一、MySQL进阶
1. 索引
在数据库性能优化中,索引是提升查询效率的核心手段。
1.1 使用规则
1. 验证索引的效率
'通过指令查询,我们准备的数据库里面有1000w条数据。
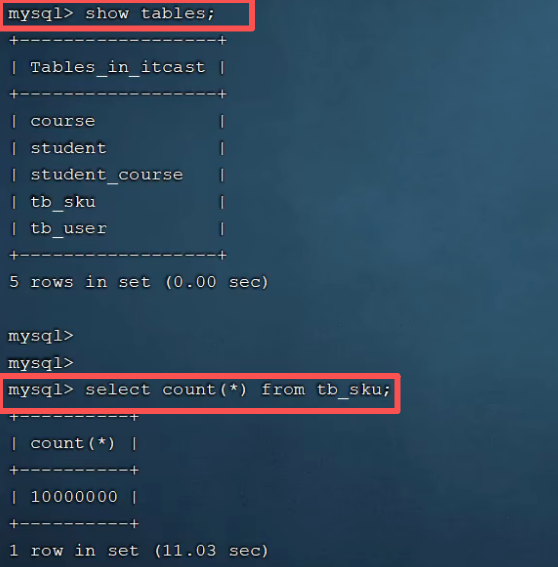
该指令可以将因为数据量太大而导致输出的格式变形的问题

根据sn字段进行查询,执行的效率如下:用时20多秒,效率极其低下!
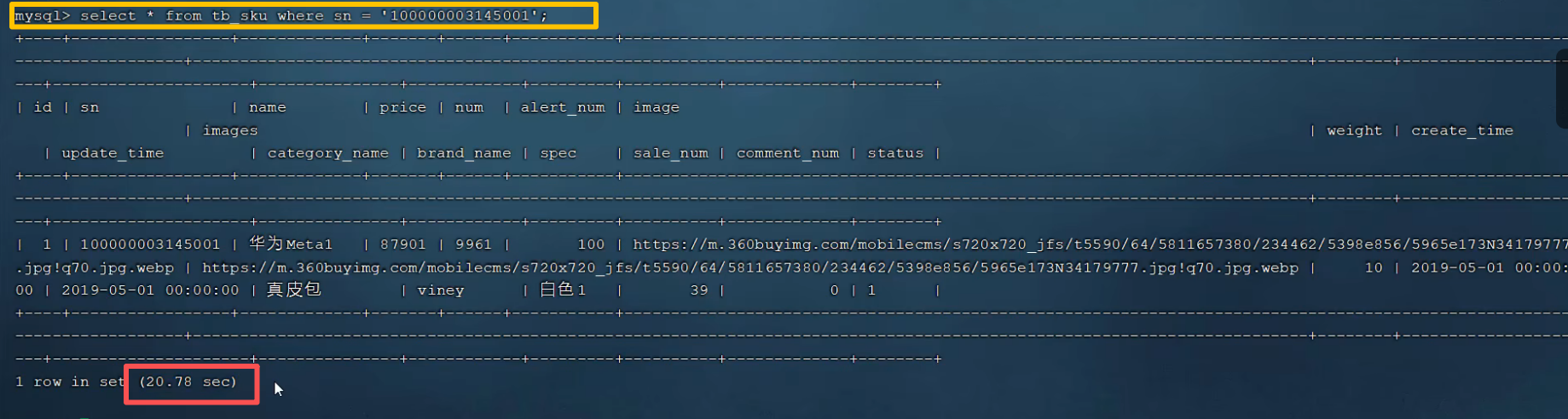
原因很简单,通过主键id查询,有默认的索引查询,而sn并没有建立索引,效率极其低下在庞大的数据量面前。

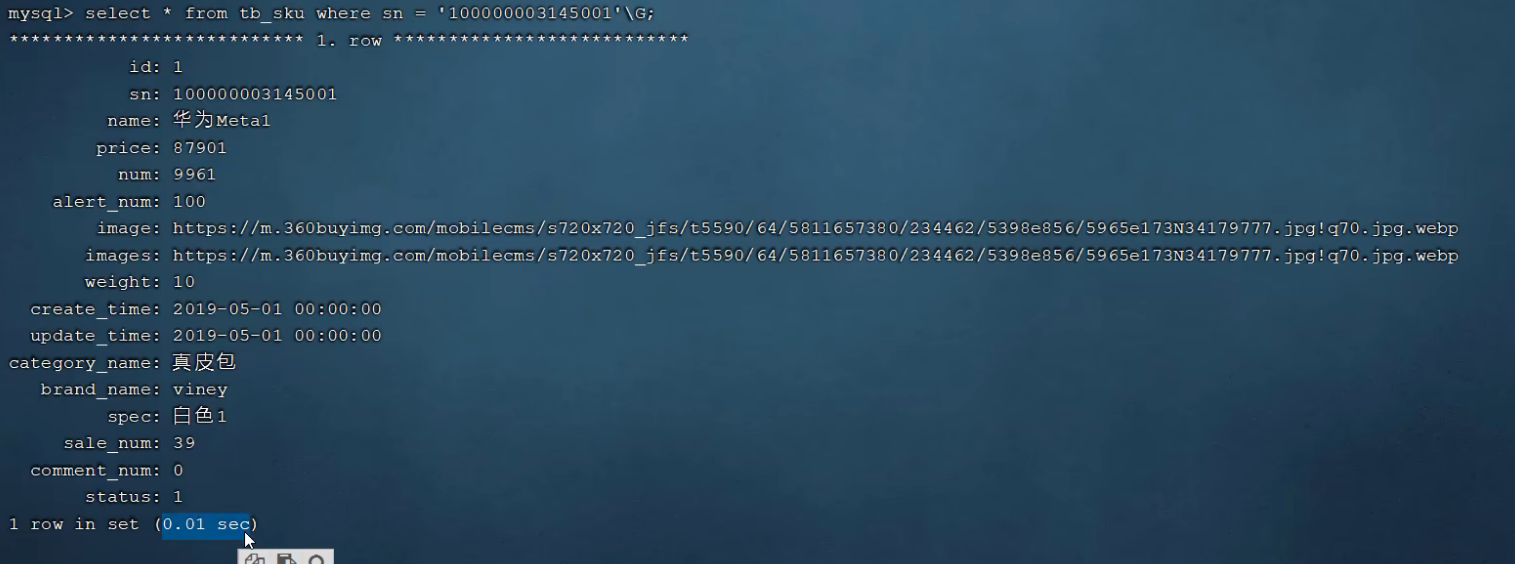
通过指令创建索引

再次执行相同的sql查询语句,对比耗时情况:20s对比0.01s,根本不是一个数量级的优化!
2. 最左前缀法则
核心概念
当创建联合索引(a, b, c)时:
- 查询条件必须从最左列开始,且连续
- 不能跳过中间列,否则后续列索引失效
详细示例
sql
-- 创建联合索引
CREATE INDEX idx_a_b_c ON table(a, b, c);
