一、消息队列
1.什么是消息队列
消息队列是进程间通信(IPC)的一种方式 (和管道、共享内存是同级的通信手段),作用是让多个进程通过 "消息队列" 来传递结构化的数据(消息)。
2.消息队列结构体设计
消息载体硬性要求
传递的消息必须封装为自定义结构体,且有严格格式要求:
①结构体第一个成员必须是 long int 类型 (命名一般为mtype),代表「消息类型」,取值要求:mtype ≥ 1;
②从第二个成员开始,可自定义任意数据(字符数组、整型、浮点型等),用来存放实际要传递的业务数据。
标准示例:
// 消息结构体:格式固定、可直接复用
struct msgbuf {
long mtype; // 第一成员必须是long,消息类型,≥1
char mtext[128]; // 自定义数据区,存实际消息内容,可改类型/大小
};3. 核心操作(2 个核心,原版保留)
添加消息(发消息):将封装好的「消息结构体」,发送并存入消息队列;
读取消息(收消息) :从消息队列中,取出指定mtype类型的消息结构体。
4.消息队列 3 大核心函数(原版补充 + 极简参数 + 核心作用,好记不复杂)
①msgget() ------ 创建 / 获取消息队列(对标共享内存shmget)
核心作用:创建一个新的消息队列,或获取系统中已存在的消息队列;
核心逻辑:进程通过唯一 key 值,识别并操作同一个消息队列;
成功返回「消息队列 ID」,失败返回-1。
cpp
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/msg.h>
int main()
{
int msgid = msgget((key_t)1234, IPC_CREAT|0600);
if (msgid == -1 )
{
exit(1);
}
exit(0);
}关键代码行讲解:
-
msgget((key_t)1234, IPC_CREAT|0600):(key_t)1234:给消息队列指定一个唯一标识(钥匙) ,其他进程用相同的1234可以找到这个队列;IPC_CREAT:规则是 "如果这个队列不存在,就新建一个;如果已经存在,就直接获取它";0600:设置消息队列的权限(当前用户可读可写);- 执行后返回「消息队列的 ID」,存在
msgid变量里。
-
if (msgid == -1 ) exit(1);:如果msgget执行失败(比如权限不足),msgid会等于-1,此时直接退出程序。
使用命令ipcs看到我们的创建的消息队列
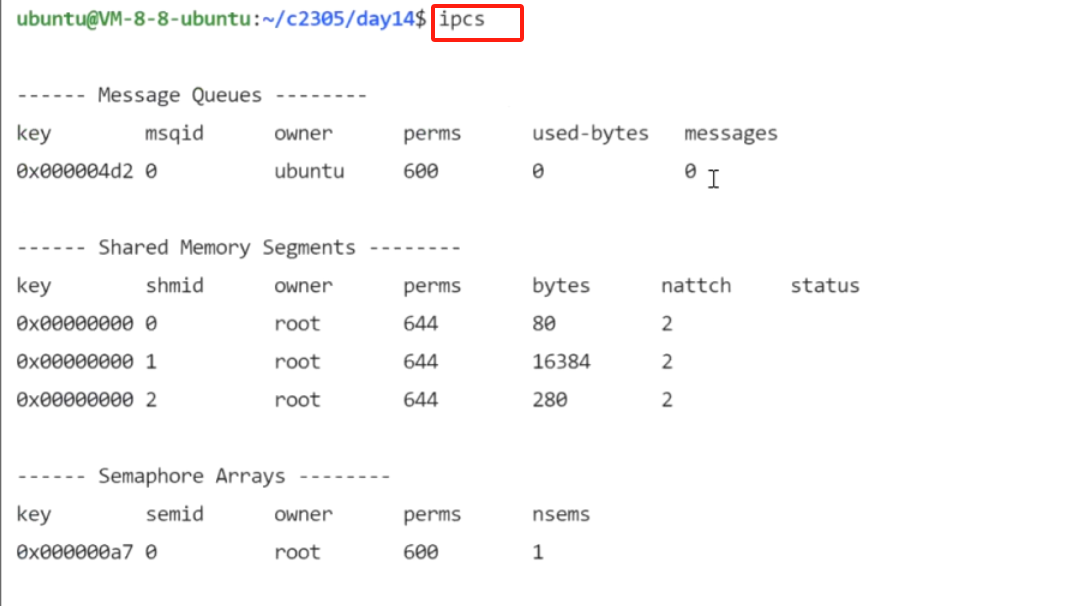
② msgsnd() ------ 向队列添加消息(发消息)
核心作用:把封装好的「消息结构体」,发送到指定的消息队列中;
核心逻辑:传入「队列 ID + 消息结构体地址」,完成消息发送;
成功返回0,失败返回-1。
cpp
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/msg.h>
struct mess
{
long type;
char buff[128];
};
int main()
{
