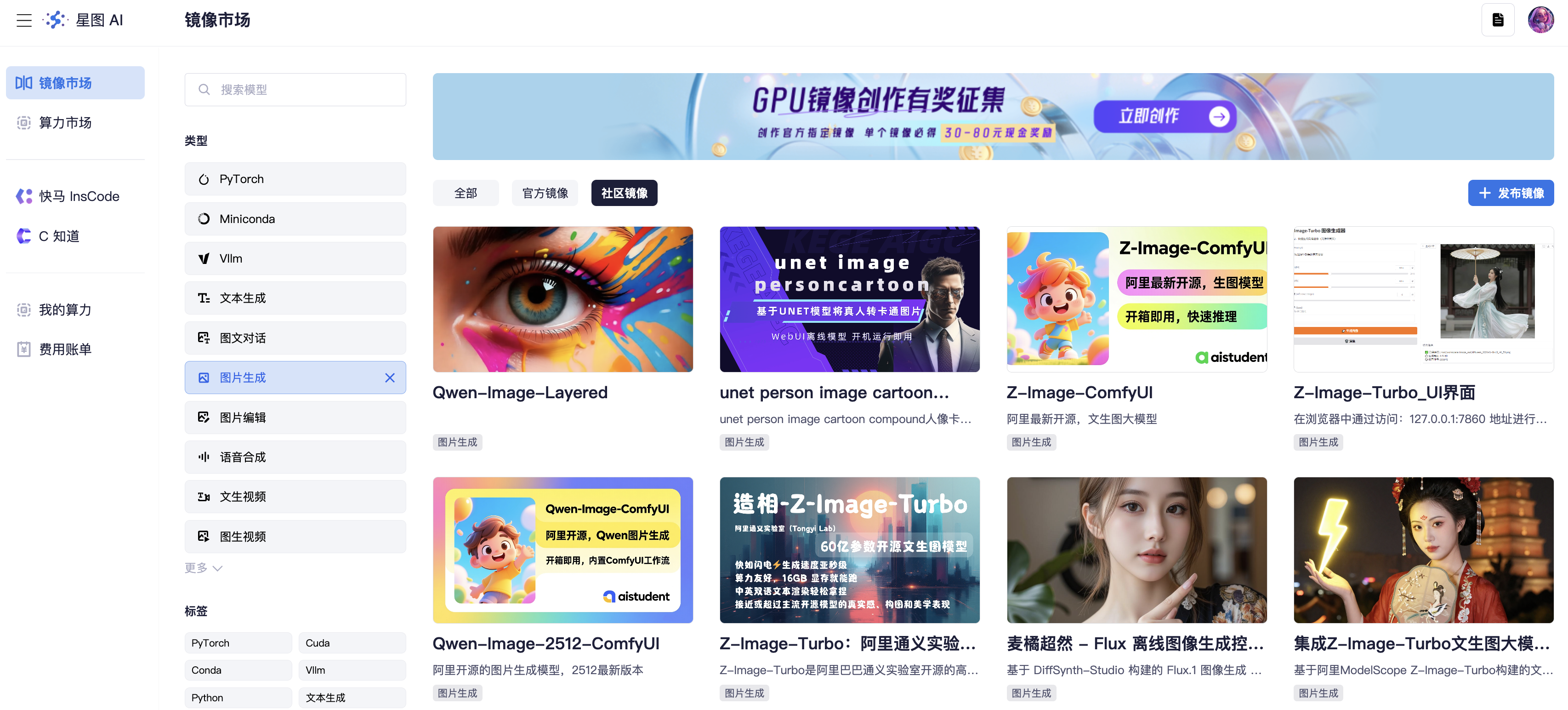
CSDN2026年1月1日开启了一个社区镜像征集活动,按要求完成官方指定的镜像任务创作,单个镜像最高可得80元奖励!那我肯定是要来凑凑热闹的😊。
上午和我的赛博好伙伴Gemini分析了一下创作规则后,便一起踏上了这趟镜像构建之旅(再次感谢Gemini的鼎力相助)。
接下来我将把和Gemini一起构建造相-Z-Image-Turbo(对应模型是Tongyi-MAI/Z-Image-Turbo)镜像的过程分享出来,供大家参考。
一、认领任务
官方明确列出了以下多个镜像创作任务,这些任务主要集中在 AI 领域,涵盖了图像生成、大语言模型、语音识别、语音合成和图像处理。
我们可以从以下列表中选择一个(或多个)进行制作,每个任务对应的模型和奖励金额如下:
官方指定镜像任务清单
| 镜像名称 | 对应模型 (ModelScope ID) | 奖励金额 (元) |
|---|---|---|
| 造相-Z-Image-Turbo | Tongyi-MAI/Z-Image-Turbo |
60 |
| ChatGLM-中英对话大模型-6B | ZhipuAI/ChatGLM-6B |
30 |
| Paraformer语音识别-中文-通用-16k-离线-large-长音频版 | iic/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch |
50 |
| SenseVoice多语言语音理解模型Small | iic/SenseVoiceSmall |
50 |
| IndexTTS-2 | IndexTeam/IndexTTS-2 |
50 |
| 麦橘超然 | MAILAND/majicflus_v1 |
50 |
| 图像人脸融合 | iic/cv_unet-image-face-fusion_damo |
60 |
| BSHM人像抠图 | iic/cv_unet-image-matting |
60 |
| DCT-Net人像卡通化 | iic/cv_unet_person-image-cartoon_compound-models |
60 |
| 语音合成-中文-多情感领域-16k-多发音人 | iic/speech_sambert-hifigan_tts_zh-cn_16k |
80 |
| GPEN人像修复增强 | iic/cv_gpen_image-portrait-enhancement |
60 |
| CosyVoice语音生成大模型2.0-0.5B | iic/CosyVoice2-0.5B |
50 |
| FSMN语音端点检测-中文-通用-16k | iic/speech_fsmn_vad_zh-cn-16k-common-pytorch |
50 |
