TL;DR
- 场景:类别不平衡时 Accuracy 失真,业务更关心"少数类捕获"和"误伤成本"。
- 结论:用混淆矩阵统一口径,再用 Precision/Recall/F1 与 ROC/AUC 做权衡与阈值选择。
- 产出:TP/FP/FN/TN 定义与指标映射 + sklearn 指标/绘图接口版本要点 + 常见坑速查卡。

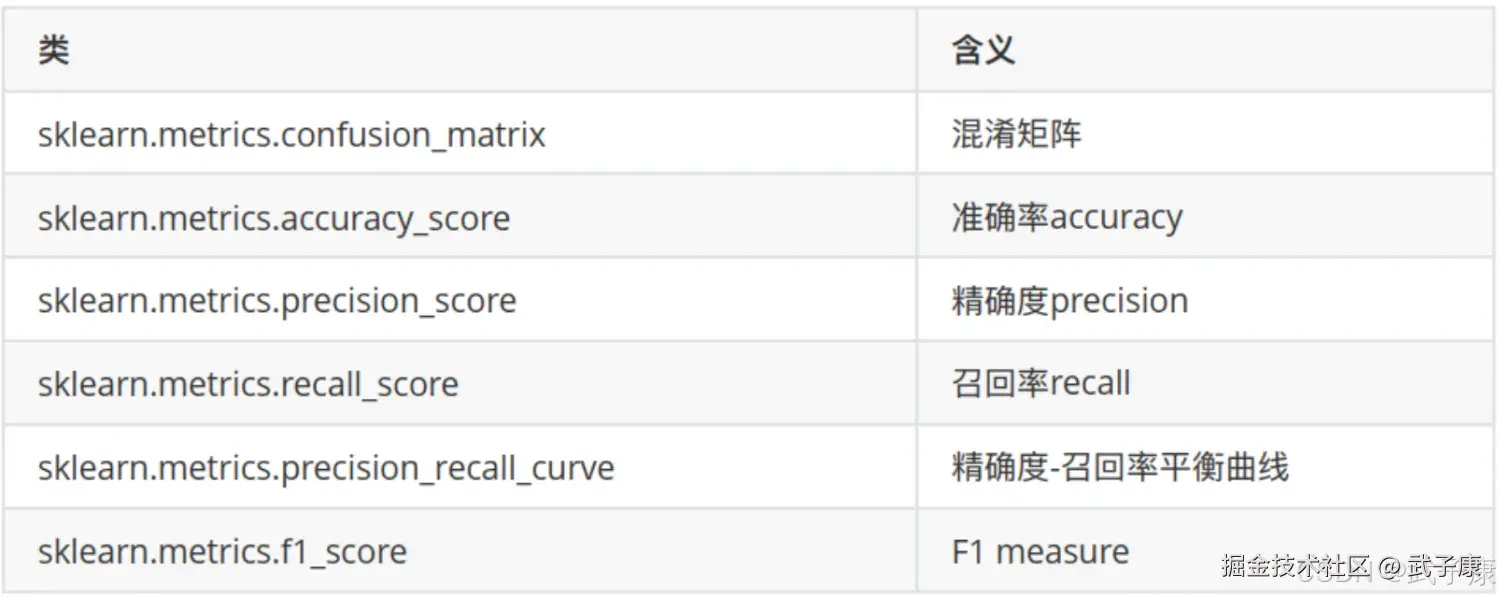
版本矩阵
| 项/接口 | 已验证 | 说明 |
|---|---|---|
| scikit-learn | ✅ 1.8.0 | PyPI 标注最新稳定版,发布日期 2025-12-10;Requires: Python ≥3.11 |
| Python | ✅ ≥3.11 | sklearn 1.8.0 明确要求 Python ≥3.11 |
| NumPy | ✅ ≥1.24.1 | sklearn 1.8.0 依赖声明 |
| SciPy | ✅ ≥1.10.0 | sklearn 1.8.0 依赖声明 |
| sklearn.metrics.confusion_matrix | ✅ 1.8.0 | 文档normalize={'true','pred','all'}:按真实/预测/全体归一化 |
| sklearn.metrics.ConfusionMatrixDisplay | ✅ 1.8.0 | 文档推荐用 from_estimator/from_predictions 生成展示对象 |
| sklearn.metrics.roc_curve | ✅ 1.8.0 | 文档签名含 pos_label,输入是 y_score(分数/概率),非离散标签 |
| sklearn.metrics.RocCurveDisplay | ✅ 1.8.0 | 文档从 estimator 直接生成 ROC 展示 |
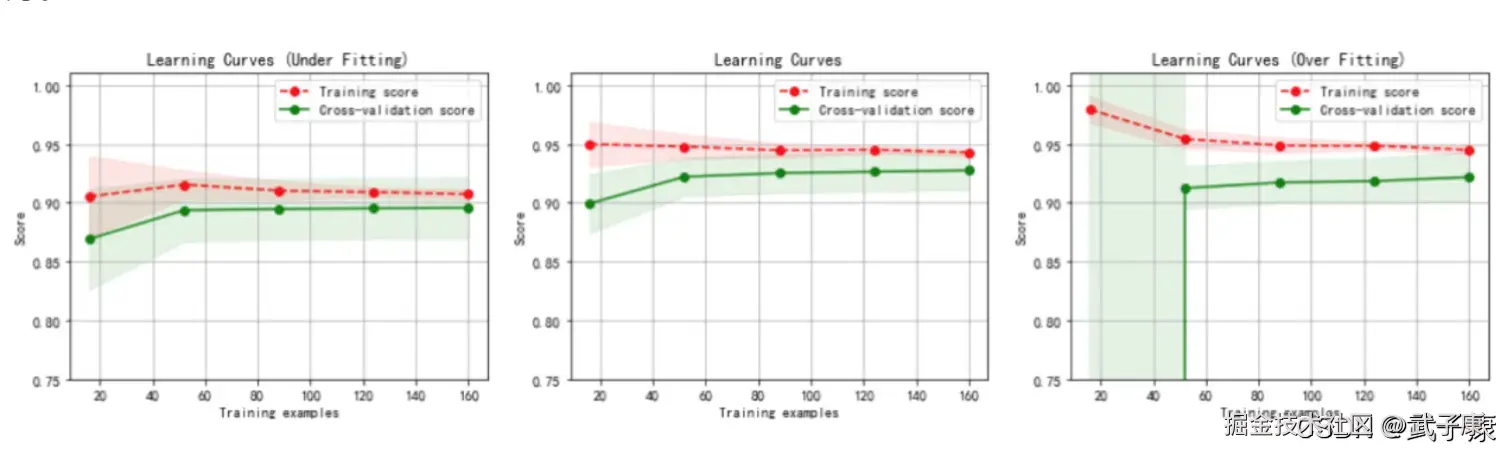
混淆矩阵
