AddSR: 利用对抗扩散蒸馏技术加速基于扩散模型的盲超分辨率重建
AddSR: Accelerating Diffusion-based Blind Super-Resolution with Adversarial Diffusion Distillation
作者: Ying Tai, Rui Xie∗, Chen Zhao, Kai Zhang, Zhenyu Zhang, Jun Zhou, Jian Yang
发表期刊: Pattern Recognition
论文地址: https://doi.org/10.1016/j.patcog.2025.113012
摘要
基于 Stable Diffusion (SD) 的盲超分辨率(Blind Super-Resolution)方法在从低分辨率 (LR) 输入重建具有丰富细节的清晰、高分辨率 (HR) 图像方面展现了令人印象深刻的生成能力。然而,它们的实际应用往往受限于效率低下,因为它们通常需要数十次甚至上百次的采样步数。受对抗扩散蒸馏 (Adversarial Diffusion Distillation, ADD) 的启发,我们结合这种方法设计了一种极具效能且高效的盲超分辨率方法。尽管如此,仍存在两个挑战:首先,原始 ADD 会显著降低结果的保真度,导致感知-失真(perception-distortion)不平衡。其次,基于 SD 的方法对条件输入的质量非常敏感,而 LR 图像往往具有复杂的退化,这进一步阻碍了修复效果。
为了解决这些问题,我们引入了时间步自适应 ADD (Timestep-Adaptive ADD, TA-ADD),以缓解由原始 ADD 引起的感知-失真不平衡。此外,我们提出了一种**基于预测的自精炼策略(prediction-based self-refinement strategy)**来估计 HR,从而在无需额外模块的情况下提供更多的高频信息。大量实验表明,我们的方法 AddSR 在生成更优修复结果的同时,速度显著快于以往基于 SD 的最先进模型(例如,比 SeeSR 快 7倍)。
代码可见:https://github.com/NJU-PCALab/AddSR。
关键词: 超分辨率,扩散模型,生成先验,效率
1. 引言
盲超分辨率重建 (BSR) 旨在将经过复杂且未知退化的低分辨率 (LR) 图像转换为清晰的高分辨率 (HR) 版本。与退化过程单一且已知的经典超分辨率 1--4 不同,BSR 专为增强现实世界的退化图像而设计,赋予其更高的实用价值。
生成模型(例如生成对抗网络 GAN 和扩散模型)在 BSR 任务中展现出实现真实细节的显著优势。基于 GAN 的模型 5--8 通过对抗训练学习从输入 LR 图像分布到 HR 图像分布的映射。然而,在处理具有复杂纹理的自然图像时,由于对抗目标的不稳定 7, 9,它们往往难以生成令人满意的视觉结果。最近,扩散模型 (DM) 10--14 因其强大的生成能力以及结合多模态信息的能力而备受关注。基于 DM 的 BSR 方法大致可分为两类:不含 Stable Diffusion (SD) 先验的方法 15, 16 和包含 SD 先验的方法 17--19。SD 先验可以显著增强模型捕捉自然图像分布的能力 20,从而使生成的 HR 图像具有真实的细节。鉴于 DM 的迭代细化特性,基于扩散的方法通常优于基于 GAN 的方法,尽管是以牺牲效率为代价的。虽然已经提出了几种加速策略 21, 22,但由于忽略了感知-失真权衡,它们并不适用于 BSR 设置。因此,迫切需要能在现实应用中提供卓越修复质量同时保持高效率的 BSR 模型。
为了实现上述目标,我们从对抗扩散蒸馏 (ADD) 21 中汲取灵感,并将其引入 BSR 任务。然而,仍然存在两个关键挑战:1) 感知-失真不平衡 23--25:在 BSR 任务中直接应用 ADD 会导致保真度降低,引起感知-失真不平衡,从而损害有效性。2) 高频细节的高效修复:条件输入的质量会显著影响修复结果 26。以往基于 SD 的方法 17, 19 依赖于额外的退化去除模块来预处理 LR 图像以进行调节,这阻碍了效率。因此,高效地获取具有更多高频信号的条件输入来指导修复,是实现高效且有效的盲超分辨率 (BSR) 的关键挑战。
