1.异常、泛型、集合体系
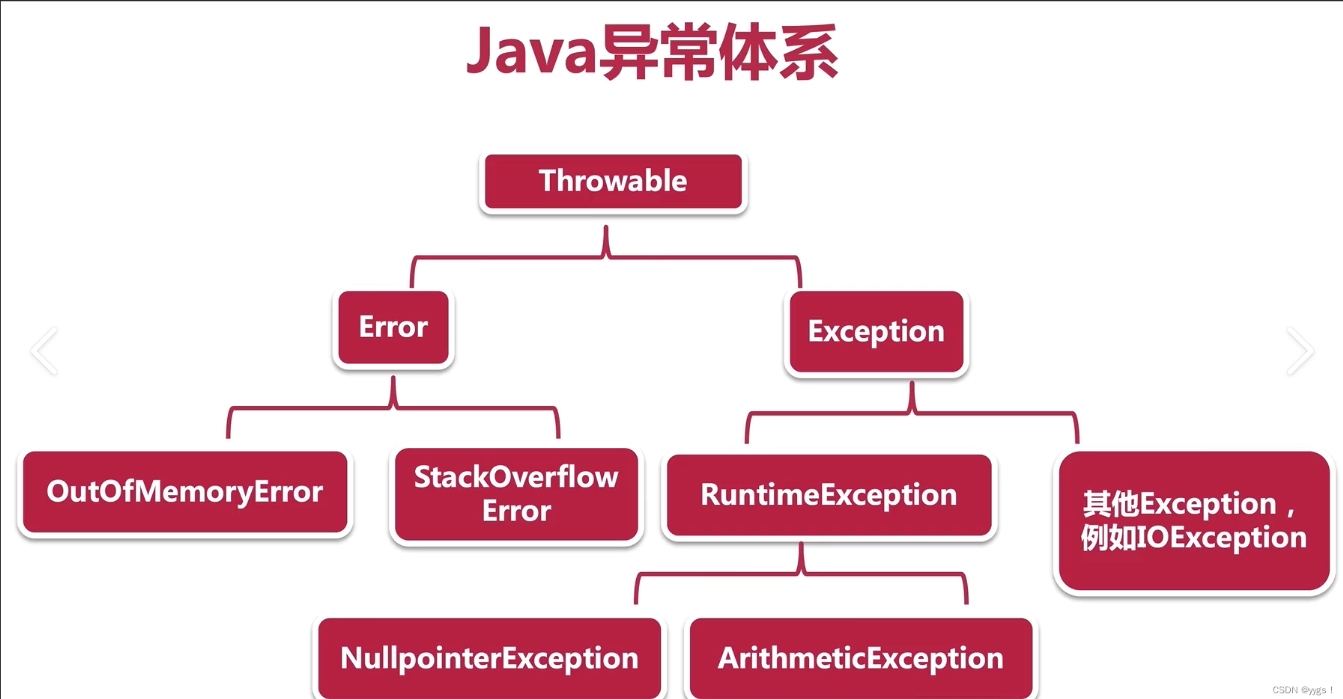
Error:错误 ,一般不用
Exception:
-
运行时异常: RuntimeException及其子类,编译阶段不会出现错误提醒,运行时出现的异常
-
编译时异常: 编译阶段就会出现的错误提醒。
异常的基本处理
throws 抛出异常
try catch 捕获异常
1.1异常的作用
- 定位程序的bug的关键信息
2.可以作为方法的一种特殊的返回值,以便通知上层调用者的,方法的执行问题
例子: 异常作为返回值返回
java
public static void main(String[] args){
System.out.println(" 程序开始");
try{
div(1,0);// 出现异常
}catch (Exception e){
e.printStackTrace();
System.out.println("程序执行失败(通知执行失败),但是继续执行");
}
System.out.println("程序结束");
}
//返回两个数的除数
public static int div(int a, int b) throws Exception{
if (b==0){
//异常作为返回值
throw new Exception("分母不能为0");
}
return a/b;
}
程序开始
程序执行失败,但是继续执行
程序结束
java.lang.Exception: 分母不能为01.2自定义异常
1自定义编译时异常
编译时异常需要抛出异常或者捕获异常
举例定义: a/b b=0 可能触发是运行时异常,下面只是举个例子,主要看如何自定义异常
java
/**
* 继承异常
* 重写Exception构造器
* 哪里需要就throw
*/
public class NewException extends Exception{
public NewException() {
}
public NewException(String message) {
super(message);
}
}
java
public static int div(int a, int b) throws NewException{
if (b==0){
//异常作为返回值
throw new NewException("分母不能为0");
}
return a/b;
}
NewException: 分母不能为0
at Main.div(Main.java:16)
at Main.main(Main.java:5)2.自定义运行时异常
跟上面一样
运行时异常 div方法中不写throws NewException 也不会出错
继承RuntimeException,重写构造器
小结: 一般使用自定义运行时异常, 不会将错误抛给其他人
1.3泛型
一般用E、T、K、V
定义类、接口、方法时,同时声明一个或者多个类型变量 <E>
1.泛型:类、方法、接口
称为泛型类、泛型接口、泛型方法 、他们统称为泛型
java
public class Generic<E>{}
java
public interface Generic<T>{void add(T b);}
java
public <T> void add(T b){}
public <T> T add(T a,T b){
return a;
}
java
public T add(T b){} //这个并不是泛型方法2.通配符
泛型上限 ? extend Car ? 必须是Car或者其子类
泛型下限? super Car ? 必须是Car 或者其父类
3.泛型支持的类型
集合和泛型都不支持基本数据类型int double......
