因为工作的关系,经常有朋友找我咨询大大小小的软件问题。问得多了,难免精力有限,于是就萌生了这么一个"AI软件咨询"的念头趁着年尾工作不忙,用Claude Code把这东西搓了出来,记录下来分享一下踩过的坑,也请各位老哥帮忙看看产品如何。
第一个坑:眼高手低,上来就想搞多Agent协同
我一开始的想法很宏大,因为咱也是看了不少文章,记了不少术语的,所以我上来就让Claude给我整个多Agent架构的设计,结果Claude先劝住了我(也许是Linus风格的CLAUDE.local.md起了作用):真正的多Agent架构没必要,你一个人也玩不转,用Persona-based Pipeline就行了。
Persona-based Pipeline是什么?
先说多Agent架构:5个独立的Agent各管一摊,通过消息队列或API互相通信。听起来很酷,但问题是调试地狱------一个bug可能跨3个Agent,你得翻5份log才能定位。
Persona-based Pipeline的思路不一样:只有一个Agent,但它有多重人格。根据对话进行到哪个阶段,切换不同的System Prompt,让同一个Agent表现出不同的专业能力。
对比一下:
| 多Agent架构 | Persona-based Pipeline | |
|---|---|---|
| 调试复杂度 | 高(多份log,跨Agent追踪) | 低(一份log搞定) |
| 状态同步 | 需要消息队列/共享存储 | 天然共享(同一个Agent) |
| 维护成本 | 需要3-4人团队 | 1人可维护 |
| 灵活性 | Agent可独立扩展 | 扩展需改同一个Agent |
| 适用场景 | 大团队、复杂系统 | 小团队、快速迭代 |
Claude给出的Persona-based Pipeline设计:
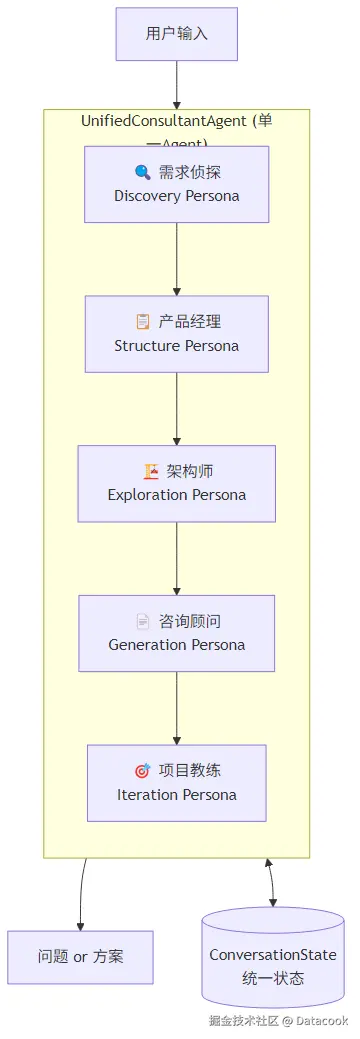
核心思想是单一推理循环:不管在哪个阶段,每轮对话只调用一次AI。AI根据当前状态自己决定:是继续问问题,还是生成方案。
python
class UnifiedConsultantAgent:
"""统一的咨询 Agent - 单一推理循环"""
async def process_turn(self, state, user_input):
# 1. 根据阶段选择Persona(切换System Prompt)
persona = PERSONAS[state.phase]
# 2. 单次AI调用,完成所有工作
result = await self.client.messages.create(
model=self.model,
messages=[{"role": "user", "content": prompt}]
)
# 3. AI自己决定:继续问 or 生成方案
if result.decision == "ask":
return result.question
else:
return result.solution5个Persona各司其职:
| 阶段 | Persona | 干什么 |
|---|---|---|
| Discovery | 需求侦探 | 像麦肯锡顾问一样提问,挖掘用户自己都没想清楚的需求 |
| Structure | 产品经理 | 把收集到的信息整理成结构化需求文档 |
| Exploration | 架构师 | 引导用户参与技术选型决策(React还是Vue?单体还是微服务?) |
| Generation | 咨询顾问 | 生成完整技术方案,包括架构图、预算、路线图 |
| Iteration | 项目教练 | 根据用户反馈持续优化方案 |
这套架构的好处:调试只看一个地方的log,代码量从5个Agent互相调用变成一个Agent + 5套Prompt,维护成本大幅下降。
第二个坑:Chat式自由对话,AI问个没完没了
架构定好之后开始开发。一开始Claude是照着ChatGPT的交互做了个聊天界面------用户打字,AI回复,自由对话。但问题很快暴露:AI会没完没了地问问题。用户说"我想做个电商app",AI问"目标用户是谁",用户答了,AI又问"预算多少",答了又问"时间呢"......说实话我自己回答了3个问题就已经不耐烦了,而AI觉得信息还不够。
