
摘要
本文提出一种创新框架,将率失真理论与最优传输几何应用于教育知识图谱构建。通过Fused Gromov-Wasserstein距离量化语义失真,结合迭代优化操作,系统能从非结构化讲义中生成高质量、信息保真的知识图谱,显著提升AI生成的选择题质量,为个性化教育和AI辅助教学提供了理论基础。
阅读原文或https://t.zsxq.com/739Qt获取原文pdf和自制中文资料
一、研究背景:AI教育助手的质量困境
1.1 AI驱动的教育问题生成
人工智能驱动的学习助手(AILA)系统能够从教学材料(如讲义和幻灯片)中自动生成教育问题,特别是选择题(MCQs)。这种技术为教育工作者节省了大量时间和精力。

然而,尽管便利性显著,大型语言模型(LLM)生成的选择题存在严重的质量问题,包括:
-
幻觉现象
:生成不存在的知识点
-
事实错误
:内容与源材料不符
-
问题平庸
:缺乏认知挑战性
-
选项模糊
:答案界定不清
-
干扰项过于简单
:降低题目区分度
1.2 知识图谱的潜在价值
最近的研究表明,将知识图谱(KGs)与大型语言模型集成,能显著提高LLM驱动答案的事实准确性、可解释性和推理能力。基于这一洞察,研究团队提出将知识图谱整合到AILA系统中,以增强选择题的生成质量。
特别重要的是,研究者致力于构建面向任务的知识图谱,采用一套基于教学法的关系,如:
-
prerequisite-of (前置依赖)
-
contrastingWith (对比关系)
-
example-of (实例关系)
这些关系使课程感知的问题生成既具有认知参与性,又具有智力挑战性。
二、核心挑战:完整性与复杂性的平衡
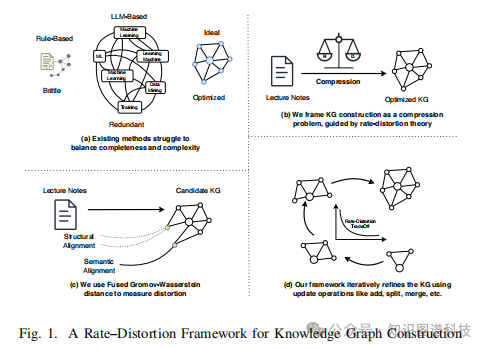
2.1 现有方法的局限性
从非结构化讲义和幻灯片中提取知识图谱仍然是一个具有挑战性的问题。当前的自动化方法在平衡完整性和复杂性方面存在困难:
规则驱动的方法:
-
使用语法模式和启发式规则提取概念和关系
-
优点:结构清晰
-
缺点:脆弱性强,难以泛化到设计规则之外的场景
机器学习与LLM方法:
-
能从文本中提取概念和关系
-
优点:灵活性高
-
缺点:
-
频繁产生不完整的知识图谱,缺失关键元素
-
或产生臃肿的图谱,包含冗余节点和事实
-
层次结构中的不一致性或错误
-
跨领域性能差异大
-
引入虚假关系或语义漂移
-
2.2 缺失的理论机制
现有方法要么过度生成内容,要么需要大量人工策展来确保正确性。目前缺乏一种原则性机制来平衡知识图谱的复杂性与其对源内容的表示准确度。这正是本研究要解决的核心问题。
三、创新框架:率失真理论遇见知识图谱
3.1 理论基础:信息压缩的视角
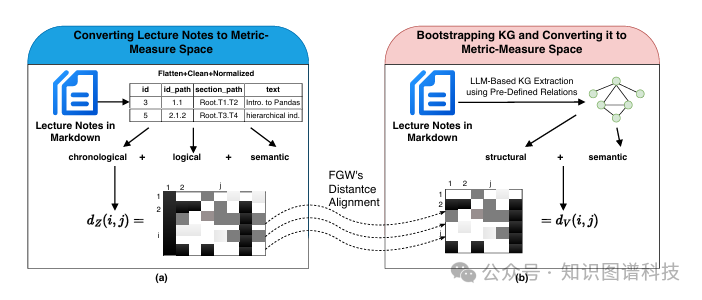
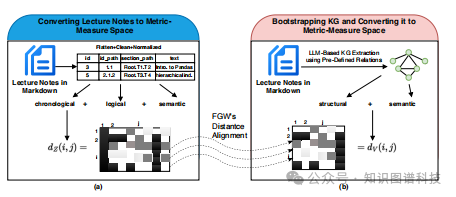
本研究引入了一个新颖的框架,将率失真(Rate-Distortion, RD)理论 和最优传输理论相结合,指导知识图谱的构建。