原因
java
Java 泛型的实现依赖「类型擦除(Type Erasure)」------ 编译期泛型会被擦除为 object类型(或指定的上限类型),运行时 JVM 不感知泛型信息。
基本数据类型(int/long/byte 等)不是 object的子类他们一般使用包装类Interger、Double等
java
ArrayList<int> doubles = new ArrayList<>();3.自动装箱和自动拆箱
java
Integer.valueOf();
Integer.parseInt()2.集合框架、Stream流
2.1Collection单列集合(单个值)
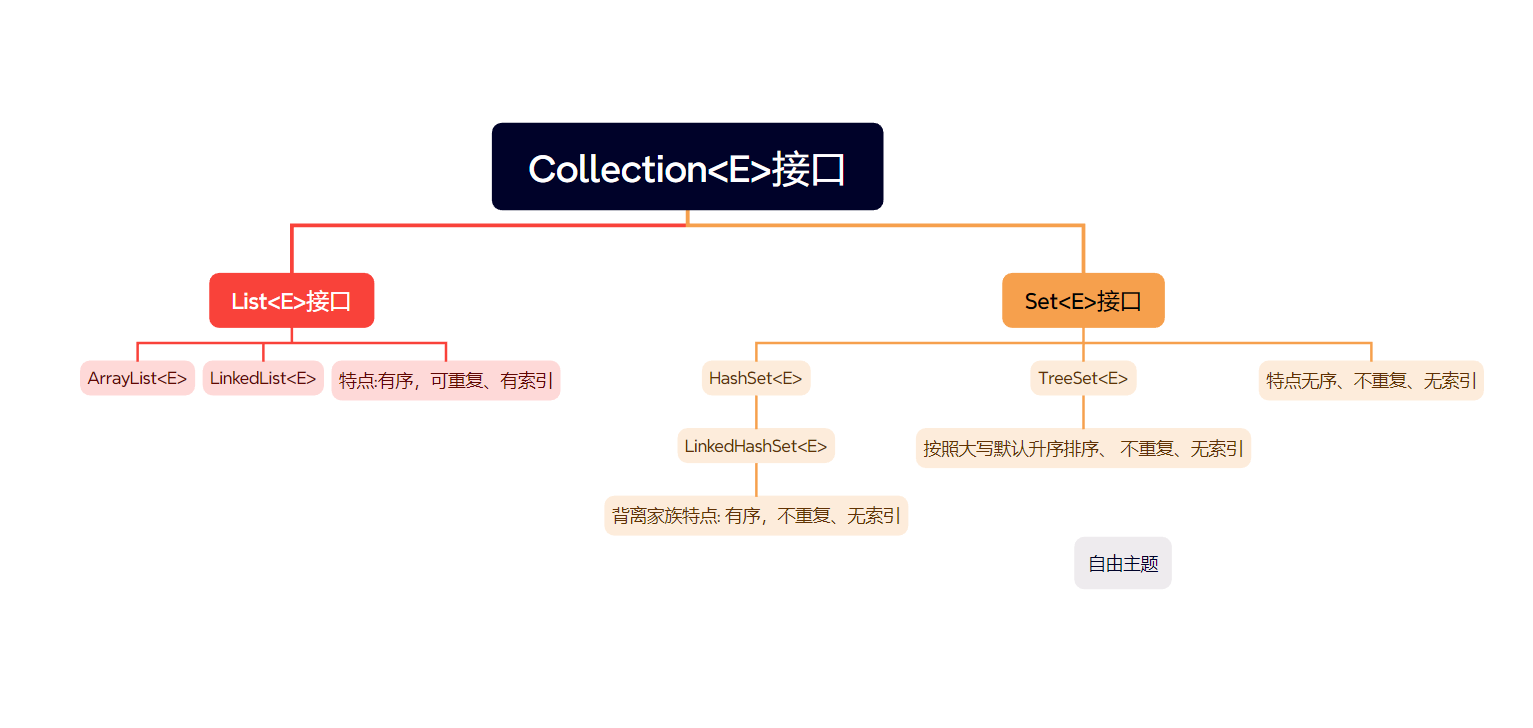
1.collection 中的方法
add remove clear(清空) isEmpty contains toArray(转换为数组) size(长度)
2.遍历集合的三种方式
1.迭代器iterator
java
ArrayList<String> strings = new ArrayList<>();
strings.add("hello");
strings.add("world");
strings.add("java");
hasNext() 这个方法底层时判断下标是否超过数组长度,所以作为条件
next() 其实是底层执行的方法,开始下标为0 // 不用管
java
//得到集合的迭代器
Iterator<String> iterator = strings.iterator();
while (iterator.hasNext()){
String s = iterator.next();
System.out.println(s);
}2.增强for循环
1.可以遍历数组或者集合
- 底层实现是迭代器
java
for (String a : strings){
System.out.println(a);
}3.forEach方法
Lambda JDK8开始
java
strings.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
//简化
strings.forEach(s-> System.out.println(s));
//简化
strings.forEach(System.out::println);4.遍历结合的区别
并发修改异常问题(遍历集合的同时又存在增删集合元素行为时可能出现业务异常)
结论: 增强for和foreach只适合查询,不适合查询时修改,迭代器适合查询时修改并且适合(有索引和无索引的集合),如果集合支持索引,可以使用for循环遍历每删除一个数据i--,或者倒着遍历
java
ArrayList<String> strings = new ArrayList<>();
strings.add("黑枸杞");
strings.add("山药");
strings.add("红枸杞");
strings.add("黄枸杞");
strings.add("狗尾巴草");
strings.add("茯苓");1.其中黄枸杞会漏删,此时可以在remove后添加i--解决
java
for (int i = 0 ;i<strings.size();i++){
String name = strings.get(i);
if (name.contains("枸杞")){
strings.remove(i);
}
}
strings.forEach(System.out::println);2.或者倒着遍历删除
java
for (int i = strings.size()-1;i>=0;i--){
String name = strings.get(i);
if (name.contains("枸杞")){
strings.remove(i);
}
} 3.但是遇到无索引的集合,没有办法使用索引遍历,此时需要使用迭代器, it.remove自己的删除方法进行数据的删除
java
Iterator<String> it = strings.iterator();
while (it.hasNext()){
if (it.next().contains("枸杞")){
it.remove();
}
}
strings.forEach(System.out::println);出现问题的原因是因为集合在删除数据时,后面的元素会补上来,导致数据索引位置发生变化。
3. List集合的特有方法
add(int index,E element) remove(int index) set(int index, E element) get(int index)
4. ArrayList和LinkedList的区别
底层原理不同
ArrayList底层原理是数组实现, LinkdeList是链表实现
ArraList特点:
1.根据索引查询速度快 -- > 数组有索引
2.增删数据效率低--> 数据需要前后移动
ArrayList扩容原理
首次扩容是第一次添加数据时,数组长度+10
后续扩容 原数组长度+ 长度右移1位 --> 1.5倍
LinkedList特点:
双链表实现,由结点组成,由数据以及下一个数据的地址组成
1.占用内存多
2.查询慢,查询只能从开头开始找,虽然有索引(伪索引)但是还是从第一个遍历
3.增删相对快,因为不需要挪动数据,对首尾元素增删速度快,因为是链表,
addFirst(E e) addLast(E e) getFirst() getLast() removeFirst() removeLast()
LinkedList可以制作栈(先进后出)或者队列(先进先出)
5.HashSet集合的底层原理
hash值 就是int类型的随机值,java中每个对象都有一个哈希值
JDK8之前 哈希表 = 数组+链表
JDK8之后 哈希表 = 数组+ 链表+红黑树
哈希值特点
1.同一个对象的哈希值是相同的
2.不同的对象,他们的哈希值大概率不相等,但也有可能相等(哈希碰撞)
为什么出现哈希碰撞 --> int 范围 -21亿到21亿 45亿对象
底层原理
1,默认长度为16 默认加载因子0.75 数组名talbe\[\]
2.使用元素的哈希值和数组的长度做运算,计算出存入的位置
3判断位置是否为null,如果null直接存入,如果不为null,equall比较,JDK8之前,新元素存入数组,占老元素位置,老元素挂下面,JDK8 开始,新元素直接挂老元素下面
4.JDK8开始 当链表长度超过8,且数组长度>=64时,自动将链表转成红黑树(小走左,大走右)
6.HashSet集合去重的机制
解决对象内容一样但是哈希值却不一样的问题。 以及哈希碰撞的问题
重写hasCode、equals方法
Java中的lombok已经重写,所以这个只存在手写类的情况。但是就算手写也可以使用ptg快速写出equals和hasCode方法,所以了解就行
大概长这样
java
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}7.LinkedHashSet集合
依旧使用数组、链表、红黑树实现
为什么会有序呢--> 因为每个元素都额外过了一个双链表的机制记录它前后元素的位置
8.TreeSet集合
按照从小到大的方式进行排列
对于数值类型,默认按照本身的大小
对于字符串类型,默认按照首字母的编号
对于自定义类型的对象,无法排序
1.所以要进行自定义对象排序
