一、认识解析器 & SQL解析器
1.1、什么是解析器?
解析器是计算机科学和编程语言领域中至关重要的工具,其核心作用是将人类可理解的 "形式化语言"(如代码、数据格式、表达式等)转换为机器可处理的结构,从而实现信息的解析、验证和后续处理。我们需要解析器的原因可以从多个维度来理解。
人类使用的语言(无论是编程语言如 Python、数据格式如 JSON,还是查询语句如 SQL)是结构化的字符串,但机器无法直接理解这种字符串的逻辑含义。
-
例如,程序员写的
x = (a + b) * 3是一串字符,但机器需要知道这是 "先算a+b,再乘以 3,最后赋值给 x" 的运算逻辑,解析器充当这个角色,解析为一个语法树,再按照指定的规则一步步来进行运算。// 解析器 扫描解析方程 x = (a + b) * 3 得到的语法树AST
[=] / \ [x] [*] / \ [+] [3] / \ [a] [b]解释执行步骤:
1、从根节点 = 开始,表示这是一个赋值操作。
2、左子树 x 是赋值目标,右子树 * 是计算内容。
3、计算 * 时,先计算左子树 +(a + b),再乘以右子树 3。
4、最后将结果赋值给 x。 -
例如,程序员写的编程语言,如C语言、Java语言等,这些语言都有特定的语法规则,通过解析器来将代码转为AST语法规则树,再进行编译字节码、机器码来执行。
// 解析器 扫描解析 Java代码 if (x > 0) { y = 10; } 得到的语法树AST
[if]
/
[>] [block]
/ \
[x] [0] [=]
/
[y] [10]解析执行步骤:
1、根节点 if 表示条件判断。
2、先计算条件 >(x > 0),如果为真:
3、进入 block 执行内部语句 y = 10(将 10 赋值给 y)。
4、如果为假,跳过整个 block。 -
...
解析器的作用就是将这种字符串 "拆解" 为有意义的语法结构(如抽象语法树 AST),让机器能按规则执行。
1.2、如何实现解析器?
在编译器实现中, 主要要做的就是词法分析和语法分析:
- 词法分析:解析代码并生成Token(一个单词的字面和它的种类及语义值)序列, 词法分析的实现一般称为扫描器(Scanner);
-
- 核心逻辑:定义token(语义)、scanner(用于扫描token)
- 语法分析:利用扫描器生成的Token序列来生成抽象语法树, 语法分析的实现一般称为解析器(Parser).
-
- 核心逻辑:作用是进行语法检查、并构建由输入的单词组成的数据结构(一般是语法分析树、抽象语法树等层次化的数据结构)。
举个例子:
数学表达式:1 + 2 * 3
// 首先在进行词法、语法分析前,我们先定义好token
单词字面 Token类型 说明
1 INTEGER 整数1
+ ADD_OP 加法运算符
2 INTEGER 整数2
* MUL_OP 乘法运算符
3 INTEGER 整数3
// 1、进行词法分析,从表达式前往后扫描会得到一组Token流(实际会在词法分析扫描过程的同时进行语法分析来不断构建AST)
[INTEGER(1), ADD_OP(+), INTEGER(2), MUL_OP(*), INTEGER(3)]
// 2、语法分析(整个过程会去校验是否有语法错误问题),根据运算符优先级(*优先于+)和Token流,构建AST:
[+]
/ \
1 [*]
/ \
2 3通常我们按照上面两个核心组件即可实现一个解析器,利用解析器解析得到AST 语法树之后我们就可以做很多事情了。
问题来了,我们现在就有一个需求需要实现一种规则的解析器怎么办?
