您定制的《模式识别与机器学习:特征选择与提取》复习报告。这份报告基于您提供的课件内容,将核心概念进行了结构化整理,去掉了冗余信息,重点解析了难点(特别是K-L变换/PCA),并补充了通俗的解释。
第四章 特征选择和提取
4.1 目的
核心问题:维数灾难 (Curse of Dimensionality)
我们往往认为特征越多越好,但实际上并非如此。
-
现象:随着特征维度(Dimension)的增加,数据点在空间中变得极其稀疏。
-
后果:
距离失效 :在高维空间中,最大距离和最小距离的比值趋近于1(MaxDistMinDist→1\frac{MaxDist}{MinDist} \rightarrow 1MinDistMaxDist→1)。这意味着所有点之间的距离看起来都差不多,基于距离的分类器(如KNN)会失效 。
计算复杂:计算量呈指数级增长。
解决方案:降维(Dimensionality Reduction)。即在保证分类精度的前提下,减少特征维数 。
4.2 两个基本概念:选择 vs 提取
在降维时,我们有两种主要手段,概念上必须区分清楚 :
| 概念 | 定义 | 直观理解 | 数学表达 |
|---|---|---|---|
| 特征选择 (Selection) | 从原始特征集合中挑选出一个子集。 | 从100个特征里挑出最有用的10个,不改变特征本身的值。 | 从 {x1,...,xn}\{x_1, ..., x_n\}{x1,...,xn} 中选出 {xi1,...,xim}\{x_{i1}, ..., x_{im}\}{xi1,...,xim} |
| 特征提取 (Extraction) | 通过变换(映射),将原始特征组合成新的特征。 | 将身高和体重组合计算出BMI指数,产生了新的数值。 | y=f(x1,...,xn)y = f(x_1, ..., x_n)y=f(x1,...,xn) |
4.3 特征选择 (Feature Selection) 的三种策略
特征选择的目标是去除冗余 (Redundant)和无关(Irrelevant)的特征。本章重点介绍三种方法 :
过滤式 (Filter)
原理:在进入模型训练之前,先用统计指标给每个特征打分,筛选出高分特征。与后续使用的分类器无关。
常用指标 :
相关系数 :衡量特征与标签的线性关系。
互信息 (Mutual Information) :MI(xi,y)=∑p(xi,y)logp(xi,y)p(xi)p(y)MI(x_i, y) = \sum p(x_i, y) \log \frac{p(x_i, y)}{p(x_i)p(y)}MI(xi,y)=∑p(xi,y)logp(xi)p(y)p(xi,y),衡量特征包含了多少关于标签的信息。
信息增益 (Information Gain) :特征出现前后,熵减少了多少 。
χ2\chi^2χ2 (卡方) 统计量:测试特征与类别是否独立 。
- 优缺点:速度快,但忽略了特征之间的组合效应(比如特征A单独没用,但和特征B组合起来很有用,过滤式会把A扔掉)。
包裹式 (Wrapper)
原理:直接把分类器的性能作为评价标准。像"试错法"一样,尝试不同的特征组合,看哪个组合训练出来的模型效果好 。
-
搜索策略:
- 前向搜索:从0开始,每次加一个最好的特征。
- 后向搜索(递归特征消除 RFE):从所有特征开始,每次删一个最没用的特征。
-
优缺点:准确率高,但计算开销极大(需要反复训练模型)。
嵌入式 (Embedded)
-
原理:特征选择是模型训练过程的一部分 。
-
典型算法:
- L1 正则化 (Lasso):训练时让部分特征的权重变成0,从而自动剔除特征。
- 决策树/随机森林:树模型在分裂节点时会自动选择最优特征,可以输出Feature Importance。
4.4 特征提取核心:离散K-L变换 (与PCA相关)
这是本章的重难点 。K-L变换(Karhunen-Loeve Transform)是一种正交变换,目的是在降维后均方误差最小 。
基本原理
我们希望找到一个新的坐标系(一组基向量 Φ\PhiΦ),把原始数据投影到这个新坐标系上,保留最重要的维度。
原始数据:xxx (nnn维)变换公式:y=ΦTxy = \Phi^T xy=ΦTx (mmm维,且 m<nm < nm<n)
准则:最小均方误差(Minimum Mean Square Error)。
即丢弃部分维度后,重构回去的数据与原数据差距最小 12。
数学推导关键点
要使误差最小,变换矩阵 Φ\PhiΦ 的列向量必须满足以下条件:
正交性:Φ\PhiΦ 由正交向量组成。
特征向量:Φ\PhiΦ 的列向量必须是数据自相关矩阵 RRR(或协方差矩阵 CCC)的特征向量。
R=ExxTR = Exx\^TR=ExxT
Rφj=λjφjR \varphi_j = \lambda_j \varphi_jRφj=λjφj (λ\lambdaλ是特征值,φ\varphiφ是特征向量)