从上一节的例子中可以看出,如果我们的目标是希望尽量捕获少数类,那准确率这个模型评估逐渐失效,所以我们需要新的模型评估指标来帮助我们。如果简单来看,其实我们只需要查看模型在少数类上的准确率就好了,只要能够将少数类尽量捕捉出来,就能够达到我们的目的。 但此时,新问题又出现了,我们对多数类判断错误后,会需要人工甄别或者更多的业务上的措施来一一排除我们判断错误的多数类,这种行为往往伴随着很高的成本。 比如银行在判断一个申请信用卡的客户是否会违约行为的时候,如果一个客户被判断为会违约,这个客户的信用卡申请就会驳回,如果为了捕捉会违约的人,大量地将不会违约的客户判断为会违约的客户,就会有许多无辜的客户的申请被驳回。 也就是说,单纯的追求捕捉少数类,就会成本太高,而不顾及少数类,又会无法达成模型的效果。所以在现实中,我们往往在寻找捕获少数类的能力和将多数判错后需要付出的成本的平衡。如果一个模型在能够尽量捕获少数类的情况下,还能够尽量对多数判断正确,则这个模型就非常优秀了。为了评估这样的能力,我们将引入新的模型评估指标:混淆矩阵可以帮助我们。
- 混淆矩阵是二分类问题的多维衡量指标体系,在样本不平衡时极其有用
- 在混淆矩阵中,我们将少数类认为时正例,多数类认为时负例
- 在决策树,随机森林这些算法里,即是说少数类是1,多数类时 0
- 在 SVM 里,就是说少数类时 1,多数类时 -1
普通的混淆里,一般使用「0,1」来表示,混淆矩阵如其名,十分容易让人混淆,在需要教材中各种各样的名称和定义让大家难以理解和记忆。 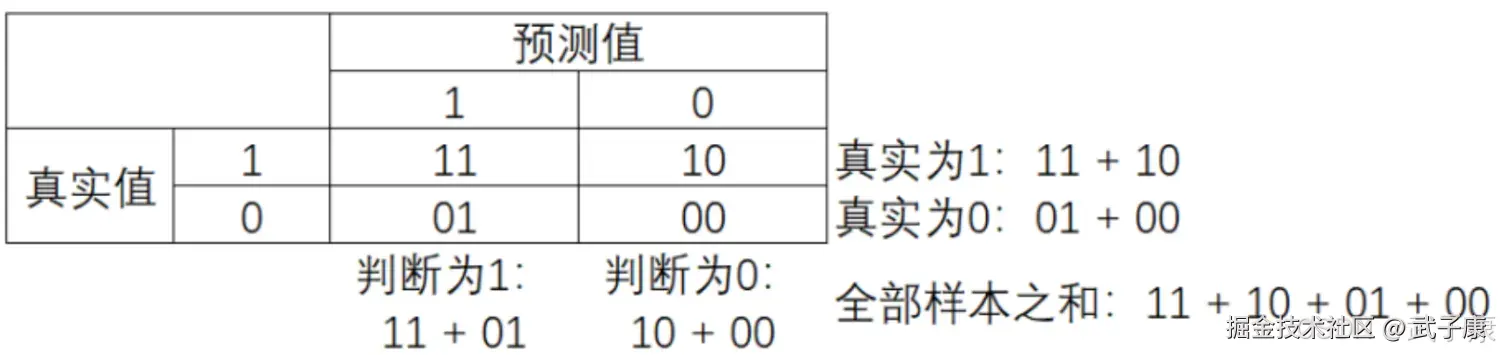
其中:
- 行代表预测情况,列则表示实际情况
- 预测值是 1,记为 P(Positive)
- 预测值是 0,记为 N(Negative)
- 预测值与真实值相同,记为 T(True)
- 预测值与真实值相反,记为 F(False)
因此矩阵中四个元素分别表示:
- TP(True Positive)真实为 1,预测为 1
