深度学习常用的框架
常用的有:Caffe,TensorFlow,Keras,PyTorc
Caffe:优点:只需要配置文件即可搭建深度神经网络模型
缺点:安装麻烦,缺失很多新网络模型,近几年几乎不更新
TensorFlow:由Google公司开发:
1.x版本:缺点:代码比较冗余,上手有难度
2.x版本:收购了keras,代码不兼容1.x版本
Keras:基于 TensorFlow 封装
优点:简化代码难度 。
PyTorch:Facebook(现 Meta )开发
优点:上手极容易,直接套用模板
PyTorch安装
可以参考下面链接的文章
https://blog.csdn.net/2401_83998832/article/details/156233860?spm=1001.2014.3001.5502
CPU:又称中央处理器,作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。可以形象地理解为有25%的ALU(运算单元)、有25%的Control(控制单元)、50%的Cache(缓存)单元。
GPU:又称图像处理器,是一种专门在个人电脑等一些移动设备上做图像和图形相关运算工作的微处理器。可以形象地理解为90%的ALU(运算单元),5%的Control(控制单元)、5%的Cache(缓存)。
注意:自己需要下载的版本,还有要注意是cpu还是gpu
PyTorch认识(手写数字识别案例)
利用mnist数据集实现神经网络的图像识别。
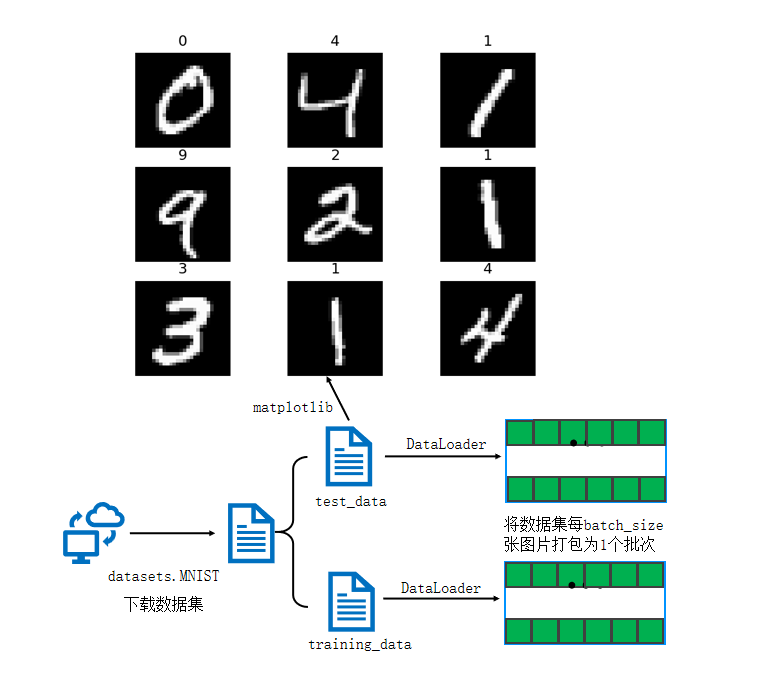
数据集加载与预处理
深度学习的第一步是数据准备,PyTorch 提供了torchvision.datasets模块,内置了 MNIST 等经典数据集,方便开发者直接使用。MNIST 数据集包含 60000 张训练图像和 10000 张测试图像,每张图像为 28×28 像素的灰度图,对应 0-9 十个数字。
下载训练数据集(包含训练图片+标签)
python
training_data = datasets.MNIST( #跳转到函数的内部源代码,pycharm按下ctrl + 鼠标点击
root="data", #表示下载的手写数字 到哪个路径。60000
train=True, #读取下载后的数据中的训练集
download=True, #如果你之前已经下载过了,就不用下载
transform=ToTensor(), )#张量,图片是不能直接传入神经网络模型
下载测试数据集(包含训练图片+标签)
python
test_data = datasets.MNIST( #跳转到函数的内部源代码,pycharm按下ctrl + 鼠标点击
root="data", #表示下载的手写数字 到哪个路径。60000
train=False, #读取下载后的数据中的训练集
download=True, #如果你之前已经下载过了,就不用下载
transform=ToTensor(), )#Tensor是在深度学习中提出并广泛应用的数据类型
#Numpy数组只能在CPU上运行。Tensor可以在GPU上运行。这在深度学习应用中可以显著提高计算速度。
print(len(training_data))创建数据DataLoader(数据加载器)
为了提高训练效率,使用DataLoader将数据集按批次(batch_size)打包,每次训练时批量读取数据,同时支持打乱数据顺序(shuffle=True)
python
# batch_size:将数据集分为多份,每一份为batch_size个数据
# 优点:可以减少内存的使用,提高训练速度
train_dataloader = DataLoader(training_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
for X,y in test_dataloader:#X是表示打包好的每一个数据包
