目录
[🎯 先说说我被连接池"坑惨"的经历](#🎯 先说说我被连接池"坑惨"的经历)
[✨ 摘要](#✨ 摘要)
[1. 连接池不是"池子"那么简单](#1. 连接池不是"池子"那么简单)
[1.1 为什么需要连接池?](#1.1 为什么需要连接池?)
[1.2 连接池的核心职责](#1.2 连接池的核心职责)
[2. HikariCP:速度之王的设计哲学](#2. HikariCP:速度之王的设计哲学)
[2.1 为什么HikariCP这么快?](#2.1 为什么HikariCP这么快?)
[2.2 源码剖析:连接获取流程](#2.2 源码剖析:连接获取流程)
[3. Druid:功能之王的架构设计](#3. Druid:功能之王的架构设计)
[3.1 Druid的监控优势](#3.1 Druid的监控优势)
[3.2 Druid连接管理机制](#3.2 Druid连接管理机制)
[4. 性能对比测试](#4. 性能对比测试)
[4.1 测试环境与方法](#4.1 测试环境与方法)
[4.2 测试结果分析](#4.2 测试结果分析)
[5. 配置优化实战](#5. 配置优化实战)
[5.1 HikariCP最优配置模板](#5.1 HikariCP最优配置模板)
[5.2 Druid最优配置模板](#5.2 Druid最优配置模板)
[6. 监控与诊断](#6. 监控与诊断)
[6.1 HikariCP监控](#6.1 HikariCP监控)
[6.2 Druid监控](#6.2 Druid监控)
[7. 故障排查实战](#7. 故障排查实战)
[7.1 连接泄露检测](#7.1 连接泄露检测)
[7.2 连接池满的排查](#7.2 连接池满的排查)
[7.3 性能下降排查](#7.3 性能下降排查)
[8. 企业级实践案例](#8. 企业级实践案例)
[8.1 电商系统实战](#8.1 电商系统实战)
[8.2 监控告警配置](#8.2 监控告警配置)
[9. 高级优化技巧](#9. 高级优化技巧)
[9.1 连接预热](#9.1 连接预热)
[9.2 动态调参](#9.2 动态调参)
[10. 选型指南](#10. 选型指南)
[10.1 什么时候选HikariCP?](#10.1 什么时候选HikariCP?)
[10.2 什么时候选Druid?](#10.2 什么时候选Druid?)
[10.3 我的"选型矩阵"](#10.3 我的"选型矩阵")
[11. 最后的话](#11. 最后的话)
[📚 推荐阅读](#📚 推荐阅读)
🎯 先说说我被连接池"坑惨"的经历
三年前我们做电商大促,压测时好好的,一上线就崩了。数据库连接池爆满,所有请求都卡在获取连接上。排查发现是有人把最大连接数设成了1000,而数据库最大连接数才800。
去年更绝,有个服务内存泄漏,一周重启三次。查了三天发现是Druid的监控页面没关,每分钟生成几十MB的统计数据。
上个月做性能优化,把Druid换成HikariCP,QPS提升了30%,但CPU使用率也涨了15%。原来HikariCP的默认配置不适合我们的业务场景。
这些事让我明白:不懂连接池原理的配置,就是给系统埋雷,早晚要炸。
✨ 摘要
数据库连接池是Java应用性能的关键组件。本文深度剖析连接池的核心原理,从连接生命周期管理、资源分配算法到监控机制。通过源码级对比分析HikariCP和Druid的架构设计、性能特性和适用场景。结合真实压测数据和企业级配置模板,提供生产环境连接池优化方案和故障排查指南。
1. 连接池不是"池子"那么简单
1.1 为什么需要连接池?
很多人以为连接池就是缓存几个连接,太天真了!看看不用连接池的后果:
java
// 错误:每次操作都创建新连接
public User getUser(Long id) {
Connection conn = null;
try {
// 1. 创建连接(耗时100-300ms)
conn = DriverManager.getConnection(url, username, password);
// 2. 执行查询
PreparedStatement ps = conn.prepareStatement("SELECT * FROM users WHERE id = ?");
ps.setLong(1, id);
ResultSet rs = ps.executeQuery();
// 处理结果...