- FN(False Negative)真实为 1,预测为 0
- FP(False Positive)真实为 0,预测为 1
- TN(True Negative)真实为 0,预测为 0
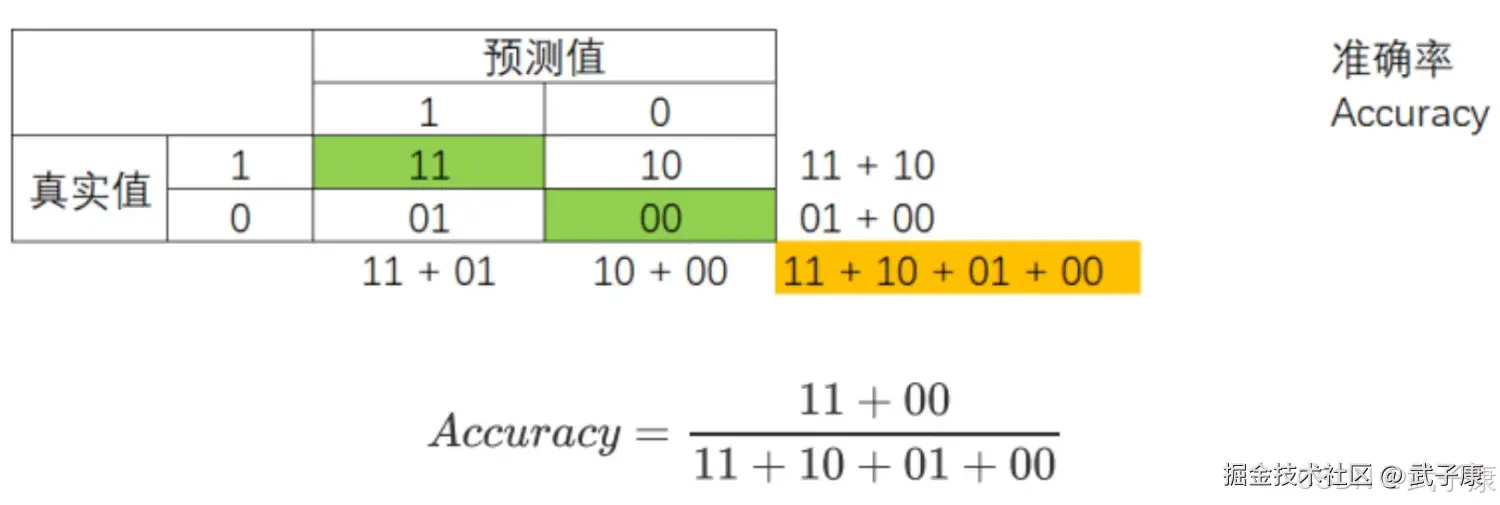
基于混淆矩阵,我们有一系列不同的模型评估指标,这些评估指标范围都在【0,1】之间,所以有11 和 00为分子的指标都是越来越接近 1 越好,所以 01 和 10 为分子的指标都是越来越接近 0 越好。 对于所有指标,我们用橙色表示分母,用绿色表示分子,则我们有:
准确率 Accuracy
精确度 Precision
 精确度 Precision,又叫查准率,表示在所有预测结果为 1 的样例数中,实际为 1 的样例数所占比重。精确度越低,意味着 01 比重很大,则代表你的模型对多数类 0 误判率越高,误伤了过多的多数类。为了避免对多数类的误伤,需要追求高精确度。 精确度是将多数类判错后所需要付出成本的衡量
精确度 Precision,又叫查准率,表示在所有预测结果为 1 的样例数中,实际为 1 的样例数所占比重。精确度越低,意味着 01 比重很大,则代表你的模型对多数类 0 误判率越高,误伤了过多的多数类。为了避免对多数类的误伤,需要追求高精确度。 精确度是将多数类判错后所需要付出成本的衡量
召回率 Recall
召回率 Recall,又称为敏感度(sensitivity),真正率,查全率,表示所有真实为 1 的样本中,被我们预测正确的样本所占的比例。 召回率越高,代表我们尽量捕捉出了越多的少数类。召回率越低,代表我们捕捉出足够的少数类。
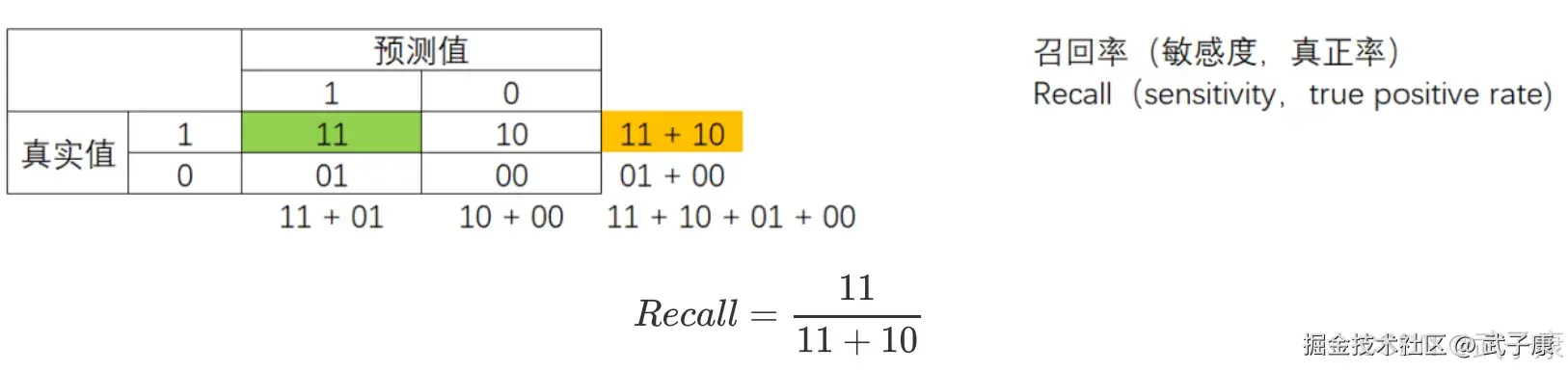 我们希望不计代价,找出少数类(比如潜逃的犯罪分子),那我们会追求高召回率,相反如果我们的目标不是尽量捕获少数类,那我们就不需要在意召回率。 注意召回率和精确度的分子是相同的(都是 11),只是分母不同。 而召回率和精确度是此消彼长的,两者之间的平衡代表了捕捉少数类的需求和尽量不要误伤多数类的需要求的平衡。 究竟要偏向哪一方,取决于我们的业务需求:究竟是误伤多数类的成本更高,还是无法捕捉少数类的代表更高。