核心思想:
-
将讲义内容视为"源信息"
-
将知识图谱视为"压缩表示"
-
利用最优传输理论量化两者之间的失真程度
在信息论中,率失真理论提供了一种形式化方法,用于量化在给定压缩率(复杂度)下可实现的最小失真(信息损失)。
3.2 数学形式化
研究团队将讲义和知识图谱形式化为两个度量测度空间(metric measure spaces):
率(Rate)定义:
-
R = 知识图谱的大小
-
反映知识图谱的复杂性和紧凑性
失真(Distortion)定义:
-
D = 度量知识图谱与源内容偏离程度的距离
-
使用融合Gromov-Wasserstein(FGW)距离量化
优化目标 :
最小化拉格朗日目标函数:
code
L = R + βD其中β是权衡参数,用于平衡压缩与保真度。
3.3 Fused Gromov-Wasserstein距离:双重对齐
FGW距离是本框架的核心创新之一。它扩展了传统的Wasserstein距离,能够同时考虑结构和语义差异:
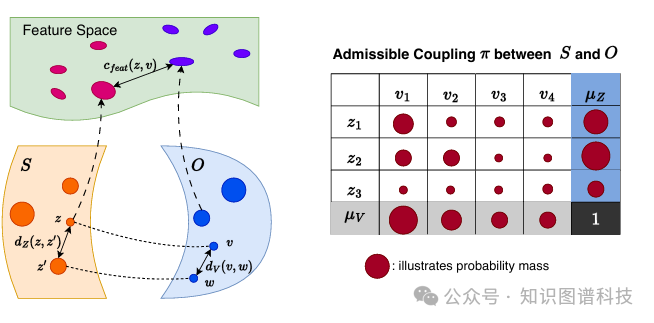
结构对齐:
-
保持讲义内容中概念之间的关系结构
-
确保图谱拓扑与源材料一致
语义对齐:
-
保持概念的语义内容
-
确保图谱节点准确代表原始概念
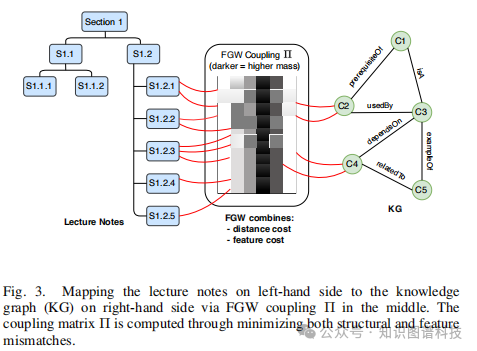
通过分析与FGW距离相关的耦合矩阵,可以指导知识图谱的迭代更新。
四、系统实现:迭代优化策略
4.1 知识图谱更新操作
研究团队提出了五种知识图谱更新操作,每种操作都根据其对L = R + βD目标的影响进行评估:
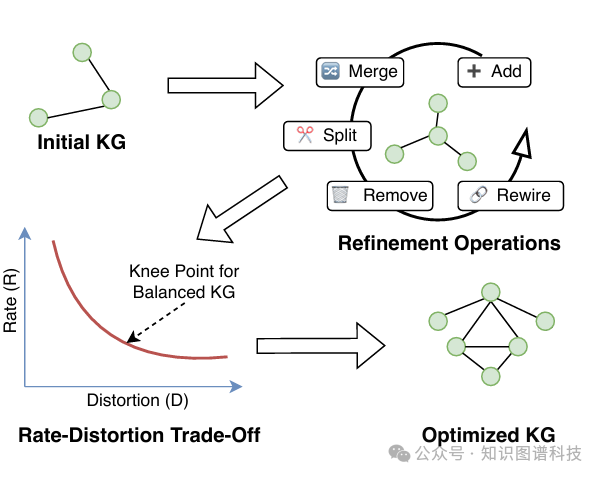
-
添加(Add):引入新概念
-
增加覆盖率,提高完整性
-
代价:增加复杂度(Rate上升)
-
-
合并(Merge):合并相似概念
-
减少冗余,降低复杂度
-
风险:可能损失细粒度信息
-
-
拆分(Split):拆解粗粒度概念
-
提高表达精度
-
代价:增加节点数量
-
-
删除(Remove):修剪不必要的概念
-
简化图谱结构
-
关键:不能删除重要节点
-
-
重连(Rewire):调整关系连接
-
优化图谱拓扑
-
改善结构对齐度
-
4.2 迭代优化流程
通过迭代应用这些操作符,并接受能改善权衡的变更,知识图谱被逐步优化至最优的率失真平衡。整个过程是一个贪心搜索策略,在每一步选择能最大程度降低目标函数L的操作。
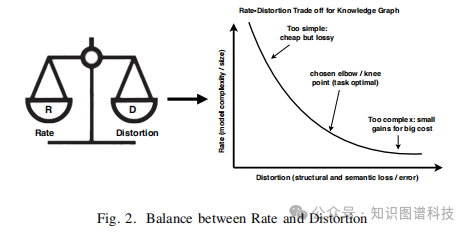
4.3 收敛准则:率失真曲线的"拐点"
通过绘制率失真曲线(R-D曲线),可以识别"拐点"(elbow point)------在该点之后,添加更多概念带来的失真减少呈递减趋势。这提供了一个原则性的停止准则,而不是依赖临时阈值。
五、系统原型与实验验证
5.1 原型系统开发