在本文中,我们提出了一种基于 ADD 的新型 AddSR,用于盲超分辨率重建,它在增强修复效果的同时加快了基于 SD 模型的推理速度。AddSR 中有两个关键设计来分别解决上述问题:1) 我们引入了时间步自适应对抗扩散蒸馏 (TA-ADD) 损失,该损失设计了一个与时间步相关的二元权重函数,以实现感知-失真平衡,在较小的推理步数下增强生成能力,而在较大的推理步数下减弱生成能力。2) 我们提出了一种简单而有效的策略------基于预测的自精炼 (PSR),它使用从预测噪声中估计出的 HR 图像来控制模型输出。这种方法能够高效地修复高频组件的条件,并进一步使修复结果包含更多高频细节。我们的主要贡献可以归纳为以下三个方面:
- 据我们所知,所提出的 AddSR 是首个探索利用 ADD 实现高效且有效的盲超分辨率的工作,在提供更佳感知质量的同时,比 SeeSR 18 实现了 7×7\times7× 的加速。
- 我们引入了一种新的 TA-ADD 损失,以解决原始 ADD 带来的感知-失真不平衡问题,使 AddSR 在保持相当保真度的同时生成更优的感知质量。
- 我们提出了一种基于预测的自精炼策略,以高效地修复条件,并使修复结果能够生成更多细节,而无需额外的模块。
2. 相关工作
基于 GAN 的 BSR。 近年来,盲超分辨率 (BSR) 因其其实用性引起了广泛关注。对抗训练 27, 28 被引入 SR 任务中以避免生成过度平滑的结果。BSRGAN 5 设计了一种随机打乱策略来扩大退化空间,用于训练一个综合的 SR 模型。Real-ESRGAN 6 提出了一种更实用的、被称为"高阶"的退化过程来合成真实的 LR 图像。KDSRGAN 29 估计隐式退化表示以辅助修复过程。虽然基于 GAN 的 BSR 方法仅需一步即可修复 LR 图像,但其对复杂自然图像进行超分辨率处理的能力有限。在这项工作中,我们的 AddSR 基于扩散模型无缝地实现了卓越的修复性能,使其成为一个引人注目的选择。
基于扩散模型的 BSR。 扩散模型在图像生成任务(如文本到图像)中展现了显著优势。一种常见的方法 15, 30--32 是从头训练一个非多模态扩散模型,该模型在每一步将 LR 图像与噪声的拼接作为输入。另一种方法 17--20 则充分利用预训练多模态扩散模型(即 SD 模型)的先验知识,这需要训练一个 ControlNet 并结合新的自适应结构(如交叉注意力)。与上述方法相比,基于 SD 的方法因其能有效地整合高层级信息而在性能上表现出色。然而,巨大的参数量和对大量采样步数的需求给现实应用带来了严峻挑战。
高效扩散模型。 已有若干工作 33, 34 被提出以加速 DM 的推理过程。虽然这些方法可以将采样步数从数千步减少到 20∼5020 \sim 5020∼50 步,但修复效果会急剧下降。最近,对抗扩散蒸馏 (ADD) 21 被提出,在保持令人满意的生成能力的同时,实现 1∼41 \sim 41∼4 步推理。然而,ADD 最初是为文本到图像任务设计的。考虑到 BSR 的多方面特性,如图像质量、退化或保真度与真实感之间的权衡,利用 ADD 来加速基于 SD 的 BSR 模型并非易事。相比之下,AddSR 引入了两个关键设计使 ADD 适配 BSR 任务,使其兼具效能与效率。
3. Methodology
3.1. Overview of AddSR
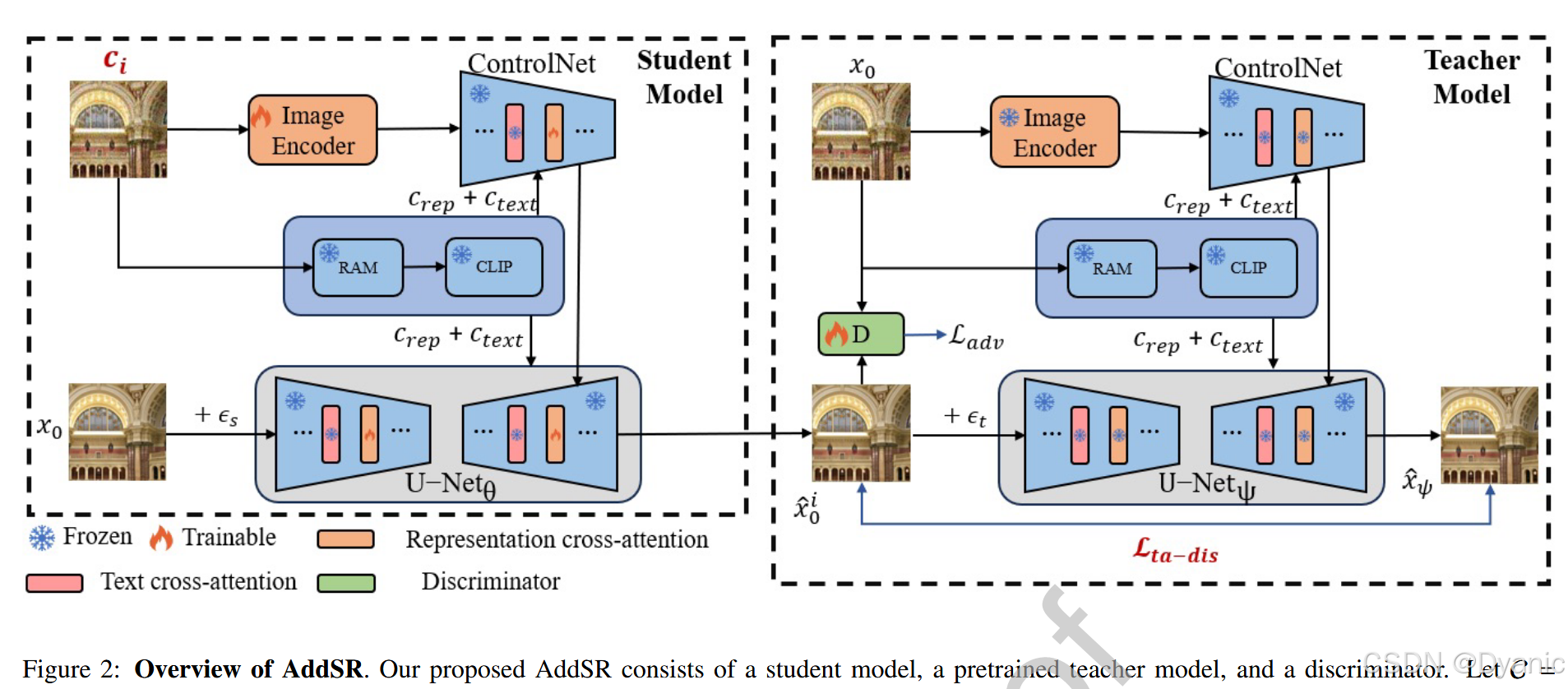
网络组件。 如图 2 所示,AddSR 的训练过程主要由三个部分组成:权重为 θ\thetaθ 的学生模型、权重冻结为 ψ\psiψ 的预训练教师模型,以及权重为 ϕ\phiϕ 的判别器。具体而言,学生模型和教师模型具有相同的结构,且学生模型由教师模型初始化。学生模型结合了一个 ControlNet 35,用于接收 xLRx_{LR}xLR 或预测的 x^0i−1\hat{x}0^{i-1}x^0i−1,以控制 U-Net 的输出。此外,学生模型利用 RAM 36 获取表示嵌入 crepc{rep}crep 以提取高层级信息(即图像内容),并将此信息发送给 CLIP 37 以生成文本嵌入 ctextc_{text}ctext。这些嵌入有助于主干网络(U-Net 和 ControlNet)生成高质量的修复图像。至于判别器,我们遵循 StyleGAN-T 38,并以 DINOv2 39 从 xLRx_{LR}xLR 中提取的 cimgc_{img}cimg 作为条件。
训练程序。