1.实现 Comparable 接口,重写其中的方法
2.TreeSet集合的构造器中自带一个Comparable参数
java
TreeSet<Student> students1 = new TreeSet<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.getAge() - o2.getAge();
}
});
//简化
TreeSet<Student> students1 = new TreeSet<>(Comparator.comparingInt(Student::getAge));但是有问题,当年龄相等时,它会student对象去掉,当然也有解决办法,再比较其他元素,实现Comparable自己重写比较规则,有点麻烦 。但是这个时候最好使用ArrayList+排序
java
Collections.sort(list, Comparator.comparingInt(Student::getAge));2.2Map 双列集合(键值对)
- 数据结构: 键值对
- 键不允许重复,但是值可以重复,键值一一对应
HashMap:无序,不重复、无索引(用的最多)
LinkedHashMap :有序,不重复,无索引
TreeMap:升序,不重复,无索引
put(key,value) size() clear() isEmpty() get(key) remove(key) containsKey(key) containsValue(value) Set<K> keySet()取出所有键 Collection<V> values()取出所有值
1. Map集合的遍历方式
- 使用键遍历集合
java
//使用键遍历集合
for(String key:hashMap.keySet()){
System.out.println(hashMap.get( key));
}2.使用键值对遍历集合
java
Set<Map.Entry<String, String>> entries = hashMap.entrySet();//[("1":"1"),("2","2"),......]
for (Map.Entry<String,String> entry: entries){
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}- Lamda表达式
java
hashMap.forEach(new BiConsumer<String, String>() {
@Override
public void accept(String s, String s2) {
System.out.print("键"+s);
System.out.print("值"+s2);
System.out.println(" ");
}
});
//可简化
hashMap.forEach((k,v)->{System.out.println("key"+k+"value"+v);});实现类的底层原理和Set集合一一对应,应为底层就是用的Map集合
HashSet其实是使用HashMap实现的,只是没有要值而已,所以底层原理和HashSet一样
LinkedHashSet 底层使用的是LinkedHashMap实现的
TreeSet底层使用的是TreeMap,TreeMap按照键升序
2.3Stream流
JDK8新增的一套API,可以用于操作集合或者数组的数据
优势: Stream流大量的结合Lamda的语法风格来编程,功能强大,性能高效,代码简介,可读性好(函数式编程Stream+Lamda)
1.获取Stream流
1.Collection中提供的方法
//Collection下的集合
Stream<String> stream = list.stream(); //new List()
//map集合
Stream<Map.Entry<String, String>> stream1 = map.entrySet().stream()2.数组的Stream流
Arrays.stream();3.Stream提供的方法
Stream.of()2.Stream流的中间方法
filter() 数据过滤
list.stream().filter(s->s.startsWith("张") && s.length() == 2).forEach(System.out::println);sorted() 升序
List<String> collect = list.stream().sorted().collect(Collectors.toList());
collect.forEach(System.out::println);sorted()指定规则排序
// sorted根据String中method compareTo排序 根据unicode码点排序
list.stream().sorted(String::compareTo).forEach(System.out::println); limilt()获取前几个元素
list.stream().limit(2).forEach(System.out::println); //打印前两个元素skip()跳过前几个元素
list.stream().skip(2).forEach(System.out::println);dustinct()去重
list.stream().distinct().forEach(System.out::println); map()元素加工
//stream流实现首字母大写
list.stream()
.filter(s->s != null && !s.isEmpty()) //首先确保substring()方法不会越界,或者空指针
.map(s ->{ return s.substring(0,1).toUpperCase(Locale.CHINA)+s.substring(1);}) //首字母大写,并且拼接后面的内容
.forEach(System.out::println);
}concat()合并流
//stream流实现首字母大写
ArrayList<String> s1 = new ArrayList<>(Arrays.asList("1","2","3"));
ArrayList<Integer> s2 = new ArrayList<>(Arrays.asList(1,2,4));
Stream<Object> concat = Stream.concat(s1.stream(),s2.stream());3.收集Stream流
1.forEach()
2.count() //返回总数
3.max()
Optional<String> max = list.stream().max((s1, s2) -> s1.length() - s2.length());
String s = max.get();
System.out.println(s);4.min()
- collect() 转换为集合
toList
toSet
toMap
toMap()中的两个参数是匿名内部类,实现apply方法,给k、v定义做键做值的规则
Map<String, String> collect = list.stream().collect(Collectors.toMap(k->k, v -> v));6.toArray() 转换为数组
4可变参 ...