误差与特征值的关系
-
丢弃某些维度产生的误差,等于被丢弃的那些特征值之和 。
-
结论 :为了让误差最小,我们应该保留最大 的mmm个特征值对应的特征向量,丢弃最小的特征值。
算法步骤 (如何做题/计算)
如果题目给你一组样本数据,让你做K-L变换(或PCA),步骤如下:
- 中心化(重要):将样本均值变为0(x←x−xˉx \leftarrow x - \bar{x}x←x−xˉ)。此时自相关矩阵 RRR 等价于协方差矩阵 CCC。这一步做完,K-L变换通常被称为主成分分析 (PCA) 。
- 求矩阵:计算协方差矩阵 R≈1N∑xxTR \approx \frac{1}{N} \sum x x^TR≈N1∑xxT。
- 求特征:求解特征方程 ∣R−λI∣=0|R - \lambda I| = 0∣R−λI∣=0,得到特征值 λi\lambda_iλi。(III是单位矩阵)
- 排序:将特征值从大到小排序 λ1>λ2>...>λn\lambda_1 > \lambda_2 > ... > \lambda_nλ1>λ2>...>λn。
- 选基向量:选取前 mmm 个大特征值对应的特征向量 φ1,...,φm\varphi_1, ..., \varphi_mφ1,...,φm。
- 构造变换矩阵:Φ=φ1,φ2,...,φm\Phi = \\varphi_1, \\varphi_2, ..., \\varphi_mΦ=φ1,φ2,...,φm。
- 转换:新特征 y=ΦTxy = \Phi^T xy=ΦTx。
K-L变换/PCA 的物理意义
- 去相关:变换后的新特征之间是互不相关的(协方差为0,对角化)。
- 最大方差:保留的特征方向是数据方差(变化)最大的方向,也就是信息量最大的方向。
4.5 案例解析
题目 :
有两类模式(假设概率相等),数据如下:
ω1\omega_1ω1: (−5,−5)T,(−5,−4)T(-5, -5)^T, (-5, -4)^T(−5,−5)T,(−5,−4)T
ω2\omega_2ω2: (5,5)T,(5,6)T(5, 5)^T, (5, 6)^T(5,5)T,(5,6)T
求一维的特征提取。
步骤1:列出所有样本并计算整体均值向量mmm
为什么要求均值?
KL变换要求数据零均值化(去中心化),这样协方差矩阵才真正反映数据的变异性,而不是位置偏移。
所有样本(总N=4N=4N=4个):
ω1\omega_1ω1:x1=(−5−5)\mathbf{x}_1 = \begin{pmatrix}-5\\-5\end{pmatrix}x1=(−5−5),x2=(−5−4)\mathbf{x}_2 = \begin{pmatrix}-5\\-4\end{pmatrix}x2=(−5−4)
ω2\omega_2ω2:x3=(55)\mathbf{x}_3 = \begin{pmatrix}5\\5\end{pmatrix}x3=(55),x4=(56)\mathbf{x}_4 = \begin{pmatrix}5\\6\end{pmatrix}x4=(56)
整体均值
m=1N∑k=1Nxk=14(x1+x2+x3+x4)m = \frac{1}{N} \sum_{k=1}^N \mathbf{x}_k = \frac{1}{4} (\mathbf{x}_1 + \mathbf{x}_2 + \mathbf{x}_3 + \mathbf{x}_4)m=N1∑k=1Nxk=41(x1+x2+x3+x4)
逐维计算:
第一维:(−5−5+5+5)/4=0(-5 -5 +5 +5)/4 = 0(−5−5+5+5)/4=0
第二维:(−5−4+5+6)/4=2/4=0.5(-5 -4 +5 +6)/4 = 2/4 = 0.5(−5−4+5+6)/4=2/4=0.5
故
m=(00.5)m = \begin{pmatrix}0\\0.5\end{pmatrix}m=(00.5)
步骤2:数据去中心化(零均值化)
每个样本减去均值:x~k=xk−m\tilde{\mathbf{x}}_k = \mathbf{x}_k - mx~k=xk−m
计算结果:
x~1=(−5−5.5)\tilde{\mathbf{x}}_1 = \begin{pmatrix}-5\\-5.5\end{pmatrix}x~1=(−5−5.5)
x~2=(−5−4.5)\tilde{\mathbf{x}}_2 = \begin{pmatrix}-5\\-4.5\end{pmatrix}x~2=(−5−4.5)
x~3=(54.5)\tilde{\mathbf{x}}_3 = \begin{pmatrix}5\\4.5\end{pmatrix}x~3=(54.5)
x~4=(55.5)\tilde{\mathbf{x}}_4 = \begin{pmatrix}5\\5.5\end{pmatrix}x~4=(55.5)
步骤3:计算总协方差矩阵RRR(2×22\times22×2)
为什么用总协方差?