-- 有效查询(使用最左前缀)
SELECT * FROM table WHERE a = 1; -- 有效
SELECT * FROM table WHERE a = 1 AND b = 2; -- 有效
SELECT * FROM table WHERE a = 1 AND b = 2 AND c = 3; -- 有效
-- 无效查询(跳过中间列)
SELECT * FROM table WHERE b = 2; -- 无效
SELECT * FROM table WHERE a = 1 AND c = 3; -- 无效(b列缺失)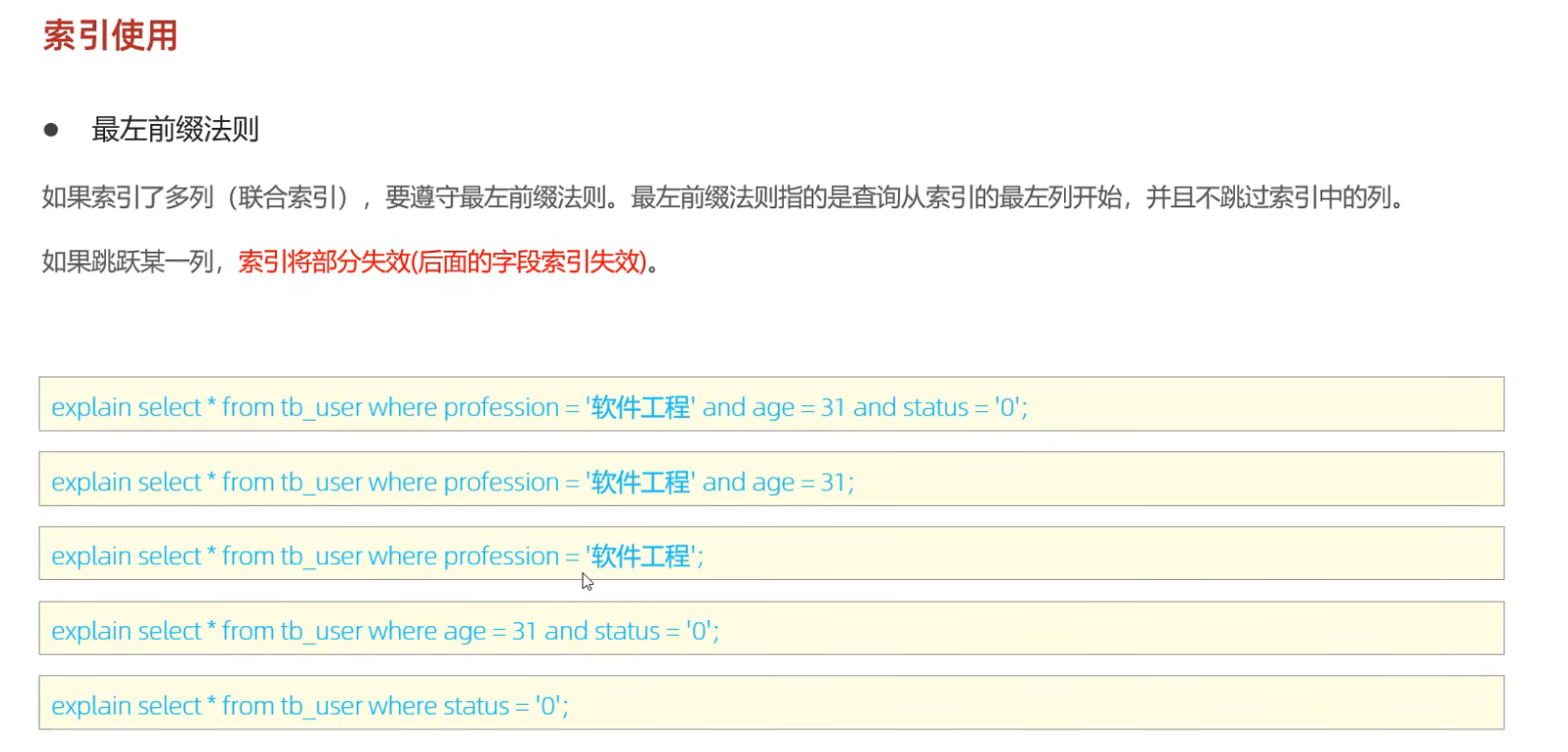
生动类比:想象一本电话簿,按姓氏排序,姓氏相同再按名字排序。查找"姓张的人"(只用最左列姓氏)→ ✅ 有效;查找"名叫三的人"(只用名字,跳过了姓氏)→ ❌ 无效。
3. 范围查询
问题现象
在联合索引中,如果使用>、<等范围查询,范围查询右侧的列索引会失效。
案例分析
sql
-- 创建联合索引