print(f"Shape of X[N,C,H,W]:{X.shape}")#
print(f"Shape of y: f{y.shape} {y.dtype}")
break判断当前设备是否支持GPU,其中mps是苹果m系列芯片的GPU
python
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")神经网络模型构建
定义神经网络 类的继承这种方式
python
class NeuralNetwork(nn.Module): #通过调用类的形式来使用神经网络,神经网络的模型,nn.mdoule
def __init__(self): #python基础关于类,self类自己本身
super().__init__() #继承的父类初始化
self.flatten = nn.Flatten() #展开,创建一个展开对象flatten
self.hidden1 = nn.Linear(28*28,128) #第1个参数:有多少个神经元传入进来,第2个参数:有多少个数据传出去
self.hidden2 = nn.Linear(128,256) #第1个参数:有多少个神经元传入进来,第2个参数:有多少个数据传出去
self.out = nn.Linear(256,10) #输出必须和标签的类别相同,输入必须是上一层的神经元个数
def forward(self,x): #前向传播,你得告诉它 数据的流向 是神经网络层连接起来,函数名称不能改
x = self.flatten(x) #图像进行展开
x = self.hidden1(x)
x = torch.relu(x) #激活函数,torch使用的relu函数
x = self.hidden2(x)
x = torch.relu(x)
x = self.out(x)
return x
model = NeuralNetwork().to(device) #把刚刚创建的模型传入到GPU
print(model)优化器与损失函数选择
优化器
优化器的作用是通过调整模型参数来最小化损失函数,常见的优化器包括:
-
批量梯度下降法(BGD):使用全部样本计算梯度,收敛次数少但每次迭代需要用到所有数据,内存占用大、耗时久;
-
随机梯度下降法(SGD):随机抽取单个样本计算梯度,速度快但收敛波动大,易陷入局部最优,搜索起来比较盲目,并不是每次都朝着最优的方向;
-
小批量梯度下降法(Mini-batch GD):结合前两者优势,将数据分成小批量计算梯度,是目前最常用的优化方式;
-
自适应优化器:如 Adam、RMSprop、AdaGrad 等,能够自动调整学习率,收敛速度更快,适合复杂模型。
损失函数
损失函数用于衡量模型预测结果与真实标签的差异,分类任务常用交叉熵损失函数
python
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.005)CrossEntropyLoss:
输入:pred(形状 N, 10 的 raw logits),标签 y(形状 N,整数类索引)。
内部实现包括 softmax 与负对数似然(log_softmax + NLLLoss)。
默认 reduction='mean',返回单个标量(该批次的平均损失)。
Adam 优化器:
自适应一阶优化器,通常比简单 SGD 收敛更快,适合大多数场景。
lr=0.005 是学习率(步长);你可以根据训练曲线调整(过大会发散,过小收敛慢)。
model.parameters():把模型里可训练的参数传给优化器。
激活函数与梯度问题解决
激活函数的作用是为神经网络引入非线性,使模型能够拟合复杂数据。早期常用的 sigmoid 函数存在梯度消失问题,因为其导数取值范围在 0-0.25 之间,经过多层传播后梯度会趋近于 0,导致深层网络参数无法更新。
梯度消失:如果连乘的因子大部分小于1,最后乘积的结果可能趋于0,也就是梯度消失,后面的网络层的参数不发生变化.