另一个更严重的问题是,这个系统的预期用户自己可能都还没想明白想要什么,发散式的提问不仅不能帮他们理清思路,反而让人更糊涂。
把这些问题跟Claude描述了之后,它建议我换个思路:把自由对话改成引导式问答。
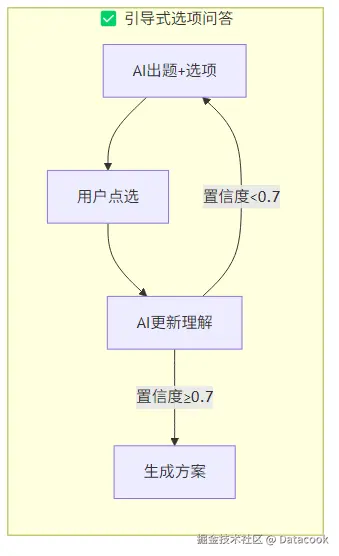
核心改动有三个:
1. 选项卡代替自由输入
AI生成问题时,同时给出3-4个选项,用户点选就行。同时提供了"补充说明",减少打字负担,也避免了理解歧义。
php
interface QuestionOption {
value: string // 选项值
label: string // 显示文字
recommended: boolean // 是否推荐
explanation?: string // 选这个意味着什么
cost_impact?: string // 对成本的影响(如"+20%")
time_impact?: string // 对工期的影响(如"+2周")
}前端用卡片展示,标记出推荐选项,以及附加说明每个选项对成本、工期等的影响:
ini
<OptionCard
option={{ label: "React + Vite", recommended: true, cost_impact: "基准", time_impact: "最快" }}
isSelected={selected}
onToggle={handleToggle}
/>2. 置信度自动判断何时停止
不再硬编码"问5轮就停",而是让AI自己评估信息收集的完整度:
ini
MAX_ROUNDS = 7 # 硬上限,防止死循环
CONFIDENCE_THRESHOLD = 0.7 # 置信度阈值
class ConversationState:
confidence: float = 0.0 # AI对"信息够了"的信心,0-1
round_count: int = 0 # 当前轮次
# AI每轮对话后更新置信度
# 当 confidence >= 0.7 或 round_count >= 7 时,自动生成方案3. 置信度进度条
用户能实时看到AI"觉得信息够不够",心理上有预期:
css
{/* 实际代码 - Consultation.tsx */}
<div className="flex items-center justify-between mb-2">
<span>对话轮次: {roundCount}</span>
<span>置信度: {Math.round(confidence * 100)}%</span>
</div>
<div className="h-2 bg-gray-200 rounded-full">
<div
className="h-full bg-primary-600"
style={{ width: `${confidence * 100}%` }} // 进度条宽度 = 置信度
/>
</div>
// 显示效果:对话轮次: 3 置信度: 65%
// [==============> ]这么改完之后,产品前端的基本雏形就形成了。
第三个坑:产出的方案泛泛而谈,没有针对性
随着前端框架的稳定,很快就发现新的问题:产出的方案空话连篇,根本不具备商业价值。
Claude建议用两阶段生成:先出骨架,再逐章节深化。
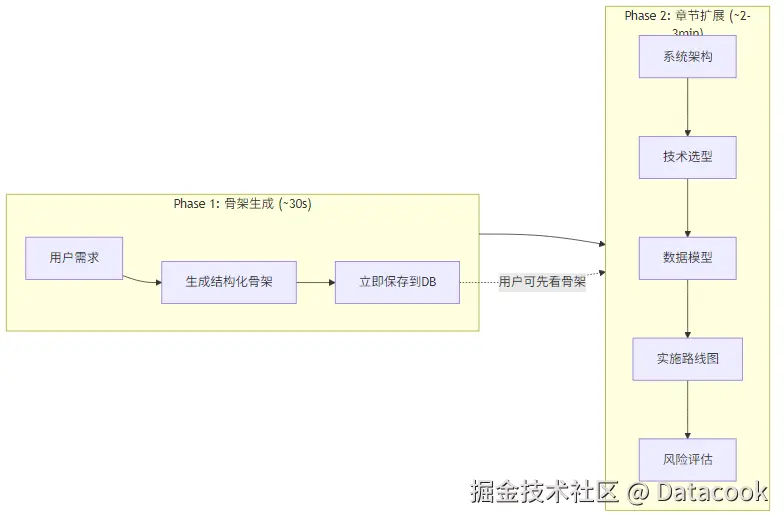
Phase 1:骨架生成
30秒内出一个结构化的方案框架。包含标题、功能清单、技术栈概要、预算范围、时间线。
Phase 2:章节深化
骨架出来后,对每个章节单独调用AI扩展。比如"系统架构"章节,会专门生成:
python
# section_expander.py - 章节扩展器
SECTION_EXPANSION_PROMPTS = {
SectionType.ARCHITECTURE: '''
你是一位资深技术架构师。请深化"系统架构"章节。
必须包含:
1. type - 架构类型
2. description - 详细架构说明(300-500字)
3. diagram_mermaid - 完整的系统架构图
4. deployment_diagram - 部署架构图(新增)
5. data_flow_diagram - 数据流图(新增)
6. design_principles - 设计原则列表