CREATE INDEX idx_a_b_c ON table(a, b, c);
-- 有效查询
SELECT * FROM table WHERE a = 1 AND b = 2 AND c = 3; -- 索引全部有效
-- 无效查询(范围查询后列失效)
SELECT * FROM table WHERE a = 1 AND b > 2 AND c = 3; -- c列失效Explain结果:
sql
key: idx_a_b_c
key_len: 49 (仅a、b列有效)
Extra: Using where解决方案
- 将范围查询放在联合索引的最后
- 尽量使用
>=和<=替代>和<

4. 索引失效情况
a. 索引列运算
sql
-- 索引失效
SELECT * FROM users WHERE YEAR(create_time) = 2023;
-- 优化后
SELECT * FROM users WHERE create_time >= '2023-01-01' AND create_time < '2024-01-01';
b. 字符串不加引号
sql
-- 索引失效(status为varchar类型)
SELECT * FROM users WHERE status = 0;
-- 优化后
SELECT * FROM users WHERE status = '0';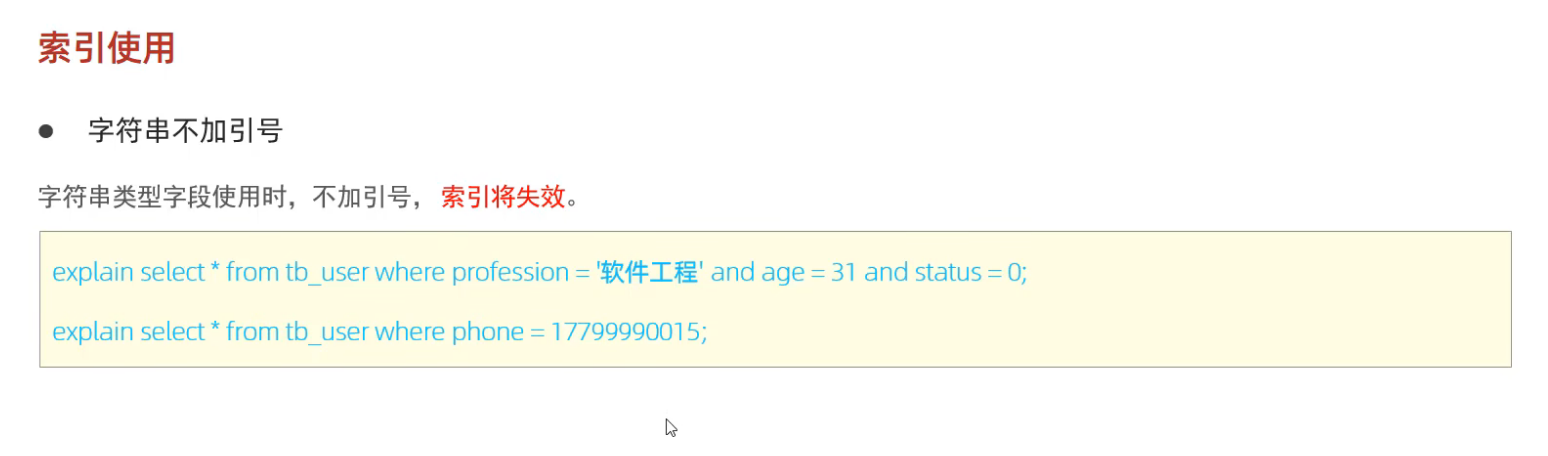
c. 模糊查询
sql
-- 索引失效
SELECT * FROM users WHERE name LIKE '%张';
-- 优化后
SELECT * FROM users WHERE name LIKE '张%';
d. or连接的条件
sql
-- 索引失效(可能不使用索引)
SELECT * FROM users WHERE status = '0' OR age = 30;
-- 优化后(使用UNION)
SELECT * FROM users WHERE status = '0'
UNION ALL
SELECT * FROM users WHERE age = 30;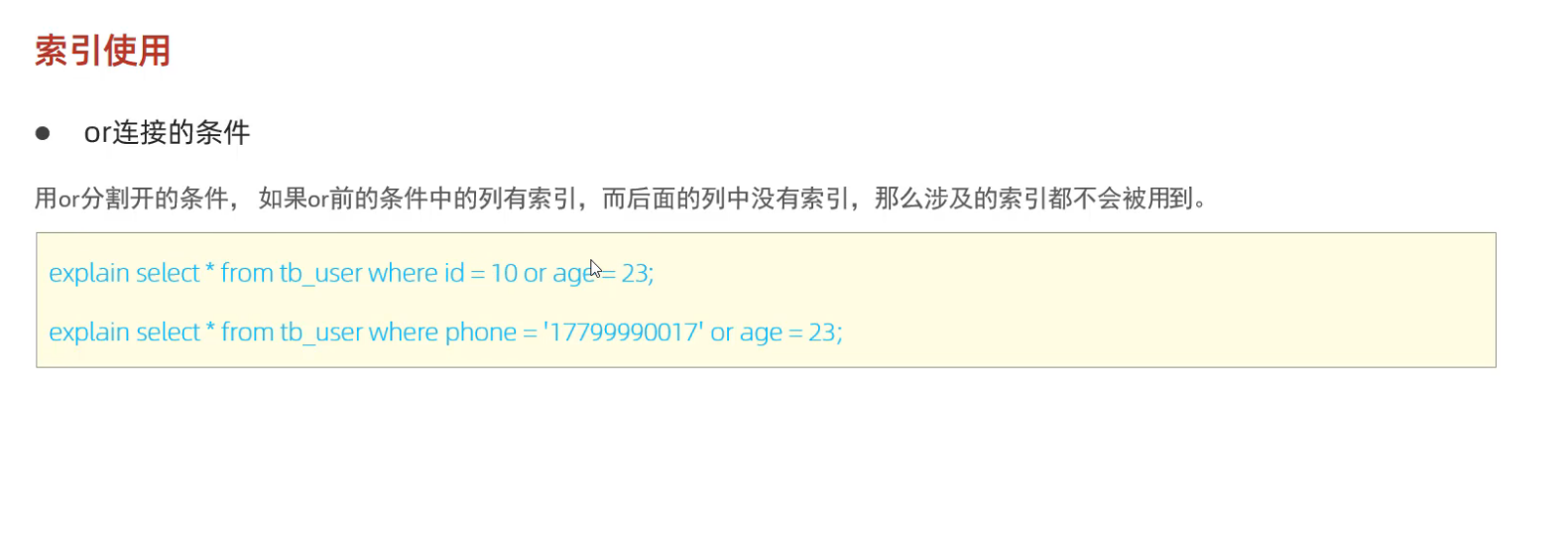
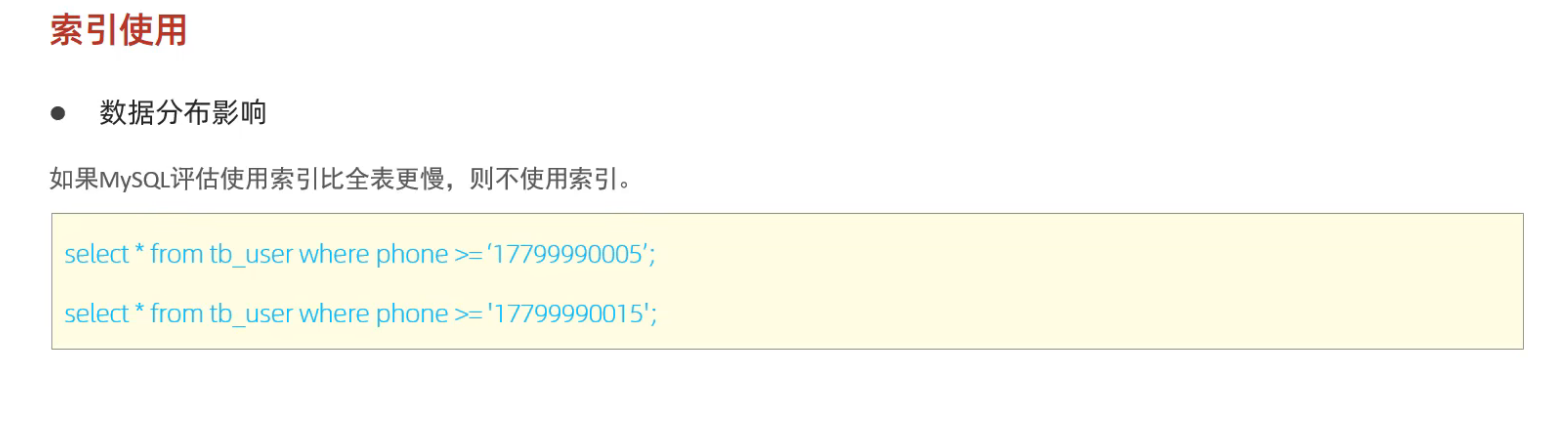
