摘要
llama.cpp是一个基于C/C++开发的高效大语言模型推理工具,支持跨平台部署和Docker快速启动,核心功能是在有限的计算资源情况下本地部署使用大模型。本文介绍了通过Docker方式部署llama.cpp的步骤,包括如何下载模型、CPU/GPU配置及启动参数说明。llama.cpp提供Web UI界面和OpenAI兼容API,支持文本和多模态对话,对电脑配置要求不高,完全免费且私密,让普通用户也能轻松在本地运行大语言模型。
LLama.cpp简介
- llama.cpp 是一个在 C/C++ 中实现大型语言模型(LLM)推理的工具
2.支持跨平台部署,也支持使用 Docker 快速启动
3.可以运行多种量化模型,对电脑要求不高,CPU/GPU设备均可流畅运行。
支持模型包含:llama系列,qwen系列,gemma系列,Falcon、Alpaca、GPT4All、Chinese LLaMA、Vigogne、Vicuna、Koala、OpenBuddy、Pygmalion、Metharme、WizardLM、Baichuan、Aquila、Starcoder、Mistral AI、Refact、Persimmon、MPT、Bloom、StableLM-3b-4e1t等。
4.开源地址参考:https://github.com/ggml-org/llama.cpp
5.支持模型格式:GUFF(llama提供了转换成GUFF格式的工具)
6.纯C/C++实现,没有任何依赖
7.对Apple Silicon(如M1/M2/M3芯片)提供一流支持 - 通过ARM NEON、Accelerate和Metal框架优化
8.支持x86架构的AVX、AVX2、AVX512和AMX指令集
9.支持1.5位、2位、3位、4位、5位、6位和8位整数量化,实现更快的推理和更低的内存使用
为NVIDIA GPU提供自定义CUDA内核(通过HIP支持AMD GPU,通过MUSA支持摩尔线程MTT GPU)
10.支持Vulkan和SYCL后端
11.CPU+GPU混合推理,可部分加速大于总VRAM容量的模型
12.工作流程图:
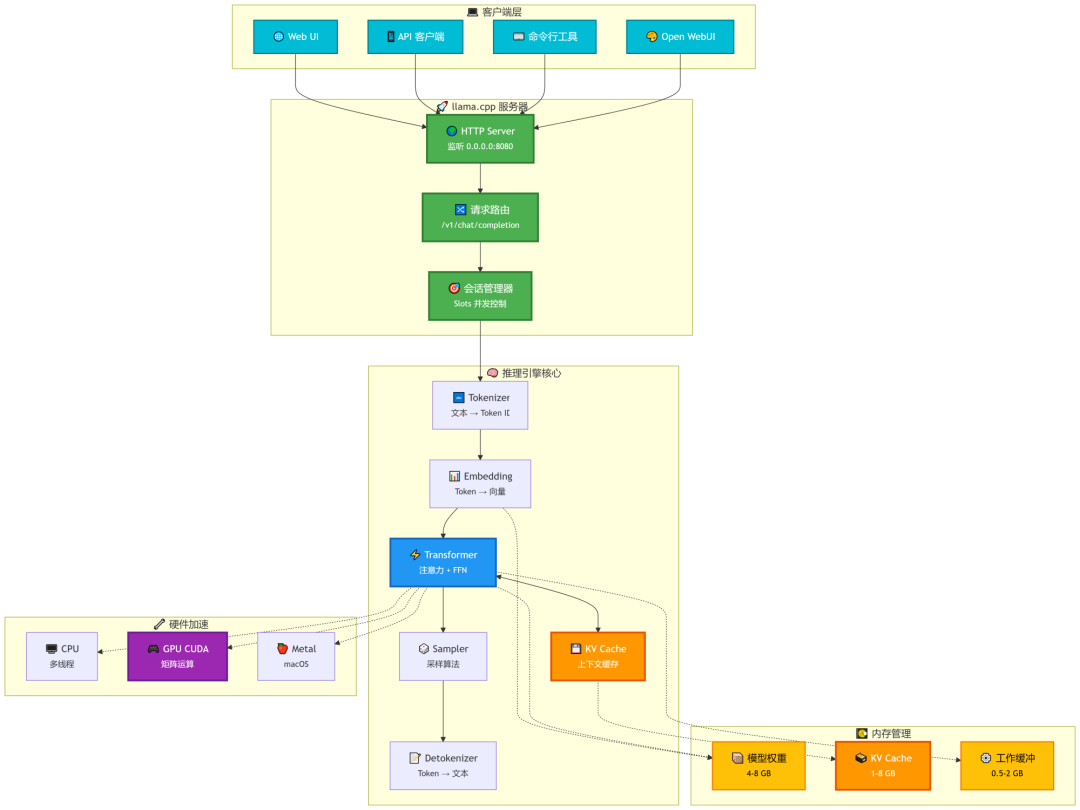
大模型下载
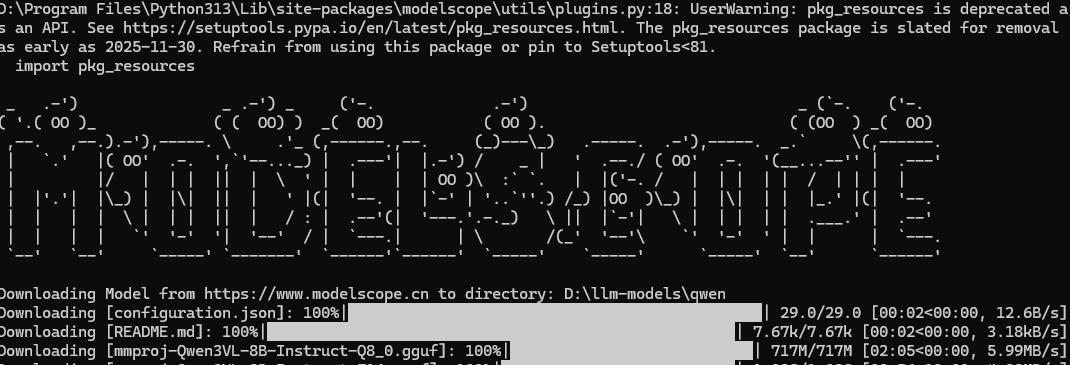
本文以Qwen3-VL-8B-Instruct-GGUF为列演示如何下载大模型。
1.huggingface官网官网下载,https://huggingface.co/models
2.modelscope(魔塔)下载
登录huggingface需要科学上网,所以这里选择modelscope下载。
第一,需要安装python,这个是基础,如果不会的话自己去搜索;
第二,安装modelscope,打开CMD命令行,输入pip install modelscope;
第三,在命令行中输入:
modelscope download --model Qwen/Qwen3-VL-8B-Instruct-GGUF --local_dir qwen
加--local_dir参数是为了指定到的地址。
下面是我的命令行:

通过以上命令可以将Qwen3-VL-8B-Instruct-GGUF中的所有文件下载到d:/llm-models/qwen文件夹中,等待下载完成即可。如果只是下载部分文件也可以自己指定,具体怎么操作可以去查看modelscope中的文档说明:Qwen3-VL-8B-Instruct-GGUF · 模型库
下载llama.cpp
llama.cpp有已经编译好的可直接执行的程序,如果仅仅是部署使用,可直接下载对应版本,下载地址:
运行大模型Llama-cli
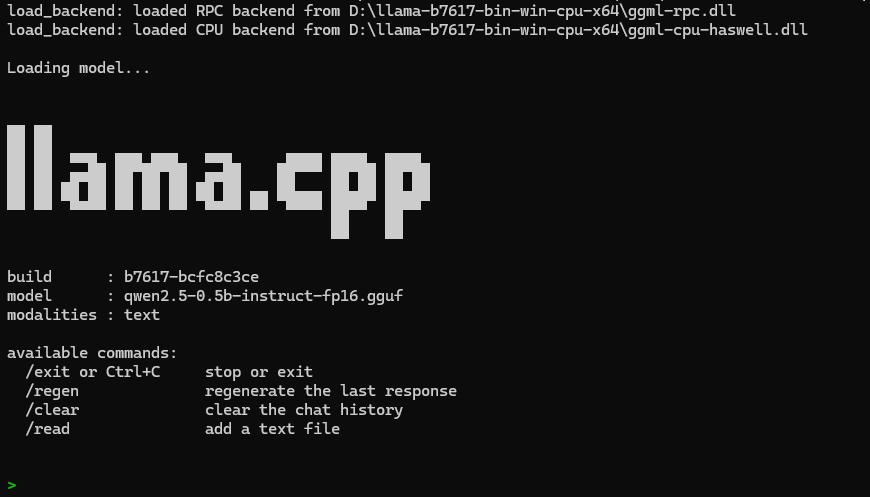
使用llama-cli运行指定的大模型

这是运行成功后的界面:
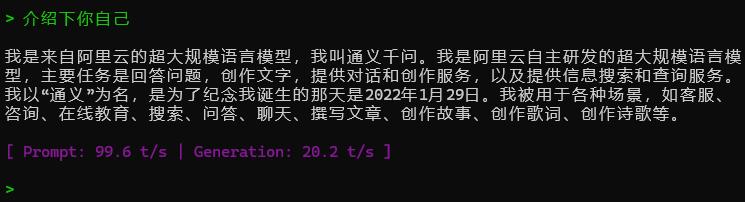
然后就可以直接在上面输入信息与大模型对话了:
编译llama.cpp源码
需要的环境如下:
1.下载cmake,Download CMake
2.带有 "使用 C++ 的桌面开发" 工作负载的 Visual Studio Community Edition
3.下载llama.cpp源码(也可以使用git下载),https://github.com/ggerganov/llama.cpp
使用cmd进入llama.cpp的源码目录:
先运行:cmake -B build
如果没有安装CURL,会出现如下提示:
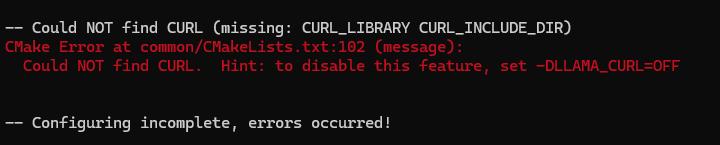
禁用CURL即可,即使用下面的命令:
cmake -B build -DLLAMA_CURL=OFF
会出现如下的警告,不用管。

然后再运行:cmake --build build --config Release
大概10分钟左右,编译好的dll和可执行文件就好了,基本不会出现其他问题。
后记
如果大模型太大,导入时可能会提示缓存不够,那就换个小点的模型。