int msgid = msgget((key_t)1234, IPC_CREAT|0600);
if (msgid == -1 )
{
exit(1);
}
struct mess m;
m.type = 1;
strcpy(m.buff,"hello1");
msgsnd(msgid,&m,128,0);
exit(0);
}-
定义消息结构体
struct mess:遵循消息队列的硬性规则:- 第一个成员是
long type(消息类型,值≥1); - 第二个成员是自定义的
char buff[128](用来存实际要发送的内容)。
- 第一个成员是
-
创建消息队列 :通过
msgget((key_t)1234, IPC_CREAT|0600)创建 / 获取key=1234的消息队列,失败则退出程序。 -
封装消息:
- 定义结构体变量
struct mess m; - 给
m.type赋值为1(指定消息类型,后续读消息时要匹配这个类型); - 用
strcpy(m.buff,"hello1")把要发送的内容"hello1"存入结构体的数据区。
- 定义结构体变量
-
发送消息到队列 :调用
msgsnd(msgid, &m, 128, 0):msgid:目标消息队列的 ID;&m:要发送的消息结构体地址;128:消息数据区(buff)的大小;0:默认发送规则(阻塞等待,直到发送成功)。
运行后可以看到 我们们的消息队列个数发生改变
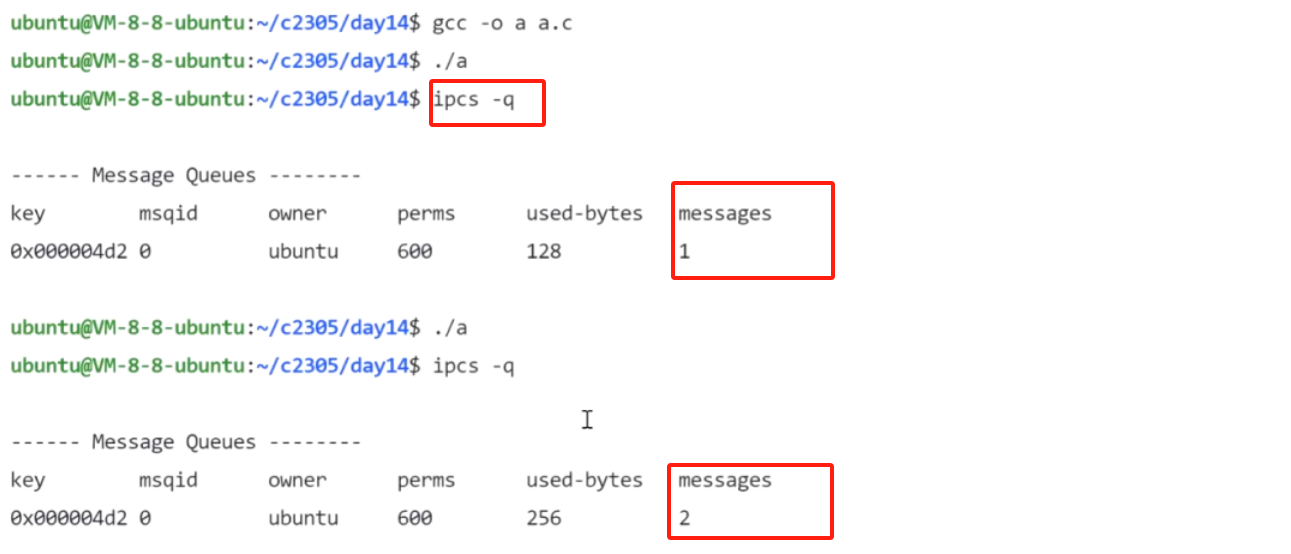
③msgrcv() ------ 从队列读取消息(收消息)
核心作用:从指定消息队列中,读取指定 mtype 类型的消息;
核心优势:可精准读取某一类消息,未指定的消息会留在队列中,实现「类型筛选」;
成功返回读取的字节数,失败返回-1。
cpp
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/msg.h>
struct mess
{
long type;
char buff[128];
};
int main()
{
int msgid = msgget((key_t)1234, IPC_CREAT|0600);
if (msgid == -1 )
{
exit(1);
}
struct mess m;
msgrcv(msgid,&m,128,1,0);
printf("read msg:%s\n",m.buff);
exit(0);
}这段代码是消息队列的「读取消息」程序,与之前的「发送消息」程序配套,核心作用是从指定消息队列中读取特定类型的消息:
- 获取消息队列 :通过
msgget((key_t)1234, IPC_CREAT|0600)找到key=1234的消息队列(与发送端使用同一key,确保操作同个队列); - 读取消息 :调用
msgrcv(msgid,&m,128,1,0):msgid:目标消息队列的 ID;&m:用于接收消息的结构体变量地址;128:接收消息的长度(对应结构体中buff的大小);1:指定读取「类型为 1」的消息(需与发送端的m.type一致,才能准确读取对应消息);0:默认阻塞规则(若队列中无对应消息,程序会等待直到消息到达);
