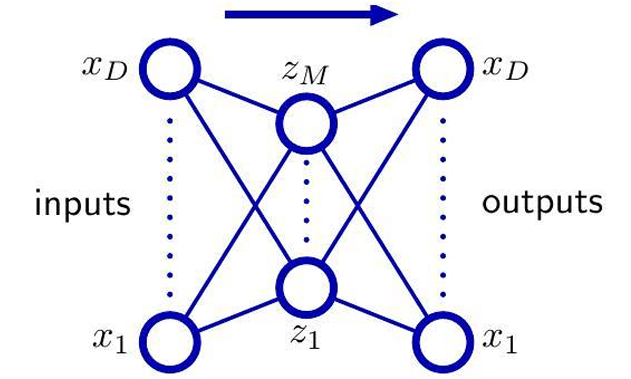
在所有 d ′ d' d′ 维线性子空间中,找到一个子空间(正交基),使数据投影后"丢失的信息最少"
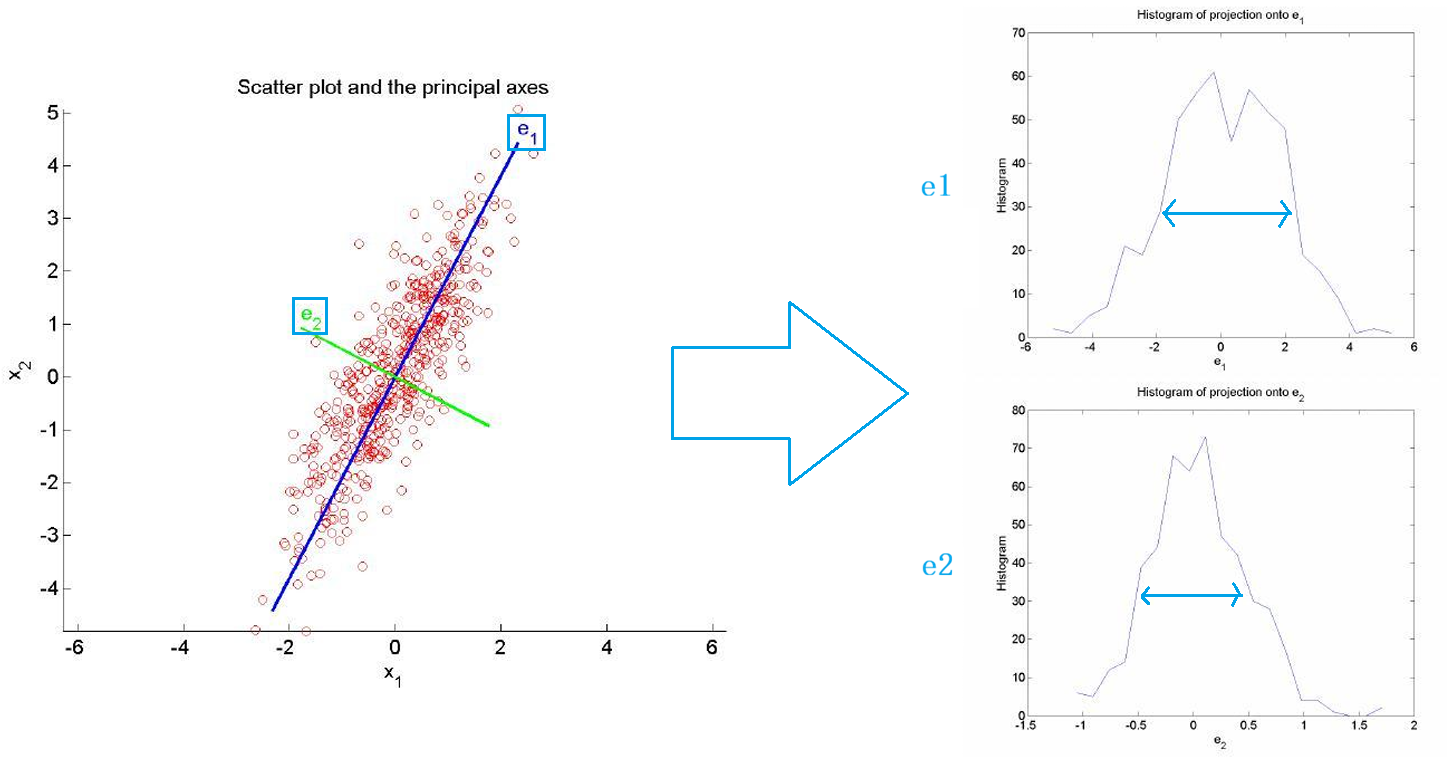
PCA 并不是在"找特征",而是在选一个低维平面/子空间
重构误差(最小化)
对每个样本做三步:
原始样本: x i ∈ R d x_i \in \mathbb{R}^d xi∈Rd
投影到低维子空间(压缩):
d ′ d' d′个基向量 e e e, 每个基向量都是低维空间的一个方向
每个基向量 e e e都有 d d d个值(代表该基向量与各原始特征的关系)
各个基向量 e e e都相互正交
再从低维子空间还原回高维(重构): x ~ i \tilde{x}_i x~i
重构误差 就是: ∥ x i − x ~ i ∥ 2 \|x_i - \tilde{x}_i\|^2 ∥xi−x~i∥2
-> 用"能否被好好还原"来衡量所选的低维子空间是不是一个"好子空间"
目标函数
J d ′ = ∑ i = 1 n ∥ ∑ k = 1 d ′ y i k e k − x i ∥ 2 = ∑ i ∥ x ~ i − x i ∥ 2 i J_{d'} = \sum_{i=1}^{n} \left\| \sum_{k=1}^{d'} y_{ik} \mathbf{e}_k - \mathbf{x}_i \right\|^2 =\sum_i \|\tilde{x}_i - x_i\|^2i Jd′=i=1∑n k=1∑d′yikek−xi 2=i∑∥x~i−xi∥2i
e k e_k ek:低维子空间的第 k k k 个基向量(方向)
y i k = e k T x i y_{ik}=e_k^Tx_i yik=ekTxi:样本 x i x_i xi 在方向 e k e_k ek 上的长度
∑ k = 1 d ′ y i k e k \sum_{k=1}^{d'} y_{ik} e_k ∑k=1d′yikek:用低维子空间"拼出来"的 x ~ i \tilde{x}_i x~i
x ~ i = ∑ k = 1 d ′ e k T x i e k \tilde{x}i=\sum{k=1}^{d'} e_k^Tx_i e_k x~i=∑k=1d′ekTxiek
正交基 δ i j \delta_{ij} δij
PCA 的最优解一定可以选成正交基
