1、在魔塔社区 我的NoteBook 创建
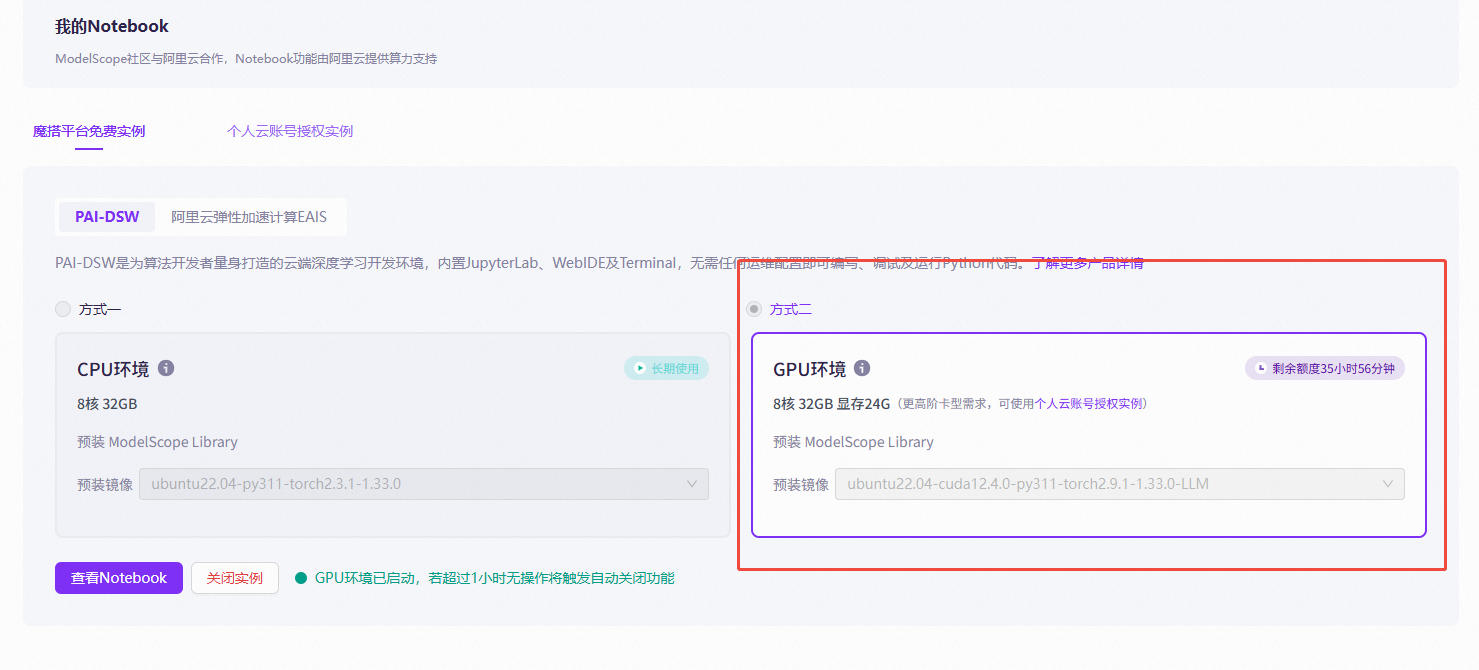
2、查看python3版本
root@dsw-1587650-85987c5ff6-92cls:/mnt/workspace# python3 --version
Python 3.11.11
3、检查 NVIDIA GPU 是否可见
nvidia-smi
Mon Jan 5 17:19:17 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA A10 Off | 00000000:00:07.0 Off | Off |
| 0% 30C P8 20W / 150W | 0MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
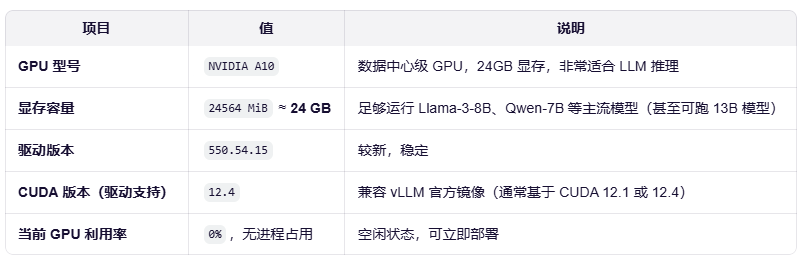
NVIDIA A10 是 Ampere 架构,支持 FP16、INT8、Tensor Core,vLLM 的 PagedAttention 能充分发挥其性能。
3、docker 版本
你是在 魔搭(ModelScope)社区申请的 Notebook(即阿里云 PAI-DSW 实例),这类环境有以下特点:
✅ 你的环境现状(基于你之前的输出)
- 用户:
root(拥有高权限) - Python:3.11.11(✅ 兼容 vLLM)
- GPU:NVIDIA A10 24GB(✅ 非常适合运行 LLM)
- 已能运行
nvidia-smi(✅ 驱动正常)
阿里云 PAI-DSW 实例本身不支持在容器内再次运行 Docker(即不支持嵌套虚拟化)。以下是关键说明:
-
容器化设计:DSW 实例基于容器技术实现,其运行环境本身是容器化的,因此不支持在容器内安装和使用 Docker。
-
替代方案:
- 使用 ECS 部署:如果应用强依赖 Docker,建议使用阿里云 ECS 云服务器来部署。
- 制作自定义镜像:可以通过 DSW 实例制作自定义镜像并保存到阿里云容器镜像服务(ACR),然后在其他服务(如 PAI- DLC 或 PAI-EAS)中使用。
- 使用 Docker 镜像启动实例:可将 Docker 镜像推送到 ACR,然后在创建 DSW 实例时选择该镜像。
-
注意事项:
- DSW 实例不支持在运行时安装 Docker(如通过
apt-get命令)。 - 若需使用特定 Docker 环境,应在创建 DSW 实例时选择支持 Docker 的实例类型(如 Lingjun 资源)。