- 打印消息 :通过
printf输出读取到的消息内容。

可以看到 我们每次执行一次b.c 消息队列的个数就减少1
二、进程与线程再回顾
①先理清基础概念:进程与线程的关系
- 进程 :是 "正在运行的程序",操作系统会给它分配独立的资源(内存、文件句柄等)就是一个正在运行的程序。
- 线程 :是 "进程内的执行单元",它共享进程的资源 ,但有自己的执行流程;操作系统调度的最小单位是线程。(是进程内部的一条执行路径)
- "同一东西的两个角度":
- 从「资源分配」看:这是进程(进程持有资源);
- 从「调度 / 执行」看:这是线程(线程负责执行代码)。
②单线程程序:只有main()一个执行流
单线程程序的执行逻辑很简单:
- 整个程序只有一个执行入口
main(),代码从main()的第一行开始,从头到尾顺序执行,直到main()结束,程序(进程)也就终止了。
③多线程程序:main() + 线程函数void* fun(void* arg) 同时执行
多线程程序会同时运行多个执行流,其中:
main():是主线程的执行函数 (进程启动后,默认会创建一个主线程,执行main()里的代码)。void* fun(void* arg):是自定义线程的执行函数(你需要手动创建新线程,让新线程执行这个函数里的代码)。
核心特点:
- 这两个函数是 **"同时执行"** 的:主线程在执行
main()的同时,新线程在执行fun(); - 线程函数的格式是固定要求 :
- 返回值必须是
void*(执行完可返回数据); - 参数必须是
void* arg(可给线程传递任意类型的参数)。
- 返回值必须是
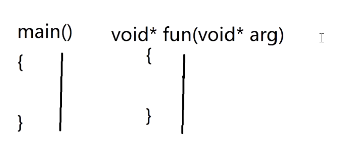
④线程实现
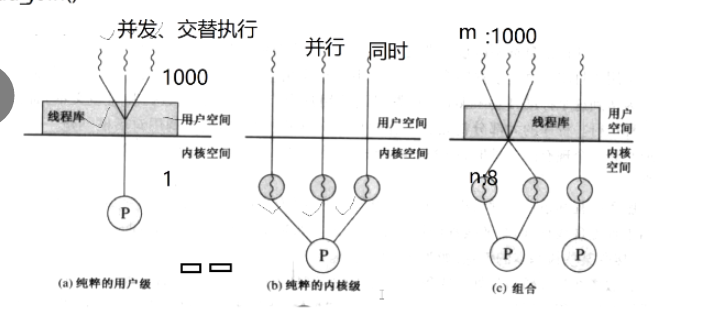
一、用户级线程(对应图示 (a))
实现方式
- 由用户空间的 "线程库"(而非操作系统内核)管理和调度,内核完全感知不到线程的存在,只把整个进程当作一个单一的执行单元。
核心特点
- 线程是 "模拟" 的:进程内的多个用户级线程,对内核而言只有 "一条执行路径",线程的切换、调度由线程库在用户空间完成;
- 开销小:线程创建、切换无需内核参与,速度快、资源消耗少;
- 无法利用多处理器并行 :即使有多个处理器,内核只能将整个进程分配给一个处理器,所以多个用户级线程只能并发(交替)执行,不能并行(同一时刻同时执行)。
二、内核级线程(对应图示 (b))
实现方式
- 由操作系统内核直接管理和调度,内核能感知到每个线程的存在,线程的创建、切换、调度都由内核完成。
核心特点
- 线程是 "真实" 的:每个内核级线程都是独立的调度单元,内核会为其分配 CPU 时间片;
- 开销大:线程的创建、切换需要陷入内核态,资源消耗多、速度慢;
- 可利用多处理器并行 :多个内核级线程可以被内核分配到不同处理器上,实现同一时刻的并行执行(如图示 (b) 中多个线程同时运行)。
三、组合方式(对应图示 (c))
实际系统常采用 "用户级线程 + 内核级线程" 的组合模型:
- 进程内的多个用户级线程,映射到少量内核级线程上;