(1) 带有基于预测自精炼的学生模型:首先,我们从 {s1,s2,s3,s4}\{s_1, s_2, s_3, s_4\}{s1,s2,s3,s4}(从 0 到 999 中均匀选取)中随机选择一个学生时间步 sss,并在 HR 图像 x0x_0x0 上执行前向过程以生成噪声状态 xs=αˉsx0+1−αˉsϵx_s = \sqrt{\bar{\alpha}_s} x_0 + \sqrt{1 - \bar{\alpha}s}\epsilonxs=αˉs x0+1−αˉs ϵ。其次,我们将 xsx_sxs 连同条件 cic_ici(C={xLR,x^01,x^02,x^03}C = \{x{LR}, \hat{x}_0^1, \hat{x}0^2, \hat{x}0^3\}C={xLR,x^01,x^02,x^03} 的第 iii 个元素,其中 x^0i−1\hat{x}0^{i-1}x^0i−1 通过 PSR 获取,以减少退化影响并为修复过程提供更多高频信息,详见 3.2 节)、crepc{rep}crep 和 ctextc{text}ctext 输入到学生模型中,生成样本 x^0i(xs,s,crep,ctext,ci)\hat{x}0^i(x_s, s, c{rep}, c{text}, c_i)x^0i(xs,s,crep,ctext,ci)。
(2) 教师模型:首先,我们从 {t1,t2,...,t1000}\{t_1, t_2, \dots, t_{1000}\}{t1,t2,...,t1000} 中等概率选择一个教师时间步 ttt,并对学生生成的样本 x^θ\hat{x}\thetax^θ 执行前向过程,得到噪声状态 x^θ,t=αˉtx^0i+1−αˉtϵ\hat{x}{\theta,t} = \sqrt{\bar{\alpha}t} \hat{x}0^i + \sqrt{1 - \bar{\alpha}t}\epsilonx^θ,t=αˉt x^0i+1−αˉt ϵ。其次,我们将 x^θ,t\hat{x}{\theta,t}x^θ,t 连同条件 x0x_0x0、crep′c'{rep}crep′ 和 ctext′c'{text}ctext′ 输入到教师模型中,生成样本 x^ψ(x^θ,t,t,crep′,ctext′,x0)\hat{x}\psi(\hat{x}{\theta,t}, t, c'{rep}, c'{text}, x_0)x^ψ(x^θ,t,t,crep′,ctext′,x0)。注意,x^ψ\hat{x}\psix^ψ 是以 x0x_0x0 而非 xLRx{LR}xLR 为条件的。主要原因是使用 x0x_0x0 代替 xLRx_{LR}xLR 来调节教师模型的输出,可以迫使学生模型在即使以 cic_ici 为条件时,也能隐式学习 HR 图像的高频信息。
(3) 针对 BSR 任务的时间步自适应 ADD:它由两部分组成:对抗损失和一种新型的时间步自适应蒸馏损失,后者与教师和学生模型的时间步均相关。总体目标函数为:
LTA−ADD=Lta−dis(x^0i(xs,s,ρ,ci),x^ψ(x^θ,t,t,ρ′,x0),d(s,t))+λLadv(x^0i(xs,s,ρ,ci),x0,ψcimg),(1) \mathcal{L}{TA-ADD} = \mathcal{L}{ta-dis}(\hat{x}0^i(x_s, s, \rho, c_i), \hat{x}\psi(\hat{x}{\theta,t}, t, \rho', x_0), \\d(s, t)) + \lambda \mathcal{L}{adv}(\hat{x}0^i(x_s, s, \rho, c_i), x_0, \psi{c_{img}}), \tag{1} LTA−ADD=Lta−dis(x^0i(xs,s,ρ,ci),x^ψ(x^θ,t,t,ρ′,x0),d(s,t))+λLadv(x^0i(xs,s,ρ,ci),x0,ψcimg),(1)
其中 ρ\rhoρ 表示 crepc_{rep}crep 和 ctextc_{text}ctext,ρ′\rho'ρ′ 代表 crep′c'{rep}crep′ 和 ctext′c'{text}ctext′。λ\lambdaλ 是平衡权重,经验性地设置为 0.02。ψcimg\psi_{c_{img}}ψcimg 是以 cimgc_{img}cimg 为条件的判别器。d(s,t)d(s, t)d(s,t) 是由学生时间步 sss 和教师时间步 ttt 定义的权重函数,动态调整 Lta−dis\mathcal{L}{ta-dis}Lta−dis 和 Ladv\mathcal{L}{adv}Ladv 以缓解感知-失真不平衡。进一步的分析见 3.3 节。
3.2. Prediction-based Self-Refinement
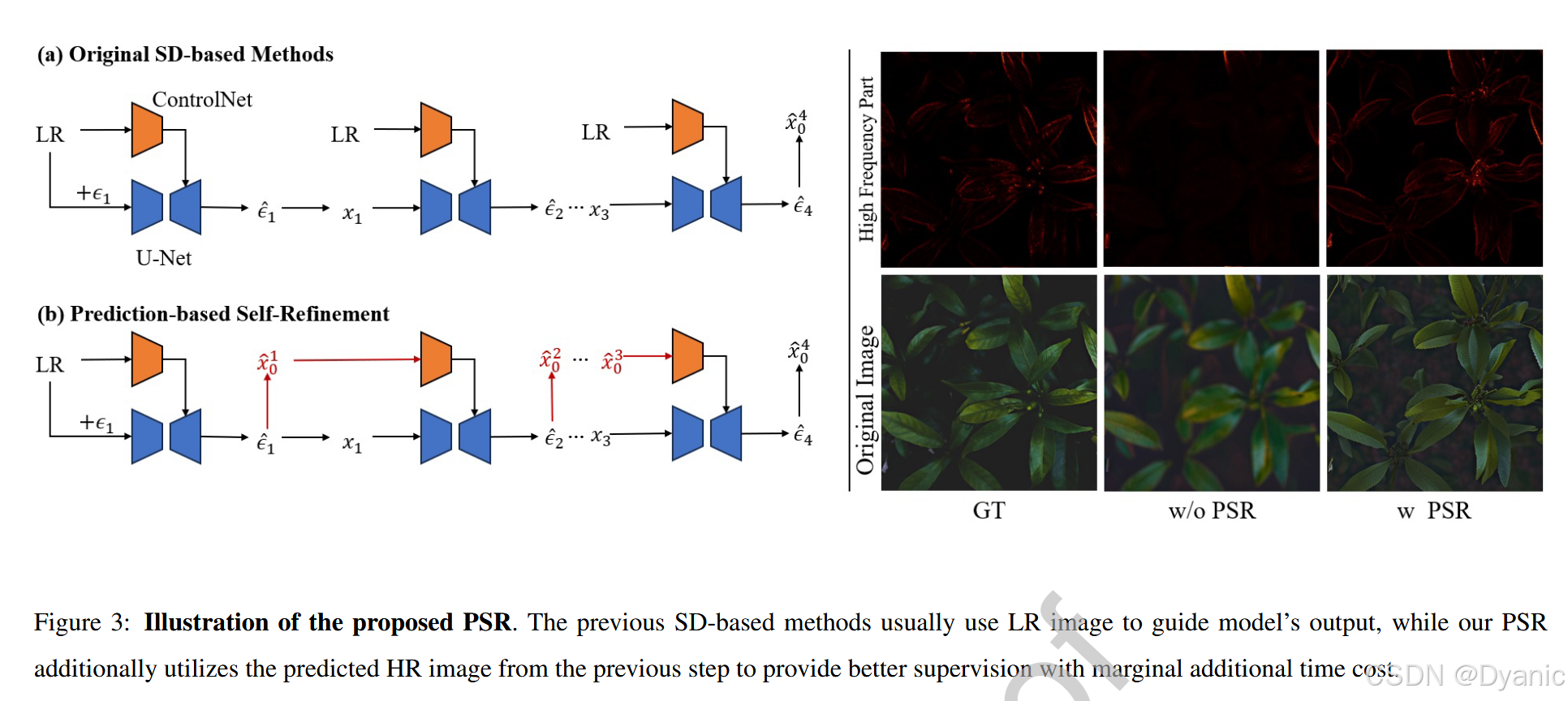