print(String ...arr)2.4Collections方法
1.addAll(集合,数据)
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list,"1","2","3");2.顺序打乱
Collections.shuffle(list);3.升序
Collections.sort(list);4.自定义排序规则
Collections.sort(list, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.length()-o2.length();
}
});3.File、字符集、IO流框架
3.1File IO流
File对文件进行操作, IO流进行数据的读写
1.操作文件
创建文件对象
new File(''绝对路径/相对路径")
1.boolean exists()判断当前文件对象的路径是否存在文件/文件夹
2.boolean isFile()判断是否为文件
3,boolean isDiretory()判断是否为文件夹
- String name() 获取文件名(包括后缀)
5.long length()获取文件的大小
- long lastModified() 获取文件最后的修改时间
7.String getPath()获取文件相对路径
8.getAbsolutePath()绝对路径
9.boolean createNewFile()创建新文件
10.boolean mkdir()创建一级文件
11.boolean mkdirs()创建多级文件
12 boolean delete() 删除(删除之后回收站找不到)
- String\[\] list() 获取当前目录下一级文件名称
14.File\[\] listFiles() 获取当前目录下一级文件对象
3.2字符集
ASCII 美国信息交换标准代码 使用1个字节存储一个字符
GBK (国标) 汉字编码字符集 包含2万个汉字等字符 GBK中一个中文字符编码成2个字节的形式存储。 GBK兼容ASCII字符集
GBK 中二进制 汉字第一位为1 字符第一个为0来区分汉字和字符
每个国家都有自己的字符集,不利于国家之间的交流
Unicode字符集(统一码)是国际组织制定的,可以容纳世界上所有,文字、符号的字符集(4个字节表示一个字符)
UTF-8 Unicode字符集的一种编码方案,采取可变长编码方案
英文字符、数字 只占1个字节,汉字占 3个字节
前缀码 来区分使用多少个字节存储
1字节 0开头
2字节 110 10
3字节 1110 10 10
4字节 11110 10 10 10
3.4 字符集的编码和解码
String 中提供了对应的方法
编码
getBytes(内容);
getBytes(内容,字符集)
解码
new String(内容)
new String(内容 字符集)
3.5 IO流
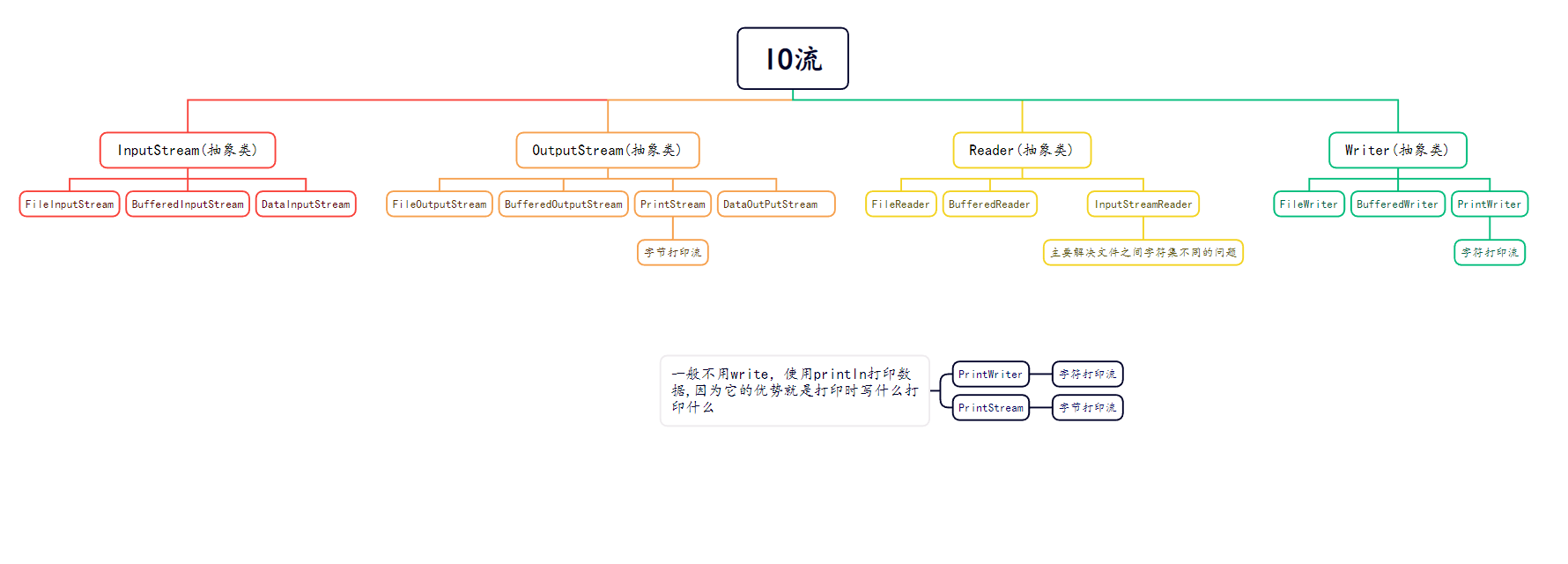
字节输入输出流,遇到中文可能会出现乱码,除非一次性读完文件的所有内容
字节流主要用来文件的复制,读取非文本内容
1.输入FileInputStream
获取输入流的两种方式 --> 构造器
1.相对路径 2. 文件对象
read() //单个字节读取
read(byte\[\] is) //字节数组读取
readAllBytes() //读取文件中的所有字节 (但是当文件特别大时,会出现内存溢出)
2.输出FileOutputStream
获取方式--> 构造器
-
文件对象 2. 相对路径 3. 文件对象,是否开启追加 4. 相对路径,是否开启追加
new FileOutputStream("day01-collection/src/1.txt", true)
write
记得关闭管道 close()
字符流
3.FileReader FileWriter
和字节流类似
flush() 刷新缓冲区,将缓冲区的数据写出去
close() 关闭包含缓冲区刷新
4.Buffered缓冲流
作用:包装字节流、字符流,加快读写速度
InputStream is = new FileInputStream("day01-collection/src/1.txt");//写相对路径
InputStream is_plus = new BufferedInputStream(is); //使用缓冲流包装,加快读取速度使用BufferedInputStream
//获取当前时间
long start = System.currentTimeMillis();
InputStream is = new FileInputStream("day01-collection/src/1.txt");//写相对路径
InputStream is_plus = new BufferedInputStream(is); //使用缓冲流包装,加快读取速度
byte[] arr =new byte[3];
int len;
while ((len = is.read(arr))!= -1){
System.out.print(new String(arr,0,len));
}
//获取结束时间
long end = System.currentTimeMillis();
System.out.println("运行时间:"+(end-start)+"ms");Buffered字符缓冲流新增方法
readLine()
String line;
while (( line= is_plus.readLine())!=null){
System.out.println(line);
}小练习 读取文件内容写到另一个文件,偷工减料版
FileReader fr = new FileReader("day01-collection\\src\\1.txt ");
BufferedReader br = new BufferedReader(fr);
FileWriter fw = new FileWriter("day01-collection\\src\\2.txt ");
BufferedWriter bw = new BufferedWriter(fw);
String line;
while ((line = br.readLine())!=null){
bw.write( line+"\n");
bw.flush(); //必须要刷新缓冲区,要不然写不进去
}5.其他流
1.InputStreamReader(字符输入流)
解决不同编码时,字符流读取文本内容乱码的问题
原理:先获取文件的原始字节流,再将其按真实的字符集编码转成字符输入流,这样字符输入流中的字节码就不乱码了
"好" --> [-27, -91, -67]
//第一步先转换为字节
//然后根据对应需要的字符集进行转换转换过程
假如a.txt是使用GBK编写,你的代码用的是UTF-8,InputStreamReader(r, "GBK"); 指定GBK转成字符流,然后用字符流输出数据,这样就不会乱码
InputStream r = new FileInputStream("D:\\a.txt");
Reader gbk = new InputStreamReader(r, "GBK");2.打印流
PrintStream 字节打印流 , PrintWriter 字符打印流
优势:写什么打印什么
一般不用其中的write()写数据,而是使用println()打印数据
//字节打印流
PrintStream ps = new PrintStream("day01-collection/src/1.txt");
//字符打印流, (如果想要追加内容,需要设置true,使用FileWriter,因为PrintWriter构造器中没有追加操作,包括上面也一样,想要追加就要new FileOutPutStream)
PrintWriter pw = new PrintWriter(new FileWriter("day01-collection/src/1.txt",true));
//写入(打印)什么数据直接写就行,很方便
ps.println(97);
ps.println("niah");
ps.println("你好");
ps.println("!");3. 特殊数据流
DataOutPutStream DataInputStream
应用场景:一般用在通信场景
允许把数据和其类型一并写出去
构造器 DataOutPutStream(OutPutStream out)
主要方法
writeByte(int v) 写byte类型数据
writeInt(int v)写int数据
write(Doublev) 写double数据
writerUTF(String str)写String类型数据
DataInputStream方法与上面相似
dis.available()>0 判断条件
但是如果数据类型多样,那么怎么发就要怎么接,不然会乱码