| SeACoParaformer热词语音识别-中文-通用-16k-离线-large | iic/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch |
50 |
| 基于FST的中文ITN | thuduj12/fst_itn_zh |
40 |
| CAM++说话人确认-中文-通用-200k-Spkrs | iic/speech_campplus_sv_zh-cn_16k-common |
50 |
| emotion2vec+large语音情感识别基座模型large模型 | iic/emotion2vec_plus_large |
60 |
| Ngram语言模型-中文-ai-wesp-fst | iic/speech_ngram_lm_zh-cn-ai-wesp-fst |
50 |
| BSHM通用抠图 | iic/cv_unet_universal-matting |
60 |
插播一下Gemini贴心给的建议:
- 如果你有 GPU 资源 (如本地有显卡或使用云算力):建议挑战 "造相-Z-Image-Turbo" 或 "图像人脸融合",奖励最高(60元),且这类镜像的视觉效果好,容易通过审核。
- 如果你对 语音技术 感兴趣:SenseVoice 或 Paraformer 是目前非常火的开源模型,文档比较齐全。
- 如果你想快速上手 :ChatGLM-6B 虽然奖励只有30元,但社区教程极多,构建难度相对较低。
二、星图AI购买算力实例
确定好任务后,根据模型所需算力资源的大小,我们去算力市场租用GPU。

我GPU数量只选择了1个,然后听gemini的建议预先安装PyTorch 2.5。
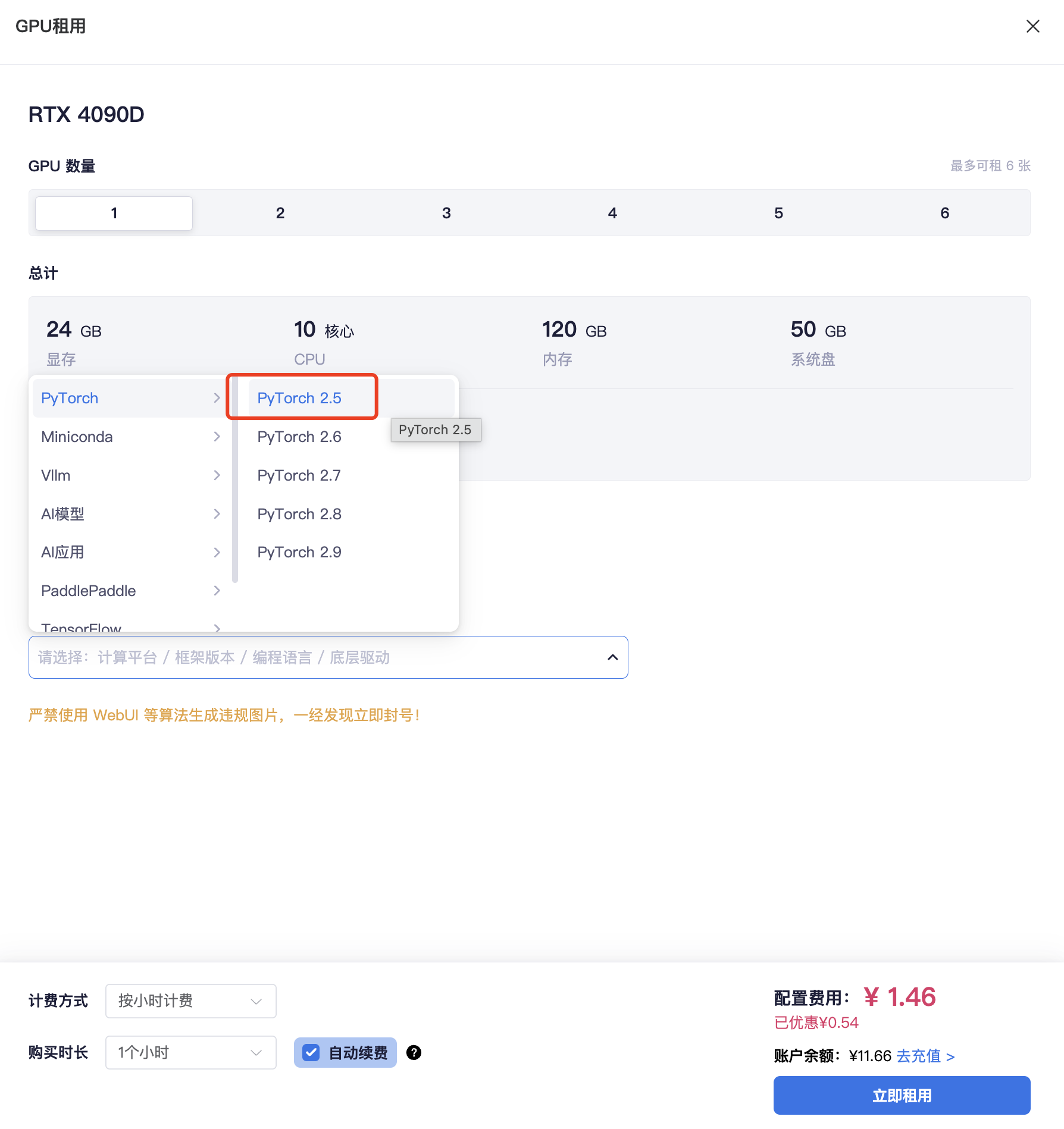
像我一样选择按时计费的朋友们需要注意,最好启用「自动续费」,因为模型下载都需要花费一定时间,万一没及时手动续费这个运行实例就会自动关机(或者你先把模型下载到数据盘也行,如果是放到系统盘,实例关机后数据会重置)。

但最后保存镜像的时候记得模型服务启动所需的一切代码、模型权重文件等都要放到系统盘!(更多详情请移步帮助文档)
三、下载模型
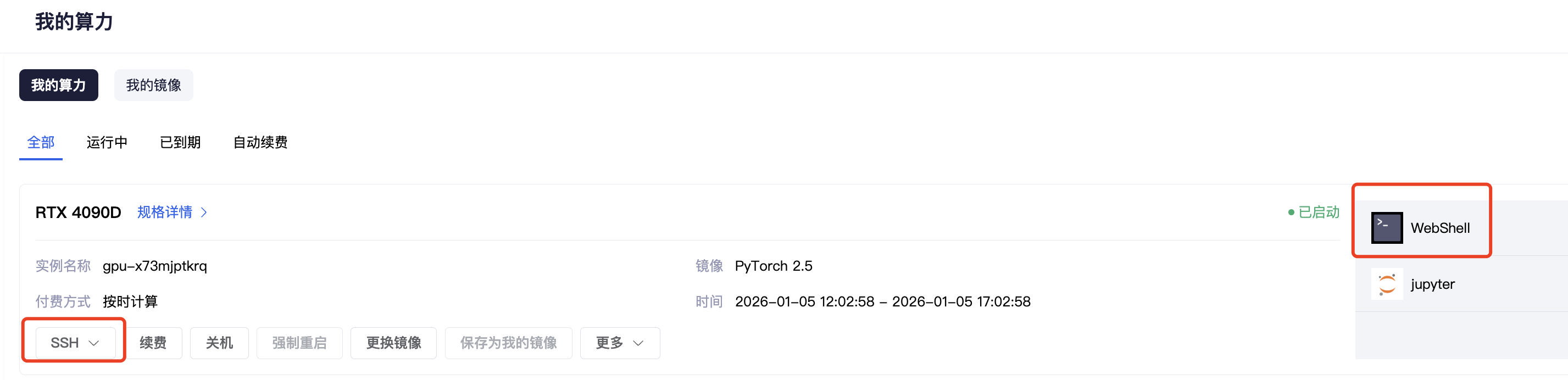
购买好算力后,可以在「我的算力」看到运行实例。
可以通过本地SSH或webshell的方式访问实例终端。
首先我们在根目录下创建一个文件夹。
bash
cd /
mkdir Z-Image-Turbo-service
cd Z-Image-Turbo-service接着把必要的库安装一下。
bash
pip install modelscope gradio diffusers transformers accelerate opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple然后我们执行这个命令,即通过SDK的方式将模型下载到当前目录下:
bash
# 下载模型到当前目录(数据盘)
python -c "from modelscope.hub.snapshot_download import snapshot_download; snapshot_download('Tongyi-MAI/Z-Image-Turbo', cache_dir='./model_weights')"如果你想不被中断&后台执行,可以加上nohup和&:
bash
nohup python -c "from modelscope.hub.snapshot_download import snapshot_download; snapshot_download('Tongyi-MAI/Z-Image-Turbo', cache_dir='./model_weights')" &模型下载的同时我们来完成基于该模型web服务的启动python代码。
四、app.py代码编写
以下是通义lab在huggingface上提供的官方参考代码,通过 diffusers库中的相关函数方法进行文生图模型的加载和推理。这里给大家分享一个经验,就是如果模型开源团队有提供官方参考代码的话,最好一开始就作为上下文信息提供给AI,否则直接让AI生成,很有可能代码会存在一些问题。(我就是经历了将AI生成的代码无脑复制,多次报错调整,最后把官方参考代码给到AI才fix~)
bash
import torch
from diffusers import ZImagePipeline
# 1. Load the pipeline
# Use bfloat16 for optimal performance on supported GPUs
pipe = ZImagePipeline.from_pretrained(
"Tongyi-MAI/Z-Image-Turbo",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=False,
)
pipe.to("cuda")
# [Optional] Attention Backend
# Diffusers uses SDPA by default. Switch to Flash Attention for better efficiency if supported:
# pipe.transformer.set_attention_backend("flash") # Enable Flash-Attention-2
# pipe.transformer.set_attention_backend("_flash_3") # Enable Flash-Attention-3
# [Optional] Model Compilation
# Compiling the DiT model accelerates inference, but the first run will take longer to compile.