我们希望不计代价,找出少数类(比如潜逃的犯罪分子),那我们会追求高召回率,相反如果我们的目标不是尽量捕获少数类,那我们就不需要在意召回率。 注意召回率和精确度的分子是相同的(都是 11),只是分母不同。 而召回率和精确度是此消彼长的,两者之间的平衡代表了捕捉少数类的需求和尽量不要误伤多数类的需要求的平衡。 究竟要偏向哪一方,取决于我们的业务需求:究竟是误伤多数类的成本更高,还是无法捕捉少数类的代表更高。
F1 Measure
为了同时兼顾精确度和召回率,我们创造了两者的调和平均数作为考量两者平衡的综合性指标,称之为F1 Measure。 两个数之间的调和平均倾向于靠近两个数中比较小的那一个数,因此我们追求尽量高的F1 Measure,能够保证我们精确度和召回率都比较高。 F1 Measure 在 0,1之间分布,越接近 1 越好。
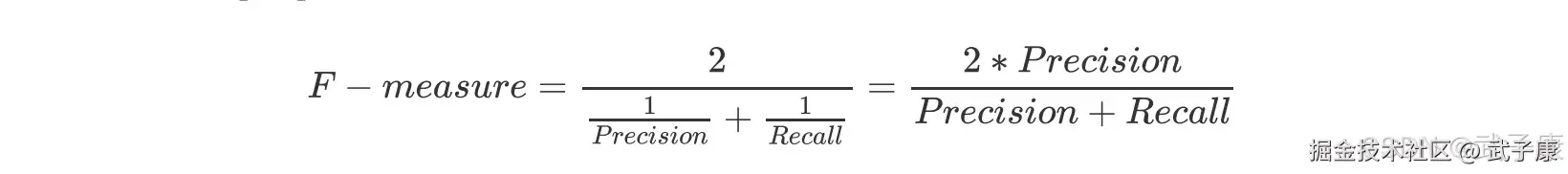
假负率
从 Recall 延伸出来的另一个评估指标叫做假负率(False Negative Rate),它等于 1 - Recall,用于衡量。 所有真实为 1 的样本中,被我们错误判断为 0 的,通常用的不多。
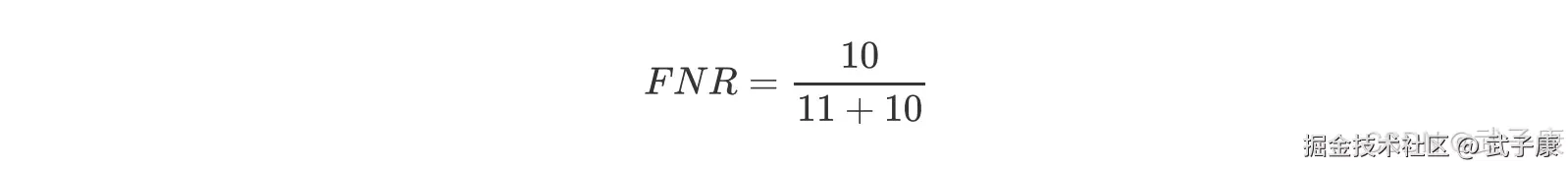
ROC 曲线
ROC 的全称是:Receiver Operating characteristic Curve,其主要的分析方法就是画这条特征曲线。 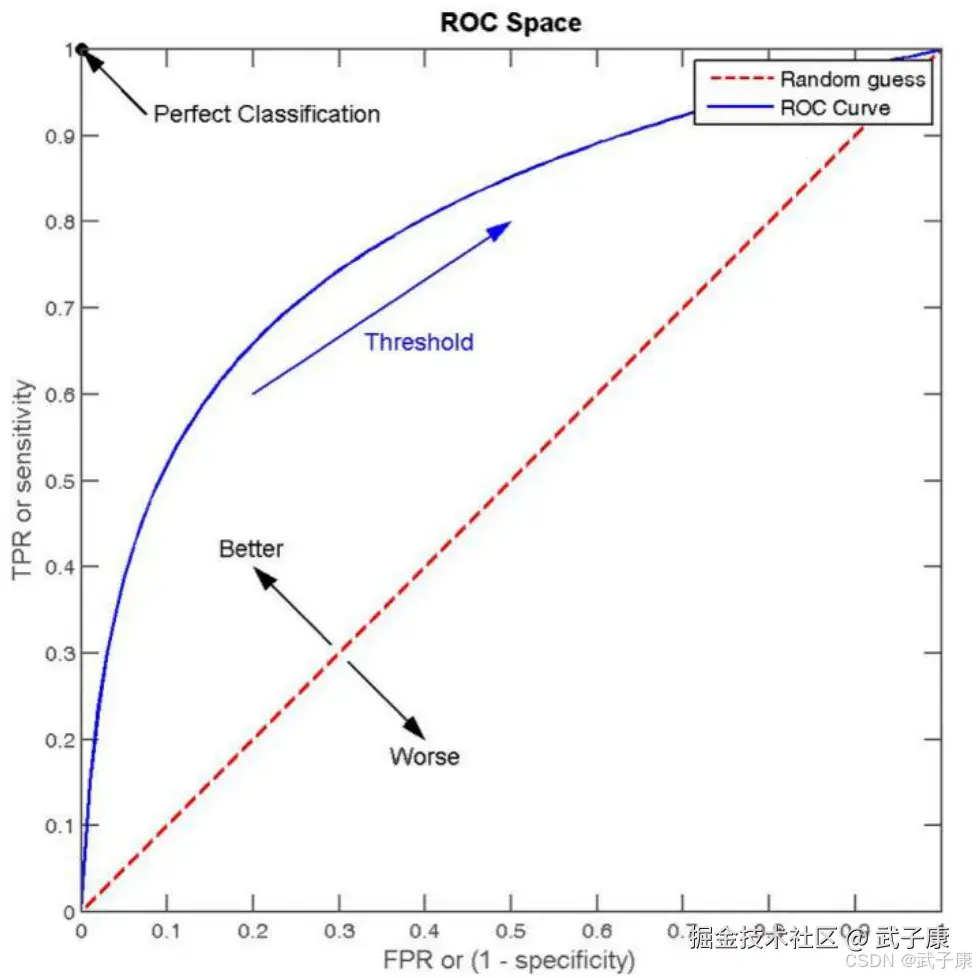
该曲线的横坐标为假正率(False Positive Rate,FPR),N 是真实负样本的个数,FP 是N 个负样本中被分类器预测为正样本的个数。  纵坐标为召回率,真正率(True Positive Rate,TPR):