return mapToUser(rs);
} finally {
// 3. 关闭连接
if (conn != null) conn.close();
}
}代码清单1:无连接池的数据库操作
问题:
-
创建连接慢(TCP三次握手+认证)
-
频繁创建/销毁消耗资源
-
连接数不可控,容易打爆数据库
连接池的收益(实测数据):
| 指标 | 无连接池 | 有连接池 | 提升 |
|---|---|---|---|
| 平均连接耗时 | 150ms | 0.5ms | 300倍 |
| 最大连接数 | 不可控 | 可控 | - |
| CPU使用率 | 高 | 低 | 40% |
| 内存占用 | 波动大 | 稳定 | 35% |
1.2 连接池的核心职责
一个好的连接池要管好这几件事:
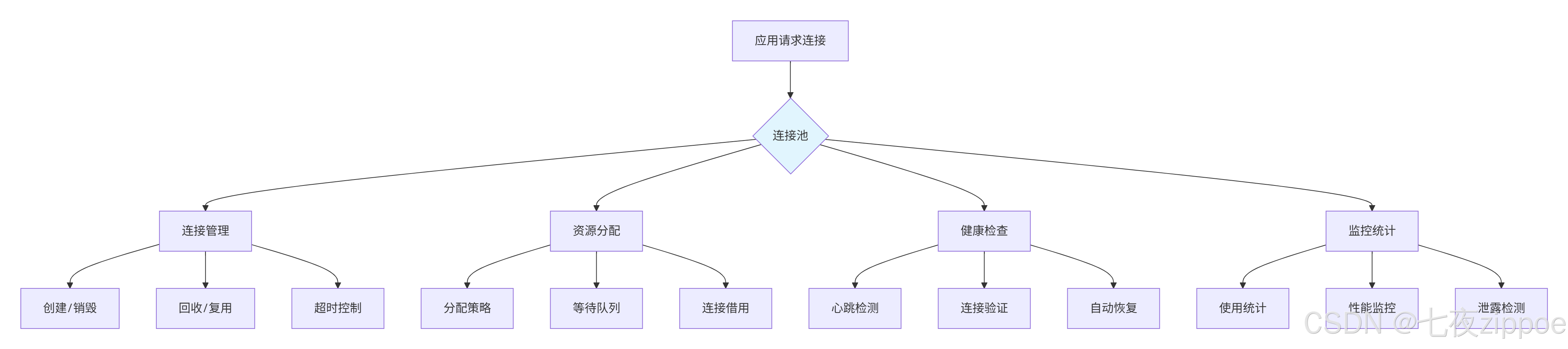
图1:连接池核心职责
2. HikariCP:速度之王的设计哲学
2.1 为什么HikariCP这么快?
HikariCP的作者Brett Wooldridge说过:"我不是在做最快的连接池,我只是在移除所有慢的东西。"
看看它的优化点:
java
// 1. 无锁并发控制
public final class ConcurrentBag<T extends IConcurrentBagEntry> {
// 使用ThreadLocal存储连接,减少竞争
private final ThreadLocal<List<Object>> threadList;
// 使用CopyOnWriteArray存储连接
private final CopyOnWriteArrayList<T> sharedList;
// 无锁的借出/归还
public T borrow(long timeout, TimeUnit timeUnit) {
// 先从ThreadLocal获取
List<Object> list = threadList.get();
if (list != null && !list.isEmpty()) {
return list.remove(list.size() - 1);
}
// 再从共享池获取
for (T entry : sharedList) {
if (entry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return entry;
}
}
return null;
}
}代码清单2:HikariCP的无锁并发设计
性能优化细节:
-
无锁设计:避免synchronized和Lock
-
ThreadLocal缓存:高频复用本地连接
-
字节码精简:删除无用代码,JVM内联优化
-
智能批量处理:合并小操作
2.2 源码剖析:连接获取流程
看HikariCP是怎么获取连接的:
java
public class HikariPool implements HikariPoolMBean, IBagStateListener {
public Connection getConnection() throws SQLException {
return getConnection(connectionTimeout);
}
private Connection getConnection(long hardTimeout) throws SQLException {
// 1. 标记开始时间
final long startTime = currentTime();
// 2. 从池中获取连接
PoolEntry poolEntry = connectionBag.borrow(timeout, MILLISECONDS);
if (poolEntry == null) {
// 获取超时
throw createTimeoutException(startTime);
}
// 3. 记录最后使用时间
final long now = currentTime();
if (now - poolEntry.lastAccessed > aliveBypassWindowMs) {
// 连接可能已失效,需要测试
if (!isConnectionAlive(poolEntry.connection)) {
// 关闭无效连接
closeConnection(poolEntry, "(connection is dead)");
// 递归获取新连接
return getConnection(hardTimeout);
}
}