-> 正交基不是假设,是最优形式
设 {u_i}, i=1,...,D 是一组正交基,满足:
x n = c 1 u 1 + c 2 u 2 + . . . + c d u d u i T u j = δ i j = { 0 , i ≠ j 1 , i = j x_n = c_1u_1 + c_2u_2 + ... + c_du_d \\ u_i^T u_j = \delta_{ij} = \begin{cases} 0, & i \ne j \\ 1, & i =j \end{cases} xn=c1u1+c2u2+...+cduduiTuj=δij={0,1,i=ji=j
c c c 代表在各个正交基向量上的投影系数
推导:
x n = ∑ i = 1 D c i u i u j T x n = u j T ∑ i = 1 D c i u i u j T x n = ∑ i = 1 D c i ( u j T u i ) u j T x n = c j ⋅ 1 + ∑ i ≠ j c i ⋅ 0 = c j x_n = \sum_{i=1}^D c_i u_i \\ u_j^T x_n = u_j^T \sum_{i=1}^D c_i u_i \\ u_j^T x_n = \sum_{i=1}^D c_i \, (u_j^T u_i) \\ u_j^T x_n = c_j \cdot 1 + \sum_{i\neq j} c_i \cdot 0 = c_j xn=i=1∑DciuiujTxn=ujTi=1∑DciuiujTxn=i=1∑Dci(ujTui)ujTxn=cj⋅1+i=j∑ci⋅0=cj
得到:
u j T x n = c j u_j^T x_n = c_j ujTxn=cj
在正交基下,投影系数 c i c_i ci = 样本向量 x n x_n xn 与 基向量 u i u_i ui 的内积
进而得到:
x n = ∑ i = 1 D ( u i T x n ) u i x_n = \sum_{i=1}^{D} (u_i^T x_n)\, u_i xn=i=1∑D(uiTxn)ui
任意向量,都可以分解成"沿每个正交方向的分量之和"
PCA 接下来做的事是: 只保留其中的一部分方向
重构样本
x ~ n = ∑ i = 1 M z n i u i + ∑ i = M + 1 D b i u i \widetilde{x}n = \sum{i=1}^{M} z_{ni} u_i + \sum_{i=M+1}^{D} b_i u_i x n=i=1∑Mzniui+i=M+1∑Dbiui