- 既保留了用户级线程 "开销小" 的优势,又能通过内核级线程利用多处理器实现并行。
两类线程的核心差异总结
| 维度 | 用户级线程 | 内核级线程 |
|---|---|---|
| 管理主体 | 用户空间的线程库 | 操作系统内核 |
| 内核感知性 | 内核无感知(只认进程) | 内核可感知每个线程 |
| 线程开销 | 小(用户空间完成操作) | 大(需内核参与操作) |
| 多处理器利用能力 | 无法并行,只能并发 | 可利用多处理器实现并行 |
三、并发与并行的核心概念
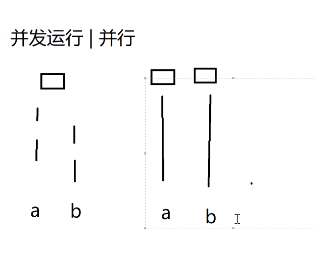
一、并发运行
- 定义 :在同一个时间段内 ,多个任务(如程序 a、b)都有执行动作,但并非同一时刻同时执行。
- 执行方式 :
- 若只有单个处理器 :处理器会在 a、b 两个任务的执行路径之间快速交替切换(比如先执行 a 的一段代码,再切换执行 b 的一段代码),从宏观上看 a、b "同时在运行"。
- 若有多个处理器:也可以是多个任务在不同处理器上交替执行,但核心是 "时间段内都有执行,非同一时刻"。
- 对应图示左侧:a、b 的执行路径是 "交替中断" 的(体现 "切换执行")。
二、并行运行
- 定义 :在同一时刻 ,多个任务(如程序 a、b)是真正同时执行的。
- 执行条件 :必须要有多个处理器(至少 2 个)------ 比如处理器 1 执行 a 的路径,处理器 2 同时执行 b 的路径,二者在时间上完全重叠。
- 对应图示右侧:a、b 的执行路径是 "连续无中断" 的(体现 "同时执行")。
三、核心区别总结
| 维度 | 并发运行 | 并行运行 |
|---|---|---|
| 核心特征 | 时间段内都有执行,非同一时刻 | 同一时刻,真正同时执行 |
| 处理器要求 | 单个 / 多个处理器均可 | 必须多个处理器 |
| 执行方式 | 任务间交替切换 | 任务在不同处理器上同时执行 |
补充:模拟两个线程对打印机的访问
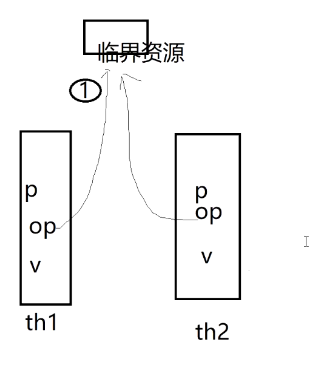
极简核心总结(贴合图片 + 信号量 = 1,全考点覆盖,直接记)
- 临界资源 :
th1/th2共同访问的共享资源,同一时刻只能被1 个线程操作,否则会数据错乱; - 信号量(值 = 1):解决临界资源竞争的同步工具,初始值固定为 1;
- P 操作 :信号量 - 1,线程申请访问临界资源,成功则独占,失败则阻塞等待;
- V 操作 :信号量 + 1,线程用完释放临界资源,唤醒等待的线程;
- 核心效果 :通过 P/V 配对使用,保证
th1和th2永远交替访问临界资源,不会同时操作。
cpp
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <pthread.h>
#include <semaphore.h>
sem_t sem;
void* fun1(void* arg)
{
for(int i = 0; i < 5; i++ )
{
sem_wait(&sem); // P操作:申请信号量