- 方式一:不依赖任何工具,那就必须手写扫描器和解析器。
- 方式二:使用现成市面上解析器, 实际上扫描器和解析器也都可以根据一定的规则自动生成。于是就出现了一系列的解析器生成器, 如Yacc, Anltr, JavaCC等。
若是使用方式二,这些解析器生成器都可以根据自定义的语法规则文件自动生成解析器代码:
- 比如JavaCC可以根据后缀为
.jj的语法规则文件生成解析器的Java代码, 这就避免了手动编写扫描器和解析器的繁琐, 可以让我们专注于语法规则的设计。 - 比如antlr可以通过编写.g4语法规则文件,也可以生成相应的解析器、扫描器来助力我们快速实现一些编译器。
1.3、什么是SQL解析器?
SQL解析器是能够将SQL语句转换为计算机可理解和执行结构的程序组件。它将文本形式的SQL语句转换为抽象语法树(AST),为后续的查询优化和执行提供基础。
**通俗一点来说:**能够对SQL进行解析转换语法树的一个解析工具。
为什么需要SQL解析?
操作数据库的结构化数据,可以编写一套SQL规则,人类按照指定规则编写SQL,就可以完成一些数据的增删改查的处理,那么就需要有SQL解析器能够解析SQL从而执行对应操作。
SQL解析器使用场景位于哪里?我们数栈又为什么需要SQLParser解析器呢?
常见数据库执行sql,整个解析过程:
SQL文本 → 词法分析(Tokenizer)→ 语法分析(Parser)→ AST → 语义分析 → 优化SQL -> 产生执行计划对应执行任务 应用到袋鼠云数栈平台上的场景:
SQL文本 → 词法分析(Tokenizer)→ 语法分析(Parser)→ AST → 应用层(实现类型识别,表字段血缘、表解析、SQL脱敏) -> 子产品应用1.4、认识市面上的一些解析器 & SQL解析器
一览图
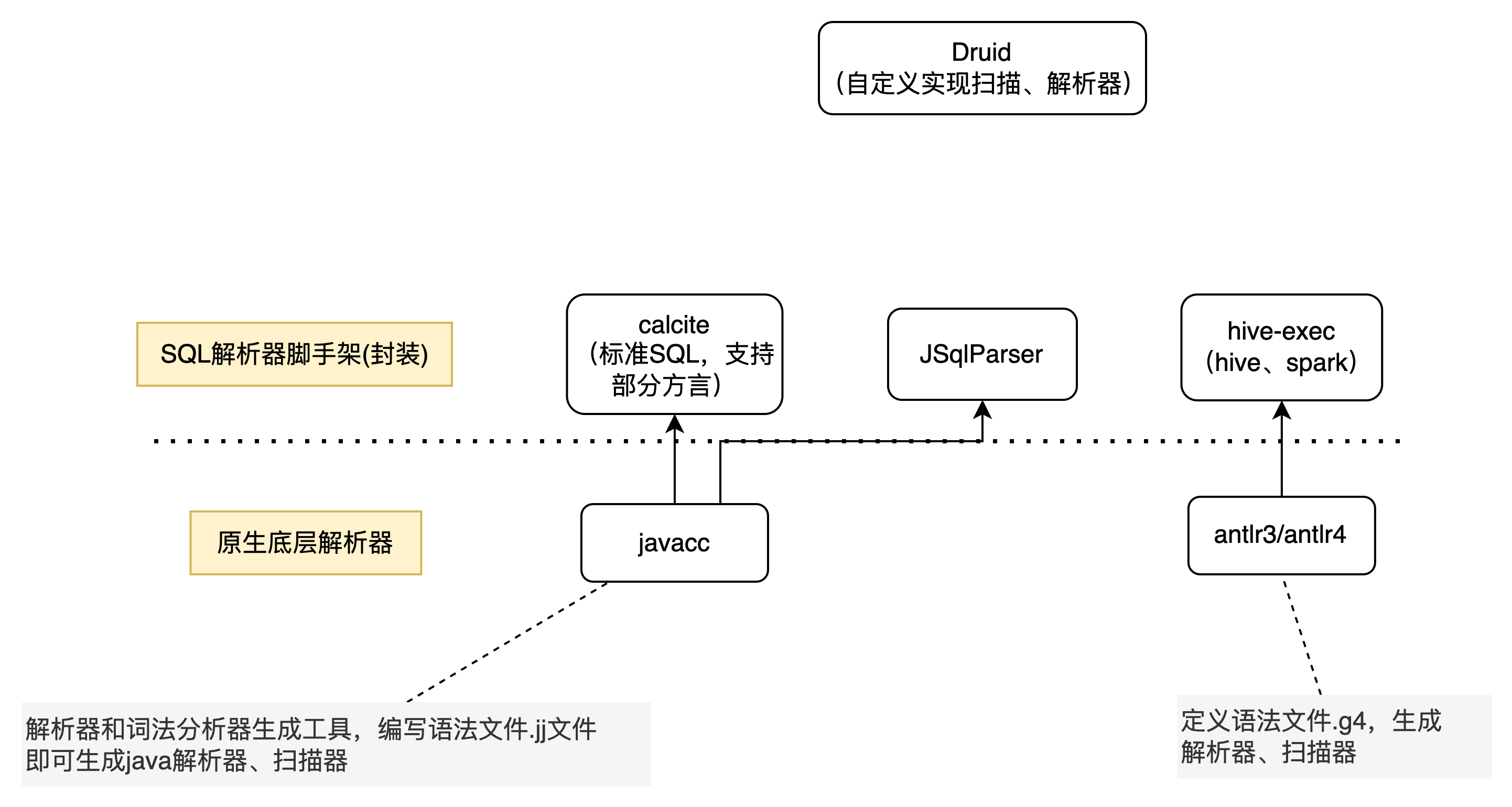
1.4.1、底层解析器
1)底层解析器件:市面上主流就是javacc、antlr3/4,内部已经帮你封装好扫描器、解析器,你只需要按照一定的规则去编写语法文件,即可完成扫描器、语法解析器代码编写,下面是区别:
|------------|------------|------------------|----------------|
| 特性 | JavaCC | ANTLR 3 | ANTLR 4 |
| 语法分析算法 | LL(k) | LL(*) | LL (*)(自适应预测) |
| 左递归处理 | 不支持,需手动转换 | 需手动转换 | 自动处理 |
| 目标语言 | Java | Java、C#、Python 等 | 同 ANTLR 3 |
| 错误处理 | 基础错误恢复 | 增强的错误恢复 | 智能错误恢复与诊断 |
| 语法复杂度 | 简单直观 | 较复杂 | 简化(相比 ANTLR 3) |
| 工具链 | 基础工具 | 丰富(包括调试工具) | 进一步增强(如可视化工具) |
| 应用场景 | 小型项目、教育 | 中大型项目 | 大型项目、复杂语法 |
| 社区活跃度 | 一般 | 活跃 | 非常活跃 |
| 发布时间 | 1990 年代 | 2007 年左右 | 2012 年发布 |
JavaCC:
- javacc官网:https://javacc.github.io/javacc/
- github:https://github.com/javacc/javacc
Antlr4:
值得一提的是,antlr4支持很多编程语言以及各种类型的SQL,antlr4有一个官方语法仓库:https://github.com/antlr/antlr4,支持了大量的SQL语法规则,都已经适配好了,至于为什么后续我们改造中没有直接使用antlr4,而是选择使用druid-core来进行二开实现后续会进行单独说明。
- grammars-v4:这是一个开源项目,提供了多种语言的语法文件,包括 SQL 方言(如 MySQL、PL/SQL、T-SQL 等)。开发者可以直接使用这些语法文件,或者在此基础上进行扩展。
- PS:袋鼠云的数栈前端团队离线任务等其他子产品的SQL编辑器里就使用到了SQLParser(强依赖antlr4),我这里贴下开源仓库地址 https://github.com/DTStack/dt-sql-parser/blob/main/README-zh_CN.md,基于antlr4-c3来进行扩展一些额外功能,他们主要实现的如关键词高亮,代码补全等功能。
1.4.2、calcite & hive-exec(SQL解析器)
为什么说他们是SQL解析器脚手架呢?
- 脚手架指的是已经实现了在sql标准规范上给我们基于javacc、或者antlr实现了一套SQL词法、语法解析规则,我们只需要按照他们实现的扩展即可,主要包含如下:
calcite :基于javacc,已经实现了标准SQL解析的能力,一个模块化、可扩展的SQL解析器和优化器框架,你可以基于这套标准SQL解析框架去扩展自定义的SQL语法。
hive-exec包:基于antlr3,支持hive数据源的语法解析。
- 底层基于antlr3实现,是hive的核心包。
- 早期数栈就是使用的这个核心包来对hive、spark实现SQL解析,后续来实现一系列的应用层解析能力。
1.4.3、JSqlParser、Druid-core
JSqlParser:JSqlParser是一个SQL语句解析器。它在Java类的可遍历层次结构中转换SQL。JSqlParser不限于一个数据库,而是提供了对Oracle,SqlServer,MySQL,PostgreSQL等许多特殊数据库的支持。
Druid-core: 完成使用 java自己实现扫描器、语法解析器 ,解析出来的语法树同样是一颗更加具像化的抽象语法树(具有继承关系)
核心对比区别
|-------------------------|------------|------------------------------------------------|------------------------------------------------|---------------------------------|-------------------------------------------------|--------------------------------------------------------------------------|
| 工具 | javacc | antlr4 | calcite | hive-exec | JsqlParser | Druid-core |
| 依赖工具 | 原生定义解析规则 | 原生定义解析规则 | 基于javacc | 基于antlr3 | 基于javacc | 原生java实现扫描、解析器件 |
| 解析SQL能力 | 无 | 有,官方有相应扩展SQL类型语法规则(生态极好) | 标准SQL(支持多方言扩展,生态实现较弱) | HiveSQL、Spark | 标准SQL,支持Oracle,MySql,SQLServer、PostgreSQL特定方面解析 | 支持mysql、oracle、hive、spark、doris、starrocks等 |