z n i z_{ni} zni 是与数据相关的系数
b i b_i bi 是常数系数
降维的核心是保留前 M M M 个与数据相关的系数,丢弃后 D − M D-M D−M 个常数系数
对重构误差 J 求偏导,可得最优系数:
{ z n i = x n T u i , i = 1 , ... , M b i = x ˉ T u i , i = M + 1 , ... , D \begin{cases} z_{ni} = x_{n}^{T}u_i, & i=1,\ldots, M \\ b_i = \bar{x}^{T} u_i, & i=M+1,\ldots, D \end{cases} {zni=xnTui,bi=xˉTui,i=1,...,Mi=M+1,...,D
x ˉ \bar{x} xˉ 是样本均值, 以此来作为常数
此时,误差可化简为:
(误差只剩"被丢弃的方向")(重构误差 = 样本在"被丢弃方向"上的投影)
x n − x ~ n = ∑ i = M + 1 D { ( x n − x ˉ ) T u i } u i x_{n} - \tilde{x}{n} = \sum{i=M+1}^{D} \left\{ \left(x_{n}-\bar{x}\right)^{\mathrm{T}} u_{i} \right\} u_{i} xn−x~n=i=M+1∑D{(xn−xˉ)Tui}ui
最终误差与协方差矩阵
将误差代入目标函数,最终得到:
(PCA 的重构误差 = 被丢弃方向上的方差之和)
J = ∑ i = M + 1 D u i T S u i J = \sum_{i=M+1}^{D} u_{i}^{\mathrm{T}} S u_i J=i=M+1∑DuiTSui
其中 S = 1 N ∑ n = 1 N ( x n − x ˉ ) ( x n − x ˉ ) T S = \frac{1}{N} \sum_{n=1}^{N} \left(x_{n}-\bar{x}\right)\left(x_{n}-\bar{x}\right)^{\mathrm{T}} S=N1∑n=1N(xn−xˉ)(xn−xˉ)T 是样本协方差矩阵
如果: S u i = λ i u i S u_i = \lambda_i u_i Sui=λiui
那么: u i T S u i = λ i u_i^T S u_i = \lambda_i uiTSui=λi