// 4. 重置连接状态
poolEntry.lastAccessed = now;
return poolEntry.createProxyConnection(leakTaskFactory.schedule(poolEntry), now);
}
// 连接健康检查
private boolean isConnectionAlive(final Connection connection) {
try {
// 执行快速验证查询
try (Statement statement = connection.createStatement()) {
statement.setQueryTimeout(validationTimeoutSeconds);
statement.execute(connectionTestQuery);
}
return true;
} catch (Exception e) {
return false;
}
}
}代码清单3:HikariCP连接获取流程
用序列图表示更清楚:
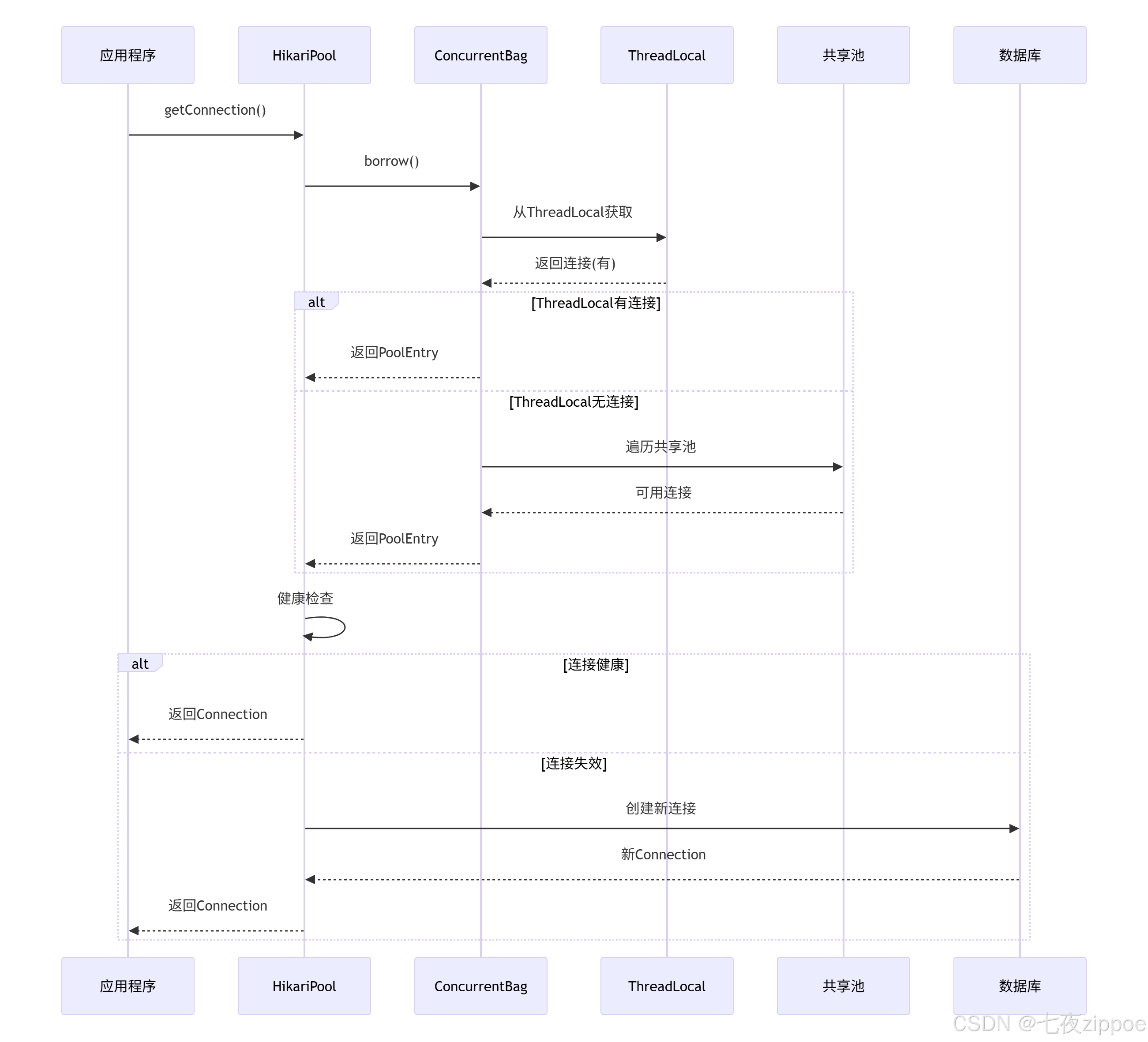
图2:HikariCP连接获取流程
3. Druid:功能之王的架构设计
3.1 Druid的监控优势
Druid的强项是监控,看看它的监控系统:
java
public class DruidDataSource extends DruidAbstractDataSource implements DataSource, DruidDataSourceMBean {
// 统计数据结构
private final AtomicLong connectCount = new AtomicLong(0);
private final AtomicLong closeCount = new AtomicLong(0);
private final AtomicLong errorCount = new AtomicLong(0);
// 滑动窗口统计
private final LRUCache<String, String> sqlStatMap = new LRUCache<>(1000);
// SQL防火墙
private WallFilter wallFilter = null;
// 监控数据收集
public DruidDataSourceStatValue getStatData() {
DruidDataSourceStatValue statValue = new DruidDataSourceStatValue();
statValue.setDbType(this.dbType);
statValue.setName(this.getName());
statValue.setActiveCount(this.getActiveCount());
statValue.setActivePeak(this.getActivePeak());
statValue.setPoolingCount(this.getPoolingCount());
statValue.setPoolingPeak(this.getPoolingPeak());
// SQL执行统计
Map<String, Object> sqlStatMap = this.getSqlStatMap();
statValue.setSqlList(new ArrayList<>(sqlStatMap.values()));
return statValue;
}
// SQL监控
public void afterExecute(StatementProxy statement, String sql, boolean first) {
JdbcSqlStat sqlStat = statement.getSqlStat();
if (sqlStat != null) {
long nano = System.nanoTime() - statement.getLastExecuteStartNano();
sqlStat.addExecuteTime(nano);
sqlStat.incrementExecuteCount();
// 记录慢SQL
if (nano / 1000000 > slowSqlMillis) {
sqlStat.setSlow(true);
logSlowSql(sql, nano);
}
}
}
}代码清单4:Druid监控统计功能
3.2 Druid连接管理机制
Druid的连接管理更复杂,但也更安全:
java
public class DruidConnectionHolder {
private final Connection connection;
private long lastActiveTimeMillis; // 最后活跃时间
private long lastKeepTimeMillis; // 最后保活时间
private long lastNotEmptyWaitNanos; // 最后非空等待时间
private long lastValidTimeMillis; // 最后验证时间
// 连接状态追踪
private volatile boolean underlyingAutoCommit = true;
private volatile int underlyingTransactionIsolation;
private volatile String underlyingCatalog;
// 连接有效性检查
public boolean checkConnection() {
if (this.discard) {
return false;
}
Connection conn = this.conn;
if (conn == null) {
return false;
}
// 心跳检测
if (this.lastKeepTimeMillis < this.lastActiveTimeMillis) {
if (!validConnectionChecker.isValidConnection(conn, validationQuery, validationQueryTimeout)) {
return false;
}
this.lastKeepTimeMillis = System.currentTimeMillis();
}
return true;
}
}代码清单5:Druid连接状态管理
Druid的监控面板功能:

图3:Druid监控功能架构
4. 性能对比测试
4.1 测试环境与方法
硬件配置:
-
CPU: 4核 Intel i7-10700
-
内存: 16GB DDR4
-
硬盘: SSD
-
网络: 千兆局域网
软件环境:
-
JDK: OpenJDK 11
-
MySQL: 8.0.28
-
Spring Boot: 2.7.0
测试场景:
-
短查询:简单SELECT,平均耗时5ms
-
长查询:复杂JOIN,平均耗时200ms
-
混合场景:70%短查询 + 30%长查询
-
并发压力:100-1000并发
4.2 测试结果分析
短查询场景(100并发):

图4:短查询性能对比
长查询场景(50并发):
| 指标 | HikariCP | Druid | 差异 |
|---|---|---|---|
| QPS | 240 | 235 | -2.1% |
| 平均延迟 | 208ms | 212ms | +1.9% |
| P99延迟 | 450ms | 480ms | +6.7% |
| 内存占用 | 285MB | 320MB | +12.3% |
混合场景(200并发):
java
// 测试代码片段
@SpringBootTest
class ConnectionPoolBenchmark {
@Autowired
private DataSource dataSource;
@Test
void testMixedWorkload() throws Exception {
ExecutorService executor = Executors.newFixedThreadPool(200);
List<Future<Long>> futures = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
futures.add(executor.submit(() -> {
long start = System.currentTimeMillis();
try (Connection conn = dataSource.getConnection()) {
// 70%概率执行短查询
if (ThreadLocalRandom.current().nextDouble() < 0.7) {
executeShortQuery(conn);
} else {
executeLongQuery(conn);
}
}
return System.currentTimeMillis() - start;
}));
}
// 统计结果...