KL变换是对整体数据的第二阶统计进行对角化,得到全局最优的去相关基。
样本协方差矩阵(这里用除以NNN的有偏估计):
R=1N∑k=1Nx~kx~kTR = \frac{1}{N} \sum_{k=1}^N \tilde{\mathbf{x}}_k \tilde{\mathbf{x}}_k^TR=N1∑k=1Nx~kx~kT
逐个计算外积后求和除以4,得:
R=(25252525.25)R = \begin{pmatrix}25 & 25\\25 & 25.25\end{pmatrix}R=(25252525.25)
步骤4:对协方差矩阵RRR进行特征值分解
求解特征方程det(R−λI)=0\det(R - \lambda I) = 0det(R−λI)=0:
det(25−λ252525.25−λ)=(25−λ)(25.25−λ)−625=0\det \begin{pmatrix}25-\lambda & 25\\25 & 25.25-\lambda\end{pmatrix} = (25-\lambda)(25.25-\lambda) - 625 = 0det(25−λ252525.25−λ)=(25−λ)(25.25−λ)−625=0
化简得二次方程:
λ2−50.25λ+6.25=0\lambda^2 - 50.25\lambda + 6.25 = 0λ2−50.25λ+6.25=0
判别式Δ=50.252−25=2500\Delta = 50.25^2 - 25 = 2500Δ=50.252−25=2500,根为:
λ1,2=50.25±502\lambda_{1,2} = \frac{50.25 \pm 50}{2}λ1,2=250.25±50
最大特征值λ1=50.125\lambda_1 = 50.125λ1=50.125(即201/4201/4201/4)
最小特征值λ2=0.125\lambda_2 = 0.125λ2=0.125(即1/41/41/4)
步骤5:求对应特征向量并归一化
对于最大特征值λ1=50.125\lambda_1 = 50.125λ1=50.125:
(R−λ1I)ϕ1=0(R - \lambda_1 I)\phi_1 = 0(R−λ1I)ϕ1=0得方向近似(11)\begin{pmatrix}1\\1\end{pmatrix}(11)
归一化后主成分方向:
ϕ1=12(11)≈(0.70710.7071)\phi_1 = \frac{1}{\sqrt{2}} \begin{pmatrix}1\\1\end{pmatrix} \approx \begin{pmatrix}0.7071\\0.7071\end{pmatrix}ϕ1=2 1(11)≈(0.70710.7071)
步骤6:一维KL变换(降维到1维)
取最大特征向量作为投影方向,变换矩阵(行向量):
A=ϕ1T=12(11)A = \phi_1^T = \frac{1}{\sqrt{2}} \begin{pmatrix}1 & 1\end{pmatrix}A=ϕ1T=2 1(11)
一维特征值为:
y=A(x−m)=12(x1+x2−0.5)y = A (\mathbf{x} - m) = \frac{1}{\sqrt{2}} (x_1 + x_2 - 0.5)y=A(x−m)=2 1(x1+x2−0.5)
步骤7:计算每个样本的一维特征值
ω1\omega_1ω1第一点(−5,−5)(-5,-5)(−5,−5):y=12(−5−5.5)=−10.52≈−7.4246y = \frac{1}{\sqrt{2}} (-5 -5.5) = \frac{-10.5}{\sqrt{2}} \approx -7.4246y=2 1(−5−5.5)=2 −10.5≈−7.4246
ω1\omega_1ω1第二点(−5,−4)(-5,-4)(−5,−4):y=12(−5−4.5)=−9.52≈−6.7175y = \frac{1}{\sqrt{2}} (-5 -4.5) = \frac{-9.5}{\sqrt{2}} \approx -6.7175y=2 1(−5−4.5)=2 −9.5≈−6.7175
ω2\omega_2ω2第一点(5,5)(5,5)(5,5):y=12(5+4.5)=9.52≈6.7175y = \frac{1}{\sqrt{2}} (5 + 4.5) = \frac{9.5}{\sqrt{2}} \approx 6.7175y=2 1(5+4.5)=2 9.5≈6.7175
ω2\omega_2ω2第二点(5,6)(5,6)(5,6):y=12(5+5.5)=10.52≈7.4246y = \frac{1}{\sqrt{2}} (5 + 5.5) = \frac{10.5}{\sqrt{2}} \approx 7.4246y=2 1(5+5.5)=2 10.5≈7.4246