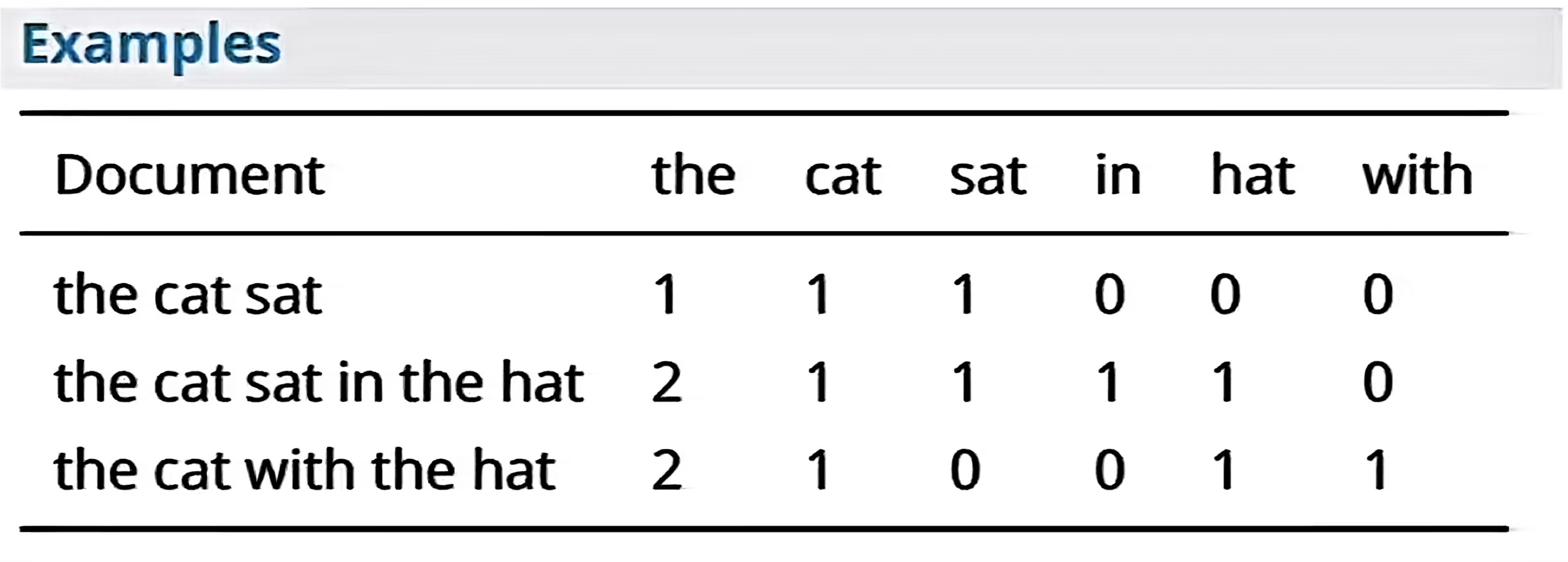
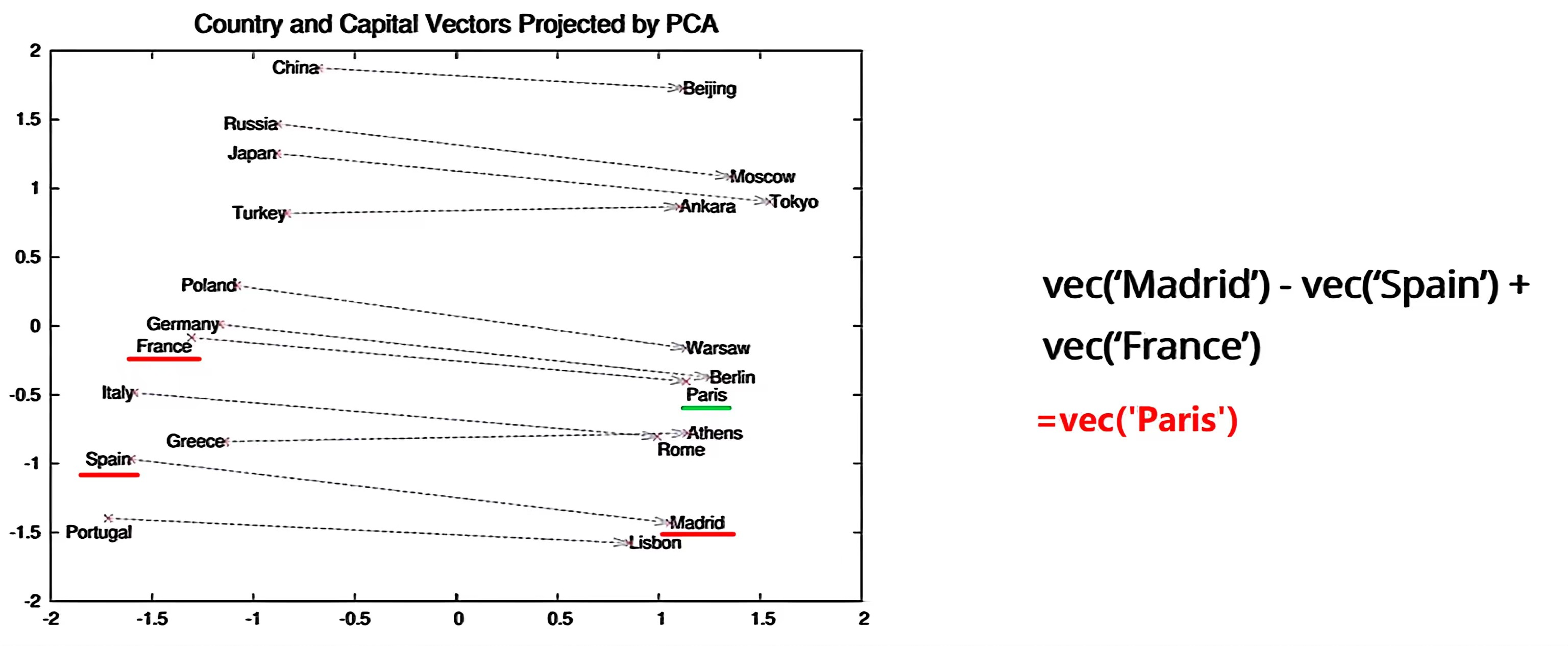
Word Embedding 的目标: 用低维、稠密的连续向量表示词,并让"语义相近的词在向量空间中距离更近"
Word2Vec
词的含义来自它的上下文
-> 语义相似的词会出现在相似的上下文中
Skip-gram:
给定语料:"the king loves the queen"
以窗口大小 c = 2 c=2 c=2 为例:当中心词是 king, 要预测the, loves
于是训练样本变成:
( king → the ) , ( king → loves ) (\text{king} \rightarrow \text{the}),\quad (\text{king} \rightarrow \text{loves}) (king→the),(king→loves)
Skip-gram 的目标函数(最大化):
1 T ∑ t = 1 T ∑ − c ≤ j ≤ c , j ≠ 0 log p ( w t + j ∣ w t ) \frac{1}{T}\sum_{t=1}^{T}\sum_{-c\leq j\leq c,j\neq 0}\log p\left(w_{t+j}\mid w_{t}\right) T1t=1∑T−c≤j≤c,j=0∑logp(wt+j∣wt)
T T T:语料中词的总数
w t w_t wt:中心词
w t + j w_{t+j} wt+j:上下文词
目标 :给定中心词 w t w_t wt,最大化真实上下文词出现的概率
Skip-gram 的概率模型:(Softmax)
p ( w O ∣ w I ) = exp ( v w O ′ ⊤ v w I ) ∑ w = 1 W exp ( v w ′ ⊤ v w I ) p\left(w_{O}\mid w_{I}\right) =\frac{\exp\left(v_{w_{O}}^{\prime\top} v_{w_{I}}\right)} {\sum_{w=1}^{W}\exp\left(v_{w}^{\prime\top} v_{w_{I}}\right)} p(wO∣wI)=∑w=1Wexp(vw′⊤vwI)exp(vwO′⊤vwI)