在分布式数据库架构中,MySQL Group Replication(MGR,组复制)凭借高可用、强一致性的特性成为主流集群方案。其稳定运行依赖三大核心机制:故障检测、选主算法与故障转移策略。本文将结合实际配置参数,详细拆解这三大机制的实现逻辑,为运维人员提供实操参考。
一、MGR 故障检测:从"可疑"到"处理"的全流程
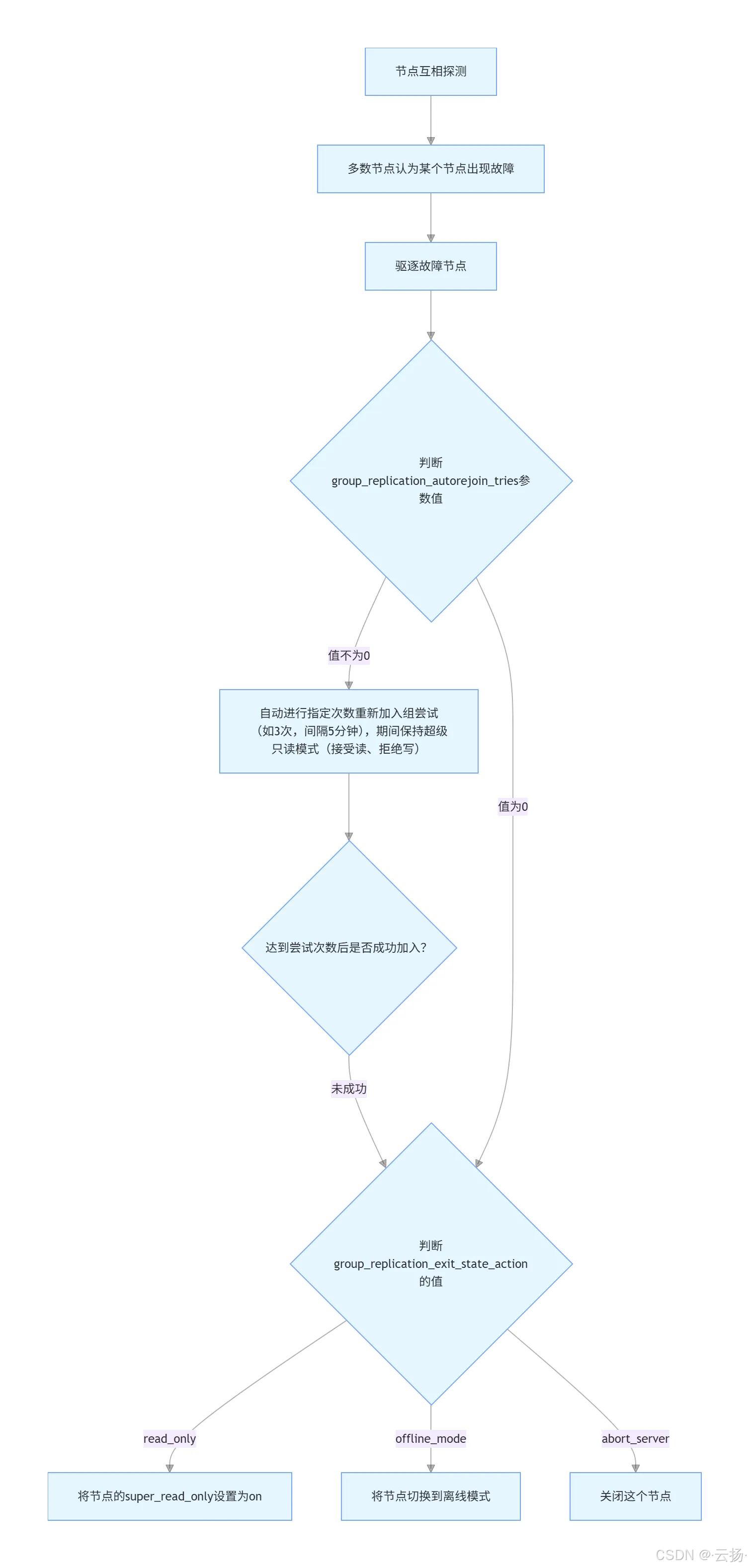
MGR 集群通过节点间协同判断故障,确保单个节点异常不影响整体稳定性,核心流程分为 5 个关键步骤:
-
故障检测启动:集群内所有节点会互发检测消息以确认在线状态。若节点 A 在指定时间内未收到节点 B 的消息,会先将节点 B 标记为"可疑节点",而非直接判定故障,避免网络抖动导致的误判。
-
故障确认与驱逐:仅单个节点标记"可疑"不足以判定故障,需满足"集群多数节点均认为该节点可疑"的条件(如 3 节点集群需至少 2 个节点确认)。一旦满足,集群会正式判定节点 B 故障,并立即将其驱逐出集群,防止故障节点干扰数据同步。
-
故障节点的状态限制 :被驱逐后,节点 B 的状态会自动切换为
error,同时强制设置为只读模式------此时该节点仅允许读操作,拒绝所有写请求,避免数据不一致。 -
自动重加入机制(参数可控) :故障节点是否尝试重新加入集群,由参数
group_replication_autorejoin_tries决定:- 若参数值≠0(如配置为 3):节点会在故障后尝试 3 次重连集群,每次间隔 5 分钟;重连期间始终保持只读模式,避免重连过程中产生数据冲突。
- 若参数值=0:节点不触发自动重连,直接进入最终状态处理环节。
-
最终状态处理(参数决定行为) :当自动重连失败(或未开启自动重连)时,参数
group_replication_exit_state_action定义节点的最终走向:read_only:保持只读模式(super_read_only = ON),适用于需保留故障节点数据供后续分析的场景。offline_mode:切换到离线模式,节点脱离集群但不关闭进程,可手动排查故障后重新加入。abort_server:直接关闭该节点进程,适用于对资源占用敏感、需快速释放资源的集群。