| 语法树节点是否具有类继承关系(抽象SQL结构) | 无 | 无 | 有 | 无 | 有 | 有(极强) |
| 优缺点 | 从零定义SQL规则 | 官方语法生态支持能力强 ,支持visitor等模式,解析语法树无抽象继承关系 | 提供标准SQL解析,但生态数据源语法支持较弱,需要手动去扩展分层单独写语法规则文件(成本大) | 只支持特定hive、spark语法解析,无法扩展分层其他数据源 | api层面无区分数据源类型,虽然整体提供较好特性能力且支持部分SQL方言 | 支持数据源解析能力的分层,**解析AST 语法树有继承关系,支持数据源生态较好。**缺点:java代码自实现分析扫描器,入门学习有难度。 |
二、数栈原始的SQLParser
历史背景
下面是各个服务会涉及到的功能以及使用到的解析器:
离线服务:
- 涉及功能:sql类型识别、真实表解析、SQL脱敏、行列级权限
- 实现:calcite & hive-exec模块解析器,加上druid兜底
API服务:
- 涉及功能:api解析(预编译、非预编译)、真实表解析、行列级权限
- 实现:calcite + druid
label标签:
- 涉及功能:标签解析
- 实现:calcite
实时 flinksql:
- 涉及功能:字段、表血缘
- 实现:Flink提供的parser、hive-exec、正则。
资产服务:
- 涉及功能:表、字段血缘解析、真实表解析、SQL类型识别
- 实现:使用到calicite、druid 以及hive-exec。
**总体描述:**目前主要维护较多的离线、API、资产模块的SQL解析,可以看到不同的子产品解析会使用涉及到很多解析工具,也同样包含多种兜底情况。
关于SQL解析扩展方面 :历史针对于SQL语法层面的扩展很少 ,=做过扩展的就是基于calcite扩展了部分语法(统一是在extend-calcite模块中,做过语法扩展历史有limit、like关键字等)
历史设计实现思路
不同数据源整体分类:calcite(rdb类型)、hive-exec(spark、hive)进行解析。【druid、正则方式作为兜底】
业务逻辑分类:
一类:对于SQL类型识别、表解析、SQL脱敏、行列级权限
- 根据SQL类型使用calcite、hive-exec来进行SQL解析得到语法树
- 根据语法树来进行上述业务逻辑处理
另一类:对于血缘实现,calcite、hive-exec解析得到的语法树 => 转换数栈自己的语法树 => 针对自己语法树来实现表、字段血缘解析。
- 根据SQL类型使用calcite、hive-exec来进行SQL解析得到语法树
- 自定义语法树,实现了两套转换器Node Adapter逻辑,calcite语法树 => 自定义语法树、hive-exec语法树(AstNode) => 自定义语法树
- 通过血缘解析逻辑针对于自定义语法树完成解析能力 【以前设计应该是聚焦一套逻辑实现血缘解析】
历史设计的遗留问题
1、不同数据源语法解析扩展能力弱,基本不同rdb语法需要去正则前置处理 或者 单独去extend-calcite去扩展语法(扩展语法集中在一个模块)
2、使用到了多种不同的解析框架,各种兜底,代码维护难 ,拿到语法树之后进行应用层解析逻辑也冗余到一起,维护起来到处都是if 判断数据源兼容逻辑,可能改一个地方会影响到其他地方,从而不可维护。
3、血缘解析扩展弱,学习成本极高。
- 首先你需要了解calcite、astnode的各种类型节点定义,你还需要有自定义语法树能力。