动机。 如图 3 (a) 所示,原始基于 SD 的方法在每个推理步骤中直接使用 LR 图像来控制 DM 的输出。然而,一些研究 17, 19 发现修复结果会受到条件质量的影响,因为 LR 图像通常遭受多种退化,这会显著干扰修复过程(例如,见图 4 第一行)。为了提供更好的条件,这些方法采用额外的退化去除模型来预清洗 LR 图像,旨在减轻退化的影响。然而,此类方法往往会损害效率,阻碍了高效方法的设计。
方法。 为了实现高频细节的高效修复,我们提出了一种新型的基于预测的自精炼(PSR)策略,该策略仅产生极小的效率开销。PSR 的核心思想是利用预测的噪声来估计 HR。具体而言,我们在每一步使用以下公式:
x^0=(xs−1−αsϵθ,s)/αs(2) \hat{x}0 = (x_s - \sqrt{1 - \alpha_s}\epsilon{\theta,s}) / \sqrt{\alpha_s} \tag{2} x^0=(xs−1−αs ϵθ,s)/αs (2)

从预测噪声中估计 HR 图像 x^0\hat{x}0x^0,然后在下一步中控制模型输出,其中 xsx_sxs 是噪声状态,ϵθ,s\epsilon{\theta,s}ϵθ,s 是在时间步 sss 处的预测噪声。每一步中的 x^0\hat{x}_0x^0 拥有更多的高频信息,能更好地控制模型输出(例如,见图 3 右侧及图 4 左侧)。虽然 PSR 没有使用额外的模块来预清洗 LR 图像,但 PSR 估计的 HR 图像表现出优于 LR 图像的质量(图 4 右侧)。通过利用我们简单而有效的 PSR,AddSR 能够捕获带有高频信息的条件,在不牺牲效率的情况下生成具有增强细节的修复结果。更多视觉结果见图 6。
3.3. Timestep-Adaptive ADD
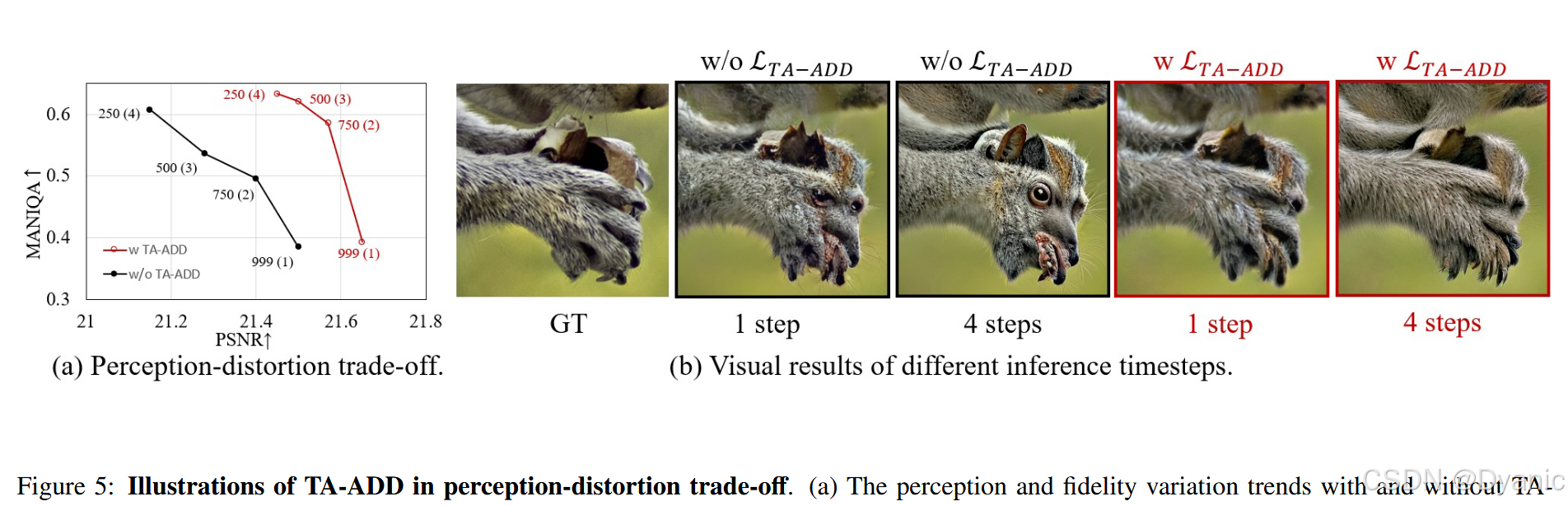
动机。 感知-失真权衡 23 是 SR 任务中众所周知的现象。我们观察到,直接使用 ADD 训练 BSR 任务会加剧这一现象,如图 5(a) 所示。具体而言,在头三个推理步中,保真度显著下降,伴随着感知质量的提升。在最后一个推理步中,保真度保持在较低水平,而感知质量剧烈增加。上述情况可能导致两个问题:(1) 当推理步数较小时,修复图像的质量欠佳。(2) 随着推理步数增加,生成的图像可能会出现"幻觉"。
分析。 主要原因在于 ADD 对不同的学生时间步在 GAN 损失和蒸馏损失上保持一致的权重,如图 7(a) 所示。一旦确定了教师时间步,对抗损失与蒸馏损失的比率对于不同的学生时间步保持不变。然而,由于生成图像的感知质量随推理步数的增加而逐渐提高,权重不变的 ADD 可能会导致在小推理步时对学生模型的对抗约束不足,从而生成模糊图像。相反,随着推理步数增加,对抗训练约束变得过强,导致生成"幻觉"(见图 5(b))。
方法。 为了解决这个问题,我们将原始的一元权重函数 (∏i=0t(1−βi))1/2(\prod_{i=0}^t (1 - \beta_i))^{1/2}(∏i=0t(1−βi))1/2 扩展为二元权重函数 d(s,t)d(s, t)d(s,t),允许根据学生时间步和教师时间步动态调整对抗损失与蒸馏损失的比率,如图 7(b) 所示。具体来说,当仅执行一个推理步时,我们增加该比率,并随着推理步数的增加逐渐减小该比率。这缓解了前述的小推理步生成模糊图像和大推理步产生"幻觉"的问题。我们采用指数形式来控制权重比率。函数 d(s,t)d(s, t)d(s,t) 为:
d(s,t)=(∏i=0t(1−βi))1/2×μ⋅νp(s)−1,(3) d(s, t) = \left( \prod_{i=0}^t (1 - \beta_i) \right)^{1/2} \times \mu \cdot \nu^{p(s)-1}, \tag{3} d(s,t)=(i=0∏t(1−βi))1/2×μ⋅νp(s)−1,(3)
其中 β\betaβ 代表噪声调度系数,ttt 和 sss 分别表示教师和学生时间步。超参数 μ\muμ 设置初始权重比率,而 ν\nuν 控制蒸馏损失随学生时间步的增加量,通常较大的 ν\nuν 会带来更高的保真度。函数 p(⋅)p(\cdot)p(⋅) 作为一个投影函数,将学生时间步映射到推理步(例如,将 s=999s = 999s=999 映射为 1)。我们主要考虑指数和线性形式来控制权重比率。4.6 节提供了不同超参数的详细设置对比。通过这些对比,我们发现指数形式的 d(s,t)d(s, t)d(s,t) 效果良好,因此我们在后续实验中使用公式 (3) 作为蒸馏损失函数。
4. 实验
4.1. 实验设置