梯度爆炸:如果连乘的因子大部分大于1,最后乘积可能趋于无穷,这就是梯度爆炸
造成上述两个情况的原因:梯度反向传播中的连乘效应。对于更普遍的梯度消失问题,可以考虑以下方案解决: 用ReLU、tanh、P-ReLU、R-ReLU、Maxout等替代sigmoid函数
ReLU 函数有效解决了梯度消失问题,其表达式为f(x)=max(0,x),当 x>0 时导数为 1,能够保持梯度稳定传播,已成为目前深度学习中最常用的激活函数。在上述模型中,我们在全连接层后添加了 ReLU 激活函数,为模型引入非线性能力。
【ReLU】:如果激活函数的导数是1,那么就没有梯度消失问题了
模型训练与测试
模型训练
python
def train(dataloader, model, loss_fn, optimizer):
model.train()
batch_size_num = 1
for X,y in dataloader:
X,y = X.to(device), y.to(device)
pred = model.forward(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_value = loss.item()
if batch_size_num % 100 == 0:
print(f"loss: {loss_value:>7f} [number:{batch_size_num}]")
batch_size_num += 1模型测试
python
def Test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X,y in dataloader:
X,y = X.to(device), y.to(device)
pred = model.forward(X)
test_loss += loss_fn(pred,y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test result: \n Accuracy:{(100*correct)}%, Avg loss:{test_loss}")循环训练和输出
python
epochs = 10
for t in range(epochs):
print(f"epoch {t+1}\n---------------")
train(train_dataloader, model, loss_fn, optimizer)
print("Done!")
Test(test_dataloader, model, loss_fn)完整代码
python
# import torch
# print(torch.__version__)
'''
MNIST包含70000张手写数字图像:60000用于训练,10000用于测试
图像是灰度的,28×28像素的,并且居中的,以减少预处理和加快运行
'''
import torch
from torch import nn #导入神经网络模块
from torch.utils.data import DataLoader #数据包管理工具,打包数据
from torchvision import datasets #封装了很多与图像相关的模型,数据集
from torchvision.transforms import ToTensor #数据转换,张量,将其他类型的数据转换为tensor张量,numpy array
'''下载训练数据集(包含训练图片+标签)'''
training_data = datasets.MNIST( #跳转到函数的内部源代码,pycharm按下ctrl + 鼠标点击
root="data", #表示下载的手写数字 到哪个路径。60000
train=True, #读取下载后的数据中的训练集
download=True, #如果你之前已经下载过了,就不用下载
transform=ToTensor(), #张量,图片是不能直接传入神经网络模型
) #对于pytorch库能够识别的数据一般是tensor张量
'''下载测试数据集(包含训练图片+标签)'''
test_data = datasets.MNIST( #跳转到函数的内部源代码,pycharm按下ctrl + 鼠标点击
root="data", #表示下载的手写数字 到哪个路径。60000
train=False, #读取下载后的数据中的训练集
download=True, #如果你之前已经下载过了,就不用下载
transform=ToTensor(), #Tensor是在深度学习中提出并广泛应用的数据类型
) #Numpy数组只能在CPU上运行。Tensor可以在GPU上运行。这在深度学习应用中可以显著提高计算速度。
print(len(training_data))
# '''展示手写数字图片,把训练集中的59000张图片展示'''
# from matplotlib import pyplot as plt
# figure = plt.figure()
# for i in range(9):
# img,label = training_data[i+59000] #提取第59000张图片
#
# figure.add_subplot(3,3,i+1) #图像窗口中创建多个小窗口,小窗口用于显示图片
# plt.title(label)
# plt.axis("off") #plt.show(I) 显示矢量
# plt.imshow(img.squeeze(),cmap="gray") #plt.imshow()将Numpy数组data中的数据显示为图像,并在图形窗口中显示
# a = img.squeeze() #img.squeeze()从张量img中去掉维度为1的,如果该维度的大小不为1,则张量不会改变
# plt.show()
'''创建数据DataLoader(数据加载器)'''
# batch_size:将数据集分为多份,每一份为batch_size个数据
# 优点:可以减少内存的使用,提高训练速度
train_dataloader = DataLoader(training_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
for X,y in test_dataloader:#X是表示打包好的每一个数据包
print(f"Shape of X[N,C,H,W]:{X.shape}")#
print(f"Shape of y: f{y.shape} {y.dtype}")
break