}
}代码清单6:混合场景测试代码
混合场景测试结果:
| 连接池 | 总耗时(ms) | 成功请求 | 失败请求 | 平均延迟 |
|---|---|---|---|---|
| HikariCP | 8450 | 990 | 10 | 8.5ms |
| Druid | 9200 | 985 | 15 | 9.3ms |
5. 配置优化实战
5.1 HikariCP最优配置模板
# application-hikari.yml
spring:
datasource:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/db?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true
username: ${DB_USER}
password: ${DB_PASSWORD}
hikari:
# 连接池大小(核心配置)
maximum-pool-size: 20 # 公式:CPU核数 * 2 + 磁盘数量
minimum-idle: 5 # 最小空闲连接
# 连接生命周期
max-lifetime: 1800000 # 30分钟,MySQL wait_timeout的1/2
connection-timeout: 5000 # 5秒获取连接超时
idle-timeout: 600000 # 10分钟空闲超时
# 连接健康检查
connection-test-query: SELECT 1
validation-timeout: 3000
keepalive-time: 30000 # 30秒保活
# 性能优化
connection-init-sql: SET NAMES utf8mb4
data-source-properties:
cachePrepStmts: true
prepStmtCacheSize: 250
prepStmtCacheSqlLimit: 2048
useServerPrepStmts: true
useLocalSessionState: true
rewriteBatchedStatements: true
cacheResultSetMetadata: true
cacheServerConfiguration: true
elideSetAutoCommits: true
maintainTimeStats: false代码清单7:HikariCP生产配置
配置详解:
-
maximum-pool-size:不是越大越好,要匹配数据库的max_connections -
max-lifetime:要小于数据库的wait_timeout -
keepalive-time:防止连接被数据库主动断开
5.2 Druid最优配置模板
# application-druid.yml
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/db?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai
username: ${DB_USER}
password: ${DB_PASSWORD}
druid:
# 连接池大小
initial-size: 5
min-idle: 5
max-active: 20
# 连接获取
max-wait: 5000
# 连接健康检查
validation-query: SELECT 1
validation-query-timeout: 3000
test-on-borrow: false
test-on-return: false
test-while-idle: true
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
# 监控配置
web-stat-filter:
enabled: true
url-pattern: /*
exclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*"
stat-view-servlet:
enabled: true
url-pattern: /druid/*
reset-enable: false
login-username: admin
login-password: admin
# 监控过滤器
filters: stat,wall,slf4j
filter:
stat:
enabled: true
log-slow-sql: true
slow-sql-millis: 1000
wall:
enabled: true
config:
delete-allow: false
drop-table-allow: false代码清单8:Druid生产配置
关键区别:
-
Druid有
initial-size,HikariCP没有 -
Druid支持更复杂的健康检查策略
-
Druid的监控配置更丰富
6. 监控与诊断
6.1 HikariCP监控
HikariCP监控相对简单,但够用:
java
@Component
public class HikariMonitor {
@Autowired
private HikariDataSource dataSource;
@Scheduled(fixedDelay = 30000)
public void monitorHikari() {
HikariPoolMXBean pool = dataSource.getHikariPoolMXBean();
Map<String, Object> metrics = new HashMap<>();
metrics.put("activeConnections", pool.getActiveConnections());
metrics.put("idleConnections", pool.getIdleConnections());
metrics.put("threadsAwaitingConnection", pool.getThreadsAwaitingConnection());