于是: J = ∑ i = M + 1 D λ i J = \sum_{i=M+1}^D \lambda_i J=∑i=M+1Dλi
结论:想让误差最小,就丢掉最小的特征值
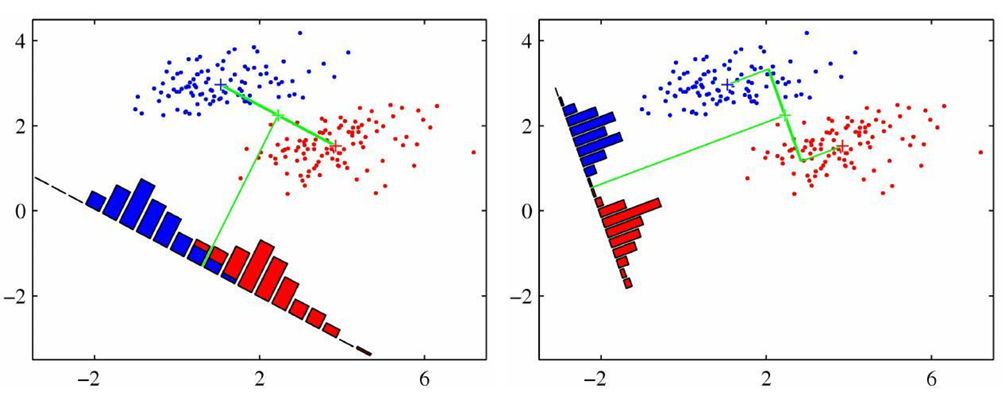
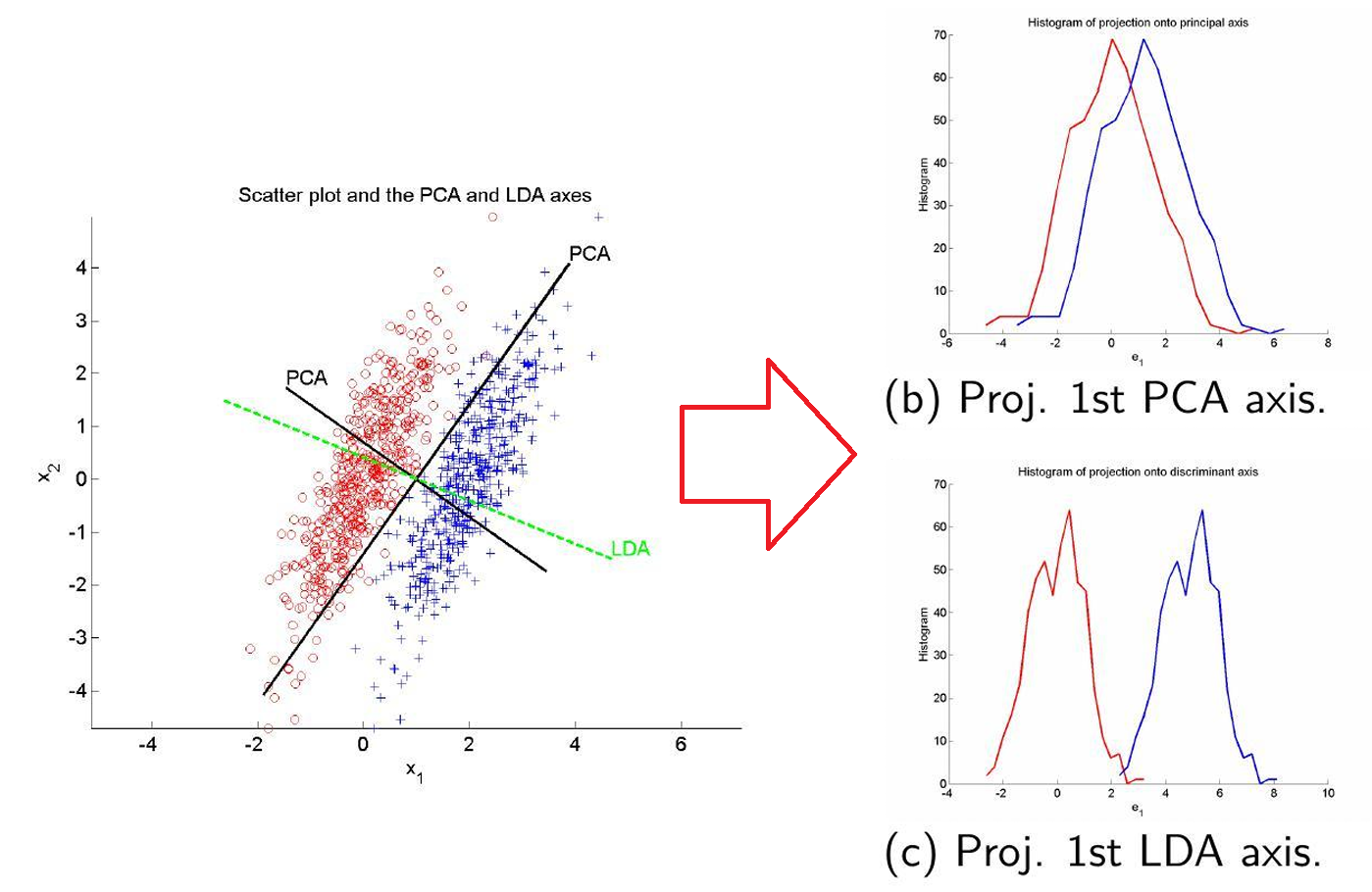
最小化重构误差 ⇔ 最大化方差
本征维度
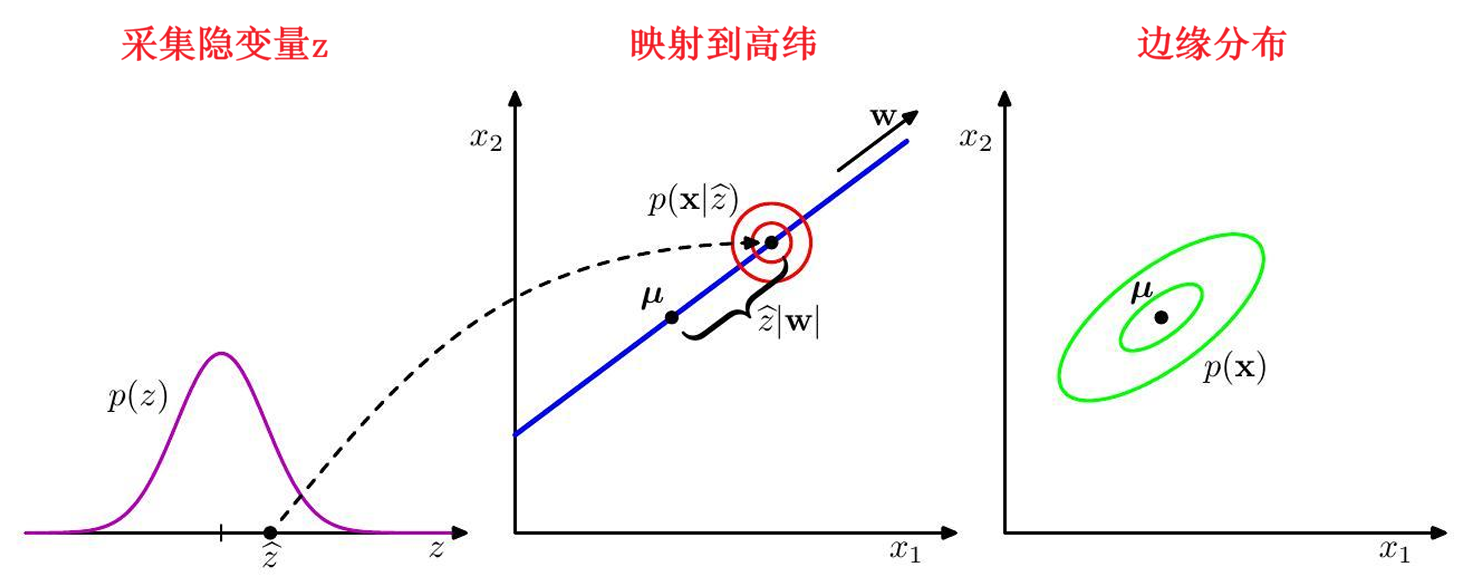
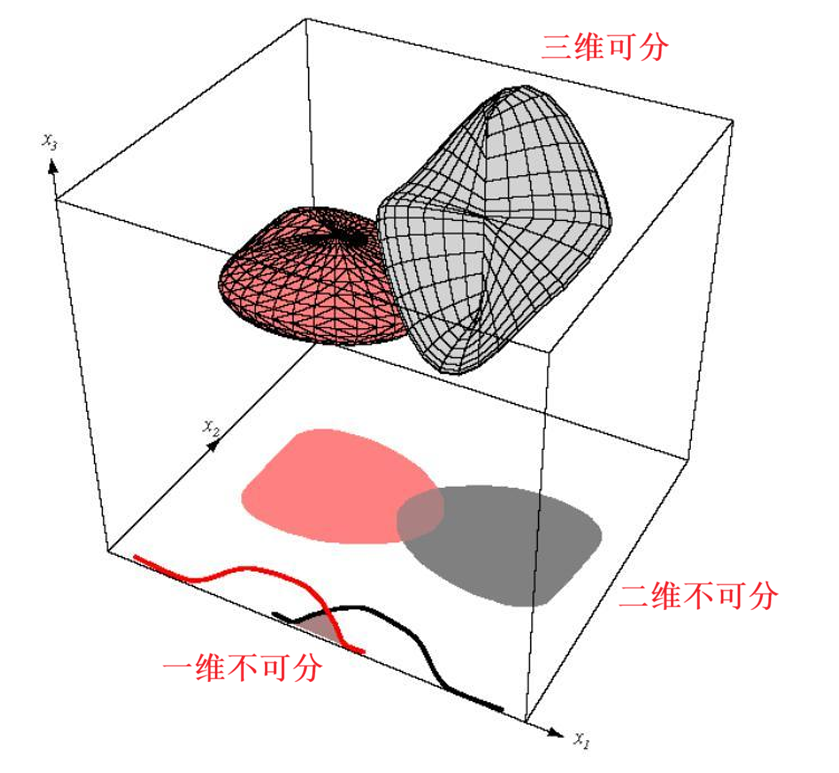
高维数据并没有"真正占满"高维空间,而是集中分布在一个低维子空间中
本征维度:数据实际分布的低维超平面维度(低于观测维度)
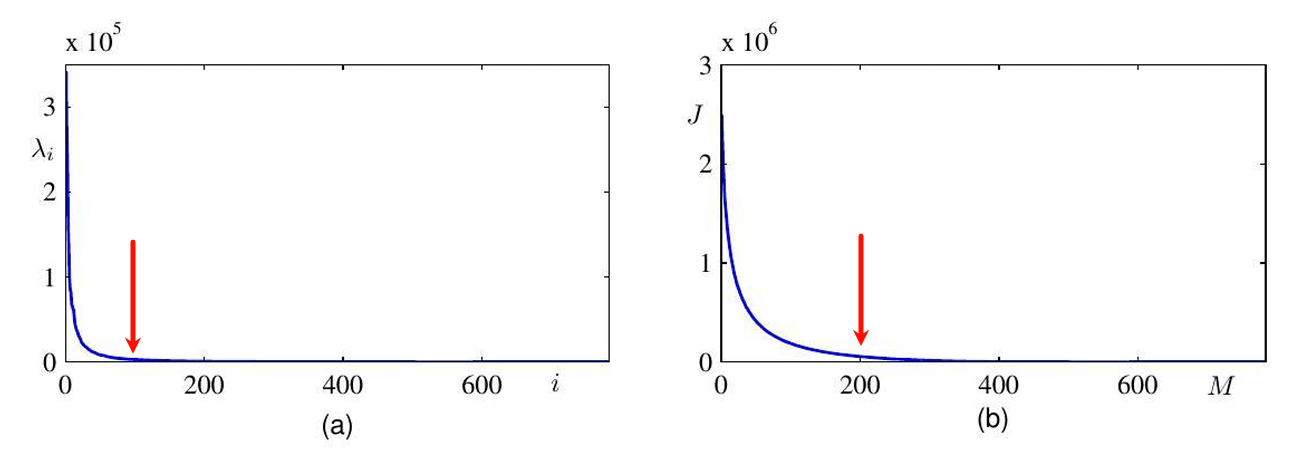
MNIST的维度: D = 784 D = 784 D=784(28×28 像素)
但数据"真正用到"的维度:可能只有 100 ∼ 200 100\sim200 100∼200
784维降至250维即可保留主要信息:
特征值的意义: λ i = 数据在方向 u i 上的方差 \lambda_i = \text{数据在方向 } u_i \text{ 上的方差} λi=数据在方向 ui 上的方差
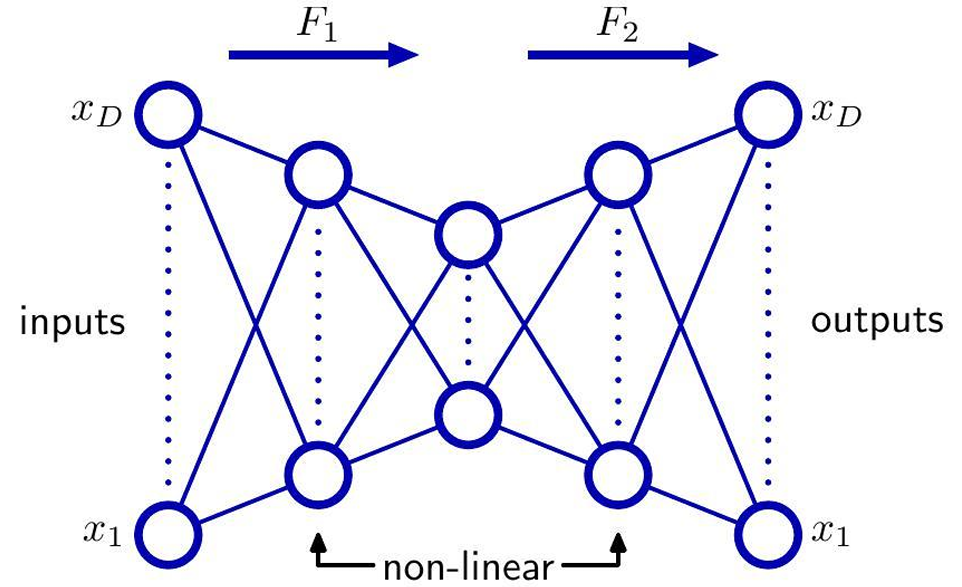
x → h 1 → h 2 → z → h 2 ′ → h 1 ′ → x ~ x \rightarrow h_1 \rightarrow h_2 \rightarrow z \rightarrow h_2' \rightarrow h_1' \rightarrow \tilde{x} x→h1→h2→z→h2′→h1′→x~
在到达瓶颈层之前,空间已经被反复"弯曲"和"拉直"
编码函数 f ( x ) f(x) f(x) 是深度复合非线性
解码函数 g ( z ) g(z) g(z) 同样是深度复合非线性
-> 整体学到的是一个非线性流形坐标系
线性判别分析LDA
LDA: linear discriminant analysis
1.类别分离度的度量
设投影向量为 w w w,类别 C_k 的投影均值 为 m_k = w\^T \\mu_k ( ( ( \\mu_k 是原始空间中类别 C_k 的均值)