// ------------------- 临界区开始 -------------------
printf("A");
fflush(stdout);
int n = rand() % 3;
sleep(n);
printf("A");
fflush(stdout);
// ------------------- 临界区结束 -------------------
sem_post(&sem); // V操作:释放信号量
n = rand() % 3;
sleep(n);
}
}
void* fun2(void* arg)
{
for(int i = 0; i < 5; i++ )
{
sem_wait(&sem); // P操作:申请信号量
// ------------------- 临界区开始 -------------------
printf("B");
fflush(stdout);
int n = rand() % 3;
sleep(n);
printf("B");
fflush(stdout);
// ------------------- 临界区结束 -------------------
sem_post(&sem); // V操作:释放信号量
n = rand() % 3;
sleep(n);
}
}
int main()
{
sem_init(&sem,0,1); // 初始化信号量,值为1
pthread_t id1,id2;
pthread_create(&id1,NULL,fun1,NULL);
pthread_create(&id2,NULL,fun2,NULL);
pthread_join(id1,NULL);
pthread_join(id2,NULL);
sem_destroy(&sem); // 销毁信号量
exit(0);
}1. 核心功能
基于信号量(值 = 1) 实现 2 个线程的同步互斥,保证打印输出 AA/BB 成对出现,不会乱序成ABAB这类情况。
2. 关键重点
定义全局信号量sem,主线程中sem_init(&sem,0,1)初始化值为 1,实现互斥锁效果。
sem_wait(&sem)=P 操作、sem_post(&sem)=V 操作,二者严格包裹临界区。
【临界区】:两个线程中printf("A")+printf("A") / printf("B")+printf("B") 代码段,是被保护的核心,同一时刻仅 1 个线程能进入执行。
临界区内fflush(stdout):强制刷新输出缓冲区,确保字符即时打印,避免输出卡顿 / 错乱。
临界区外的sleep(n):模拟线程业务耗时,体现「线程交替执行、临界区独占访问」的效果。
3. 执行效果
线程 1 固定输出成对AA,线程 2 固定输出成对BB,最终结果只会是AAAAAABBBBBB/BBBBBBAAAAAA或交替成对的形式,绝对不会出现交叉乱序。
4. 收尾规范
主线程通过pthread_join等待子线程执行完毕,最后sem_destroy(&sem)销毁信号量,释放资源无泄漏。
创建三个线程,第一个线程 打印A 第二个线程 打印B 第三个线程 打印C
要求:打印出来的顺序 ABCABCABC.........