- 有了这两点前置基础之后,你需要去扩展calcite、astnode节点转换自定义语法树节点的逻辑(容易死循环)。
- 直到转换自己的语法树之后,才到了血缘解析层面的解析,你还需要懂血缘解析的逻辑,这一套下来门槛很高。
三、SQLParser技术改造
3.1、SQLParser分层改造(双层改造)
拆分为两个层面分层:语法解析、应用层解析
第一个层面:语法解析分层
解析器方面:
在解析SQL层面,我们期望能够有一个可扩展实现的解析器和扫描器,这就需要我们有一个基于标准SQL的解析扫描实现,在上层抽象类中定义各个抽象的指定类型的扫描方法,能够实现后续各个不同数据源的扫描扩展。
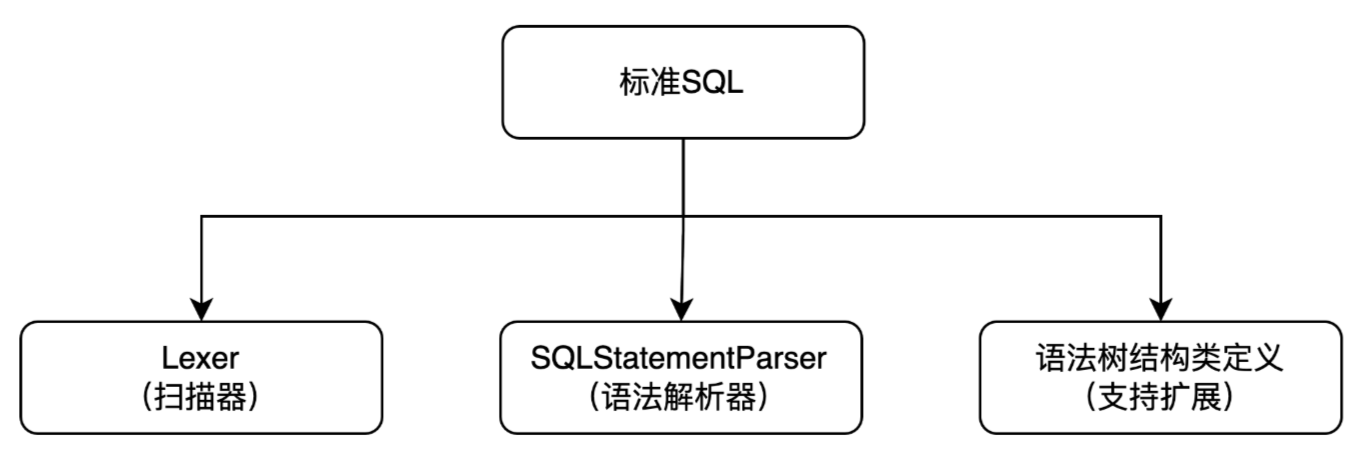
分层实现扫描器、解析器都可支持继承复用功能,且相互独立互不影响,结构类可自定义扩展:
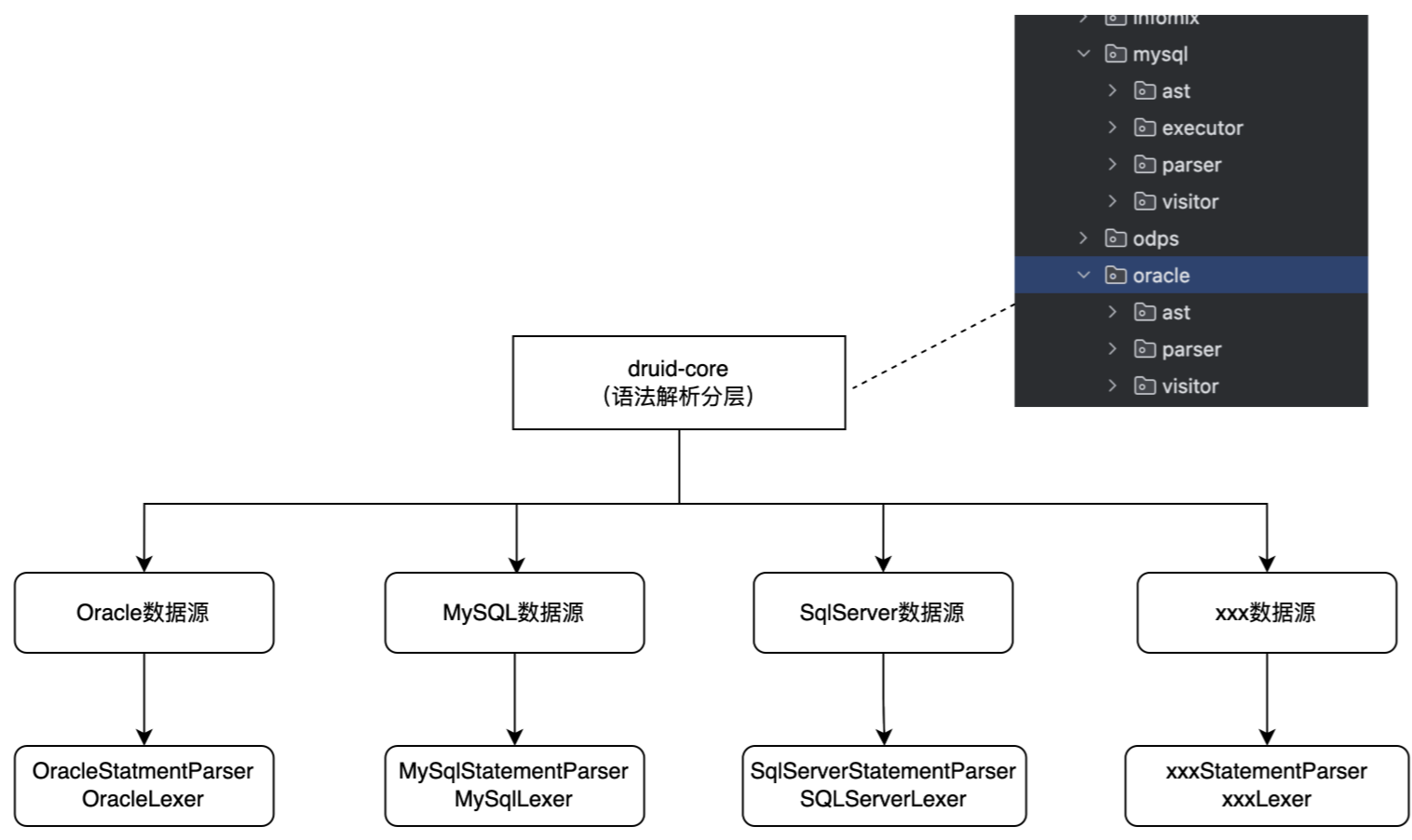
语法树方面:
通过解析器,能够将SQL转为一个语法树,而对于最终的语法树,我们更期望的应该是一个具象的语法树,而不是特别精细的类似于antlr4的语法树,我们期望的应该是所有不同类型的SQL可以转为一个对应具体类型的一个结构,如:create sql、select sql、insert sql、update sql、delete sql,能够都去抽象出来对应的类如下图,每个类有对应特定类型的属性值,如表名、字段名等属性。【这里是拿到druid的抽象实现】
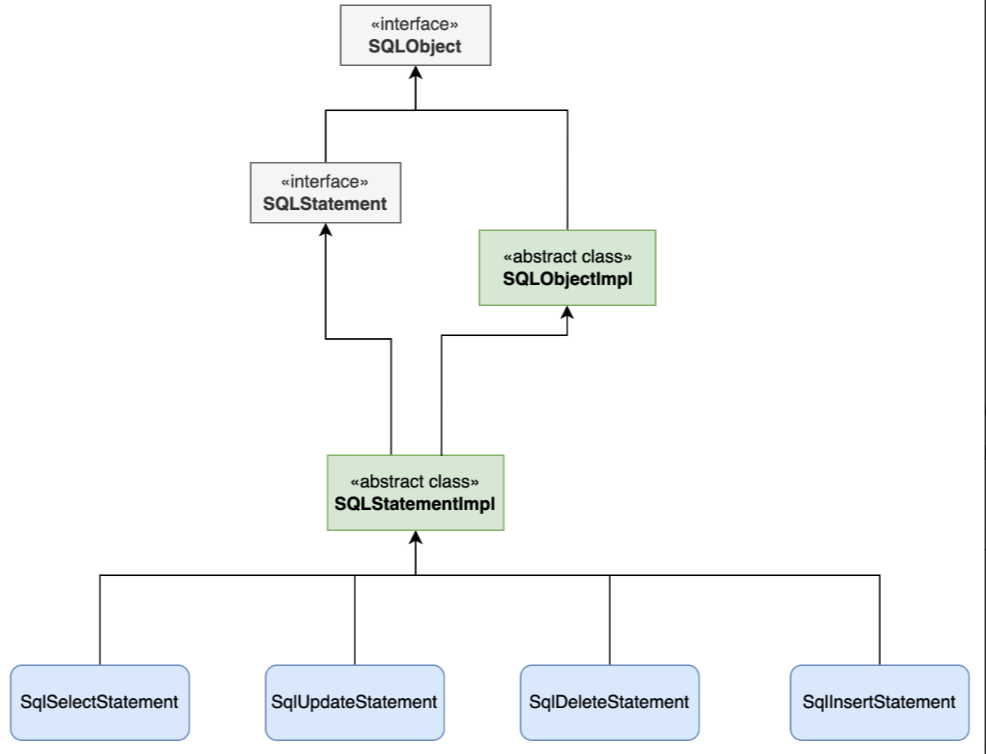
当我们来解析同一个sql,来看下不同的解析框架得到的结果:
select * from changlu where id = 1 and name = 3;Druid得到的语法树结构则为SQLSelectStatment,其为一个select sql,同时整个sql中的各个结构则为各个属性:
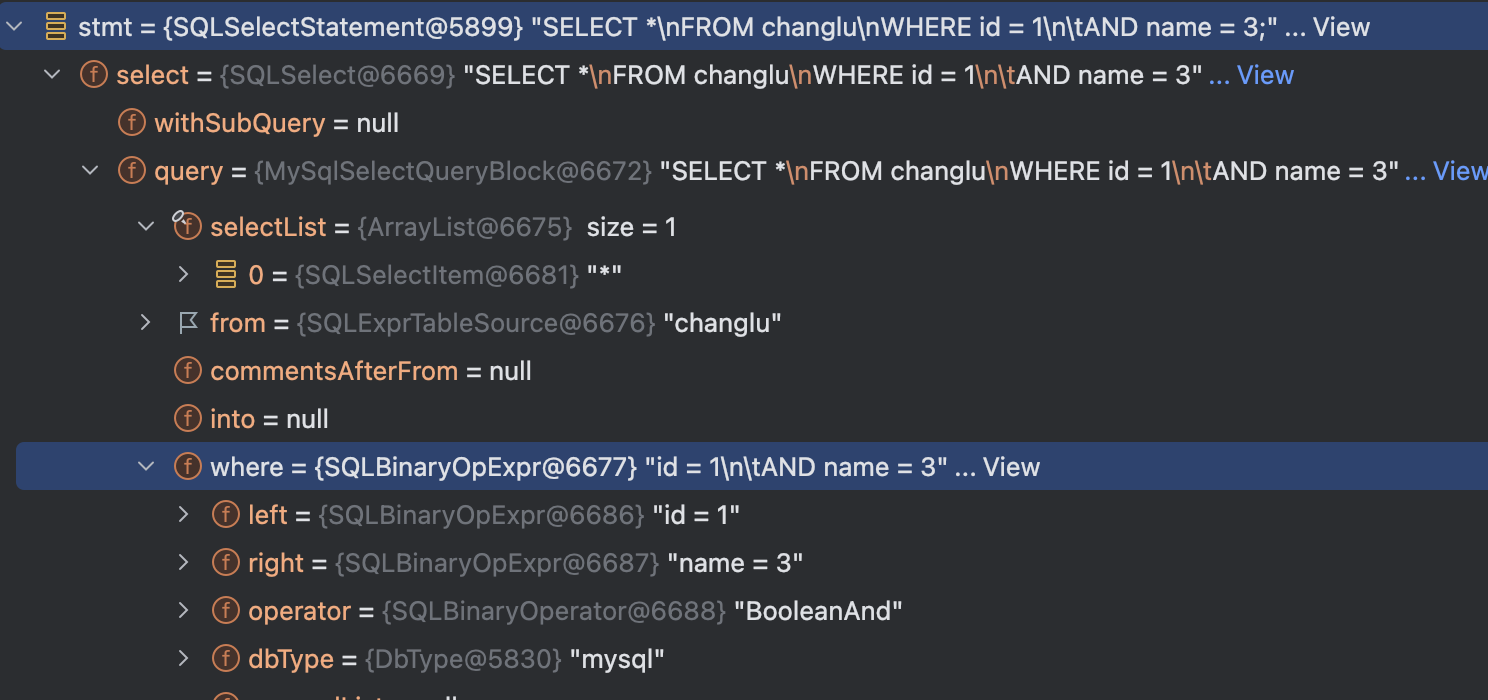
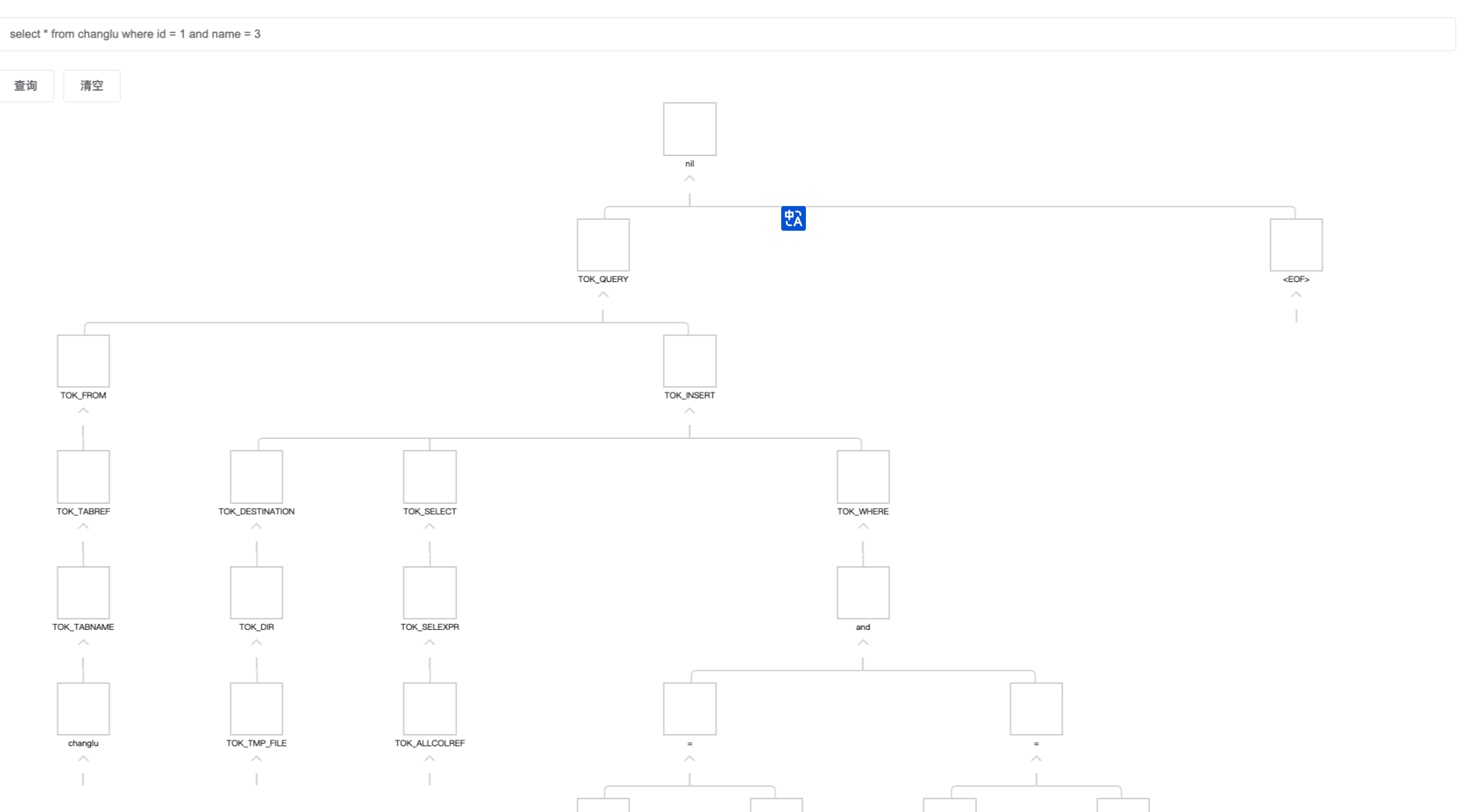
而不是antlr3得到的一颗语法树,如下(这个是hive-exec包解析到的树,底层使用的是antlr3):
通过对市面上各种SQL解析器调研,发现druid中的core包中就实现了我们想要的这样子可扩展实现的扫描器、解析器 ,最终不同的数据源SQL都可以具像化的转为对应类型的Statement类结构,也就是比较具像化的语法树 ,后续我们就可以在这样子的统一结构的语法树中实现一套业务逻辑处理,就能够实现表解析、血缘解析、SQL脱敏等等业务层功能。
实际上通过使用calcite、antlr3/4都可以实现后续的业务逻辑处理,这里选择druid-core的原因和其他数据源的对比主要有以下几点:
1、calcite分层的话,单独数据源需要单独抽取一个模块,同时需要单独每一个数据源去维护一个语法规则文件,具有调试难度较大,官方对于特定不同数据源语法的支持较弱,如果要实现calcite分层,基本我们需要从头开始去针对不同数据源去完善语法规则文件,而且还只是在语法解析层面。
2、anlr4官网提供的grammer库,虽然很全,但是并不适用我们需要对多种不同类型的SQL实现多种业务逻辑解析,如表解析、血缘等,因为虽然官网提供grammer库支持了很多数据源,但是你会发现解析到语法树之后,他们不同类型的sql对应的语法树节点的名称都是各不相同的,你可以理解每一种数据源解析出来语法树之后,需要对每一个语法树来进行适配各个业务层解析。
