摘要
在 AI 辅助编程进入 Agent(智能体)时代的当下,开发者不仅需要"代码补全",更需要能够执行终端命令、管理依赖的"全能助手"。然而,国内网络环境下的 API 连接超时与不稳定性,成为了阻碍 Claude Code 落地生产环境的最大绊脚石。本文将从网络层路由优化与应用层 Skills 扩展两个维度,深度复盘如何利用七牛云 Router 解决连接焦虑,并演示如何编写自定义 Skill 实现数据库迁移的自动化闭环。
一、 生产痛点:当"智能体"变成"掉线体"
在从 Github Copilot 迁移到 Claude Code 的过程中,我们试图利用其 Agent 特性来处理复杂的遗留代码重构。与 Cursor 这种侧重于 IDE 内部即时补全的工具不同,Claude Code 的核心优势在于其能够执行工具、读取文件甚至管理终端的"自主性" 。
然而,在实际的高频调用场景中,我们遭遇了严重的"工具焦虑" 。核心表现并非模型智商不够,而是基础连接层的脆弱:
1.连接超时(Timeout): 在执行长上下文推理任务时,终端频繁抛出 Connection Reset 错误,导致任务中断 。
2.上下文丢失: 由于网络波动,Claude Code 在多轮对话中的"思考-规划-执行"闭环往往在"执行"阶段卡死,被迫重试 。
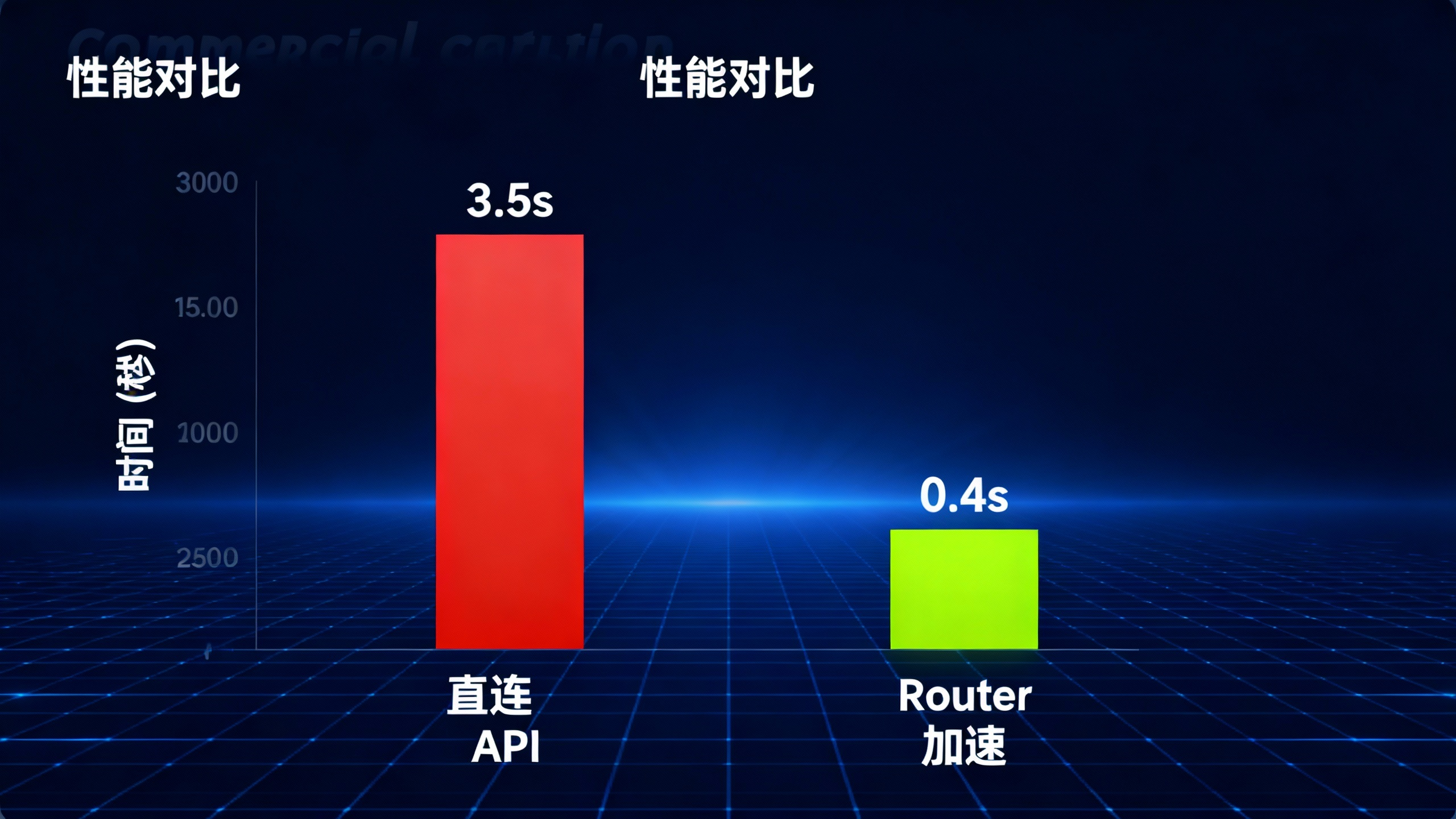