纵坐标为召回率,真正率(True Positive Rate,TPR): 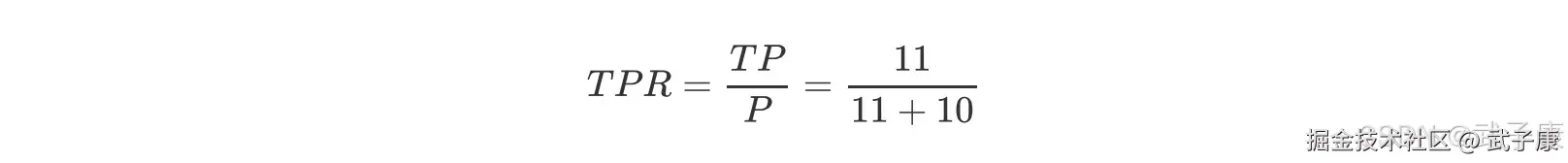 P 是真实正样本的个数,TP 是 P 个正样本被分类器预测为正样本的个数。
P 是真实正样本的个数,TP 是 P 个正样本被分类器预测为正样本的个数。
sklearn 中的混淆矩阵
决策树的算法评价
决策树优点详解
-
易于理解和解释
- 决策树采用树形结构展示决策过程,可视化程度高,非专业人士也能理解
- 每个节点代表一个特征判断,分支代表判断结果,叶子节点代表最终决策
- 示例:在银行贷款审批场景中,可以直观看到"收入>5万→信用良好→批准"这样的决策路径
-
数据预处理要求低
- 不需要特征缩放或标准化(如决策树对特征的数值范围不敏感)
- 能直接处理类别型特征,无需one-hot编码(但sklearn实现需要)
- 注意:主流实现(如sklearn)确实不支持缺失值自动处理,需提前填充
-
预测效率高
- 预测时间复杂度为O(log n),n是训练样本数
- 对比:KNN预测需要O(n),SVM需要O(n_sv)支持向量数量
- 适合实时预测场景,如金融风控系统需要毫秒级响应
-
多类型数据处理能力
- 可混合处理数值特征(如年龄、收入)和类别特征(如性别、职业)
- 既可用于分类(预测类别标签)也可用于回归(预测连续值)
- 应用场景示例:房价预测(回归)和客户流失预测(分类)可使用相同算法
-
模型鲁棒性
- 对数据分布假设较少,即使特征间存在非线性关系也能较好处理
- 对异常值相对不敏感,因为分裂依据是特征排序而非绝对值
决策树缺点详解
-
过拟合风险
- 容易生长出过于复杂的树,完美拟合训练数据但泛化能力差
- 解决方案:
- 预剪枝:设置max_depth(最大深度)、min_samples_leaf(叶节点最小样本数)
- 后剪枝:训练完整树后剪除不重要的分支
- 示例:限制max_depth=5通常能平衡模型复杂度与性能