信号量的选择 要几个信号量 就要看我们要控制几个地方
ABC显然是不能用 同一个信号进行控制 A打印完 B才能打印 B打印完 C才能打印
代码如下:
cpp
#include <stdio.h>
#include <pthread.h>
#include <semaphore.h>
#include <unistd.h>
// 定义3个信号量,控制线程执行顺序
sem_t sem1, sem2, sem3;
// 线程1:打印A
void* fun1(void* arg) {
for (int i = 0; i < 3; i++) { // 循环3次,对应ABCABCABC
sem_wait(&sem1); // 等待sem1(初始值1,第一个执行)
printf("A");
fflush(stdout);
sem_post(&sem2); // 唤醒线程2(sem2+1)
}
return NULL;
}
// 线程2:打印B
void* fun2(void* arg) {
for (int i = 0; i < 3; i++) {
sem_wait(&sem2); // 等待线程1唤醒
printf("B");
fflush(stdout);
sem_post(&sem3); // 唤醒线程3(sem3+1)
}
return NULL;
}
// 线程3:打印C
void* fun3(void* arg) {
for (int i = 0; i < 3; i++) {
sem_wait(&sem3); // 等待线程2唤醒
printf("C");
fflush(stdout);
sem_post(&sem1); // 唤醒线程1,形成循环
}
return NULL;
}
int main() {
// 初始化信号量:sem1=1(让线程1先执行),sem2=0、sem3=0(初始阻塞)
sem_init(&sem1, 0, 1);
sem_init(&sem2, 0, 0);
sem_init(&sem3, 0, 0);
pthread_t id1, id2, id3;
pthread_create(&id1, NULL, fun1, NULL);
pthread_create(&id2, NULL, fun2, NULL);
pthread_create(&id3, NULL, fun3, NULL);
pthread_join(id1, NULL);
pthread_join(id2, NULL);
pthread_join(id3, NULL);
sem_destroy(&sem1);
sem_destroy(&sem2);
sem_destroy(&sem3);
printf("\n");
exit(0);
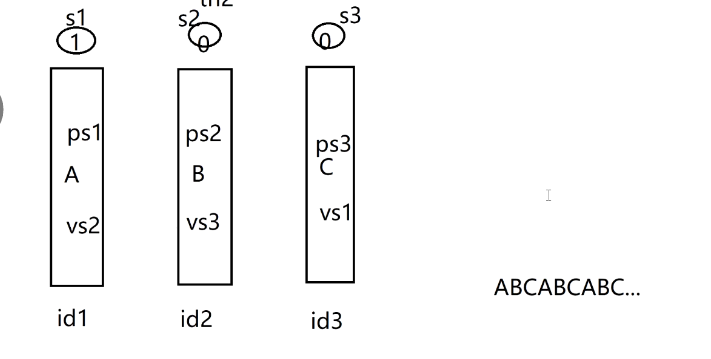
}一、先明确图中符号的含义(对应代码 + 信号量)
s1/s2/s3:代表 3 个信号量,圆圈里的数字是信号量的初始值 (s1=1、s2=0、s3=0);ps1/ps2/ps3:对应代码里的sem_wait(P 操作,申请信号量);vs2/vs3/vs1:对应代码里的sem_post(V 操作,释放信号量);id1/id2/id3:对应 3 个线程,分别执行打印A、B、C的逻辑。
二、完整执行过程(从初始化到循环)
阶段 1:初始化(图中信号量初始值)
s1=1、s2=0、s3=0:- 只有
id1对应的ps1(P 操作)能申请到s1(因为s1=1); id2的ps2、id3的ps3会因为s2=0、s3=0,直接阻塞等待。
- 只有
阶段 2:第一次循环(完成第一个ABC)
-
id1执行(打印 A):ps1:执行sem_wait(&s1),s1从1→0;- 打印