J ( w ) = 类间方差 类内方差 = ( m 2 − m 1 ) 2 s 1 2 + s 2 2 = w T S B w w T S W w S B = ( m 2 − m 1 ) ( m 2 − m 1 ) T S W = ∑ n ∈ C 1 ( x n − m 1 ) ( x n − m 1 ) T + ∑ n ∈ C 2 ( x n − m 2 ) ( x n − m 2 ) T J(\mathbf{w}) = \frac{\text{类间方差}}{\text{类内方差}} = \frac{\left(m_{2} - m_{1}\right)^{2}}{s_{1}^{2} + s_{2}^{2}}=\frac{w^TS_Bw}{w^TS_Ww} \\ S_B=(m_2-m_1)(m_2-m_1)^T \\ S_W=\sum_{n \in C_1} (x_n-m_1)(x_n-m_1)^T + \sum_{n \in C_2} (x_n-m_2)(x_n-m_2)^T J(w)=类内方差类间方差=s12+s22(m2−m1)2=wTSWwwTSBwSB=(m2−m1)(m2−m1)TSW=n∈C1∑(xn−m1)(xn−m1)T+n∈C2∑(xn−m2)(xn−m2)T
得到:
S w − 1 S B w = λ w S_w^{-1}S_Bw=\lambda w Sw−1SBw=λw
3.最优投影方向求解
将准则函数推广到多类别场景,定义类内散度矩阵 S w S_w Sw 和类间散度矩阵 S B S_B SB,则准则函数变为:
J ( W ) = t r ( W T S B W ) t r ( W T S w W ) J(W) = \frac{tr(W^T S_B W)}{tr(W^T S_w W)} J(W)=tr(WTSwW)tr(WTSBW)
结论:当 W 的列向量是 S_w\^{-1} S_B 的最大特征值对应的特征向量时, J(W) 达到最大
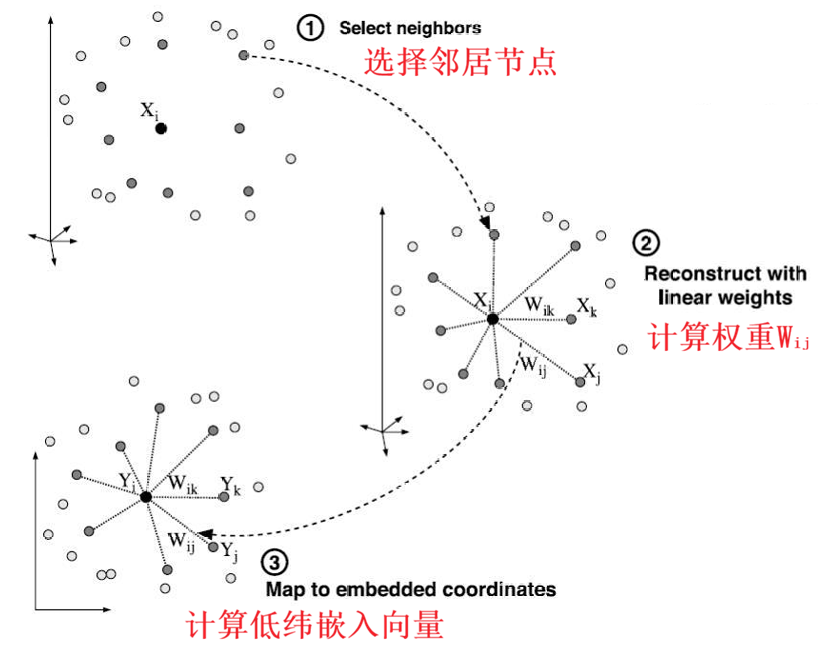
在局部小邻域中,点 x i x_i xi 可以由它的邻居 x j x_j xj 按某个固定比例'拼'出来 :
x i ≈ ∑ j W i j x j x_i \approx \sum_j W_{ij} x_j xi≈j∑Wijxj
W i j W_{ij} Wij 表示邻居 j j j 在重构 i i i 时的重要程度
只允许"邻居"参与重构 :