训练数据集。 我们采用 DIV2K 40、Flickr2K 41、LSDIR 的前 2 万张图像以及 FFHQ 42 的前 1 万张人脸图像进行训练。我们使用与 Real-ESRGAN 6 相同的退化模型来合成 HR-LR 对。
测试数据集。 我们在 4 个数据集上评估 AddSR:DIV2K-val 40、DRealSR 43、RealSR 44 和 RealLR200 18。我们在 DIV2K-val 上进行 4 种退化类型的测试以全面评估 AddSR,除 RealLR200 外,所有数据集都被裁剪为 512×512512 \times 512512×512 并退化为 128×128128 \times 128128×128 的 LR 图像。
实现细节。 我们采用 SeeSR 18 作为教师模型。注意,我们的方法适用于大多数现有的基于 SD 的 BSR 方法,用于改善修复结果和加速。学生模型由教师模型初始化,并使用 Adam 优化器微调 5 万次迭代。批大小和学习率分别设置为 6 和 2×10−52 \times 10^{-5}2×10−5。AddSR 在 512×512512 \times 512512×512 分辨率下使用 4 张 NVIDIA A100 GPU (40G) 进行训练。
评估指标。 我们采用无参考指标(即 MANIQA 45、MUSIQ 46、CLIPIQA 47)和全参考指标(即 LPIPS 48、PSNR、SSIM 49)来全面评估 AddSR。无参考指标被优先考虑,因为它们与人类感知更加一致。
对比方法。 我们比较了大量的最新 BSR 方法,包括基于 GAN 的方法:BSRGAN 5、Real-ESRGAN 6、MM-RealSR 50、LDL 7、FeMaSR 8 以及基于扩散的方法:StableSR 19、ResShift 15、PASD 20、DiffBIR 17、SeeSR 18。
4.2. 合成数据评估
为了证明所提出的 AddSR 在处理各种退化情况下的优势,我们利用 DIV2K-val 数据集和不同的退化过程合成了 4 个测试数据集。定量结果总结在表 1 中。由于基于 SD 的方法强调感知质量,我们提供了使用感知优先参数的结果。在消融研究(表 10)中,我们展示了平衡参数下的对应结果。结论包括:(1) 我们的 AddSR-4 在 4 种退化情况下均取得了最高的 MANIQA、MUSIQ 和 CLIPIQA 得分。特别是在 MANIQA 上,AddSR 比第二优的方法平均高出 16% 以上。(2) 基于扩散的模型通常在 PSNR、SSIM 和 LPIPS 等全参考指标上得分较低,这可能是因为它们具有强大的生成能力,能够生成 GT 中不存在的逼真细节。然而,全参考指标并不能精确反映人类偏好(见图 8),如 51, 52 所讨论。(3) AddSR-1 可以生成与除 SeeSR 之外的其他基于 SD 的方法相当的结果,但显著减少了采样步数(即从 ≥15\ge 15≥15 步减少到仅 1 步)。
为了更直观地比较,我们在图 9 中提供了视觉结果。可以看到,像 FeMaSR 这样的基于 GAN 的方法无法为展示的三张 LR 图像重建清晰且细节丰富的 HR 图像。至于基于 SD 的方法 DiffBIR,它倾向于生成错误的纹理。这主要是因为 DiffBIR 使用一个退化去除结构来去除 LR 图像的退化。然而,处理后的 LR 图像是模糊的,这可能导致模糊的结果。得益于我们提出的 PSR,AddSR 使用预测的 x^0i−1\hat{x}_0^{i-1}x^0i−1 来控制模型输出,它具有更多的高频信息且几乎不需要额外的时间成本。借助 TA-ADD,AddSR 能够生成精确的图像和丰富的细节。简而言之,AddSR 生成的图像比最先进的模型具有更好的感知质量,同时需要更少的推理步骤和更少的时间。
此外,我们在表 2 中提供了与 SOTA 感知方法 SUPIR 51 的比较,其中详细列出了参数、推理时间、训练资源、训练数据和指标。如表所示,SUPIR 展现出比 AddSR 更好的感知质量。然而,AddSR 在模型大小、推理时间、保真度、感知质量和训练资源消耗之间取得了更好的平衡。虽然 SUPIR 展现了强大的修复能力,但在某些退化场景下仍可能失败,如图 10 的第一个示例所示。此外,由于其强大的生成能力,修复结果可能包含与原始 LR 图像不一致的细节,例如图 10 中第二个示例的纹理和第三个示例的英文字母。
4.3. 真实世界数据评估