-
模型不稳定性
- 训练数据微小变化可能导致完全不同的树结构
- 根本原因:贪婪算法的局部最优特性
- 改进方法:
- 使用集成学习(如随机森林)通过多棵树投票降低方差
- 随机森林中设置max_features参数控制特征采样随机性
-
局部最优问题
- 每次分裂只考虑当前节点的最优解,不能回溯调整之前的分裂
- 可能导致次优全局模型
- 解决方案:
- 集成方法:通过Bagging或Boosting组合多个弱学习器
- 特征工程:人工构造更有判别力的特征
-
类别不平衡敏感
- 当某一类别样本占比过大时,模型会偏向该类别
- 解决方法:
- 上采样少数类或下采样多数类
- 使用类别权重参数(如class_weight='balanced')
- 采用AUC等对类别不平衡不敏感的评价指标
- 示例:在欺诈检测中,正常交易占比99%时需特别处理不平衡问题
错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
| 混淆矩阵"行列含义"对不上(看起来 TP/FP 被交换) | 把轴含义记反(真实/预测放反)或画图工具默认顺序误读 | 用 3~5 条手工样例算一次 TP/FP/FN/TN,对照矩阵四格明确 confusion_matrix(y_true, y_pred) 语义;展示时统一标注"真实/预测";必要时转置但要同步改口径 |
| Precision/Recall 数值异常(Precision 很低或 Recall 很低且不符合直觉) | 正例标签 pos_label 不一致(0/1 vs -1/1 vs 字符串);labels 排序与业务正例不一致 | 打印 np.unique(y_true) 与 np.unique(y_pred);检查"少数类是否真被当作正类"在 ROC/二分类指标里显式设 pos_label;在混淆矩阵里显式设 labels=neg,pos 保持业务顺序 |