非邻近点: W i j = 0 \text{非邻近点:}\quad W_{ij}=0 非邻近点:Wij=0 要求 ∑ j W i j = 1 \sum_j W_{ij}=1 ∑jWij=1 -> 消除平移影响
假设所有数据整体平移: x j → x j + c x_j \rightarrow x_j + c xj→xj+c
如果: ∑ j W i j = 1 j \sum_j W_{ij} = 1j ∑jWij=1j
那么: ∑ j W i j ( x j + c ) = ∑ j W i j x j + c \sum_j W_{ij}(x_j + c) = \sum_j W_{ij}x_j + c ∑jWij(xj+c)=∑jWijxj+c
-> 重构误差 不变
"只用邻居 + 权重和为 1",可以得到:
平移不变
旋转不变
等比例缩放不变
-> 权重 W i j W_{ij} Wij 捕捉的是"纯几何关系"
重构误差函数(学习权重) :
ϵ ( W ) = ∑ i ∥ x i − ∑ j W i j x j ∥ 2 \epsilon(\mathbf{W}) = \sum_{i} \left\| \mathbf{x}{i} - \sum{j} W_{ij} \mathbf{x}_{j} \right\|^{2} ϵ(W)=i∑ xi−j∑Wijxj 2
约束条件:
每个样本仅能由其邻近点重构(非邻近点 W i j = 0 W_{ij}=0 Wij=0)
权重矩阵每行和为1( ∑ j W i j = 1 \sum_j W_{ij}=1 ∑jWij=1)
性质:权重 W_{ij} 对样本的旋转、缩放、平移变换具有不变性
LLE认为: 只要低维空间能保持同样的重构权重,全局结构自然会对
低维嵌入误差函数(固定权重) :
Φ ( Y ) = ∑ i ∥ y i − ∑ j W i j y j ∥ 2 \Phi(\mathbf{Y}) = \sum_{i} \left\| \mathbf{y}{i} - \sum{j} W_{ij} \mathbf{y}_{j} \right\|^{2} Φ(Y)=i∑ yi−j∑Wijyj 2
求解:通过稀疏特征值分解最小化 \\Phi(\\mathbf{Y}) ,取最小的 d' 个非零特征向量作为低维坐标
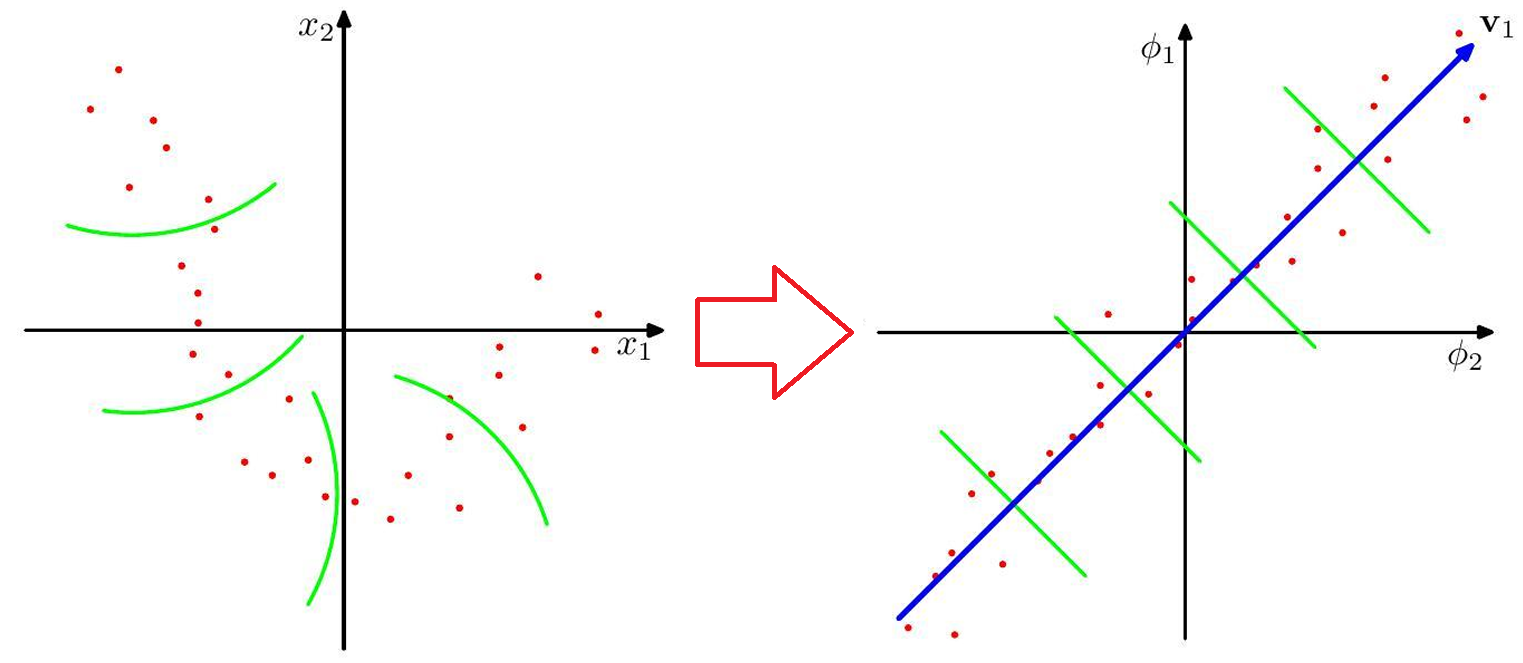
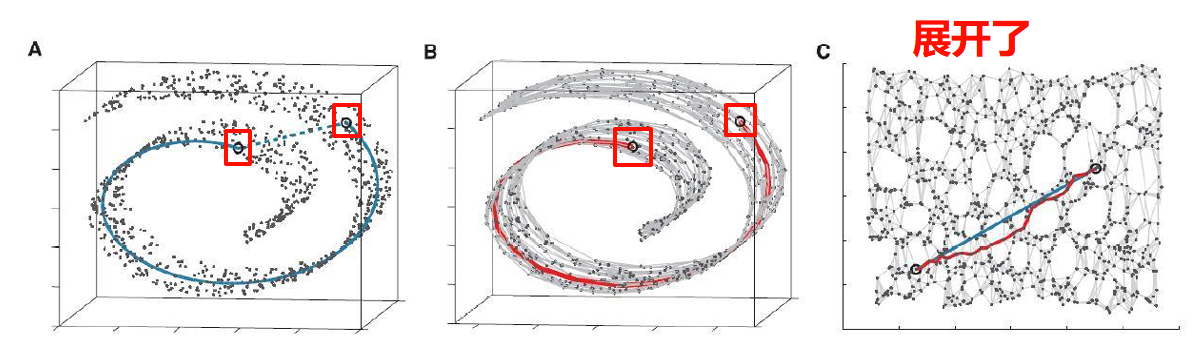
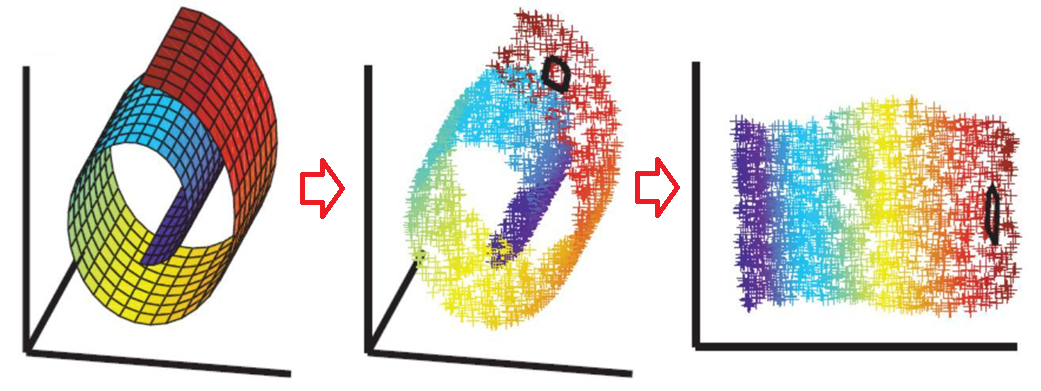