e. 数据分布影响
- 当索引列的值分布极不均匀(如性别字段,只有"男"和"女"),索引效果会大打折扣
- 优化:考虑使用覆盖索引或调整查询策略
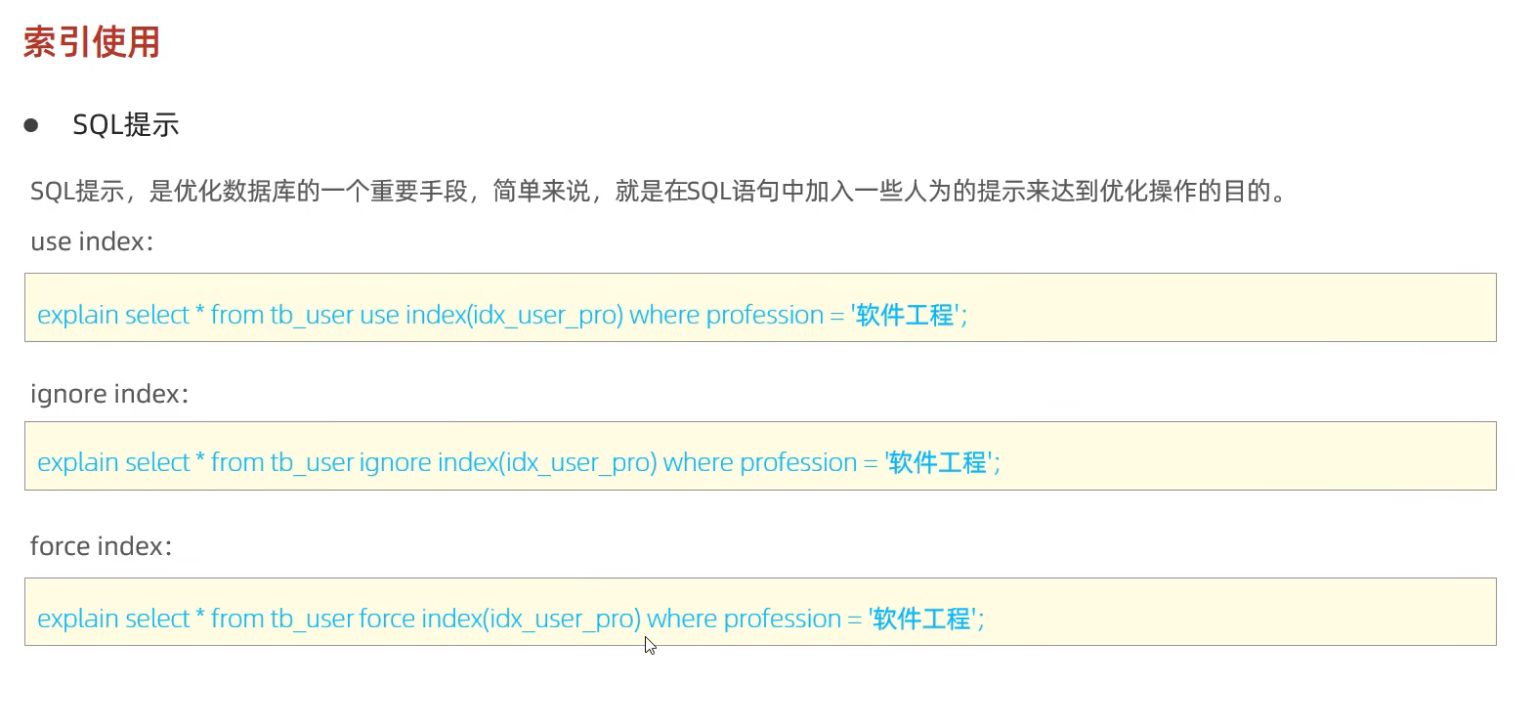
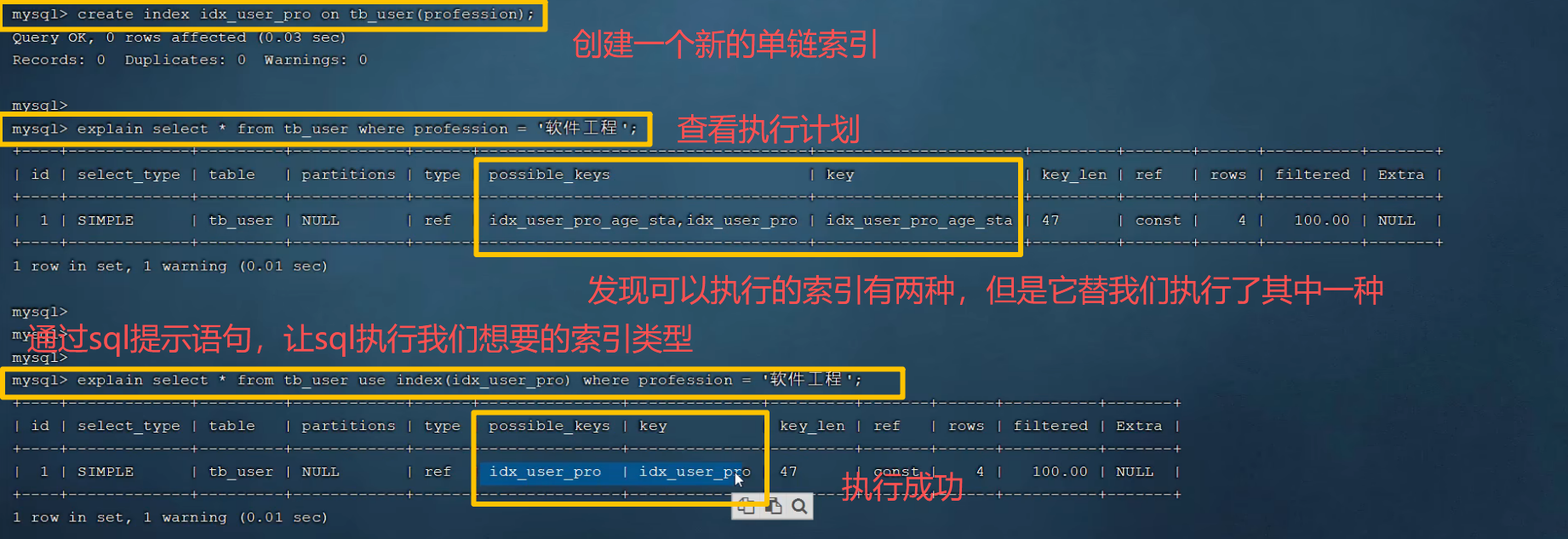
5. sql提示
MySQL支持使用SQL提示强制使用特定索引:
sql
SELECT * FROM table USE INDEX(idx_a_b_c) WHERE a = 1 AND b = 2;使用场景:当优化器选择的索引不是最优时,可以使用提示强制指定索引。
6. 覆盖索引和回表查询
回表查询
- 定义:通过辅助索引定位主键,再通过聚集索引获取完整行数据
- 过程:扫描两遍索引树
- 性能影响:比直接扫描聚集索引慢
案例 :
user表有id(主键)、name(索引)、age字段
sql
SELECT * FROM user WHERE name = '张三'; -- 需要回表查询
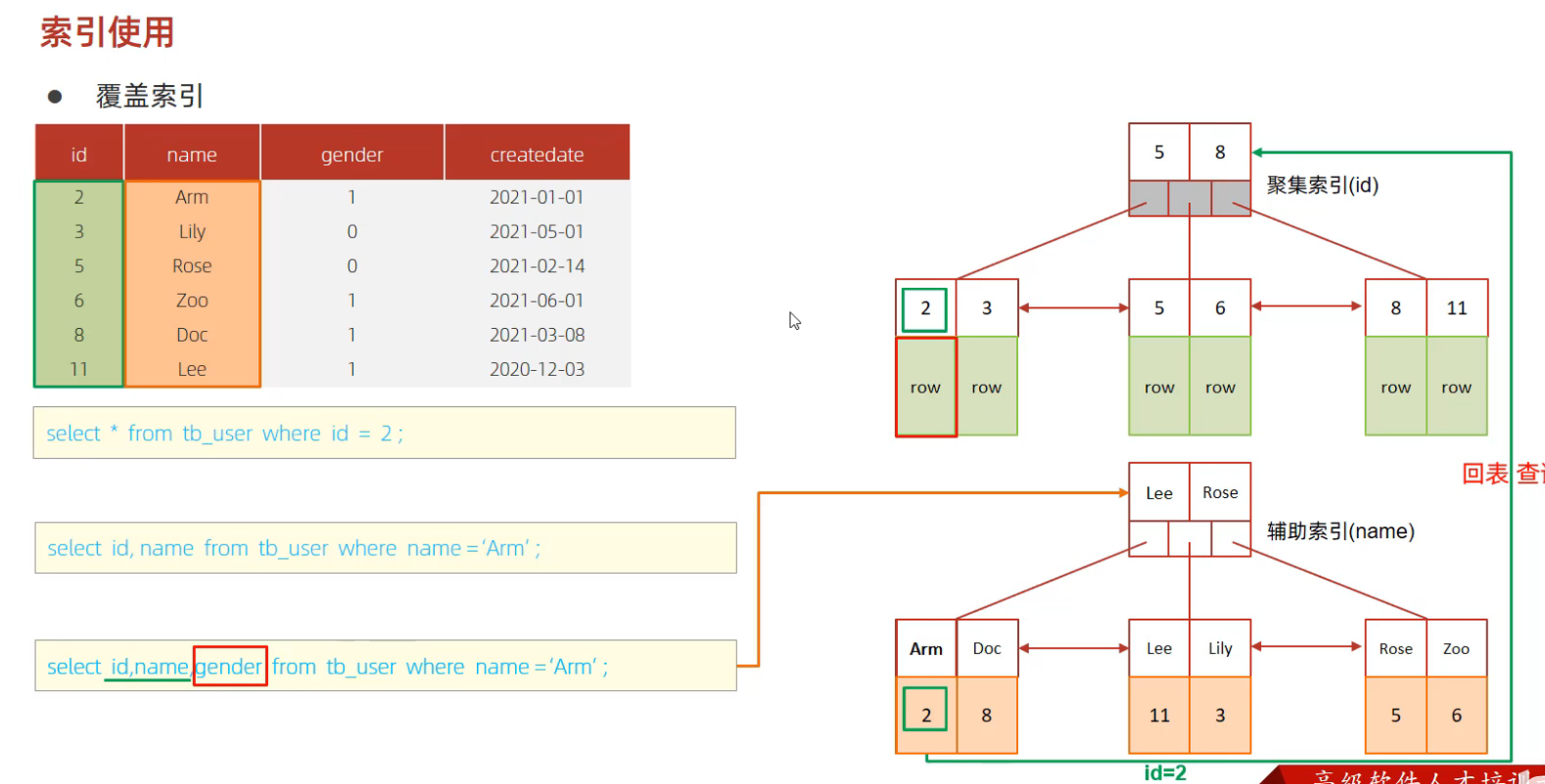
覆盖索引