DataOutputStream ops = new DataOutputStream(new FileOutputStream("day01-collection/src/1.txt"));
ops.writeUTF("你好啊");
ops.writeUTF("fsefse");
ops.writeUTF("你好fsef啊");
ops.writeUTF("f");
ops.writeUTF("哈哈");
DataInputStream dis = new DataInputStream(new FileInputStream("day01-collection/src/1.txt"));
while (dis.available()>0){
System.out.println(dis.readUTF());
}6.IO框架
简介:预设写好的代码库和一组工具,简化加速开发过程
commons-io

列举一些方法
//FileUtils
FileUtils.copyFile(); //复制文件
FileUtils.copyDirectory(); //复制文件夹
FileUtils.deleteDirectory(); //删除文件夹
FileUtils.readFileToString() //读数据
FileUtils.writeStringToFile() //写数据
//IOUtils
IOUtils.copy() //复制文件
IOUtils.write();//写数据4.多线程
概述:多线程是指从软硬件上实现的多条执行流程的技术(多条线程由CPU负责调度执行)。
4.1线程创建
1.继承Thread类,重写run方法 start()
2.实现Runable接口 实现run方法,包装成Thread对象 start()
Runnable pt = new PrimeThread();
1.new Thread(pt).start();
//直接使用匿名内部类+lamda实现
2.new Thread(() -> System.out.println("子线程启动")).start();
//实现Runnable接口
public class PrimeThread implements Runnable{
@Override
public void run(){
for (int i = 0 ; i<20 ; i++) System.out.println("子线程工作中"+i);
}
}3.实现Collable接口,重写call方法,封装成FutureTask 线程交给Thread start启动,通过FutureTask对象的get方法获取返回值。
CallableThread ct = new CallableThread();
//FutureTask是任务对象,本质是实现了Runnable接口
FutureTask<String> ft = new FutureTask(ct);
//创建线程对象
Thread t = new Thread(ft);
t.start();
//获取结果
String s = ft.get();
System.out.println(s);
public class CallableThread implements Callable<String>{
@Override
public String call() throws Exception {
String str = "你好";
for (int i = 0; i < 10; i++){
str+="!";
}
return str;
}
}4.2线程的常用方法
run() 线程任务方法
start()
getName() 获取当前线程的名称
setName() 设置名称
static Thread currentThread() 获取当前执行的线程对象 --》 哪个线程在调用这个方法,就拿那个线程
static void sleep(long time) 休眠
final join() 让调用当前方法的线程先执行完
构造器
new Thread(String name)指定名称
new Thread(Runnable target)任务对象Runnable封装成线程对象
new Thread(Runnable target,String name) 额外指定名称
4.3线程安全
简述: 多个线程,同时操作同一个共享资源的时候,可能会出现业务安全问题
原因:
- 存在多个线程同时执行
- 同时访问一个共享资源
- 存在修改该共享资源
解决:
线程同步:让多个线程一次访问共享资源,避免出现线程安全问题。
1.同步代码块
作用: 把访问共享资源的核心代码上锁,以此保证线程安全
原理:每次只允许一个线程加锁后进入,执行完毕自动解锁,其他线程才可以进来执行
注意事项:对于当前同时执行的线程来说,同步锁必须是同一把(同一个对象),否则在会出bug
this,.class、常量一般不要使用 范围大,而且外部类可能获取锁
建议使用以下锁
private final Object INSTANCE_LOCK = new Object(); //实例锁
private static final Object GLOBAL_LOCK = new Object(); //全局锁
和实例锁一样,只是为每个独立资源又定义专属私有 final 锁 //专属资源
synchronized ("d") {//锁对象必须对于限制的线程唯一
System.out.println("共享资源的核心代码部分......");
}2.同步方法
作用:把访问共享资源的核心方法给上锁,保证线程安全
public synchronized void impMethod(){
System.out.println("共享资源部分");
}3.lock锁
Lock rtl = new ReentrantLock();
rtl.lock();
try{
System.out.println("共享资源");
}finally {
rtl.unlock();
}4.4线程池
简述:线程池就是一个可以复用线程的技术
解决的问题:创建新线程的开销很大,并且请求过多时,肯定会产生大量线程,严重影响系统的性能。
1.创建线程池
JDK5.0提供线程池接口ExecutorService
方式一: ExecutorService的实现类ThreadPoolExecutor创建一个线程池对象
BlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(3);
ThreadPoolExecutor pool = new ThreadPoolExecutor(
3, // 核心线程数
5, //最大线程数
2, //临时线程存活时间
TimeUnit.SECONDS, //存活时间单位
queue, //任务队列
Executors.defaultThreadFactory(), //线程工厂 任务对象转换为线程对象
new ThreadPoolExecutor.CallerRunsPolicy() //拒绝策略 失败之后的策略
);方式二:使用Excutors(线程池工具类)调用方法返回不同特点的线程池对象
但阿里开发手册等规范不推荐直接用 Executors 创建(易引发内存 / 性能问题)
Executors.newFixedThreadPool(5); //固定线程池
Executors.newSingleThreadExecutor(); //单个线程池
Executors.newCachedThreadPool(); //无限线程池
Executors.newScheduledThreadPool(5); //定时线程池
Executors.newSingleThreadScheduledExecutor(); //单个定时线程池2.什么时候创建临时线程
核心线程都在忙,任务队列也慢了,并且还可以创建临时线程,才会创建
3. 拒绝策略
当线程池忙不过来时,就会触发拒绝策略
new ThreadPoolExecutor.AbortPolicy() 默认,抛出异常,丢弃任务 new ThreadPoolExecutor.DiscardPolicy() 丢弃任务,不抛出异常 不推荐
new ThreadPoolExecutor.DiscardOldestPolicy() 抛弃任务队列中执行时间最长的任务,然后把当前任务加入到队列中
new ThreadPoolExecutor.CallerRunsPolicy() 主线程调用跳过线程池4.处理任务
简单创建一个线程池
ExecutorService es = Executors.newFixedThreadPool(5);//固定线程池运行Runable任务对象
es.execute(()-> System.out.println("任务"));运行Callable任务对象
Future<String> submit = es.submit(new CallableThread());