研究团队开发了一个原型系统,并在一组数据科学讲义上进行了演示。系统从自动从讲义中引导生成的初级知识图谱开始,通过RD引导的过程逐步产生更具代表性的知识图谱,试图覆盖关键概念。
5.2 实验设计
数据来源 :数据科学课程讲义
初始状态 :自动引导生成的基础知识图谱
优化过程 :应用迭代优化操作
评估维度:
-
内容覆盖率
-
选择题质量(15项质量标准)
-
率失真曲线演化
5.3 实验结果
关键发现:
-
渐进式改进:
-
知识图谱在迭代过程中逐步覆盖更多关键概念
-
率失真曲线清晰展示了优化轨迹
-
-
MCQ质量提升:
-
从优化后的知识图谱生成的选择题在所有15项质量标准上均持续超越从原始讲义生成的题目
-
显著减少了幻觉、事实错误和模糊选项
-
-
最优拐点识别:
-
实验清晰展示了率失真曲线如何在优化过程中演化
-
成功识别出最优"拐点",验证了理论预测
-
5.4 定量指标
研究报告了以下定量指标:
-
内容覆盖率
:优化后的知识图谱覆盖原始讲义中更高比例的关键概念
-
MCQ质量得分
:在事实准确性、认知复杂度、干扰项质量等15个维度上的综合评分显著提升
-
率失真权衡
:成功实现了紧凑性与保真度的最优平衡
六、理论贡献与创新点
6.1 信息论视角的知识工程
本研究首次将率失真理论应用于知识图谱工程,提供了清晰的优化目标:
-
知识图谱被视为源知识的压缩表示
-
RD最优对应于一个既不过大(包含每个细节)也不过小(遗漏重要概念)的知识图谱
-
这种形式化提供了比临时启发式更坚实的理论基础
6.2 最优传输的应用
Fused Gromov-Wasserstein距离的引入是关键创新:
-
同时考虑语义内容和关系结构
-
超越了传统的基于特征的相似度度量
-
为知识图谱与源材料的对齐提供了几何化的度量
6.3 可解释的优化过程
与黑盒深度学习方法不同,本框架提供了:
-
可解释的率失真曲线
:直观展示优化过程
-
明确的操作语义
:每个更新操作的作用清晰可见
-
原则性停止准则
:基于拐点的客观判断标准
七、相关工作与领域定位
7.1 知识图谱提取技术演进
传统方法:
-
命名实体识别(NER)
-
关系抽取(RE)
-
语言学启发式规则
深度学习时代:
-
神经网络模型
-
预训练语言模型
-
大型语言模型(LLM)驱动的知识图谱生成
当前挑战:
-
LLM生成的知识图谱可能产生不一致或逻辑无效的层次结构
-
需要额外的算法或专家审查来确保质量控制
7.2 率失真理论的应用
率失真理论源于Shannon的信息论,描述了信号压缩与信息损失之间的基本权衡。率失真曲线给出了在任意给定率下可实现的最小失真。
相关应用:
-
Bardera等人提出的基于率失真的信息论聚类框架
-
实现了数据的最大压缩分组,同时保持最小信号失真
本研究的独特性 :
首次将RD视角应用于知识图谱工程,为教育知识表示提供了理论基础。
7.3 教育领域的知识图谱
知识图谱和概念图在许多教育应用中发挥重要作用:
-
智能辅导系统
:作为领域模型,编码学生必须学习的关键概念和结构化课程的关系
