会议:COLING 2025
作者:Tengfei Feng, Liang He et al.(清华,Tsinghua University,新疆大学)
核心关键词:KBQA|语义解析|LLM + 知识图谱 | KGQA
一、动机 & 问题背景
该工作聚焦于知识图谱问答(KBQA):即给定一个自然语言问题,基于大规模知识库输出答案。现有的知识库问答(KBQA)方法可以大致分为基于信息检索(Information Retrieval,IR)的方法和基于语义分析(Semantic Parsing,SP)的方法。
基于信息检索(IR) 的方法主要是从图或其他知识库中检索相关的事实知识来回答给定的问题。
基于基于语义分析(SP) 的方法旨在将自然语言问题转换为知识库上的可执行逻辑形式(例如,SPARQL,查询图)。
- 精度不足:基于IR或SP 存在精度不足或泛化能力差的问题
基于LLM 的KBQA方法常常能对常识性和事实性问题给出正确的答案,但直接生成逻辑形式流程易受知识图噪声谱干扰。使用大语言模型(LLM)来生成这种逻辑形式存在两大挑战:
- 幻觉问题:LLM可能会生成知识库中不存在的关系或实体。
- 知识不精确:LLM内部的知识可能与特定知识库中的事实不完全一致,尤其在处理复杂问题时,准确率会下降。
为了解决上述问题,本文提出了一个名为 RGR-KBQA 的新框架。通过在逻辑形式生成前后两次引入知识图谱信息,有效缓解大语言模型在逻辑形式生成中的幻觉问题,并在复杂多跳问题上显著提升性能。
二、RGR-KBQA 总体框架概述
RGR-KBQA 是面向知识库问答(KBQA)的三阶段框架,通过 "检索--生成--再检索" 流程提升大语言模型(LLM)生成逻辑形式的准确性:
- 先检索 :从知识图谱中检索与问题最相关的推理路径(最优关系链);
- 再生成 :微调 LLM,使其在给定 问题 与 最相关的推理路径 时生成结构化逻辑形式(如 S-expression);
- 后修正:对生成结果中的实体和关系进行语义匹配,替换为知识库中的标准标识,确保可执行。
该方法有效缓解 LLM 幻觉,提高 KBQA 的准确率与可解释性。
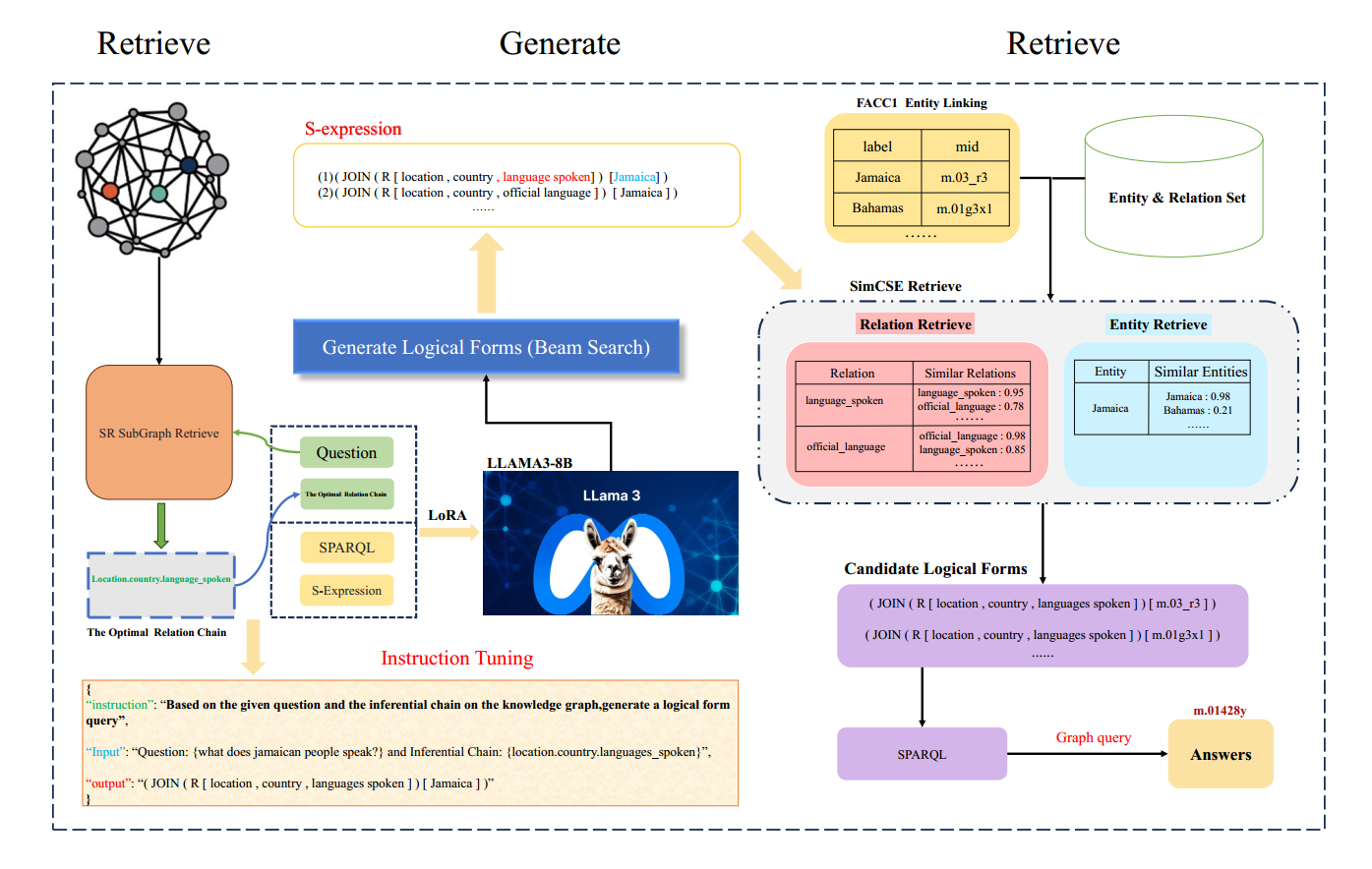
给定一个问题和一个知识库,RGR-KBQA首先检索最相关的最佳关系链。
然后使用由 <自然语言问题+最佳关系链,逻辑形式>构成的"问-答 对" 所组成的 数据集微调LLM。微调的LLM随后,将自然语言问题加最佳关系链,转换为相应的逻辑形式。
然后执行逻辑形式中的实体和关系进行检索,并搜索可以转换为知识图上的可执行SPARQL查询的逻辑形式。
最后,通过执行转换后的SPARQL查询,生成最终答案。
三、 第一阶段:Optimal Relation Chain 抽取
目标 :给定问题q, 从知识图谱中找到相关的推理路径。
方法 :利用可训练的子图检索模型,识别从问题中的主题实体 到潜在答案的最优关系链(Optimal Relation Chain)。
子图检索的目标是找到概率P(a)最大的子图G, 从主题实体到答案实体的最短路径被用作指导子图检索模型学习的监督信号。
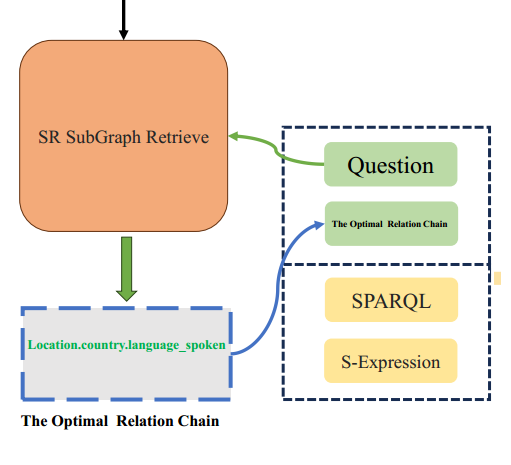
由上图所示,示例用的问题q:what does jamaican people speak?