3、druid-core对于扫描解析全部自定义实现,同时扫描器、解析器支持可扩展分层,同时不同SQL类型解析出来的语法树都是同一棵具象语法树,我们可以轻松的写一套逻辑即可适用多种不同的RDB SQL类型的业务解析。
- 唯一缺点就是:你需要理解其扫描器、语法解析器的核心原理实现,要能够理解原始node节点的抽象设计并很好的继承去实现。
关于druid-core内部使用方面:
- 目前团队内部已经开始进行druid二开,独立一个druid仓库来去维护后续语法解析能力的扩展,截止目前已进行了多次语法扩展,如支持doris的alter类型的sql、like %${var}%结构类型以及select 字段精确点位记录等,扩展速度方面也较快。
- 对于后续druid官方开源仓库更新迭代,我们也会去定期进行合并代码进来,在针对我们自己的SQL语法扩展中,我们单独去维护了一组单测,主要用于测试验证我们自行扩展的语法,避免后期合并代码 & 修改业务逻辑影响语法解析能力。
第二个层面:业务解析分层
**回顾之前的解析层:**我们对于不同类型的SQL通过一套通用的扫描解析器 解析之后可以得到一颗统一抽象结构语法树。
那针对我们应用层: 针对 统一的语法树实现一套解析方法实现。在实现这样子的一套通用的解析方法过程中,我们也考虑到可能不同的SQL类型我们就扩展特定的SQLStatment节点,我们还去进行了业务层解析的分层,能够实现针对某个数据源来进行业务解析分层扩展。
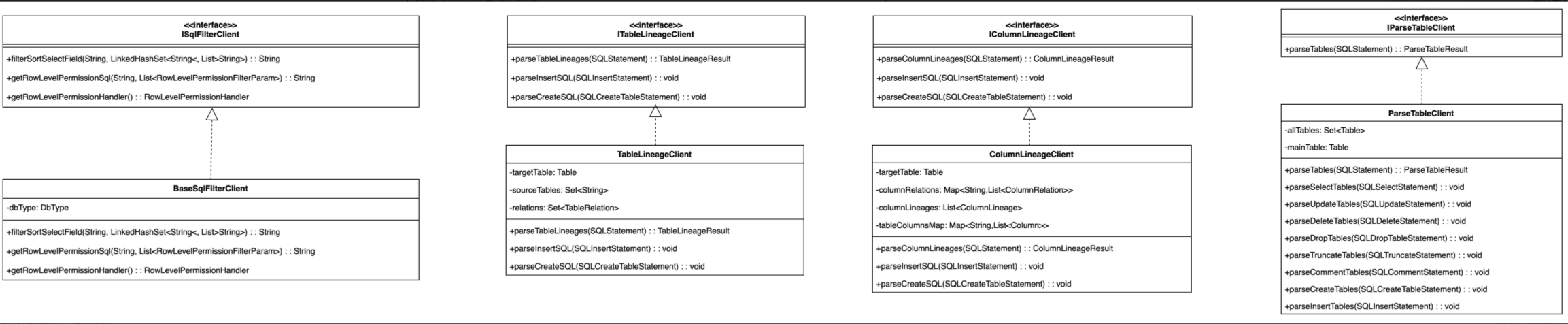
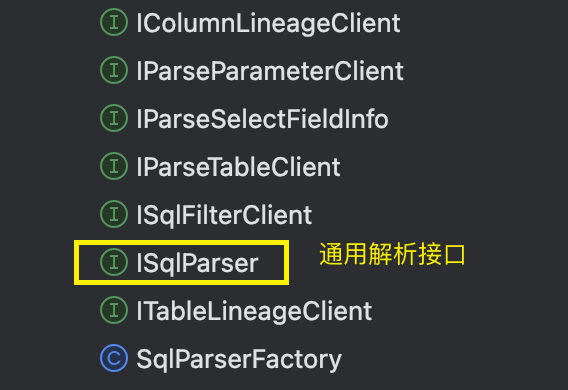
我们设计了接口及相应的组件:
- ISqlParser接口,这个接口具有不同业务层解析的能力,如表、字段血缘解析、表解析、函数解析、SQL脱敏、API解析等等。
- BaseSqlParser类:作为一套通用的解析语法树的基类解析实现类,其内部设计了多个getxxxClient的获取特定组件的方法,实际上对应的一些解析方法具体实现会根据所绑定的具体client来提供某个解析能力。

例如权限相关的解析我们单独设计了一个ISqlFilterClient接口,其就有一个BaseSqlFilterClient的基类实现,将这个组件通过get的方式封装到BaseSqlParser中,就能够实现后续不同的ISqlParser解析方面的动态分层扩展更换相应的组件了。
目前在我们sqlparser模块中维护了业务层解析分层的实现:
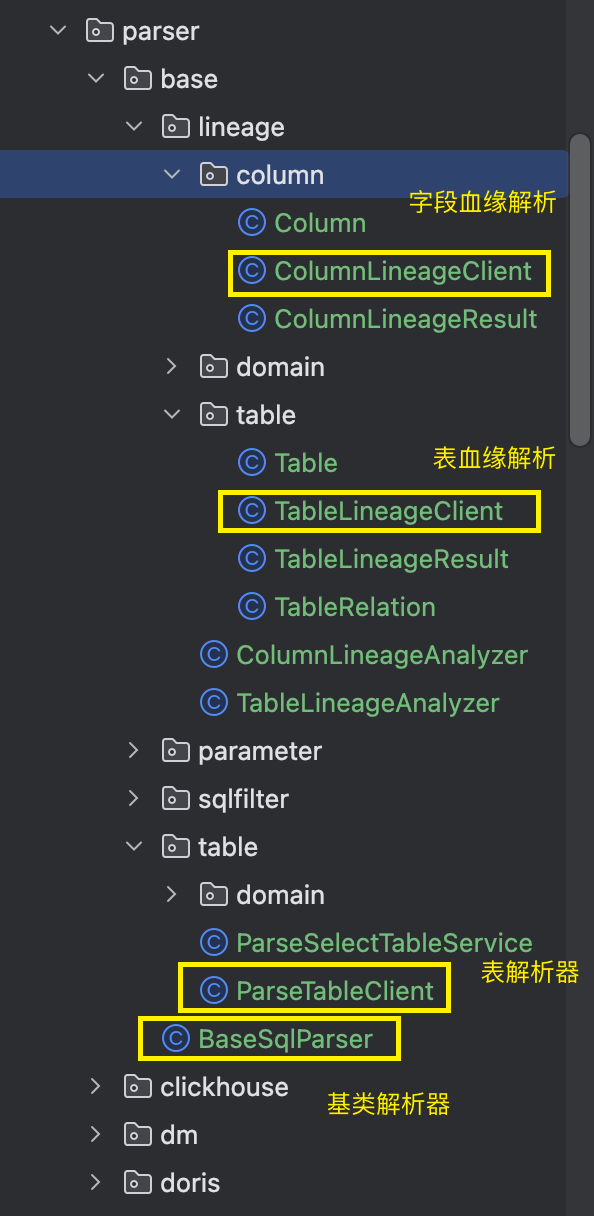
在我们基类BaseSqlParser中实现大致如下:
public class BaseSqlParser implements ISqlParser {
@Override
public ColumnLineageResult parseColumnLineages(String sql, Map<String, List<Column>> tableColumnsMap) {
SQLStatement sqlStatement = this.parseStatement(sql);
return this.parseColumnLineages(sqlStatement, tableColumnsMap);
}
@Override
public ColumnLineageResult parseColumnLineages(SQLStatement sqlStatement, Map<String, List<Column>> tableColumnsMap) {