- 定义:查询所需的所有字段都包含在索引中,无需回表
- 标识 :EXPLAIN的
Extra字段显示Using index
优化案例:
sql-- 原查询(回表) SELECT * FROM user WHERE name = '张三'; -- 优化后(覆盖索引) SELECT id, name FROM user WHERE name = '张三';
通过将查询字段限制为索引中已有的字段,避免了回表查询。
为什么要避免使用selcet*?
因为返回所有的字段,极易出现回表查询,影响查询效率。除非你有一个联合索引包含所有的字段。
7. 前缀索引
适用场景
- 字符串字段长度过长(如
VARCHAR(255)) - 字段值前缀有足够区分度
sql
-- 前缀长度为10
CREATE INDEX idx_name_prefix ON users(name(10));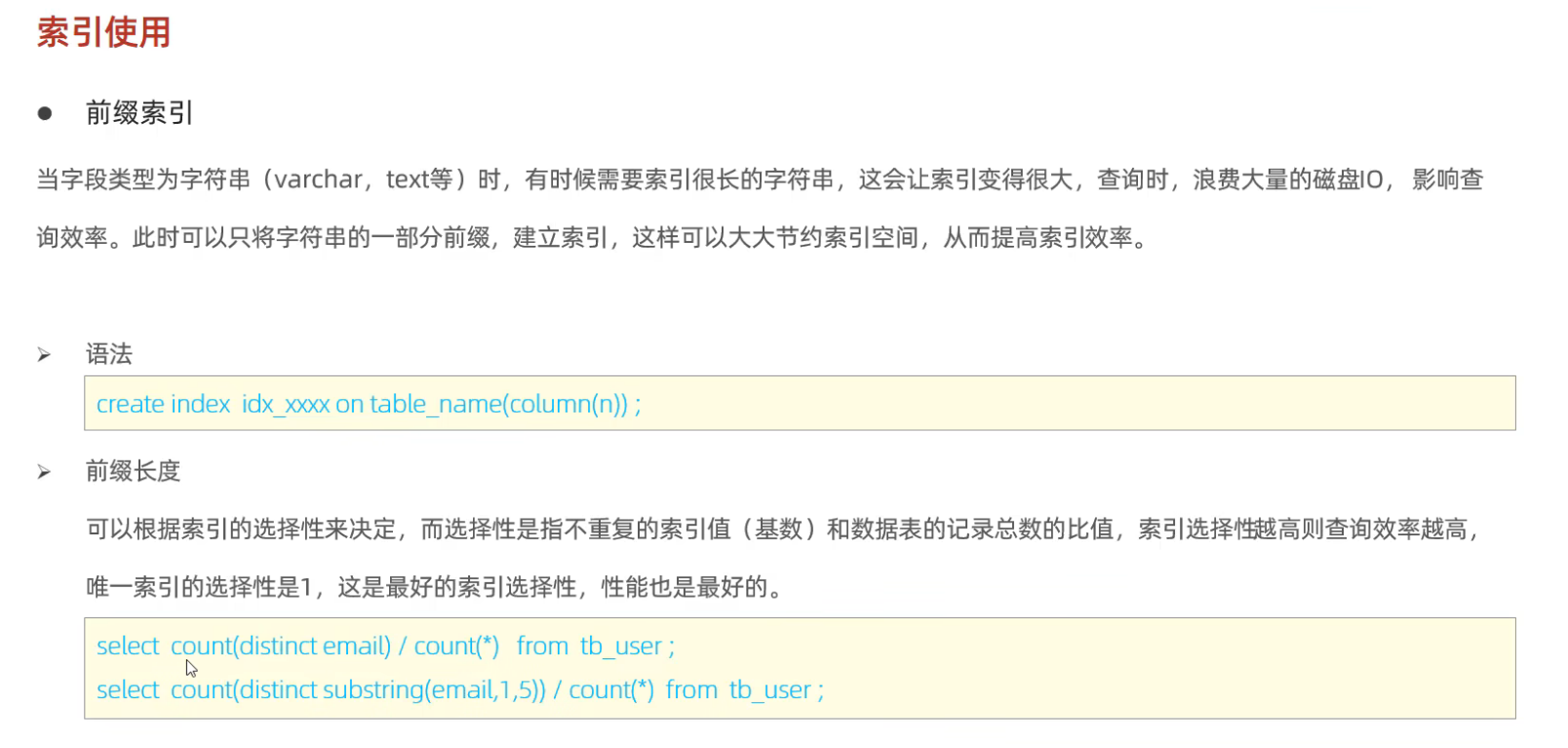
- 优势:减少索引大小,提高索引效率
- 风险:前缀长度过短可能导致索引区分度低
最佳实践 :通过