metrics.put("totalConnections", pool.getTotalConnections());
// 发送到监控系统
sendToMonitoringSystem(metrics);
// 预警逻辑
if (pool.getThreadsAwaitingConnection() > 10) {
alert("连接池等待线程过多: " + pool.getThreadsAwaitingConnection());
}
if ((double) pool.getActiveConnections() / dataSource.getMaximumPoolSize() > 0.8) {
alert("连接池使用率超过80%");
}
}
}代码清单9:HikariCP监控代码
6.2 Druid监控
Druid的监控强大得多:
java
@RestController
@RequestMapping("/api/monitor")
public class DruidMonitorController {
@Autowired
private DruidDataSource dataSource;
@GetMapping("/datasource")
public Map<String, Object> getDataSourceStats() {
DruidDataSourceStatValue statValue = dataSource.getStatValue();
Map<String, Object> stats = new HashMap<>();
stats.put("name", statValue.getName());
stats.put("activeCount", statValue.getActiveCount());
stats.put("activePeak", statValue.getActivePeak());
stats.put("poolingCount", statValue.getPoolingCount());
stats.put("poolingPeak", statValue.getPoolingPeak());
stats.put("connectCount", statValue.getConnectCount());
stats.put("closeCount", statValue.getCloseCount());
stats.put("waitThreadCount", statValue.getWaitThreadCount());
// SQL统计
List<Map<String, Object>> sqlStats = new ArrayList<>();
for (Object sqlStat : statValue.getSqlList()) {
if (sqlStat instanceof JdbcSqlStatValue) {
JdbcSqlStatValue sql = (JdbcSqlStatValue) sqlStat;
Map<String, Object> sqlMap = new HashMap<>();
sqlMap.put("sql", sql.getSql());
sqlMap.put("executeCount", sql.getExecuteCount());
sqlMap.put("executeTimeMillis", sql.getExecuteTimeMillis());
sqlMap.put("slowCount", sql.getSlowCount());
sqlStats.add(sqlMap);
}
}
stats.put("sqlStats", sqlStats);
return stats;
}
@GetMapping("/slow-sql")
public List<Map<String, Object>> getSlowSql() {
List<Map<String, Object>> slowSqlList = new ArrayList<>();
Map<String, Object> statMap = dataSource.getSqlStatMap();
for (Object value : statMap.values()) {
if (value instanceof JdbcSqlStat) {
JdbcSqlStat sqlStat = (JdbcSqlStat) value;
if (sqlStat.getSlowCount() > 0) {
Map<String, Object> slowSql = new HashMap<>();
slowSql.put("sql", sqlStat.getSql());
slowSql.put("slowCount", sqlStat.getSlowCount());
slowSql.put("totalTime", sqlStat.getExecuteMillisTotal());
slowSqlList.add(slowSql);
}
}
}
return slowSqlList;
}
}代码清单10:Druid监控接口
7. 故障排查实战
7.1 连接泄露检测
这是最常见的问题,两种连接池的检测方式:
HikariCP泄露检测:
# application.yml
spring:
datasource:
hikari:
leak-detection-threshold: 30000 # 30秒
java
// HikariCP会在连接借用超过阈值时记录警告
// 日志示例:
// Connection leak detection triggered for connection, stack trace follows
// java.lang.Exception: App connection leak detectionDruid泄露检测:
spring:
datasource:
druid:
remove-abandoned: true
remove-abandoned-timeout: 300 # 300秒
log-abandoned: trueDruid的检测更强大,能自动回收泄露连接。
7.2 连接池满的排查