System.out.println(submit.get()); //获取结果一般根据IO密集型和CPU密集型判断核心线程数的数目--> 搜ai
Runtime.getRuntime().availableProcessors(); 获取当前CPU核数5.并发和并行
并发:同一时间段内,多个任务交替进行(CPU 切换执行),任务之间 "你停我干、我停你干"。
并行:同一时刻,多个任务真正同时执行(多 CPU 核心 / 多处理器分别执行不同任务)
5.网络编程、综合项目
可以让设备中的程序与网络上其他设备中的程序进行数据交互的技术(网络通信)1.
1.基本的通信架构
C/S架构 客户端/服务端 BS架构 浏览器/服务端
java.net.* 下提供了网络编程的方案
2.网络编程三要素
Ip(设备在网络中的标识) 端口(应用程序在网络中的标识) 协议
3.通信协议
计算机网络中,连接和通信数据的规则称为网络通信
UDP协议
用户数据报协议(User Datagram Protocol)
UDP是面向无连接,不可靠的通信协议
不事先建立连接,数据包含,自己的IP、端口、目的地IP、端口、数据(限制在64KB内)发送方不管对方在不在线,数据中间丢失也不管,如果接收方收到数据也不返回确认,故不可靠
应用场景: 视频直播,语音通话
快速入门java java.net.DataGramSocket 这个类下
发送端
//创建UDP通信中的内容载体
DatagramSocket socket = new DatagramSocket();
//创建发送载体
/**
* 1. 数据内容
* 2. 发送的数据长度
* 3. 发送的地址
* 4. 端口号
*/
DatagramPacket packet = new DatagramPacket("hello".getBytes(),"hello".getBytes().length,
InetAddress.getLocalHost(),8080);
//发送数据
socket.send(packet);
接受端
//创建接受数据载体
DatagramSocket socket = new DatagramSocket(8080);
//UDP最大可接受64kb大小的内容
byte[] bytes = new byte[1024 * 64];
DatagramPacket packet = new DatagramPacket(bytes, bytes.length);
//接受数据
socket.receive(packet);
//获取接受的数据长度
int length = packet.getLength();
//查看数据是否收到
String s = new String(bytes,0,length);
System.out.println("服务端收到的数据是"+s);
//获取对方的IP地址和端口
System.out.println("对方的IP"+packet.getAddress().getHostAddress()+"对方的端口"+ packet.getPort());;TCP协议
面向连接、可靠通信
步骤: 三次握手建立连接(确保双方通信),传输数据进行确认,四次挥手断开连接
应用场景:网页,文件下载,支付
缺点:通信效率不高,比较安全
实现类:java.net.socket 快速入门
发送端
/**
* 创建TCP通信发送端
*/
System.out.println("发送端启动......");
//创建与接受端的连接
Socket socket = new Socket("127.0.0.1", 9999);
//获取发送数据的输出流
OutputStream os = socket.getOutputStream();
//包装成其他流,提高性能 建议使用特殊流
DataOutputStream dos = new DataOutputStream(os);
//发送数据
dos.writeUTF("Hello, My world");
dos.writeLong(18133800175L);
//一般在try catch finally 中进行关闭
dos.close();
System.out.println("发送端任务结束,关闭任务进程");
接受端
//创建接收端
ServerSocket ss = new ServerSocket(9999);
//进行尝试与发送端进行连接操作
Socket accept = ss.accept();
//获取接收端的输入流
InputStream is = accept.getInputStream();
//进行数据包装并输出内容
DataInputStream dis = new DataInputStream(is);
System.out.println("获取的内容"+dis.readUTF()+"\n"+dis.readLong());
InetSocketAddress isa = (InetSocketAddress) accept.getRemoteSocketAddress();
System.out.println("对方的IP和端口"+isa.getAddress().getHostAddress()+ isa.getPort() );
//关闭进程
ss.close();多发多收的时候记得刷新数据 flush()
TCP通信中多个客户端发送消息 快速案例
Tcp_Client
//客户端
Socket s =null;
DataOutputStream dos= null;
try {
s = new Socket("127.0.0.1", 9999);
OutputStream os = s.getOutputStream();
dos = new DataOutputStream(os);
//输入内容
Scanner sc = new Scanner(System.in);
while ( true){
System.out.println("请输入内容:");
String content = sc.nextLine();
if("exit".equals(content)){
dos.close();
s.close();
break;
}
dos.writeUTF(content);
dos.flush();//刷新管道中的内容
}
} catch (IOException e) {
throw new RuntimeException(e);
}finally {
try {
dos.close();
s.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
Tcp_Server
//服务端设置可以接受多个客户端的消息
ServerSocket ss = null;
try {
ss= new ServerSocket(9999);
//创建多线程可以获取对应的客户端发送的消息
while (true){
//创建读取客户端信息的线程类
Socket s = ss.accept();
Tcp_Reader tcpReader = new Tcp_Reader(s);
//线程启动
tcpReader.start();
}
} catch (IOException e) {
throw new RuntimeException(e);
}finally {
try {
ss.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
Tcp_Reader
public class Tcp_Reader extends Thread{
private Socket a;
public Tcp_Reader(Socket a) {
this.a = a;
}
//创建多线程类,实现客户端信息的分开处理
@Override
public void run() {
DataInputStream dis = null;
InputStream is = null;
try {
is = a.getInputStream();
dis = new DataInputStream(is);
InetSocketAddress isa= (InetSocketAddress) a.getRemoteSocketAddress();
while (true) {
System.out.println(isa.getHostString()+"端口"+isa.getPort()+":"+dis.readUTF());
}
} catch (IOException e) {
throw new RuntimeException(e);
}finally {
try {
dis.close();
is.close();
a.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
}B/S架构的原理
4.Java高级技术
1.测试单元Junit
导包测试方法,检验项目是否有错误