表 3 展示了在 3 个真实世界数据集上的定量结果。我们可以看到,AddSR 在 MANIQA、MUSIQ 和 CLIPIQA 指标上均取得了最高得分,这与合成退化情况相同。这表明 AddSR 具有出色的泛化能力,能够处理未知的复杂退化,使其在现实场景中具有实用价值。此外,AddSR-1 优于基于 GAN 的方法,这主要归功于扩散模型与对抗训练的结合。这种结合使 AddSR 能够利用预训练扩散模型的强大先验并注入高层级信息,从而增强修复过程,即使在单步推理中也能生成高质量的感知图像。
图 11 和图 12 展示了可视化结果。我们展示了建筑和人脸的示例,以全面比较各种方法。一个明显的观察结果是,AddSR 生成的线条更清晰、更规则,这在第一个建筑示例的线性图案中得到了证明。在第二个示例中,原始 LR 图像退化严重,FeMaSR 和 ResShift 未能生成人脸,仅显示了模糊的人脸轮廓。DiffBIR 能够生成更多细节,但仍然不清晰。SeeSR 生成的图像存在伪影。相反,我们的 AddSR 可以在单步推理中生成与 FeMaSR 和 ResShift 相当的结果。随着推理步数的增加,AddSR 生成了更清晰、细节更丰富的人脸,显著优于上述方法。
提示引导的修复。 扩散模型的优势之一是可以与文本结合。在图 13 中,我们展示了我们的 AddSR 能够通过结合手动提示,在 4 步内高效地实现更精确的修复结果。即,我们可以手动输入 LR 图像的文本描述来辅助修复过程。具体来说,图 13(a) 展示了使用 RAM 提示修复图像中的格子衬衫可以通过手动提示修改为迷彩图案。在图 13(b) 中,使用原始 RAM 提示修复的蜘蛛侠具有嘴巴和胡须,而手动提示准确修复了穿着蜘蛛网套装的人。图 13© 显示,使用手动提示可以将芯片上的文本从 '2ALC515' 更正为 '24LC515'。最后,图 13(d) 说明,虽然 RAM 提示清晰地渲染了树枝,但手动提示保留了蘑菇预期的背景模糊效果,与真实情况相符。
4.4. 与其他高效方法的比较
我们与几种其他高效方法 30, 53 以及 SeeSR 18 和 StableSR 19 的 Turbo 版本进行了定量比较,如表 4 所示。AddSR-1 在 RealLR200 上的 MANIQA 和 MUSIQ 指标,以及 DrealSR 上的 PSNR、SSIM 和 MANIQA 指标上均取得了相当的性能。AddSR-1 没有超过其他高效方法的主要原因是,那些方法是专门为单步推理训练的,这使得它们在单步设置中具有优势。相比之下,AddSR 提供了更大的灵活性,允许应用多个推理步。如表 4 所示,AddSR-2 在 RealLR200 和 DrealSR 数据集上的 MANIQA 和 MUSIQ 指标上优于其他高效方法。此外,AddSR-4 在 MANIQA 和 MUSIQ 指标上均取得了最佳结果。
我们在图 14 中也展示了定性比较。AddSR-1 的视觉结果与其他高效方法相当。得益于 AddSR 的灵活性,我们可以执行多个推理步。AddSR-2 和 AddSR-4 生成的图像比其他高效方法更清晰、更逼真。
4.5. 复杂度分析
我们在表 5 中比较了基于扩散的方法的推理步数和运行时间。运行时间是在一块 A100 GPU 上计算的。通过比较,我们可以得出以下观察结果:1) SinSR 在所有单步方法中具有最快的运行时间,因为它不是基于 SD 的方法,并且总的网络参数较少。2) 在基于 SD 的方法中,OSEDiff、S3Diff 和 AddSR 在单步推理中的运行时间相似,因为它们的网络结构相似。
4.6. 消融研究
改进训练过程的有效性。 为了丰富教师模型提供的信息,我们改进了训练过程,将输入的 LR 图像替换为 HR 图像作为 ControlNet、RAM 和 CLIP 的输入。由于我们采用 SeeSR 作为基线,我们也将其 RAM 输入的 LR 图像替换为 HR 图像。定量结果如表 6 所示。在 HR 输入的监督下,修复图像的感知质量变得更好。
时间步自适应 ADD 形式的比较。 为了确定时间步自适应 ADD 的最佳设置,我们对其不同形式进行了实验:指数形式和线性形式。具体而言,指数形式定义如公式 (3),而线性形式定义如下:
d(s,t)=(∏i=0t(1−βi))1/2×(γ⋅p(s)+κ)(4) d(s, t) = \left( \prod_{i=0}^t (1 - \beta_i) \right)^{1/2} \times (\gamma \cdot p(s) + \kappa) \tag{4} d(s,t)=(i=0∏t(1−βi))1/2×(γ⋅p(s)+κ)(4)