7. scalability_notes - 扩展性说明
''',
# ... 其他章节
}每个章节独立扩展,互不影响。最终方案从200行变成800-1200行,配以Mermaid图表(架构图、ER图、甘特图、序列图等),质量完全不一样。
第四个坑:方案生成超时,云服务直接断连接
两阶段生成效果不错,但又碰到新问题:云服务默认30-60秒就会断开"idle"连接。而章节扩展要2-3分钟,经常生成到一半连接就断了。
Claude建议用SSE流式响应 + 心跳机制:
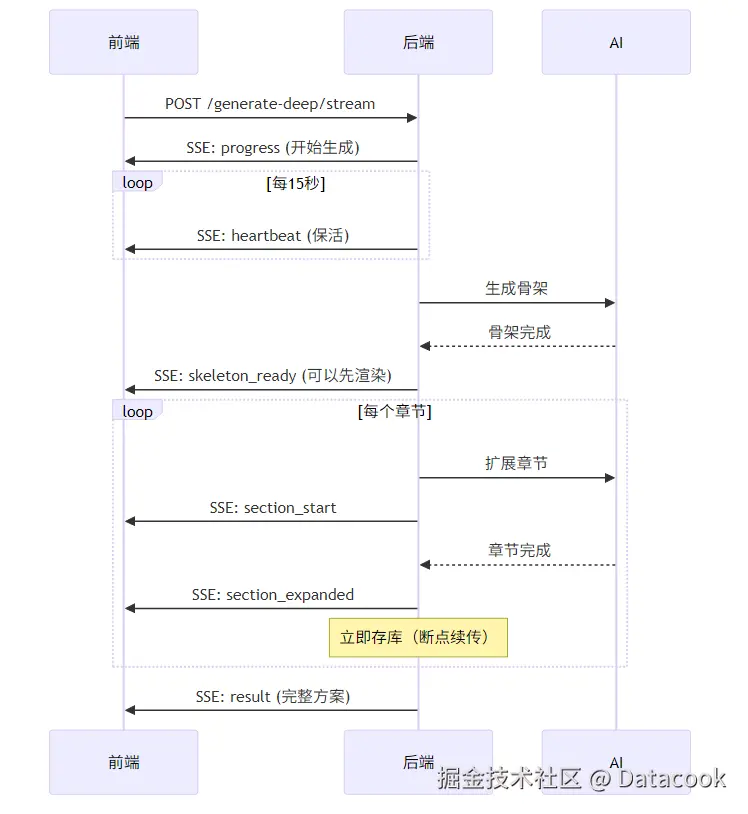
核心代码:
python
# solutions.py - 一键深度生成的SSE流
DEEP_GENERATION_CONFIG = {
"section_timeout_seconds": 90, # 单章节超时
"total_timeout_seconds": 300, # 整体超时(5分钟)
"max_retry_per_section": 1, # 每章节最大重试次数
"heartbeat_interval_seconds": 15, # 心跳间隔
}
async def heartbeat_sender():
"""后台心跳发送器 - 防止云服务断连"""
while not stop_event.is_set():
await asyncio.sleep(15)
yield ": heartbeat\n\n" # SSE注释格式的心跳
async def _stream_deep_solution_generation(...):
# Phase 1: 骨架
yield await sse_event("skeleton_ready", {"solution": skeleton})
# Phase 2: 逐章节扩展
for section_type in recommended_sections:
yield await sse_event("section_start", {"section_type": section_type})
expanded = await expander.expand_section(section_type, solution)
# 每个章节完成立即存库(断点续传支持)
await repo.expand_section(session_id, section_type, expanded)
yield await sse_event("section_expanded", {
"section_type": section_type,
"enhanced_content": expanded.enhanced_content,
"word_count": expanded.word_count,
"diagram_count": expanded.diagram_count,
})三个关键设计:
- 心跳保活:每15秒发一个SSE注释包,让云服务知道连接还活着
- 即时存库:每个章节完成立即保存,断了也不怕------下次可以从断点继续
- 失败跳过:某章节超时/失败不影响其他章节,失败的可以单独重试
最后闲聊几句
前面提到过的Linus风格的CLAUDE.local.md,我个人是十分喜欢,除了解决问题的思路很简洁明快之外,说话也很好听,动不动就是"你的垃圾代码"如何如何,整个Vibe Coding的过程完全不困。
我自己在执行较长任务时喜欢加一个后缀:
- 我暂时不干预,所有产品和技术决策由你做出,我一会儿回来验收成果;
- 不用着急出结果,所有细节你慢慢做,做对最重要;
- 遇到不确定的,先查一下context 7里的文档;还不确定的,网上搜索一下;
- 从全栈的视角去规划子任务,所有子任务分阶段执行,必要时用子Agent进行,每个阶段结束时跑一下单元测试,以免最后发现不行要推到重来;
- UI部分不用纠结,按现代主流风格去写就行,
因为我还装了很多backend/frontend-developer, python-experts之类的agent, 这个命令会自动把这些工具组织起来协同工作,虽然最终产出的代码还是免不了会有错误,但我还是坚持着一行代码不手写地把这个产品做了出来。
再次请各位老哥共同来试用评价一下:advisor.datacook.cloud/
最后也祝大家能把心中所想快速地实现出来。