Optimal Relation Chain 抽取的结果为:location.country.languages_spoken
3.1 问题--关系相似度建模
使用 RoBERTa 对问题和关系文本进行编码:
s c o r e ( q , r ) = f ( q ) ⋅ h ( r ) score(q, r) = f(q) \cdot h(r) score(q,r)=f(q)⋅h(r)
其中:
- f ( q ) f(q) f(q) 表示问题的向量表示
- h ( r ) h(r) h(r) 表示关系文本的向量表示
3.2 多跳路径扩展机制
在第 t t t 步,当前路径历史为:
r 1 , r 2 , ... , r t − 1 \] \[r_1, r_2, \\dots, r_{t-1}\] \[r1,r2,...,rt−1
将问题与路径历史拼接后重新编码:
f ( q t ) = RoBERTa ( q ; r 1 , r 2 , ... , r t − 1 ) f(q_t) = \text{RoBERTa}(q; r_1, r_2, \\dots, r_{t-1}) f(qt)=RoBERTa(q;r1,r2,...,rt−1)
当前关系的选择概率为:
p ( r ∣ q t ) = 1 1 + exp ( s c o r e ( q t , END ) − s c o r e ( q t , r ) ) p(r \mid q_t) = \frac{1}{1 + \exp(score(q_t, \text{END}) - score(q_t, r))} p(r∣qt)=1+exp(score(qt,END)−score(qt,r))1
其中:
- END \text{END} END 为虚拟终止关系
- 当终止概率最高时停止路径扩展
3.3 路径整体评分
完整路径的概率定义为:
p ( path ∣ q ) = ∏ t = 1 ∣ path ∣ p ( r t ∣ q t ) p(\text{path} \mid q) = \prod_{t=1}^{|\text{path}|} p(r_t \mid q_t) p(path∣q)=t=1∏∣path∣p(rt∣qt)
最终选择概率最大的路径作为 Optimal Relation Chain(最优关系链)。
3.4 关系链的价值分析
- 显式约束 LLM 的推理方向
- 与逻辑形式结构天然对齐
- 在信息量与噪声之间取得平衡
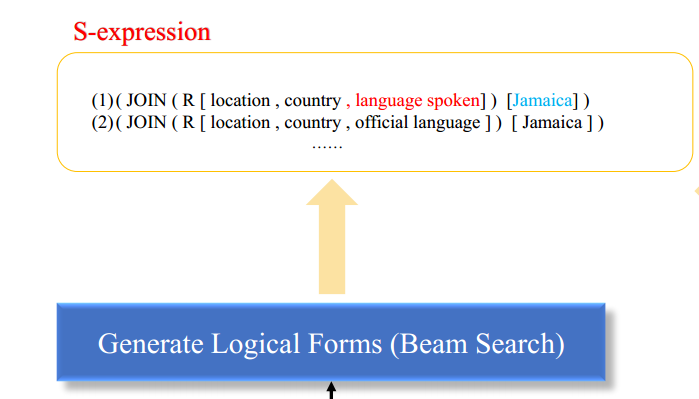