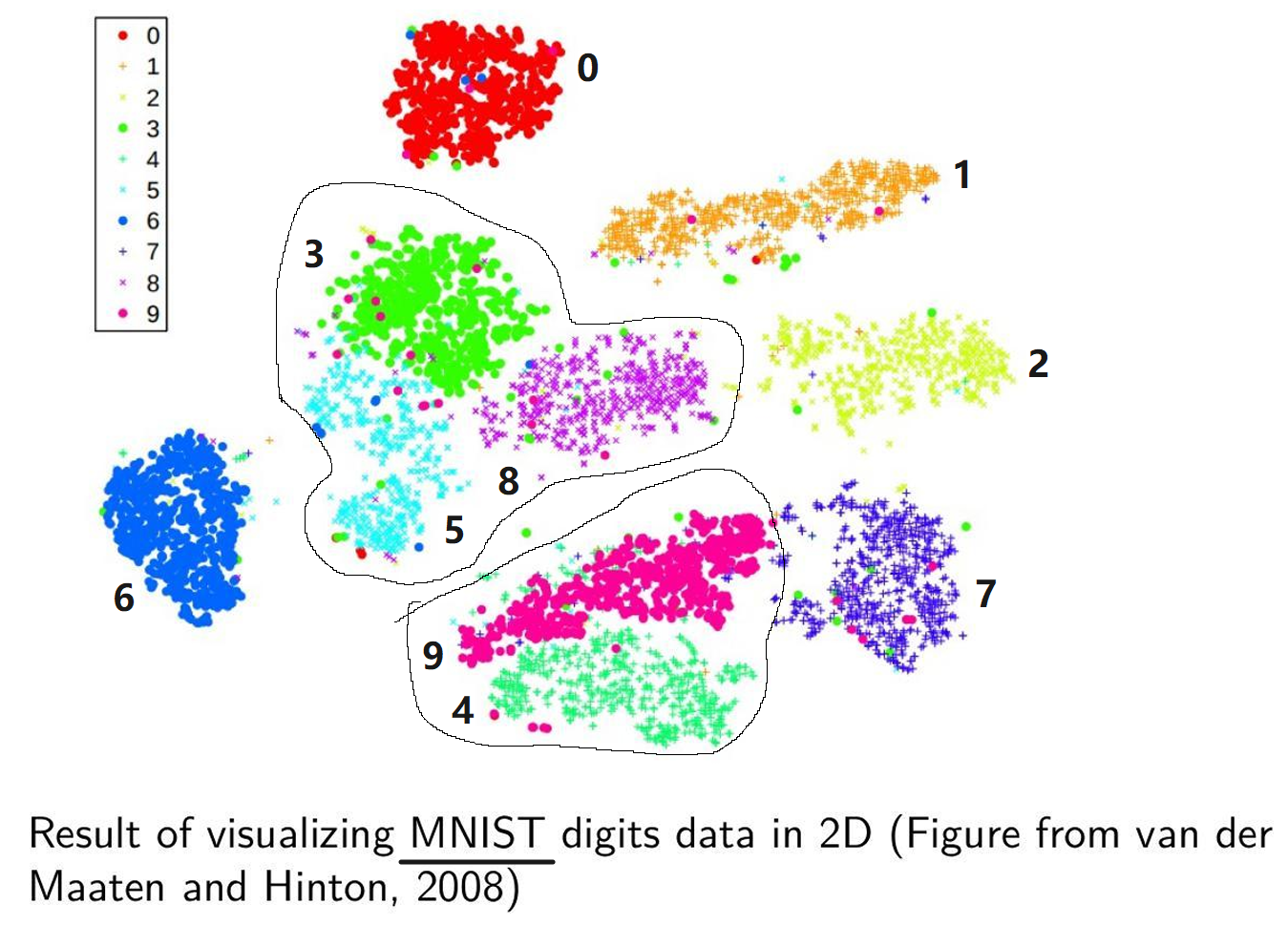
瑞士卷:
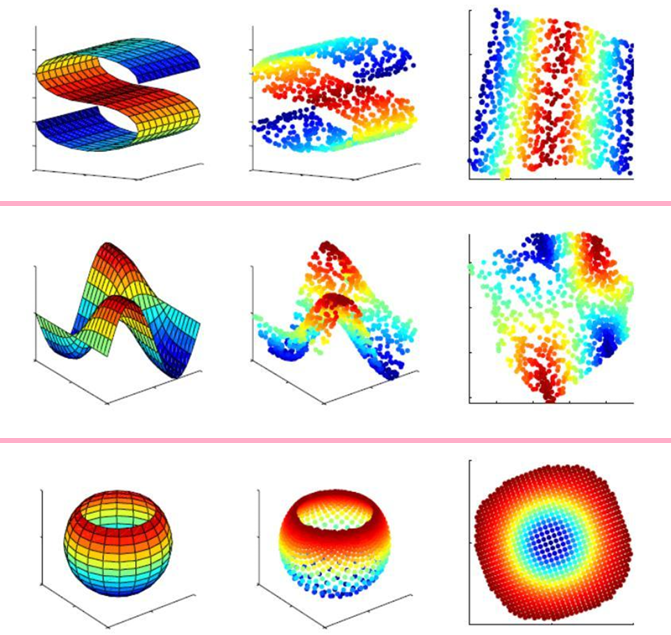
其他图例:
3.随机近邻嵌入(SNE)与t-SNE
SNE: 在某个点看来,谁像其邻居
让低维空间中的邻居关系,看起来像高维空间中的邻居关系
SNE 不关心:距离值是否准确or全局几何是否保留
-> 只关心相似性排序是否一致
把"几何问题"变成"概率匹配问题":
p j ∣ i = exp ( − ∥ x i − x j ∥ 2 / 2 σ 2 ) ∑ k ≠ i exp ( − ∥ x i − x k ∥ 2 / 2 σ 2 ) q j ∣ i = exp ( − ∥ z i − z j ∥ 2 / 2 σ 2 ) ∑ k ≠ i exp ( − ∥ z i − z k ∥ 2 / 2 σ 2 ) p_{j|i} = \frac{\exp(-\|\mathbf{x}_i - \mathbf{x}j\|^2 / 2\sigma^2)}{\sum{k \neq i} \exp(-\|\mathbf{x}_i - \mathbf{x}k\|^2 / 2\sigma^2)} \\ q{j|i} = \frac{\exp(-\|\mathbf{z}_i - \mathbf{z}j\|^2 / 2\sigma^2)}{\sum{k \neq i} \exp(-\|\mathbf{z}_i - \mathbf{z}_k\|^2 / 2\sigma^2)} pj∣i=∑k=iexp(−∥xi−xk∥2/2σ2)exp(−∥xi−xj∥2/2σ2)qj∣i=∑k=iexp(−∥zi−zk∥2/2σ2)exp(−∥zi−zj∥2/2σ2)
p j ∣ i p_{j|i} pj∣i: 如果我站在点 i i i,我会以多大概率把 j j j 当作邻居
距离越近 → 概率越大
距离越远 → 指数衰减
维度
p(高维相似性)
q(低维相似性)
所在空间
原始高维空间 x i ∈ R D x_i \in \mathbb{R}^D xi∈RD
嵌入后的低维空间 y i ∈ R d y_i \in \mathbb{R}^d yi∈Rd
表示什么
真实邻居关系
可视化后的邻居关系
含义
点 j j j 在高维中是点 i i i 邻居的概率
点 j j j 在低维图中看起来像点 i i i 邻居的概率
数学形式
p j ∣ i p_{j\mid i} pj∣i