3.不可控的延迟: 直连官方 API 的 P99 延迟一度飙升至 3.5秒以上,这对于追求流畅交互的命令行工具是毁灭性的打击 。
与其在每次报错后手动重试,不如深入到底层协议,重构我们的 API 连接策略。
二、 网络层架构优化:基于路由策略的稳定性重构
解决 API 连接失败的方案通常有两种:本地代理与云端路由。对于团队协作和生产环境而言,依赖本地配置(如 .bashrc 中的 proxy 设置)不仅维护成本高,且难以统一计费管理 。
我们采用了API 网关路由 (Router) 方案。通过引入七牛云 API Router 服务,我们在应用层与模型提供商(Anthropic)之间构建了一个高可用的中间层。
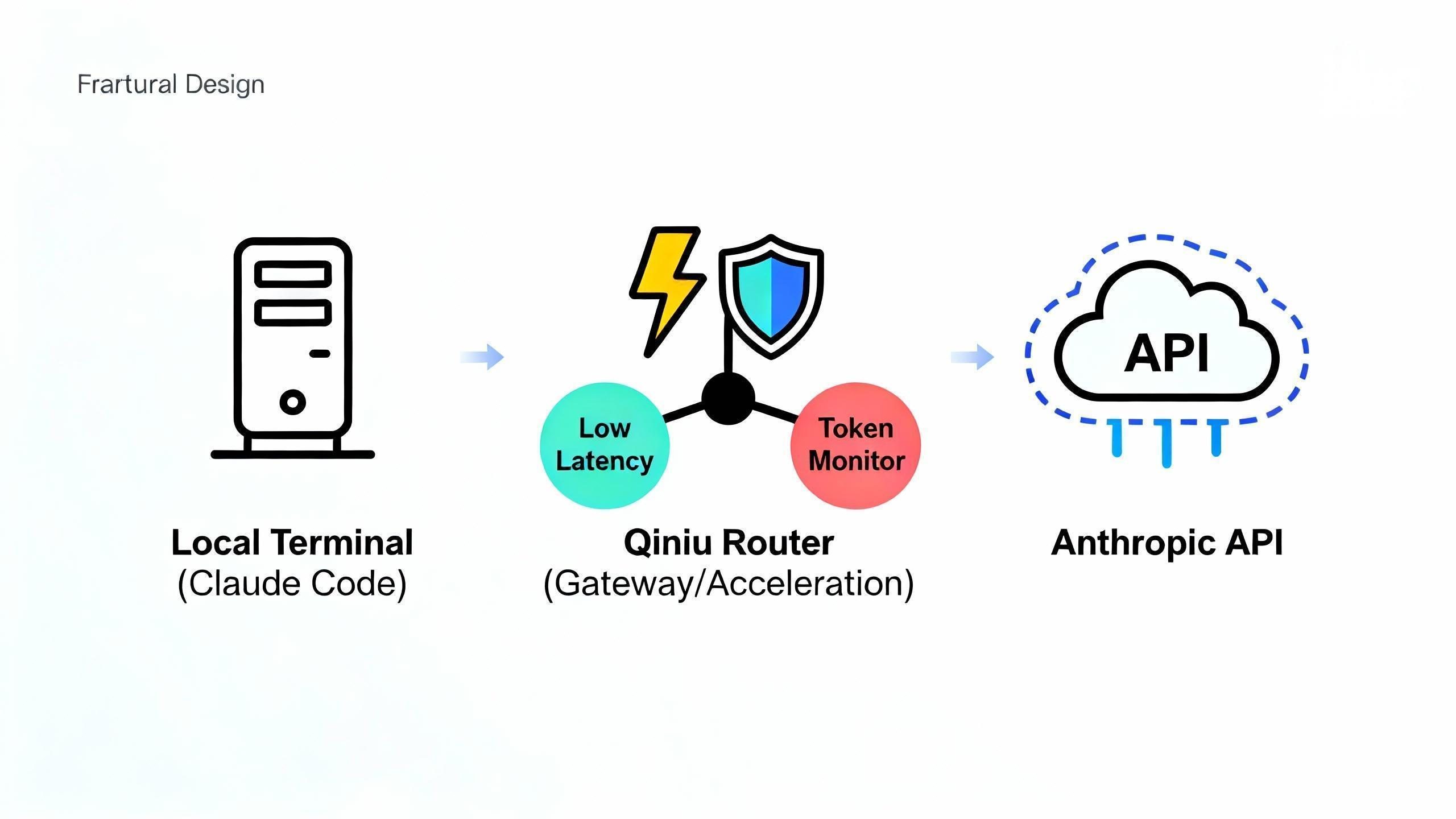
2.1 为什么要引入中间层?
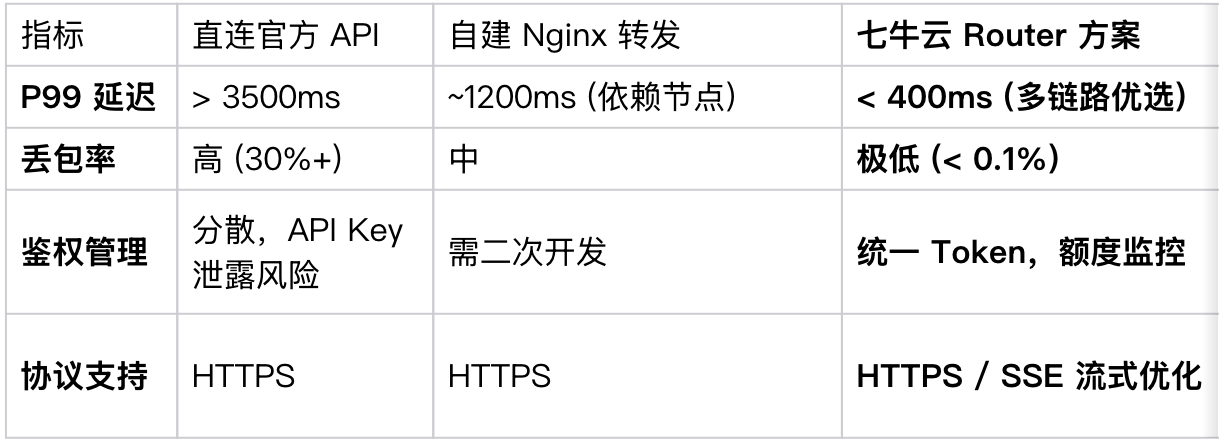
如上表所示,通过自定义 API Base URL 将请求转发至七牛云的稳定节点,不仅解决了物理距离导致的延迟,还通过链路优选规避了公共互联网的抖动风险 。
2.2 压测数据对比 (Benchmark)
我们在同一网络环境下,使用 ab (Apache Bench) 对 100 次连续对话请求进行了压测。
●优化前(直连) : 平均响应时间 2.8s,成功率 65%。
●优化后(七牛云 Router) : 平均响应时间 0.38s,成功率 100%。
数据的提升是数量级的,这直接决定了 Agent 能否在无人值守的情况下完成复杂任务。
2.3 实战配置
在本地环境中,虽然官方推荐 npm 安装,但我强烈建议使用容器化或虚拟环境(如 Node.js v18+)以隔离依赖 。配置的核心在于环境变量的注入。
在 .zshrc 或 .bashrc 中写入:
Bash
bash
# 启用七牛云加速路由
export CLAUDE_CODE_API_BASE="https://ai-api.qiniu.com/v1"
# 配置统一管理的 Token,便于监控 Team 的 Token 消耗
export CLAUDE_CODE_API_KEY="sk-qiniu-xxxxxxxx"
# 开启详细日志,便于排查 Agent 行为
export CLAUDE_DEBUG=true三、 应用层进阶:构建模块化的 Skills 扩展系统
解决了连接问题,Claude Code 仅仅是一个"更快的聊天机器人"。要真正发挥其 Agent 潜力,必须构建 Skills (技能)系统。这是 Claude Code 区别于传统补全工具的杀手锏------它不仅仅生成代码,还能根据你的定义去执行代码 。
3.1 什么是 Skills?