# pipe.transformer.compile()
# [Optional] CPU Offloading
# Enable CPU offloading for memory-constrained devices.
# pipe.enable_model_cpu_offload()
prompt = "Young Chinese woman in red Hanfu, intricate embroidery. Impeccable makeup, red floral forehead pattern. Elaborate high bun, golden phoenix headdress, red flowers, beads. Holds round folding fan with lady, trees, bird. Neon lightning-bolt lamp (⚡️), bright yellow glow, above extended left palm. Soft-lit outdoor night background, silhouetted tiered pagoda (西安大雁塔), blurred colorful distant lights."
# 2. Generate Image
image = pipe(
prompt=prompt,
height=1024,
width=1024,
num_inference_steps=9, # This actually results in 8 DiT forwards
guidance_scale=0.0, # Guidance should be 0 for the Turbo models
generator=torch.Generator("cuda").manual_seed(42),
).images[0]
image.save("example.png")Gemini给出的app.py代码如下:
bash
import gradio as gr
import torch
# 注意:确保你的 diffusers 版本是最新的以支持 ZImagePipeline
from diffusers import ZImagePipeline
import os
# 1. 设定本地模型路径
model_path = "/Z-Image-Turbo-service/model_weights/Tongyi-MAI/Z-Image-Turbo"
print("🚀 正在加载 Z-Image-Turbo 原生 Diffusers 引擎 (bfloat16)...")