'''判断当前设备是否支持GPU,其中mps是苹果m系列芯片的GPU'''
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device") #字符串的格式化,CUDA驱动软件的功能:pytorch能够去执行cuda的命令
# 神经网络的模型也需要传入到GPU,1个batch_size的数据集也需要传入到GPU,才可以进行训练
''' 定义神经网络 类的继承这种方式'''
class NeuralNetwork(nn.Module): #通过调用类的形式来使用神经网络,神经网络的模型,nn.mdoule
def __init__(self): #python基础关于类,self类自己本身
super().__init__() #继承的父类初始化
self.flatten = nn.Flatten() #展开,创建一个展开对象flatten
self.hidden1 = nn.Linear(28*28,128) #第1个参数:有多少个神经元传入进来,第2个参数:有多少个数据传出去
self.hidden2 = nn.Linear(128,256) #第1个参数:有多少个神经元传入进来,第2个参数:有多少个数据传出去
self.out = nn.Linear(256,10) #输出必须和标签的类别相同,输入必须是上一层的神经元个数
def forward(self,x): #前向传播,你得告诉它 数据的流向 是神经网络层连接起来,函数名称不能改
x = self.flatten(x) #图像进行展开
x = self.hidden1(x)
x = torch.relu(x) #激活函数,torch使用的relu函数
x = self.hidden2(x)
x = torch.relu(x)
x = self.out(x)
return x
model = NeuralNetwork().to(device) #把刚刚创建的模型传入到GPU
print(model)
def train(dataloader,model,loss_fn,optimizer):
model.train() #告诉模型,我要开始训练,模型中w进行随机化操作,已经更新w,在训练过程中,w会被修改的
# pytorch提供2种方式来切换训练和测试的模式,分别是:model.train() 和 mdoel.eval()
# 一般用法是:在训练开始之前写上model.train(),在测试时写上model.eval()
batch_size_num = 1
for X,y in dataloader: #其中batch为每一个数据的编号
X,y = X.to(device),y.to(device) #把训练数据集和标签传入cpu或GPU
pred = model.forward(X) # .forward可以被省略,父类种已经对此功能进行了设置
loss = loss_fn(pred,y) # 通过交叉熵损失函数计算损失值loss
# Backpropagation 进来一个batch的数据,计算一次梯度,更新一次网络
optimizer.zero_grad() # 梯度值清零
loss.backward() # 反向传播计算得到每个参数的梯度值w
optimizer.step() # 根据梯度更新网络w参数
loss_value = loss.item() # 从tensor数据种提取数据出来,tensor获取损失值
if batch_size_num %100 ==0:
print(f"loss: {loss_value:>7f} [number:{batch_size_num}]")
batch_size_num += 1
def Test(dataloader,model,loss_fn):
size = len(dataloader.dataset) #10000
num_batches = len(dataloader) # 打包的数量
model.eval() #测试,w就不能再更新
test_loss,correct =0,0
with torch.no_grad(): #一个上下文管理器,关闭梯度计算。当你确认不会调用Tensor.backward()的时候
for X,y in dataloader:
X,y = X.to(device),y.to(device)
pred = model.forward(X)
test_loss += loss_fn(pred,y).item() #test_loss是会自动累加每一个批次的损失值
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
a = (pred.argmax(1) == y) #dim=1表示每一行中的最大值对应的索引号,dim=0表示每一列中的最大值对应的索引号
b = (pred.argmax(1) == y).type(torch.float)
test_loss /= num_batches #能来衡量模型测试的好坏
correct /= size #平均的正确率
print(f"Test result: \n Accuracy:{(100*correct)}%, Avg loss:{test_loss}")
loss_fn = nn.CrossEntropyLoss() #创建交叉熵损失函数对象,因为手写字识别一共有十种数字,输出会有10个结果
optimizer = torch.optim.Adam(model.parameters(),lr=0.005) #0.01创建一个优化器,SGD为随机梯度下降算法
# # params:要训练的参数,一般我们传入的都是model.parameters()
# # lr:learning_rate学习率,也就是步长
# # loss表示模型训练后的输出结果与样本标签的差距。如果差距越小,就表示模型训练越好,越逼近真实的模型
# 只跑一轮(可尝试)
# train(train_dataloader,model,loss_fn,optimizer) #训练1次完整的数据。多轮训练
# Test(test_dataloader,model,loss_fn)
epochs = 10
for t in range(epochs):
print(f"epoch {t+1}\n---------------")
train(train_dataloader,model,loss_fn,optimizer)
print("Done!")
Test(test_dataloader,model,loss_fn)