- DSW 实例不支持在运行时安装 Docker(如通过
总结:DSW 实例不支持 Docker 嵌套运行,但可通过制作自定义镜像或使用 ECS 替代实现 Docker 环境。
改用:阿里云弹性加速计算EAIS
root@eais-bjyut84k3r9ns75m8kvm-0:/mnt/workspace# python --version
Python 3.11.11
root@eais-bjyut84k3r9ns75m8kvm-0:/mnt/workspace# nvidia-smi
Tue Jan 6 09:59:51 2026
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.161.03 Driver Version: 470.161.03 CUDA Version: 12.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla P100-PCIE... On | 00000000:00:08.0 Off | Off |
| N/A 32C P0 26W / 250W | 0MiB / 16280MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
root@eais-bjyut84k3r9ns75m8kvm-0:/mnt/workspace#
- GPU 型号 :Tesla P100-PCIE(即 P100 PCIe 版本)
- 显存容量 :16280 MiB ≈ 16 GB
- CUDA 版本:12.1(驱动支持)
- 当前显存使用:0 MiB(空闲)
参考: vLLM+Qwen3+OpenWebUI保姆级教程!搭建属于你的智能助手
本地部署大模型,其实很简单:只需三步!
-
下载模型
-
选择推理引擎
-
启动服务

vLLM1 是一个高效、易用的大型语言模型(LLM)推理与服务框架,最初由加州大学伯克利分校的 Sky 计算实验室2 开发,现已成为由学术界与工业界共同维护的开源社区项目。
vLLM 的核心优势在于其卓越的性能和广泛的兼容性:
🚀 为什么 vLLM 推理速度如此出众?
• PagedAttention 技术:通过分页管理注意力机制中的键值缓存,极大提升了内存使用效率,有效降低延迟。
• 优化的 CUDA 内核:集成了 FlashAttention 和 FlashInfer 等高效计算技术,显著提升推理吞吐量。
• 高吞吐量解码算法:支持多种解码策略,如并行采样、束搜索(Beam Search)等,灵活适应不同场景。
🎯 为什么 vLLM 被广泛使用?