# 2. 初始化 Pipeline
# 使用 bfloat16 是 4090D 的最佳选择,既省显存又保精度
pipe = ZImagePipeline.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
use_safetensors=True
)
pipe.to("cuda")
# 3. 推理函数
def generate(prompt, steps, seed):
# 设置随机种子
generator = torch.Generator("cuda").manual_seed(int(seed))
# 执行生成
# Turbo 模型建议 guidance_scale=0.0,步数 4-9 步
image = pipe(
prompt=prompt,
num_inference_steps=int(steps),
guidance_scale=0.0,
generator=generator,
).images[0]
return image
# 4. 构建 Gradio WebUI
with gr.Blocks(title="CSDN 镜像赛 - 造相 Z-Image Turbo") as demo:
gr.Markdown("# 🎨 造相 Z-Image-Turbo 极速生成站")
gr.Markdown("基于最新的 Z-Image 架构,针对 4090D 深度优化。")
with gr.Row():
with gr.Column():
prompt = gr.Textbox(label="输入提示词 (Prompt)", placeholder="例如:一个穿着赛博朋克盔甲的熊猫...", lines=3)
with gr.Row():
steps = gr.Slider(minimum=1, maximum=20, value=9, step=1, label="采样步数 (Steps)")
seed = gr.Number(value=42, label="随机种子 (Seed)")
btn = gr.Button("开始生成", variant="primary")
with gr.Column():
output_img = gr.Image(label="生成结果")
btn.click(fn=generate, inputs=[prompt, steps, seed], outputs=output_img)
gr.Examples(
examples=[
["一个穿着宇航服的猫在月球上漫步,写实风格", 9, 42],
["Cyberpunk city street, neon lights, high detail, 8k", 9, 123]
],
inputs=[prompt, steps, seed]
)
if __name__ == "__main__":
# 监听 7860 端口
demo.launch(server_name="0.0.0.0", server_port=7860)我们把这段代码复制到 /Z-Image-Turbo-service 下,然后直接运行看看:
bash
# 可以先把需要用到的相关库升级一下
# 升级 diffusers 和 transformers 到最新版
pip install -U diffusers transformers accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple
# 运行 app.py 脚本,⚠️需确保模型已完成下载!!
python app.py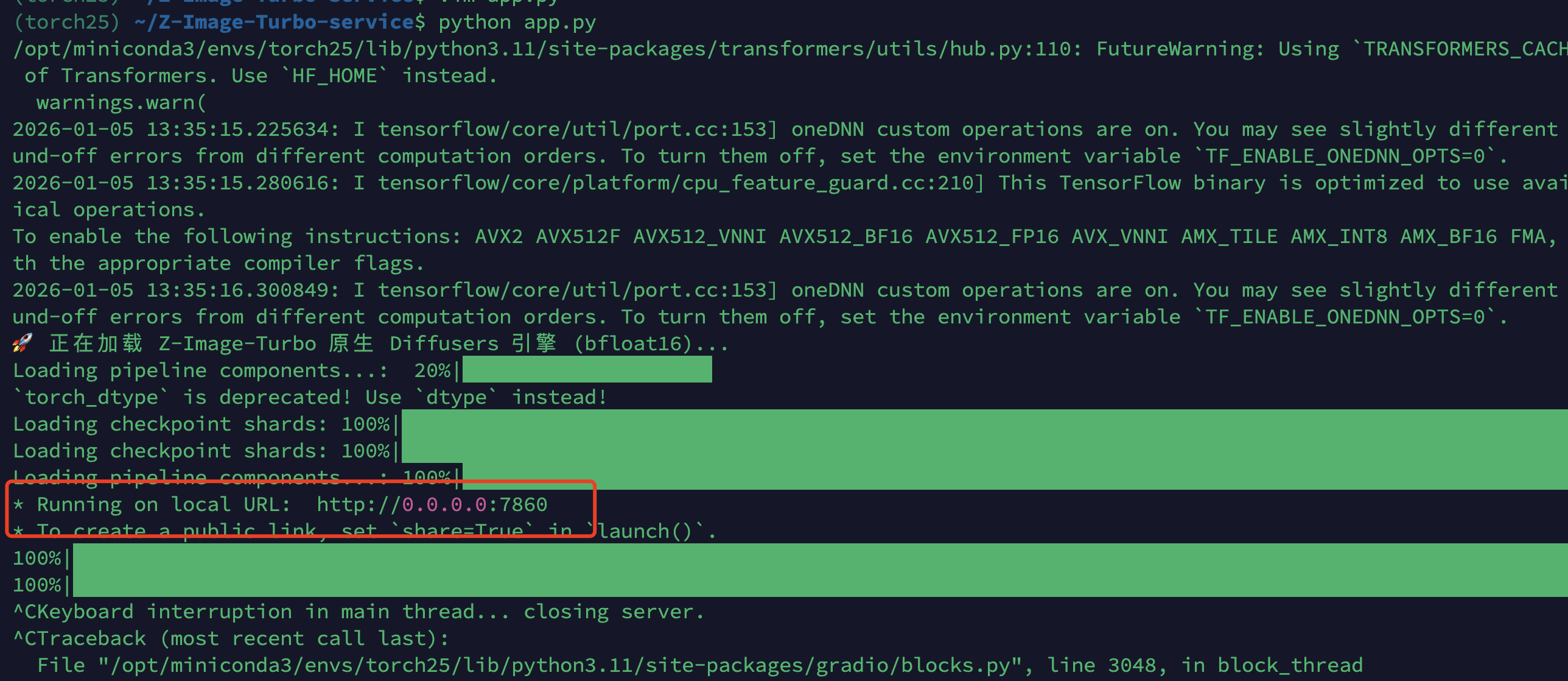
当观察到终端出现 * Running on local URL: http://0.0.0.0:7860 ,说明模型加载一切正常 🎉。
这个时候可以用SSH隧道的方式将实例的7860端口映射到本地7860。
bash
ssh -L 7860:127.0.0.1:7860 -p 31099 root@gpu-x73mjptkrq.ssh.gpu.csdn.net本地浏览器访问 http://127.0.0.1:7860,就可以看到「造相」的网页。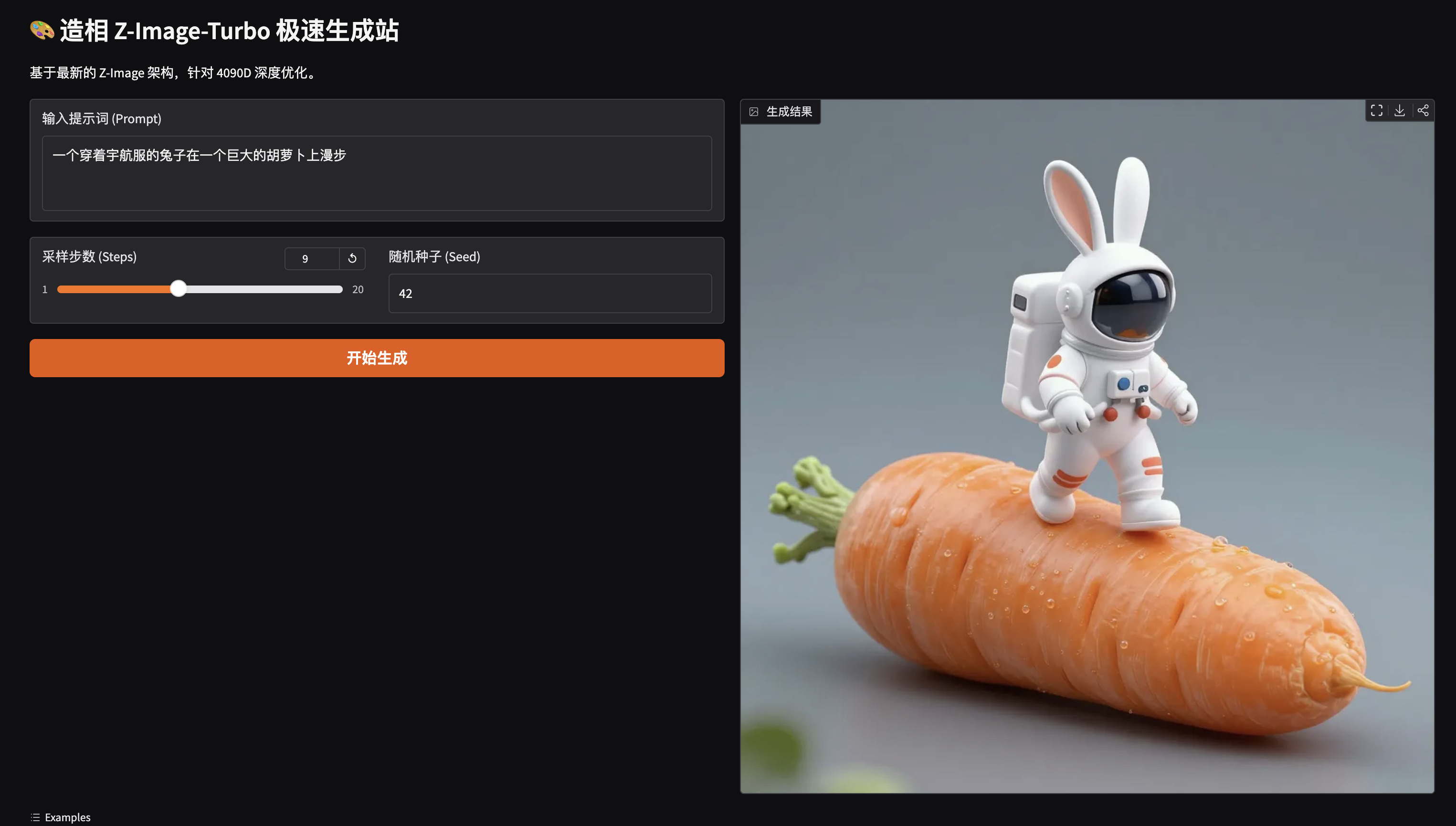
稍微试了下,速度确实特别快。
五、配置并启动 Supervisor
官方文档强烈推荐的步骤,也是为了可以更方便管理模型应用服务。
1. 安装 Supervisor
bash
apt-get update && apt-get install -y supervisor2. 写入配置文件
python路径可通过命令 which python 获取。
bash
cat <<EOF > /etc/supervisor/conf.d/z-image.conf
[program:z-image-turbo]
command=/opt/miniconda3/envs/torch25/bin/python /Z-Image-Turbo-service/app.py
directory=/Z-Image-Turbo-service