q j ∣ i q_{j\mid i} qj∣i
由谁决定
数据本身(距离 + 高斯核)
当前低维坐标(画出来的图)
是否被优化
否(固定不变)
是(不断调整)
"犯错"时的后果
------
被 KL 散度惩罚
KL 散度: K L ( P ∥ Q ) KL(P\|Q) KL(P∥Q)
-> 如果我以 P P P 为真实分布,却用近似分布 Q Q Q 来近似,会损失多少信息
K L ( P ∥ Q ) = ∑ p log p q KL(P\|Q)=\sum p \log\frac{p}{q} KL(P∥Q)=∑plogqp
定义马氏距离(mahalanobis distance)为:
∥ x i − x j ∥ M 2 = ( x i − x j ) T M ( x i − x j ) \| \mathbf{x}_i - \mathbf{x}_j \|_M^2 = (\mathbf{x}_i - \mathbf{x}_j)^T M (\mathbf{x}_i - \mathbf{x}_j) ∥xi−xj∥M2=(xi−xj)TM(xi−xj)
其中 M M M 是半正定度量矩阵(保证距离非负、对称), 也叫度量矩阵(metric matrix)
特殊情况:若 M M M 是对角阵,则等价于对不同特征赋予不同权重(特征加权)
想要距离是非负以及对称, 也就是M得是半正定的
2.与最近邻KNN分类器的结合
将度量矩阵 M M M 嵌入最近邻分类器的性能度量中,定义样本 x j x_j xj 对 x i x_i xi 的影响概率:
p i j = exp ( − ∥ x i − x j ∥ M 2 ) ∑ l exp ( − ∥ x i − x l ∥ M 2 ) p_{ij} = \frac{\exp\left(-\|\mathbf{x}{i}-\mathbf{x}{j}\|{M}^{2}\right)}{\sum{l}\exp\left(-\|\mathbf{x}{i}-\mathbf{x}{l}\|_{M}^{2}\right)} pij=∑lexp(−∥xi−xl∥M2)exp(−∥xi−xj∥M2)
说明: i = j i=j i=j 时 p i j p_{ij} pij 最大,影响随距离增大而减小
通过领域知识约束 p i j p_{ij} pij(相似样本 p i j p_{ij} pij 大,不相似样本 p i j p_{ij} pij 小),可求解得到最优度量矩阵 M M M