• 与 HuggingFace 模型无缝集成:无需额外转换,直接加载主流模型。
• 兼容 OpenAI API 接口:方便开发者快速迁移或集成已有项目。
• 支持 Prefix Caching(前缀缓存)与 Multi-LoRA:显著提升服务响应速度与多模型并发能力。
一、Huggingface下载模型
安装包Huggingface
pip install -U huggingface_hub

添加环境变量
export HF_ENDPOINT=https://hf-mirror.com

创建目录 /mnt/workspace/models_hf/Qwen
export HF_ENDPOINT=https://hf-mirror.com
hf download Qwen/Qwen2.5-7B-Instruct-AWQ --local-dir /mnt/workspace/models_hf/Qwen/
pip install "huggingface_hub>=0.34.0,<1.0" --force-reinstall --no-cache-dir
上面的流程不好使 。。 模型无法访问
改用魔塔社区的模型地址:
https://modelscope.cn/models/qwen/Qwen2.5-7B-Instruct/summary
https://modelscope.cn/models/qwen/Qwen2.5-7B-Instruct-AWQ/summary
安装 modelscope
pip install modelscope
下载官方 AWQ 4-bit 量化版(推荐!仅 ~6GB)
modelscope download --model qwen/Qwen2.5-7B-Instruct-AWQ --revision master
原版 FP16 无法在 16GB P100 上推理,请优先使用 -AWQ 版本
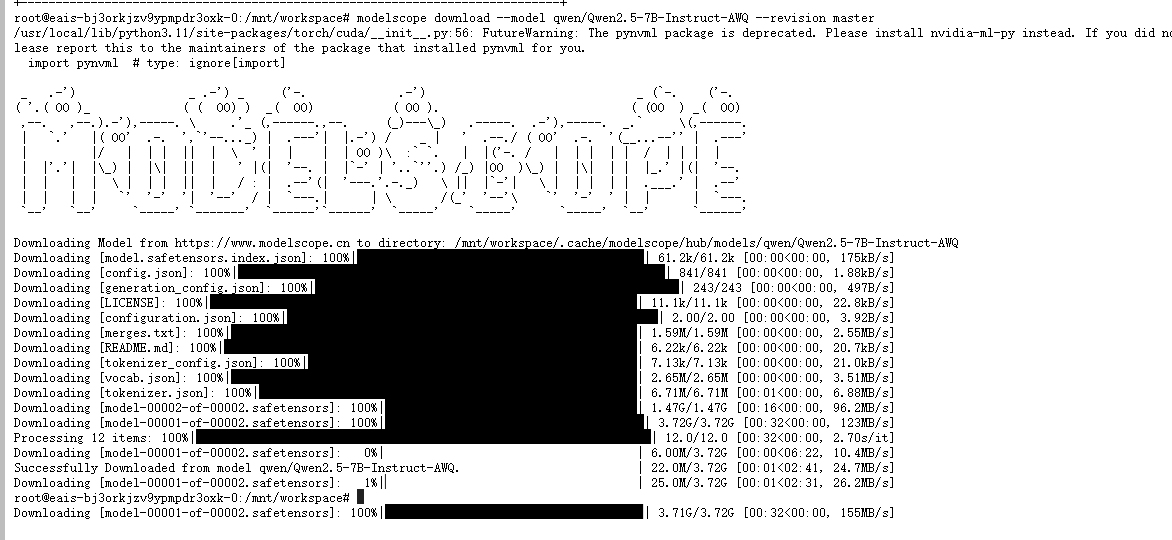
下载后的目录地址:
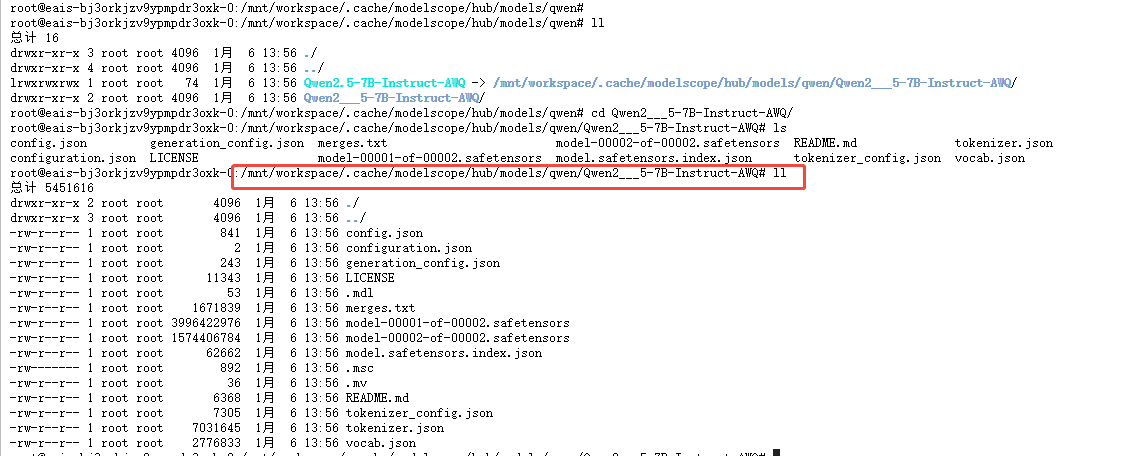
要用pip install 安装vllm
pip install vllm -U
启动命令:
python -m vllm.entrypoints.openai.api_server --model /mnt/workspace/.cache/modelscope/hub/models/qwen/Qwen2.5-7B-Instruct-AWQ --quantization awq --dtype auto --port 8000 --host 0.0.0.0 --tensor-parallel-size 1 --gpu-memory-utilization 0.95 --max-model-len 32768 --max-num-seqs 256
报错了
python -c "import torch; print(torch.version); print('CUDA:', torch.version.cuda); print('Available:', torch.cuda.is_available());print(torch.cuda.get_device_name(0))"
2.9.0+cu128
CUDA: 12.8
Available: True