IColumnLineageClient columnLineageClient = this.getColumnLineageClient(tableColumnsMap);
// 执行字段血缘解析
return columnLineageClient.parseColumnLineages(sqlStatement);
}
@Override
public ParseTableResult parseTables(SQLStatement sqlStatement) {
IParseTableClient parseTableClient = this.getParseTableClient();
// 执行表解析
return parseTableClient.parseTables(sqlStatement);
}
// 替换解析表组件
protected IParseTableClient getParseTableClient() {
return new ParseTableClient();
}
// 替换字段血缘解析组件
protected IColumnLineageClient getColumnLineageClient(Map<String, List<Column>> tableColumnsMap) {
return new ColumnLineageClient(tableColumnsMap);
}
}对于具体的业务解析就会分别分布在特定的xxxClient中去实现。
**那么语法层的解析如何去扩展呢?**例如我们在二开的druid-core中去扩展了mysql的特定SQL类型的statemnet节点:MySqlRenameTableStatement。
那么在对应的业务层表解析中,我们实际上在进行表解析逻辑处理时,也要对该类型的statement类型来进行解析,不然的话就会出现遗漏掉需要解析的真实表。
我们首先单独定义一个叫做MysqlParseTableClint,其继承ParseTableClient,并重写其中的parseTables方法:
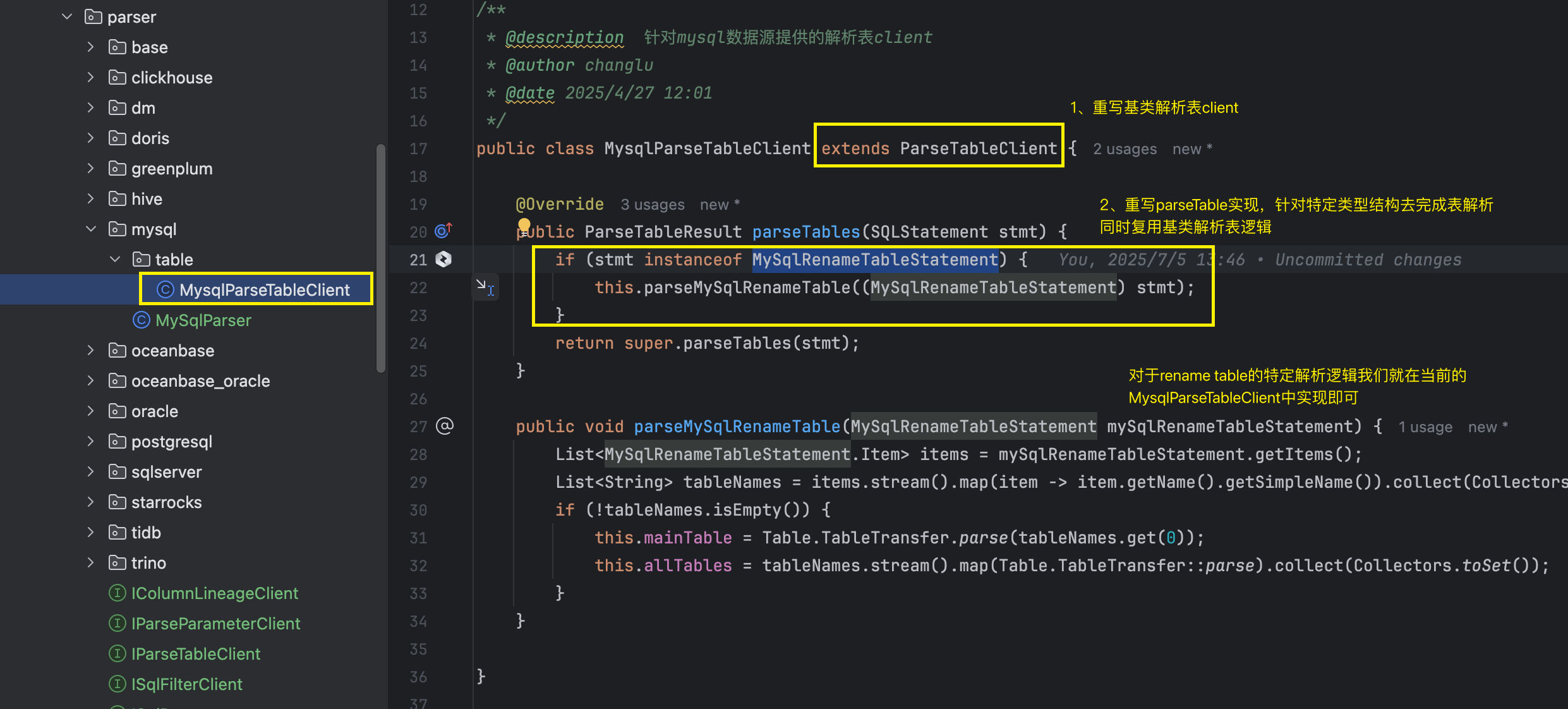
接着将该解析组件注册到MySqlParser中:
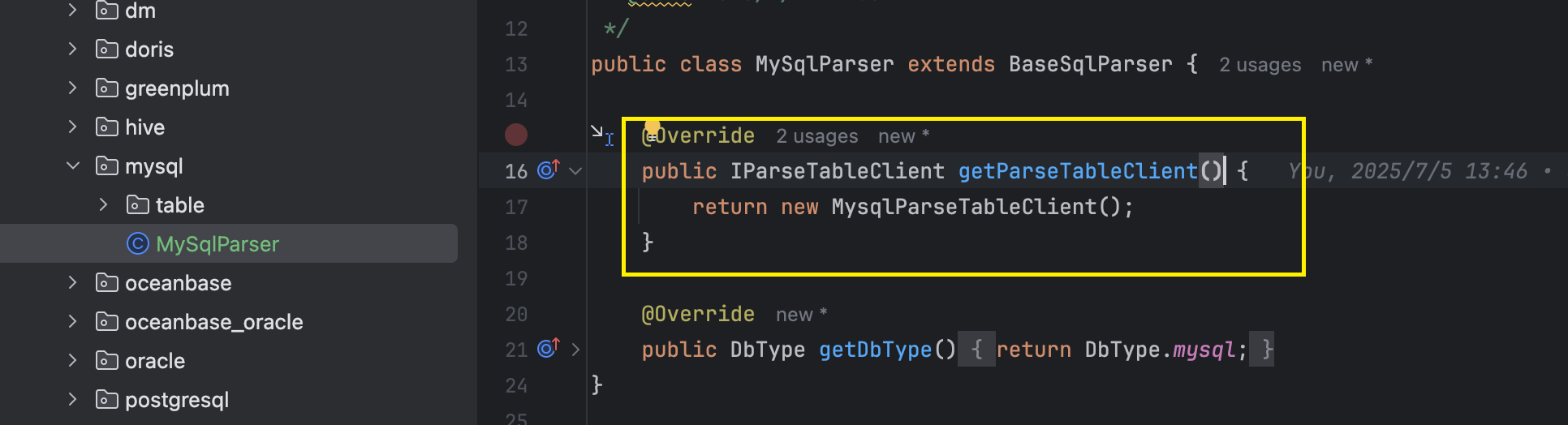
这样子我们就完成了特定MySQL的SQL解析器件的扩展。
3.2、分层改造后的API使用方式
我们在去使用特定SQL解析的时候,首先通过工厂类SqlParserFactory来根据指定数据源类型拿到特定的SqlParser实现,接着使用这个sqlparser即可完成特定的表解析、字段解析、血缘解析等等,接口调用方式目前还是非常简洁易懂的。
// 准备sql
String sql = getSql();
// 1、获取到sqlparser解析器
// 方式一:工厂方式获取
ISqlParser sqlParser = SqlParserFactory.getSqlParser(DbType.mysql);
// 方式二:直接new
// MySqlParser mySqlParser = new MySqlParser();
// 2、实现解析功能
// 2.1、解析表
ParseTableResult parseTableResult = sqlParser.parseTables(sql);
System.out.println("====解析表====");
