
细粒度识别准确率低?完整原文见链接:如何提升 VLM 的细粒度识别能力呢?
视觉语言模型在图像描述、图文检索等任务中展现了强大的通用视觉识别能力。但当面对"苹果手机"与"三星手机"这类细微差异时,它的回答可能就不那么靠谱了。
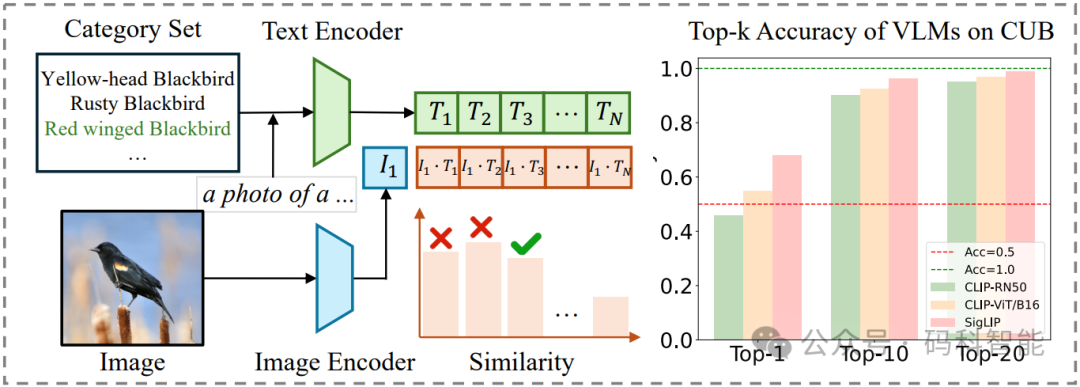
以业界标杆CLIP为例,其表现揭示了一个惊人反差:在CIFAR10粗粒度数据集上达到90%准确率,而在CUB-200鸟类细粒度数据集上骤降至仅50%。即使是专攻细粒度的SigLIP,在CUB-200上的表现也止步于70%左右。
更深入的分析揭示了一个关键发现:虽然这些模型的Top-1准确率不尽如人意,但它们的Top-10准确率却能突破90%。这意味着VLM能够圈定正确范围,却难以在相似选项中做出最终抉择。
那如果把模型换成你,你会怎么处理?人类通常不会直接给出答案,而是经历一个自然的认知过程:首先是快速筛查,先确定这大概是某种鸟,然后再精细观察"喙的形状、羽毛纹路",通过细微特征的比对做出最终判断。
这一过程恰好对应认知科学中的"双系统理论":系统1:直觉快速,基于经验快速反应,但容易出错,系统2:深思熟虑,通过逻辑分析做出精准判断,但需要时间。
而当前VLM的表现完美对应了"系统1"的特征:能够快速识别出合理的候选类别子集,却缺乏"系统2"的精细辨别能力,导致在相似类别间频繁出错。
来自四川大学与南洋理工大学的研究团队提出了一种无需训练、不依赖标注数据或是参考样本、在推理时即插即用的 VLM 增强方法,从而补上精细思考模块,实现从大致正确到精确识别的跨越。
论文及源码可查看原文:VLM细粒度识别新范式!