| ROC 曲线"像一条直线/点很少/与预期相反" | 把 y_pred(0/1标签)当成 y_score;或分数方向反了(正例分数更小) | 检查传入 roc_curve 的第二个参数是否只有 {0,1};检查正例的分数均值是否更高传 predict_proba:,1 或 decision_function;必要时取反分数或修正正例定义(pos_label) |
| 归一化后的混淆矩阵"百分比不对"(每行不和为1或每列不和为1) | 误解 normalize='true'/'pred'/'all' 的分母 | 观察归一化后是"行和=1"还是"列和=1"需要"召回视角"用 normalize='true';需要"精确视角"用 normalize='pred';全体占比用 normalize='all' |
| Accuracy 很高但业务效果差(漏掉关键少数类) | 类别不平衡导致多数类主导;阈值默认 0.5 不匹配成本函数 | 看混淆矩阵中 FN 是否偏大;看 Recall/TPR 是否偏低以 Precision/Recall/F1 或 ROC/AUC 为主;按业务成本调阈值,并在评估报告里固定"正例定义+阈值" |
| "捕获少数类"提升后,误伤多数类激增(审核/拒绝量爆炸) | 单点追求 Recall,忽略 FP 成本 | 看 FP 与 Precision 的变化趋势以 Precision 作为成本约束,做阈值扫描/PR 权衡;在上线指标中同时锁定 Precision 下限与 Recall 下限 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-218 RocketMQ Java API 实战:同步/异步 Producer 与 Pull/Push Consumer MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ已完结,RocketMQ正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解