2.反射
概念: 加载类,并允许以编程的方式解剖类中的各种成分(成员变量、方法、构造器)
1. 反射具体学习的内容
1、反射第一步,加载类,获取类的字节码:class对象
2.、类的构造器 Constructor 对象
3、类的成员变量; Filed 对象
4,获取类的成员方法 Method对象
2.获取Class对象的三种方式
1.类名.class
2.调用Class提供的方法 public static Class forName(String package)
3.Object 提供的方法 public Class getClass() Class c3 = 对象.getClass();
//1. .class
Class tcpReader = Tcp_Reader.class ;
System.out.println(tcpReader); //一般是全类名 包名.类名
//2. Class
Class aClass = Class.forName("Tcp_Reader"); //写全类名
System.out.println(aClass);
//3. Object 的方法
Class aClass1 = "Tcp_Reader".getClass();3.获取类的信息
//获取类的类名
Class stu = Student.class;
stu.getName(); //全类名
stu.getSimpleName();//类名
//获取类的构造器
stu.getConstructor()//获取单个public构造器
stu.getConstructors() // 获取所有public构造器
stu.getDeclaredConstructor()//获取单个构造器包括私有的
stu.getDeclaredConstructors()//获取所有构造器
//获取类的成员变量
stu.getField()
stu.getFields()
stu.getDeclaredField()
stu.getDeclaredFields()
//获取类的成员方法
stu.getMethod()
stu.getMethods()
stu.getDeclaredMethod()
stu.getDeclaredMethods() 1.1构造器-->创建对象
//创建对象获取类名
Class stu = Student.class;
//使用构造器创建对象
Constructor dc = stu.getDeclaredConstructor();
Object o = dc.newInstance();
System.out.println(o);
//获取私有构造器创建对象
Constructor pdc = stu.getDeclaredConstructor(String.class, int.class);
//绕过访问权限
pdc.setAccessible(true);
//创建对象
Object o1 = pdc.newInstance("张三", 18);
System.out.println(o1);1.2成员变量--> 取值、赋值
//创建对象获取类名
Class stu = Student.class;
//创建对象才能取值或者赋值
Student s = new Student("张三",99);
//获取成员变量的
Field name = stu.getDeclaredField("name");
//绕过权限
name.setAccessible(true);
//设置s对象的name属性的值为李四
name.set(s,"李四");
//取值
Object o = name.get(s);
System.out.println("取值"+o);
System.out.println("更改变量的值后的对象"+s);1.3成员方法--> 调用方法
//创建对象获取类名
Class stu = Student.class;
//创建对象才能调用他的成员方法
Student student = new Student("张三", 18);
Method method = stu.getDeclaredMethod("printStudent", Student.class);
//绕过权限
method.setAccessible(true);
//方法执行 对象,方法参数 返回值 invoke
Object invoke = method.invoke(student, student);
System.out.println(invoke);
//补充Student类中的方法定义
private String printStudent(Student s) {
System.out.println("姓名:" + s.name + ",年龄:" + s.age);
return "姓名:" + s.name + ",年龄:" + s.age;
}1.4应用场景
1.基本作用: 可以得到一个类的全部成分然后操作
-
可以破坏封装性
-
可以绕过泛型的约束
反射能 "偷偷往泛型集合里塞错类型的值",但取出来用的时候一定会 "露馅"------ 这也是 Java 泛型设计的初衷:编译期保证类型安全,运行时哪怕用反射绕开,也会付出异常的代价。
作用:不是跳过约束,而是解析泛型的实际类型,实现类型安全的动态处理。
import java.lang.reflect.ParameterizedType;
import java.lang.reflect.Type;
import java.util.ArrayList;
import java.util.List;
public class GenericTypeDemo {
// 定义一个带泛型的父类
static class BaseDao<T> {}
// 子类指定泛型为Student
static class StudentDao extends BaseDao<Student> {}
public static void main(String[] args) {
// 反射获取子类的泛型实际类型(Student)
Type genericSuperclass = StudentDao.class.getGenericSuperclass(); //BaseDao<Student>
ParameterizedType parameterizedType = (ParameterizedType) genericSuperclass;//<Student>
Type[] actualTypeArguments = parameterizedType.getActualTypeArguments();//["Student的全类名"]
System.out.println("泛型实际类型:" + actualTypeArguments[0]); // 输出:class com.example.Student
}
}4. 注解
注解概述:java中的特殊标记
作用:让其他程序根据注解信息来决定怎么执行该程序
注解反编译之后,其实注解下的属性是一个个的抽象方法
普通注解:定义在代码元素上的注解
元注解;定义在普通注解上,使用元注解约束它的规则
4.1普通注解
/**
* 自定义注解
*/
public @interface A {
public String name(); //无默认值的属性
public int age() default 88; //有默认值的属性
}特殊属性value
当注解中只有一个变量value时,或者其他属性有默认值时,使用注解的地方可以直接写值
1.仅有一个value属性
/**
* 自定义注解
*/
public @interface A {
public String value();
}
2.其他属性有默认值时
/**
* 自定义注解
*/
public @interface A {
public int age() default 22;
public String value();
}
//使用时可以简化名称,直接写值
@A("delete")4.2元注解
@Target(ElementType.METHOD) //约束注解的位置
TYPE 类、接口
FIELD 成员变量
METHOD 成员方法
PARAMETER 方法参数
CONSTRUCTOR 构造器
LOCAL_VARIABLE 局部变量
@Retention(RetentionPolicy.RUNTIME) //声明注解的存活周期
SOURCE 只作用在源码阶段,字节码中不存在
CLASS(默认值) 保留字节码文件阶段,运行阶段不存在
RUMTIME(开发常用) 一直保留到运行阶段4.3注解的解析
判断类、方法、成员变量上是否存在注解,并把注解的内容解析出来
AnnotatedElement接口中提供了解析注解的方法
解析过程 --> 通过反射
1、获取注解所在类的字节码对象
2、根据注解所在的位置,根据反射获取对应的类、方法、构造器等等
3、可以判断类上是否有指定类型的注解