二、MGR 选主算法:单主模式下的"优先级规则"
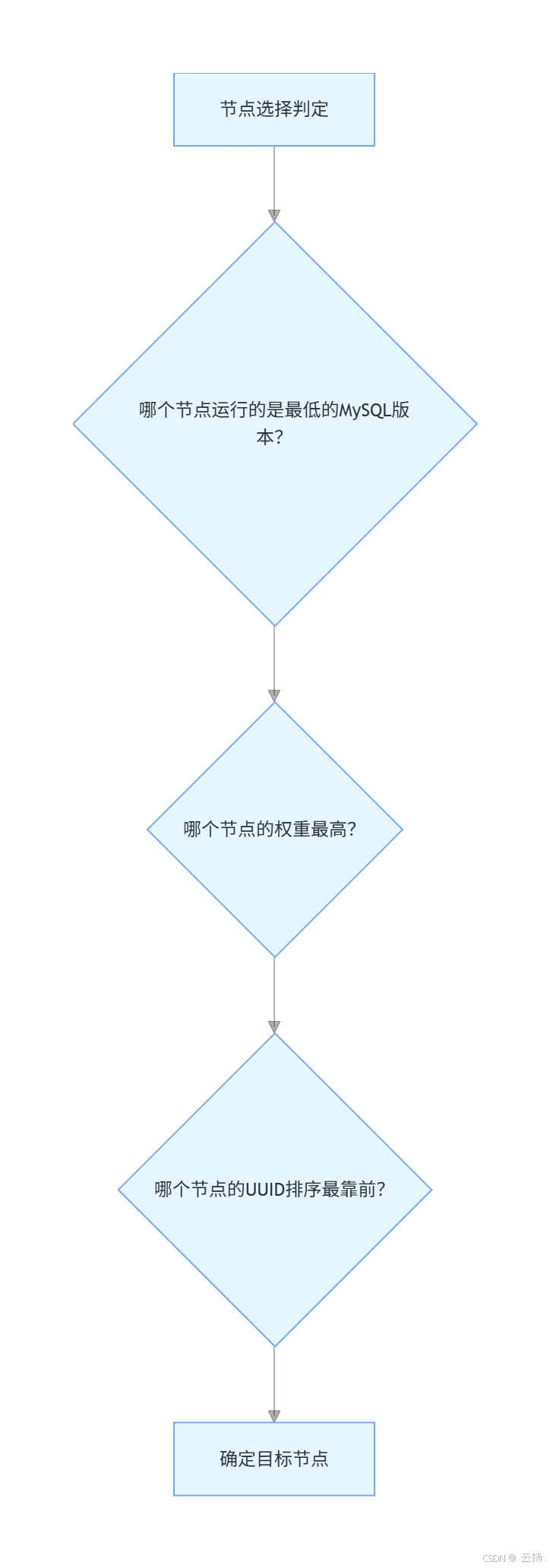
MGR 单主模式(默认模式)下,主节点负责读写操作,从节点仅同步数据。当主节点故障时,集群会自动选举新主,选举优先级遵循"版本→权重→UUID"的三级规则:
1. 首要因素:MySQL 版本(避免日志回放冲突)
版本是选主的核心依据,因高版本 MySQL 的日志格式、特性与低版本存在差异,高版本节点可能无法正常回放低版本日志,故优先选择高版本节点:
- 若所有节点版本 ≥ 8.0.17:按补丁版本排序(如 8.0.32 优于 8.0.31),版本最高者优先。
- 若所有节点版本 ≤ 8.0.16:按主要版本排序(忽略补丁版本,如 8.0.16 与 8.0.15 视为不同主要版本),版本最高者优先。
2. 次要因素:节点权重(自定义优先级)
当多个节点版本相同时,通过参数 group_replication_member_weight 定义优先级:
- 该参数取值范围为 0-100,默认值 50,权重值越大,选主优先级越高(如权重 80 的节点优于权重 50 的节点)。
- 可通过命令
show global variables like 'group_replication_member_weight'查看当前节点的权重配置。
3. 最终因素:UUID 生成顺序(兜底规则)
若版本与权重均相同,集群会按节点 UUID 的生成顺序排序,UUID 生成时间更早、排序更靠前的节点优先成为主节点,确保选主结果唯一,避免"平局"。
多主模式补充说明
多主模式下,所有节点均支持读写操作,故主节点故障时 MGR 本身不处理客户端层面的故障转移;需依赖 MySQL ROUTE 工具,将客户端请求重定向到其他正常的读写节点,实现服务连续性。
三、MGR 故障转移:数据一致性与可用性的权衡