连接池满了怎么排查?看这个流程:
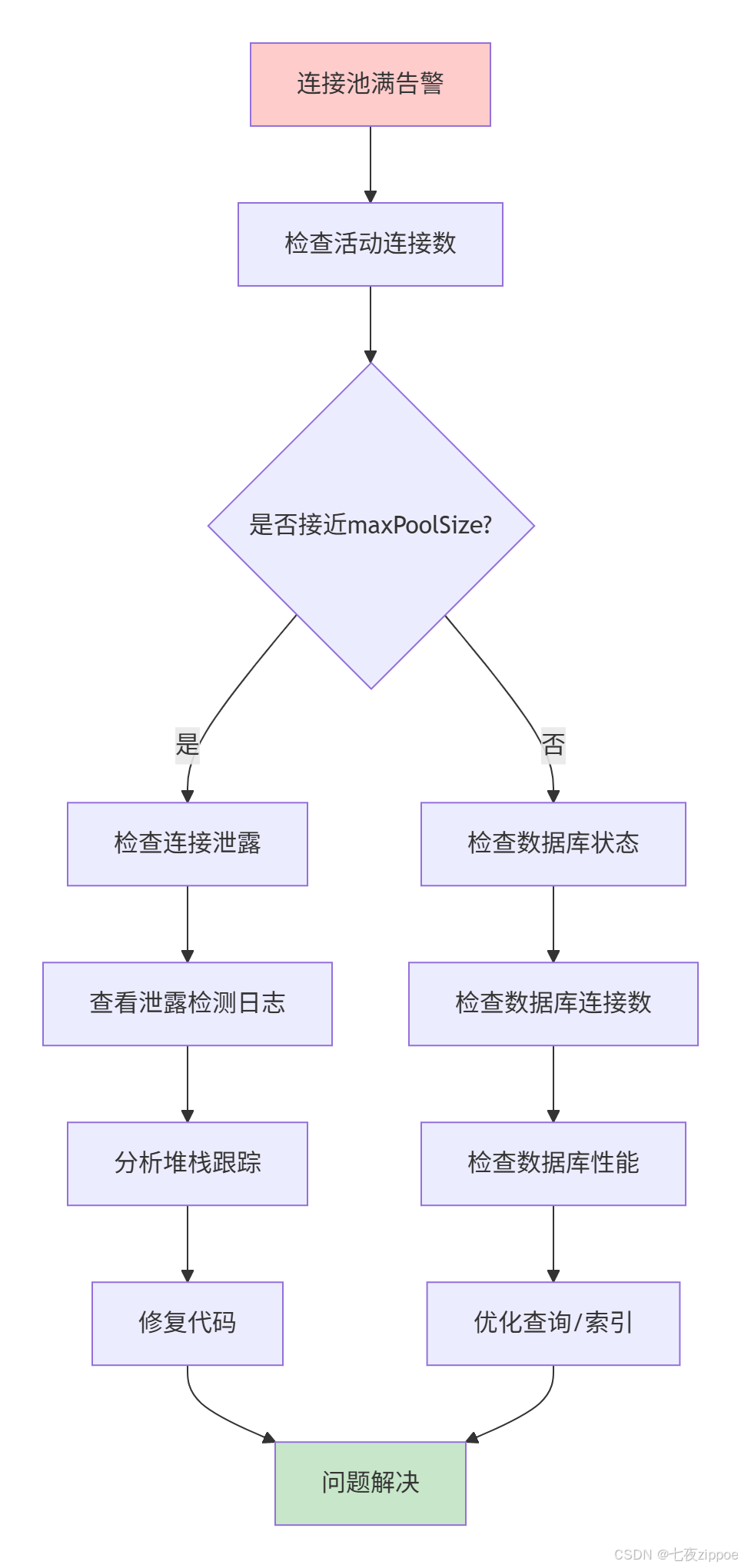
图5:连接池满排查流程
具体排查命令:
sql
-- 1. 查看数据库当前连接
SHOW PROCESSLIST;
SHOW STATUS LIKE 'Threads_connected';
-- 2. 查看数据库最大连接数
SHOW VARIABLES LIKE 'max_connections';
-- 3. 查看连接状态
SELECT * FROM information_schema.processlist
WHERE COMMAND != 'Sleep'
ORDER BY TIME DESC;7.3 性能下降排查
连接池性能下降的可能原因:
java
// 诊断工具类
@Component
public class ConnectionPoolDiagnoser {
public void diagnose(HikariDataSource dataSource) {
HikariPoolMXBean pool = dataSource.getHikariPoolMXBean();
System.out.println("=== HikariCP诊断报告 ===");
System.out.printf("活动连接: %d/%d%n",
pool.getActiveConnections(),
dataSource.getMaximumPoolSize());
System.out.printf("空闲连接: %d%n", pool.getIdleConnections());
System.out.printf("等待线程: %d%n", pool.getThreadsAwaitingConnection());
System.out.printf("总连接: %d%n", pool.getTotalConnections());
// 连接获取时间统计
if (dataSource.getMetricRegistry() != null) {
Timer timer = dataSource.getMetricRegistry()
.getTimers()
.get("hikari.pool.Wait");
if (timer != null) {
System.out.printf("平均获取时间: %.2fms%n",
timer.getMean() / 1000000);
System.out.printf("P95获取时间: %.2fms%n",
timer.getSnapshot().get95thPercentile() / 1000000);
}
}
}
}代码清单11:连接池诊断工具
8. 企业级实践案例
8.1 电商系统实战
我们有个电商系统,大促时遇到的问题和解决方案:
问题:订单提交时连接池满,用户下单失败。
分析:
-
订单提交涉及多个数据库操作
-
事务时间过长,连接占用久
-
突发流量导致连接不够用
解决方案:
java
@Service
public class OrderService {
// 优化前:一个事务包含所有操作
@Transactional
public void createOrder(OrderDTO order) {
// 1. 创建订单(50ms)
orderDao.insert(order);
// 2. 扣减库存(100ms)
inventoryService.reduce(order.getItems());
// 3. 记录日志(50ms)
logService.recordOrder(order);
// 总耗时:200ms,连接占用200ms
}
// 优化后:拆分事务,缩短连接占用时间
public void createOrderOptimized(OrderDTO order) {
// 1. 快速创建订单(短事务)
createOrderQuickly(order);
// 2. 异步处理其他操作
CompletableFuture.runAsync(() -> {
inventoryService.reduce(order.getItems());
});
CompletableFuture.runAsync(() -> {
logService.recordOrder(order);
});
}
@Transactional(timeout = 5) // 5秒超时
public void createOrderQuickly(OrderDTO order) {
orderDao.insert(order);
}
}代码清单12:电商订单服务优化
优化效果:
-
连接占用时间:200ms → 50ms
-
支持并发:1000 → 4000
-
连接池大小:50 → 20(减少60%资源)
8.2 监控告警配置
生产环境必须配置告警:
# prometheus告警规则
groups:
- name: connection_pool_alerts
rules:
- alert: ConnectionPoolHighUsage
expr: spring_hikari_connections_active / spring_hikari_connections_max > 0.8
for: 5m
labels:
severity: warning
annotations:
summary: "连接池使用率过高"
description: "连接池使用率超过80%,当前值: {{ $value }}%"
- alert: ConnectionWaitTimeout
expr: rate(spring_hikari_connections_timeout_total[5m]) > 0
labels:
severity: critical
annotations:
summary: "连接获取超时"
description: "连接获取超时次数增加,可能连接池已满"
- alert: SlowSQLDetected
expr: rate(druid_slow_sql_total[5m]) > 10
labels:
severity: warning
annotations:
summary: "慢SQL数量增加"
description: "过去5分钟慢SQL数量: {{ $value }}"代码清单13:连接池监控告警规则
9. 高级优化技巧
9.1 连接预热
避免冷启动时的性能问题:
java
@Component
public class ConnectionPoolWarmup {
@Autowired
private DataSource dataSource;
@EventListener(ApplicationReadyEvent.class)
public void warmupConnections() {
if (dataSource instanceof HikariDataSource) {
HikariDataSource hikari = (HikariDataSource) dataSource;
int minIdle = hikari.getMinimumIdle();
// 预热连接
ExecutorService executor = Executors.newFixedThreadPool(minIdle);
List<Future<?>> futures = new ArrayList<>();
for (int i = 0; i < minIdle; i++) {
futures.add(executor.submit(() -> {
try (Connection conn = hikari.getConnection();
Statement stmt = conn.createStatement()) {
stmt.execute("SELECT 1");
} catch (SQLException e) {
log.error("预热连接失败", e);
}
}));
}
// 等待所有预热完成
for (Future<?> future : futures) {
try {
future.get();
} catch (Exception e) {
// ignore
}
}
executor.shutdown();
}
}
}代码清单14:连接池预热
9.2 动态调参
根据负载动态调整连接池:
java
@Component
@Slf4j
public class DynamicPoolAdjuster {
@Autowired
private HikariDataSource dataSource;
@Scheduled(fixedDelay = 60000) // 每分钟检查一次
public void adjustPoolSize() {
HikariPoolMXBean pool = dataSource.getHikariPoolMXBean();
int active = pool.getActiveConnections();
int max = dataSource.getMaximumPoolSize();
double usageRate = (double) active / max;
// 使用率持续高,增加连接池
if (usageRate > 0.8) {
int newSize = Math.min(max * 2, 100); // 最多100
dataSource.setMaximumPoolSize(newSize);
log.info("连接池扩容: {} -> {}", max, newSize);
}
// 使用率持续低,缩小连接池
else if (usageRate < 0.3 && max > 10) {
int newSize = Math.max((int)(max * 0.8), 10);
dataSource.setMaximumPoolSize(newSize);
log.info("连接池缩容: {} -> {}", max, newSize);
}
}
}代码清单15:动态连接池调整
10. 选型指南
10.1 什么时候选HikariCP?
选择HikariCP的场景:
-
🚀 追求极致性能
-
📊 监控需求简单
-
🎯 应用稳定,不需要复杂诊断
-
💻 资源受限环境
配置建议:
# 适用:Web应用、微服务
maximum-pool-size: ${CPU核数} * 2
minimum-idle: 5-10
leak-detection-threshold: 3000010.2 什么时候选Druid?
选择Druid的场景:
-
🔍 需要详细监控和诊断
-
🛡️ 需要SQL防火墙
-
📈 需要SQL性能分析
-
🏢 企业级运维需求
配置建议:
# 适用:企业后台、数据分析系统
max-active: 20-50
filters: stat,wall,slf4j
remove-abandoned: true10.3 我的"选型矩阵"
根据项目特点选择:
| 项目特点 | 推荐 | 理由 |
|---|---|---|
| 高性能要求 | HikariCP | 速度最快 |
| 监控需求强 | Druid | 监控功能丰富 |
| 资源紧张 | HikariCP | 内存占用小 |
| 安全要求高 | Druid | 有SQL防火墙 |
| 团队熟悉Spring Boot | HikariCP | 默认集成 |
| 需要SQL分析 | Druid | SQL监控强大 |
11. 最后的话
连接池选型不是非此即彼,关键要匹配业务场景。HikariCP像跑车,追求极致性能;Druid像SUV,功能全面但稍重。
我见过太多团队在这上面犯错:有的在简单系统上用Druid,监控拖慢性能;有的在复杂系统上用HikariCP,出了问题没法排查。
记住:没有最好的连接池,只有最合适的连接池。理解原理,合理配置,持续监控,才是正道。
📚 推荐阅读
官方文档
-
**HikariCP官方文档** - 最权威的参考
-
**Druid官方文档** - 功能最全的文档
性能分析
监控工具
-
**Prometheus监控** - 监控指标收集
-
**Grafana仪表板** - 监控数据展示
性能测试
最后建议 :不要盲目相信默认配置,一定要根据你的业务特点进行调整。做好监控,定期分析,持续优化。记住:连接池调优是个持续的过程,不是一次性的任务。