四、 第二阶段:LLM 生成逻辑形式
- 目标:基于问题和检索到的关系链,生成结构化的逻辑形式(如 S-expression)。
- 方法:这一阶段的实现是通过调整LLM提示词实现的。本文为效果更佳对LLM进行了微调。
- 效果:使模型学会融合外部知识与自然语言语义,生成更准确的查询结构。
这一阶段的提示词,输入为 "问题 + 最优关系链",输出 为 "对应逻辑形式",如下图所示:

另外,本文采用 S-expression 作为中间逻辑表示,包含:
JOIN:关系跳转AND:逻辑约束R:反向关系COUNT、GT等算子
这种表示形式 结构清晰、易于序列生成、可直接转换为 SPARQL。
五、 第三阶段:生成后的无监督检索纠错
这一阶段的目的是校正生成逻辑形式中的实体和关系,确保其在知识库中可执行。
实验发现:
- 完全匹配逻辑形式:63.5%
- Beam Search 候选中正确:77.4%
- 逻辑结构骨架正确率:92%
这表明LLM 更擅长生成"推理结构",而非精确的 KG 实体与关系。
因此,相信LLM返回结构,不完全相信内容。于是论文引入基于相似度检索的纠错机制。
对于生成的实体 e e e,在 KG 实体集合中检索:
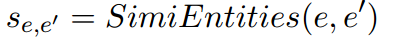
关系检索过程完全相同。这里大概是使用无监督 SimCSE训练后的embeding进行余弦相似度的匹配,然后选取 Top- k k k 候选实体。
可执行性检索结果的最终选择:首先枚举候选逻辑形式,将其转换为 SPARQL,并执行查询。丢弃不可执行结果,直到返回第一个可执行答案。这一阶段的示例如下图所示:
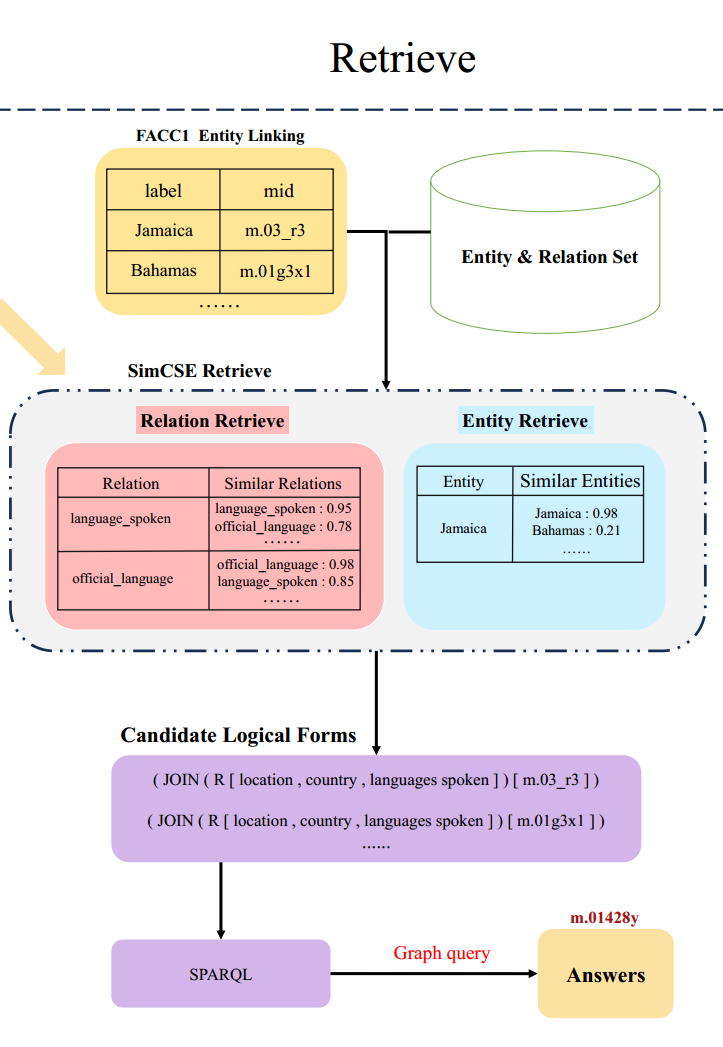
将修正后的逻辑形式转换为 SPARQL 查询 ,在知识库上执行以获得答案。整个流程可解释、可验证,显著缓解了 LLM 的幻觉问题。
六、实验结果与分析
(1) 去掉 Optimal Relation Chain 所有指标下降,证明单独LLM无法做的很好
(2) 随机关系链,反而伤害性能
(3) 去掉最后一次 Retrieval,明显性能下降
因此本文的三阶段是必要的,缺一不可的。
七、本文的优缺点
优点:
- 方法设计清晰、工程可落地
- 有效缓解 LLM 幻觉
- 逻辑可解释(SPARQL)
- 不依赖超大闭源模型
- 对复杂 KBQA 有效
局限性:
- 强依赖 KG 质量
- 训练和推理成本仍偏高
- Optimal Relation Chain 本身可能出错
- 实验测试范围太小