4、通过反射获取的类、方法、 构造器等等获取注解
5、通过注解获取对应的属性
Class<test> a = test.class;
//如果是方法上的注解
Method method = a.getMethod("demo1");
boolean annotationPresent1 = method.isAnnotationPresent(A.class);
System.out.println(annotationPresent1);
/**
* 1.判断a上是否有A.class类型的注解
* 2.获取A.class类型的注解
* 3.输出注解下的属性
*/
boolean annotationPresent = a.isAnnotationPresent(A.class);
System.out.println(annotationPresent);
//获取注解
A annotation = a.getAnnotation(A.class);
int age = annotation.age();
String value = annotation.value();
System.out.println(age+"-------"+value);4.4注解的作用和应用场景
作用:对程序做特殊标记,进行对应的处理
例子:日志打印制作
public static void main(String[] args) throws Exception {
StudentService studentService = new Main().new StudentService();
LogUtil logUtil = new Main().new LogUtil();
logUtil.invokeWithLog(studentService, "getStudent");
}
// 自定义注解:标记需要打印日志的方法
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME) // 必须设为RUNTIME,反射才能读取
public @interface Log {
String value() default "执行方法";
}
// 使用注解
public class StudentService {
@Log("查询学生")
public void getStudent() {
System.out.println("查询学生逻辑");
}
}
// 反射解析注解,自动打印日志
public class LogUtil {
public static void invokeWithLog(Object obj, String methodName) throws Exception {
Method method = obj.getClass().getMethod(methodName);
// 读取注解
if (method.isAnnotationPresent(Log.class)) {
Log log = method.getAnnotation(Log.class);
LocalDateTime now = LocalDateTime.now();
System.out.println("时间"+now+"::"+"["+log.value()+"]" + ":开始执行"); // 打印"查询学生:开始执行"
}
method.invoke(obj); // 执行方法
}
}5.动态代理
java.long.reflet.proxy类提供了为对象创建代理的方法;
public class Main {
public static void main(String[] args) throws Exception {
//创建明星对象
Star s = new Star("蜡笔小新");
//创建代理对象
StarService proxy = create_proxy(s);
//代理调用
proxy.sing();
proxy.dance();
}
//代理
public static StarService create_proxy(Star s){
/**
* 参数
* 1.指定那个类加载器去加载生成的代理类
* 2.指定代理类需要实现的接口
* 3.用于指定代理对象需要如何去代理(代理要做的事情)
*/
StarService starService = (StarService) Proxy.newProxyInstance(Main.class.getClassLoader(), s.getClass().getInterfaces(), new InvocationHandler() {
/**
* 参数
* 1.代理对象
* 2.代理对象正在执行的方法
* 3.正在执行的方法参数
*/
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (method.getName().equals("sing")){
System.out.println("代理准备前置工作,并且收钱100万");
}else if (method.getName().equals("dance")){
System.out.println("代理准备前置工作,准备收钱20万");
}
return method.invoke(s, args);
}
});
return starService;
}
}
/**
* 代理接口
*/
public interface StarService {
public void sing();
public void dance();
}
//被代理的对象
public class Star implements StarService{
private String star_name;
public Star(String star_name) {
this.star_name = star_name;
}
@Override
public void sing() {
System.out.println(this.star_name+"唱歌");
}
@Override
public void dance() {
System.out.println(this.star_name+"跳舞");
}
}小练习:有100名囚犯,每个囚犯有随机编号(0-200)按顺序排列(1-100)每次枪毙奇数位置的囚犯,求最后剩下的囚犯编号,以及第一次所在的位置
import lombok.AllArgsConstructor;
import lombok.Data;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Random;
import java.util.stream.IntStream;
public class Main {
public static void main(String[] args) {
long star = System.currentTimeMillis();
List<Integer> randomId = Main.getRandomId();
ArrayList<Prisoner> prisoners = new ArrayList<>();
for (int i = 0; i < 100; i++){
Prisoner prisoner = new Prisoner(randomId.get(i),i+1);
prisoners.add(prisoner);
}
while (prisoners.size()!=1){
for (int i = prisoners.size()-1; i >= 0; i--){
if((i+1)%2!=0){
prisoners.remove(i);
}
}
}
long end = System.currentTimeMillis();
System.out.println("耗时:" + (end - star)/1000.0+"秒");
System.out.println(prisoners);
}
//随机数获取
public static List<Integer> getRandomId(){
// 1. 初始化集合:生成100个0-199的随机整数
ArrayList<Integer> list = new ArrayList<>();
Random random = new Random(); // 优化:只创建一个Random实例,避免频繁新建
while (list.size() < 100) {
list.add(random.nextInt(200));
}
return list;
}
//创建囚犯对象
@Data
@AllArgsConstructor
public static class Prisoner{
private Integer code;
private Integer firstLocation;
}
}