其中,超参数 κ\kappaκ 设置初始权重比率,而 γ\gammaγ 控制蒸馏损失随学生时间步的增加量。不同设置下指数和线性形式的定量结果分别列于表 7 和表 8。表中不同形式的最佳设置以灰色背景高亮显示。从这些表中,我们可以得出以下结论:(1) 指数形式的最佳结果优于线性形式。因此,我们使用公式 (3) 作为蒸馏损失函数。此外,当 μ=0.5\mu = 0.5μ=0.5 和 ν=2.1\nu = 2.1ν=2.1 时,我们在保持良好保真度的同时实现了最佳感知质量,因此我们对公式 (3) 使用此设置。(2) 增加控制蒸馏损失比率的超参数(即 ν\nuν 和 γ\gammaγ)通常会导致更高的保真度。例如,当我们固定 μ\muμ 为 0.5 并增加 ν\nuν 时,4 步推理的总体趋势显示感知质量下降,保真度提高。因此,我们可以通过调整 ν\nuν 来实现感知-失真权衡。
TA-ADD 在平衡感知和保真度方面的有效性。 所提出的 TA-ADD 旨在平衡修复图像的感知和保真度质量。定量结果如表 9 所示。尽管我们在后期的推理步骤中增加了蒸馏损失的权重,但感知质量仍然有所提高。这可能归因于初始步骤产生了足够高感知质量的图像,当与 PSR 结合时,提供了更多信息丰富的线索。因此,后期的推理步骤可以实现高感知质量。
此外,我们可以调整 TA-ADD 中的超参数和推理步数,以实现具有竞争力的 PSNR 和 SSIM 结果,同时在感知质量方面表现出色。我们主要比较了在保真度(基于 GAN 的 Real-ESRGAN)和感知质量(SeeSR)方面领先的方法。如表 10 所示,与 SeeSR 相比,我们的方法显著提高了感知质量,同时也提供了更好的保真度。与 Real-ESRGAN 相比,我们的方法在保持相当保真度的同时,显示出感知质量的大幅提升。这表明 TA-ADD 有效地驾驭了感知-保真度权衡。具体而言,我们进行了以下调整:1) 在训练期间,TA-ADD 使用较大的 μ\muμ 和 ν\nuν 值(μ=0.7,ν=2.1\mu=0.7, \nu=2.1μ=0.7,ν=2.1),以及 2) 较少的推理步数(2 步)以实现高保真度结果。
视觉结果如图 15 右侧所示。对于上面的 3 张图像,内容是雕像。然而,在没有 TA-ADD 的情况下,模型将其手幻觉为鸟。对于下面的 3 张图像,原始背景是岩石。同样,如果不利用 TA-ADD,AddSR 可能会将背景幻觉为狼的眼睛。相反,在 TA-ADD 的帮助下,修复图像可以生成与 GT 更一致的内容。TA-ADD 约束模型不过度利用其生成能力,从而在图像内容中保留更多信息,与 GT 紧密对齐。具体而言,使用 TA-ADD,上图雕像手的纹理保持不变,下图背景保留了岩石的失焦外观。
PSR 的有效性。 如表 9 所示,结合 PSR 显著提高了感知质量,而计算成本极低。包括 MANIQA、MUSIQ 和 CLIPIQA 在内的所有三个感知指标在两个流行的真实世界数据集 RealLR200 和 DrealSR 上都有所提高。此外,我们使用额外的退化去除模型来替代 PSR 以展示 PSR 的有效性。遵循 StableSR 19 和 DiffBIR 17,我们使用 Real-ESRGAN 6 或 SwinIR 54 来替代 PSR。定量结果如表 11 所示。我们发现使用 Real-ESRGAN 或 SwinIR 可以获得与我们提出的 PSR 相当的结果。然而,使用 Real-ESRGAN 或 SwinIR 会牺牲效率,因为它需要额外的退化去除模型。
我们还尝试将 PSR 应用于其他基于 SD 的方法而无需微调。然而,我们发现直接将 PSR 应用于现有的基于 SD 的方法通常会导致输出崩溃。这种现象的主要原因可以总结如下:1) 其他基于 SD 的方法通常需要数十个步骤,这导致最初预测的 HR 图像显著偏离真实值 (GT)。随着去噪过程的进行,这些误差会累积,最终导致最终结果出现显著偏差。2) 由于缺乏微调,ControlNet 输入的预测 HR 图像的分布与预训练期间使用的 LR 图像有显著差异。这种差异使得模型无法有效地处理这种条件,最终导致最终输出崩溃。
5. 推理策略
在本节中,我们将讨论不同推理策略对 AddSR 的影响。我们主要考虑两个方面:1) 混合 PSR,如 5.1 节所述;2) 不同正面提示的影响,如 5.2 节所探讨。
5.1. 混合基于预测的自精炼
为了减轻由预测的 HR 图像引起的误差累积,我们可以使用 LR 图像和预测的 HR 图像的混合来控制模型输出,而不是仅仅依赖预测的 HR 图像。这种方法可以表述如下:
xmix=rx^0i−1+(1−r)xLR(5) x_{mix} = r\hat{x}0^{i-1} + (1 - r)x{LR} \tag{5} xmix=rx^0i−1+(1−r)xLR(5)