System.out.println(parseTableResult.getMainTable());// 获取主表
System.out.println(parseTableResult.getAllTableName()); // 获取解析到的所有表
// 2.2、解析字段血缘
System.out.println("\n====解析字段血缘====");
// 针对select * from table 场景,可传入tableColumnsMap封装真实的表字段信息
Map<String, List<Column>> tableColumnsMap = new HashMap<String, List<Column>>(){
{
this.put("users",
Arrays.asList(new Column("id", 0)
, new Column("name", 1)
));
this.put("orders",
Arrays.asList(new Column("amount", 0)
, new Column("id", 1)
));
}
};
ColumnLineageResult columnLineageResult = sqlParser.parseColumnLineages(sql, tableColumnsMap);
columnLineageResult.printColumnLineage();
// 2.3、解析表血缘
System.out.println("\n====解析表血缘====");
TableLineageResult tableLineageResult = sqlParser.parseTableLineages(sql);
List<TableLineage> tableLineages = tableLineageResult.getTableLineages();
System.out.println(tableLineages);
// 2.4、解析函数
System.out.println("\n====解析函数====");
Set<String> functions = sqlParser.parseFunction(sql);
System.out.println(functions);3.3、内部子产品 & 历史逻辑兼容处理
通过此次技术改造,我们可以说是重点会对druid-core来进行二开语法解析扩展,同时还会基于druid-core完成解析表、血缘等等的业务逻辑处理,我们将目前数栈应用到的业务逻辑,基于druid解析到的语法树都进行重新实现了一遍。
对于历史子产品的兼容逻辑处理,我们额外单独设计了一个Proxy类和特定的DruidNodeParser,用于替换历史的calciteNodeParser,将历史的CalciteNodeParser作为解析兜底,后续碰到语法解析能力不足的优先都会以当前这一套分层实现来去扩展维护。
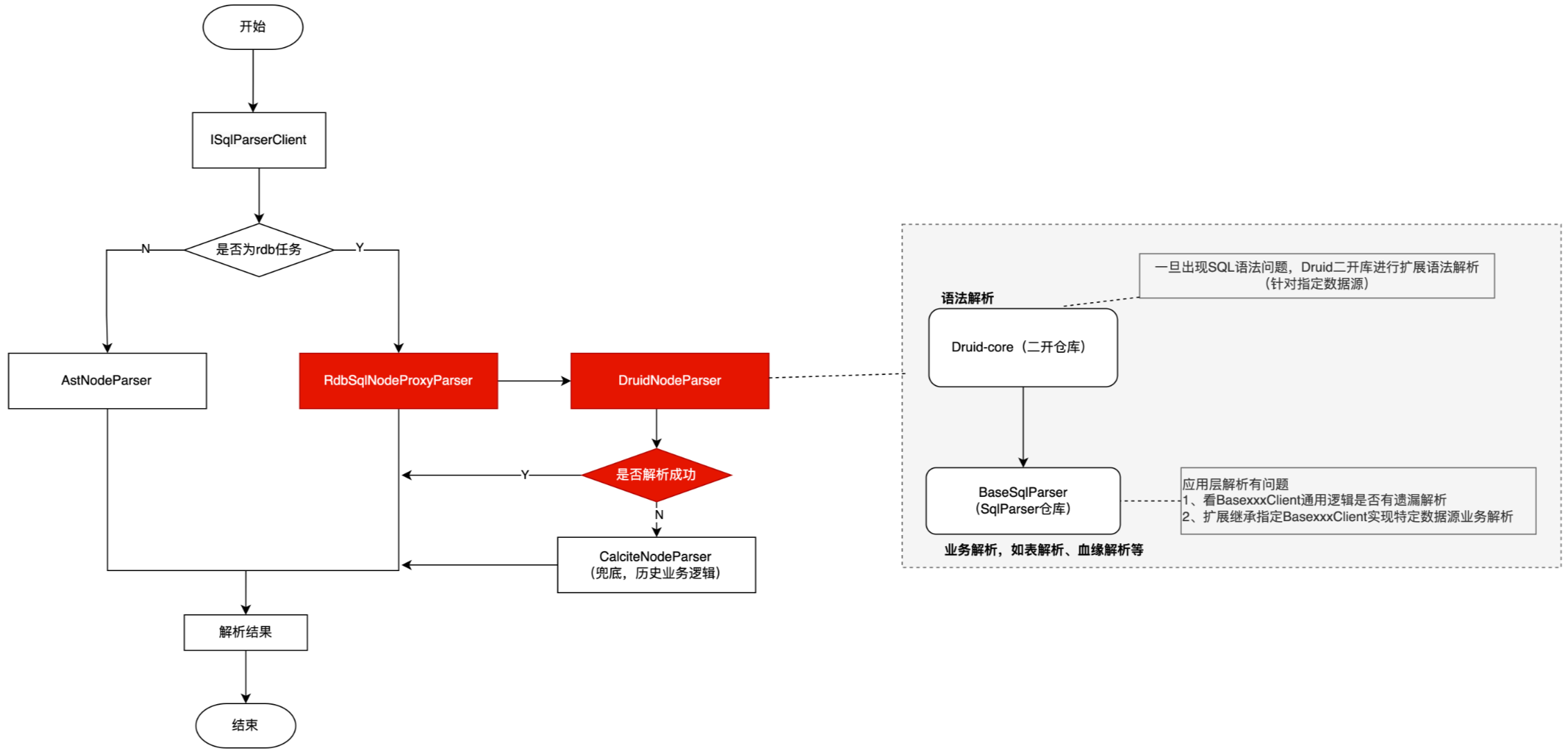
这对这个proxy类实现&兜底逻辑,我们主要目的也是去本地单测未涉及到以及测试侧验证的单例来进行兜底,避免影响客户原始业务逻辑能力。
同时目前我们并没有将所有的不同数据源SQL类型的解析之前一次性迁移为当前这一套逻辑,因为袋鼠云是面向toB场景,为大量很多公司、政企服务,我们目前也在内部慢慢针对部分特定数据源解析逻辑进行平滑迁移,实现未来能够支撑更多不同类型SQL的解析能力和业务扩展能力。
未来设想
后续我们完善测试验证之后,会对这样一套SQL解析框架核心实现逻辑进行开源,各位小伙伴可以期待一下。