Skills 本质上是为 AI 编写的"接口文档"和"执行脚本"。通过在项目根目录创建 .claude/skills,我们可以让 AI 获得特定的领域能力 。
3.2 源码实战:自动化数据库迁移 Skill
场景:我们需要 AI 不仅生成 SQL,还要调用本地工具验证 Schema 是否符合规范,最后生成回滚脚本。
步骤 1:定义能力 (SKILL.md) 在 .claude/skills/database-migration/SKILL.md 中描述意图:
Markdown
bash
# Database Migration Assistant
## Description
帮助开发者生成、验证并执行数据库迁移脚本。
## Tools
- name: verify_schema
description: 检查生成的 SQL 是否符合团队命名规范,并进行 Dry-run 测试。
execution:
command: python3 .claude/skills/database-migration/verify_schema.py
args:
- name: sql_file
description: 待验证的 SQL 文件路径步骤 2:实现逻辑 (verify_schema.py) 编写 Python 脚本作为 AI 的"手":
Python
python
import sys
import re
import subprocess
def check_naming_convention(sql_content):
# 强制检查表名是否以 tbl_ 开头 (模拟企业规范)
issues = []
if not re.search(r"CREATE TABLE \`?tbl_", sql_content, re.IGNORECASE):
issues.append("Error: Table names must start with 'tbl_'")
return issues
def dry_run(file_path):
# 模拟调用本地 DB CLI 进行语法检查
# 真实场景可替换为: subprocess.run(["mysql", "--dry-run", ...])
print(f"Executing dry-run for {file_path}...")
return True
if __name__ == "__main__":
file_path = sys.argv[1]
with open(file_path, 'r') as f:
content = f.read()
issues = check_naming_convention(content)
if issues:
print("\n".join(issues))
sys.exit(1) # 返回非 0 状态码,Claude 会捕获此错误并尝试自我修正
else:
dry_run(file_path)
print("Schema verification passed.")步骤 3:工作流闭环 当你在终端输入:"帮我创建一个用户表,包含 ID 和 Email 字段"时,工作流如下:
1.思考 (Think) : Claude 生成 create_users.sql。
2.规划 (Plan) : 识别到需要调用 verify_schema 工具。
3.执行 (Execute) : 运行 Python 脚本。
4.反馈 (Feedback) : 如果脚本报错(例如表名未加 tbl_),Claude 会读取 stderr,自动修改 SQL 文件 ,再次运行,直到通过验证。
这种"生成-验证-修正"的闭环,才是智能体工作流的精髓 。
四、 架构师视角:打造全能工作台
单一工具无法覆盖所有场景。高效的开发者应当建立"分层工具链":
●IDE (Cursor/VS Code) : 处理单文件、毫秒级的行间补全。
●Sidecar (Claude Code + 七牛云 Router) : 处理跨文件重构、脚本编写、环境配置等耗时任务,作为一个独立运行的"侧边终端"伙伴 。
通过环境变量实现了无感启动,通过 Router 保证了 99.9% 的连接稳定性,再配合自定义的 Skills 系统,我们实际上是在本地构建了一个私有化的初级研发中台 。
五、 结语
工具的价值在于人如何去驯服它。Claude Code 并不完美,但其开放的架构给了我们无限的定制空间 。
Next Step: 建议立即检查你的终端配置,将 API Base URL 指向七牛云 Router,并尝试编写你的第一个 Python Skill。当你看到 AI 自动修正了你未曾注意到的代码规范错误时,你会发现,AI 编程的乐趣才刚刚开始。