-
个性化学习
:根据知识图谱适配学习路径
-
自动问题生成
:基于知识结构生成多样化问题
LLM在教育中的应用现状:
-
研究表明LLM能增强学生学习和表现
-
擅长生成多样化问题类型,减少教师工作量
-
但直接使用面临质量、教学法和人工监督依赖的重大挑战
-
AI生成的MCQ需要大量验证,存在模糊性或对齐性差的问题
八、实践意义与应用前景
8.1 教育技术优化
即时应用:
-
提高AI教学助手的问题生成质量
-
减少教师在内容策展上的工作量
-
确保自动生成内容的教学有效性
长期影响:
-
建立可信赖的AI教育工具生态
-
促进个性化学习规模化实施
-
支持适应性课程设计
8.2 知识工程方法论
本研究为知识工程提供了:
-
原则性设计框架
:超越启发式的理论指导
-
质量保证机制
:基于数学优化的质量控制
-
可扩展架构
:适用于不同领域和任务的通用方法
8.3 跨学科融合
本工作体现了多学科融合:
-
信息论
:率失真理论
-
数学
:最优传输理论
-
计算机科学
:知识图谱、NLP、机器学习
-
教育学
:认知科学、教学法
这种融合为AI+教育领域开辟了新的研究方向。
九、局限性与未来工作
9.1 当前局限
虽然本研究取得了重要进展,但仍存在一些局限:
计算复杂度:
-
FGW距离计算在大规模图谱上可能较慢
-
需要进一步优化算法效率
领域适应性:
-
当前在数据科学讲义上验证
-
需要在更多学科领域测试泛化能力
参数调优:
-
β参数的选择影响率失真权衡
-
需要探索自动化参数选择策略
9.2 未来研究方向
技术改进:
-
开发更高效的FGW距离近似算法
-
探索增量更新策略,避免全图重计算
-
集成深度学习模型增强语义理解
应用拓展:
-
扩展到更多学科领域(STEM、人文、社科)
-
支持多模态内容(视频、音频讲座)
-
整合学生学习数据,实现个性化知识图谱
理论深化:
-
探索率失真理论与认知负荷理论的关联
-
研究知识图谱复杂度与学习效果的关系
-
建立教育知识表示的信息论基础
十、结论
本研究建立了一个将信息论与最优传输理论应用于教育知识图谱构建的创新框架。通过将知识图谱视为源内容的压缩表示,并使用Fused Gromov-Wasserstein距离量化失真,我们为知识图谱工程提供了坚实的数学基础。实验结果表明,该框架能够有效平衡图谱的完整性与复杂性,显著提升AI生成选择题的质量。
本研究的贡献不仅限于技术层面,更在于为AI辅助教育提供了可解释、可信赖的理论支撑。随着教育技术的不断发展,我们期待这一框架能够推动更多高质量教育工具的诞生,真正实现让AI更懂教育的愿景。
欢迎加入「知识图谱增强大模型产学研」知识星球,获取最新产学研相关"知识图谱+大模型"相关论文、政府企业落地案例、避坑指南、电子书、文章等,行业重点是医疗护理、医药大健康、工业能源制造领域,也会跟踪AI4S科学研究相关内容,以及Palantir、OpenAI、微软、Writer、Glean、OpenEvidence等相关公司进展。