A; vs2:执行sem_post(&s2),s2从0→1(唤醒id2)。
-
id2执行(打印 B):ps2:执行sem_wait(&s2),s2从1→0;- 打印
B; vs3:执行sem_post(&s3),s3从0→1(唤醒id3)。
-
id3执行(打印 C):ps3:执行sem_wait(&s3),s3从1→0;- 打印
C; vs1:执行sem_post(&s1),s1从0→1(唤醒id1,准备下一次循环)。
阶段 3:后续循环(重复 ABC,直到结束)
- 第一个
ABC完成后,s1回到1,s2/s3回到0,和初始化状态完全一致; id1再次通过ps1申请s1,重复 "id1→id2→id3" 的流程,依次打印A→B→C;- 循环 3 次后,最终输出
ABCABCABC(和图右侧的结果完全匹配)。
三、图的核心价值:可视化同步逻辑
这张图把 "信号量的 P/V 操作、线程的唤醒顺序" 完全可视化了:
- 线程的执行顺序是 **
id1→id2→id3→id1**(形成闭环); - 每个线程的 "P 操作申请信号量、V 操作唤醒下一个线程",是实现
ABC顺序的核心; - 信号量的初始值 + P/V 操作的配合,保证了线程 "严格按顺序执行,不会乱序"。
四、互斥锁
互斥锁主要解决的场景就是互斥型场景:我用你就不能用 。一定条件下可以和一个初始值为1的信号量互换。就是初值为1的信号量

一、核心对应关系(图的左半部分)
图中左侧的lock/unlock与P/V操作是等价概念:
lock= 信号量的P操作(申请资源,独占临界区);unlock= 信号量的V操作(释放资源,允许其他线程访问)。
二、互斥锁的 4 个核心接口(图的右半部分,pthread 库函数)
互斥锁是解决临界资源竞争的常用同步工具(和信号量值 = 1 的作用完全一致),这 4 个函数是其完整生命周期:
pthread_mutex_init:初始化互斥锁,准备使用;pthread_mutex_lock:加锁(等价于lock/P 操作),申请临界资源,失败则阻塞;pthread_mutex_unlock:解锁(等价于unlock/V 操作),释放临界资源,唤醒等待的线程;pthread_mutex_destroy:销毁互斥锁,释放资源。
三、关键知识点补充
- 互斥锁是信号量(值 = 1)的简化版:功能完全一致,但接口更简洁,工程中更常用;
- 核心作用:保证同一时刻只有 1 个线程能进入临界区,避免资源竞争;
- 与信号量的区别:互斥锁只能用于 "线程互斥",而信号量还能实现 "线程同步(如 ABC 顺序)"。
五、查看线程ID
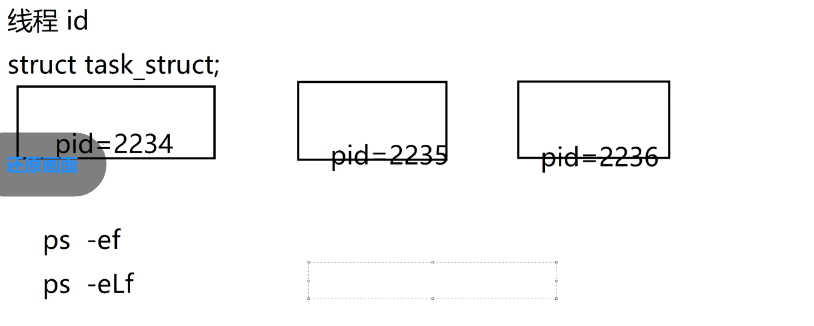
1. 线程 ID 的本质(struct task_struct)
- 图中的
struct task_struct是Linux 内核中描述进程 / 线程的核心结构体 (每个进程 / 线程在内核中都对应一个task_struct实例); - 结构体中的
pid(如2234/2235/2236)是内核给每个线程分配的唯一标识符(线程 ID,也叫轻量级进程 ID)。
2. 查看进程 / 线程的终端指令
图中的ps指令用于在 Linux 系统中查看进程 / 线程信息:
ps -ef:查看系统中所有进程的信息(默认不显示线程);ps -eLf:查看系统中所有进程包含其下线程 的信息(L参数是显示线程的关键)。
3. 核心逻辑
- 同一进程下的多个线程,会对应多个
task_struct(每个线程一个),且各自有独立的pid(线程 ID); - 通过
ps -eLf可以看到进程下的所有线程,而ps -ef只能看到进程本身。