其中 xmixx_{mix}xmix 表示 x^0i−1\hat{x}0^{i-1}x^0i−1 和 xLRx{LR}xLR 的混合,rrr 是混合比率。如表 12 所示,比率为 0 表示仅使用 LR 图像作为 ControlNet 输入,而比率为 1 表示仅使用预测的 HR 图像作为 ControlNet 输入。基于表中的结果,我们可以得出以下结论:1) 增加混合比率,即增加预测 HR 图像的比例,可以提高感知质量。这可以通过两个真实世界数据集上 MANIQA、MUSIQ 和 CLIPIQA 指标随比率增加而逐渐提高来证明。这种改善可归因于预测的 HR 图像中的高频信息,它丰富了修复结果的细节。2) 保真度随着混合比率的增加而降低。具体而言,DrealSR 数据集上的 PSNR 和 SSIM 指标随着混合比率的增长而下降。主要原因是,虽然预测的 HR 图像包含更多高频信息,但它可能会引入 LR 图像中不存在的细节。这些误差在去噪过程中累积,最终损害了保真度。
视觉结果如图 16 所示。随着混合比率的增加,结果变得更清晰,如第一行和第三行的示例所示。然而,过高的比率也可能引入误差。例如,在第二行和第四行中,虽然结果看起来更清晰、更逼真,但某些细节偏离了原始 LR 图像,如第四行示例中更细的字体。
5.2. 正面提示的影响
由于 AddSR 在推理过程中不使用无分类器引导 55,我们的分析主要集中在正面提示的影响上。遵循 StableSR 19,我们比较了三种设置:1) 无正面提示,记为 \[\];2) "清晰、高分辨率、8k、极其详细、最佳质量、锐利",记为 1;以及 3) "好照片",记为 2。如表 13 所示,使用正面提示 1 略微提高了感知质量指标,但损害了结果的保真度,这与使用正面提示 2 的效果相似。主要原因是带有正面提示的修复结果生成了更清晰的细节,提高了感知质量指标,但偏离了原始 LR 图像,降低了保真度。如图 17 所示,使用正面提示 1 有助于 SR 模型更好地去除退化(例如,第一个示例)并生成更准确的结构,例如第二个示例中狗的眼睛。
6. 讨论
在本节中,我们提供了 ADD、SeeSR 和我们提出的 AddSR 之间的比较。它们的架构图如图 18 所示。首先,ADD 和 AddSR 之间的区别主要体现在两个方面:1) ControlNet 的引入 :ADD 最初是为文本到图像任务开发的,通常仅接受文本作为输入。相比之下,AddSR 是一个图像到图像模型,需要额外的 ControlNet 来接收来自 LR 图像的信息。2) 感知-失真权衡:ADD 旨在从文本生成逼真的图像。然而,将 ADD 引入盲 SR 会带来感知-失真不平衡问题(请参阅我们提交文件中的 3.4 节),这一问题已通过我们在 AddSR 中提出的时间步自适应 ADD 得到解决。
其次,SeeSR 和 AddSR 之间的关键区别在于:1) 蒸馏的引入 :SeeSR 是基于需要 50 个推理步骤的原版 SD 模型训练的,而 AddSR 利用教师模型蒸馏出一个高效的学生模型,仅需 1∼41 \sim 41∼4 步。2) 高频信息 :SeeSR 使用 LR 图像 yyy 作为 ControlNet 的输入。相比之下,AddSR 一方面采用 HR 图像 x0x_0x0 作为教师模型 ControlNet 的输入,以提供高频信号,因为推理过程中不需要教师模型。另一方面,AddSR 提出了一种新颖的基于预测的自精炼(PSR),通过用预测图像替换 LR 图像作为学生模型 ControlNet 的输入,进一步提供高频信息。因此,AddSR 能够生成具有更真实细节的结果。
7. 结论
在本文中,我们提出了 AddSR,这是一种有效且高效的框架,它将 Stable Diffusion 先验应用于盲超分辨率。
(优势) 为了解决原始 ADD 固有的感知-失真不平衡问题,我们引入了时间步自适应 ADD (TA-ADD),它在不同的学生时间步上动态地为 GAN 和蒸馏损失分配不同的权重。与目前依赖静态 LR 图像或外部预清洗模块的基于 SD 的方法不同,我们的方法实现了基于预测的自精炼 (PSR) 策略。通过用前一步估计的 HR 图像替换 LR 图像,AddSR 为教师模型提供了更丰富的高频信息和更强的监督信号。大量实验表明,这种方法在仅 1∼41 \sim 41∼4 步内就能生成具有增强纹理和边缘的卓越结果。
局限性与未来工作。 虽然 AddSR 显著加速了基于 SD 的推理,但由于 SD 主干网络的庞大参数,其计算量仍然比轻量级 GAN 要大。未来的工作将致力于通过模型量化和简化架构来缩小这一效率差距,并将我们的自适应框架扩展到视频超分辨率领域。