user=root
autostart=true
autorestart=true
redirect_stderr=true
stdout_logfile=/var/log/z-image-turbo.log
EOF3. 启动服务
bash
service supervisor start
# 或者如果 service 不行,用这个:
# /usr/bin/supervisord -c /etc/supervisor/supervisord.conf4. 检查状态
bash
supervisorctl status z-image-turbo显示为 RUNNING 状态则OK。

5. 检查日志
我们也可以通过对 z-image-turbo 服务产生日志的实时观察监控程序运行的状态。
bash
tail -f /var/log/z-image-turbo.log六、测试web服务
通过 supervisorctl 将服务启动后,保险起见可以再本地试用一下web服务,如果图片可以正常生成,那这个镜像创作的大部分工作就算完成了~
七、保存&发布镜像
接着将实例关机(如果不放心可以将所有数据先备份到数据盘),然后点击「保存为我的镜像」,需要提供一张镜像配图还有readme说明等。
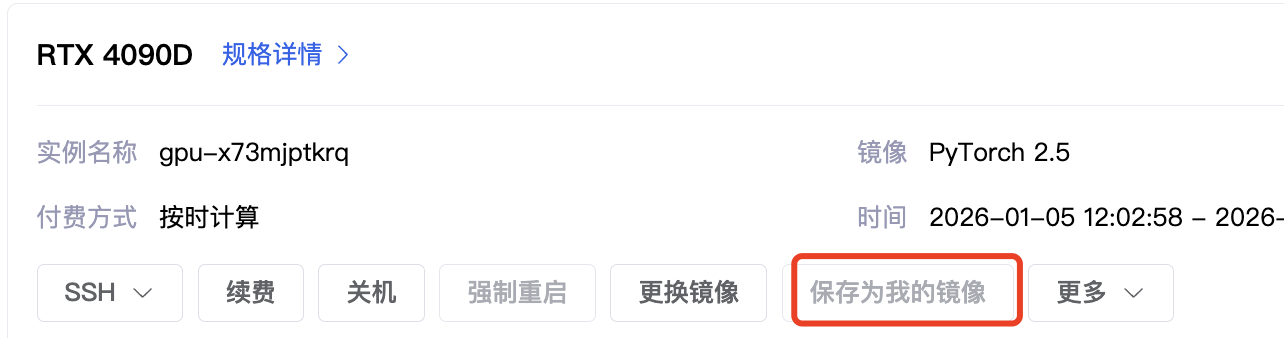
保存好后会先进入到推送状态,有些耗时,可能有个1小时。
推送完成后就可以发布了,需要被审核。
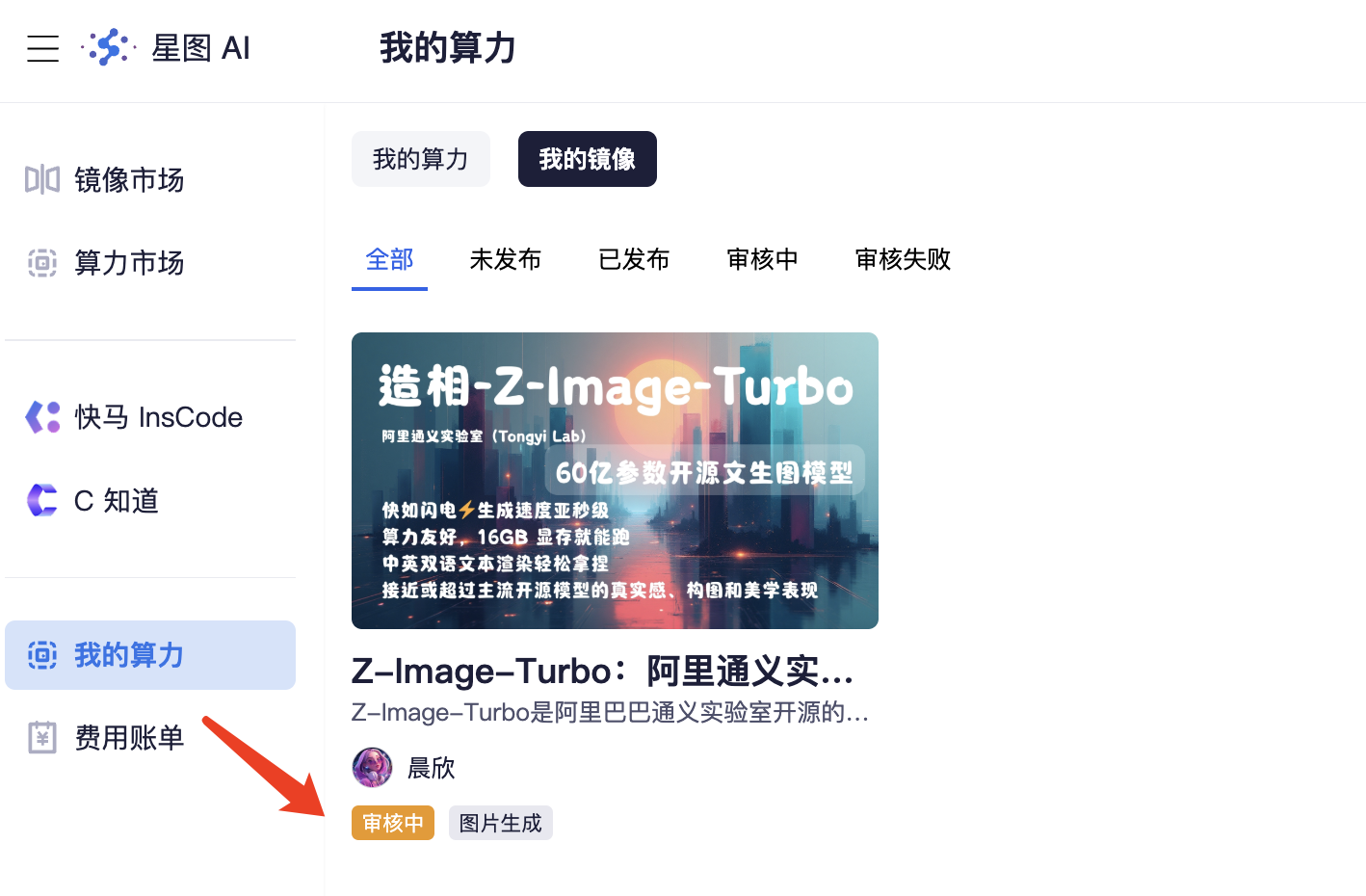
八、镜像市场查看
刚刚一看审核通过咯,有需要的朋友可以看看噢 👉 造相-Z-Image-Turbo 😊