SELECT COUNT(DISTINCT LEFT(name, 10)) / COUNT(*) FROM users;计算区分度,确保前缀长度足够。
8. 单列索引和联合索引的选择问题
选择原则
| 场景 | 推荐索引类型 | 说明 |
|---|---|---|
| 单条件高频查询 | 单列索引 | 简单直接,效率高 |
| 多条件组合查询 | 联合索引 | 符合最左前缀原则 |
| 查询字段与索引字段匹配 | 覆盖索引 | 避免回表,性能最优 |
| 长字符串字段 | 前缀索引 | 减少索引大小 |

决策流程
- 分析查询模式:收集SQL日志,确定高频查询条件
- 评估字段区分度:确保索引字段有足够区分度
- 考虑查询字段:如果查询需要返回的字段在索引中,优先考虑覆盖索引
- 权衡存储与性能:避免过度索引,平衡存储空间与查询性能
sql
-- 情景:查询条件为 (category_id, price, status)
-- 方案1:创建三个单列索引
CREATE INDEX idx_category ON products(category_id);
CREATE INDEX idx_price ON products(price);
CREATE INDEX idx_status ON products(status);
-- 方案2:创建联合索引
CREATE INDEX idx_category_price_status ON products(category_id, price, status);
-- 方案3:创建覆盖索引
CREATE INDEX idx_category_price_status_cover ON products(category_id, price, status) INCLUDE (name, description);分析:方案2比方案1好,因为联合索引可以利用最左前缀原则;方案3比方案2更好,因为覆盖索引可以避免回表查询。
结语:索引优化的系统思维
索引优化不是简单的"加索引",而是一个系统化的过程:
- 先分析:通过慢查询日志和EXPLAIN分析问题SQL
- 再设计:根据查询模式和字段特性设计合适索引
- 后验证:通过实测和EXPLAIN确认优化效果
- 持续优化:定期分析索引使用情况,清理冗余索引
金句:"索引不是越多越好,而是越合适越好。" ------ 一位资深DBA