当主节点故障、从节点提升为新主时,新主会面临"积压事务处理"的问题------即主节点故障前未同步到从节点的事务。MGR 提供两种处理策略,需根据业务对"数据一致性"与"服务可用性"的需求选择:
1. 两种核心策略对比
- 可靠性优先:新主节点必须先将所有积压事务应用完成,再开放读写操作。该策略能确保数据 100% 一致,但会因事务处理耗时导致短暂服务不可用(耗时取决于积压事务量),适合金融、电商等对数据一致性要求极高的场景。
- 可用性优先:新主节点不等待积压事务处理,直接开放读写操作。该策略能快速恢复服务可用性,但可能出现"新写数据与未同步的积压事务冲突",导致短暂数据不一致,适合对可用性要求高于一致性的场景(如非核心业务的日志存储)。
2. 可靠性优先的参数配置
若业务选择"可靠性优先"策略,需通过参数 group_replication_consistency 实现:
- 首先通过命令查询当前配置:
show global variables like "group_replication_consistency"; - 若需启用可靠性优先模式,将参数值设为
before_on_primary_failover:设置后,新主节点会自动先处理完所有积压事务,再接收新的读写请求,从配置层面保障数据一致性。
总结:MGR 稳定运行的核心逻辑
MGR 集群的高可用并非单一机制实现,而是"故障检测(及时发现异常)→ 选主算法(快速确定新主)→ 故障转移(平衡一致与可用)"三者协同的结果:
- 故障检测通过"多数节点确认"与"参数控制最终状态",避免误判与资源浪费;
- 选主算法通过"版本→权重→UUID"的优先级,确保新主节点兼容且高效;
- 故障转移通过两种策略的权衡,满足不同业务的核心需求。
对运维人员而言,熟练掌握上述机制及对应参数(如 group_replication_autorejoin_tries、group_replication_member_weight),是应对 MGR 集群异常、保障业务连续性的关键。